
1. 始める前に
「ADK を使用して AI エージェントを構築する」シリーズの第 4 回へようこそ。この実践的な Codelab では、これまでのセッションで学んだことを組み合わせて、データ アナリスト エージェントを作成します。このエージェントは、データを分析して有益な分析情報を生成し、データ分析ワークフローの重要な側面を自動化するように設計されています。
ADK に含まれる強力なツールを使用して、アップロードされたファイルを探索し、Google Cloud BigQuery などのエンタープライズ レベルのデータベースに接続できるようにします。
この Codelab には、goo.gle/adk-data-analyst という短縮 URL からもアクセスできます。
前提条件
- 生成 AI のコンセプトに関する基礎知識
- Python プログラミングの基本的なスキルと、コマンドラインの使用に慣れていること。
- このシリーズの以前の Codelab「基盤」と「ツールによる強化」のコンセプトを理解していること。
学習内容
- ADK フレームワークを使用して、機能するデータ アナリスト エージェントを構築する方法。
- エージェントがアップロードされたドキュメントからデータを分析できるようにする方法。
- エンタープライズ レベルのデータ分析のためにエージェントを BigQuery データベースに接続する方法。
- エージェントのコアロジック(目的や手順など)を定義する手法。
必要なもの
- 動作するパソコンと信頼できるインターネット接続。
- Google Cloud コンソールにアクセスするためのブラウザ(Chrome など)
- 好奇心と学習意欲。
2. はじめに
今日のデータドリブンな世界では、大量の情報を迅速かつ正確に分析する能力がこれまで以上に重要になっています。しかし、有意義な分析情報を抽出するプロセスには、SQL などの分野の深い技術的専門知識が必要となることが多く、意思決定の遅延につながるボトルネックが生じます。このギャップを埋め、会話をするのと同じくらい簡単に複雑なデータセットを操作できるとしたらどうでしょうか?
AI エージェントは、この状況を変えつつあります。AI エージェントは、ユーザーとデータの間のインテリジェントなインターフェースとして機能し、自然言語の質問を理解して技術的なクエリに変換し、行動につながる分析情報を数秒で提供できます。
この Codelab では、Agent Development Kit(ADK)を使用して実践的なデータ アナリスト エージェントを構築し、データ分析の未来を体験します。まず、基本的なエージェントを作成し、その機能を段階的に強化していきます。まず、アップロードされたドキュメントから非構造化データを分析するようにエージェントをトレーニングします。次に、強力なエンタープライズ グレードのデータ ウェアハウスである Google Cloud BigQuery に接続して、大規模な実際の医療データセットに対してクエリを実行して分析します。
このチュートリアルの最後には、機能する AI アシスタントだけでなく、ルーチン データタスクを自動化し、分析を加速し、ユーザーとチームにとって重要な分析情報へのアクセスを民主化できるエージェントを構築する方法をしっかりと理解できます。
3. Google Cloud サービスを構成する
Google Cloud プロジェクトを作成する
この Codelab の作業を整理し、他のプロジェクトと分離するために、まず新しい Google Cloud プロジェクトを作成します。
プロジェクト作成ページを開くには、[] をクリックします。
プロジェクト作成ページで必要な情報を入力します。
- プロジェクト名: 任意の名前を入力します(
genai-workshopなど)。4 ~ 30 文字で、文字、数字、一重引用符、ハイフン、スペース、感嘆符のみを含めることができます。 - ロケーション: [組織なし] のままにします。
- 請求先アカウント: プロンプトが表示されたら、[Google Cloud Platform トライアル版請求先アカウント](または優先する有効な請求先アカウント)を選択します。このオプションが表示されない場合は、そのまま続行してください。
生成されたプロジェクト ID をコピーしておきます。後で必要になります。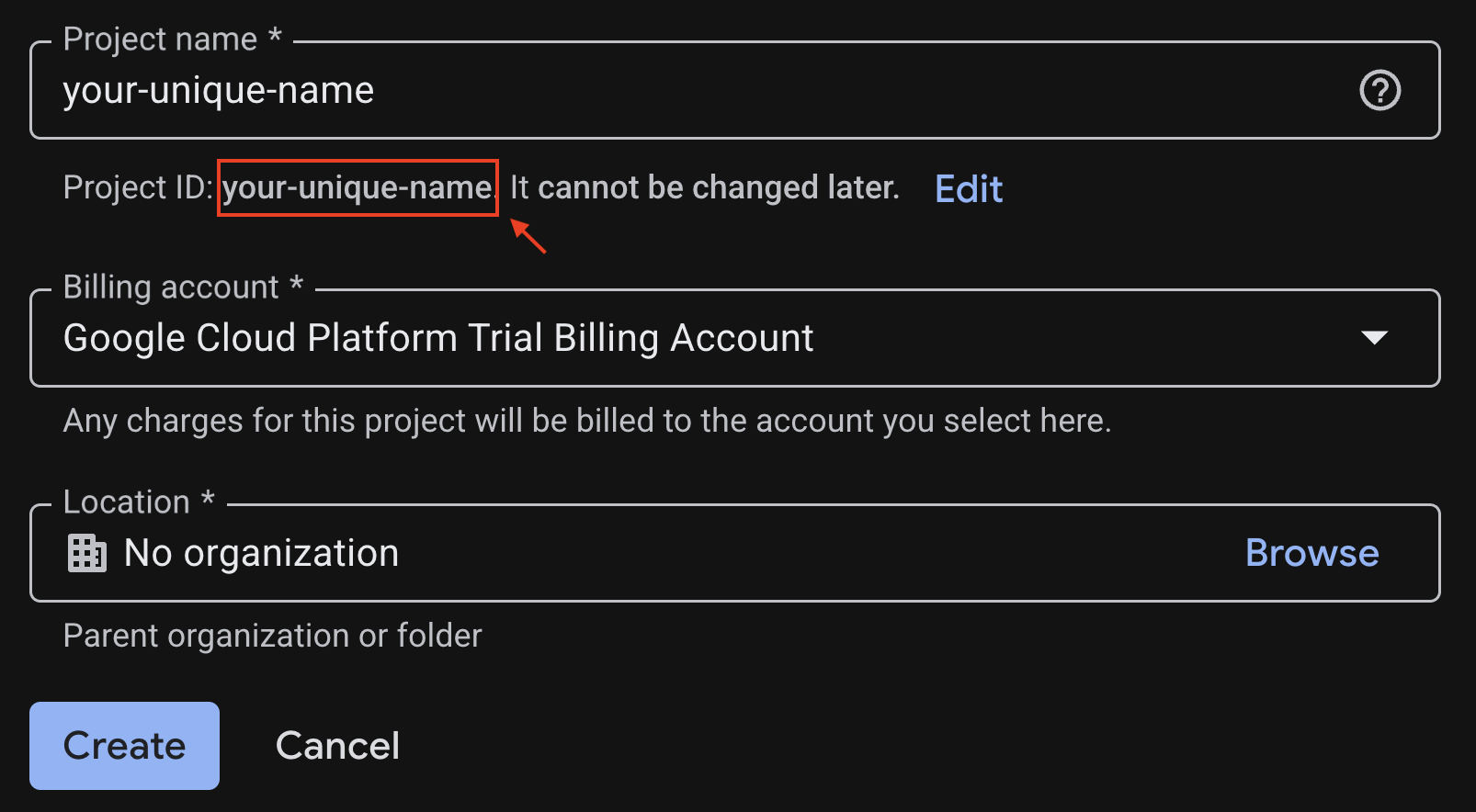
問題がなければ、[作成] ボタンをクリックします。
Cloud Shell を構成する
Cloud Shell は、この Codelab に必要なすべてのツールが事前構成された環境です。プロジェクトが正常に作成されたら、次の手順で Cloud Shell を設定します。
Cloud Shell を起動する
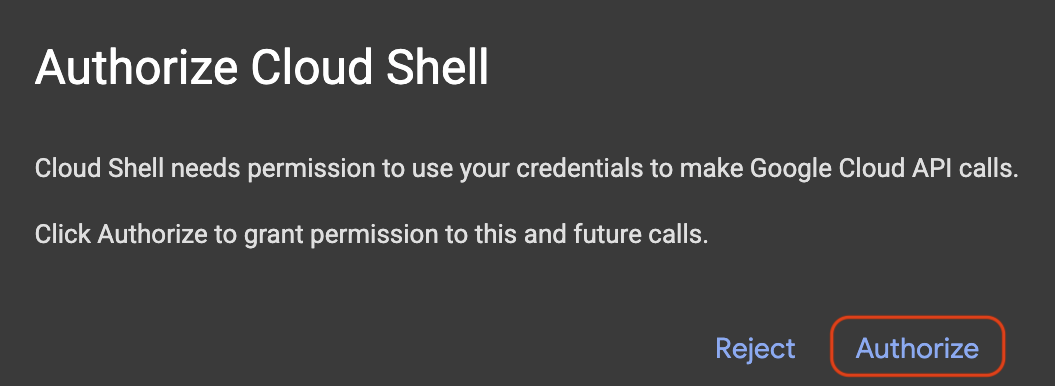
Cloud Shell を起動するには、 [] をクリックします。
承認を求めるポップアップが表示されたら、[承認] をクリックします。
プロジェクト ID を設定する
replace-with-your-project-id は、上記のプロジェクト作成手順で取得した実際のプロジェクト ID に置き換えます。Cloud Shell ターミナルで次のコマンドを実行して、正しいプロジェクト ID を設定します。
gcloud config set project replace-with-your-project-id
Cloud Shell ターミナルで正しいプロジェクトが選択されていることを確認します。選択したプロジェクト ID が黄色でハイライト表示されます。

3. 必要な API を有効にする
Google Cloud サービスを使用するには、まずプロジェクトでそれぞれの API を有効にする必要があります。Cloud Shell ターミナル で次のコマンドを実行して、この Codelab のサービスを有効にします。
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com
オペレーションが成功すると、ターミナルに Operation/... finished successfully というメッセージが表示されます。
4. Python 仮想環境を作成する
次に、プロジェクトの依存関係を管理するための隔離された Python 環境を作成します。
1. プロジェクト ディレクトリを作成して移動します。
mkdir -p ai-agents-adk && cd ai-agents-adk
**2. 仮想環境を作成して有効にします。
uv venv --python 3.12
source .venv/bin/activate
ターミナル プロンプトの先頭に (ai-agents-adk) が表示され、仮想環境が有効になっていることを示します。

3. 既存のキャッシュを削除する
rm -rf ~/.cache
4. adk ページをインストールする
uv pip install google-adk --no-cache
5. フォルダを Cloud Shell ワークスペースとして開く
cd ~
cloudshell workspace ai-agents-adk
5. スターター エージェントを作成する
環境が整ったら、簡単な ADK コマンドを使用して AI エージェントを作成します。
1. エージェントを作成する
ターミナルで、次のコマンドを実行します。
adk create data_analyst_agent
**2. エージェントを設定する
エージェントを構成するように求められます。以下を選択します。
- モデルを選択する: 1 を選択します。
gemini-2.5-flash。 - バックエンドを選択する: 2 を選択します。
Vertex AI。 - Google Cloud プロジェクト ID を入力する: Enter キーを押して正しいプロジェクト ID を確認 します。
- Google Cloud リージョンを入力する: Enter キーを押してデフォルトの
us-central1を使用します。
3. 開発用ウェブサーバーを起動する
エージェントが作成されたら、次のコマンドを実行して開発用ウェブサーバーを起動します。
adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
ターミナルのリンク(http://localhost:8000)を **Ctrl+クリック** または **Cmd+クリック** します。または、
- [**ウェブ プレビュー**] ボタンをクリックします。
- [ポートを変更] を選択します。
- ポート番号 を入力します(例: 8000)。
- [変更してプレビュー] をクリックします。
ブラウザにチャット アプリケーションのような UI が表示されます。
4. エージェントとチャットする
このインターフェースからエージェントとチャットしてみましょう。「こんにちは。何ができますか?」 などと入力します。
6. ドキュメントからデータを分析する
このセクションでは、ドキュメントをエージェントにアップロードし、その内容について質問します。
1. ドキュメントを要約する
次の手順でドキュメントの概要を取得します。
- Google のヘルスケア戦略に関するファイルをダウンロード します。
- エージェントの UI で [ファイルをアップロード] ボタンをクリックし、ダウンロードしたファイルを選択 します。
- チャット インターフェースで、エージェントにファイルの要約を依頼します。「このファイルの概要を教えてください」
- Enter キーを押します。
ドキュメントの内容の簡潔な要約が表示されます。

**2. より詳細な質問をする
次に、より詳細な質問をして、ドキュメントの内容を詳しく調べてみましょう。
- Google が現在 AI とデータ イニシアチブでターゲットとしている主な病気は何ですか?
- Google は、医療データの相互運用性を改善し、データサイロを解消するためにどのような計画を立てていますか?
- Google Cloud は、医療機関や研究者をサポートするためにどのように活用されていますか?
- Google が次に検討している可能性のある新しい疾患分野は何ですか(COPD、がん、メンタルヘルスなど)?
3. さらに質問する
さらに、もっと聞くことで、詳細を調査するためのページ参照番号を調べることもできます。
- 糖尿病関連の情報はどこに記載されていますか?
- 病気に関する関連ページに移動してください。
- 確認すべき興味深いグラフはどこにありますか?
チャレンジ: エージェントに分析させたい独自のドキュメントを見つけてアップロードします。その内容についてエージェントに質問します。
7. ドキュメントの分析情報とライブ ウェブ検索を組み合わせる
エージェントはドキュメントの専門家になりましたが、強力なアナリストは最新の外部情報にもアクセスする必要があります。エージェントにウェブ検索機能を追加しましょう。
- Cloud Shell ターミナルで Ctrl+C キーを押して 、ウェブサーバーを停止します。
- 次のコマンドを実行して、Cloud Shell エディタで
data_analyst_agent/agent.pyファイルを開きます 。
cloudshell edit data_analyst_agent/agent.py
google_searchツールをインポートして追加するようにファイルを変更します 。
from google.adk.agents.llm_agent import Agent
from google.adk.tools import google_search
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction="""
First, check the uploaded files for an answer.
If the information is not in the files, use your tools to search the web.
Answer user questions to the best of your ability.
""",
tools=[
google_search
]
)
- ターミナルで次のコマンドを入力して、ファイルを保存し、ターミナルでウェブサーバーを再起動します 。
adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
- エージェントの UI で、
GoogleHealthStrategy.pdfファイルを再アップロード します。 - ドキュメントのコンテキストと外部情報の両方を必要とする質問をします 。
The document discusses Google's strategy in healthcare. What are three other major tech companies that are also investing heavily in healthcare AI, and what are their primary focus areas?
エージェントは、ドキュメントとライブ Google 検索の両方から情報を合成して、包括的な回答を提供します。いくつかの質問を試してみてください。
- ドキュメントには、糖尿病性網膜症に AI を使用することが記載されています。この分野で FDA の承認を受けた最新のテクノロジーで、過去 1 年間に発表されたものはありますか?
- ファイルにはパートナーシップについて記載されています。Google がヘルスケア分野で最近行ったコラボレーションに関する最新のニュース記事やプレスリリースはありますか?
チャレンジ: 独自のドキュメントに対して同様の質問をしてみてください。ローカル ドキュメントとインターネットの結果を利用するものです。
8. BigQuery で医療データを分析する
個々のドキュメントをアップロードすることはスケーラブルではありません。実際のシナリオでは、データは Google Cloud BigQuery などのエンタープライズ システムに存在します。
現在、エージェント アプリケーションを構築するデベロッパーは、独自のカスタムツールを構築して維持することを余儀なくされています。この手動プロセスは時間がかかり、リスクが高く、大きなオーバーヘッドが生じます。デベロッパーは、イノベーションに集中するのではなく、認証からエラー処理まで、すべてを処理する必要があります。
Agent Development Kit(ADK)には、BigQuery とのやり取りを行うためのファーストパーティ ツールが含まれています。この分析では、メディケアおよびメディケイド サービス センター(CMS) が提供する一般公開のメディケア利用データセット を使用します。
まず、エージェントを大規模な一般公開の医療データセットに接続しましょう。
- Cloud Shell ターミナルで Ctrl+C キーを押して 、ウェブサーバーを停止します。
- ターミナルで次のコマンドを実行して、Cloud Shell エディタで
data_analyst_agent/agent.pyファイルを開きます 。
cloudshell edit data_analyst_agent/agent.py
- ファイルの内容全体を 次のコードに置き換えて、強力な
BigQueryToolsetを構成します。
import google.auth
from google.adk.agents.llm_agent import Agent
from google.adk.tools import google_search
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.bigquery import (
BigQueryToolset,
BigQueryCredentialsConfig
)
from google.adk.tools.bigquery.config import (
BigQueryToolConfig,
WriteMode
)
# Automatically get credentials from the gcloud environment
application_default_credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(
credentials=application_default_credentials
)
# Configure the BigQuery tool
tool_config = BigQueryToolConfig(
write_mode=WriteMode.ALLOWED,
application_name='data_analyst_agent'
)
# Create the toolset with the specified configurations
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config, bigquery_tool_config=tool_config
)
# Create an agent with google search tool as a search specialist
google_search_agent = Agent(
model='gemini-2.5-flash',
name='google_search_agent',
description='A search agent that uses google search to get latest information about current events, weather, or business hours.',
instruction='Use google search to answer user questions about real-time, logistical information.',
tools=[google_search],
)
# Define the final agent with its instructions and tools
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description=(
"Agent to answer questions about BigQuery data and execute SQL queries."
),
instruction="""
You are an expert data analyst agent with access to BigQuery tools.
When a user asks about a dataset, first use your tools to understand its schema.
Then, use this knowledge to construct and execute SQL queries to answer the user's questions.
Always confirm with the user if their question is ambiguous (e.g., for which year?).
""",
tools=[
AgentTool(google_search_agent),
bigquery_toolset
],
)
- ターミナルで次のコマンドを入力して、ファイルを保存し、ターミナルでウェブサーバーを再起動します 。
adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
- これで、エージェントに一般公開のメディケア データセットの分析を依頼できます。まず、データを探索します。
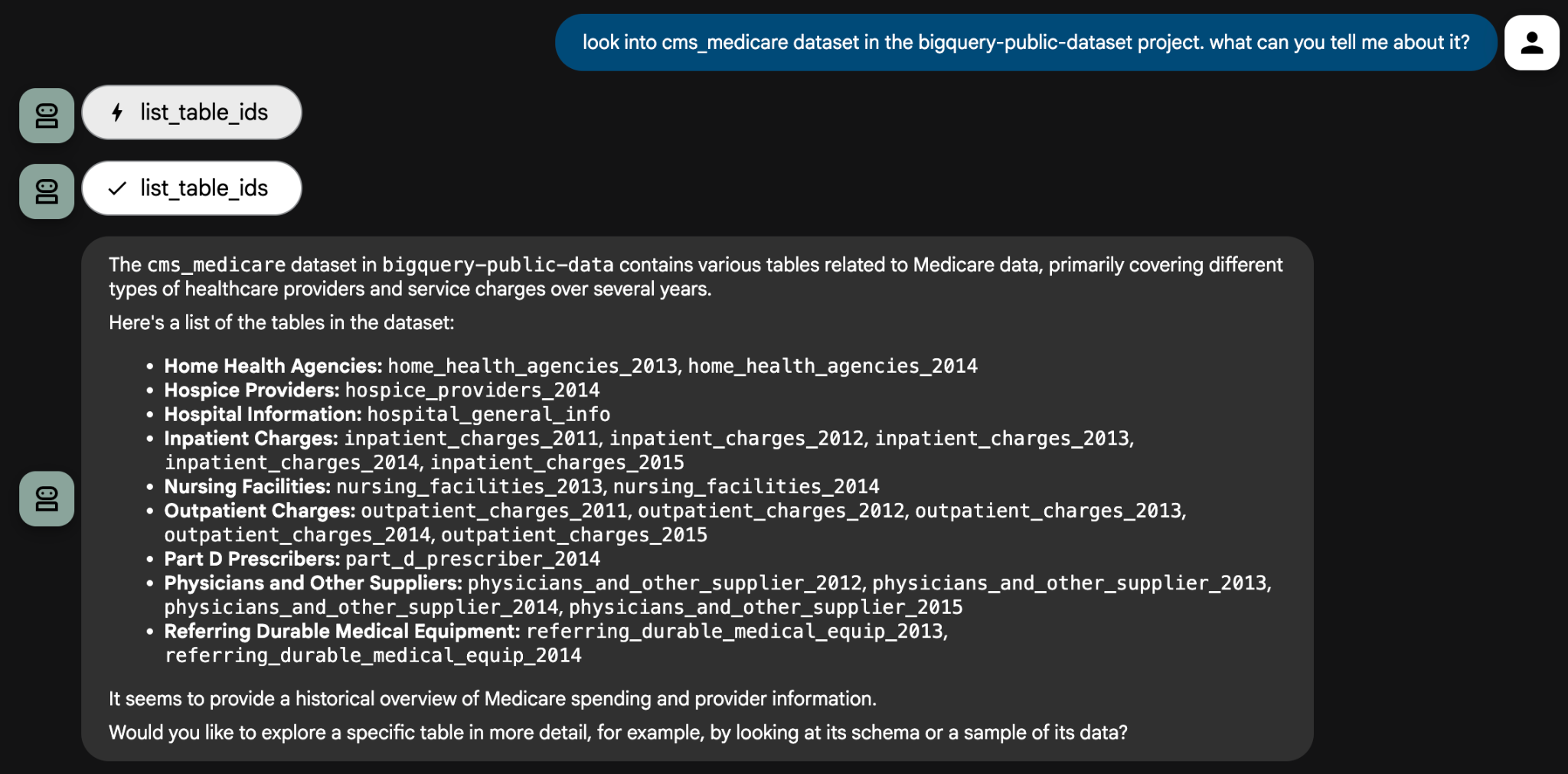
Look into the cms_medicare dataset in the bigquery-public-data project. What can you tell me about it?
エージェントはツールを使用してデータセットを検査し、使用可能なテーブルのリストを提供します。そこから、具体的な分析に関する質問でドリルダウンできます。エージェントは、クエリが正確であることを確認するために、確認のための質問をする場合があります。
一部の質問では、クエリの作成に使用できるように、プロジェクト ID をエージェントに提供する必要があります。次に例を示します。
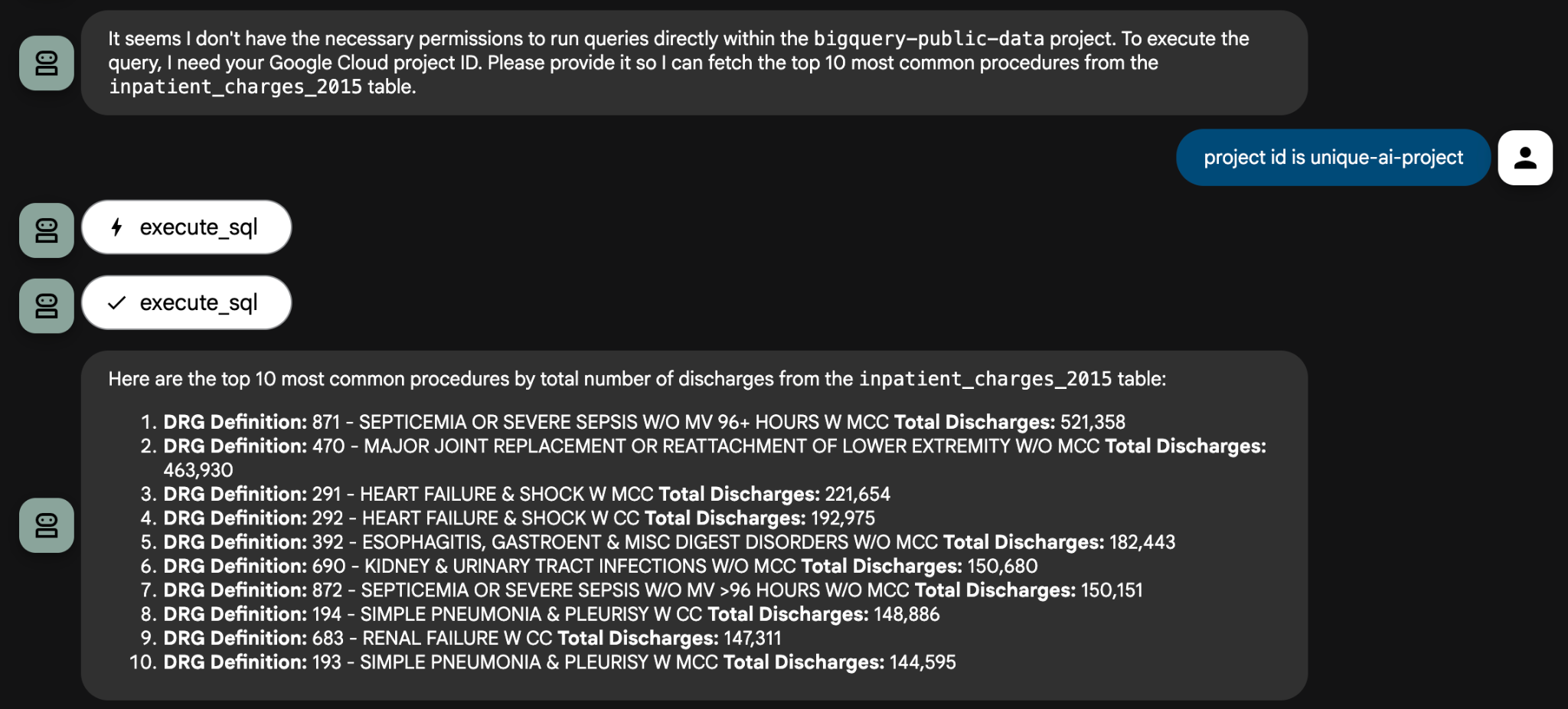
試すことができる分析プロンプトの例を次に示します。
inpatient_charges_2015テーブルを使用して、退院総数で上位 5 つの手順(DRG 定義)は何ですか?- カリフォルニア州(CA)の「MAJOR JOINT REPLACEMENT」 の平均総支払額はいくらですか?
- 同じ手順で、平均対象料金が最も高い州はどこですか?
これでこの Codelab は終了です。エンタープライズ データシステムを搭載したデータ エージェントで実現できることのほんの一部 しか紹介していません。cms_medicare データセットについてご不明な点がございましたら、エージェントにお気軽にお問い合わせください。
チャレンジ: BigQuery で別の 一般公開データセットを見つけて、エージェントを使用して探索します。独自のデータを使用して独自のデータセットを作成し、非公開で分析することもできます。
9. クリーンアップ(オプション)
今後の課金を回避するには、この Codelab で使用したリソースを削除します。
1. エージェントを停止する
Cloud Shell ターミナルで Ctrl+C キーを押して、adk web プロセスを停止します。
**2. プロジェクト ファイルを削除する
Cloud Shell 環境からエージェント コードを削除するには、ターミナルで次のコマンドを実行します。
cd ~ && rm -rf ai-agents-adk
3. API を無効にする
以前に有効にした API を無効にするには、ターミナルで次のコマンドを実行します。
gcloud services disable \
aiplatform.googleapis.com \
bigquery.googleapis.com
4. プロジェクトをシャットダウンする
Google Cloud プロジェクト全体を削除する場合は、プロジェクトのシャットダウン ガイドの手順に沿って操作してください。
10. まとめ
おめでとうございます!Agent Development Kit(ADK)フレームワークを使用して、データ アナリスト エージェントを正常に構築できました。このエージェントは、さまざまなソースからデータを分析し、分析情報を生成し、データ分析ワークフローの一部を自動化できます。
学習を続けるには、次のリソースをご覧ください。
- 公式ブログ投稿: AI エージェント向けの BigQuery ツールセットの発表を読む
- ドキュメントを確認する: 新機能と高度なガイドについては、Agent Development Kit(ADK)の公式ドキュメントをご覧ください。
- コードを参照する: ADK GitHub リポジトリを確認する。
- 詳細なデータを確認する: Google Cloud 一般公開データセット カタログを探索する。