
1. はじめに
このチュートリアルでは、Google Cloud Run で Agent Development Kit(ADK)を使用して構築された強力なエージェントをデプロイ、管理、モニタリングする方法について説明します。ADK を使用すると、複雑なマルチエージェント ワークフローに対応できるエージェントを作成できます。フルマネージド サーバーレス プラットフォームである Cloud Run を活用することで、基盤となるインフラストラクチャを気にすることなく、エージェントをスケーラブルなコンテナ化アプリケーションとしてデプロイできます。この強力な組み合わせにより、Google Cloud の堅牢でスケーラブルな環境のメリットを享受しながら、エージェントのコアロジックに集中できます。
このチュートリアルでは、ADK と Cloud Run のシームレスな統合について説明します。エージェントのデプロイ方法を学習し、本番環境のような設定でアプリケーションを管理する際の実際的な側面について説明します。トラフィックを管理してエージェントの新しいバージョンを安全にロールアウトする方法について説明します。これにより、完全なリリース前に一部のユーザーで新機能をテストできます。
さらに、エージェントのパフォーマンスをモニタリングする実践的な経験を積むことができます。ロードテストを実施して、Cloud Run の自動スケーリング機能を実際に確認することで、実際のシナリオをシミュレートします。エージェントの動作とパフォーマンスに関する詳細な分析情報を得るために、Cloud Trace を使用してトレースを有効にします。これにより、リクエストがエージェントを通過する際の詳細なエンドツーエンドのビューが提供され、パフォーマンスのボトルネックを特定して対処できます。このチュートリアルを終了すると、Cloud Run で ADK を活用したエージェントを効果的にデプロイ、管理、モニタリングする方法を包括的に理解できます。
この Codelab では、次の手順でアプローチします。
- ADK エージェント データベース セッション サービスで使用する CloudSQL に PostgreSQL データベースを作成する
- 基本的な ADK エージェントを設定する
- ADK ランナーで使用されるデータベース セッション サービスを設定
- エージェントを Cloud Run に初回デプロイする
- 負荷テストと Cloud Run 自動スケーリングの検査
- 新しいエージェント リビジョンをデプロイし、新しいリビジョンへのトラフィックを徐々に増やす
- クラウド トレースを設定し、エージェントの実行トレースを検査する
アーキテクチャの概要
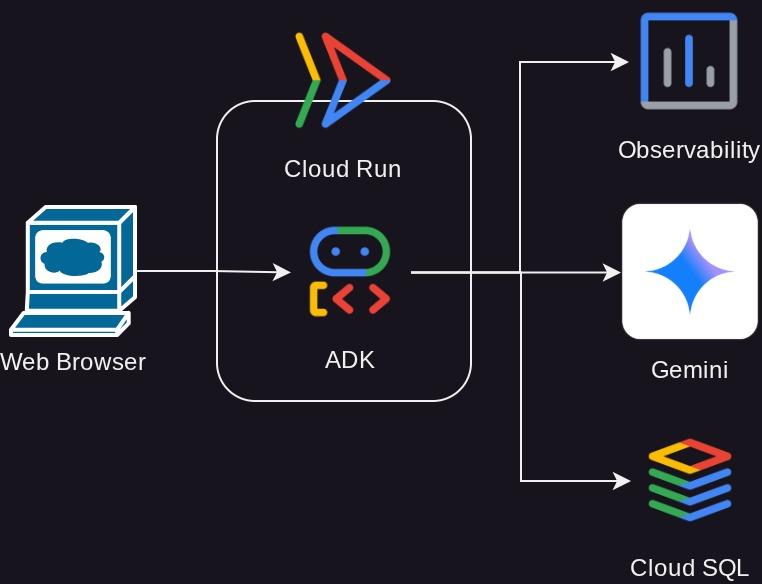
前提条件
- Python の操作に慣れている
- HTTP サービスを使用した基本的なフルスタック アーキテクチャの理解
学習内容
- ADK の構造とローカル ユーティリティ
- データベース セッション サービスを使用して ADK エージェントを設定する
- Database セッション サービスで使用される CloudSQL に PostgreSQL を設定
- Dockerfile を使用してアプリケーションを Cloud Run にデプロイし、初期環境変数を設定する
- ロードテストで Cloud Run の自動スケーリングを構成してテストする
- Cloud Run を使用した段階的リリースの戦略
- Cloud Trace への ADK エージェントのトレースを設定する
必要なもの
- Chrome ウェブブラウザ
- Gmail アカウント
- 課金が有効になっている Cloud プロジェクト
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としており、サンプル アプリケーションで Python を使用します。ただし、ここで説明するコンセプトを理解するために Python の知識は必要ありません。
2. 🚀 ワークショップのセットアップを準備しています
このチュートリアルでは Cloud Shell IDE を使用します。次のボタンをクリックして移動します。
Cloud Shell に移動したら、GitHub からこの Codelab のテンプレート作業ディレクトリのクローンを作成します。次のコマンドを実行します。作業ディレクトリは deploy_and_manage_adk ディレクトリに作成されます。
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
次に、ターミナルで次のコマンドを実行して、クローン作成したリポジトリを作業ディレクトリとして開きます。
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
その後、インターフェースは次のようになります。
これがメインのインターフェースになります。上部に IDE、下部にターミナルが表示されます。次に、以前に申し込んだトライアルの請求先アカウントにリンクされる Google Cloud プロジェクトを作成して有効にするために、ターミナルを準備する必要があります。ターミナル セッションを常に準備できるように、スクリプトを用意しました。次のコマンドを実行します(deploy_and_manage_adk ワークスペース内にいることを確認してください)。
bash setup_trial_project.sh && source .env
このコマンドを実行すると、プロジェクト ID 名の候補が表示されます。Enter を押して続行できます。

しばらく待ってから、コンソールに次の出力が表示されたら、次のステップ 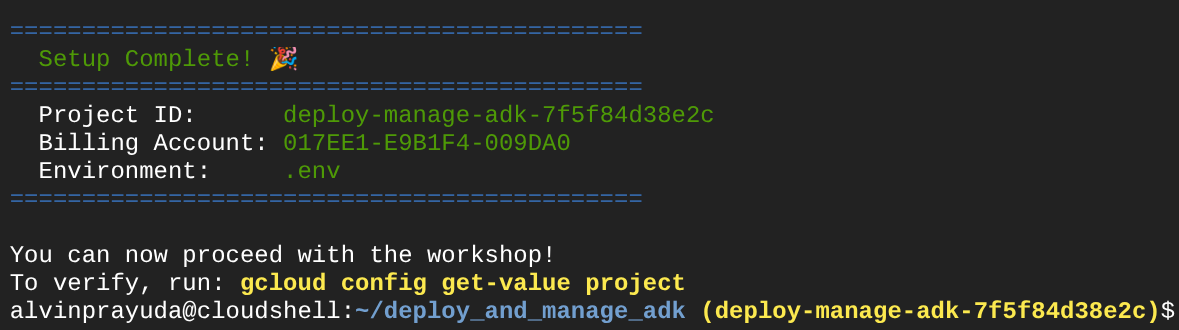 に進みます。
に進みます。
これは、ターミナルがすでに認証され、正しいプロジェクト ID に設定されていることを示しています(現在のディレクトリ パスの横の黄色)。このコマンドは、新しいプロジェクトの作成、プロジェクトの検索とトライアルの請求先アカウントへのリンク、環境変数構成用の .env ファイルの準備、ターミナルでの正しいプロジェクト ID の有効化を支援します。
これで、次のステップに進む準備ができました。
3. 🚀 API を有効にする
このチュートリアルでは、CloudSQL データベース、Gemini モデル、Cloud Run を操作します。これらのプロダクトでは、次の API を有効にする必要があります。次のコマンドを実行して、これらの API を有効にします。
この処理にはしばらく時間がかかることがあります。
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
コマンドが正常に実行されると、次のようなメッセージが表示されます。
Operation "operations/..." finished successfully.
4. 🚀 Python 環境のセットアップと環境変数
この Codelab では Python 3.12 を使用し、uv Python プロジェクト マネージャーを使用して、Python のバージョンと仮想環境の作成と管理の必要性を簡素化します。この uv パッケージは、Cloud Shell にすでにプリインストールされています。
次のコマンドを実行して、.venv ディレクトリの仮想環境に必要な依存関係をインストールします。
uv sync --frozen
次に、このプロジェクトに必要な環境変数ファイルを検査します。以前は、このファイルは setup_trial_project.sh スクリプトによって設定されていました。次のコマンドを実行して、エディタで .env ファイルを開きます。
cloudshell open .env
.env ファイルには、次の構成がすでに適用されています。
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
この Codelab では、GOOGLE_CLOUD_LOCATION と GOOGLE_GENAI_USE_VERTEXAI. の事前構成済みの値を使用します。
次のステップでは、エージェントが状態とセッションの永続性に使用するデータベースを作成します。
5. 🚀 CloudSQL データベースの準備
ADK エージェントが後で使用するデータベースが必要です。Cloud SQL に PostgreSQL データベースを作成しましょう。次のコマンドを実行して、最初にデータベース インスタンスを作成します。デフォルトの postgres データベース名を使用するため、ここではデータベースの作成をスキップします。チュートリアルでは、デフォルトのデータベース ユーザー名(postgres)も構成する必要があります。パスワードには ADK-deployment123 を使用します。
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-west1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
上記のコマンドでは、最初の共通の gcloud sql instances create adk-deployment は、データベース インスタンスの作成に使用するコマンドです。このチュートリアルでは、サンドボックスの最小仕様を使用します。2 番目のコマンド gcloud sql users set-password postgres は、デフォルトの postgres ユーザー名のパスワードを変更するために使用されます。
データベース インスタンス名として adk-deployment を使用します。完了すると、次のような出力がターミナルに表示されます。これは、インスタンスの準備が完了し、デフォルトのユーザー パスワードが更新されたことを示しています。
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-west1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
このデータベースのデプロイには時間がかかるため、CloudSQL データベースのデプロイが完了するまで、次のセクションに進みましょう。
6. 🚀 ADK と Gemini 2.5 を使用して天気エージェントを構築する
ADK のディレクトリ構造の概要
まず、ADK の機能とエージェントの構築方法について説明します。ADK の完全なドキュメントは、こちらの URL でご覧いただけます。ADK は、CLI コマンド実行内で多くのユーティリティを提供します。以下に例を示します。
- エージェント ディレクトリ構造を設定する
- CLI の入出力でインタラクションをすばやく試す
- ローカル開発 UI ウェブ インターフェースをすばやく設定する
次に、weather_agent ディレクトリでエージェントの構造を確認します。
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
init.py と agent.py を調べると、次のコードが表示されます。
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
ADK コードの説明
このスクリプトには、次のものを初期化するエージェントの初期化が含まれています。
- 使用するモデルを
gemini-2.5-flashに設定する - 天気エージェントとしてエージェント機能をサポートするツール
get_weatherを提供
ウェブ UI をローカルで実行する
これで、エージェントとやり取りして、その動作をローカルで検査できるようになりました。ADK を使用すると、開発ウェブ UI を使用して、やり取り中に何が起こっているかを調べることができます。次のコマンドを実行して、ローカル開発 UI サーバーを起動します。
uv run adk web --port 8080
次の例のような出力が生成されます。これは、ウェブ インターフェースにすでにアクセスできることを意味します。
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
確認するには、Cloud Shell エディタの上部にある [ウェブでプレビュー] ボタンをクリックし、[ポート 8080 でプレビュー] を選択します。
次のウェブページが表示されます。左上のプルダウン ボタンで利用可能なエージェント(この場合は weather_agent)を選択し、ボットとやり取りできます。左側のウィンドウには、エージェントの実行時のログの詳細に関する多くの情報が表示されます。
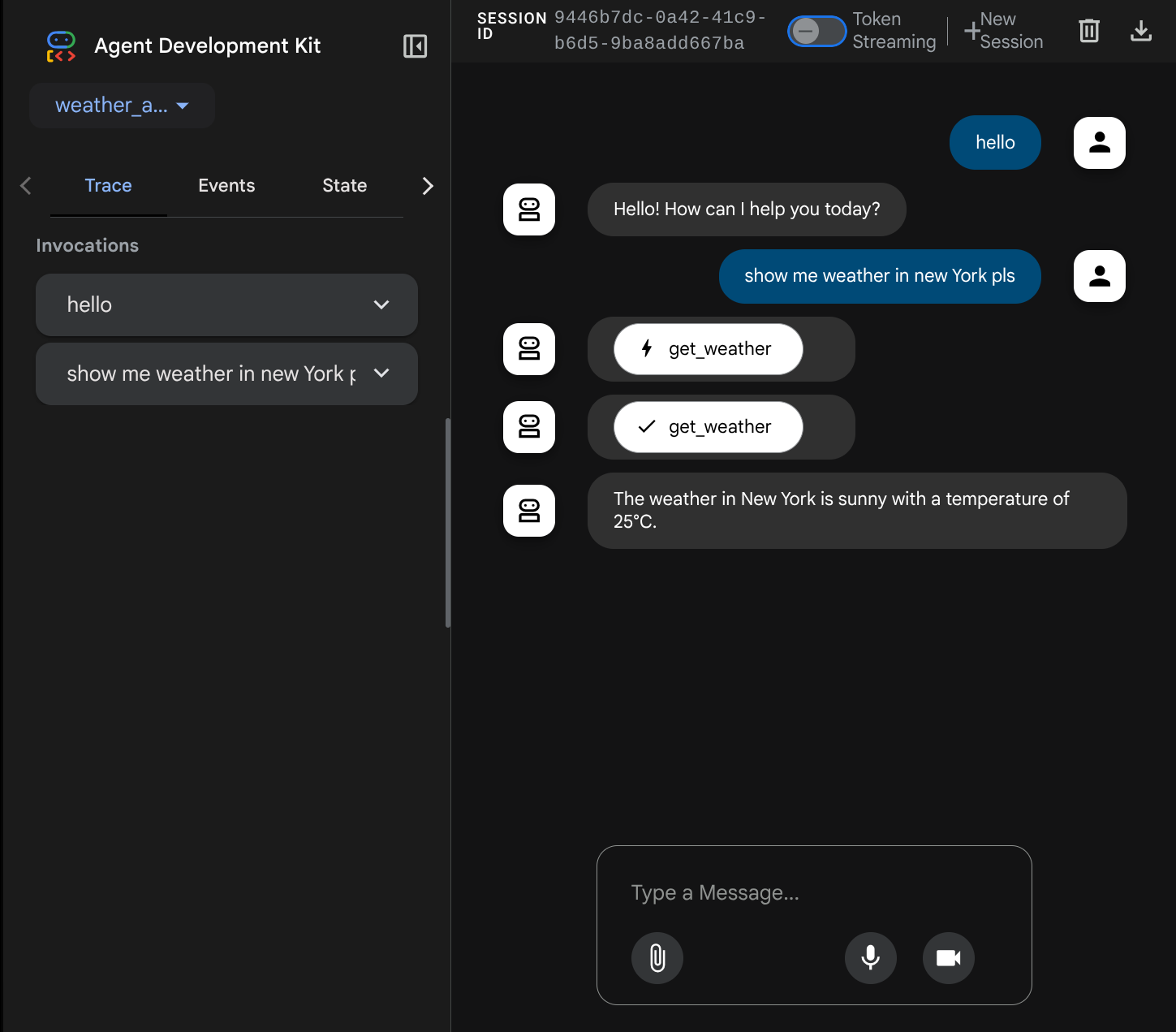
では、操作してみましょう。左側のバーでは、各入力のトレースを検査できます。これにより、エージェントが最終的な回答を生成するまでに各アクションにかかった時間を把握できます。
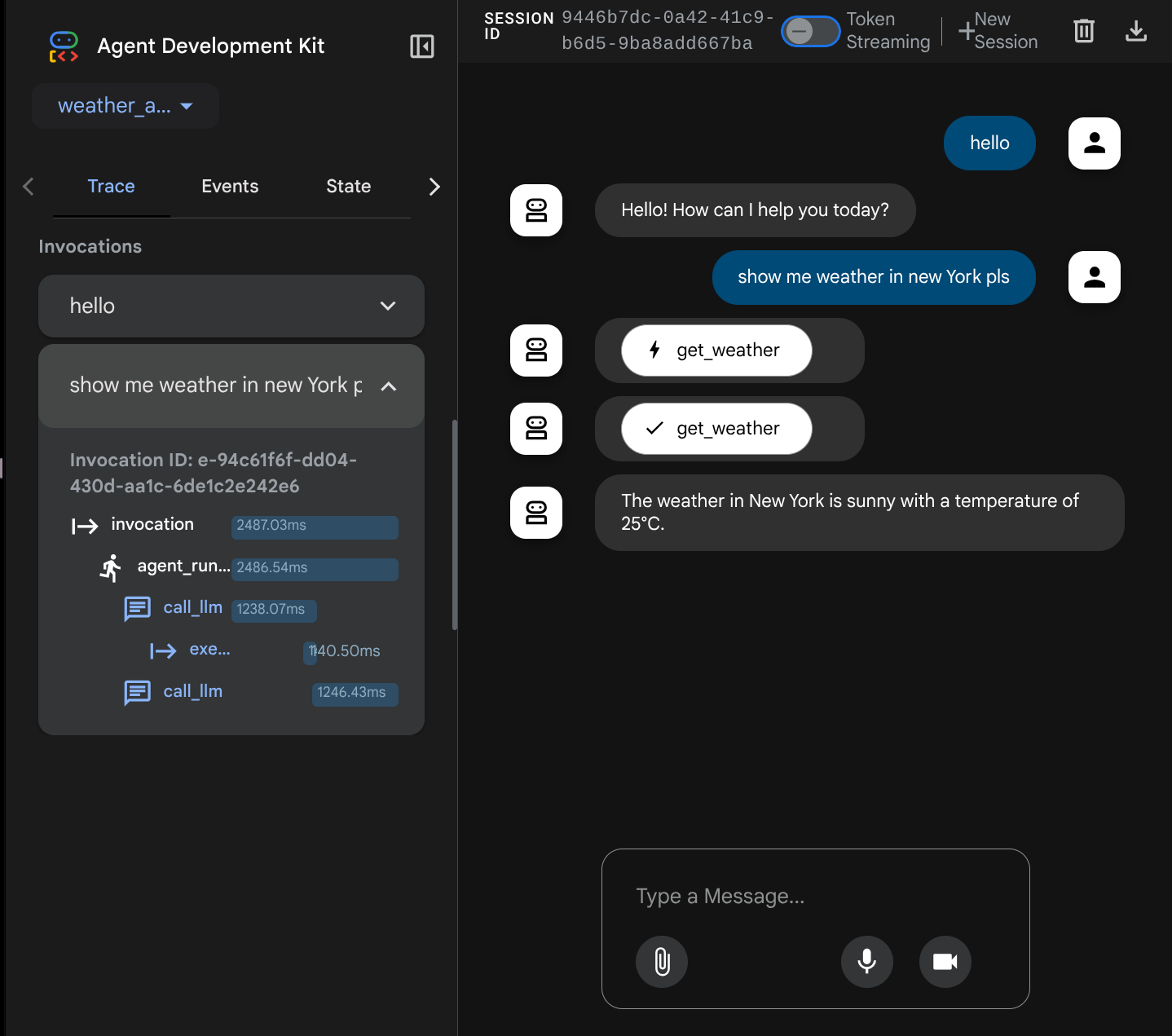
これは ADK に組み込まれているオブザーバビリティ機能の 1 つで、現在はローカルで検査しています。後で、これが Cloud Tracing に統合され、すべてのリクエストのトレースが一元化される方法について説明します。
7. 🚀 Cloud Run へのデプロイ
次に、このエージェント サービスを Cloud Run にデプロイします。このデモでは、このサービスは他のユーザーがアクセスできる公開サービスとして公開されます。ただし、安全ではないため、ベスト プラクティスではありません。
このデプロイ シナリオでは、エージェント バックエンド サービスをカスタマイズできます。Dockerfile を使用して、エージェントを Cloud Run にデプロイします。この時点で、アプリケーションを Cloud Run にデプロイするために必要なファイル(Dockerfile と server.py)はすべて用意されています。この 2 つの項目を使用すると、エージェントのデプロイを柔軟にカスタマイズできます(カスタム バックエンド ルートの追加や、モニタリング目的の追加のサイドカー サービスの追加など)。これについては後で詳しく説明します。
次に、まずサービスをデプロイします。Cloud Shell ターミナルに移動し、現在のプロジェクトがアクティブなプロジェクトに構成されていることを確認します。セットアップ スクリプトを再度実行します。必要に応じて、コマンド gcloud config set project [PROJECT_ID] を使用してアクティブなプロジェクトを構成することもできます。
bash setup_trial_project.sh && source .env
次に、.env ファイルを再度開きます。DB_CONNECTION_NAME 変数のコメントを解除して、正しい値を入力する必要があります。
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
DB_CONNECTION_NAME の値を取得するには、Cloud SQL ダッシュボードにアクセスします。
作成したインスタンスをクリックします。Cloud コンソールの上部にある検索バーに移動し、「cloud sql」と入力します。[Cloud SQL] プロダクトをクリックします。
以前に作成したインスタンスが表示されるので、それをクリックします。
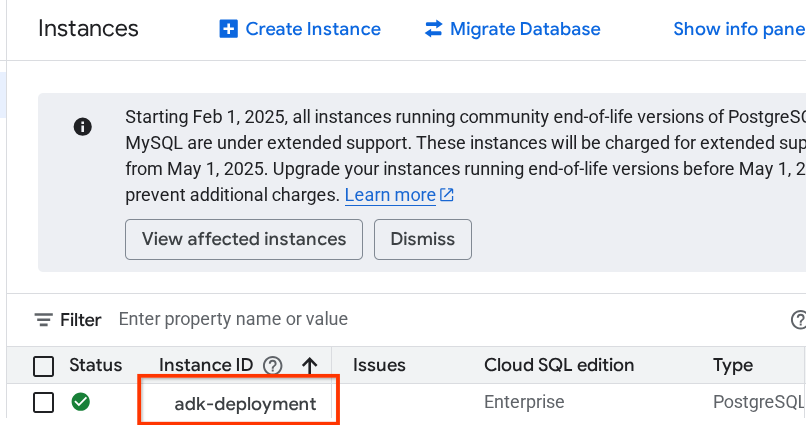
インスタンス ページで、[このインスタンスに接続] セクションまでスクロールすると、接続名をコピーして DB_CONNECTION_NAME の値を置き換えることができます。
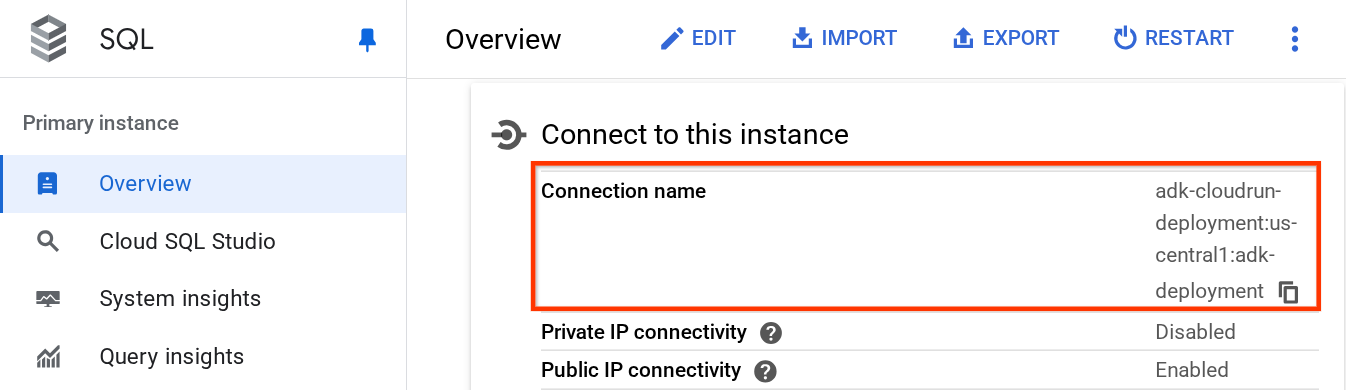
その後、次のコマンドを使用して .env ファイルを開きます。
cloudshell edit .env
.env ファイルの DB_CONNECTION_NAME 変数を変更します。env ファイルは次の例のようになります。
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
その後、デプロイ スクリプトを実行します。
bash deploy_to_cloudrun.sh
Docker リポジトリのアーティファクト レジストリの作成を確認するよう求められたら、「Y」と答えます。
デプロイ プロセスを待っている間に、deploy_to_cloudrun.sh を見てみましょう。
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-west1 \
--min 1 \
--memory 1G \
--concurrency 10
このスクリプトは、.env 変数を読み込んでから、デプロイ コマンドを実行します。
よく見ると、サービスをデプロイする場合に必要なすべての処理(イメージのビルド、レジストリへの push、サービスのデプロイ、IAM ポリシーの設定、リビジョンの作成、トラフィックのルーティングなど)は、1 つの gcloud run deploy コマンドで実行できます。この例では、Dockerfile がすでに提供されているため、このコマンドはそれを使用してアプリをビルドします。
デプロイが完了すると、次のようなリンクが表示されます。
https://weather-agent-*******.us-west1.run.app
この URL を取得したら、シークレット ウィンドウまたはモバイル デバイスからアプリケーションを使用して、エージェントの Dev UI にアクセスできます。デプロイの完了を待つ間に、次のセクションでデプロイしたばかりの詳細なサービスを確認しましょう。
8. 💡 Dockerfile とバックエンド サーバー スクリプト
エージェントをサービスとしてアクセスできるようにするため、エージェントを FastAPI アプリ内にラップし、Dockerfile コマンドで実行します。以下は Dockerfile の内容です。
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
ここでは、エージェントをサポートするために必要なサービスを構成できます。たとえば、本番環境用に Session、Memory、Artifact サービスを準備します。使用する server.py のコードは次のとおりです。
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
サーバーコードの説明
server.py スクリプトで定義されている内容は次のとおりです。
get_fast_api_appメソッドを使用して、エージェントを FastAPI アプリに変換します。これにより、ウェブ開発 UI で使用されるのと同じルート定義が継承されます。get_fast_api_appメソッドにキーワード引数を追加して、必要なセッション サービス、メモリ サービス、アーティファクト サービスを構成します。このチュートリアルでは、SESSION_SERVICE_URI環境変数を構成すると、セッション サービスはそれを使用します。それ以外の場合は、インメモリ セッションを使用します。- カスタムルートを追加して、他のバックエンド ビジネス ロジックをサポートできます。スクリプトでは、フィードバック機能のルートの例を追加します。
get_fast_api_app引数パラメータでクラウド トレースを有効にして、トレースを Google Cloud Trace に送信します。- uvicorn を使用して FastAPI サービスを実行する
デプロイがすでに完了している場合は、Cloud Run URL にアクセスして、ウェブ開発 UI からエージェントを操作してみてください。
9. 🚀 ロードテストによる Cloud Run 自動スケーリングの検査
次に、Cloud Run の自動スケーリング機能を確認します。このシナリオでは、インスタンスあたりの最大同時実行数を有効にして、新しいリビジョンをデプロイします。前のセクションでは、最大同時実行数を 10(フラグ --concurrency 10)に設定しました。したがって、この数を超える負荷テストを行うと、Cloud Run がインスタンスのスケーリングを試行することが予想されます。
load_test.py ファイルを調べてみましょう。これは、locust フレームワークを使用して負荷テストを行うために使用するスクリプトです。このスクリプトは、次の処理を行います。
- ランダム化された user_id と session_id
- user_id の session_id を作成する
- 作成したユーザー ID とセッション ID を使用してエンドポイント「/run_sse」にアクセスします。
デプロイされたサービスの URL が必要になります。Cloud Run コンソールに移動できます。
次に、weather-agent サービスを見つけてクリックします。
サービス URL は、リージョン情報のすぐ横に表示されます。例:

簡略化するために、次のスクリプトを実行して、最近デプロイされたサービス URL を取得し、SERVICE_URL 環境変数に保存します。
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-west1 \
--format 'value(status.url)')
次のコマンドを実行して、エージェント アプリのロードテストを行います。
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
実行すると、次のような指標が表示されます。(この例では、すべてのリクエストが成功しています)。
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
次に、Cloud Run で何が起こったかを確認します。デプロイしたサービスに再度アクセスして、ダッシュボードを確認します。これにより、Cloud Run が受信リクエストを処理するためにインスタンスを自動的にスケーリングする方法を確認できます。インスタンスあたりの最大同時実行数を 10 に制限しているため、Cloud Run インスタンスは、この条件を満たすようにコンテナの数を自動的に調整しようとします。
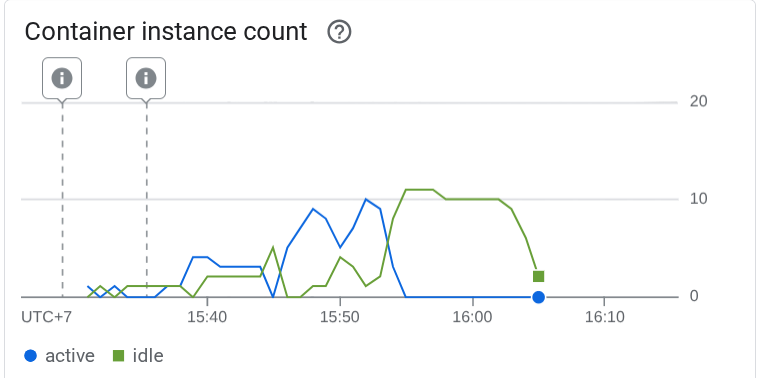
10. 🚀 新しいリビジョンの段階的なリリース
次のシナリオを考えてみましょう。エージェントのプロンプトを更新したい。次のコマンドを使用して weather_agent/agent.py を開きます。
cloudshell edit weather_agent/agent.py
次のコードで上書きします。
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
次に、新しいリビジョンをリリースするが、すべてのリクエスト トラフィックが新しいバージョンに直接送信されないようにします。Cloud Run を使用して段階的なリリースを行うことができます。まず、–no-traffic フラグを使用して新しいリビジョンをデプロイする必要があります。以前のエージェント スクリプトを保存して、次のコマンドを実行します。
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-west1 \
--no-traffic
完了すると、以前のデプロイ プロセスと同様のログが届きます。ただし、処理されたトラフィックの数が異なります。配信されたトラフィックが 0% と表示されます。
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
次に、Cloud Run ダッシュボードに移動します。
次に、weather-agent サービスを見つけてクリックします。
[リビジョン] タブに移動すると、デプロイされたリビジョンのリストが表示されます。
新しくデプロイされたリビジョンが 0% で提供されていることがわかります。ここから、その他メニュー(⋮)をクリックして [トラフィックの管理] を選択します。
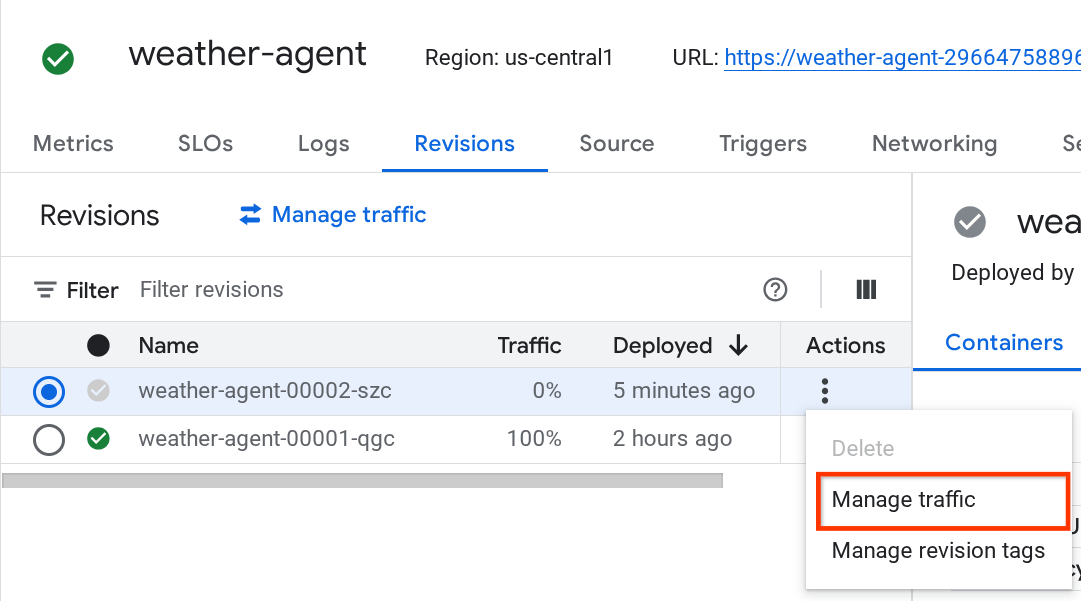
新しく表示されたウィンドウで、各リビジョンに転送されるトラフィックの割合を編集できます。
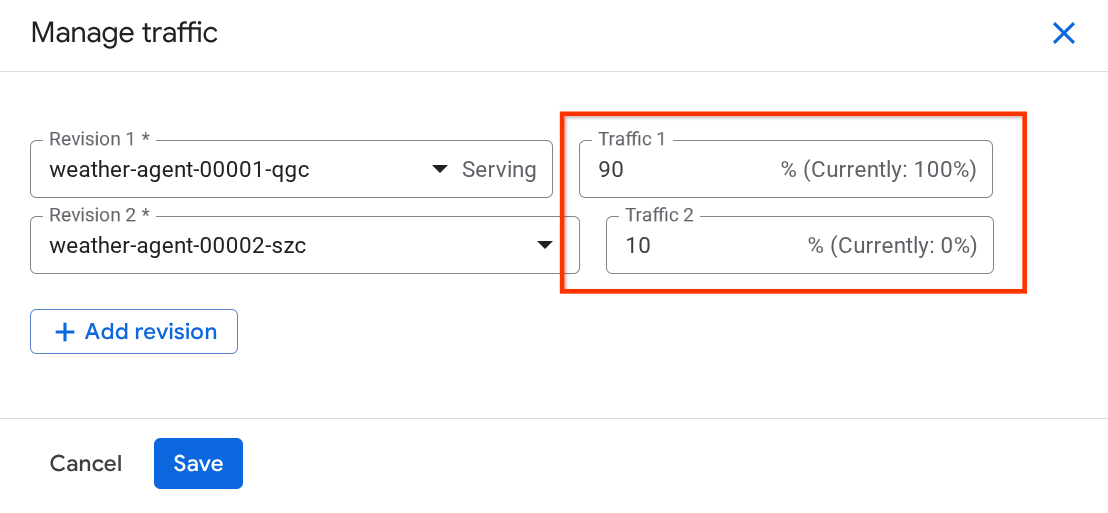
しばらく待つと、トラフィックは割合の構成に基づいて比例的に転送されます。これにより、新しいリリースで問題が発生した場合に、以前のリビジョンに簡単にロールバックできます。
11. 🚀 ADK トレース
ADK で構築されたエージェントは、OpenTelemetry を埋め込むことでトレースをサポートしています。Cloud Trace を使用して、トレースをキャプチャして可視化します。以前にデプロイしたサービスで有効にする方法について、server.py を確認してみましょう。
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
ここでは、trace_to_cloud 引数を True に渡します。他のオプションを使用してデプロイする場合は、このドキュメントで、さまざまなデプロイ オプションから Cloud Trace へのトレースを有効にする方法の詳細を確認してください。
サービス ウェブ開発 UI にアクセスして、エージェントとチャットしてみてください。その後、[Trace エクスプローラ] ページに移動します。
トレース エクスプローラ ページに、エージェントとの会話のトレースが送信されたことが表示されます。[スパン名] セクションで、エージェントに固有のスパン(agent_run [weather_agent] という名前)を確認してフィルタできます。
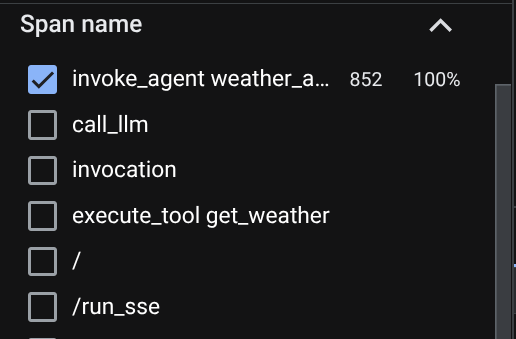
スパンがすでにフィルタされている場合は、各トレースを直接検査することもできます。エージェントが実行した各アクションの詳細な所要時間が表示されます。たとえば、以下の画像をご覧ください。
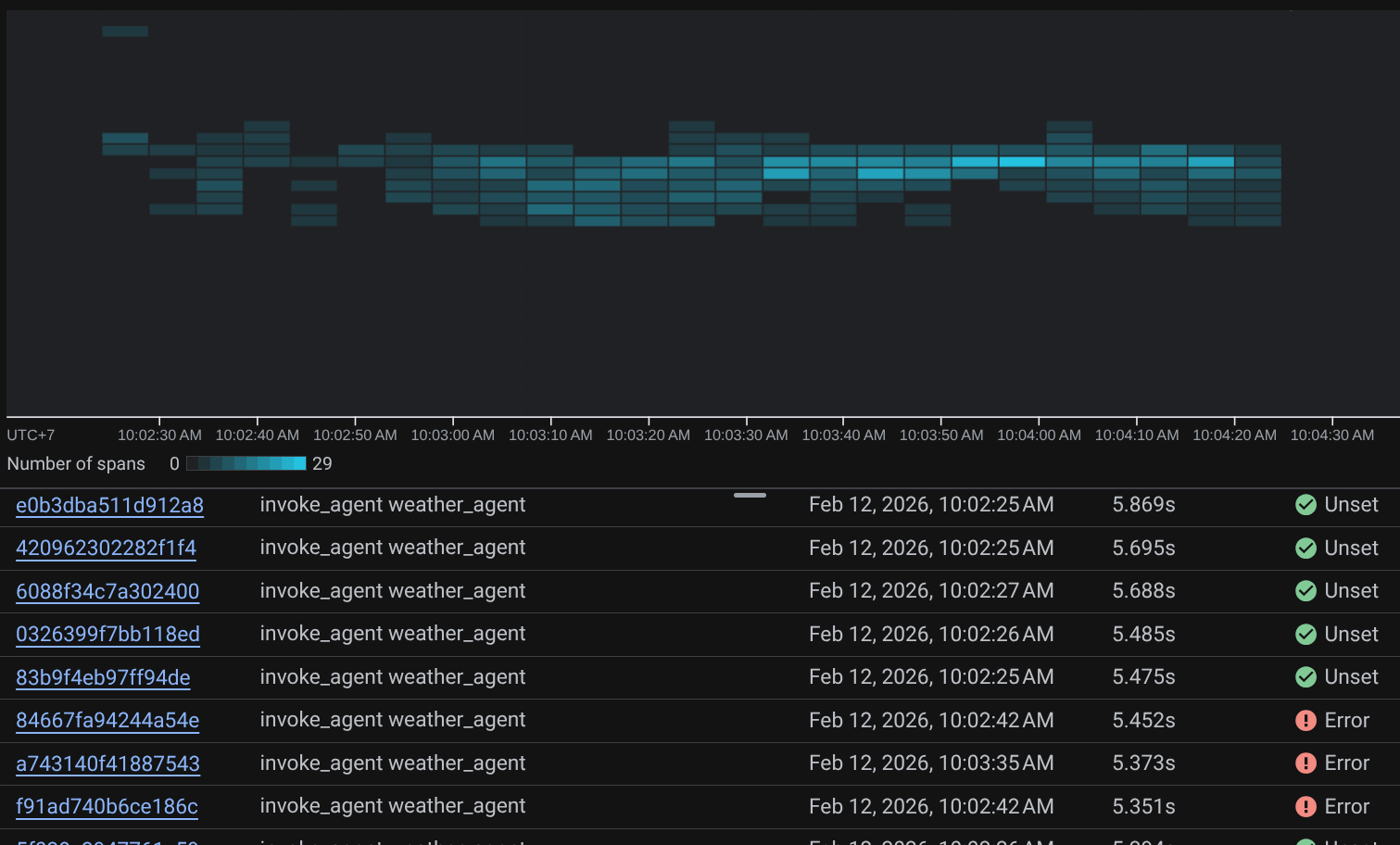
各セクションで、以下のように属性の詳細を確認できます。
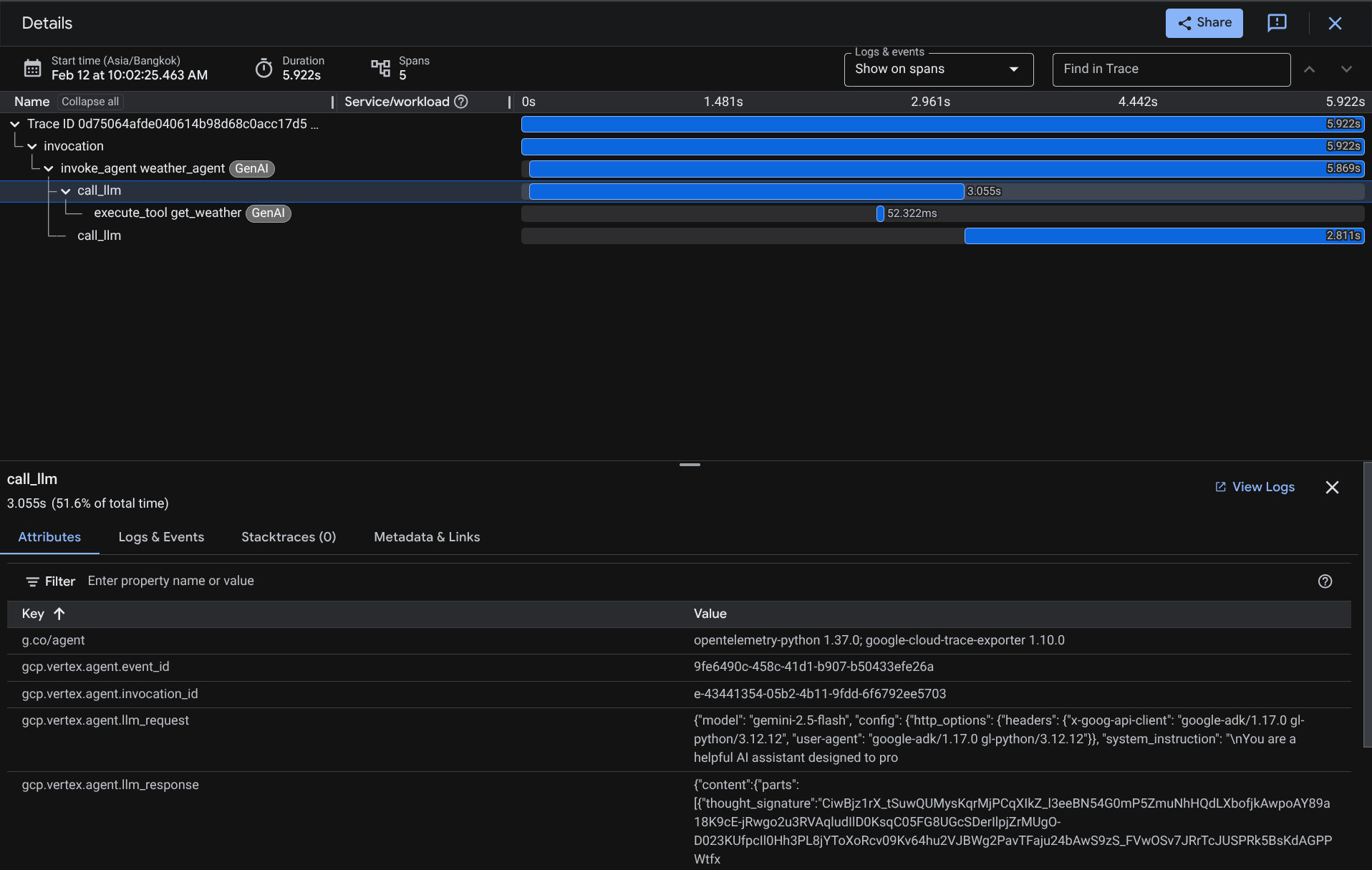
これで、エージェントとユーザーのやり取りに関するオブザーバビリティと情報が充実し、問題のデバッグに役立つようになりました。さまざまなツールやワークフローを試してみてください。
12. 🎯 課題
マルチエージェント ワークフローまたはエージェント ワークフローを試して、負荷がかかった場合のパフォーマンスとトレースを確認する
13. 🧹 クリーンアップ
この Codelab で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。