
1. Введение
В этом руководстве вы узнаете, как развернуть, управлять и отслеживать работу мощного агента, созданного с помощью Agent Development Kit (ADK) на платформе Google Cloud Run. ADK позволяет создавать агентов, способных выполнять сложные многоагентные рабочие процессы. Используя Cloud Run, полностью управляемую бессерверную платформу, вы можете развернуть своего агента как масштабируемое контейнеризированное приложение, не беспокоясь о базовой инфраструктуре. Это мощное сочетание позволяет вам сосредоточиться на основной логике вашего агента, одновременно пользуясь преимуществами надежной и масштабируемой среды Google Cloud.
В этом руководстве мы рассмотрим бесшовную интеграцию ADK с Cloud Run. Вы узнаете, как развернуть агент, а затем перейдете к практическим аспектам управления вашим приложением в условиях, приближенных к производственной среде. Мы рассмотрим, как безопасно развертывать новые версии агента, управляя трафиком, что позволит вам тестировать новые функции на ограниченном количестве пользователей перед полным релизом.
Кроме того, вы получите практический опыт мониторинга производительности вашего агента. Мы смоделируем реальный сценарий, проведя нагрузочное тестирование, чтобы понаблюдать за возможностями автоматического масштабирования Cloud Run в действии. Для более глубокого понимания поведения и производительности вашего агента мы включим трассировку с помощью Cloud Trace. Это обеспечит детальное сквозное представление запросов по мере их прохождения через ваш агент, что позволит вам выявлять и устранять любые узкие места в производительности. К концу этого руководства вы получите полное понимание того, как эффективно развертывать, управлять и отслеживать ваши агенты на базе ADK в Cloud Run.
В ходе выполнения практического задания вы будете использовать следующий пошаговый подход:
- Создайте базу данных PostgreSQL в CloudSQL для использования в качестве службы сессий базы данных ADK Agent.
- Настройте базовый агент ADK.
- Настройте службу сессий базы данных для использования в ADK Runner.
- Первоначально разверните агент в облаке.
- Тестирование нагрузки и проверка масштабируемости облачных сервисов.
- Внедрите новую версию агента и постепенно увеличивайте трафик на новые версии.
- Настройте трассировку облака и проверьте трассировку выполнения агента.
Обзор архитектуры
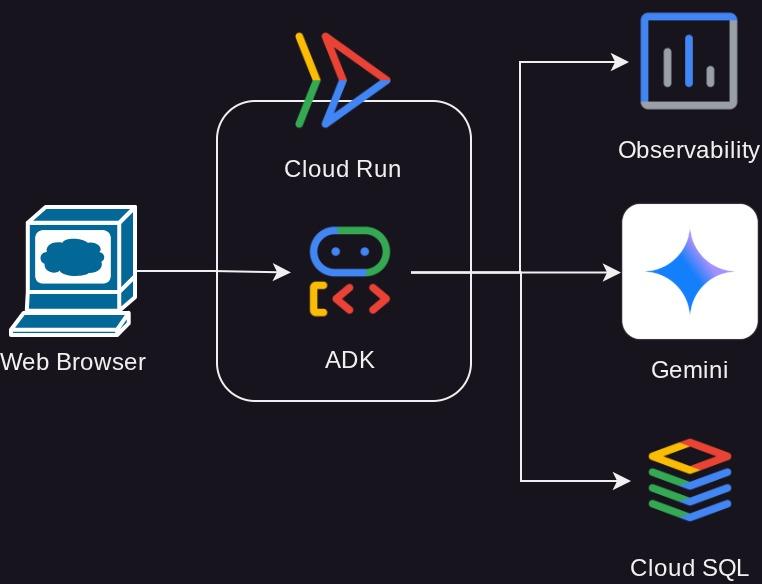
Предварительные требования
- Уверенно работаю с Python.
- Понимание базовой архитектуры полного стека с использованием HTTP-сервисов.
Что вы узнаете
- Структура ADK и локальные утилиты
- Настройка агента ADK с использованием службы сессий базы данных.
- Настройка PostgreSQL в CloudSQL для использования службой сессий базы данных.
- Разверните приложение в Cloud Run с помощью Dockerfile и настройте начальные переменные среды.
- Настройка и тестирование автоматического масштабирования Cloud Run с нагрузочным тестированием.
- Стратегия поэтапного внедрения с помощью Cloud Run
- Настройте трассировку агента ADK в Cloud Trace.
Что вам понадобится
- Веб-браузер Chrome
- Аккаунт Gmail
- Облачный проект с включенной функцией выставления счетов.
Этот практический урок, разработанный для разработчиков всех уровней (включая начинающих), использует Python в качестве примера приложения. Однако знание Python не требуется для понимания представленных концепций.
2. 🚀 Подготовка к организации рабочего места
В этом уроке мы будем использовать среду разработки Cloud Shell IDE. Для перехода на неё нажмите следующую кнопку.
После входа в Cloud Shell клонируйте рабочий каталог шаблона для этого практического занятия из Github и выполните следующую команду. Она создаст рабочий каталог в директории deploy_and_manage_adk.
git clone https://github.com/alphinside/deploy-and-manage-adk-service.git deploy_and_manage_adk
Затем выполните следующую команду в терминале, чтобы открыть клонированный репозиторий в качестве рабочей директории.
cloudshell workspace ~/deploy_and_manage_adk && cd ~/deploy_and_manage_adk
После этого ваш интерфейс должен выглядеть примерно так.
Это будет наш основной интерфейс: IDE сверху, терминал снизу. Теперь нам нужно подготовить терминал для создания и активации нашего проекта Google Cloud, который будет связан с ранее активированным пробным аккаунтом. Мы подготовили для вас скрипт, который всегда будет гарантировать готовность вашей терминальной сессии. Выполните следующую команду (убедитесь, что вы уже находитесь в рабочей области deploy_and_manage_adk
bash setup_trial_project.sh && source .env
При запуске вам будет предложено ввести имя проекта (ID), для продолжения нажмите Enter

Если после некоторого ожидания вы увидите следующий вывод в консоли, значит, вы готовы перейти к следующему шагу. 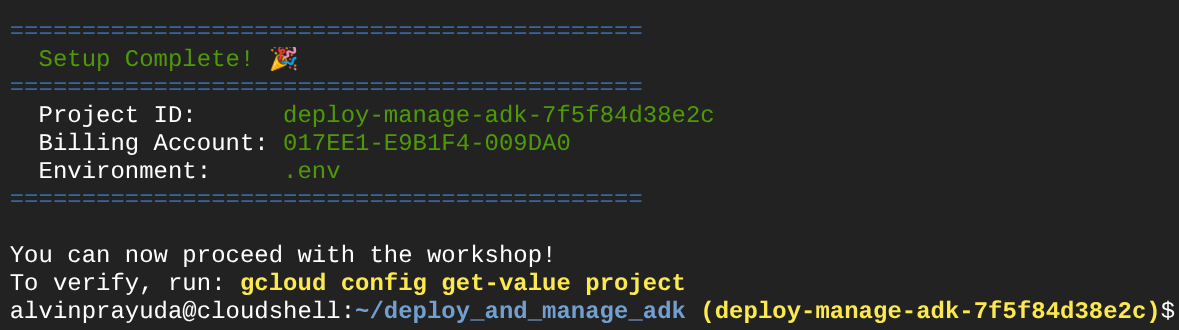
Это показывает, что ваш терминал уже авторизован и настроен на правильный идентификатор проекта (жёлтый цвет рядом с текущим путем к каталогу). Эта команда помогает вам создать новый проект, найти и связать проект с пробной учетной записью для оплаты, подготовить файл .env для настройки переменных среды, а также активировать правильный идентификатор проекта в терминале.
Теперь мы готовы к следующему шагу.
3. 🚀 Включение API
В этом руководстве мы будем взаимодействовать с базой данных CloudSQL, моделью Gemini и Cloud Run. Для работы этих продуктов потребуется активировать следующие API; выполните следующие команды, чтобы включить их.
Это может занять некоторое время.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
После успешного выполнения команды вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
4. 🚀 Настройка среды Python и переменные среды
В этом практическом занятии мы будем использовать Python 3.12 и менеджер проектов Python UV , чтобы упростить создание и управление версиями Python и виртуальными средами. Этот пакет UV уже предустановлен в Cloud Shell.
Выполните эту команду, чтобы установить необходимые зависимости в виртуальное окружение в каталоге .venv.
uv sync --frozen
Далее мы рассмотрим необходимые файлы переменных окружения для этого проекта. Ранее этот файл настраивался скриптом setup_trial_project.sh . Выполните следующую команду, чтобы открыть файл .env в редакторе.
cloudshell open .env
В файле .env уже будут применены следующие настройки.
# .env # Google Cloud and Vertex AI configuration GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=global GOOGLE_GENAI_USE_VERTEXAI=True # Database connection for session service # DB_CONNECTION_NAME=your-db-connection-name
Для этого практического занятия мы будем использовать предварительно настроенные значения для параметров GOOGLE_CLOUD_LOCATION и GOOGLE_GENAI_USE_VERTEXAI.
Теперь мы можем перейти к следующему шагу — созданию базы данных, которая будет использоваться нашим агентом для сохранения состояния и сессий.
5. 🚀 Подготовка базы данных CloudSQL
Нам понадобится база данных для использования агентом ADK в дальнейшем. Давайте создадим базу данных PostgreSQL в Cloud SQL. Сначала выполните следующую команду для создания экземпляра базы данных. Мы будем использовать имя базы данных postgres по умолчанию, поэтому создание базы данных мы пропустим. Нам также необходимо настроить имя пользователя базы данных по умолчанию (также postgres) . Для простоты урока давайте используем ADK-deployment123 в качестве пароля.
gcloud sql instances create adk-deployment \
--database-version=POSTGRES_17 \
--edition=ENTERPRISE \
--tier=db-g1-small \
--region=us-west1 \
--availability-type=ZONAL \
--project=${GOOGLE_CLOUD_PROJECT} && \
gcloud sql users set-password postgres \
--instance=adk-deployment \
--password=ADK-deployment123
В приведенной выше команде первая команда gcloud sql instances create adk-deployment используется для создания экземпляра базы данных. Для целей этого руководства мы используем минимальную спецификацию песочницы. Вторая команда gcloud sql users set-password postgres используется для изменения имени пользователя и пароля по умолчанию в PostgreSQL.
Обратите внимание, что в качестве имени экземпляра базы данных мы используем adk-deployment . После завершения в терминале должен отобразиться вывод, подобный показанному ниже, который подтверждает готовность экземпляра и обновление пароля пользователя по умолчанию.
Created [https://sqladmin.googleapis.com/sql/v1beta4/projects/your-project-id/instances/adk-deployment]. NAME: adk-deployment DATABASE_VERSION: POSTGRES_17 LOCATION: us-west1-a TIER: db-g1-small PRIMARY_ADDRESS: xx.xx.xx.xx PRIVATE_ADDRESS: - STATUS: RUNNABLE Updating Cloud SQL user...done.
Поскольку развертывание этой базы данных займет некоторое время, давайте перейдем к следующему разделу, пока не будет готова развертка базы данных CloudSQL.
6. 🚀 Создайте агента погоды с помощью ADK и Gemini 2.5
Введение в структуру каталогов ADK
Начнём с изучения возможностей ADK и способов создания агента. Полную документацию по ADK можно найти по этому адресу . ADK предлагает множество утилит в рамках выполнения команд CLI. Некоторые из них:
- Настройка структуры каталогов агента
- Быстро попробуйте взаимодействие через ввод/вывод командной строки.
- Быстрая настройка локального веб-интерфейса для разработки.
Теперь давайте проверим структуру агента в каталоге weather_agent.
weather_agent/ ├── __init__.py ├── agent.py └── tool.py
А если вы изучите файлы init.py и agent.py, то увидите следующий код.
# __init__.py
from weather_agent.agent import root_agent
__all__ = ["root_agent"]
# agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
""",
tools=[get_weather],
)
Пояснение к коду ADK
Этот скрипт содержит инициализацию нашего агента, в ходе которой мы выполняем следующие действия:
- Установите модель для использования:
gemini-2.5-flash - Предоставьте инструменту
get_weatherподдержку функциональности агента в качестве агента погоды.
Запустите веб-интерфейс локально.
Теперь мы можем взаимодействовать с агентом и локально изучать его поведение. ADK позволяет нам использовать веб-интерфейс для разработки, чтобы взаимодействовать с ним и отслеживать происходящее во время взаимодействия. Выполните следующую команду, чтобы запустить локальный сервер пользовательского интерфейса для разработки.
uv run adk web --port 8080
Результат будет выглядеть примерно так, как в следующем примере, это означает, что мы уже можем получить доступ к веб-интерфейсу.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Чтобы проверить это, нажмите кнопку « Предварительный просмотр веб-страниц» в верхней части редактора Cloud Shell и выберите «Предварительный просмотр на порту 8080».
Вы увидите следующую веб-страницу, где сможете выбрать доступных агентов в выпадающем списке в верхнем левом углу (в нашем случае это должен быть weather_agent ) и взаимодействовать с ботом. В левом окне вы увидите подробную информацию о логах во время работы агента.
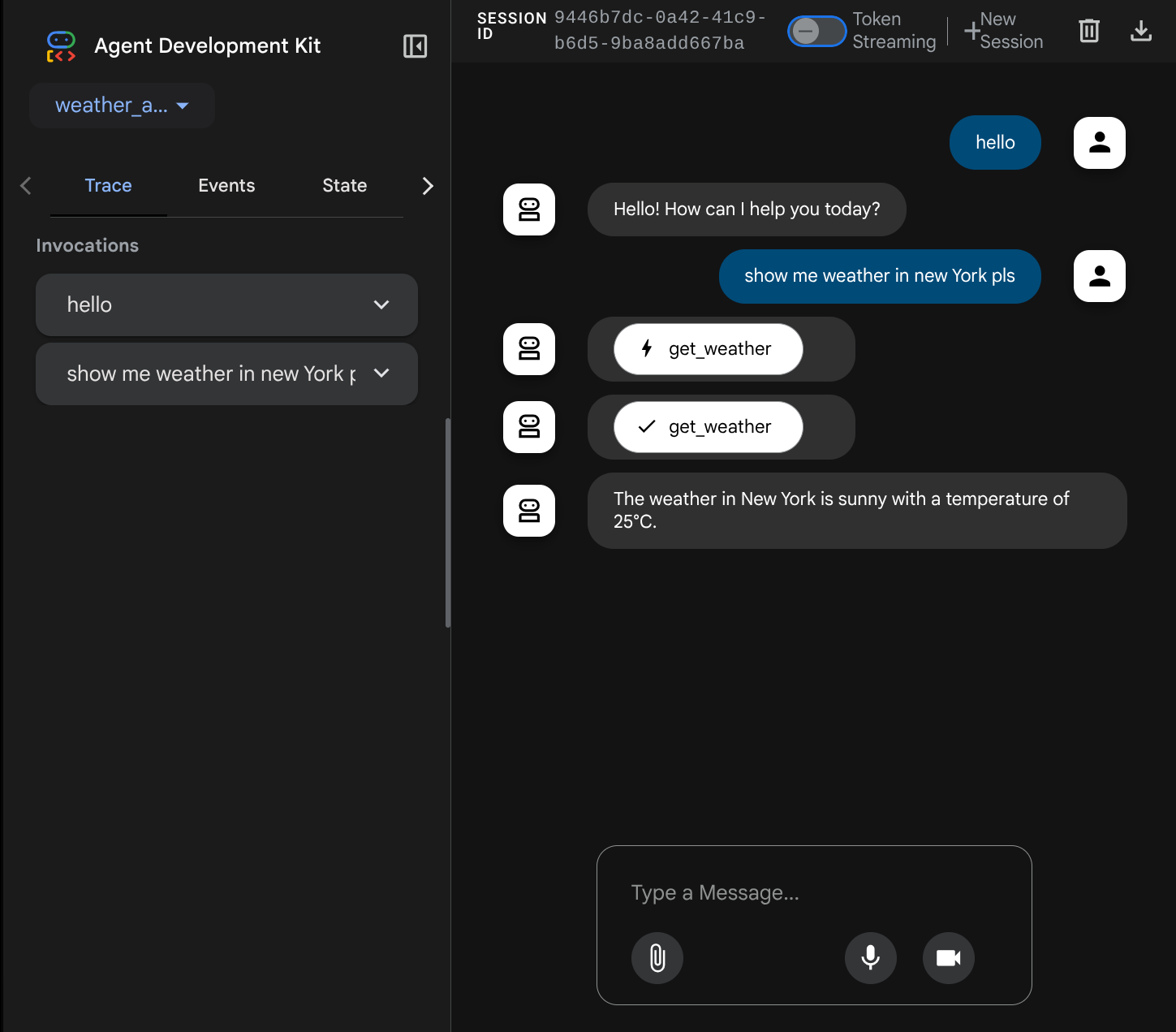
Теперь попробуйте взаимодействовать с ним. На левой панели мы можем просмотреть трассировку для каждого входного сигнала, чтобы понять, сколько времени требуется агенту для выполнения каждого действия, прежде чем сформировать окончательный ответ.
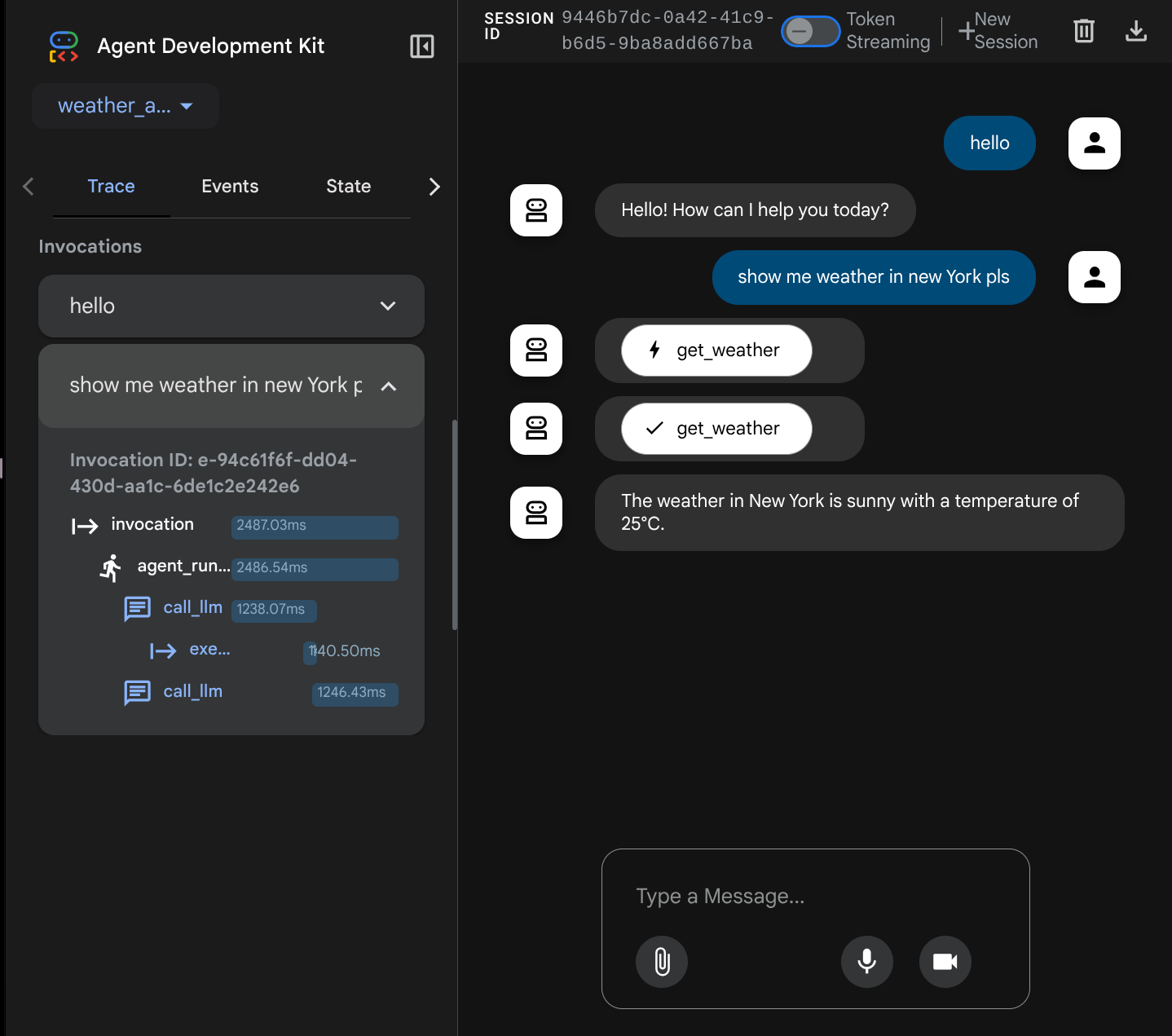
Это одна из функций мониторинга, встроенных в ADK, в настоящее время мы изучаем её локально. Позже мы увидим, как она интегрирована в Cloud Tracing, чтобы у нас была централизованная трассировка всех запросов.
7. 🚀 Развертывание в Cloud Run
Теперь давайте развернем этот агентский сервис в Cloud Run. В рамках этой демонстрации сервис будет предоставлен как общедоступный, к которому смогут получить доступ другие пользователи. Однако имейте в виду, что это не является лучшей практикой, поскольку это небезопасно.
Этот сценарий развертывания позволяет настроить бэкэнд-сервис вашего агента; для развертывания агента в Cloud Run мы будем использовать Dockerfile. На данном этапе у нас уже есть все необходимые файлы ( Dockerfile и server.py ) для развертывания наших приложений в Cloud Run. Наличие этих двух элементов позволяет гибко настраивать развертывание агента (например, добавлять пользовательские маршруты бэкэнда и/или добавлять дополнительные сервисы-сайдкары для целей мониторинга). Мы подробно обсудим это позже.
Теперь давайте сначала развернем сервис. Перейдите в терминал Cloud Shell и убедитесь, что текущий проект настроен на ваш активный проект. Давайте снова запустим скрипт настройки. При желании вы также можете использовать команду ` gcloud config set project [PROJECT_ID] для настройки вашего активного проекта.
bash setup_trial_project.sh && source .env
Теперь нам нужно снова открыть файл .env , и вы увидите, что нам нужно раскомментировать переменную DB_CONNECTION_NAME и заполнить её правильным значением.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-db-connection-name
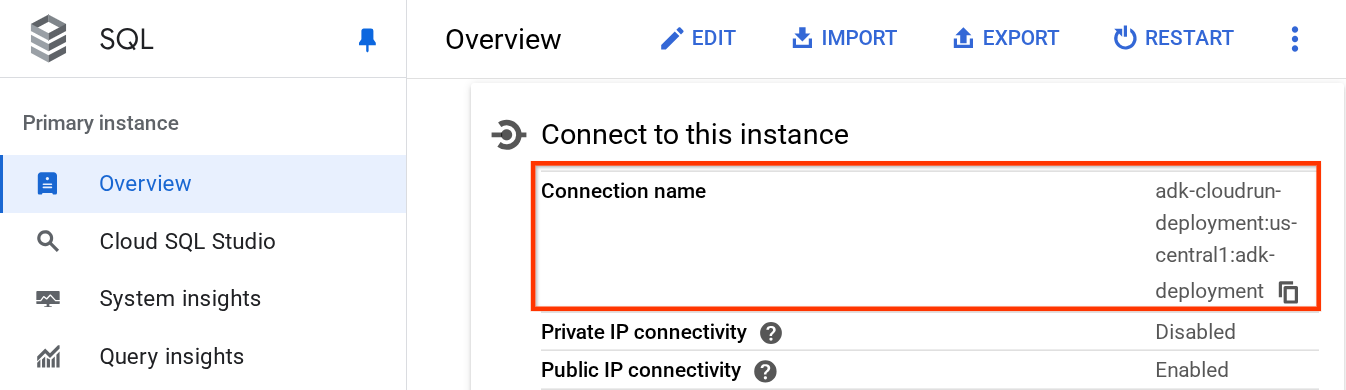
Чтобы получить значение DB_CONNECTION_NAME , перейдем к панели мониторинга Cloud SQL.
Затем щелкните созданный вами экземпляр. Перейдите к строке поиска в верхней части консоли Cloud и введите «Cloud SQL». Затем щелкните продукт Cloud SQL .
После этого вы увидите ранее созданный экземпляр, щелкните по нему.
На странице экземпляра прокрутите вниз до раздела « Подключиться к этому экземпляру », и вы сможете скопировать имя подключения , чтобы заменить им значение DB_CONNECTION_NAME .
После этого откройте файл .env с помощью следующей команды.
cloudshell edit .env
и измените переменную DB_CONNECTION_NAME в файле .env . Ваш файл env должен выглядеть примерно так, как показано в примере ниже.
# Google Cloud and Vertex AI configuration
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
# Database connection for session service
DB_CONNECTION_NAME=your-project-id:your-location:your-instance-name
После этого запустите скрипт развертывания.
bash deploy_to_cloudrun.sh
Если появится запрос на подтверждение создания реестра артефактов для репозитория Docker, просто ответьте «Да».
Пока мы ждём завершения процесса развертывания, давайте взглянем на скрипт deploy_to_cloudrun.sh.
#!/bin/bash
# Load environment variables from .env file
if [ -f .env ]; then
export $(cat .env | grep -v '^#' | xargs)
else
echo "Error: .env file not found"
exit 1
fi
# Validate required variables
required_vars=("GOOGLE_CLOUD_PROJECT" "DB_CONNECTION_NAME")
for var in "${required_vars[@]}"; do
if [ -z "${!var}" ]; then
echo "Error: $var is not set in .env file"
exit 1
fi
done
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project ${GOOGLE_CLOUD_PROJECT} \
--allow-unauthenticated \
--add-cloudsql-instances ${DB_CONNECTION_NAME} \
--update-env-vars SESSION_SERVICE_URI="postgresql+pg8000://postgres:ADK-deployment123@postgres/?unix_sock=/cloudsql/${DB_CONNECTION_NAME}/.s.PGSQL.5432",GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--region us-west1 \
--min 1 \
--memory 1G \
--concurrency 10
Этот скрипт загрузит вашу переменную .env , а затем выполнит команду развертывания.
Если присмотреться, нам нужна всего одна команда `gcloud run deploy`, чтобы выполнить все необходимые действия для развертывания сервиса: сборку образа, отправку в реестр, развертывание сервиса, настройку политики IAM, создание ревизии и даже маршрутизацию трафика. В этом примере у нас уже есть Dockerfile, поэтому эта команда будет использовать его для сборки приложения.
После завершения развертывания вы должны получить ссылку, похожую на приведенную ниже:
https://weather-agent-*******.us-west1.run.app
Получив этот URL-адрес, вы можете использовать свое приложение в режиме инкогнито или на мобильном устройстве и получить доступ к пользовательскому интерфейсу разработчика агента. Пока ожидается развертывание, давайте рассмотрим подробную информацию о службе, которую мы только что развернули, в следующем разделе.
8. 💡 Dockerfile и скрипт бэкэнд-сервера
Чтобы сделать агента доступным в качестве сервиса, мы обернем его в приложение FastAPI, которое будет запускаться по команде Dockerfile. Ниже приведено содержимое Dockerfile.
FROM python:3.12-slim
RUN pip install --no-cache-dir uv==0.7.13
WORKDIR /app
COPY . .
RUN uv sync --frozen
EXPOSE 8080
CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
Здесь мы можем настроить необходимые службы для поддержки агента, например, подготовить службы сессий , памяти или артефактов для использования в производственной среде. Вот код файла server.py , который будет использоваться.
import os
from dotenv import load_dotenv
from fastapi import FastAPI
from google.adk.cli.fast_api import get_fast_api_app
from pydantic import BaseModel
from typing import Literal
from google.cloud import logging as google_cloud_logging
# Load environment variables from .env file
load_dotenv()
logging_client = google_cloud_logging.Client()
logger = logging_client.logger(__name__)
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Get session service URI from environment variables
session_uri = os.getenv("SESSION_SERVICE_URI", None)
# Prepare arguments for get_fast_api_app
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
# Only include session_service_uri if it's provided
if session_uri:
app_args["session_service_uri"] = session_uri
else:
logger.log_text(
"SESSION_SERVICE_URI not provided. Using in-memory session service instead. "
"All sessions will be lost when the server restarts.",
severity="WARNING",
)
# Create FastAPI app with appropriate arguments
app: FastAPI = get_fast_api_app(**app_args)
app.title = "weather-agent"
app.description = "API for interacting with the Agent weather-agent"
class Feedback(BaseModel):
"""Represents feedback for a conversation."""
score: int | float
text: str | None = ""
invocation_id: str
log_type: Literal["feedback"] = "feedback"
service_name: Literal["weather-agent"] = "weather-agent"
user_id: str = ""
# Example if you want to add your custom endpoint
@app.post("/feedback")
def collect_feedback(feedback: Feedback) -> dict[str, str]:
"""Collect and log feedback.
Args:
feedback: The feedback data to log
Returns:
Success message
"""
logger.log_struct(feedback.model_dump(), severity="INFO")
return {"status": "success"}
# Main execution
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
Пояснение к серверному коду
Вот параметры, которые определены в скрипте server.py :
- Преобразуем наш агент в приложение FastAPI, используя метод
get_fast_api_app. Таким образом, мы унаследуем то же определение маршрута, которое используется для пользовательского интерфейса веб-разработки. - Настройте необходимые службы для работы с сессиями, памятью или артефактами, добавив ключевые аргументы к методу
get_fast_api_app. В этом руководстве, если мы настроим переменную окруженияSESSION_SERVICE_URI, служба сессий будет использовать её, в противном случае она будет использовать сессию в памяти. - Мы можем добавить пользовательский маршрут для поддержки другой бизнес-логики бэкэнда; в скрипте мы добавляем маршрут для функциональности обратной связи, например.
- Включите трассировку облака в параметре
get_fast_api_app, чтобы отправлять трассировку в Google Cloud Trace. - Запустите сервис FastAPI с помощью uvicorn.
Если развертывание уже завершено, попробуйте взаимодействовать с агентом через веб-интерфейс разработчика, перейдя по URL-адресу Cloud Run.
9. 🚀 Проверка автоматического масштабирования Cloud Run с помощью нагрузочного тестирования
Теперь рассмотрим возможности автоматического масштабирования Cloud Run. Для этого сценария развернем новую версию, включив ограничение на максимальное количество параллельных экземпляров. В предыдущем разделе мы установили максимальное количество параллельных экземпляров равным 10 (флаг --concurrency 10 ). Следовательно, можно ожидать, что Cloud Run попытается масштабировать свой экземпляр при проведении нагрузочного тестирования, превышающего это число.
Давайте рассмотрим файл load_test.py . Это скрипт, который мы будем использовать для нагрузочного тестирования с помощью фреймворка Locust . Этот скрипт выполнит следующие действия:
- Случайные значения user_id и session_id
- Создайте session_id для user_id.
- Обратитесь к конечной точке "/run_sse", используя созданные user_id и session_id.
Если вы пропустили этот шаг, нам потребуется URL-адрес развернутого сервиса. Мы можем перейти в консоль Cloud Run.
Затем найдите свою службу метеорологического агентства и нажмите на неё.
URL-адрес сервиса будет отображаться рядом с информацией о регионе. Например:

Чтобы упростить задачу, давайте запустим следующий скрипт, чтобы получить URL-адрес недавно развернутой службы и сохранить его в переменной среды SERVICE_URL
export SERVICE_URL=$(gcloud run services describe weather-agent \
--platform managed \
--region us-west1 \
--format 'value(status.url)')
Затем выполните следующую команду для нагрузочного тестирования нашего агентского приложения.
uv run locust -f load_test.py \
-H $SERVICE_URL \
-u 60 \
-r 5 \
-t 120 \
--headless
При запуске программы вы увидите метрики, подобные этим. (В этом примере все запросы выполнены успешно)
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /run_sse end 813 0(0.00%) | 5817 2217 26421 5000 | 6.79 0.00
POST /run_sse message 813 0(0.00%) | 2678 1107 17195 2200 | 6.79 0.00
--------|------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1626 0(0.00%) | 4247 1107 26421 3500 | 13.59 0.00
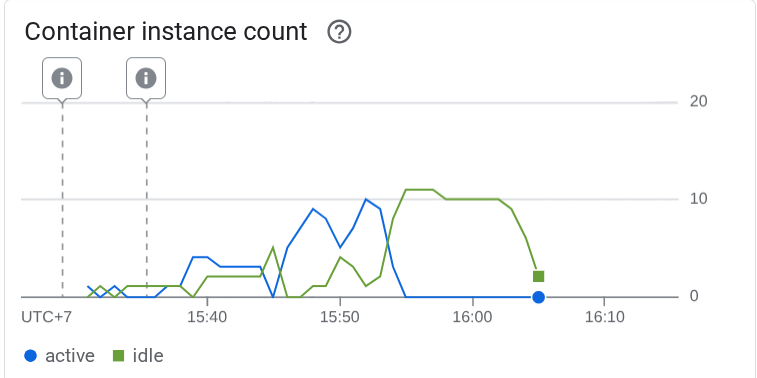
Давайте посмотрим, что произошло в Cloud Run. Снова перейдите к развернутой службе и посмотрите на панель мониторинга. Там будет показано, как Cloud Run автоматически масштабирует экземпляр для обработки входящих запросов. Поскольку мы ограничиваем максимальное количество параллельных запросов до 10 на экземпляр, экземпляр Cloud Run попытается автоматически скорректировать количество контейнеров, чтобы удовлетворить это условие.
10. 🚀 Постепенный выпуск новых версий
Теперь рассмотрим следующий сценарий. Мы хотим обновить приглашение агента. Откройте файл weather_agent/agent.py с помощью следующей команды.
cloudshell edit weather_agent/agent.py
и замените его следующим кодом:
# weather_agent/agent.py
import os
from pathlib import Path
import google.auth
from dotenv import load_dotenv
from google.adk.agents import Agent
from weather_agent.tool import get_weather
# Load environment variables from .env file in root directory
root_dir = Path(__file__).parent.parent
dotenv_path = root_dir / ".env"
load_dotenv(dotenv_path=dotenv_path)
# Use default project from credentials if not in .env
_, project_id = google.auth.default()
os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id)
os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "global")
os.environ.setdefault("GOOGLE_GENAI_USE_VERTEXAI", "True")
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="""
You are a helpful AI assistant designed to provide accurate and useful information.
You only answer inquiries about the weather. Refuse all other user query
""",
tools=[get_weather],
)
Итак, вы хотите выпустить новые ревизии, но не хотите, чтобы весь трафик запросов направлялся напрямую на новую версию. Мы можем осуществить поэтапный выпуск с помощью Cloud Run. Сначала нам нужно развернуть новую ревизию, но с флагом –no-traffic . Сохраните предыдущий скрипт агента и выполните следующую команду.
gcloud run deploy weather-agent \
--source . \
--port 8080 \
--project $GOOGLE_CLOUD_PROJECT \
--allow-unauthenticated \
--region us-west1 \
--no-traffic
После завершения вы получите аналогичный журнал, как и в предыдущем процессе развертывания, но с той разницей, что будет отображаться количество обработанного трафика. В нем будет показано 0% обработанного трафика.
Service [weather-agent] revision [weather-agent-xxxx-xxx] has been deployed and is serving 0 percent of traffic.
Далее перейдём к панели управления Cloud Run.
Затем найдите свою службу метеорологического агентства и нажмите на неё.
Перейдите на вкладку «Ревизии» , и вы увидите там список развернутых ревизий.
Вы увидите, что новые развернутые версии обслуживают 0%, отсюда вы можете нажать кнопку с изображением шашлычка (⋮) и выбрать «Управление трафиком».
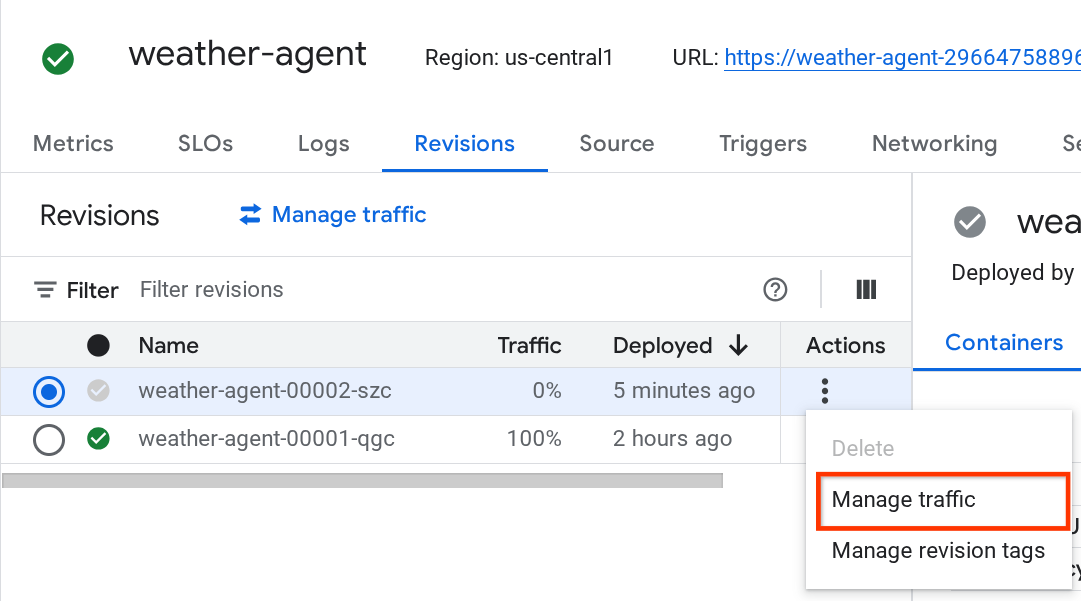
В появившемся окне вы можете изменить процент трафика, направляемого на те или иные версии.
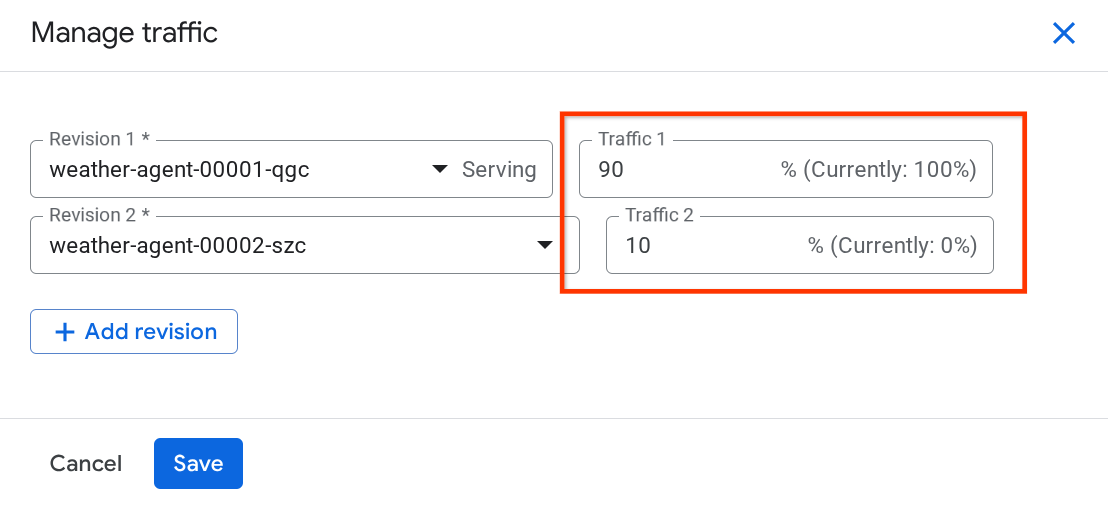
После некоторого ожидания трафик будет распределен пропорционально в соответствии с заданными процентными настройками. Таким образом, мы сможем легко вернуться к предыдущим версиям, если что-то случится с новым релизом.
11. 🚀 Отслеживание ADK
Агенты, созданные с использованием ADK, уже поддерживают трассировку с помощью встроенной открытой телеметрии. У нас есть Cloud Trace для сбора и визуализации этих данных. Давайте посмотрим в файле server.py , как мы включаем эту функцию в нашем ранее развернутом сервисе.
# server.py
...
app_args = {"agents_dir": AGENT_DIR, "web": True, "trace_to_cloud": True}
...
app: FastAPI = get_fast_api_app(**app_args)
...
Здесь мы передаем аргумент trace_to_cloud со значением True . Если вы развертываете систему с другими параметрами, вы можете ознакомиться с этой документацией для получения более подробной информации о том, как включить трассировку в Cloud Trace из различных вариантов развертывания.
Попробуйте получить доступ к веб-интерфейсу разработчика вашей службы и пообщайтесь с агентом. После этого перейдем на страницу Trace Explorer.
На странице просмотра трассировки вы увидите, что наша переписка с агентом отправлена. В разделе «Имя сегмента» вы можете отфильтровать сегмент, относящийся к нашему агенту (он называется agent_run [weather_agent] ).
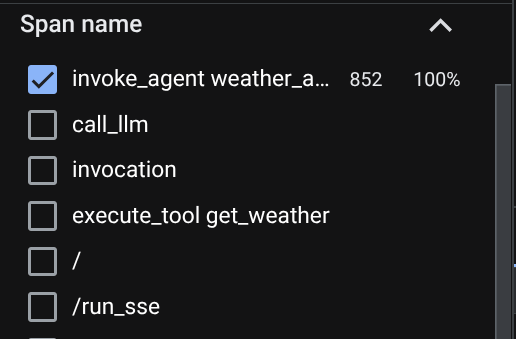
После фильтрации трассировок вы также можете просмотреть каждую из них напрямую. Будет показана подробная продолжительность каждого действия, выполненного агентом. Например, посмотрите изображения ниже.
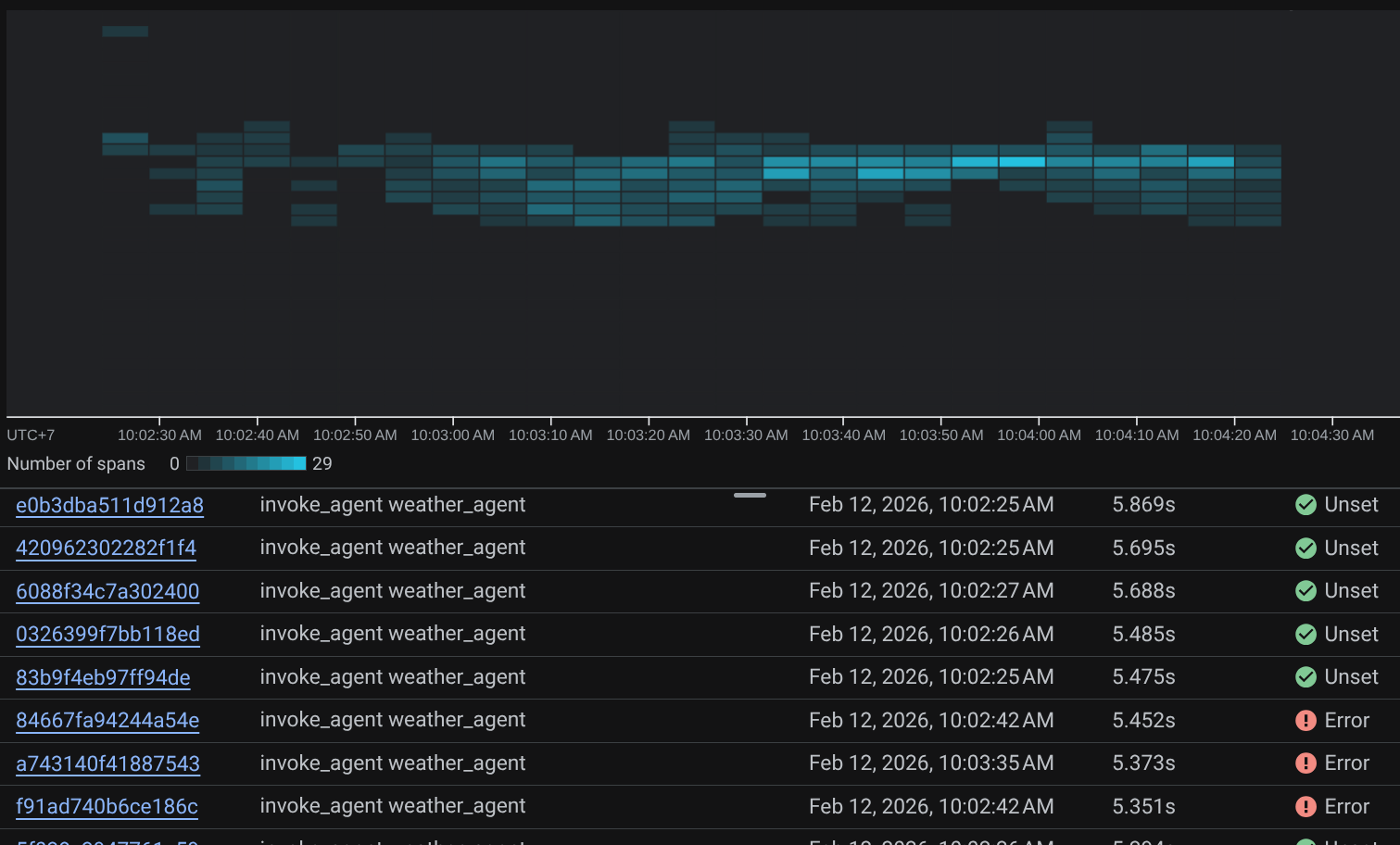
В каждом разделе вы можете просмотреть подробную информацию в атрибутах, как показано ниже.
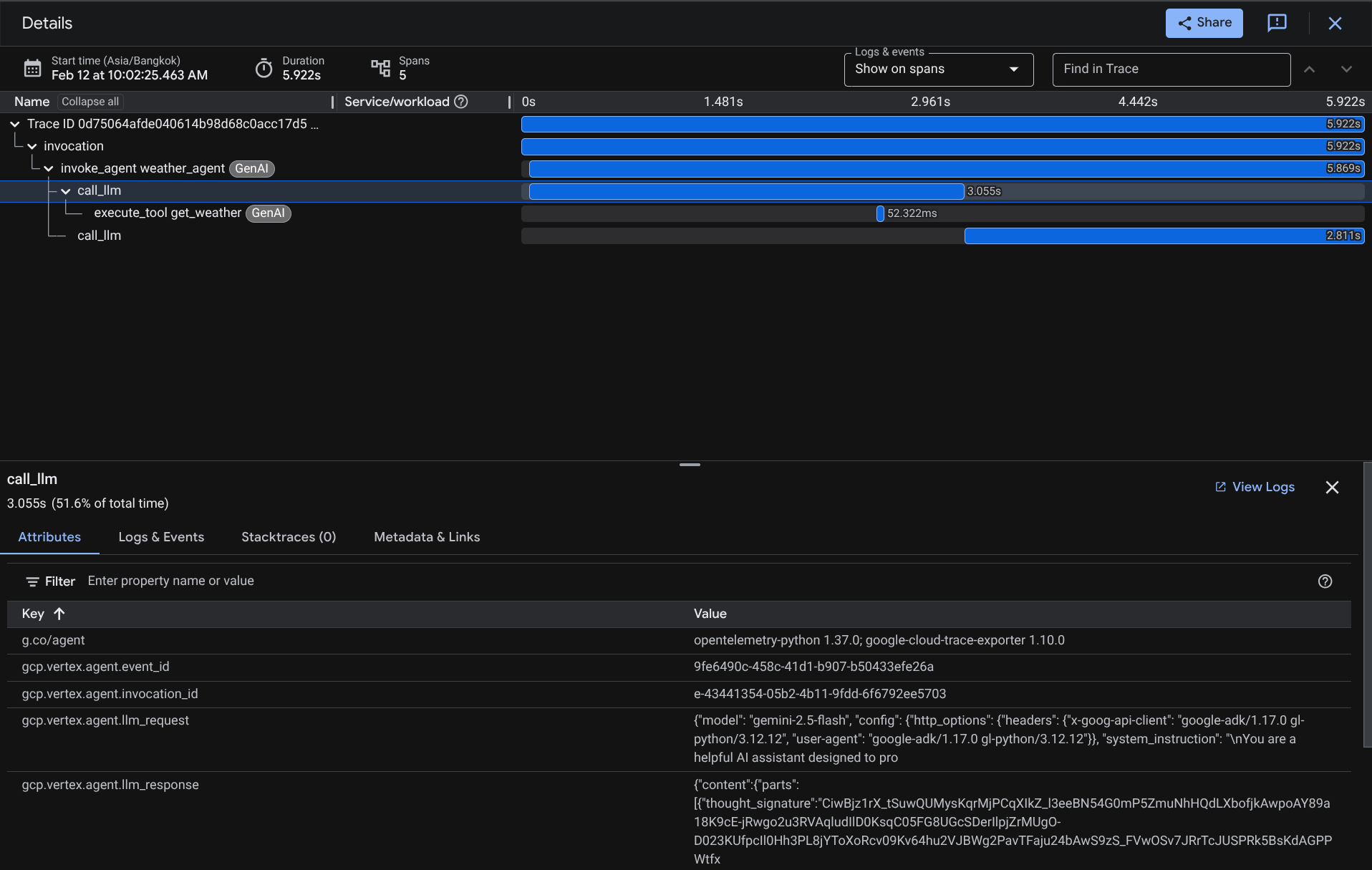
Вот и все, теперь у нас есть хорошая возможность наблюдения и информация о каждом взаимодействии нашего агента с пользователем, что поможет в отладке проблем. Смело пробуйте различные инструменты или рабочие процессы!
12. 🎯 Вызов
Попробуйте использовать многоагентные или агентные рабочие процессы, чтобы посмотреть, как они работают под нагрузкой и как выглядит трассировка.
13. 🧹 Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
- В качестве альтернативы вы можете перейти в Cloud Run в консоли, выбрать только что развернутую службу и удалить ее.