
1. Introduction
Ce tutoriel vous guidera dans le déploiement, la gestion et la surveillance d'un agent puissant créé avec l'Agent Development Kit (ADK) sur Google Cloud Run. L'ADK vous permet de créer des agents capables de gérer des workflows multi-agents complexes. En tirant parti de Cloud Run, une plate-forme sans serveur entièrement gérée, vous pouvez déployer votre agent en tant qu'application conteneurisée évolutive sans vous soucier de l'infrastructure sous-jacente. Cette combinaison puissante vous permet de vous concentrer sur la logique de base de votre agent tout en bénéficiant de l'environnement robuste et évolutif de Google Cloud.
Tout au long de ce tutoriel, nous allons explorer l'intégration parfaite de l'ADK avec Cloud Run. Vous apprendrez à déployer votre agent, puis vous vous plongerez dans les aspects pratiques de la gestion de votre application dans un environnement de type production. Nous vous expliquerons comment déployer de nouvelles versions de votre agent en toute sécurité en gérant le trafic. Vous pourrez ainsi tester de nouvelles fonctionnalités auprès d'un sous-ensemble d'utilisateurs avant un déploiement complet.
Vous vous entraînerez également à surveiller les performances de votre agent. Nous allons simuler un scénario réel en effectuant un test de charge pour observer les capacités de scaling automatique de Cloud Run en action. Pour obtenir des insights plus détaillés sur le comportement et les performances de votre agent, nous allons activer le traçage avec Cloud Trace. Vous obtiendrez ainsi une vue détaillée de bout en bout des requêtes qui transitent par votre agent, ce qui vous permettra d'identifier et de résoudre les éventuels goulots d'étranglement. À la fin de ce tutoriel, vous aurez une compréhension exhaustive de la façon de déployer, de gérer et de surveiller efficacement vos agents optimisés par ADK sur Cloud Run.
Dans cet atelier de programmation, vous allez suivre une approche par étapes :
- Créer une base de données PostgreSQL sur Cloud SQL à utiliser pour le service de session de base de données de l'agent ADK
- Configurer un agent ADK de base
- Configurer le service de session de base de données à utiliser par le programme d'exécution ADK
- Déployer l'agent initialement sur Cloud Run
- Tester la charge et inspecter l'autoscaling Cloud Run
- Déployer une nouvelle révision de l'agent et augmenter progressivement le trafic vers les nouvelles révisions
- Configurer le traçage cloud et inspecter le traçage de l'exécution de l'agent
Présentation de l'architecture
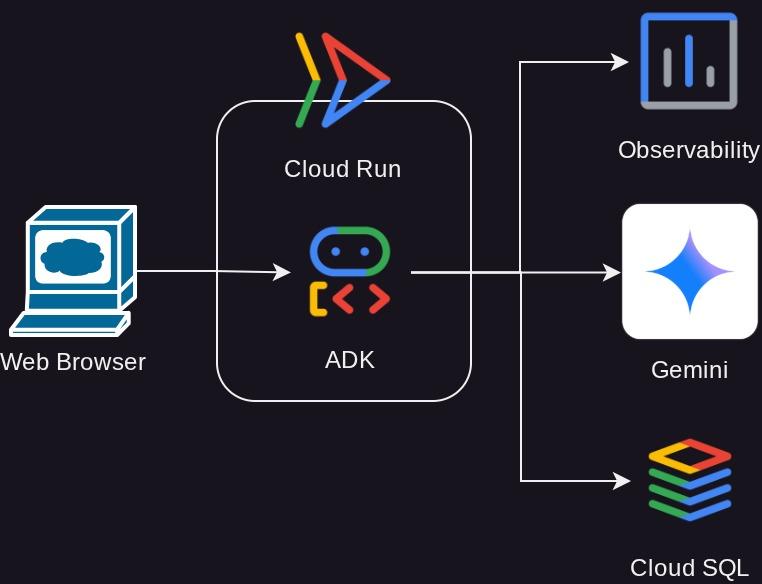
Prérequis
- Vous êtes à l'aise avec Python.
- Comprendre l'architecture full stack de base à l'aide du service HTTP
Points abordés
- Structure ADK et utilitaires locaux
- Configurer l'agent ADK avec le service de session de base de données
- Configurer PostgreSQL dans Cloud SQL pour l'utiliser avec le service de session de base de données
- Déployer l'application sur Cloud Run à l'aide du fichier Dockerfile et configurer les variables d'environnement initiales
- Configurer et tester l'autoscaling Cloud Run avec des tests de charge
- Stratégie de déploiement progressif avec Cloud Run
- Configurer le traçage de l'agent ADK vers Cloud Trace
Prérequis
- Navigateur Web Chrome
- Un compte Gmail
- Un projet Cloud pour lequel la facturation est activée
Cet atelier de programmation, conçu pour les développeurs de tous niveaux (y compris les débutants), utilise Python dans son exemple d'application. Toutefois, vous n'avez pas besoin de maîtriser Python pour comprendre les concepts présentés.
2. 🚀 Préparation de la configuration de l'atelier
Pour ce tutoriel, nous allons utiliser Cloud Shell IDE. Cliquez sur le bouton suivant pour y accéder.
Une fois dans Cloud Shell, clonez le répertoire de travail du modèle pour cet atelier de programmation à partir de GitHub en exécutant la commande suivante. Il créera le répertoire de travail dans le répertoire deploy_and_manage_adk.
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
Ensuite, exécutez la commande suivante dans le terminal pour ouvrir le dépôt cloné en tant que répertoire de travail.
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
Votre interface devrait alors se présenter comme suit :
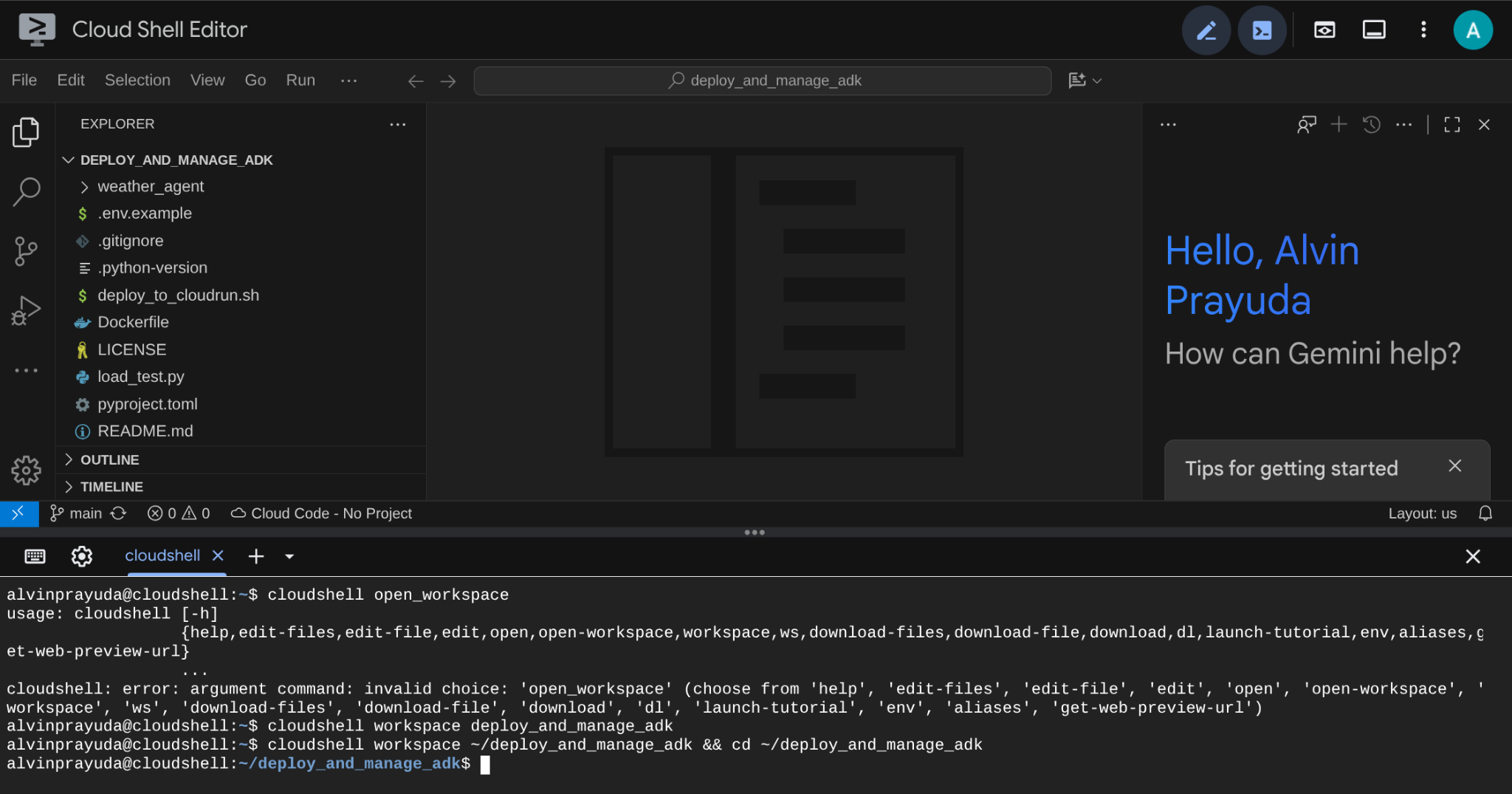
Il s'agit de notre interface principale, avec l'IDE en haut et le terminal en bas. Nous devons maintenant préparer notre terminal pour créer et activer notre projet Google Cloud, qui sera associé au compte de facturation d'essai revendiqué précédemment. Nous avons préparé un script pour vous permettre de toujours vous assurer que votre session de terminal est prête. Exécutez la commande suivante ( assurez-vous d'être déjà dans l'espace de travail deploy_and_manage_adk).
bash setup_trial_project.sh && source .env
Lorsque vous exécutez cette commande, un nom d'ID de projet suggéré s'affiche. Vous pouvez appuyer sur Enter pour continuer.

Après avoir attendu un moment, si vous voyez ce résultat dans votre console, vous pouvez passer à l'étape suivante 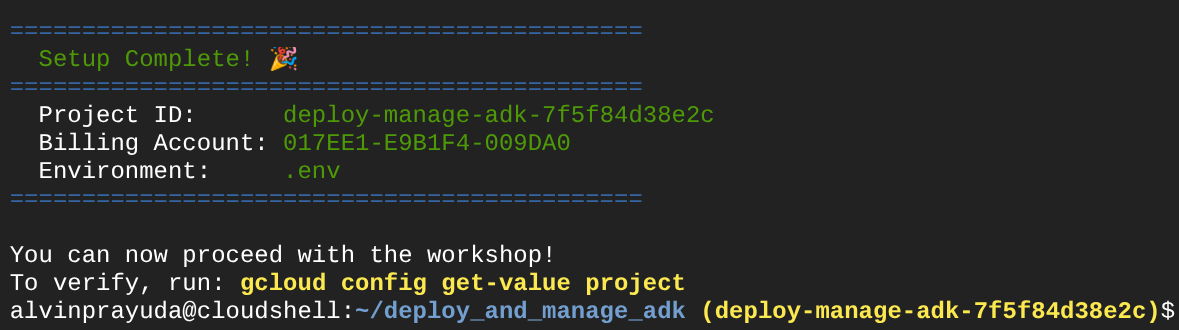
Cela montre que votre terminal est déjà authentifié et défini sur l'ID de projet approprié ( la couleur jaune à côté du chemin d'accès au répertoire actuel). Cette commande vous aide à créer un projet, à trouver et à associer le projet à un compte de facturation d'essai, à préparer le fichier .env pour la configuration de la variable d'environnement et à activer l'ID de projet approprié dans le terminal.
Nous sommes maintenant prêts à passer à l'étape suivante.
3. 🚀 Activer les API
Dans ce tutoriel, nous allons interagir avec la base de données Cloud SQL, le modèle Gemini et Cloud Run. Pour ce faire, vous devrez activer les API suivantes. Exécutez ces commandes pour les activer :
Cela peut prendre un certain temps.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
Si la commande s'exécute correctement, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
4. 🚀 Configuration de l'environnement Python et variables d'environnement
Dans cet atelier de programmation, nous utiliserons Python 3.12 et le gestionnaire de projets Python uv pour simplifier la création et la gestion de la version Python et de l'environnement virtuel. Le package uv est déjà préinstallé sur Cloud Shell.
Exécutez cette commande pour installer les dépendances requises dans l'environnement virtuel du répertoire .venv.
uv sync --frozen
Ensuite, nous allons inspecter les fichiers de variables d'environnement requis pour ce projet. Auparavant, ce fichier était configuré par le script setup_trial_project.sh. Exécutez la commande suivante pour ouvrir le fichier .env dans l'éditeur.
cloudshell open .env
Les configurations suivantes sont déjà appliquées au fichier .env.
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
Pour cet atelier de programmation, nous allons utiliser les valeurs préconfigurées pour GOOGLE_CLOUD_LOCATION et GOOGLE_GENAI_USE_VERTEXAI..
Nous pouvons maintenant passer à l'étape suivante, qui consiste à créer la base de données que notre agent utilisera pour la persistance de l'état et de la session.
5. 🚀 Préparer la base de données CloudSQL
Nous aurons besoin d'une base de données qui sera utilisée ultérieurement par l'agent ADK. Commençons par créer une base de données PostgreSQL sur Cloud SQL. Exécutez d'abord la commande suivante pour créer l'instance de base de données. Nous utiliserons le nom de base de données postgres par défaut. Nous allons donc ignorer la création de la base de données ici. Nous devons également configurer le nom d'utilisateur de notre base de données par défaut (postgres). Pour ce tutoriel, nous allons utiliser ADK-deployment123 comme mot de passe.
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-west1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
Dans la commande ci-dessus, le premier gcloud sql instances create adk-deployment commun est une commande que nous utilisons pour créer l'instance de base de données. Nous utilisons une spécification minimale du bac à sable pour ce tutoriel. La deuxième commande gcloud sql users set-password postgres permet de modifier le mot de passe par défaut du nom d'utilisateur postgres.
Notez que nous utilisons adk-deployment comme nom d'instance de base de données. Une fois l'opération terminée, un résultat semblable à celui ci-dessous doit s'afficher dans le terminal, indiquant que l'instance est prête et que le mot de passe de l'utilisateur par défaut a été modifié.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-west1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
Le déploiement de cette base de données prendra un certain temps. Passons donc à la section suivante en attendant que le déploiement de la base de données Cloud SQL soit prêt.
6. 🚀 Créer l'agent météo avec ADK et Gemini 2.5
Présentation de la structure de répertoires d'ADK
Commençons par explorer ce que l'ADK a à offrir et comment créer l'agent. La documentation complète de l'ADK est disponible sur cette URL . ADK propose de nombreux utilitaires dans l'exécution des commandes CLI. En voici quelques-uns :
- Configurer la structure du répertoire de l'agent
- Essayer rapidement l'interaction via l'entrée/sortie de la CLI
- Configurer rapidement l'interface utilisateur Web de développement local
À présent, vérifions la structure de l'agent dans le répertoire weather_agent.
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
Si vous inspectez init.py et agent.py, vous verrez ce code
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
Explication du code ADK
Ce script contient l'initialisation de notre agent, où nous initialisons les éléments suivants :
- Définissez le modèle à utiliser sur
gemini-2.5-flash. - Fournir l'outil
get_weatherpour prendre en charge la fonctionnalité d'agent météo
Exécuter l'UI Web en local
Nous pouvons maintenant interagir avec l'agent et inspecter son comportement localement. L'ADK nous permet de disposer d'une UI Web de développement pour interagir et inspecter ce qui se passe pendant l'interaction. Exécutez la commande suivante pour démarrer le serveur d'interface utilisateur de développement local :
uv run adk web --port 8080
Il générera une sortie semblable à l'exemple suivant, ce qui signifie que nous pouvons déjà accéder à l'interface Web.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Pour le vérifier, cliquez sur le bouton Aperçu Web en haut de l'éditeur Cloud Shell, puis sélectionnez Prévisualiser sur le port 8080.
La page Web suivante s'affiche. Vous pouvez y sélectionner les agents disponibles dans le menu déroulant en haut à gauche ( dans notre cas, il devrait s'agir de weather_agent) et interagir avec le robot. De nombreuses informations sur les détails du journal s'affichent dans la fenêtre de gauche pendant l'exécution de l'agent.
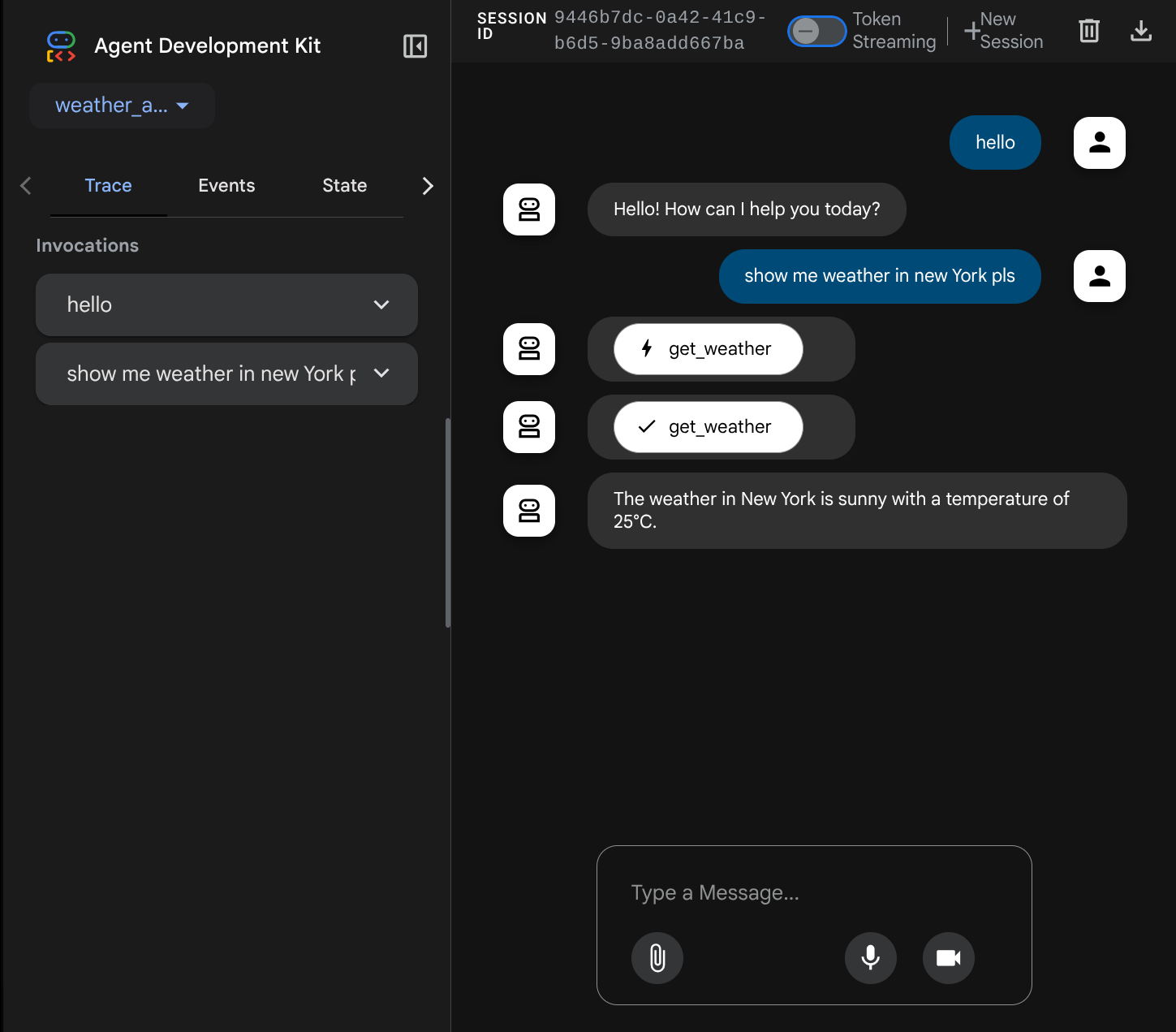
Maintenant, essayez d'interagir avec lui. Dans la barre de gauche, nous pouvons inspecter la trace de chaque entrée pour comprendre le temps nécessaire à chaque action effectuée par l'agent avant de former la réponse finale.
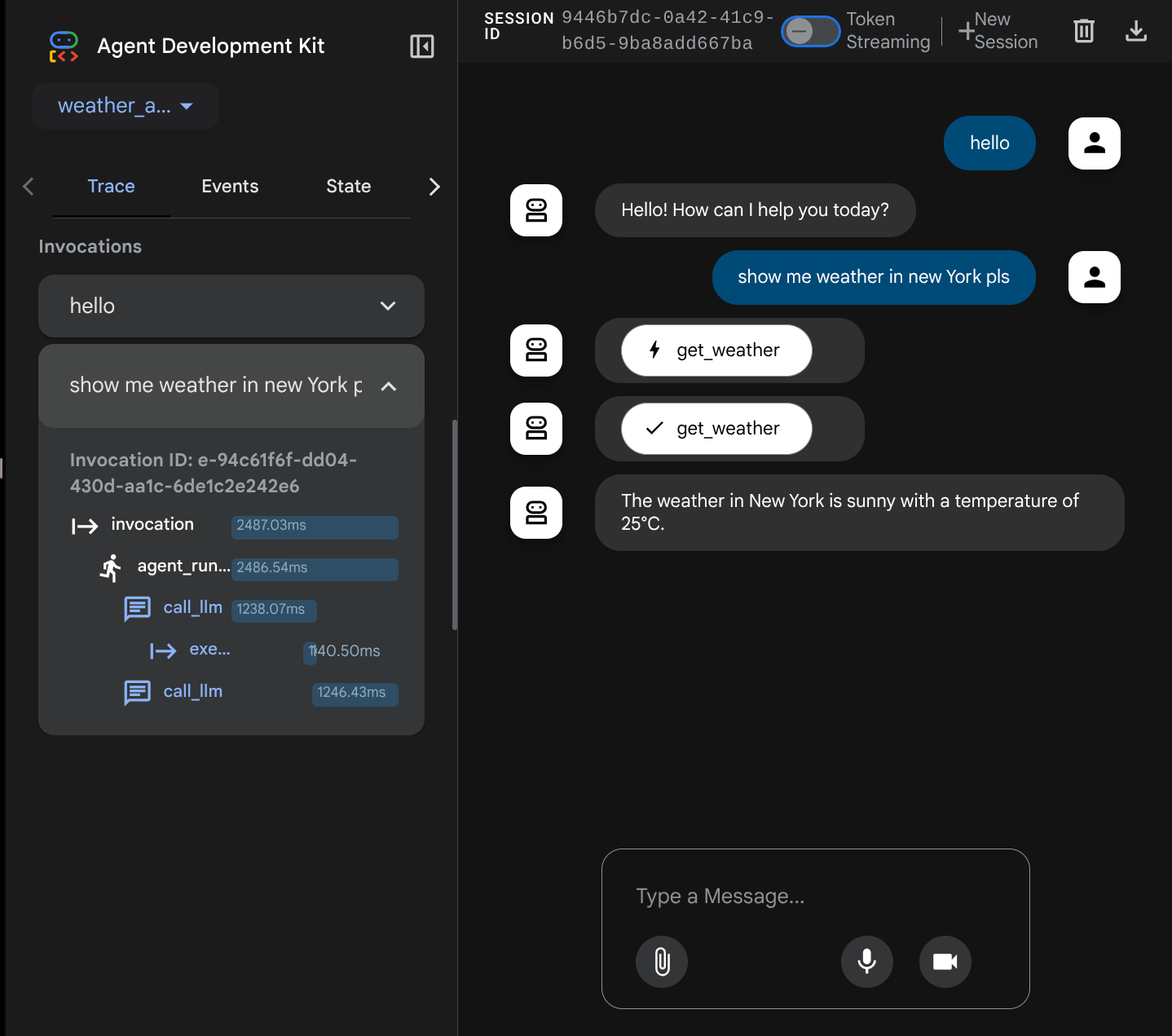
Il s'agit de l'une des fonctionnalités d'observabilité intégrées à ADK. Pour le moment, nous l'inspectons localement. Nous verrons plus tard comment l'intégrer à Cloud Trace afin de disposer d'une trace centralisée de toutes les requêtes.
7. 🚀 Déployer sur Cloud Run
Nous allons maintenant déployer ce service d'agent sur Cloud Run. Pour cette démonstration, ce service sera exposé en tant que service public accessible à tous. Toutefois, gardez à l'esprit que ce n'est pas une bonne pratique, car ce n'est pas sécurisé.
Ce scénario de déploiement vous permet de personnaliser le service de backend de votre agent. Nous utiliserons Dockerfile pour déployer notre agent sur Cloud Run. À ce stade, nous disposons déjà de tous les fichiers nécessaires ( Dockerfile et server.py) pour déployer nos applications sur Cloud Run. Ces deux éléments vous permettent de personnaliser de manière flexible le déploiement de votre agent ( par exemple, en ajoutant des routes de backend personnalisées et/ou un service side-car supplémentaire à des fins de surveillance). Nous aborderons ce point plus en détail ultérieurement.
Maintenant, déployons d'abord le service. Accédez au terminal Cloud Shell et assurez-vous que le projet actuel est configuré sur votre projet actif. Exécutons à nouveau le script d'installation. Vous pouvez également utiliser la commande gcloud config set project [PROJECT_ID] pour configurer votre projet actif.
bash setup_trial_project.sh && source .env
Maintenant, nous devons revenir au fichier .env, l'ouvrir et décommenter la variable DB_CONNECTION_NAME en lui attribuant la valeur correcte.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
Pour obtenir la valeur DB_CONNECTION_NAME, accédons au tableau de bord Cloud SQL.
Cliquez ensuite sur l'instance que vous avez créée. Accédez à la barre de recherche en haut de la console Cloud et saisissez "cloud sql". Cliquez ensuite sur le produit Cloud SQL.
L'instance créée précédemment s'affiche. Cliquez dessus.
Sur la page de l'instance, faites défiler la page jusqu'à la section Se connecter à cette instance, puis copiez le nom de la connexion pour remplacer la valeur DB_CONNECTION_NAME.
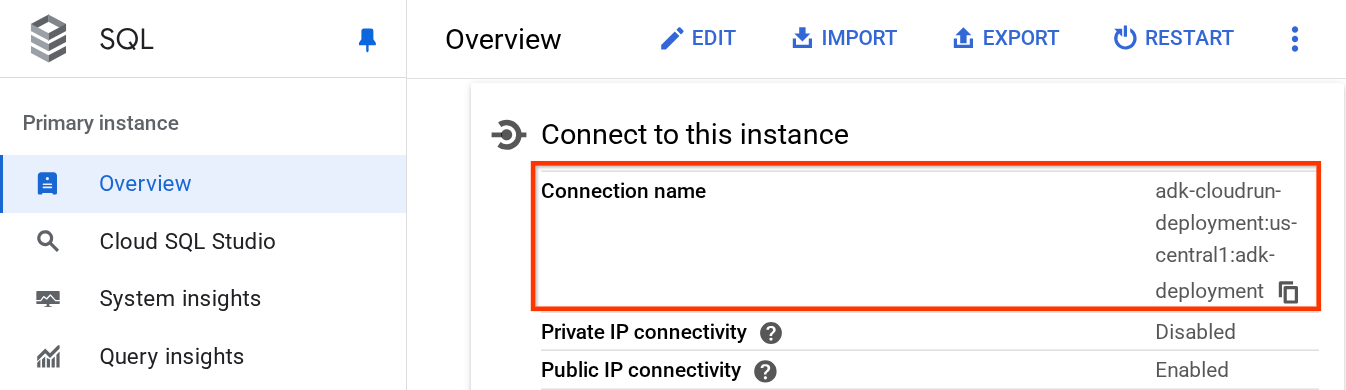
Ouvrez ensuite le fichier .env à l'aide de la commande suivante :
cloudshell edit .env
et modifiez la variable DB_CONNECTION_NAME dans le fichier .env. Votre fichier .env devrait ressembler à l'exemple ci-dessous.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
Exécutez ensuite le script de déploiement.
bash deploy_to_cloudrun.sh
Si vous êtes invité à confirmer la création d'un dépôt Docker Artifact Registry, répondez simplement Y.
En attendant le processus de déploiement, examinons le fichier deploy_to_cloudrun.sh.
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-west1 \
--min 1 \
--memory 1G \
--concurrency 10
Ce script chargera votre variable .env, puis exécutera la commande de déploiement.
Si vous regardez de plus près, vous n'avez besoin que d'une seule commande gcloud run deploy pour effectuer toutes les tâches nécessaires au déploiement d'un service : création de l'image, envoi au registre, déploiement du service, définition de la stratégie IAM, création de la révision et même routage du trafic. Dans cet exemple, nous fournissons déjà le Dockerfile. Cette commande l'utilisera donc pour créer l'application.
Une fois le déploiement terminé, vous devriez obtenir un lien semblable à celui ci-dessous :
https://weather-agent-*******.us-west1.run.app
Une fois cette URL obtenue, vous pouvez utiliser votre application depuis la fenêtre de navigation privée ou votre appareil mobile, et accéder à l'interface utilisateur de développement de l'agent. En attendant le déploiement, examinons le service détaillé que nous venons de déployer dans la section suivante.
8. 💡 Dockerfile et script du serveur backend
Pour rendre l'agent accessible en tant que service, nous allons l'encapsuler dans une application FastAPI qui sera exécutée sur la commande Dockerfile. Vous trouverez ci-dessous le contenu du Dockerfile.
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
Nous pouvons configurer les services nécessaires pour prendre en charge l'agent ici, comme la préparation des services Session, Memory ou Artifact à des fins de production. Voici le code de server.py qui sera utilisé.
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Explication du code du serveur
Voici les éléments définis dans le script server.py :
- Convertissez notre agent en application FastAPI à l'aide de la méthode
get_fast_api_app. De cette façon, nous hériterons de la même définition de route que celle utilisée pour l'interface utilisateur de développement Web. - Configurez le service de session, de mémoire ou d'artefacts nécessaire en ajoutant les arguments de mot clé à la méthode
get_fast_api_app. Dans ce tutoriel, si nous configurons la variable d'environnementSESSION_SERVICE_URI, le service de session l'utilisera. Sinon, il utilisera la session en mémoire. - Nous pouvons ajouter un itinéraire personnalisé pour prendre en charge d'autres logiques métier de backend. Dans le script, nous ajoutons un exemple d'itinéraire de fonctionnalité de commentaires.
- Activez le traçage cloud dans les paramètres d'argument
get_fast_api_apppour envoyer la trace à Google Cloud Trace. - Exécuter le service FastAPI à l'aide d'Uvicorn
Maintenant, si votre déploiement est déjà terminé, veuillez essayer d'interagir avec l'agent depuis l'UI de développement Web en accédant à l'URL Cloud Run.
9. 🚀 Inspecter l'autoscaling Cloud Run avec des tests de charge
Nous allons maintenant examiner les capacités d'autoscaling de Cloud Run. Dans ce scénario, déployons une nouvelle révision tout en activant le nombre maximal de simultanéités par instance. Dans la section précédente, nous avons défini la simultanéité maximale sur 10 ( indicateur --concurrency 10). Nous pouvons donc nous attendre à ce que Cloud Run tente de mettre à l'échelle son instance lorsque nous effectuons un test de charge qui dépasse ce nombre.
Inspectons le fichier load_test.py. Il s'agit du script que nous utiliserons pour effectuer le test de charge à l'aide du framework locust. Ce script effectue les actions suivantes :
- user_id et session_id aléatoires
- Créer un session_id pour le user_id
- Appelez le point de terminaison "/run_sse" avec les user_id et session_id créés.
Si vous l'avez manquée, nous aurons besoin de l'URL du service déployé. Nous pouvons accéder à la console Cloud Run.
Recherchez ensuite votre service weather-agent et cliquez dessus.
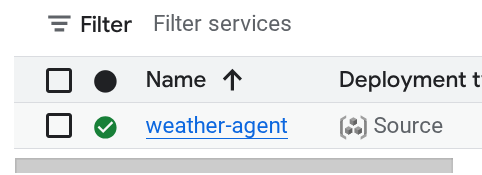
L'URL du service s'affiche juste à côté des informations sur la région. Par exemple,

Pour vous simplifier la tâche, exécutons le script suivant pour obtenir l'URL du service que vous avez récemment déployé et stockez-la dans la variable d'environnement SERVICE_URL.
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-west1 \
--format 'value(status.url)')
Exécutez ensuite la commande suivante pour tester la charge de notre application d'agent.
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
En exécutant cette commande, vous verrez des métriques comme celles-ci s'afficher. ( Dans cet exemple, toutes les exigences sont respectées.)
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
Ensuite, voyons ce qui s'est passé dans Cloud Run. Accédez de nouveau à votre service déployé et consultez le tableau de bord. Vous verrez ainsi comment Cloud Run met automatiquement à l'échelle l'instance pour gérer les requêtes entrantes. Étant donné que nous limitons la simultanéité maximale à 10 par instance, l'instance Cloud Run tentera d'ajuster automatiquement le nombre de conteneurs pour satisfaire cette condition.
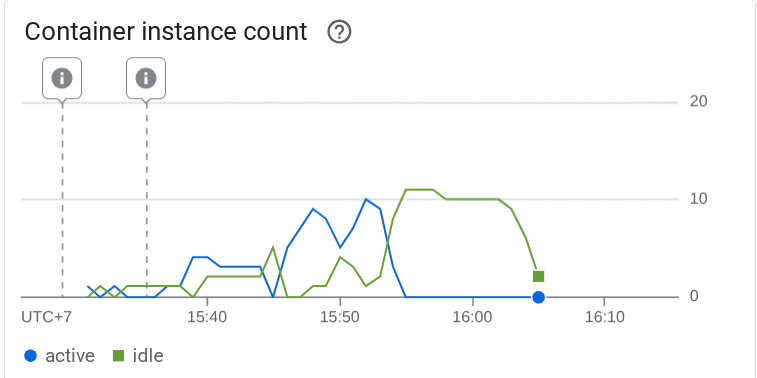
10. 🚀 Déploiement progressif des nouvelles révisions
Prenons l'exemple suivant. Nous souhaitons modifier la requête de l'agent. Ouvrez weather_agent/agent.py avec la commande suivante :
cloudshell edit weather_agent/agent.py
et remplacez-le par le code suivant :
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
Vous souhaitez ensuite publier de nouvelles révisions, mais vous ne voulez pas que tout le trafic de requêtes soit directement redirigé vers la nouvelle version. Nous pouvons effectuer un déploiement progressif avec Cloud Run. Nous devons d'abord déployer une nouvelle révision, mais avec l'indicateur –no-traffic. Enregistrez le script d'agent précédent et exécutez la commande suivante.
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-west1 \
--no-traffic
Une fois l'opération terminée, vous recevrez un journal semblable à celui du processus de déploiement précédent, à la différence du nombre de requêtes traitées. Le trafic diffusé sera de 0 %.
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
Ensuite, accédons au tableau de bord Cloud Run.
Recherchez ensuite votre service weather-agent et cliquez dessus.
Accédez à l'onglet Révisions pour afficher la liste des révisions déployées.
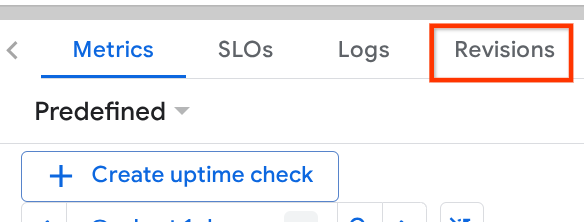
Vous verrez que les nouvelles révisions déployées diffusent 0 %. À partir de là, vous pouvez cliquer sur le bouton à trois points (⋮) et choisir Gérer le trafic.
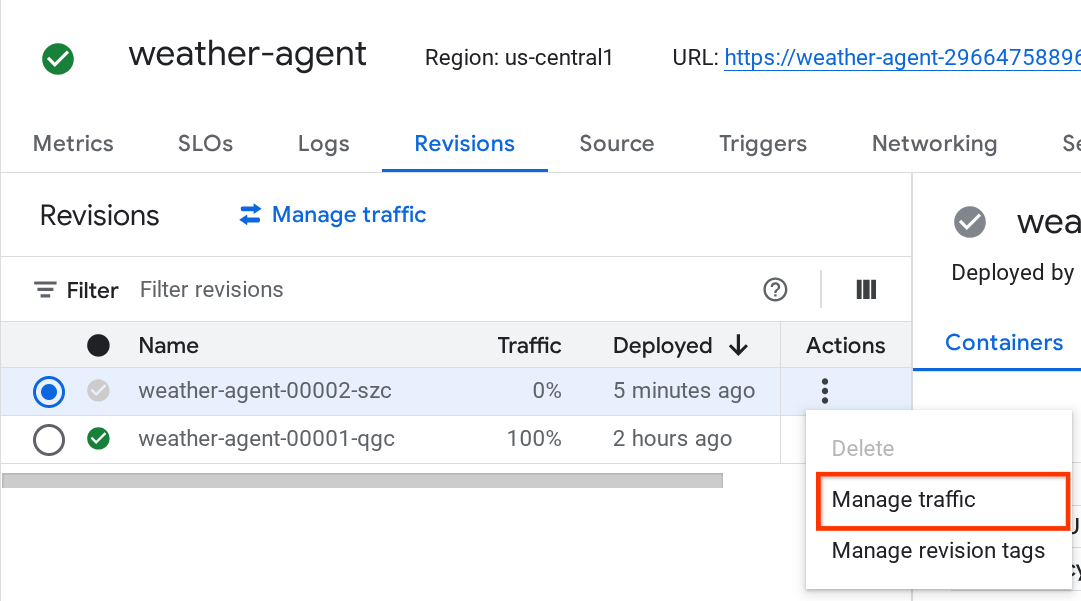
Dans la fenêtre pop-up qui s'affiche, vous pouvez modifier le pourcentage de trafic dirigé vers les révisions.
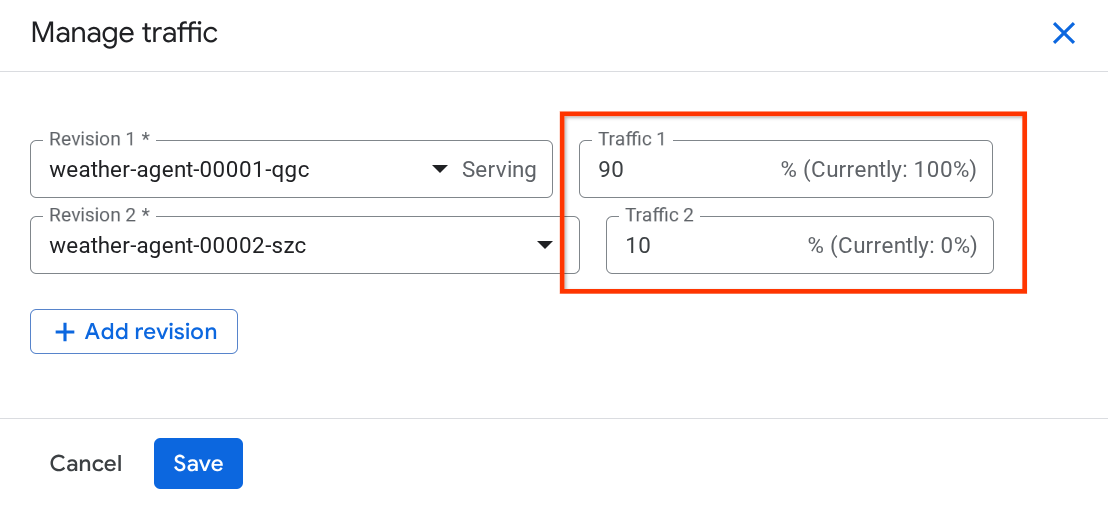
Après un certain temps, le trafic sera réparti proportionnellement en fonction des configurations de pourcentage. Ainsi, nous pouvons facilement revenir aux révisions précédentes en cas de problème avec la nouvelle version.
11. 🚀 ADK Tracing
Les agents créés avec ADK sont déjà compatibles avec le traçage à l'aide de l'intégration OpenTelemetry. Nous disposons de Cloud Trace pour capturer et visualiser ces traces. Examinons le fichier server.py pour voir comment l'activer dans le service que nous avons déployé précédemment.
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
Ici, nous transmettons l'argument trace_to_cloud à True. Si vous effectuez le déploiement avec d'autres options, vous pouvez consulter cette documentation pour savoir comment activer le traçage vers Cloud Trace à partir de différentes options de déploiement.
Essayez d'accéder à l'UI Web de développement de votre service et de discuter avec l'agent. Ensuite, accédez à la page "Explorateur Trace".
Sur la page de l'explorateur de traces, vous verrez que la trace de notre conversation avec l'agent a été envoyée. Vous pouvez le voir dans la section Nom de la portée et filtrer la portée spécifique à notre agent ( nommée agent_run [weather_agent]).
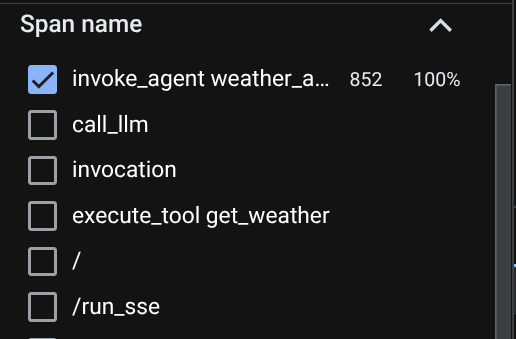
Lorsque les portées sont déjà filtrées, vous pouvez également inspecter chaque trace directement. Elle indique la durée détaillée de chaque action effectuée par l'agent. Par exemple, regardez les images ci-dessous.
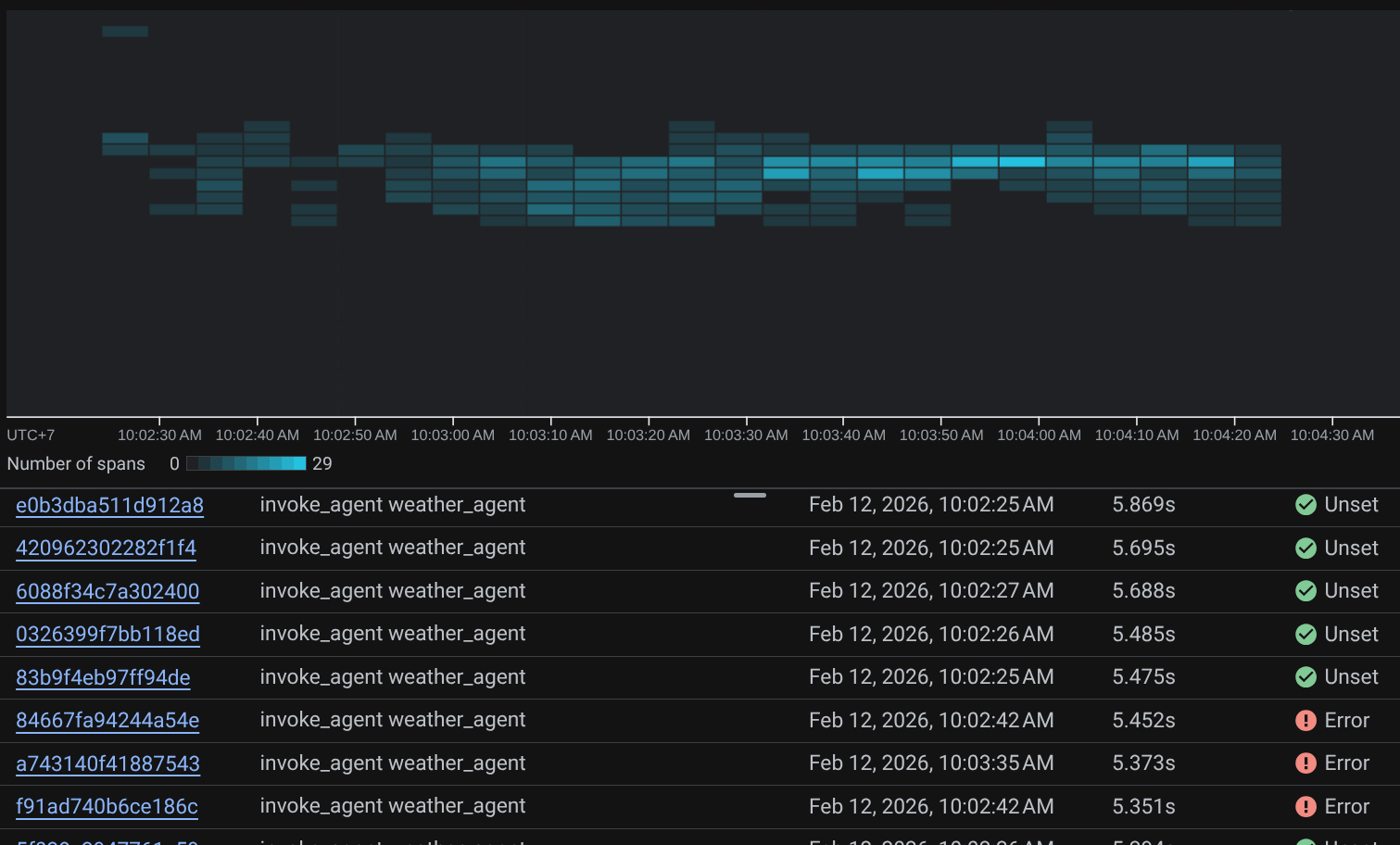
Dans chaque section, vous pouvez inspecter les détails dans les attributs, comme indiqué ci-dessous.
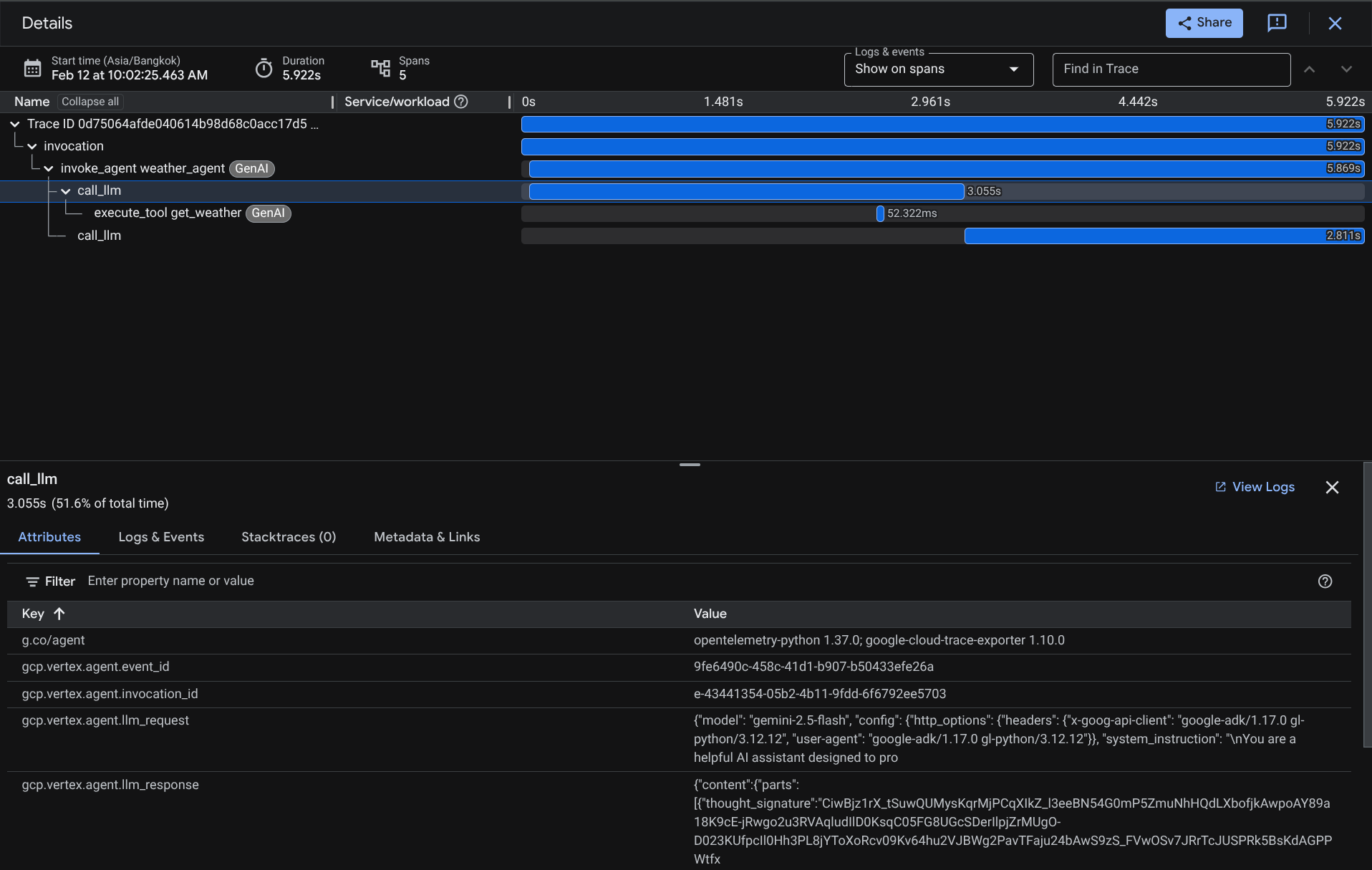
Voilà, nous disposons maintenant d'une bonne observabilité et d'informations sur chaque interaction de notre agent avec l'utilisateur pour nous aider à résoudre les problèmes. N'hésitez pas à essayer différents outils ou workflows.
12. 🎯 Défi
Essayez les workflows multi-agents ou agentiques pour voir comment ils se comportent sous charge et à quoi ressemble la trace.
13. 🧹 Nettoyer
Pour éviter que les ressources utilisées dans cet atelier de programmation soient facturées sur votre compte Google Cloud :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
- Vous pouvez également accéder à Cloud Run dans la console, sélectionner le service que vous venez de déployer, puis le supprimer.