
1. Introduzione
Questo tutorial ti guiderà nel deployment, nella gestione e nel monitoraggio di un potente agente creato con Agent Development Kit (ADK) su Google Cloud Run. L'ADK ti consente di creare agenti in grado di gestire workflow complessi e multi-agente. Sfruttando Cloud Run, una piattaforma serverless completamente gestita, puoi eseguire il deployment del tuo agente come applicazione containerizzata scalabile senza preoccuparti dell'infrastruttura sottostante. Questa potente combinazione ti consente di concentrarti sulla logica di base del tuo agente, sfruttando al contempo l'ambiente solido e scalabile di Google Cloud.
In questo tutorial esploreremo l'integrazione perfetta dell'ADK con Cloud Run. Scoprirai come eseguire il deployment dell'agente e poi approfondirai gli aspetti pratici della gestione dell'applicazione in un ambiente simile a quello di produzione. Spiegheremo come implementare in modo sicuro nuove versioni dell'agente gestendo il traffico, in modo da poter testare nuove funzionalità con un sottoinsieme di utenti prima di un rilascio completo.
Inoltre, acquisirai esperienza pratica con il monitoraggio delle prestazioni del tuo agente. Simuleremo uno scenario reale eseguendo un test di carico per osservare le funzionalità di scalabilità automatica di Cloud Run in azione. Per ottenere informazioni più approfondite sul comportamento e sul rendimento dell'agente, attiveremo la tracciabilità con Cloud Trace. In questo modo, otterrai una visualizzazione end-to-end dettagliata delle richieste mentre attraversano l'agente, il che ti consentirà di identificare e risolvere eventuali colli di bottiglia delle prestazioni. Al termine di questo tutorial, avrai una comprensione completa di come eseguire il deployment, gestire e monitorare in modo efficace gli agenti basati su ADK su Cloud Run.
Nel codelab, seguirai un approccio passo passo come segue:
- Crea un database PostgreSQL su Cloud SQL da utilizzare per il servizio di sessione del database dell'agente ADK
- Configurare un agente ADK di base
- Configura il servizio di sessione del database da utilizzare con ADK Runner
- Esegui il deployment iniziale dell'agente in Cloud Run
- Test di carico e ispezione della scalabilità automatica di Cloud Run
- Esegui il deployment della nuova revisione dell'agente e aumenta gradualmente il traffico verso le nuove revisioni
- Configura Cloud Trace e ispeziona la traccia di esecuzione dell'agente
Panoramica dell'architettura
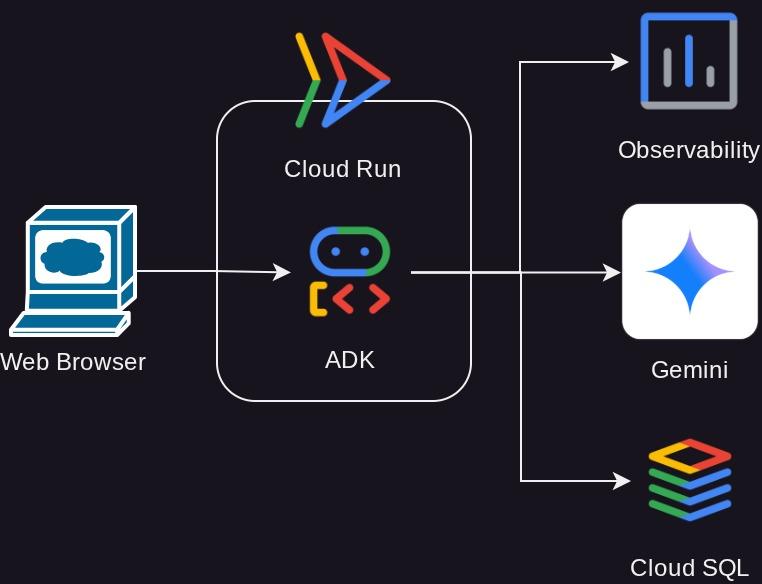
Prerequisiti
- Avere familiarità con Python
- Comprensione dell'architettura full-stack di base utilizzando il servizio HTTP
Cosa imparerai a fare
- Struttura dell'ADK e utilità locali
- Configurare l'agente ADK con il servizio di sessione del database
- Configura PostgreSQL in Cloud SQL da utilizzare con il servizio di sessione del database
- Esegui il deployment dell'applicazione in Cloud Run utilizzando Dockerfile e configura le variabili di ambiente iniziali
- Configura e testa la scalabilità automatica di Cloud Run con il test di carico
- Strategia di rilascio graduale con Cloud Run
- Configura la tracciabilità dell'agente ADK in Cloud Trace
Che cosa ti serve
- Browser web Chrome
- Un account Gmail
- Un progetto cloud con fatturazione abilitata
Questo codelab, progettato per sviluppatori di tutti i livelli (inclusi i principianti), utilizza Python nella sua applicazione di esempio. Tuttavia, la conoscenza di Python non è necessaria per comprendere i concetti presentati.
2. 🚀 Preparazione della configurazione del workshop
Ora utilizzeremo l'IDE Cloud Shell per questo tutorial. Fai clic sul seguente pulsante per accedervi.
Una volta in Cloud Shell, clona la directory di lavoro del modello per questo codelab da GitHub eseguendo il comando seguente. Verrà creata la directory di lavoro nella directory deploy_and_manage_adk
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
Poi, esegui questo comando nel terminale per aprire il repository clonato come directory di lavoro:
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
Dopodiché, l'interfaccia dovrebbe essere simile a questa
Questa sarà la nostra interfaccia principale, con l'IDE in alto e il terminale in basso. Ora dobbiamo preparare il terminale per creare e attivare il nostro progetto Google Cloud, che verrà collegato all'account di fatturazione di prova rivendicato in precedenza. Abbiamo preparato uno script per assicurarti che la sessione del terminale sia sempre pronta. Esegui questo comando ( assicurati di trovarti già all'interno del workspace deploy_and_manage_adk
bash setup_trial_project.sh && source .env
Quando esegui questo comando, ti viene chiesto di inserire il nome dell'ID progetto suggerito. Puoi premere Enter per continuare.

Dopo aver atteso un po' di tempo, se visualizzi questo output nella console, puoi passare al passaggio successivo 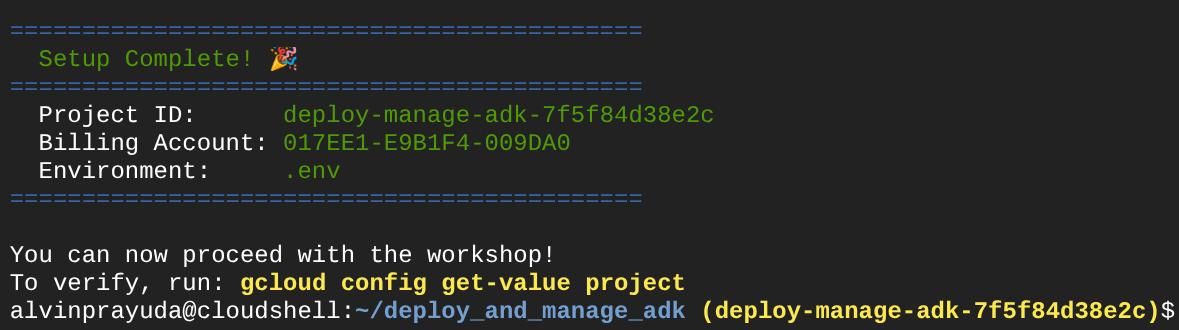
Ciò dimostra che il terminale è già autenticato e impostato sull'ID progetto corretto ( il colore giallo accanto al percorso della directory corrente). Questo comando ti aiuta a creare un nuovo progetto, a trovare e collegare il progetto a un account di fatturazione di prova, a preparare il file .env per la configurazione della variabile di ambiente e ad attivare l'ID progetto corretto nel terminale.
Ora siamo pronti per il passaggio successivo.
3. 🚀 Abilitazione delle API
In questo tutorial, interagiremo con il database CloudSQL, il modello Gemini e Cloud Run. Questi prodotti richiedono l'attivazione della seguente API. Esegui questi comandi per attivarli.
L'operazione potrebbe richiedere qualche istante.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
Se il comando viene eseguito correttamente, dovresti visualizzare un messaggio simile a quello mostrato di seguito:
Operation "operations/..." finished successfully.
4. 🚀 Configurazione dell'ambiente Python e delle variabili di ambiente
In questo codelab utilizzeremo Python 3.12 e uv python project manager per semplificare la necessità di creare e gestire la versione di Python e l'ambiente virtuale. Questo pacchetto uv è già preinstallato su Cloud Shell.
Esegui questo comando per installare le dipendenze richieste nell'ambiente virtuale nella directory .venv
uv sync --frozen
Successivamente, esamineremo i file delle variabili di ambiente richieste per questo progetto. In precedenza, questo file veniva configurato dallo script setup_trial_project.sh. Esegui questo comando per aprire il file .env nell'editor
cloudshell open .env
Vedrai le seguenti configurazioni già applicate nel file .env.
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
Per questo codelab, utilizzeremo i valori preconfigurati per GOOGLE_CLOUD_LOCATION e GOOGLE_GENAI_USE_VERTEXAI.
Ora possiamo passare al passaggio successivo, ovvero la creazione del database che verrà utilizzato dal nostro agente per la persistenza dello stato e della sessione.
5. 🚀 Preparazione del database Cloud SQL
Avremo bisogno di un database da utilizzare in un secondo momento dall'agente ADK. Creiamo un database PostgreSQL su Cloud SQL. Esegui il comando seguente per creare prima l'istanza del database. Utilizzeremo il nome del database postgres predefinito, quindi salteremo la creazione del database. Per il tutorial , dobbiamo configurare anche il nome utente del database predefinito (anche postgres), quindi utilizziamo ADK-deployment123 come password.
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-west1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
Nel comando precedente, il primo gcloud sql instances create adk-deployment comune è un comando che utilizziamo per creare l'istanza del database. Per questo tutorial, utilizziamo una specifica minima della sandbox. Il secondo comando gcloud sql users set-password postgres utilizzato per modificare la password del nome utente postgres predefinito
Tieni presente che utilizziamo adk-deployment come nome dell'istanza di database. Al termine, dovresti visualizzare un output nel terminale simile a quello mostrato di seguito, che indica che l'istanza è pronta e la password utente predefinita è aggiornata.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-west1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
Il deployment di questo database richiede un po' di tempo, quindi passiamo alla sezione successiva mentre attendiamo che il deployment del database Cloud SQL sia pronto.
6. 🚀 Crea l'agente meteo con ADK e Gemini 2.5
Introduzione alla struttura delle directory dell'ADK
Iniziamo esplorando le funzionalità dell'ADK e come creare l'agente. La documentazione completa dell'ADK è disponibile in questo URL . L'ADK ci offre molte utilità nell'esecuzione dei comandi della CLI. Alcuni di questi sono :
- Configura la struttura delle directory dell'agente
- Prova rapidamente l'interazione tramite input/output della CLI
- Configurare rapidamente l'interfaccia web dell'interfaccia utente di sviluppo locale
Ora controlliamo la struttura dell'agente nella directory weather_agent
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
Se ispezioni init.py e agent.py, vedrai questo codice
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
ADK Code Explanation
Questo script contiene l'inizializzazione dell'agente, in cui inizializziamo quanto segue:
- Imposta il modello da utilizzare su
gemini-2.5-flash - Fornisci lo strumento
get_weatherper supportare la funzionalità dell'agente come agente meteo
Esegui l'interfaccia utente web in locale
Ora possiamo interagire con l'agente e ispezionare il suo comportamento localmente. L'ADK ci consente di avere un'interfaccia utente web di sviluppo per interagire e ispezionare ciò che accade durante l'interazione. Esegui questo comando per avviare il server dell'interfaccia utente di sviluppo locale
uv run adk web --port 8080
Verrà generato un output simile al seguente esempio, il che significa che possiamo già accedere all'interfaccia web
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Ora, per verificarlo, fai clic sul pulsante Anteprima web nella parte superiore di Cloud Shell Editor e seleziona Anteprima sulla porta 8080.
Vedrai la seguente pagina web in cui puoi selezionare gli agenti disponibili nel menu a discesa in alto a sinistra ( nel nostro caso dovrebbe essere weather_agent) e interagire con il bot. Nella finestra a sinistra vedrai molte informazioni sui dettagli del log durante il runtime dell'agente.
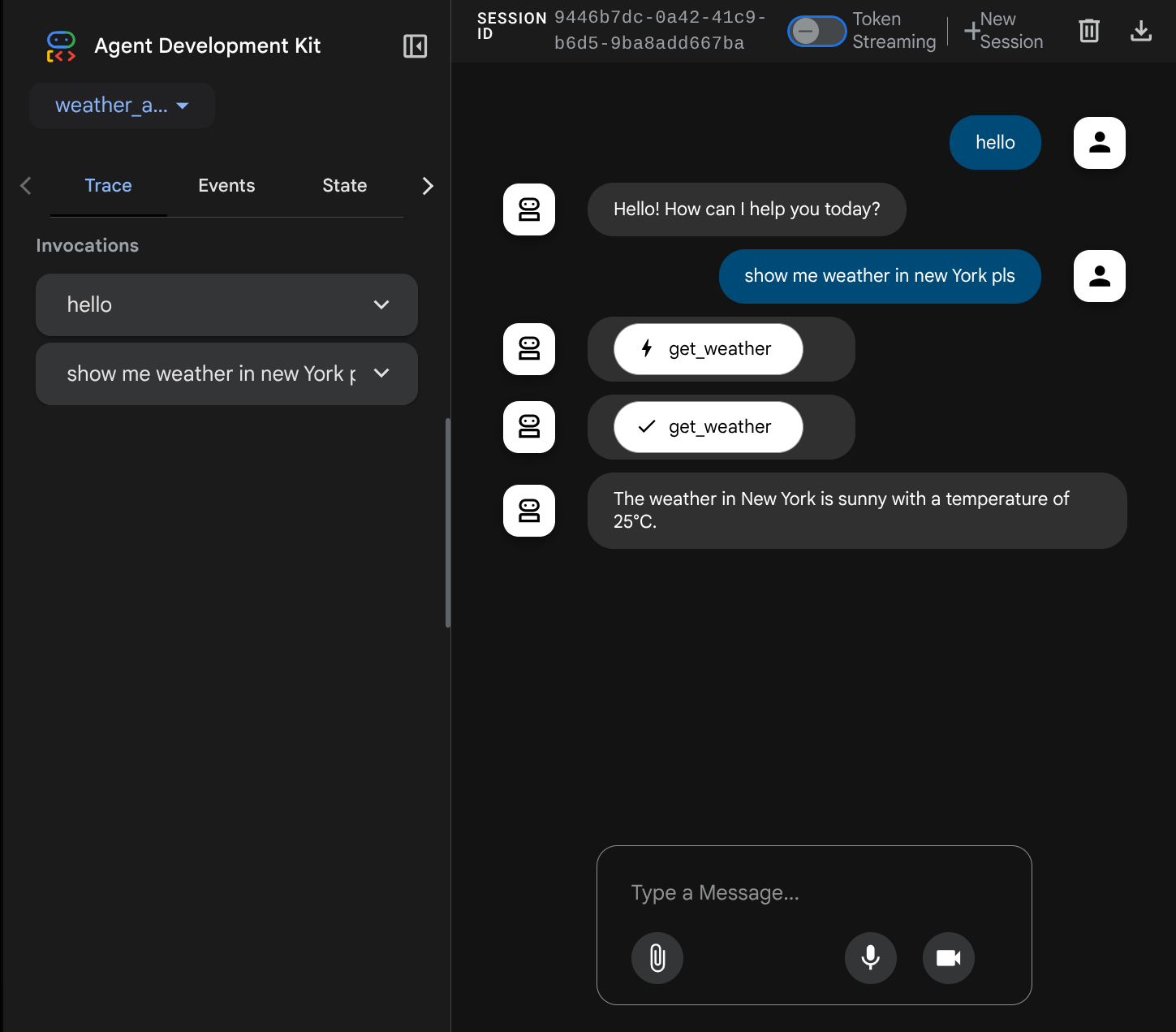
Ora prova a interagire con l'app. Nella barra a sinistra, possiamo esaminare la traccia di ogni input, in modo da capire quanto tempo impiega ogni azione intrapresa dall'agente prima di formare la risposta finale.
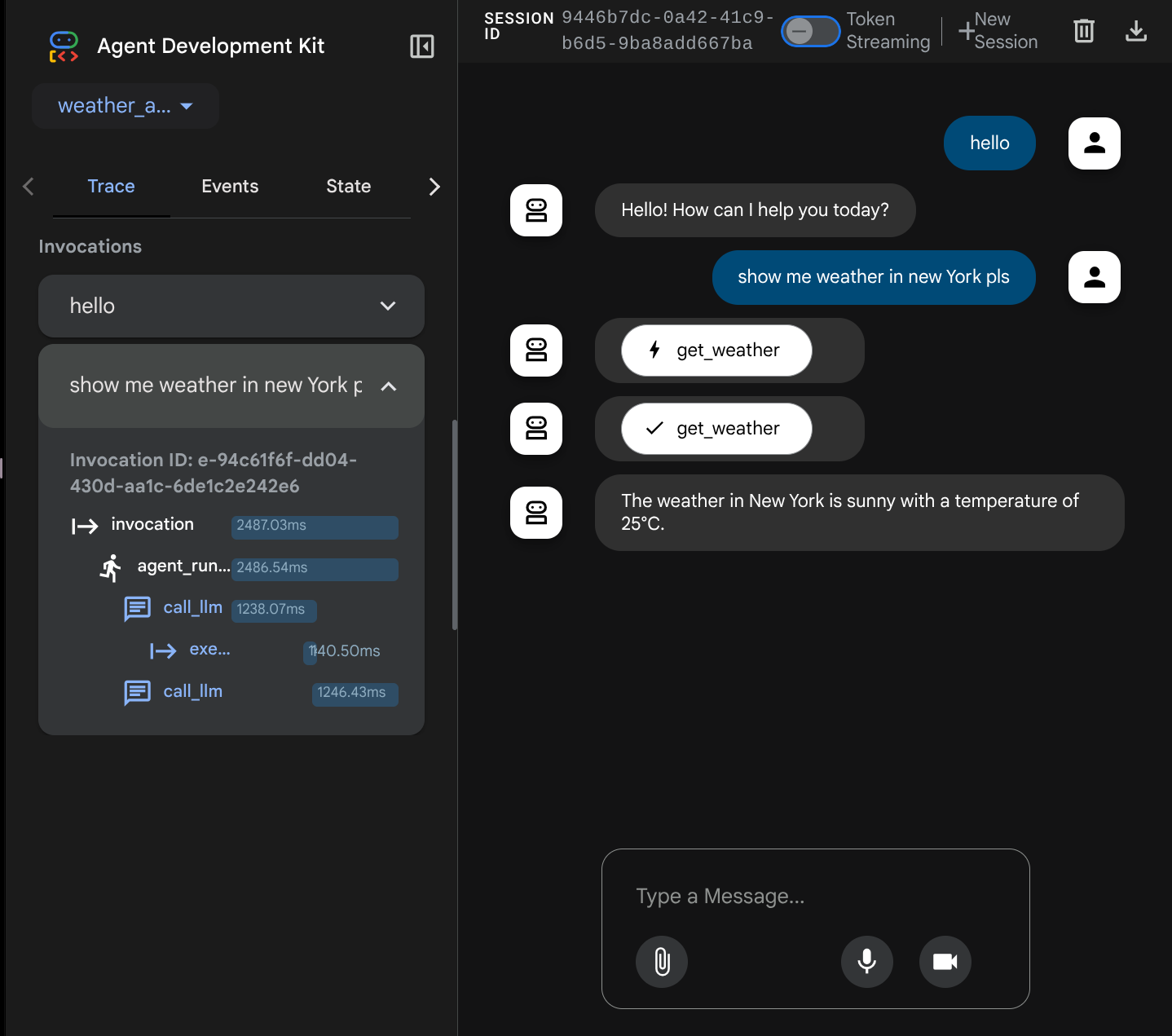
Questa è una delle funzionalità di osservabilità integrate nell'ADK, che al momento ispezioniamo localmente. Più avanti vedremo come viene integrato in Cloud Trace in modo da avere una traccia centralizzata di tutte le richieste
7. 🚀 Deployment in Cloud Run
Ora eseguiamo il deployment di questo servizio agente su Cloud Run. Ai fini di questa demo, questo servizio verrà esposto come servizio pubblico accessibile ad altri. Tuttavia, tieni presente che non si tratta di best practice, in quanto non è sicuro
Questo scenario di deployment ti consente di personalizzare il servizio di backend dell'agente. Utilizzeremo Dockerfile per eseguire il deployment dell'agente su Cloud Run. A questo punto, abbiamo già tutti i file necessari ( Dockerfile e server.py) per eseguire il deployment delle nostre applicazioni in Cloud Run. Con questi due elementi, puoi personalizzare in modo flessibile la distribuzione dell'agente ( ad es. aggiungendo route di backend personalizzate e/o un servizio sidecar aggiuntivo a scopo di monitoraggio). Approfondiremo questo argomento in dettaglio più avanti.
Ora, esegui il deployment del servizio, vai al terminale Cloud Shell e assicurati che il progetto attuale sia configurato sul progetto attivo. Esegui di nuovo lo script di configurazione. Se vuoi, puoi anche utilizzare il comando gcloud config set project [PROJECT_ID] per configurare il progetto attivo.
bash setup_trial_project.sh && source .env
Ora dobbiamo rivisitare il file .env, aprirlo e vedrai che dobbiamo rimuovere il commento della variabile DB_CONNECTION_NAME e riempirla con il valore corretto
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
Per ottenere il valore di DB_CONNECTION_NAME, visitiamo la dashboard di Cloud SQL
quindi fai clic sull'istanza che hai creato. Vai alla barra di ricerca nella sezione superiore della console Cloud e digita "Cloud SQL". Quindi, fai clic sul prodotto Cloud SQL.
Dopodiché vedrai l'istanza creata in precedenza. Fai clic su di essa.
Nella pagina dell'istanza, scorri verso il basso fino alla sezione "Connetti a questa istanza" e puoi copiare il Nome connessione per sostituire il valore DB_CONNECTION_NAME.
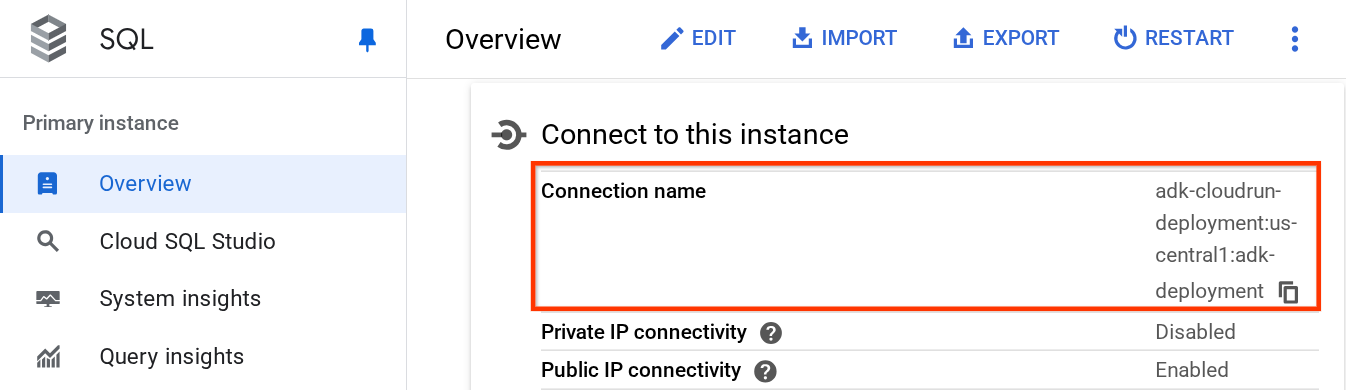
Dopodiché, apri il file .env con il seguente comando
cloudshell edit .env
e modifica la variabile DB_CONNECTION_NAME nel file .env. Il file env dovrebbe essere simile all'esempio seguente
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
Dopodiché, esegui lo script di deployment
bash deploy_to_cloudrun.sh
Se ti viene chiesto di confermare la creazione di un registro degli artefatti per il repository Docker, rispondi Y.
Mentre attendiamo il processo di deployment, diamo un'occhiata a deploy_to_cloudrun.sh
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-west1 \
--min 1 \
--memory 1G \
--concurrency 10
Questo script caricherà la variabile .env, quindi eseguirà il comando di deployment.
Se dai un'occhiata più da vicino, abbiamo bisogno di un solo comando gcloud run deploy per fare tutto il necessario per eseguire il deployment di un servizio: creare l'immagine, eseguire il push nel registro, eseguire il deployment del servizio, impostare il criterio IAM, creare la revisione e persino instradare il traffico. In questo esempio, forniamo già il Dockerfile, quindi questo comando lo utilizzerà per creare l'app
Una volta completato il deployment, dovresti ricevere un link simile a quello riportato di seguito:
https://weather-agent-*******.us-west1.run.app
Dopo aver ottenuto questo URL, puoi utilizzare l'applicazione dalla finestra Incognito o dal tuo dispositivo mobile e accedere alla UI di sviluppo dell'agente. Mentre attendiamo il deployment, esaminiamo il servizio dettagliato che abbiamo appena eseguito nella sezione successiva.
8. 💡 Dockerfile e script del server di backend
Per rendere l'agente accessibile come servizio, lo inseriremo in un'app FastAPI che verrà eseguita sul comando Dockerfile. Di seguito sono riportati i contenuti del Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
Qui possiamo configurare i servizi necessari per supportare l'agente, ad esempio preparando il servizio Session, Memory o Artifact per la produzione. Ecco il codice di server.py che verrà utilizzato
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Spiegazione del codice del server
Questi sono gli elementi definiti nello script server.py:
- Converti il nostro agente in un'app FastAPI utilizzando il metodo
get_fast_api_app. In questo modo erediteremo la stessa definizione di route utilizzata per l'interfaccia utente di sviluppo web. - Configura il servizio Session, Memory o Artifact necessario aggiungendo gli argomenti delle parole chiave al metodo
get_fast_api_app. In questo tutorial, se configuriamo la variabile di ambienteSESSION_SERVICE_URI, il servizio di sessione la utilizzerà, altrimenti utilizzerà la sessione in memoria - Possiamo aggiungere una route personalizzata per supportare un'altra logica di business di backend. Nello script aggiungiamo un esempio di route della funzionalità di feedback.
- Abilita il tracciamento cloud nei parametri arg
get_fast_api_appper inviare la traccia a Google Cloud Trace - Esegui il servizio FastAPI utilizzando uvicorn
Ora, se il deployment è già terminato, prova a interagire con l'agente dall'interfaccia utente di sviluppo web accedendo all'URL Cloud Run
9. 🚀 Ispezione della scalabilità automatica di Cloud Run con il test di carico
Ora esamineremo le funzionalità di scalabilità automatica di Cloud Run. Per questo scenario, eseguiamo il deployment di una nuova revisione abilitando il numero massimo di concorrenze per istanza. Nella sezione precedente, abbiamo impostato la concorrenza massima su 10 ( flag --concurrency 10). Pertanto, possiamo aspettarci che Cloud Run tenti di scalare la sua istanza quando eseguiamo test di carico che superano questo numero.
Esaminiamo il file load_test.py. Questo sarà lo script che utilizzeremo per eseguire il test di carico utilizzando il framework locust. Questo script eseguirà le seguenti operazioni :
- user_id e session_id randomizzati
- Crea session_id per user_id
- Chiama l'endpoint "/run_sse" con user_id e session_id creati
Se non l'hai fatto, dovrai comunicarci l'URL del servizio di cui è stato eseguito il deployment. Possiamo andare alla console Cloud Run
Quindi, trova il servizio weather-agent e fai clic.
L'URL del servizio verrà visualizzato accanto alle informazioni sulla regione. Ad es.

Per semplificare le cose, eseguiamo il seguente script per ottenere l'URL del servizio di cui è stato eseguito il deployment di recente e archiviarlo nella variabile di ambiente SERVICE_URL
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-west1 \
--format 'value(status.url)')
Quindi esegui questo comando per testare il carico della nostra app agente
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
Se lo esegui, vedrai visualizzate metriche come queste. ( In questo esempio tutte le richieste sono state completate correttamente )
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
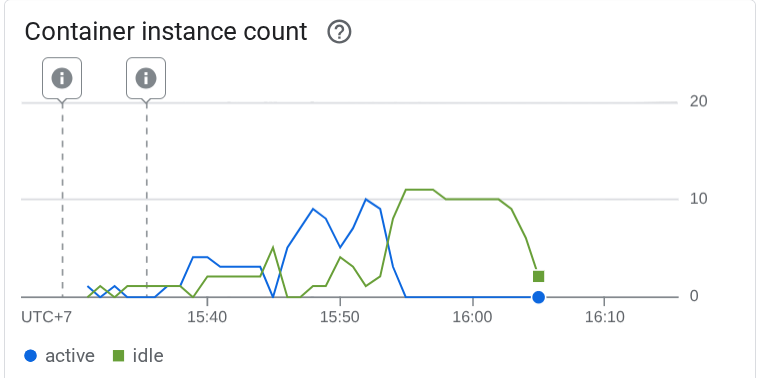
Vediamo cosa è successo in Cloud Run. Vai di nuovo al servizio di cui hai eseguito il deployment e visualizza la dashboard. In questo modo, vedrai come Cloud Run scala automaticamente l'istanza per gestire le richieste in entrata. Poiché limitiamo la concorrenza massima a 10 per istanza, l'istanza Cloud Run tenterà di regolare automaticamente il numero di container per soddisfare questa condizione.
10. 🚀 Rilascio graduale di nuove revisioni
Ora, consideriamo lo scenario seguente. Vogliamo aggiornare il prompt dell'agente. Apri weather_agent/agent.py con il seguente comando
cloudshell edit weather_agent/agent.py
e sovrascrivilo con il seguente codice:
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
Poi, vuoi rilasciare nuove revisioni, ma non vuoi che tutto il traffico delle richieste vada direttamente alla nuova versione. Possiamo eseguire il rilascio graduale con Cloud Run. Innanzitutto, dobbiamo eseguire il deployment di una nuova revisione, ma con il flag –no-traffic. Salva lo script dell'agente precedente ed esegui il comando seguente
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-west1 \
--no-traffic
Al termine, riceverai un log simile a quello della procedura di deployment precedente, con la differenza del numero di traffico servito. Verrà visualizzato lo 0% del traffico servito.
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
Dopodiché, andiamo alla dashboard di Cloud Run.
Quindi, trova il servizio weather-agent e fai clic.
Vai alla scheda Revisioni e vedrai l'elenco delle revisioni implementate.
Vedrai che le nuove revisioni implementate vengono pubblicate al 0%. Da qui puoi fare clic sul pulsante con tre puntini (⋮) e scegliere Gestisci traffico.
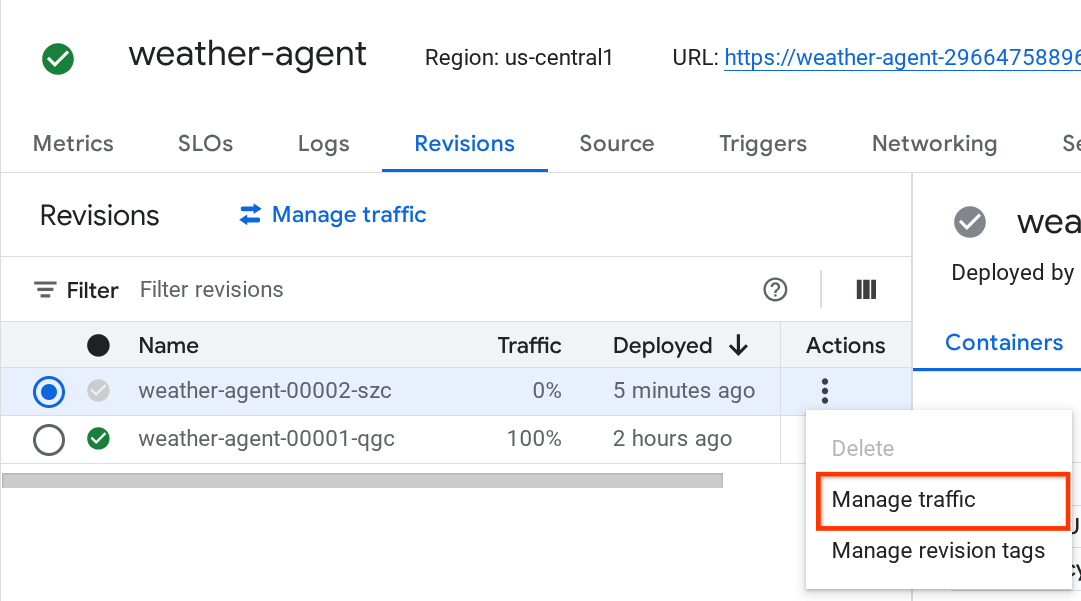
Nella nuova finestra popup, puoi modificare la percentuale di traffico indirizzato alle revisioni.
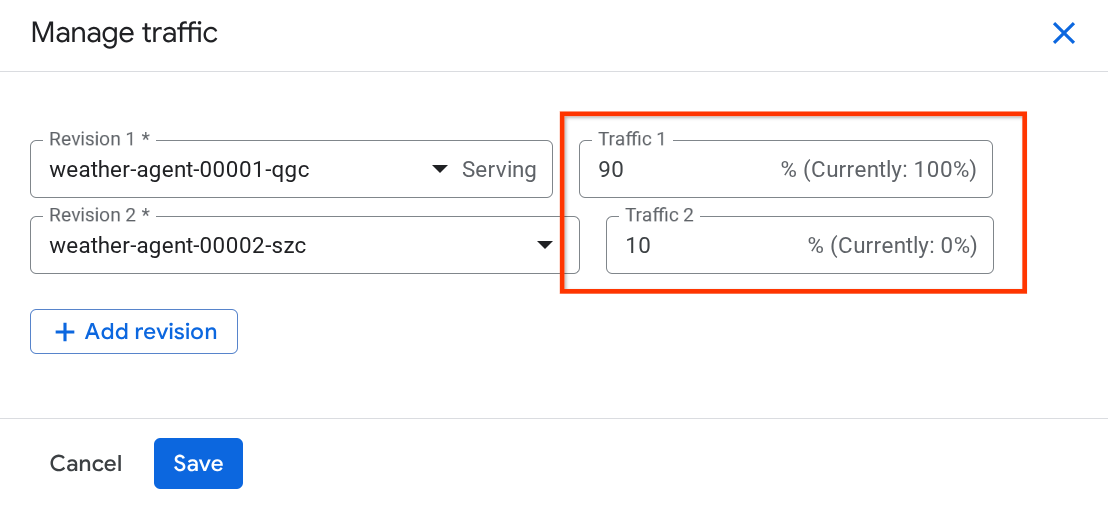
Dopo un po' di tempo, il traffico verrà indirizzato proporzionalmente in base alle configurazioni delle percentuali. In questo modo, possiamo facilmente eseguire il rollback alle revisioni precedenti se si verifica un problema con la nuova release.
11. 🚀 Tracciamento ADK
Gli agenti creati con ADK supportano già la tracciabilità utilizzando l'incorporamento di OpenTelemetry. Abbiamo Cloud Trace per acquisire le tracce e visualizzarle. Esaminiamo il file server.py per capire come abilitarlo nel servizio di cui è stato eseguito il deployment in precedenza
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
Qui passiamo l'argomento trace_to_cloud a True. Se esegui il deployment con altre opzioni, puoi consultare questa documentazione per ulteriori dettagli su come attivare la tracciatura in Cloud Trace da varie opzioni di deployment.
Prova ad accedere alla UI di sviluppo web del servizio e a chattare con l'agente. Dopodiché, andiamo alla pagina Esplora tracce.
Nella pagina di esplorazione delle tracce, vedrai che la nostra conversazione con la traccia dell'agente è stata inviata. Puoi visualizzare la sezione Nome span e filtrare lo span specifico del nostro agente ( denominato agent_run [weather_agent]).
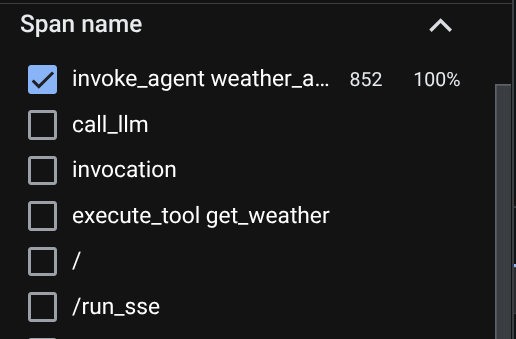
Quando gli intervalli sono già filtrati, puoi anche esaminare direttamente ogni traccia. Mostrerà la durata dettagliata di ogni azione intrapresa dall'agente. Ad esempio, guarda le immagini qui sotto
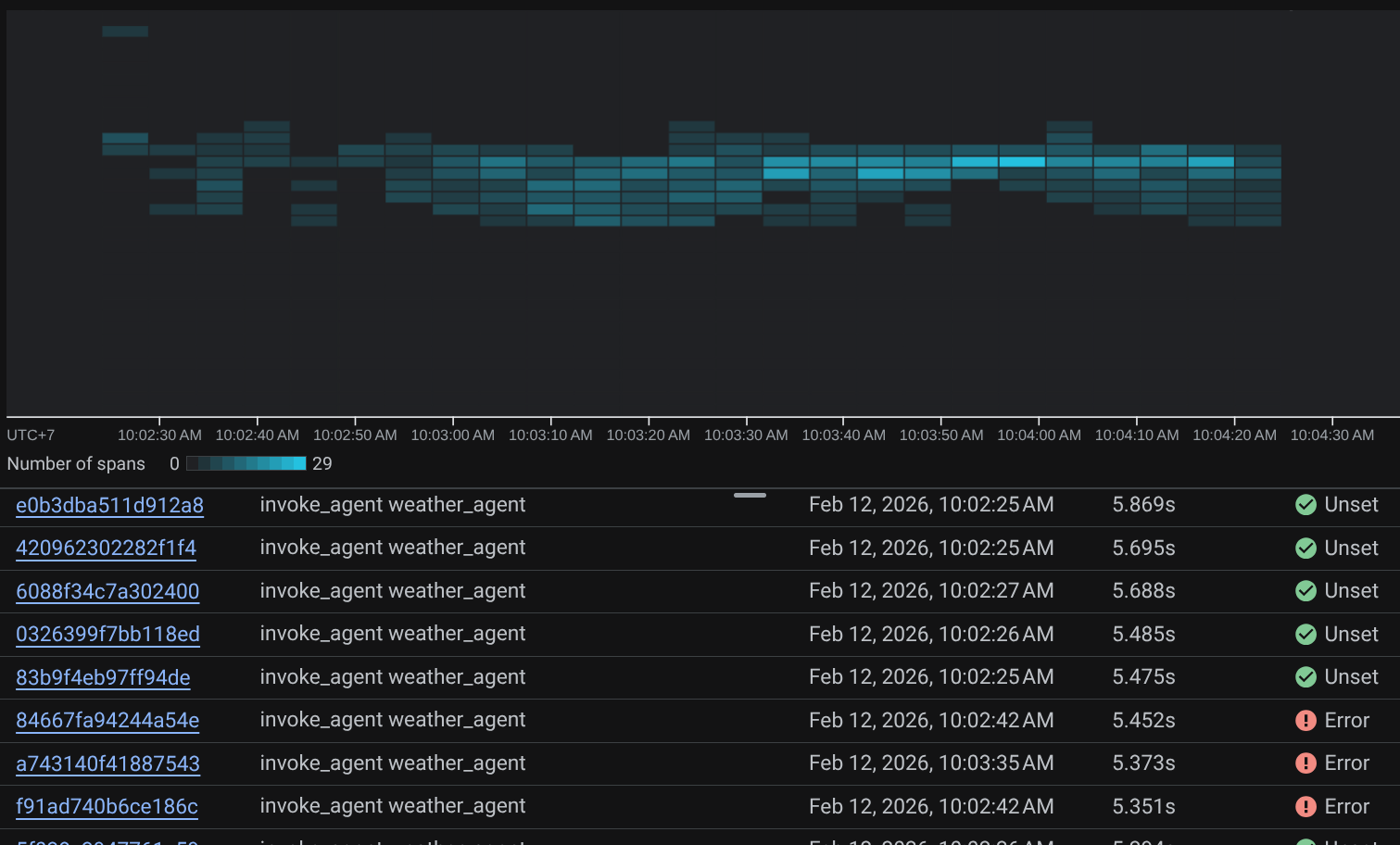
In ogni sezione, puoi esaminare i dettagli negli attributi come mostrato di seguito

Ecco fatto. Ora abbiamo una buona osservabilità e informazioni su ogni interazione del nostro agente con l'utente per facilitare il debug dei problemi. Non esitare a provare vari strumenti o flussi di lavoro.
12. 🎯 Sfida
Prova i workflow multi-agente o agentic per vedere come funzionano sotto carico e come appare la traccia
13. 🧹 Libera spazio
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo codelab, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
- In alternativa, puoi andare a Cloud Run nella console, selezionare il servizio di cui hai appena eseguito il deployment ed eliminarlo.