
1. Wprowadzenie
Ten samouczek zawiera instrukcje wdrażania zaawansowanego agenta utworzonego za pomocą pakietu Agent Development Kit (ADK) w Google Cloud Run, zarządzania nim i jego monitorowania. ADK umożliwia tworzenie agentów zdolnych do wykonywania złożonych przepływów pracy z udziałem wielu agentów. Korzystając z Cloud Run, w pełni zarządzanej platformy bezserwerowej, możesz wdrożyć agenta jako skalowalną aplikację skonteneryzowaną bez konieczności przejmowania się infrastrukturą bazową. To połączenie pozwala skupić się na podstawowej logice agenta, a jednocześnie korzystać z solidnego i skalowalnego środowiska Google Cloud.
W tym samouczku omówimy płynną integrację pakietu ADK z Cloud Run. Dowiesz się, jak wdrożyć agenta, a potem poznasz praktyczne aspekty zarządzania aplikacją w środowisku produkcyjnym. Omówimy, jak bezpiecznie wdrażać nowe wersje agenta, zarządzając ruchem i umożliwiając testowanie nowych funkcji na podzbiorze użytkowników przed pełnym udostępnieniem.
Dodatkowo zdobędziesz praktyczne doświadczenie w monitorowaniu skuteczności agenta. Przeprowadzimy test obciążenia, aby zasymulować rzeczywisty scenariusz i zaobserwować działanie funkcji automatycznego skalowania Cloud Run. Aby uzyskać bardziej szczegółowe informacje o zachowaniu i skuteczności agenta, włączymy śledzenie za pomocą Cloud Trace. Dzięki temu uzyskasz szczegółowy, kompleksowy wgląd w żądania przesyłane przez agenta, co pozwoli Ci identyfikować i usuwać wszelkie wąskie gardła. Po ukończeniu tego samouczka będziesz mieć pełną wiedzę o tym, jak skutecznie wdrażać agentów opartych na ADK w Cloud Run, zarządzać nimi i je monitorować.
W ramach ćwiczeń z programowania będziesz wykonywać kolejne czynności:
- Tworzenie bazy danych PostgreSQL w Cloud SQL na potrzeby usługi sesji bazy danych agenta pakietu ADK
- Konfigurowanie podstawowego agenta ADK
- Konfigurowanie usługi sesji bazy danych do używania przez narzędzie ADK Runner
- Początkowe wdrożenie agenta w Cloud Run
- Testowanie obciążenia i sprawdzanie autoskalowania Cloud Run
- Wdrażanie nowej wersji agenta i stopniowe zwiększanie ruchu kierowanego do nowych wersji
- Konfigurowanie śledzenia w chmurze i sprawdzanie śledzenia działania agenta
Omówienie architektury
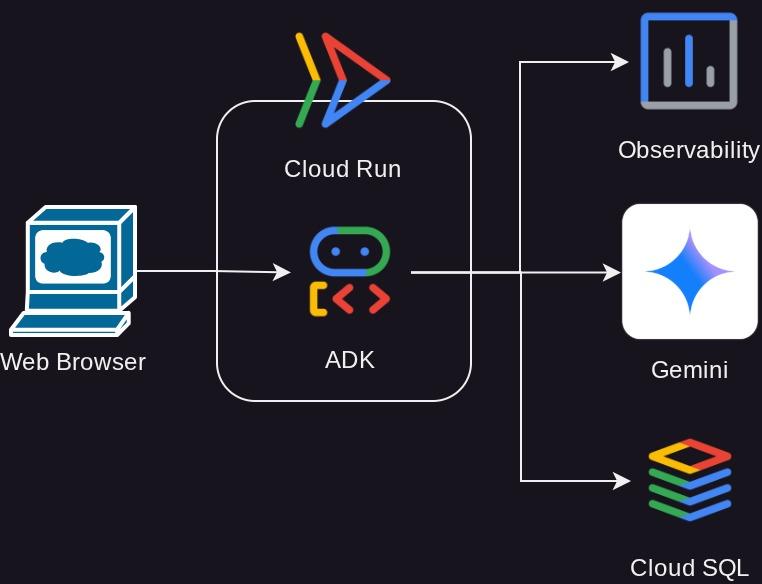
Wymagania wstępne
- znajomość języka Python;
- Znajomość podstawowej architektury pełnego stosu z użyciem usługi HTTP
Czego się nauczysz
- Struktura pakietu ADK i narzędzia lokalne
- Konfigurowanie agenta ADK za pomocą usługi sesji bazy danych
- Konfigurowanie PostgreSQL w Cloud SQL na potrzeby usługi sesji bazy danych
- Wdrażanie aplikacji w Cloud Run przy użyciu pliku Dockerfile i konfigurowanie początkowych zmiennych środowiskowych
- Konfigurowanie i testowanie autoskalowania Cloud Run za pomocą testów obciążeniowych
- Strategia stopniowego wdrażania w Cloud Run
- Konfigurowanie śledzenia agenta ADK w Cloud Trace
Czego potrzebujesz
- przeglądarki Chrome,
- konto Gmail,
- Projekt Cloud z włączonymi płatnościami
To ćwiczenie jest przeznaczone dla programistów na wszystkich poziomach zaawansowania (w tym dla początkujących). W przykładowej aplikacji używa się języka Python. Znajomość Pythona nie jest jednak wymagana do zrozumienia przedstawionych koncepcji.
2. 🚀 Przygotowywanie konfiguracji warsztatów
W tym samouczku będziemy korzystać ze środowiska IDE Cloud Shell. Aby przejść do tego środowiska, kliknij ten przycisk:
Po otwarciu Cloud Shell sklonuj z GitHuba katalog roboczy szablonu tego ćwiczenia. W tym celu uruchom to polecenie: W katalogu deploy_and_manage_adk zostanie utworzony katalog roboczy.
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
Następnie uruchom w terminalu to polecenie, aby otworzyć sklonowane repozytorium jako katalog roboczy:
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
Interfejs powinien wyglądać podobnie do tego:
Będzie to nasz główny interfejs: IDE u góry, terminal u dołu. Teraz musimy przygotować terminal do utworzenia i aktywowania projektu Google Cloud, który zostanie połączony z wcześniej zarejestrowanym próbnym kontem rozliczeniowym. Przygotowaliśmy skrypt, który zapewni, że sesja terminala będzie zawsze gotowa. Uruchom to polecenie ( upewnij się, że jesteś już w przestrzeni roboczej deploy_and_manage_adk):
bash setup_trial_project.sh && source .env
Podczas uruchamiania tego polecenia pojawi się sugestia nazwy identyfikatora projektu. Aby kontynuować, możesz nacisnąć Enter.

Jeśli po pewnym czasie w konsoli zobaczysz te dane wyjściowe, możesz przejść do następnego kroku. 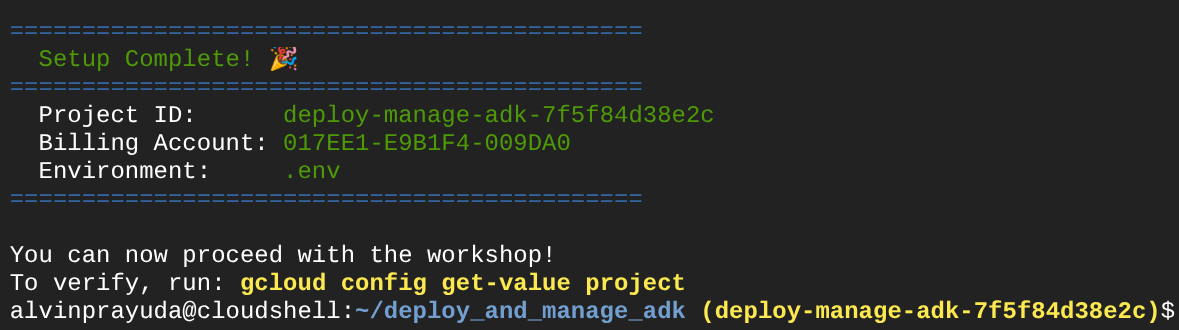
Oznacza to, że terminal jest już uwierzytelniony i ustawiony na prawidłowy identyfikator projektu ( żółty kolor obok ścieżki do bieżącego katalogu). To polecenie pomaga utworzyć nowy projekt, znaleźć i połączyć go z testowym kontem rozliczeniowym, przygotować plik .env do konfiguracji zmiennej środowiskowej, a także aktywować w terminalu prawidłowy identyfikator projektu.
Możemy teraz przejść do następnego kroku.
3. 🚀 Włączanie interfejsów API
W tym samouczku będziemy korzystać z bazy danych Cloud SQL, modelu Gemini i Cloud Run. Te usługi wymagają aktywowania tych interfejsów API. Aby je włączyć, uruchom te polecenia:
To może chwilę potrwać.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
4. 🚀 Konfigurowanie środowiska Pythona i zmiennych środowiskowych
W tym ćwiczeniu użyjemy Pythona 3.12 i menedżera projektów Pythona uv, aby uprościć tworzenie wersji Pythona i środowiska wirtualnego oraz zarządzanie nimi. Pakiet uv jest już wstępnie zainstalowany w Cloud Shell.
Uruchom to polecenie, aby zainstalować wymagane zależności w środowisku wirtualnym w katalogu .venv.
uv sync --frozen
Następnie sprawdzimy wymagane pliki zmiennych środowiskowych dla tego projektu. Wcześniej ten plik był konfigurowany przez skrypt setup_trial_project.sh. Uruchom to polecenie, aby otworzyć plik .env w edytorze:
cloudshell open .env
W pliku .env zobaczysz te konfiguracje:
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
W tym samouczku użyjemy wstępnie skonfigurowanych wartości GOOGLE_CLOUD_LOCATION i GOOGLE_GENAI_USE_VERTEXAI..
Teraz możemy przejść do następnego kroku, czyli utworzenia bazy danych, która będzie używana przez agenta do przechowywania stanu i sesji.
5. 🚀 Przygotowywanie bazy danych Cloud SQL
Później agent ADK będzie korzystać z bazy danych. Utwórzmy bazę danych PostgreSQL w Cloud SQL. Najpierw uruchom to polecenie, aby utworzyć instancję bazy danych. Użyjemy domyślnej nazwy bazy danych postgres, więc pominiemy tutaj tworzenie bazy danych. Musimy też skonfigurować domyślną nazwę użytkownika bazy danych (również postgres). Na potrzeby tego samouczka użyjemy hasła ADK-deployment123.
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-west1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
W powyższym poleceniu pierwsze wspólne gcloud sql instances create adk-deployment to polecenie, którego używamy do tworzenia instancji bazy danych. Na potrzeby tego samouczka używamy minimalnej specyfikacji piaskownicy. Drugie polecenie gcloud sql users set-password postgres służy do zmiany domyślnego hasła użytkownika postgres.
Pamiętaj, że jako nazwy instancji bazy danych używamy adk-deployment. Po zakończeniu w terminalu powinny pojawić się dane wyjściowe podobne do tych poniżej, które wskazują, że instancja jest gotowa, a hasło domyślnego użytkownika zostało zaktualizowane.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-west1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
Wdrożenie tej bazy danych zajmie trochę czasu, więc przejdźmy do następnej sekcji, czekając na zakończenie wdrażania bazy danych Cloud SQL.
6. 🚀 Tworzenie agenta pogodowego za pomocą pakietu ADK i modelu Gemini 2.5
Wprowadzenie do struktury katalogów ADK
Zacznijmy od omówienia możliwości ADK i sposobu tworzenia agenta. Pełną dokumentację pakietu ADK znajdziesz pod tym adresem URL . ADK oferuje wiele narzędzi w ramach wykonywania poleceń interfejsu CLI. Oto niektóre z nich :
- Konfigurowanie struktury katalogu agenta
- Szybkie wypróbowanie interakcji za pomocą danych wejściowych i wyjściowych interfejsu wiersza poleceń
- Szybkie konfigurowanie lokalnego interfejsu internetowego
Sprawdźmy teraz strukturę agenta w katalogu weather_agent.
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
Jeśli sprawdzisz pliki init.py i agent.py, zobaczysz ten kod:
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
ADK Wyjaśnienie kodu
Ten skrypt zawiera inicjację agenta, w której inicjujemy te elementy:
- Ustaw model, który ma być używany, na
gemini-2.5-flash - Udostępnij narzędzie
get_weather, aby obsługiwać funkcje agenta, takie jak agent pogodowy.
Lokalne uruchamianie interfejsu internetowego
Teraz możemy wchodzić w interakcje z agentem i sprawdzać jego działanie lokalnie. ADK umożliwia nam korzystanie z interfejsu internetowego do programowania, który pozwala wchodzić w interakcje i sprawdzać, co się dzieje podczas interakcji. Aby uruchomić lokalny serwer interfejsu programistycznego, wykonaj to polecenie:
uv run adk web --port 8080
Wygeneruje to dane wyjściowe podobne do poniższego przykładu, co oznacza, że możemy już uzyskać dostęp do interfejsu internetowego.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Aby to sprawdzić, kliknij przycisk Podgląd w przeglądarce w górnej części edytora Cloud Shell i wybierz Podejrzyj na porcie 8080.
Wyświetli się strona internetowa, na której w lewym górnym rogu możesz wybrać dostępnych agentów ( w naszym przypadku powinien to być weather_agent) i interagować z botem. W oknie po lewej stronie zobaczysz wiele informacji o szczegółach logu podczas działania agenta.
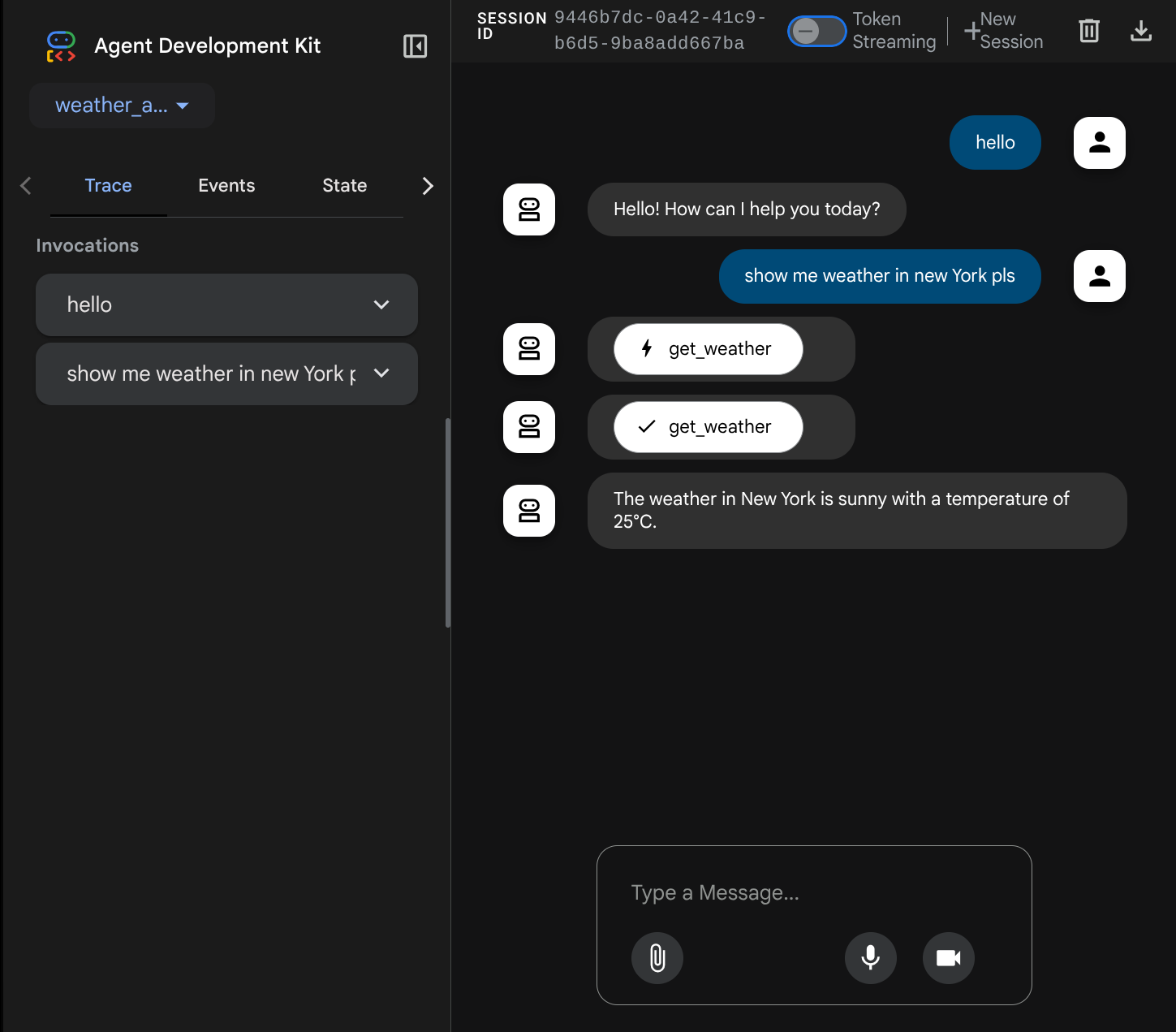
Teraz spróbuj z nim wejść w interakcję. Na pasku po lewej stronie możemy sprawdzić ślad każdego wejścia, aby dowiedzieć się, ile czasu zajmuje każda czynność wykonywana przez agenta przed sformułowaniem ostatecznej odpowiedzi.
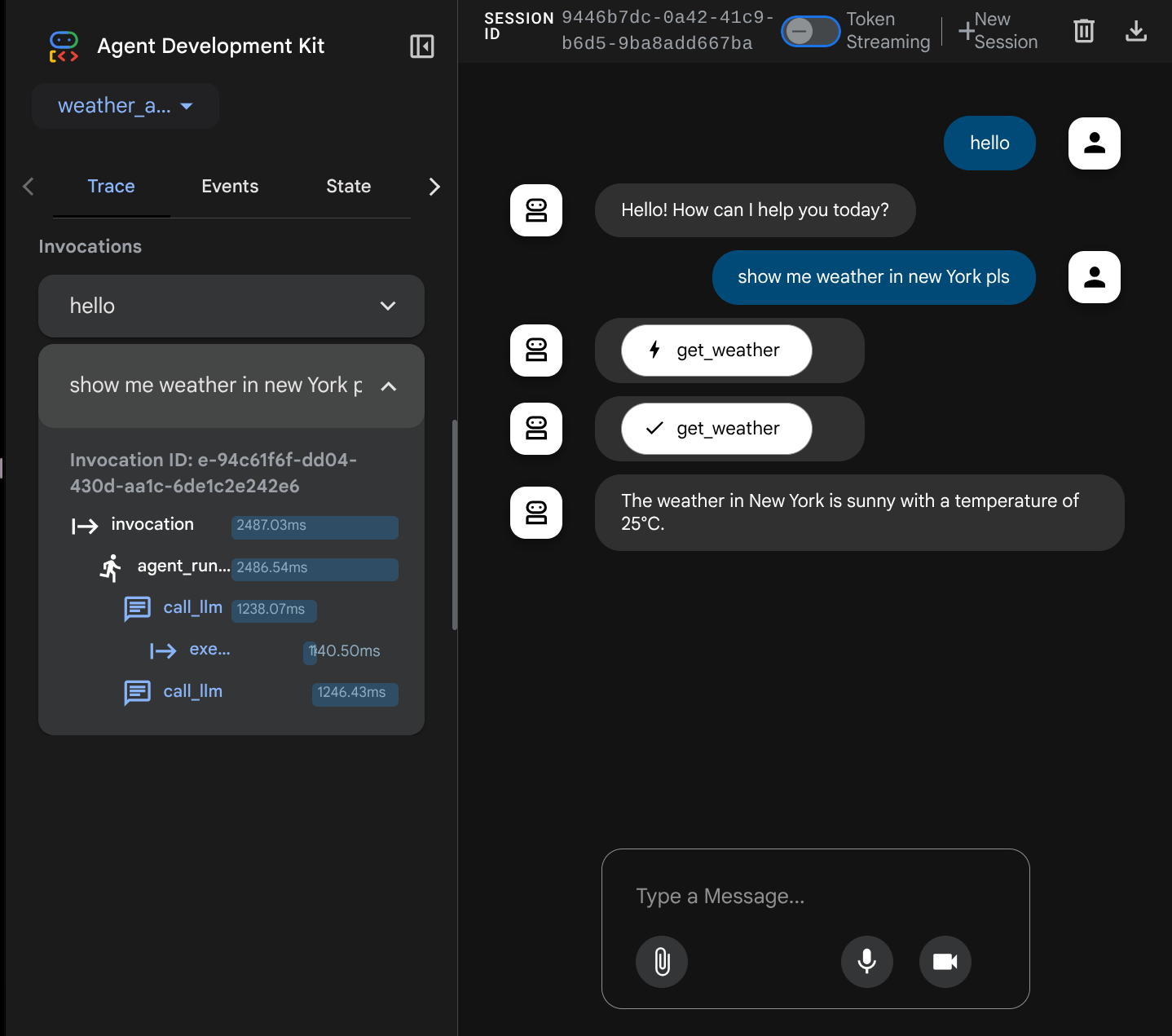
Jest to jedna z funkcji dostrzegalności wbudowanych w pakiet ADK. Obecnie sprawdzamy ją lokalnie. Później zobaczymy, jak jest to zintegrowane z Cloud Tracing, abyśmy mieli scentralizowane śledzenie wszystkich żądań.
7. 🚀 Wdrażanie w Cloud Run
Teraz wdróżmy tę usługę agenta w Cloud Run. Na potrzeby tej wersji demonstracyjnej usługa będzie udostępniana jako usługa publiczna, do której inne osoby będą miały dostęp. Pamiętaj jednak, że nie jest to sprawdzona metoda, ponieważ nie zapewnia bezpieczeństwa.
Ten scenariusz wdrażania umożliwia dostosowanie usługi backendu agenta. Do wdrożenia agenta w Cloud Run użyjemy pliku Dockerfile. Na tym etapie mamy już wszystkie potrzebne pliki ( Dockerfile i server.py), aby wdrożyć aplikacje w Cloud Run. Dzięki tym 2 elementom możesz elastycznie dostosowywać wdrożenie agenta ( np. dodawać niestandardowe trasy backendu lub dodatkową usługę pomocniczą na potrzeby monitorowania). Szczegółowo omówimy to w dalszej części artykułu.
Teraz najpierw wdróżmy usługę. Przejdź do terminala Cloud Shell i upewnij się, że bieżący projekt jest skonfigurowany jako aktywny. Uruchom ponownie skrypt konfiguracji. Opcjonalnie możesz też użyć polecenia gcloud config set project [PROJECT_ID], aby skonfigurować aktywny projekt.
bash setup_trial_project.sh && source .env
Teraz musimy ponownie otworzyć plik .env i usunąć komentarz przy zmiennej DB_CONNECTION_NAME oraz wypełnić ją prawidłową wartością.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
Aby uzyskać wartość DB_CONNECTION_NAME, otwórz panel Cloud SQL.
następnie kliknij utworzoną instancję. Przejdź do paska wyszukiwania w górnej części konsoli Cloud i wpisz „cloud sql”. Następnie kliknij usługę Cloud SQL.
Następnie zobaczysz utworzoną wcześniej instancję. Kliknij ją.
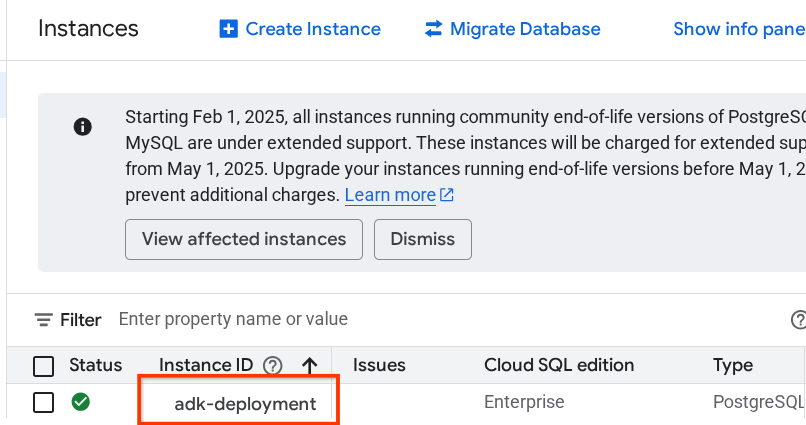
Na stronie instancji przewiń w dół do sekcji „Połącz się z tą instancją” i skopiuj nazwę połączenia, aby zastąpić wartość DB_CONNECTION_NAME.
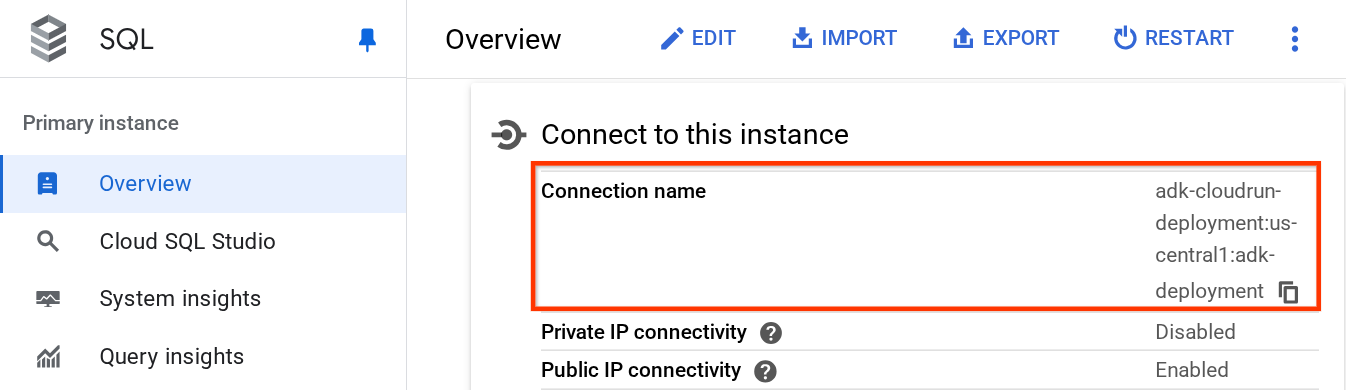
Następnie otwórz plik .env za pomocą tego polecenia:
cloudshell edit .env
i zmodyfikuj zmienną DB_CONNECTION_NAME w pliku .env. Plik env powinien wyglądać podobnie do przykładu poniżej.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
Następnie uruchom skrypt wdrażania.
bash deploy_to_cloudrun.sh
Jeśli pojawi się prośba o potwierdzenie utworzenia repozytorium Artifact Registry dla Dockera, wpisz Y.
Podczas oczekiwania na zakończenie procesu wdrażania przyjrzyjmy się skryptowi deploy_to_cloudrun.sh.
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-west1 \
--min 1 \
--memory 1G \
--concurrency 10
Ten skrypt wczyta zmienną .env, a potem uruchomi polecenie wdrożenia.
Jeśli przyjrzysz się bliżej, zobaczysz, że do wykonania wszystkich czynności niezbędnych do wdrożenia usługi wystarczy jedno polecenie gcloud run deploy: utworzenie obrazu, przesłanie go do rejestru, wdrożenie usługi, ustawienie zasad IAM, utworzenie wersji, a nawet kierowanie ruchem. W tym przykładzie udostępniamy już plik Dockerfile, więc to polecenie zostanie użyte do utworzenia aplikacji.
Po zakończeniu wdrażania powinien pojawić się link podobny do tego:
https://weather-agent-*******.us-west1.run.app
Po uzyskaniu tego adresu URL możesz używać aplikacji w oknie incognito lub na urządzeniu mobilnym i uzyskać dostęp do interfejsu programisty agenta. Podczas oczekiwania na wdrożenie przyjrzyjmy się szczegółowej usłudze, którą właśnie wdrażamy, w następnej sekcji.
8. 💡 Plik Dockerfile i skrypt serwera backendu
Aby udostępnić agenta jako usługę, umieścimy go w aplikacji FastAPI, która będzie uruchamiana za pomocą polecenia Dockerfile. Poniżej znajduje się zawartość pliku Dockerfile
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
Możemy tu skonfigurować niezbędne usługi, aby obsługiwać agenta, np. przygotować usługi Session, Memory lub Artifact do celów produkcyjnych. Oto kod pliku server.py, który będzie używany:
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Wyjaśnienie kodu serwera
Oto elementy zdefiniowane w skrypcie server.py:
- Przekształć agenta w aplikację FastAPI za pomocą metody
get_fast_api_app. W ten sposób odziedziczymy tę samą definicję trasy, która jest używana w interfejsie programowania aplikacji internetowych. - Skonfiguruj niezbędną usługę sesji, pamięci lub artefaktów, dodając argumenty słów kluczowych do metody
get_fast_api_app. Jeśli w tym samouczku skonfigurujemy zmienną środowiskowąSESSION_SERVICE_URI, usługa sesji będzie jej używać. W przeciwnym razie będzie używać sesji w pamięci. - Możemy dodać niestandardową ścieżkę, aby obsługiwać inną logikę biznesową backendu. W skrypcie dodajemy przykładową ścieżkę funkcji opinii.
- Włącz śledzenie w chmurze w parametrach argumentu
get_fast_api_app, aby wysyłać logi do Cloud Trace. - Uruchamianie usługi FastAPI za pomocą uvicorn
Jeśli wdrożenie zostało już zakończone, spróbuj wejść w interakcję z agentem w interfejsie internetowym dla deweloperów, otwierając adres URL Cloud Run.
9. 🚀 Sprawdzanie autoskalowania Cloud Run za pomocą testów obciążenia
Teraz sprawdzimy możliwości autoskalowania Cloud Run. W tym scenariuszu wdróżmy nową wersję, włączając maksymalną liczbę równoczesnych żądań na instancję. W poprzedniej sekcji ustawiliśmy maksymalną współbieżność na 10 ( flaga --concurrency 10). Możemy więc oczekiwać, że Cloud Run spróbuje skalować instancję, gdy przeprowadzimy test obciążenia, który przekroczy tę liczbę.
Przyjrzyjmy się plikowi load_test.py. Będzie to skrypt, którego użyjemy do przeprowadzenia testu obciążeniowego za pomocą platformy locust. Ten skrypt wykona te działania :
- Losowe wartości user_id i session_id
- Utwórz identyfikator sesji dla identyfikatora użytkownika.
- Wyślij żądanie do punktu końcowego „/run_sse” z utworzonymi identyfikatorami user_id i session_id.
Będziemy musieli poznać adres URL wdrożonej usługi, jeśli go nie podasz. Możemy przejść do konsoli Cloud Run
Następnie znajdź usługę weather-agent i kliknij ją.
Adres URL usługi będzie wyświetlany obok informacji o regionie. Np.

Aby ułatwić Ci pracę, uruchom ten skrypt, aby uzyskać adres URL ostatnio wdrożonej usługi i zapisać go w zmiennej środowiskowej SERVICE_URL.
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-west1 \
--format 'value(status.url)')
Następnie uruchom to polecenie, aby przetestować aplikację agenta pod kątem obciążenia:
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
Po uruchomieniu tego polecenia zobaczysz wyświetlone dane, takie jak te poniżej. ( W tym przykładzie wszystkie żądania zakończyły się powodzeniem)
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
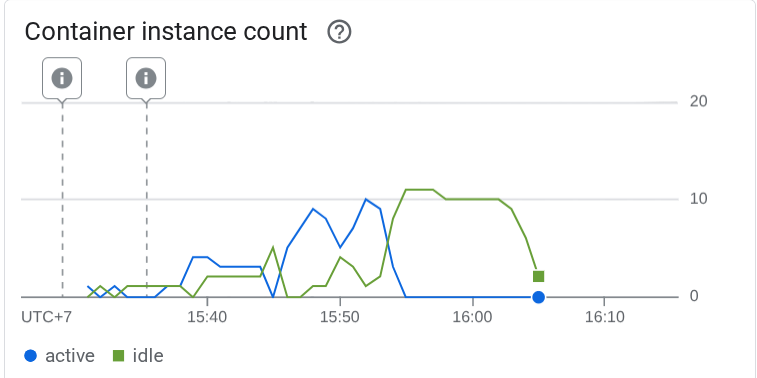
Sprawdźmy teraz, co się stało w Cloud Run. Wróć do wdrożonej usługi i wyświetl panel. Pokaże to, jak Cloud Run automatycznie skaluje instancję w celu obsługi żądań przychodzących. Ograniczamy maksymalną współbieżność do 10 na instancję, więc instancja Cloud Run automatycznie dostosuje liczbę kontenerów, aby spełnić ten warunek.
10. 🚀 Stopniowe udostępnianie nowych wersji
Rozważmy teraz ten scenariusz. Chcemy zaktualizować prompt agenta. Otwórz plik weather_agent/agent.py za pomocą tego polecenia:
cloudshell edit weather_agent/agent.py
i zastąp go tym kodem:
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
Następnie chcesz wdrożyć nowe wersje, ale nie chcesz, aby cały ruch z żądań był kierowany bezpośrednio do nowej wersji. W Cloud Run możemy przeprowadzić stopniowe wdrażanie. Najpierw musimy wdrożyć nową wersję, ale z flagą –no-traffic. Zapisz poprzedni skrypt agenta i uruchom to polecenie:
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-west1 \
--no-traffic
Po zakończeniu otrzymasz podobny dziennik jak w przypadku poprzedniego procesu wdrażania, z tą różnicą, że będzie zawierał liczbę obsłużonych żądań. Wyświetli się informacja o 0% obsłużonego ruchu.
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
Następnie przejdźmy do panelu Cloud Run.
Następnie znajdź usługę weather-agent i kliknij ją.
Otwórz kartę Wersje, na której zobaczysz listę wdrożonych wersji.
Nowa wdrożona wersja będzie obsługiwać 0% ruchu. Kliknij przycisk z 3 kropkami (⋮) i wybierz Zarządzaj ruchem.
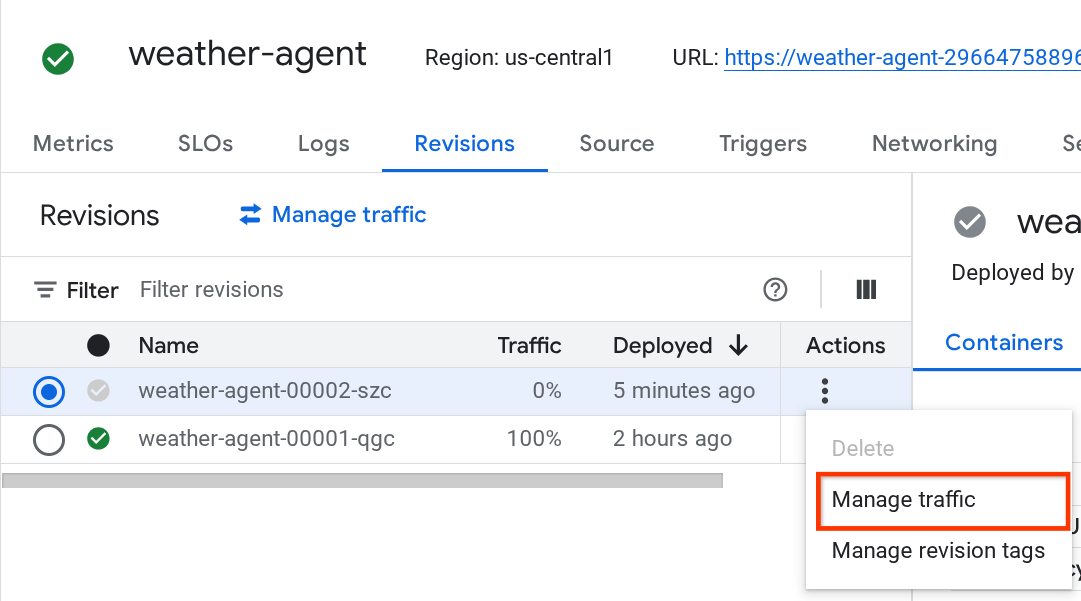
W nowo otwartym okienku możesz edytować odsetek ruchu kierowanego do poszczególnych wersji.
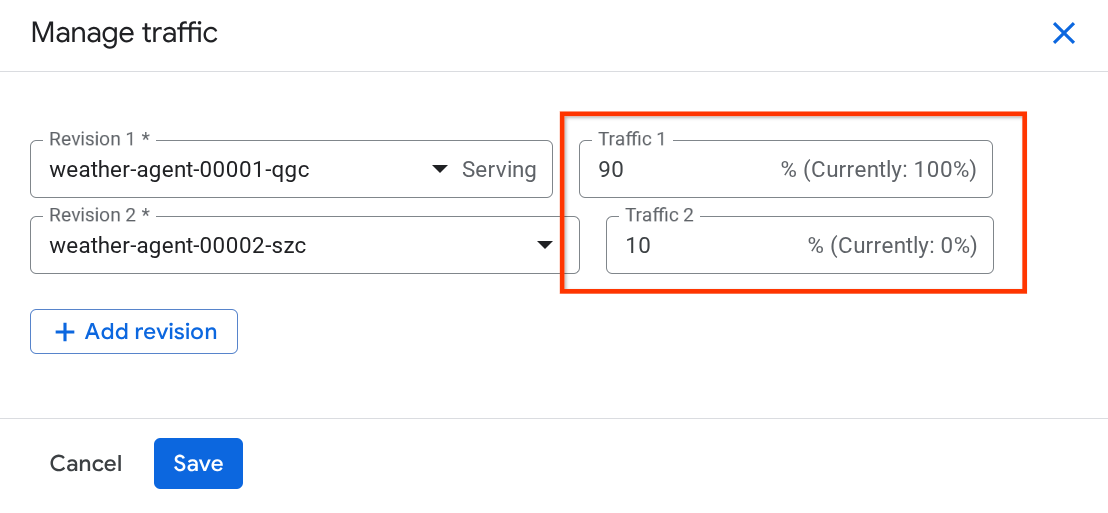
Po pewnym czasie ruch będzie kierowany proporcjonalnie na podstawie konfiguracji procentowych. Dzięki temu w razie problemów z nową wersją możemy łatwo wycofać zmiany do poprzednich wersji.
11. 🚀 Śledzenie ADK
Agenty utworzone za pomocą pakietu ADK obsługują już śledzenie za pomocą otwartej telemetrii. Mamy Cloud Trace, aby rejestrować ślady i je wizualizować. Przyjrzyjmy się plikowi server.py, aby zobaczyć, jak włączyć tę funkcję w usłudze, którą wcześniej wdrożyliśmy.
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
W tym przypadku przekazujemy argument trace_to_cloud do funkcji True. Jeśli wdrażasz usługę za pomocą innych opcji, więcej informacji o włączaniu śledzenia w Cloud Trace w przypadku różnych opcji wdrażania znajdziesz w tej dokumentacji.
Spróbuj uzyskać dostęp do interfejsu internetowego usługi i porozmawiać z agentem. Następnie przejdźmy do strony Eksplorator logów czasu.
Na stronie eksploratora śladów zobaczysz, że ślad naszej rozmowy z agentem został przesłany. W sekcji Nazwa zakresu możesz zobaczyć zakres specyficzny dla naszego agenta ( nazywa się agent_run [weather_agent]) i go odfiltrować.
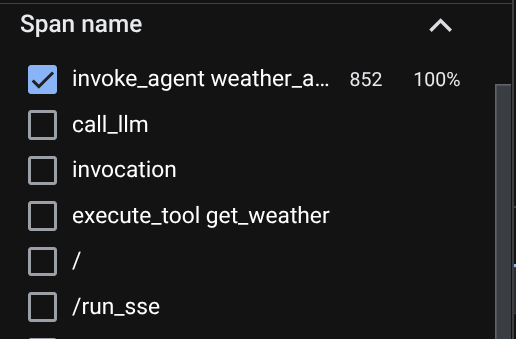
Gdy zakresy są już przefiltrowane, możesz też bezpośrednio sprawdzić każdy ślad. Wyświetla szczegółowy czas trwania każdego działania podjętego przez agenta. Na przykład spójrz na obrazy poniżej.
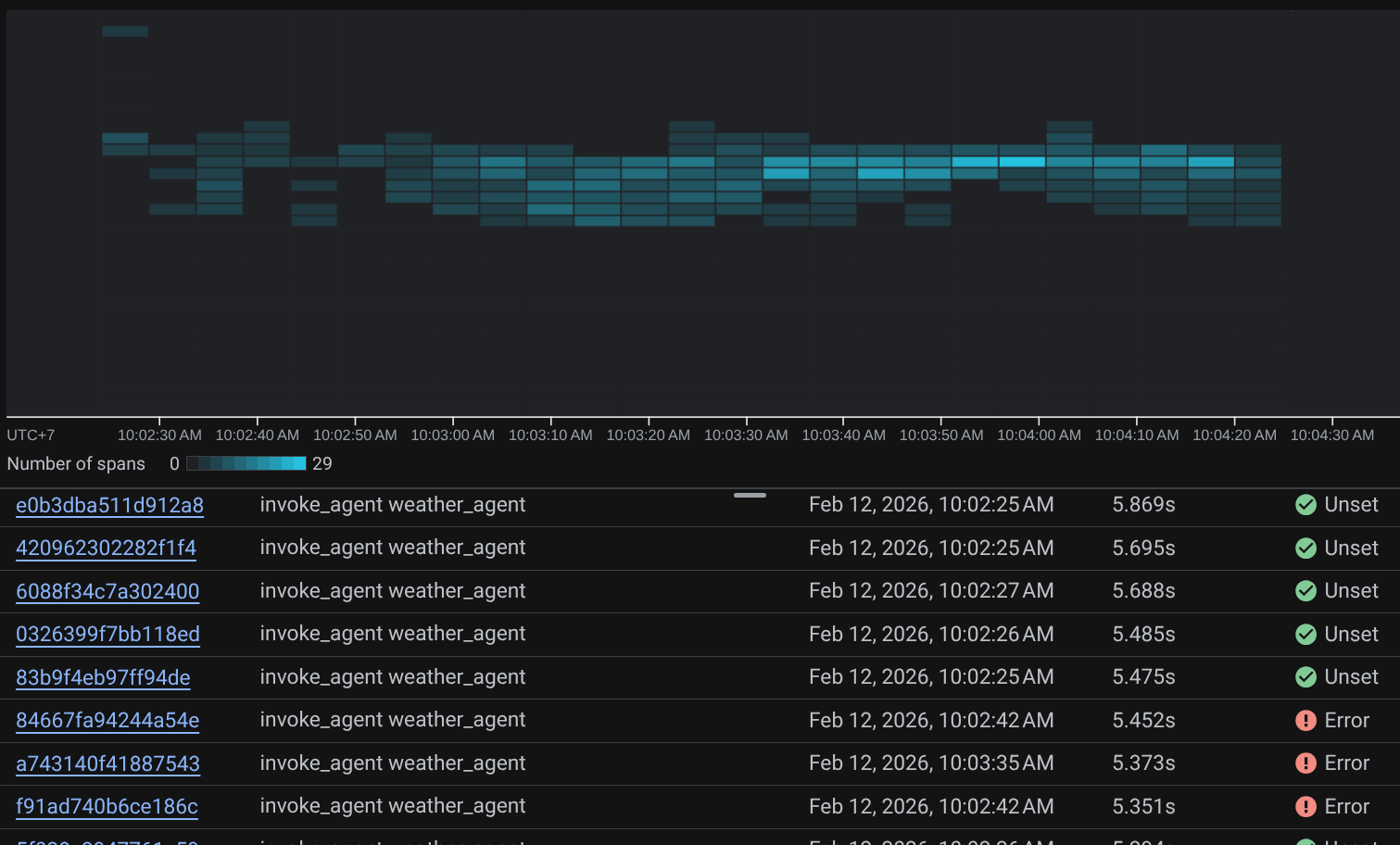
W każdej sekcji możesz sprawdzić szczegóły w atrybutach, jak pokazano poniżej.
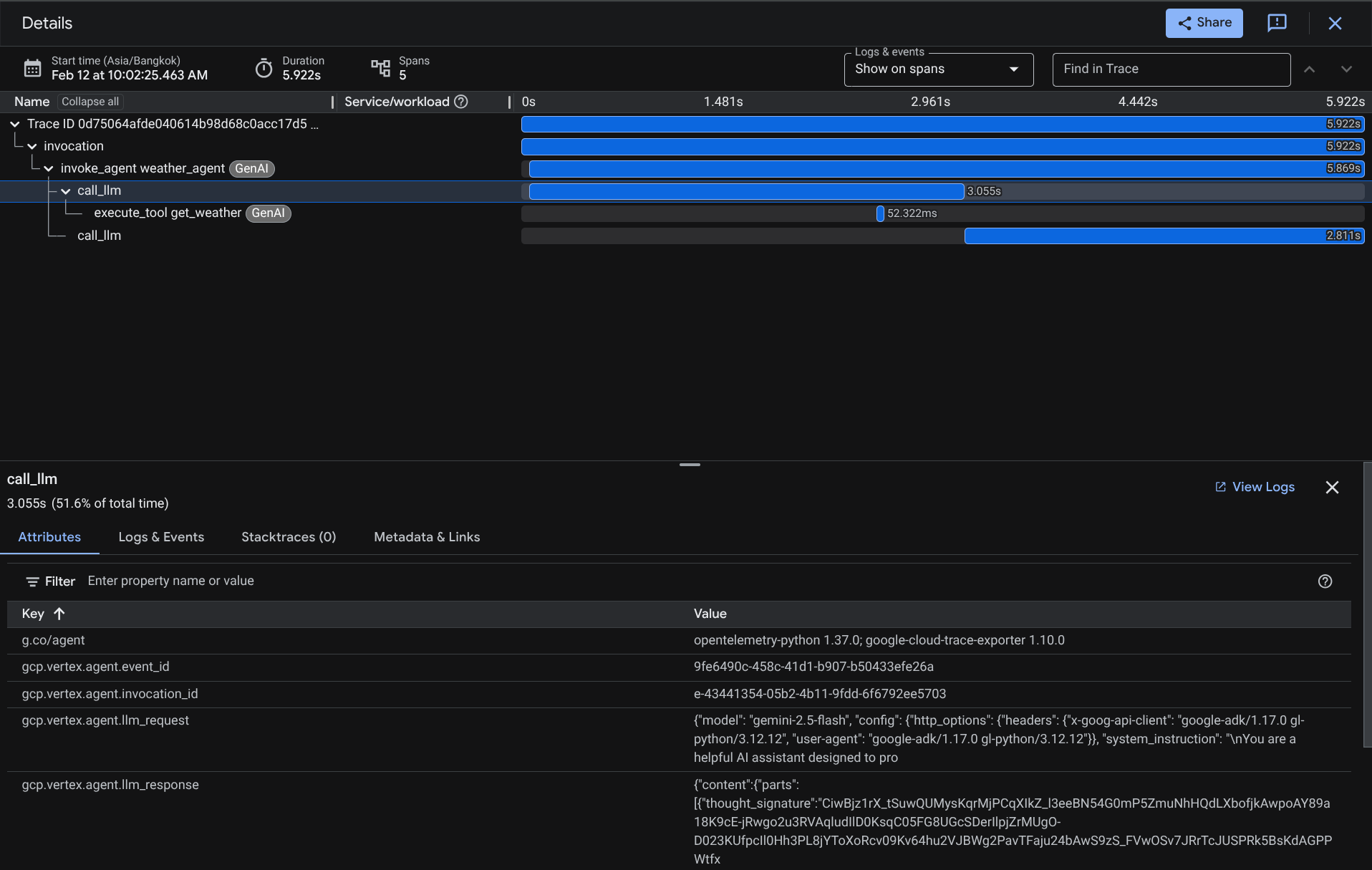
Gotowe. Teraz mamy dobrą dostrzegalność i informacje o każdej interakcji agenta z użytkownikiem, które pomogą nam debugować problemy. Możesz wypróbować różne narzędzia i procesy.
12. 🎯 Wyzwanie
Wypróbuj przepływy pracy z wieloma agentami lub przepływy pracy oparte na agentach, aby sprawdzić, jak działają pod obciążeniem i jak wyglądają logi czasu.
13. 🧹 Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym laboratorium, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
- Możesz też otworzyć Cloud Run w konsoli, wybrać wdrożoną usługę i ją usunąć.