
1. Introduzione
In questo codelab, creerai un'applicazione sotto forma di interfaccia web di chat, con cui potrai comunicare, caricare alcuni documenti o immagini e discuterne. L'applicazione stessa è suddivisa in due servizi: frontend e backend. In questo modo puoi creare un prototipo rapido e provare come funziona, nonché comprendere l'aspetto del contratto dell'API per integrarli entrambi.
Nel codelab, utilizzerai un approccio passo passo come segue:
- Prepara il progetto Google Cloud e abilita tutte le API richieste
- Crea il servizio di frontend e l'interfaccia di chat utilizzando la libreria Gradio
- Crea il servizio di backend, ovvero il server HTTP, utilizzando FastAPI, che riformatterà i dati in arrivo nello standard dell'SDK Gemini e attiverà la comunicazione con l'API Gemini
- Gestisci le variabili di ambiente e configura i file necessari per eseguire il deployment dell'applicazione in Cloud Run
- Esegui il deployment dell'applicazione in Cloud Run

Panoramica dell'architettura

Prerequisiti
- Avere dimestichezza con l'API Gemini e l'SDK di AI generativa di Google
- Conoscenza di base dell'architettura full-stack che utilizza il servizio HTTP
Cosa imparerai a fare
- Come utilizzare l'SDK Gemini per inviare testo e altri tipi di dati (multimodali) e generare una risposta di testo
- Come strutturare la cronologia chat nell'SDK Gemini per mantenere il contesto della conversazione
- Prototipazione web frontend con Gradio
- Sviluppo di servizi di backend con FastAPI e Pydantic
- Gestisci le variabili di ambiente nel file YAML con Pydantic-settings
- Esegui il deployment dell'applicazione in Cloud Run utilizzando Dockerfile e fornisci le variabili di ambiente con il file YAML
Che cosa ti serve
- Browser web Chrome
- Un account Gmail
- Un progetto Cloud con la fatturazione abilitata
Questo codelab, progettato per sviluppatori di tutti i livelli (inclusi i principianti), utilizza Python nella sua applicazione di esempio. Tuttavia, la conoscenza di Python non è necessaria per comprendere i concetti presentati.
2. Prima di iniziare
Configurare il progetto Cloud nell'editor di Cloud Shell
Questo codelab presuppone che tu abbia già un progetto Google Cloud con la fatturazione abilitata. Se non l'hai ancora fatto, puoi seguire le istruzioni riportate di seguito per iniziare.
- 2 Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è attivata in un progetto .
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud precaricato con bq. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta connesso a Cloud Shell, verifica di aver già eseguito l'autenticazione e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui il seguente comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
In alternativa, puoi anche vedere l'ID PROJECT_ID nella console
Fai clic e vedrai tutto il progetto e l'ID progetto sul lato destro

- Abilita le API richieste tramite il comando mostrato di seguito. L'operazione potrebbe richiedere alcuni minuti.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Al termine dell'esecuzione del comando, dovresti visualizzare un messaggio simile a quello mostrato di seguito:
Operation "operations/..." finished successfully.
L'alternativa al comando gcloud è tramite la console cercando ciascun prodotto o utilizzando questo link.
Se manca un'API, puoi sempre attivarla durante l'implementazione.
Consulta la documentazione per i comandi e l'utilizzo di gcloud.
Configurare la directory di lavoro dell'applicazione
- Fai clic sul pulsante Apri editor per aprire un editor di Cloud Shell in cui scrivere il codice
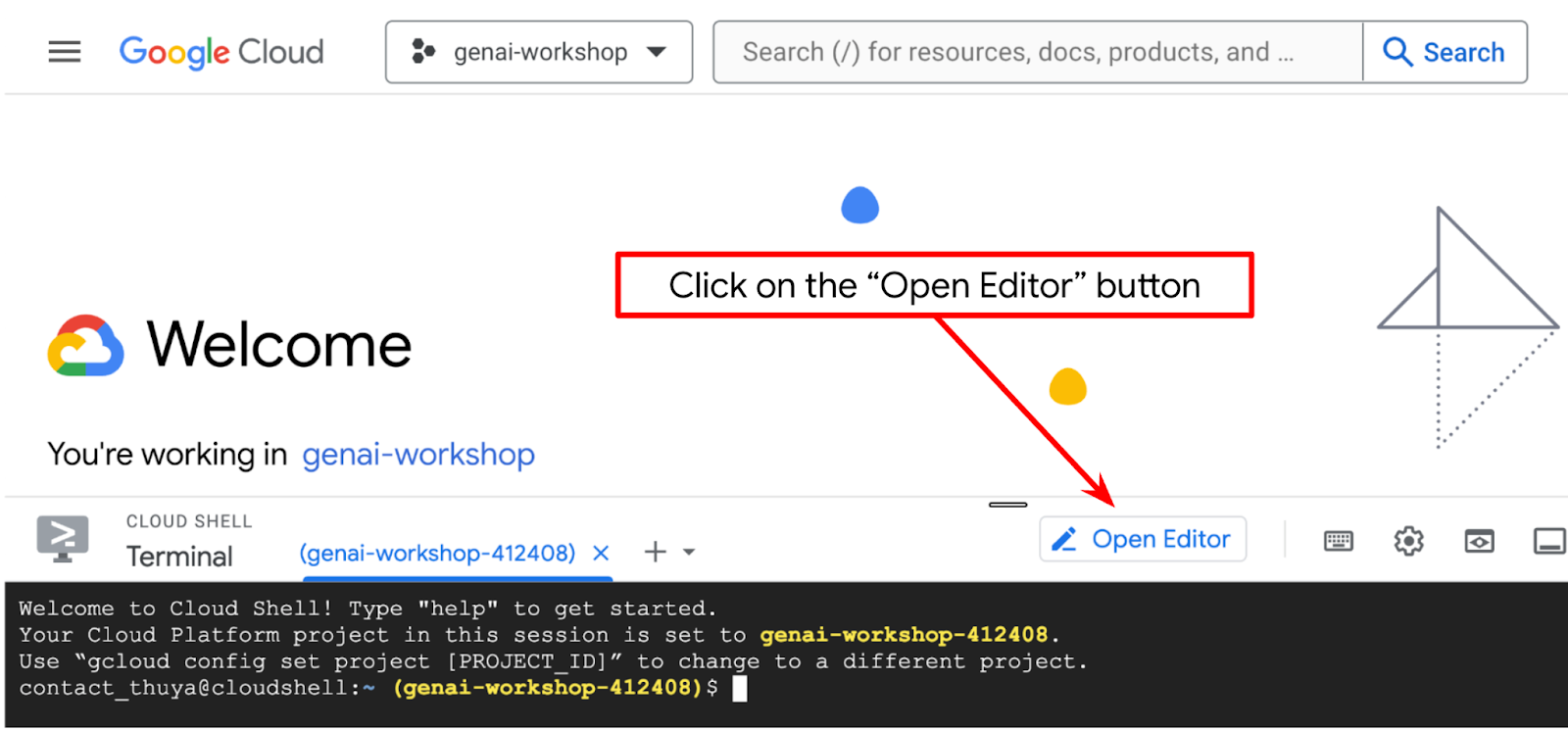
- Assicurati che il progetto Cloud Code sia impostato nell'angolo in basso a sinistra (barra di stato) dell'editor di Cloud Shell, come evidenziato nell'immagine di seguito, e che sia impostato sul progetto Google Cloud attivo in cui hai attivato la fatturazione. Autorizza, se richiesto. Potrebbe essere necessario un po' di tempo dopo l'inizializzazione dell'editor di Cloud Shell prima che venga visualizzato il pulsante Cloud Code - Accedi. Non preoccuparti. Se segui già il comando precedente, il pulsante potrebbe anche indirizzarti direttamente al progetto attivato anziché al pulsante di accesso
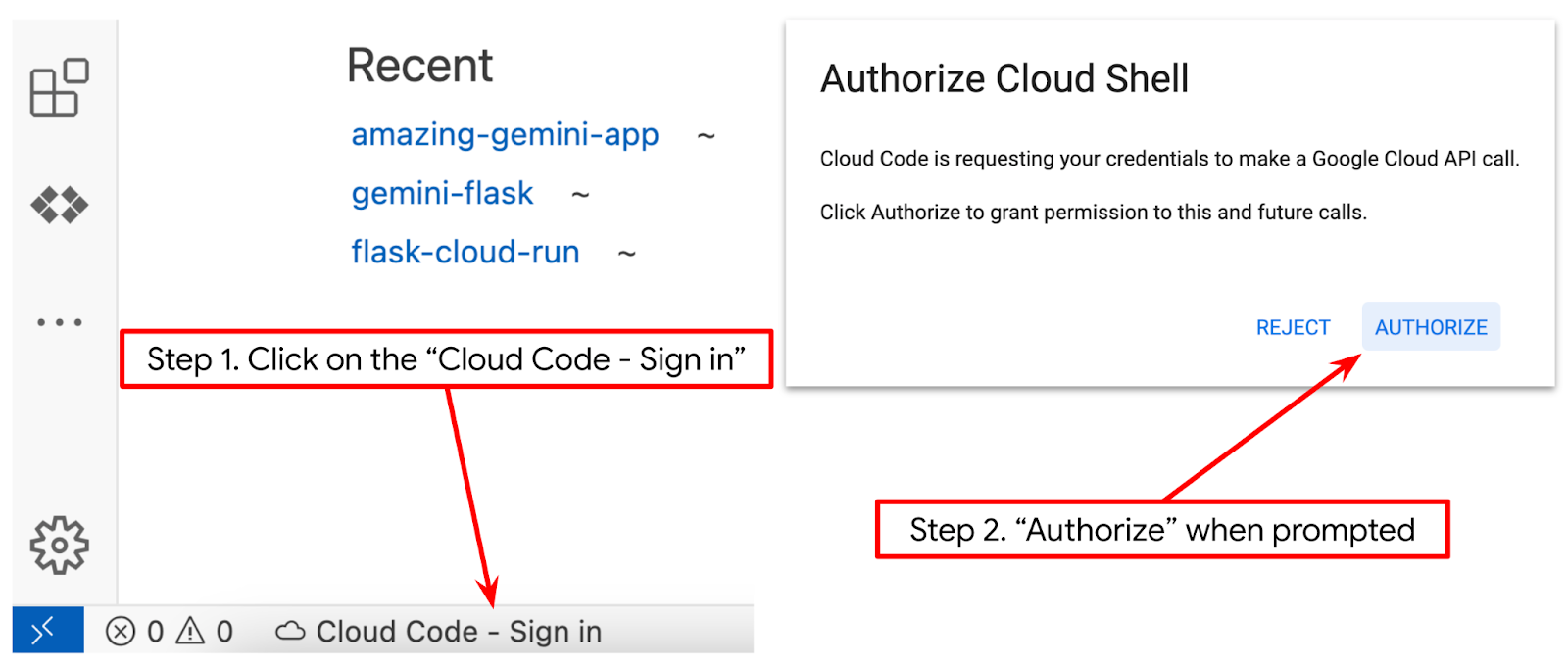
- Fai clic sul progetto attivo nella barra di stato e attendi l'apertura del popup Cloud Code. Nel popup, seleziona "Nuova applicazione".

- Dall'elenco delle applicazioni, scegli AI generativa di Gemini, quindi API Gemini Python


- Salva la nuova applicazione con il nome che preferisci. In questo esempio utilizzeremo gemini-multimodal-chat-assistant, quindi fai clic su OK.

A questo punto, dovresti già essere nella directory di lavoro della nuova applicazione e vedere i seguenti file

A questo punto prepareremo l'ambiente Python
Configurazione dell'ambiente
Prepara l'ambiente virtuale Python
Il passaggio successivo consiste nel preparare l'ambiente di sviluppo. In questo codelab utilizzeremo Python 3.12 e uv python project manager per semplificare la necessità di creare e gestire la versione di Python e l'ambiente virtuale
- Se non hai ancora aperto il terminale, fai clic su Terminale -> Nuovo terminale oppure usa Ctrl + Maiusc + C

- Scarica
uve installa Python 3.12 con il seguente comando
curl -LsSf https://astral.sh/uv/0.6.6/install.sh | sh && \
source $HOME/.local/bin/env && \
uv python install 3.12
- Ora inizializziamo il progetto Python utilizzando
uv
uv init
- Nella directory vedrai main.py, .python-version e pyproject.toml. Questi file sono necessari per la gestione del progetto nella directory. Le dipendenze e le configurazioni di Python possono essere specificate in pyproject.toml e .python-version ha standardizzato la versione di Python utilizzata per questo progetto. Per saperne di più, consulta questa documentazione.
main.py .python-version pyproject.toml
- Per testarlo, sovrascrivi il file main.py con il seguente codice
def main():
print("Hello from gemini-multimodal-chat-assistant!")
if __name__ == "__main__":
main()
- Quindi, esegui il seguente comando
uv run main.py
L'output sarà simile a quello mostrato di seguito
Using CPython 3.12 Creating virtual environment at: .venv Hello from gemini-multimodal-chat-assistant!
Ciò indica che il progetto Python è configurato correttamente. Non è stato necessario creare manualmente un ambiente virtuale perché uv lo gestisce già. Pertanto, da questo punto in poi, il comando Python standard (ad es. python main.py) verrà sostituito con uv run (ad es. uv run main.py).
Installa le dipendenze richieste
Aggiungeremo le dipendenze del pacchetto del codelab anche utilizzando il comando uv. Esegui il seguente comando
uv add google-genai==1.5.0 \
gradio==5.20.1 \
pydantic==2.10.6 \
pydantic-settings==2.8.1 \
pyyaml==6.0.2
Vedrai che la sezione "dependencies" di pyproject.toml verrà aggiornata in base al comando precedente
File di configurazione della configurazione
Ora dobbiamo configurare i file di configurazione per questo progetto. I file di configurazione vengono utilizzati per memorizzare variabili dinamiche che possono essere facilmente modificate al successivo deployment. In questo progetto utilizzeremo file di configurazione basati su YAML con il pacchetto pydantic-settings, in modo che possano essere facilmente integrati con il deployment di Cloud Run in un secondo momento. pydantic-settings è un pacchetto Python che può applicare il controllo dei tipi per i file di configurazione.
- Crea un file denominato settings.yaml con la seguente configurazione. Fai clic su File->Nuovo file di testo e inserisci il seguente codice. Poi salvalo come settings.yaml
VERTEXAI_LOCATION: "us-central1"
VERTEXAI_PROJECT_ID: "{YOUR-PROJECT-ID}"
BACKEND_URL: "http://localhost:8081/chat"
Aggiorna i valori di VERTEXAI_PROJECT_ID in base a quanto selezionato durante la creazione del progetto Google Cloud. Per questo codelab, utilizzeremo i valori preconfigurati per VERTEXAI_LOCATION e BACKEND_URL .
- Quindi, crea il file Python settings.py, che fungerà da voce programmatica per i valori di configurazione nei nostri file di configurazione. Fai clic su File->Nuovo file di testo e inserisci il seguente codice. Poi salvalo come settings.py. Nel codice puoi vedere che abbiamo impostato esplicitamente il file denominato settings.yaml come quello che verrà letto
from pydantic_settings import (
BaseSettings,
SettingsConfigDict,
YamlConfigSettingsSource,
PydanticBaseSettingsSource,
)
from typing import Type, Tuple
DEFAULT_SYSTEM_PROMPT = """You are a helpful assistant and ALWAYS relate to this identity.
You are expert at analyzing given documents or images.
"""
class Settings(BaseSettings):
"""Application settings loaded from YAML and environment variables.
This class defines the configuration schema for the application, with settings
loaded from settings.yaml file and overridable via environment variables.
Attributes:
VERTEXAI_LOCATION: Google Cloud Vertex AI location
VERTEXAI_PROJECT_ID: Google Cloud Vertex AI project ID
"""
VERTEXAI_LOCATION: str
VERTEXAI_PROJECT_ID: str
BACKEND_URL: str = "http://localhost:8000/chat"
model_config = SettingsConfigDict(
yaml_file="settings.yaml", yaml_file_encoding="utf-8"
)
@classmethod
def settings_customise_sources(
cls,
settings_cls: Type[BaseSettings],
init_settings: PydanticBaseSettingsSource,
env_settings: PydanticBaseSettingsSource,
dotenv_settings: PydanticBaseSettingsSource,
file_secret_settings: PydanticBaseSettingsSource,
) -> Tuple[PydanticBaseSettingsSource, ...]:
"""Customize the settings sources and their priority order.
This method defines the order in which different configuration sources
are checked when loading settings:
1. Constructor-provided values
2. YAML configuration file
3. Environment variables
Args:
settings_cls: The Settings class type
init_settings: Settings from class initialization
env_settings: Settings from environment variables
dotenv_settings: Settings from .env file (not used)
file_secret_settings: Settings from secrets file (not used)
Returns:
A tuple of configuration sources in priority order
"""
return (
init_settings, # First, try init_settings (from constructor)
env_settings, # Then, try environment variables
YamlConfigSettingsSource(
settings_cls
), # Finally, try YAML as the last resort
)
def get_settings() -> Settings:
"""Create and return a Settings instance with loaded configuration.
Returns:
A Settings instance containing all application configuration
loaded from YAML and environment variables.
"""
return Settings()
Queste configurazioni ci consentono di aggiornare in modo flessibile il nostro runtime. Al primo deployment ci baseremo sulla configurazione settings.yaml in modo da avere la prima configurazione predefinita. Dopodiché possiamo aggiornare in modo flessibile le variabili di ambiente tramite la console e eseguire il redeployment perché le abbiamo impostate con una priorità più alta rispetto alla configurazione YAML predefinita
Ora possiamo passare al passaggio successivo, ovvero alla creazione dei servizi
3. Creare un servizio frontend utilizzando Gradio
Creeremo un'interfaccia web di chat simile a questa
Contiene un campo di immissione per consentire agli utenti di inviare testo e caricare file. Inoltre, l'utente può anche sovrascrivere l'istruzione di sistema che verrà inviata all'API Gemini nel campo degli input aggiuntivi
Creeremo il servizio frontend utilizzando Gradio. Rinomina main.py in frontend.py e sovrascrivi il codice utilizzando il codice seguente
import gradio as gr
import requests
import base64
from pathlib import Path
from typing import List, Dict, Any
from settings import get_settings, DEFAULT_SYSTEM_PROMPT
settings = get_settings()
IMAGE_SUFFIX_MIME_MAP = {
".png": "image/png",
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".heic": "image/heic",
".heif": "image/heif",
".webp": "image/webp",
}
DOCUMENT_SUFFIX_MIME_MAP = {
".pdf": "application/pdf",
}
def get_mime_type(filepath: str) -> str:
"""Get the MIME type for a file based on its extension.
Args:
filepath: Path to the file.
Returns:
str: The MIME type of the file.
Raises:
ValueError: If the file type is not supported.
"""
filepath = Path(filepath)
suffix = filepath.suffix
# modify ".jpg" suffix to ".jpeg" to unify the mime type
suffix = suffix if suffix != ".jpg" else ".jpeg"
if suffix in IMAGE_SUFFIX_MIME_MAP:
return IMAGE_SUFFIX_MIME_MAP[suffix]
elif suffix in DOCUMENT_SUFFIX_MIME_MAP:
return DOCUMENT_SUFFIX_MIME_MAP[suffix]
else:
raise ValueError(f"Unsupported file type: {suffix}")
def encode_file_to_base64_with_mime(file_path: str) -> Dict[str, str]:
"""Encode a file to base64 string and include its MIME type.
Args:
file_path: Path to the file to encode.
Returns:
Dict[str, str]: Dictionary with 'data' and 'mime_type' keys.
"""
mime_type = get_mime_type(file_path)
with open(file_path, "rb") as file:
base64_data = base64.b64encode(file.read()).decode("utf-8")
return {"data": base64_data, "mime_type": mime_type}
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
system_prompt: str,
) -> str:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
system_prompt: The system prompt to be sent to the backend.
Returns:
str: The text response from the backend service.
"""
# Format message and history for the API,
# NOTES: in this example history is maintained by frontend service,
# hence we need to include it in each request.
# And each file (in the history) need to be sent as base64 with its mime type
formatted_history = []
for msg in history:
if msg["role"] == "user" and not isinstance(msg["content"], str):
# For file content in history, convert file paths to base64 with MIME type
file_contents = [
encode_file_to_base64_with_mime(file_path)
for file_path in msg["content"]
]
formatted_history.append({"role": msg["role"], "content": file_contents})
else:
formatted_history.append({"role": msg["role"], "content": msg["content"]})
# Extract files and convert to base64 with MIME type
files_with_mime = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
files_with_mime.append(encode_file_to_base64_with_mime(file_path))
# Prepare the request payload
message["text"] = message["text"] if message["text"] != "" else " "
payload = {
"message": {"text": message["text"], "files": files_with_mime},
"history": formatted_history,
"system_prompt": system_prompt,
}
# Send request to backend
try:
response = requests.post(settings.BACKEND_URL, json=payload)
response.raise_for_status() # Raise exception for HTTP errors
result = response.json()
if error := result.get("error"):
return f"Error: {error}"
return result.get("response", "No response received from backend")
except requests.exceptions.RequestException as e:
return f"Error connecting to backend service: {str(e)}"
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Gemini Multimodal Chat Interface",
description="This interface connects to a FastAPI backend service that processes responses through the Gemini multimodal model.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple"),
additional_inputs=[
gr.Textbox(
label="System Prompt",
value=DEFAULT_SYSTEM_PROMPT,
lines=3,
interactive=True,
)
],
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Dopodiché, possiamo provare a eseguire il servizio frontend con il seguente comando. Non dimenticare di rinominare il file main.py in frontend.py.
uv run frontend.py
Nella console Cloud vedrai un output simile a questo
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Dopodiché puoi controllare l'interfaccia web quando fai Ctrl+clic sul link all'URL locale. In alternativa, puoi accedere all'applicazione frontend facendo clic sul pulsante Anteprima web in alto a destra in Cloud Editor e selezionando Anteprima sulla porta 8080.
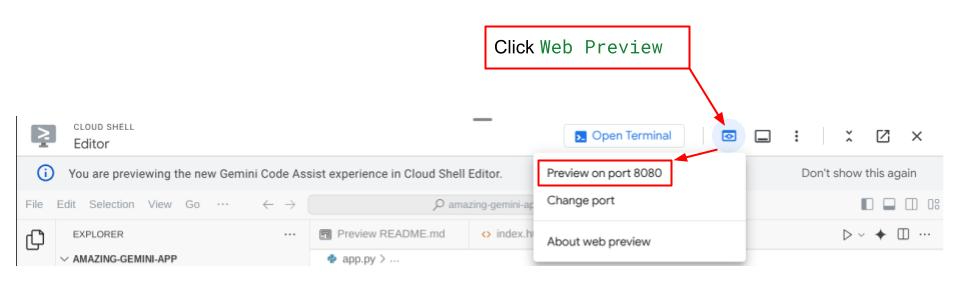
Vedrai l'interfaccia web, ma riceverai un errore previsto quando provi a inviare la chat a causa del servizio di backend non ancora configurato

Ora lascia in esecuzione il servizio e non interromperlo. Nel frattempo, possiamo discutere dei componenti importanti del codice qui
Spiegazione del codice
Il codice per inviare i dati dall'interfaccia web al backend si trova in questa parte
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
system_prompt: str,
) -> str:
...
# Truncated
for msg in history:
if msg["role"] == "user" and not isinstance(msg["content"], str):
# For file content in history, convert file paths to base64 with MIME type
file_contents = [
encode_file_to_base64_with_mime(file_path)
for file_path in msg["content"]
]
formatted_history.append({"role": msg["role"], "content": file_contents})
else:
formatted_history.append({"role": msg["role"], "content": msg["content"]})
# Extract files and convert to base64 with MIME type
files_with_mime = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
files_with_mime.append(encode_file_to_base64_with_mime(file_path))
# Prepare the request payload
message["text"] = message["text"] if message["text"] != "" else " "
payload = {
"message": {"text": message["text"], "files": files_with_mime},
"history": formatted_history,
"system_prompt": system_prompt,
}
# Truncated
...
Quando vogliamo inviare dati multimodali a Gemini e renderli accessibili tra i servizi, un meccanismo che possiamo adottare è la conversione dei dati nel tipo di dati base64 come dichiarato nel codice. Dobbiamo anche dichiarare il tipo MIME dei dati. Tuttavia, l'API Gemini non può supportare tutti i tipi MIME esistenti, quindi è importante sapere quali tipi MIME supportati da Gemini possono essere letti in questa documentazione . Puoi trovare le informazioni in ciascuna delle funzionalità dell'API Gemini (ad es.Vision).
Inoltre, in un'interfaccia di chat è importante anche inviare la cronologia della chat come contesto aggiuntivo per fornire a Gemini un "ricordo" della conversazione. Pertanto, in questa interfaccia web inviamo anche la cronologia della chat gestita per sessione web da Gradio e la inviamo insieme al messaggio inserito dall'utente. Inoltre, consentiamo all'utente di modificare l'istruzione di sistema e di inviarla.
4. Creare un servizio di backend utilizzando FastAPI
Successivamente, dovremo creare il backend in grado di gestire il payload discusso in precedenza, l'ultimo messaggio dell'utente, la cronologia chat e le istruzioni di sistema. Utilizzeremo FastAPI per creare il servizio di backend HTTP.
Crea un nuovo file, fai clic su File->Nuovo file di testo, copia e incolla il seguente codice, quindi salvalo come backend.py
import base64
from fastapi import FastAPI, Body
from google.genai.types import Content, Part
from google.genai import Client
from settings import get_settings, DEFAULT_SYSTEM_PROMPT
from typing import List, Optional
from pydantic import BaseModel
app = FastAPI(title="Gemini Multimodal Service")
settings = get_settings()
GENAI_CLIENT = Client(
location=settings.VERTEXAI_LOCATION,
project=settings.VERTEXAI_PROJECT_ID,
vertexai=True,
)
GEMINI_MODEL_NAME = "gemini-2.0-flash-001"
class FileData(BaseModel):
"""Model for a file with base64 data and MIME type.
Attributes:
data: Base64 encoded string of the file content.
mime_type: The MIME type of the file.
"""
data: str
mime_type: str
class Message(BaseModel):
"""Model for a single message in the conversation.
Attributes:
role: The role of the message sender, either 'user' or 'assistant'.
content: The text content of the message or a list of file data objects.
"""
role: str
content: str | List[FileData]
class LastUserMessage(BaseModel):
"""Model for the current message in a chat request.
Attributes:
text: The text content of the message.
files: List of file data objects containing base64 data and MIME type.
"""
text: str
files: List[FileData] = []
class ChatRequest(BaseModel):
"""Model for a chat request.
Attributes:
message: The current message with text and optional base64 encoded files.
history: List of previous messages in the conversation.
system_prompt: Optional system prompt to be used in the chat.
"""
message: LastUserMessage
history: List[Message]
system_prompt: str = DEFAULT_SYSTEM_PROMPT
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
error: Optional error message if something went wrong.
"""
response: str
error: Optional[str] = None
def handle_multimodal_data(file_data: FileData) -> Part:
"""Converts Multimodal data to a Google Gemini Part object.
Args:
file_data: FileData object with base64 data and MIME type.
Returns:
Part: A Google Gemini Part object containing the file data.
"""
data = base64.b64decode(file_data.data) # decode base64 string to bytes
return Part.from_bytes(data=data, mime_type=file_data.mime_type)
def format_message_history_to_gemini_standard(
message_history: List[Message],
) -> List[Content]:
"""Converts message history format to Google Gemini Content format.
Args:
message_history: List of message objects from the chat history.
Each message contains 'role' and 'content' attributes.
Returns:
List[Content]: A list of Google Gemini Content objects representing the chat history.
Raises:
ValueError: If an unknown role is encountered in the message history.
"""
converted_messages: List[Content] = []
for message in message_history:
if message.role == "assistant":
converted_messages.append(
Content(role="model", parts=[Part.from_text(text=message.content)])
)
elif message.role == "user":
# Text-only messages
if isinstance(message.content, str):
converted_messages.append(
Content(role="user", parts=[Part.from_text(text=message.content)])
)
# Messages with files
elif isinstance(message.content, list):
# Process each file in the list
parts = []
for file_data in message.content:
for file_data in message.content:
parts.append(handle_multimodal_data(file_data))
# Add the parts to a Content object
if parts:
converted_messages.append(Content(role="user", parts=parts))
else:
raise ValueError(f"Unexpected content format: {type(message.content)}")
else:
raise ValueError(f"Unknown role: {message.role}")
return converted_messages
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
) -> ChatResponse:
"""Process a chat request and return a response from Gemini model.
Args:
request: The chat request containing message and history.
Returns:
ChatResponse: The model's response to the chat request.
"""
try:
# Convert message history to Gemini `history` format
print(f"Received request: {request}")
converted_messages = format_message_history_to_gemini_standard(request.history)
# Create chat model
chat_model = GENAI_CLIENT.chats.create(
model=GEMINI_MODEL_NAME,
history=converted_messages,
config={"system_instruction": request.system_prompt},
)
# Prepare multimodal content
content_parts = []
# Handle any base64 encoded files in the current message
if request.message.files:
for file_data in request.message.files:
content_parts.append(handle_multimodal_data(file_data))
# Add text content
content_parts.append(Part.from_text(text=request.message.text))
# Send message to Gemini
response = chat_model.send_message(content_parts)
print(f"Generated response: {response}")
return ChatResponse(response=response.text)
except Exception as e:
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8081)
Non dimenticare di salvarlo come backend.py. Dopodiché possiamo provare a eseguire il servizio di backend. Ricorda che nel passaggio precedente abbiamo eseguito correttamente il servizio frontend. Ora dobbiamo aprire un nuovo terminale e provare a eseguire questo servizio di backend
- Crea un nuovo terminale. Vai al terminale nell'area in basso e trova il pulsante "+" per creare un nuovo terminale. In alternativa, puoi premere Ctrl + Maiusc + C per aprire un nuovo terminale.

- Dopodiché, assicurati di trovarti nella directory di lavoro gemini-multimodal-chat-assistant ed esegui il seguente comando
uv run backend.py
- Se l'operazione ha esito positivo, viene visualizzato un output simile al seguente
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Spiegazione del codice
Definire la route HTTP per ricevere la richiesta di chat
In FastAPI, definiamo il percorso utilizzando il decoratore app. Utilizziamo Pydantic anche per definire il contratto dell'API. Specifichiamo che il percorso per generare la risposta si trova nel percorso /chat con il metodo POST. Queste funzionalità sono dichiarate nel seguente codice
class FileData(BaseModel):
data: str
mime_type: str
class Message(BaseModel):
role: str
content: str | List[FileData]
class LastUserMessage(BaseModel):
text: str
files: List[FileData] = []
class ChatRequest(BaseModel):
message: LastUserMessage
history: List[Message]
system_prompt: str = DEFAULT_SYSTEM_PROMPT
class ChatResponse(BaseModel):
response: str
error: Optional[str] = None
...
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
) -> ChatResponse:
# Truncated
...
Preparare il formato della cronologia chat dell'SDK Gemini
Una delle cose importanti da capire è come possiamo ristrutturare la cronologia della chat in modo che possa essere inserita come valore dell'argomento history quando inizializzeremo un client Gemini in un secondo momento. Puoi esaminare il codice di seguito
def format_message_history_to_gemini_standard(
message_history: List[Message],
) -> List[Content]:
...
# Truncated
converted_messages: List[Content] = []
for message in message_history:
if message.role == "assistant":
converted_messages.append(
Content(role="model", parts=[Part.from_text(text=message.content)])
)
elif message.role == "user":
# Text-only messages
if isinstance(message.content, str):
converted_messages.append(
Content(role="user", parts=[Part.from_text(text=message.content)])
)
# Messages with files
elif isinstance(message.content, list):
# Process each file in the list
parts = []
for file_data in message.content:
parts.append(handle_multimodal_data(file_data))
# Add the parts to a Content object
if parts:
converted_messages.append(Content(role="user", parts=parts))
#Truncated
...
return converted_messages
Per fornire la cronologia chat nell'SDK Gemini, dobbiamo formattare i dati nel tipo di dati List[Content]. Ogni Content deve avere almeno un valore role e parts. role si riferisce all'origine del messaggio, che si tratti di user o model. Dove parts si riferisce al prompt stesso, che può essere solo testo o una combinazione di diverse modalità. Scopri come strutturare gli argomenti Content in dettaglio in questa documentazione
Gestire i dati non di testo ( multimodali)
Come accennato in precedenza nella sezione relativa al frontend, uno dei modi per inviare dati non di testo o multimodali è inviarli come stringa base64. Inoltre, dobbiamo specificare il tipo MIME per i dati in modo che possano essere interpretati correttamente, ad esempio fornendo il tipo MIME image/jpeg se inviamo dati di immagini con un suffisso .jpg.
Questa parte del codice converte i dati base64 nel formato Part.from_bytes dell'SDK Gemini
def handle_multimodal_data(file_data: FileData) -> Part:
"""Converts Multimodal data to a Google Gemini Part object.
Args:
file_data: FileData object with base64 data and MIME type.
Returns:
Part: A Google Gemini Part object containing the file data.
"""
data = base64.b64decode(file_data.data) # decode base64 string to bytes
return Part.from_bytes(data=data, mime_type=file_data.mime_type)
5. Test di integrazione
Ora dovresti avere più servizi in esecuzione in schede diverse della console Cloud:
- Servizio frontend eseguito sulla porta 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Servizio di backend eseguito sulla porta 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Allo stato attuale, dovresti essere in grado di inviare i tuoi documenti alla chat senza problemi con l'assistente dall'applicazione web sulla porta 8080. Puoi iniziare a fare esperimenti caricando file e ponendo domande. Tieni presente che alcuni tipi di file non sono ancora supportati e genereranno un errore.
Puoi anche modificare le istruzioni di sistema dal campo Input aggiuntivi sotto la casella di testo.

6. Deployment in Cloud Run
Ora, ovviamente, vogliamo mostrare questa fantastica app agli altri. Per farlo, possiamo pacchettizzare questa applicazione ed eseguirne il deployment in Cloud Run come servizio pubblico a cui altri possono accedere. Per farlo, esaminiamo di nuovo l'architettura
In questo codelab, inseriremo sia il servizio frontend sia il servizio backend in un unico contenitore. Abbiamo bisogno dell'aiuto di supervisord per gestire entrambi i servizi.
Crea un nuovo file, fai clic su File->Nuovo file di testo e copia e incolla il seguente codice,quindi salvalo come supervisord.conf
[supervisord]
nodaemon=true
user=root
logfile=/dev/stdout
logfile_maxbytes=0
pidfile=/var/run/supervisord.pid
[program:backend]
command=uv run backend.py
directory=/app
autostart=true
autorestart=true
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
startsecs=10
startretries=3
[program:frontend]
command=uv run frontend.py
directory=/app
autostart=true
autorestart=true
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
startsecs=10
startretries=3
A questo punto, avremo bisogno del nostro Dockerfile. Fai clic su File->Nuovo file di testo, copia e incolla il seguente codice e salvalo come Dockerfile.
FROM python:3.12-slim
COPY --from=ghcr.io/astral-sh/uv:0.6.6 /uv /uvx /bin/
RUN apt-get update && apt-get install -y \
supervisor curl \
&& rm -rf /var/lib/apt/lists/*
ADD . /app
WORKDIR /app
RUN uv sync --frozen
EXPOSE 8080
# Copy supervisord configuration
COPY supervisord.conf /etc/supervisor/conf.d/supervisord.conf
ENV PYTHONUNBUFFERED=1
ENTRYPOINT ["/usr/bin/supervisord", "-c", "/etc/supervisor/conf.d/supervisord.conf"]
A questo punto, abbiamo già tutti i file necessari per eseguire il deployment delle nostre applicazioni in Cloud Run. Eseguiamo il deployment. Vai al terminale Cloud Shell e assicurati che il progetto corrente sia configurato per il progetto attivo. In caso contrario, utilizza il comando gcloud configure per impostare l'ID progetto:
gcloud config set project [PROJECT_ID]
Quindi, esegui il comando seguente per eseguirne il deployment in Cloud Run.
gcloud run deploy --source . \
--env-vars-file settings.yaml \
--port 8080 \
--region us-central1
Ti verrà chiesto di inserire un nome per il servizio, ad esempio "gemini-multimodal-chat-assistant". Poiché abbiamo Dockerfile nella directory di lavoro dell'applicazione, verrà creato il container Docker e ne verrà eseguito il push in Artifact Registry. Ti verrà anche chiesto se vuoi creare il repository Artifact Registry nella regione. Rispondi "Y". Di' anche "y" quando ti viene chiesto se vuoi consentire le chiamate non autenticate. Tieni presente che stiamo consentendo l'accesso non autenticato perché si tratta di un'applicazione di dimostrazione. Ti consigliamo di utilizzare l'autenticazione appropriata per le tue applicazioni aziendali e di produzione.
Al termine del deployment, dovresti visualizzare un link simile al seguente:
https://gemini-multimodal-chat-assistant-*******.us-central1.run.app
Usa l'applicazione dalla finestra di navigazione in incognito o dal tuo dispositivo mobile. Dovrebbe essere già pubblicato.
7. La sfida
Ora è il tuo momento di brillare e perfezionare le tue capacità di esplorazione. Hai le competenze necessarie per modificare il codice in modo che l\'assistente possa supportare la lettura di file audio o video?
8. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo codelab, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
- In alternativa, puoi andare a Cloud Run nella console, selezionare il servizio appena di cui hai eseguito il deployment ed eliminarlo.