
1. 시작하기 전에
'ADK를 사용한 AI 에이전트 빌드' 시리즈의 네 번째 파트에 오신 것을 환영합니다. 이 실습 Codelab에서는 이전 세션에서 배운 내용을 결합하여 데이터 분석가 에이전트를 만듭니다. 이 에이전트는 데이터를 분석하고, 유용한 인사이트를 생성하고, 데이터 분석 워크플로의 주요 측면을 자동화하도록 설계됩니다.
ADK에 포함된 강력한 도구를 사용하여 업로드된 파일을 탐색하고 Google Cloud BigQuery와 같은 엔터프라이즈급 데이터베이스에 연결할 수 있습니다.
단축 URL(goo.gle/adk-data-analyst)을 통해 이 Codelab에 액세스할 수도 있습니다.
기본 요건
- 생성형 AI 개념에 대한 기본적인 이해
- Python 프로그래밍에 대한 기본적인 숙련도와 명령줄 사용에 대한 편안함
- 이 시리즈의 이전 Codelab인 '기반' 및 '도구로 지원'의 개념에 대한 이해
학습할 내용
- ADK 프레임워크를 사용하여 기능적인 데이터 분석가 에이전트를 빌드하는 방법
- 에이전트가 업로드된 문서의 데이터를 분석할 수 있도록 지원하는 방법
- 엔터프라이즈급 데이터 분석을 위해 에이전트를 BigQuery 데이터베이스에 연결하는 방법
- 목적과 요청 사항을 비롯한 에이전트의 핵심 로직을 정의하는 기법
필요한 항목
- 작동하는 컴퓨터와 안정적인 인터넷 연결
- Google Cloud 콘솔에 액세스하기 위한 브라우저(예: Chrome)
- 호기심과 배우고자 하는 열의
2. 소개
오늘날 데이터 기반 세상에서는 방대한 양의 정보를 빠르고 정확하게 분석하는 능력이 그 어느 때보다 중요합니다. 하지만 의미 있는 통계를 추출하는 과정에는 SQL과 같은 분야의 깊은 기술 전문성이 필요한 경우가 많아 의사 결정을 늦추는 병목 현상이 발생합니다. 이 격차를 해소하고 대화하는 것처럼 복잡한 데이터 세트와 쉽게 상호작용할 수 있다면 어떨까요?
바로 이 지점에서 AI 에이전트가 판도를 바꾸고 있습니다. AI 에이전트는 사용자와 데이터 간의 지능형 인터페이스 역할을 하여 자연어 질문을 이해하고, 이를 기술적 쿼리로 변환하고, 활용 가능한 인사이트를 몇 초 만에 제공할 수 있습니다.
이 Codelab에서는 에이전트 개발 키트 (ADK)를 사용하여 실용적인 데이터 분석가 에이전트를 빌드하여 데이터 분석의 미래를 엿볼 수 있습니다. 기본 에이전트를 만든 다음 기능을 점진적으로 개선합니다. 먼저 업로드된 문서에서 구조화되지 않은 데이터를 분석하도록 에이전트를 가르칩니다. 그런 다음 강력한 엔터프라이즈급 데이터 웨어하우스인 Google Cloud BigQuery에 연결하여 대규모 실제 의료 데이터 세트를 쿼리하고 분석합니다.
이 튜토리얼을 마치면 작동하는 AI 어시스턴트뿐만 아니라 일상적인 데이터 작업을 자동화하고, 분석을 가속화하며, 나와 팀이 중요한 인사이트에 액세스할 수 있도록 지원하는 에이전트를 구축하는 방법을 확실하게 이해하게 됩니다.
3. Google Cloud 서비스 구성
Google Cloud 프로젝트 만들기
이 Codelab의 모든 작업을 정리하고 다른 프로젝트와 분리하기 위해 새 Google Cloud 프로젝트를 만들어 보겠습니다.
프로젝트 생성 페이지에서 필수 정보를 입력합니다.
- 프로젝트 이름: 원하는 이름을 입력합니다(예:
genai-workshop). 4~30자(영문 기준)여야 하며 문자, 숫자, 작은 따옴표, 하이픈, 공백 또는 느낌표만 포함할 수 있습니다. - 위치: 조직 없음으로 설정된 상태로 둡니다.
- 결제 계정: 메시지가 표시되면 Google Cloud Platform 평가판 결제 계정 (또는 원하는 활성 결제 계정)을 선택합니다. 이 옵션이 표시되지 않으면 계속 진행하면 됩니다.
생성된 프로젝트 ID를 복사해 둡니다. 나중에 필요합니다. 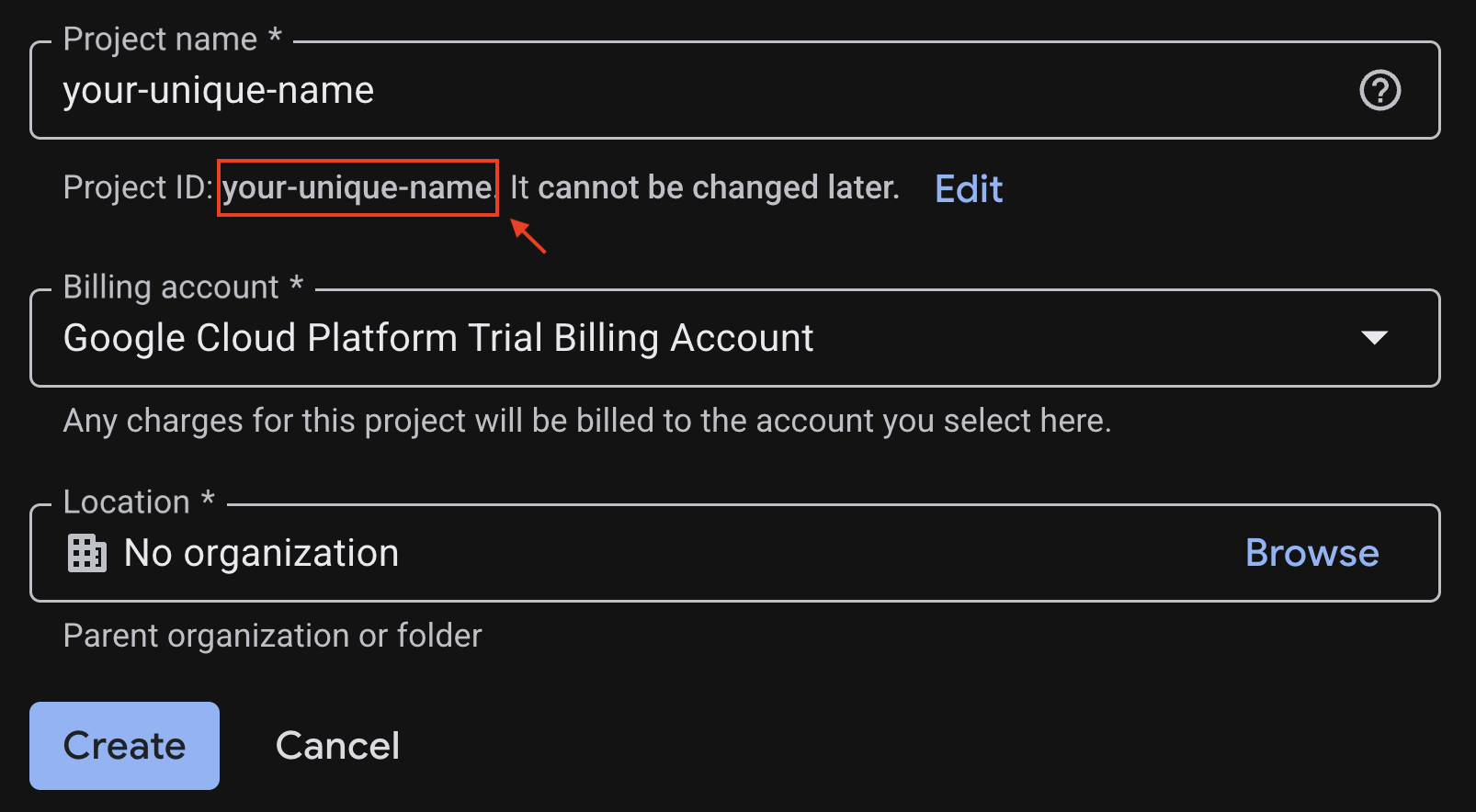
모든 것이 올바르면 만들기 버튼을 클릭합니다.
Cloud Shell 구성
Cloud Shell은 이 Codelab에 필요한 모든 도구가 사전 구성된 환경입니다. 프로젝트가 성공적으로 생성되면 다음 단계에 따라 Cloud Shell을 설정합니다.
Cloud Shell 실행
승인을 요청하는 팝업이 표시되면 승인을 클릭합니다.
프로젝트 ID 설정
replace-with-your-project-id를 위의 프로젝트 생성 단계에서 가져온 실제 프로젝트 ID로 바꿉니다. Cloud Shell 터미널에서 다음 명령어를 실행하여 올바른 프로젝트 ID를 설정합니다.
gcloud config set project replace-with-your-project-id
이제 Cloud Shell 터미널에서 올바른 프로젝트가 선택되어 있는 것을 확인할 수 있습니다. 선택한 프로젝트 ID가 노란색으로 강조 표시됩니다.

3. 필요한 API 사용 설정
Google Cloud 서비스를 사용하려면 먼저 프로젝트에 대해 해당 API를 활성화해야 합니다. Cloud Shell 터미널에서 아래 명령어를 실행하여 이 Codelab의 서비스를 사용 설정합니다.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com
작업이 성공하면 터미널에 Operation/... finished successfully 메시지가 출력됩니다.
4. Python 가상 환경을 만듭니다.
다음으로 격리된 Python 환경을 만들어 프로젝트의 종속 항목을 관리합니다.
1. 프로젝트 디렉터리를 만들고 해당 디렉터리로 이동합니다.
mkdir -p ai-agents-adk && cd ai-agents-adk
2. 가상 환경을 만들고 활성화합니다.
uv venv --python 3.12
source .venv/bin/activate
터미널 프롬프트 앞에 (ai-agents-adk)가 표시되어 가상 환경이 활성 상태임을 나타냅니다.

3. 기존 캐시 삭제
rm -rf ~/.cache
4. ADK 설치 페이지
uv pip install google-adk --no-cache
5. 폴더를 Cloud Shell 작업공간으로 열기
cd ~
cloudshell workspace ai-agents-adk
5. 시작 에이전트 만들기
환경이 준비되면 간단한 ADK 명령어를 사용하여 AI 에이전트를 만들 수 있습니다.
1. 에이전트 만들기
터미널에서 다음 명령어를 실행합니다.
adk create data_analyst_agent
2. 에이전트 구성
에이전트를 구성하라는 메시지가 표시됩니다. 다음과 같이 선택합니다.
- 모델 선택: 1을 선택합니다.
gemini-2.5-flash. - 백엔드 선택: 2를 선택합니다.
Vertex AI. - Google Cloud 프로젝트 ID 입력: Enter 키를 눌러 올바른 프로젝트 ID를 확인합니다.
- Google Cloud 리전 입력: Enter 키를 눌러 기본값인
us-central1을 사용합니다.
3. 개발 웹 서버 시작
에이전트가 생성되면 다음 명령어를 실행하여 개발 웹 서버를 시작합니다.
adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
링크를 Ctrl + 클릭하거나 Cmd + 클릭할 수 있습니다 (예: http://localhost:8000)을 실행하거나
- 웹 미리보기 버튼을 클릭합니다.
- 포트 변경을 선택합니다.
- 포트 번호 (예: 8000)를 입력합니다.
- 변경 및 미리보기를 클릭합니다.
그러면 채팅 애플리케이션과 유사한 UI가 브라우저에 표시됩니다.
4. 상담사와 채팅하기
이 인터페이스를 통해 에이전트와 채팅하세요. '안녕, 뭘 할 수 있어?'와 같이 말합니다.
6. 문서의 데이터 분석
이 섹션에서는 에이전트에 문서를 업로드하고 콘텐츠에 관해 질문합니다.
1. 문서 요약
문서의 요약을 가져오려면 다음 단계를 따르세요.
- Google의 의료 전략에 관한 파일을 다운로드하세요.
- 에이전트 UI에서 파일 업로드 버튼을 클릭하고 방금 다운로드한 파일을 선택합니다.
- 채팅 인터페이스에서 에이전트에게 파일 요약을 요청합니다('이 파일의 요약을 작성해 줘').
- Enter를 누릅니다.
문서 콘텐츠의 간결한 요약을 받게 됩니다.

2. 더 구체적으로 질문하기
이제 더 자세한 질문을 통해 문서에 대해 자세히 알아보세요.
- Google이 현재 AI 및 데이터 이니셔티브를 통해 타겟팅하고 있는 주요 질병은 무엇인가요?
- Google은 의료 데이터 상호 운용성을 개선하고 데이터 사일로를 해소하기 위해 어떤 계획을 세우고 있나요?
- Google Cloud는 의료 비즈니스와 연구자를 지원하기 위해 어떻게 활용되고 있나요?
- Google이 다음에 탐색할 수 있는 새로운 질병 영역은 무엇인가요 (예: COPD, 암, 정신 건강)?
3. 후속 질문하기
추가 조사를 위해 페이지 참조 번호를 확인하는 것과 같은 후속 질문을 할 수도 있습니다.
- 당뇨병 관련 정보는 어디에서 확인하셨나요?
- 질병에 관한 관련 페이지로 안내해 줘.
- 살펴봐야 할 흥미로운 차트는 어디에 있나요?
챌린지: 에이전트가 분석할 자체 문서를 찾아 업로드합니다. 에이전트에게 콘텐츠에 관해 질문합니다.
7. 문서 통계를 실시간 웹 검색과 결합
이제 에이전트는 문서에 관한 전문가가 되었지만 강력한 분석가도 최신 외부 정보에 액세스할 수 있어야 합니다. 에이전트가 웹을 검색할 수 있도록 해 보겠습니다.
- Cloud Shell 터미널에서 Ctrl+C를 눌러 웹 서버를 중지합니다.
- 다음 명령어를 실행하여 Cloud Shell 편집기에서
data_analyst_agent/agent.py파일을 엽니다.
cloudshell edit data_analyst_agent/agent.py
google_search도구를 가져오고 추가하도록 파일을 수정합니다.
from google.adk.agents.llm_agent import Agent
from google.adk.tools import google_search
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction="""
First, check the uploaded files for an answer.
If the information is not in the files, use your tools to search the web.
Answer user questions to the best of your ability.
""",
tools=[
google_search
]
)
- 터미널에 다음 명령어를 입력하여 파일을 저장하고 웹 서버를 다시 시작합니다.
adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
- 에이전트 UI에서
GoogleHealthStrategy.pdf파일을 다시 업로드합니다. - 이제 문서의 컨텍스트와 외부 정보가 모두 필요한 질문을 합니다.
The document discusses Google's strategy in healthcare. What are three other major tech companies that are also investing heavily in healthcare AI, and what are their primary focus areas?
이제 에이전트가 문서와 실시간 Google 검색의 정보를 종합하여 포괄적인 답변을 제공합니다. 다음과 같은 질문을 해 보세요.
- 문서에 당뇨병성 망막증에 AI를 사용하는 것이 언급되어 있습니다. 지난 1년간 발표된 이 분야의 최신 FDA 승인 기술은 무엇인가요?
- 파일에 파트너십이 언급되어 있습니다. Google의 의료 분야 최신 협업에 관한 최근 뉴스 기사나 보도 자료를 찾을 수 있나요?
챌린지: 내 문서에 비슷한 질문을 해 보세요. 로컬 문서와 인터넷 결과를 활용하는 항목
8. BigQuery로 의료 데이터 분석
개별 문서를 업로드하는 것은 확장성이 없습니다. 실제 시나리오에서는 데이터가 Google Cloud BigQuery와 같은 엔터프라이즈 시스템에 상주합니다.
현재 에이전트 애플리케이션을 빌드하는 개발자는 자체 맞춤 도구를 빌드하고 유지관리해야 하는 경우가 많습니다. 이 수동 프로세스는 느리고 위험하며 상당한 오버헤드를 생성합니다. 개발자는 혁신에 집중하는 대신 인증부터 오류 처리까지 모든 것을 처리해야 합니다.
에이전트 개발 키트 (ADK)에는 BigQuery 상호작용을 위한 퍼스트 파티 도구가 포함되어 있습니다. 이 분석에서는 Centers for Medicare & Medicaid Services (CMS)에서 제공하는 공개 Medicare Utilization 데이터 세트를 사용합니다.
먼저 에이전트를 대규모 공공 의료 데이터 세트에 연결해 보겠습니다.
- Cloud Shell 터미널에서 Ctrl+C를 눌러 웹 서버를 중지합니다.
- 터미널에서 다음 명령어를 실행하여 Cloud Shell 편집기에서
data_analyst_agent/agent.py파일을 엽니다.
cloudshell edit data_analyst_agent/agent.py
- 강력한
BigQueryToolset를 구성하려면 다음 코드로 파일의 전체 콘텐츠를 대체하세요.
import google.auth
from google.adk.agents.llm_agent import Agent
from google.adk.tools import google_search
from google.adk.tools.agent_tool import AgentTool
from google.adk.tools.bigquery import (
BigQueryToolset,
BigQueryCredentialsConfig
)
from google.adk.tools.bigquery.config import (
BigQueryToolConfig,
WriteMode
)
# Automatically get credentials from the gcloud environment
application_default_credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(
credentials=application_default_credentials
)
# Configure the BigQuery tool
tool_config = BigQueryToolConfig(
write_mode=WriteMode.ALLOWED,
application_name='data_analyst_agent'
)
# Create the toolset with the specified configurations
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config, bigquery_tool_config=tool_config
)
# Create an agent with google search tool as a search specialist
google_search_agent = Agent(
model='gemini-2.5-flash',
name='google_search_agent',
description='A search agent that uses google search to get latest information about current events, weather, or business hours.',
instruction='Use google search to answer user questions about real-time, logistical information.',
tools=[google_search],
)
# Define the final agent with its instructions and tools
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description=(
"Agent to answer questions about BigQuery data and execute SQL queries."
),
instruction="""
You are an expert data analyst agent with access to BigQuery tools.
When a user asks about a dataset, first use your tools to understand its schema.
Then, use this knowledge to construct and execute SQL queries to answer the user's questions.
Always confirm with the user if their question is ambiguous (e.g., for which year?).
""",
tools=[
AgentTool(google_search_agent),
bigquery_toolset
],
)
- 터미널에 다음 명령어를 입력하여 파일을 저장하고 웹 서버를 다시 시작합니다.
adk web --allow_origins "regex:https://.*\.cloudshell\.dev"
- 이제 에이전트에게 공개 Medicare 데이터 세트를 분석해 달라고 요청할 수 있습니다. 먼저 데이터를 살펴봅니다.
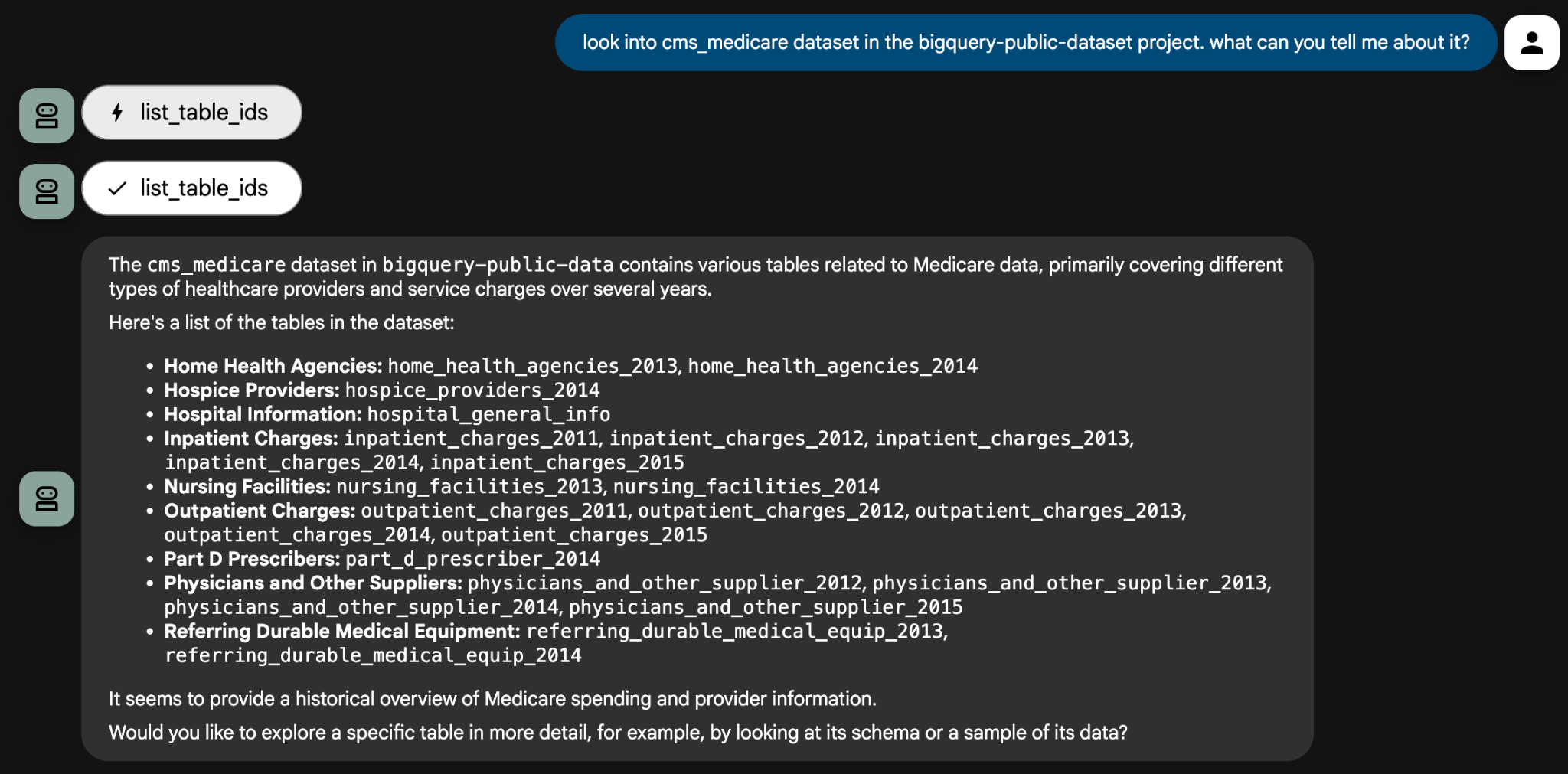
Look into the cms_medicare dataset in the bigquery-public-data project. What can you tell me about it?
에이전트가 도구를 사용하여 데이터 세트를 검사하고 사용 가능한 테이블 목록을 제공합니다. 여기에서 구체적인 분석 질문으로 드릴다운할 수 있습니다. 상담사는 질문이 정확한지 확인하기 위해 명확한 설명을 요구하는 질문을 할 수 있습니다.
일부 질문의 경우 상담사가 쿼리를 만드는 데 사용할 수 있도록 프로젝트 ID를 제공해야 합니다. 예를 들면 다음과 같습니다.
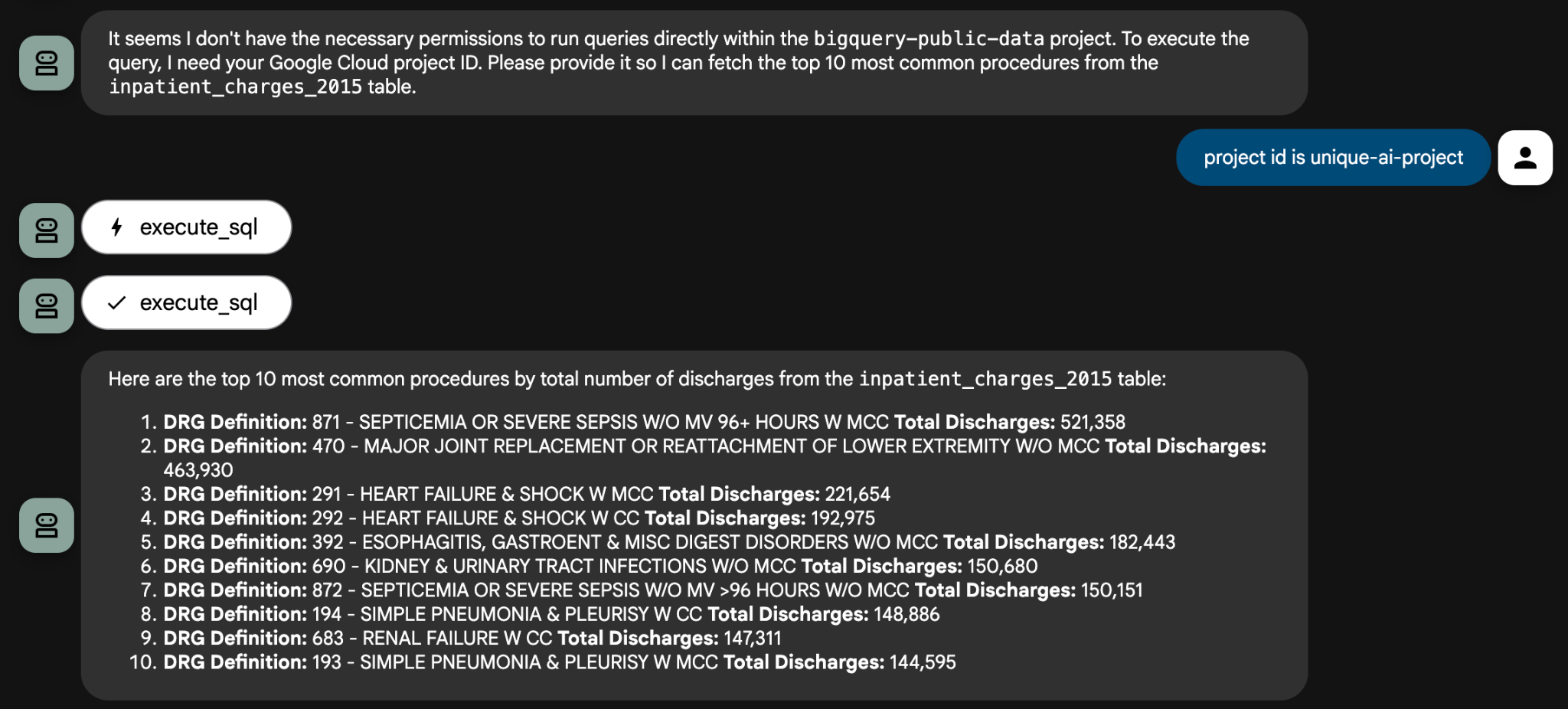
다음은 시도해 볼 수 있는 분석 프롬프트의 예입니다.
inpatient_charges_2015테이블을 사용하여 총 퇴원 수 기준 상위 5개 절차 (DRG 정의)는 무엇인가요?- 캘리포니아 (CA)에서 '주요 관절 치환술'의 평균 총 지급액은 얼마인가요?
- 동일한 시술에 대해 평균 보장 비용이 가장 높은 주는 어디인가요?
이것으로 이 Codelab을 마칩니다. 엔터프라이즈 데이터 시스템으로 구동되는 데이터 에이전트로 달성할 수 있는 것의 일부에 불과합니다. cms_medicare 데이터 세트에 관해 궁금한 점이 있으면 언제든지 상담사에게 문의하세요.
챌린지: BigQuery에서 다른 공개 데이터 세트를 찾아 에이전트를 사용하여 살펴봅니다. 자체 데이터로 데이터 세트를 만들어 비공개로 분석할 수도 있습니다.
9. 삭제(선택사항)
향후 요금이 청구되지 않도록 하려면 이 Codelab에서 사용한 리소스를 삭제하면 됩니다.
1. 에이전트 중지
Cloud Shell 터미널에서 Ctrl+C를 눌러 adk web 프로세스를 중지합니다.
2. 프로젝트 파일 삭제
Cloud Shell 환경에서 에이전트 코드를 삭제하려면 터미널에서 다음을 실행하세요.
cd ~ && rm -rf ai-agents-adk
3. API 사용 중지
이전에 사용 설정한 API를 사용 중지하려면 터미널에서 다음을 실행하세요.
gcloud services disable \
aiplatform.googleapis.com \
bigquery.googleapis.com
4. 프로젝트 종료
전체 Google Cloud 프로젝트를 삭제하려면 프로젝트 종료 가이드를 따르세요.
10. 결론
축하합니다. 에이전트 개발 키트 (ADK) 프레임워크를 사용하여 데이터 분석가 에이전트를 성공적으로 빌드했습니다. 이 에이전트는 다양한 소스의 데이터를 분석하고, 통계를 생성하고, 데이터 분석 워크플로의 일부를 자동화할 수 있습니다.
학습 여정을 계속하려면 다음 리소스를 살펴보세요.
- 공식 블로그 게시물 AI 에이전트를 위한 BigQuery 도구 세트 발표를 읽어보세요.
- 문서 살펴보기: 공식 에이전트 개발 키트 (ADK) 문서에서 새로운 기능과 고급 가이드를 확인하세요.
- 코드 탐색: ADK GitHub 저장소를 확인합니다.
- 더 많은 데이터 살펴보기: Google Cloud 공개 데이터 세트 카탈로그를 살펴보세요.