
1. はじめに
Petverse へようこそ。ペット同伴可。🐈🐶🐍🐟🦄
前提条件
- Google Cloud コンソールの基本的な知識
- SQL ステートメントの基本的な理解
学習内容
- BigQuery でデータセットとテーブルを作成する
- BigQuery で ObjectRef 列を作成して、ストレージ バケット内のマルチメディアを参照する
- BigQuery の AI 関数を使用して、非構造化データの内容からデータセットを強化する
- 類似したメディアを検索するためのマルチメディア エンベディングを作成する
- テキスト エンベディングを作成して VECTOR_SEARCH でセマンティック検索を行う
- Gemini CLI を使用してウェブ アプリケーションを作成する
必要なもの
- 請求先アカウントを含む Google Cloud アカウントと Google Cloud プロジェクト
- ウェブブラウザ(Chrome など)
2. 設定と要件
セルフペース型の環境設定
- Google Cloud Console にログインして、プロジェクトを新規作成するか、既存のプロジェクトを再利用します。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。

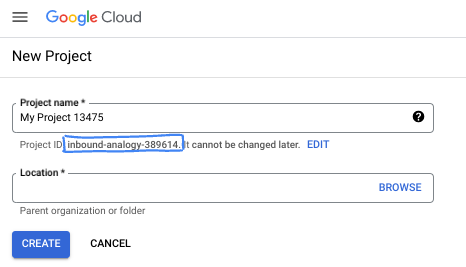
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。Google API では使用されない文字列です。いつでも更新できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Cloud コンソールでは一意の文字列が自動生成されます。通常は、この内容を意識する必要はありません。ほとんどの Codelab では、プロジェクト ID(通常は
PROJECT_IDと識別されます)を参照する必要があります。生成された ID が好みではない場合は、ランダムに別の ID を生成できます。または、ご自身で試して、利用可能かどうかを確認することもできます。このステップ以降は変更できず、プロジェクトを通して同じ ID になります。 - なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
- 次に、Cloud のリソースや API を使用するために、Cloud コンソールで課金を有効にする必要があります。この Codelab の操作をすべて行って、費用が生じたとしても、少額です。このチュートリアルの終了後に請求が発生しないようにリソースをシャットダウンするには、作成したリソースを削除するか、プロジェクトを削除します。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。
3. Cloud Shell を開く
https://shell.cloud.google.com/?show=ide%2Cterminal に移動します。プロンプトが表示されたら [承認] をクリックします。
エディタとコンソールの両方が表示されていることを確認します。
4. ヘルパー スクリプトを作成する
この操作をスムーズに行うために、関連する環境変数を設定するヘルパー スクリプトを作成します。
下の <<プロジェクト ID>> を実際のプロジェクト ID に置き換えます。
次のコマンドを Cloud Shell ターミナルにコピーし、Enter キーを押して実行します。
gcloud config set project <<PROJECT_ID>>
次のコマンドを Cloud Shell ターミナルにコピーし、Enter キーを押して実行します。これにより、必要なサービスが有効になり、ファイルが作成されて Cloud Shell で編集されます。
gcloud services enable compute.googleapis.com \
cloudresourcemanager.googleapis.com \
aiplatform.googleapis.com \
storage-component.googleapis.com \
bigqueryconnection.googleapis.com \
run.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iap.googleapis.com
edit ~/petverse-setup.sh
ファイル名が付けられた新しいタブが表示されます。次のスクリプトを新しいファイルに貼り付けます。
#!/bin/bash
# -----------------------------------------------------------------------------
# 1. Global Variables: Set your desired project ID and region here.
# -----------------------------------------------------------------------------
# 🦄 🦄 Set your project ID here ⬇️.
# Example: PROJECT_ID="your-project-id"
PROJECT_ID=""
# Set your desired region here. Default is 'us-central1'.
# Example: REGION="us-east1"
REGION="us-central1"
# -----------------------------------------------------------------------------
# 2. Check and Authenticate
# -----------------------------------------------------------------------------
echo " ➡️ Checking for active Google Cloud authentication..."
# Check if the user is authenticated; if not, prompt for authentication.
if ! gcloud auth list --format="value(account)" | grep -q @; then
echo "⚠️ Not authenticated. Please authenticate now."
gcloud auth login
fi
echo " ✅ Authentication check passed."
# -----------------------------------------------------------------------------
# 3. Get Project ID from User if not set
# -----------------------------------------------------------------------------
# If PROJECT_ID is not set in the script or as an environment variable,
# prompt the user to choose one.
if [[ -z "$PROJECT_ID" ]] && [[ -n "$DEVSHELL_PROJECT_ID" ]]; then
PROJECT_ID=$DEVSHELL_PROJECT_ID
fi
if [[ -z "$PROJECT_ID" ]]; then
echo " ⚠️ Project ID is not set. Listing available projects:"
# List projects and store them in an array.
projects_array=($(gcloud projects list --format="value(projectId)"))
# Check if projects were found.
if [[ ${#projects_array[@]} -eq 0 ]]; then
echo " ❌ No projects found. Please ensure your account has access to projects."
exit 1
fi
# Display the projects and prompt for input.
echo " "
echo "Available Projects:"
for project in "${projects_array[@]}"; do
echo "$project"
done
echo " "
read -p "Please enter your desired project ID from the list above: " PROJECT_ID
# Validate the user's input by checking if it's in the array.
if [[ ! " ${projects_array[@]} " =~ " ${PROJECT_ID} " ]]; then
echo " ❌ Invalid project ID. Please run the script again and select a valid ID."
exit 1
fi
fi
echo " ✅ Project ID set to: $PROJECT_ID"
# -----------------------------------------------------------------------------
# 4. Set Environment Variables
# -----------------------------------------------------------------------------
# Set the project and region for the current session.
echo " 🔄 Setting Google Cloud configuration for this session..."
gcloud config set project "$PROJECT_ID"
gcloud config set compute/region "$REGION"
echo " ✅ Google Cloud configuration updated."
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo " "
echo " 🎉 🦄 🦄 Script execution complete. You can now use Google Cloud commands in this shell session."
PROJECT_ID のプレースホルダをプロジェクトの名前に置き換えます。
次のコマンドをコピーして、ターミナルで実行します。
chmod +x petverse-setup.sh
~/petverse-setup.sh
予想される出力:

5. ストレージ バケットを作成する
Cloud Storage バケットを作成し、利用可能なメディアを独自のバケットにコピーします。このストレージを使用して、かわいいペットの利用可能なメディアを保存します。また、BigQuery を介してバケットにアクセスするための接続も作成します。
ターミナルに次のコマンドを貼り付けて実行します。
~/petverse-setup.sh
cd ~/
gcloud storage buckets create gs://$DEVSHELL_PROJECT_ID-petverse --uniform-bucket-level-access --location=us-central1
gcloud storage cp -r gs://sample-data-and-media/petverse/* gs://$DEVSHELL_PROJECT_ID-petverse/
bq mk --dataset --location=us-central1 --project_id=$DEVSHELL_PROJECT_ID petverse
bq mk --connection --location=us-central1 --project_id=$DEVSHELL_PROJECT_ID \
--connection_type=CLOUD_RESOURCE pet-connection
echo "your bucket is gs://$DEVSHELL_PROJECT_ID-petverse "

6. pets テーブルを作成する
ここでは、ペットに関する情報を格納するテーブルを BigQuery に作成します。
ブラウザで新しいタブを開きます。https://console.cloud.google.com/bigquery に移動します。
コンソールで、これまで使用していたプロジェクトが選択されていることを確認します。
これで、ファイル pets.csv のデータを使用してテーブルを作成できるようになりました。このファイルには、ペットの名前、好きな食べ物、おもちゃなど、ペットに関する興味深い情報が含まれています。
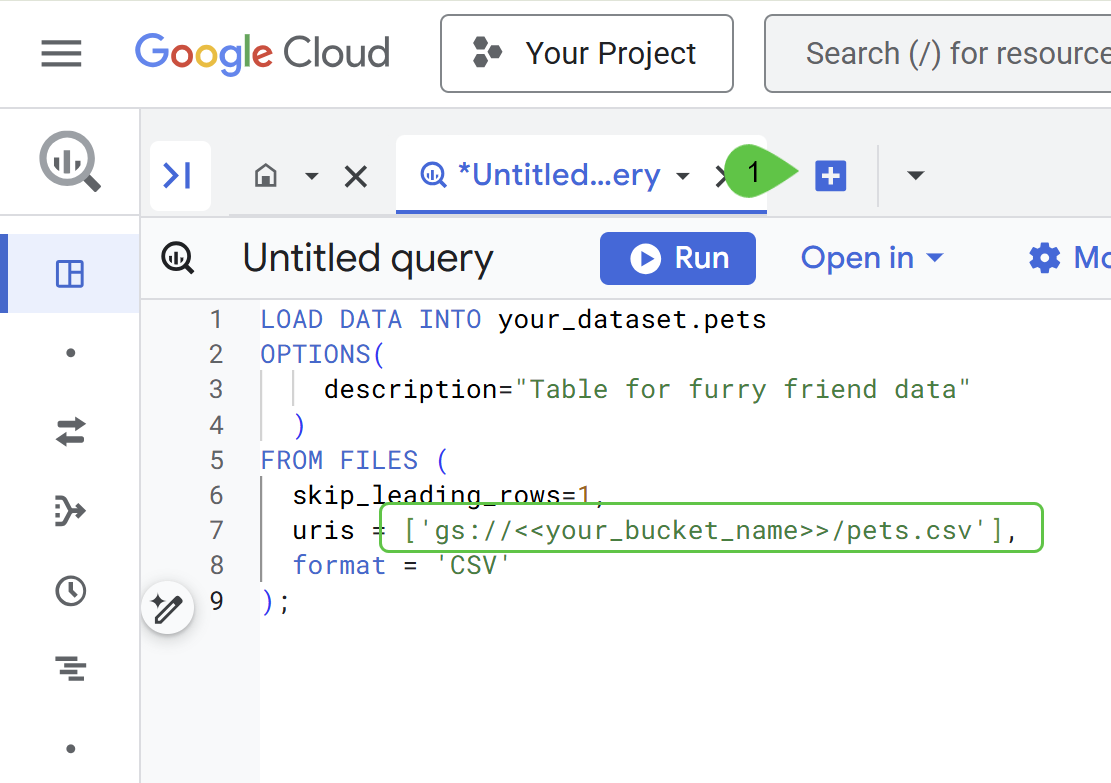
次のコードを新しい SQL クエリにコピーして、物理テーブルを作成し、データを読み込みます。
LOAD DATA INTO petverse.pets
OPTIONS(
description="Table for furry friend data"
)
FROM FILES (
skip_leading_rows=1,
uris = ['gs://<<your_bucket_name>>/pets.csv'],
format = 'CSV'
);
コード内のバケットのプレースホルダを、前の手順で作成したバケットに置き換えます。
すべてのストレージ バケットは、この URL(https://console.cloud.google.com/storage/browser)を指す別のブラウザタブで確認できます。
[実行] ボタンを使用してクエリを実行します。
データが正常に読み込まれたら、[テーブルに移動] をクリックします。
[プレビュー] をクリックして、テーブルの内容を確認します。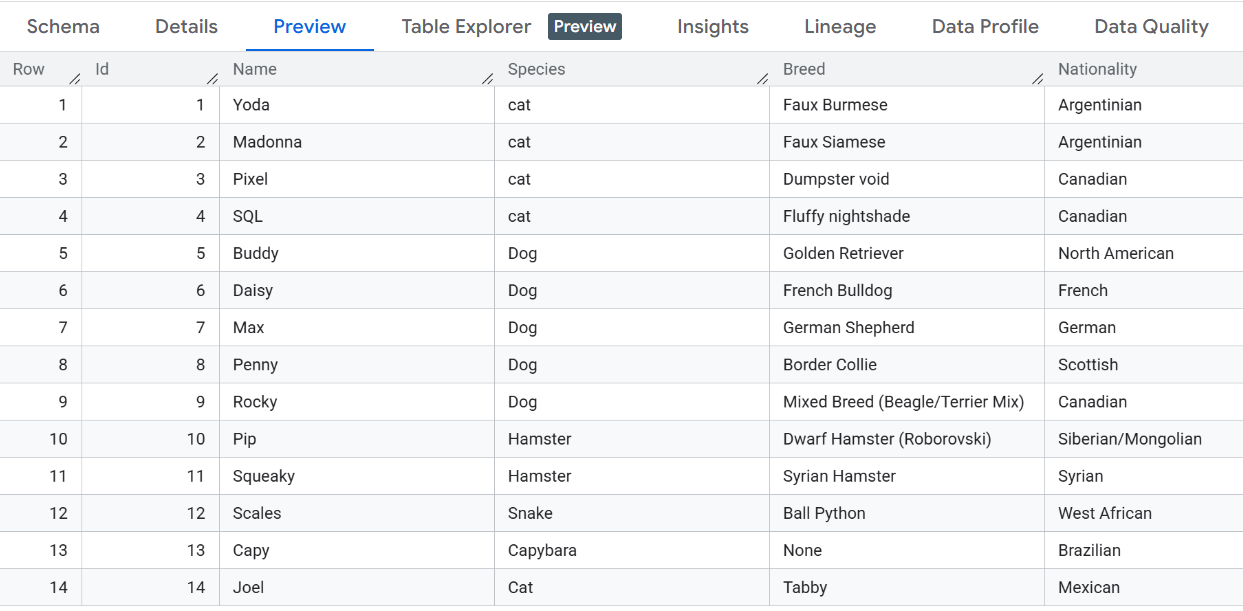
7. BigQuery をストレージ バケットに接続する
先ほど作成したバケットを確認すると、各ペットに関連するメディア ファイルのセットが見つかります。
BigQuery には、これらのバケットを読み取り、テーブル内のデータとともにファイルを使用する機能があります。この値の型は ObjectRef と呼ばれます。
[外部接続] で、先ほど作成した接続をクリックして、サービス アカウント ID を取得します。
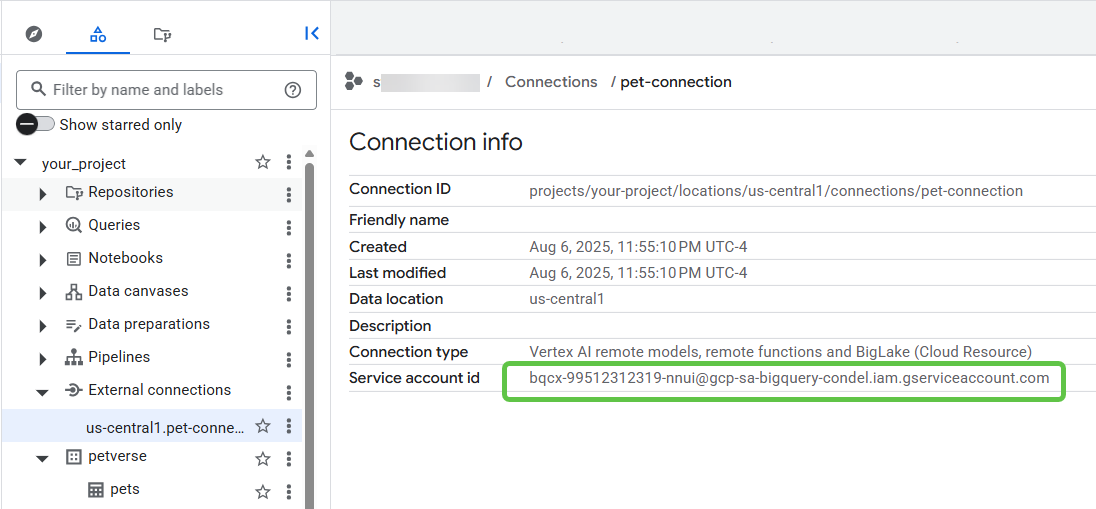
サービス アカウント ID をコピーします。
新しいブラウザタブで IAM 管理コンソール(https://console.cloud.google.com/iam-admin/)に移動します。
Storage オブジェクト閲覧者と Vertex AI ユーザーの権限を持つサービス アカウントを付与します(この権限は後で使用します)。
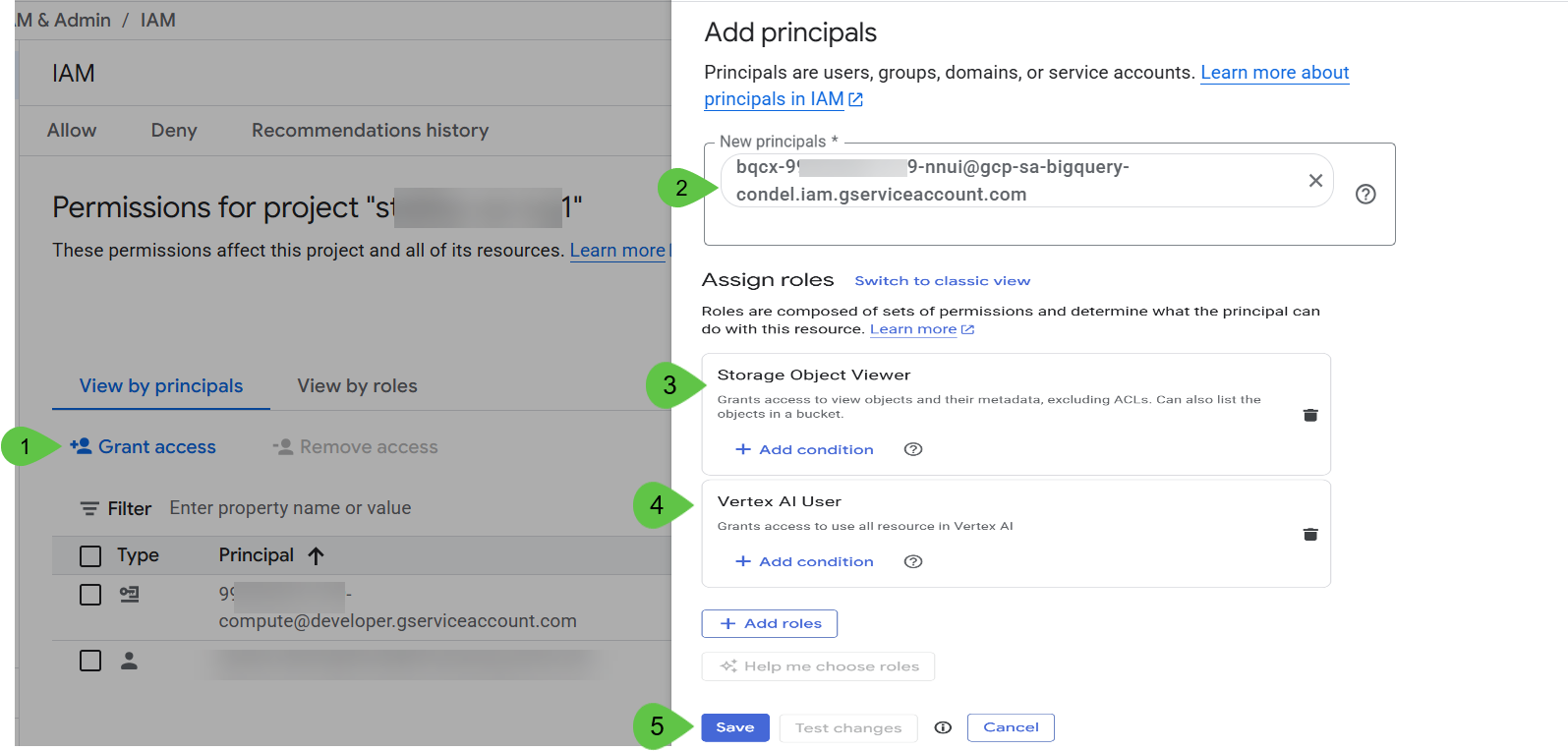
[保存] をクリックし、🕰️ 数分待ちます。
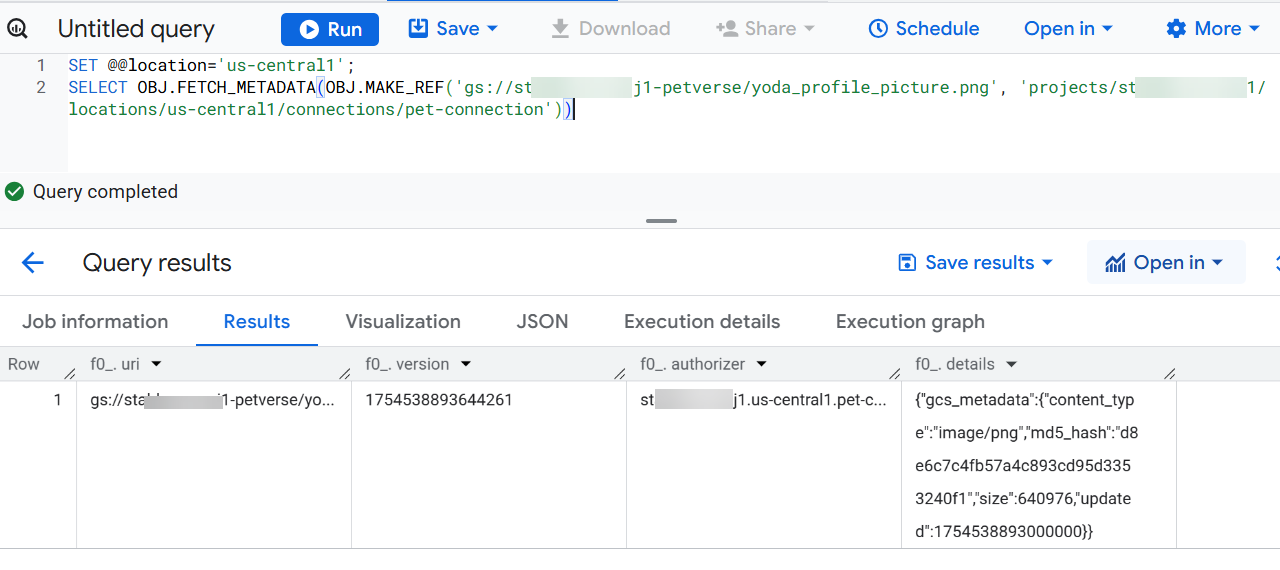
BigQuery タブに戻り、BigQuery Studio で次のクエリを使用して、BigQuery とストレージ バケット間の接続をテストします。
<<PROJECT_ID>> は、実際のプロジェクト ID に置き換えます。
SET @@location='us-central1';
SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/yoda_profile_picture.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))
[結果を表示] をクリックします。結果にメタデータが表示されます。
8. 構造化データにストレージ メディアを追加する
pets テーブルを拡張して、各ペットのプロフィール写真(利用可能な場合)を含む列を追加できます。また、メディア参照の配列を含む別の列を追加して、各ペットに関連する他のすべてのファイルを保持します。
マルチメディアにアクセスするには、この Codelab の冒頭でバケットを作成した後に作成した接続が必要です。
次のコマンドを BigQuery SQL コンソールに貼り付けて実行し、pets テーブルに 2 つの列を追加します。
SET @@location='us-central1';
ALTER TABLE petverse.pets
ADD COLUMN IF NOT EXISTS profile_picture STRUCT<uri STRING, version STRING, authorizer STRING, details JSON>,
ADD COLUMN IF NOT EXISTS additional_media ARRAY<STRUCT<uri STRING, version STRING, authorizer STRING, details JSON>>;
次のステートメントをコピーし、PROJECT_ID のプレースホルダを実際のプロジェクト ID に置き換えます。
SET @@location='us-central1';
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/yoda_profile_picture.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/Yoda_asks_for_cuddles.mp4', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))]
WHERE Id = 1;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/madonna_profile_picture.jpg', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/Madonna_description.wav', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))]
WHERE Id = 2;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/pixel_profile_picture.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/pixel_thug_life.mp4', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/pixel_description.wav', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))]
WHERE Id = 3;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/sql_profile_picture.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/SQL_description.wav', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/SQL_favorite_toy.mp4', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))]
WHERE Id = 4;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/buddy_golden_retriever.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = NULL
WHERE Id = 5;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/daisy_french_bulldog.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = NULL
WHERE Id = 6;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/max_german_shepherd.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/max_description_tells_jokes.mp4', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))]
WHERE Id = 7;
UPDATE petverse.pets SET profile_picture = NULL, additional_media = NULL WHERE Id = 8;
UPDATE petverse.pets SET profile_picture = NULL, additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/rocky_description.mp4', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))] WHERE Id = 9;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/pip_hamster.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/pip_Hamster_Wheel_Video_Generated.mp4', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))]
WHERE Id = 10;
UPDATE petverse.pets SET profile_picture = NULL, additional_media = NULL WHERE Id = 11;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/scales_snake.png', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = NULL
WHERE Id = 12;
UPDATE petverse.pets SET profile_picture = NULL, additional_media = NULL WHERE Id = 13;
UPDATE petverse.pets
SET profile_picture = (SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/Joel_Profile_Picture.jpg', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
additional_media = [(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/Joel_Catwalk.jpg', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/Joel_Flowers.jpg', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection'))),
(SELECT OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://<<PROJECT_ID>>-petverse/additional_media/Joel_Plays.jpg', 'projects/<<PROJECT_ID>>/locations/us-central1/connections/pet-connection')))]
WHERE Id = 14;
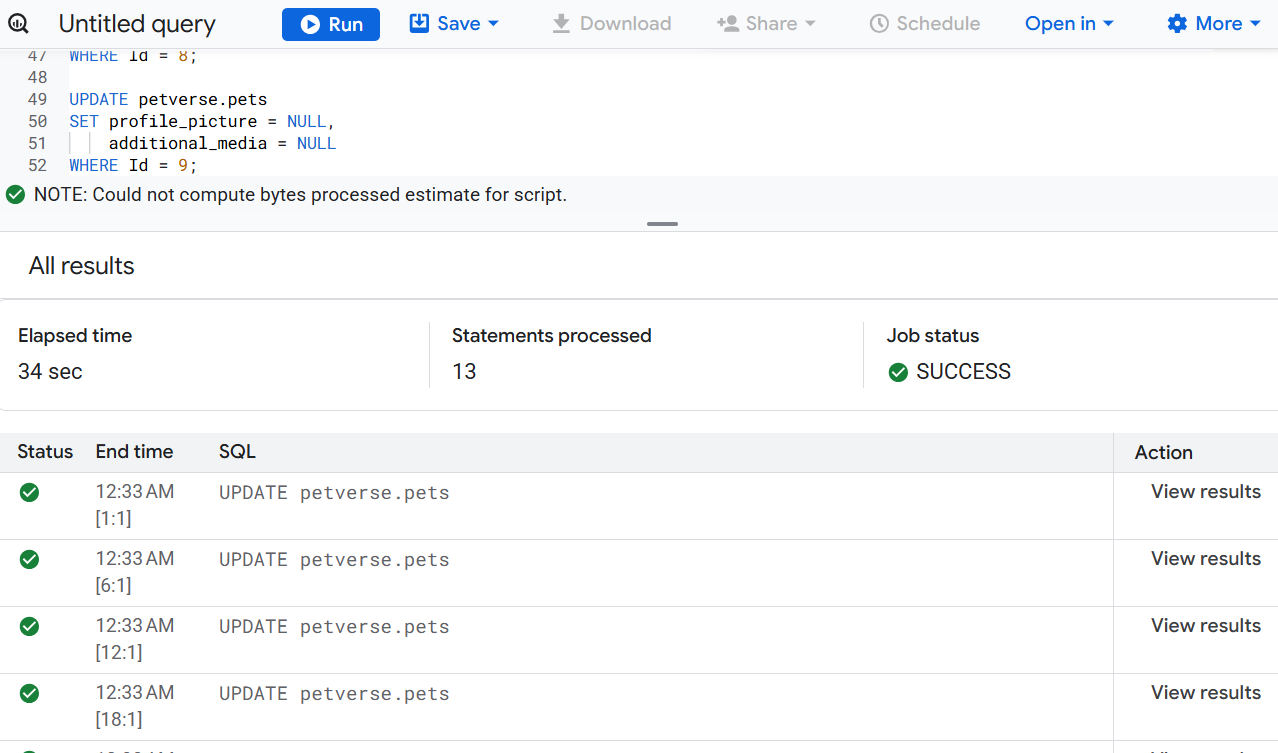
ステートメントを実行します。数分後に、実行が成功したことが表示されます。
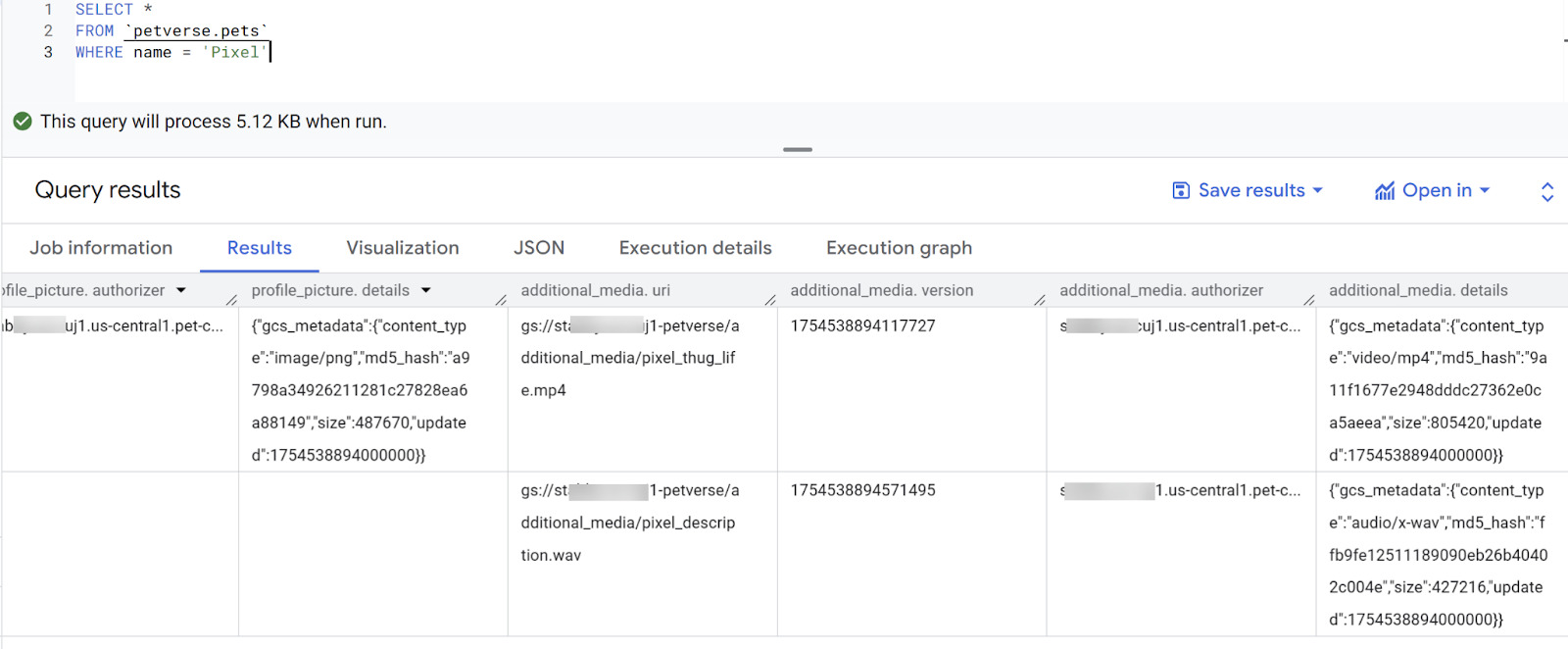
テーブルのプレビューを使用して結果を確認します。既存のプロフィール写真と、Pixel という名前の猫の追加メディアのメタデータが表示されます。
SELECT *
FROM `petverse.pets`
WHERE name = 'Pixel'
9. ペットの説明を生成する
pets テーブルをプレビューすると、Yoda、Pixel、Rocky などの一部のペットのお気に入りの食べ物やおもちゃが欠落していることがわかります。
これらの質問の答えは、これらのペットに関連する動画や音声に含まれている可能性があります。埋め込み AI 関数を使用して確認します。
次のステートメントでテストします。
SELECT name,
AI.GENERATE(
prompt=> ('What are this pet\'s favorite toy and favorite foods', additional_media ),
connection_id => 'us-central1.pet-connection',
endpoint => 'gemini-2.5-flash',
output_schema => 'food STRING, toy STRING')
FROM petverse.pets
WHERE name = 'Rocky'
Rocky の動画はストレージ バケットで確認できます。
次のステートメントを使用して、欠落している説明を更新します。
UPDATE petverse.pets AS p
SET FavoriteFood = aigen.food
FROM
(
SELECT Id, name,
AI.GENERATE(
prompt=> ('What are this pet\'s favorite toy and favorite foods', additional_media ),
connection_id => 'us-central1.pet-connection',
endpoint => 'gemini-2.5-flash',
output_schema => 'food STRING').food
FROM petverse.pets ) AS aigen
WHERE p.Id = aigen.Id
AND p.FavoriteFood IS NULL
AND p.additional_media IS NOT NULL
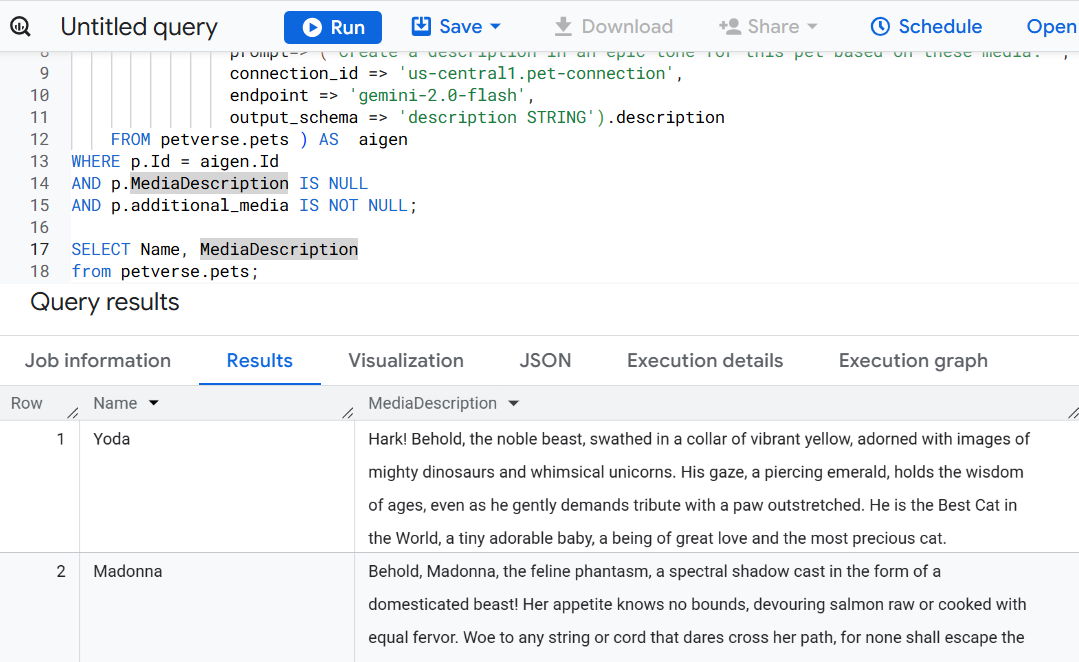
次のステートメントを使用して、ペットのマルチメディアに基づいてペットの説明を新しい列に作成します。
ALTER TABLE petverse.pets ADD COLUMN MediaDescription STRING;
UPDATE petverse.pets AS p
SET MediaDescription = aigen.description
FROM
(
SELECT Id, name,
AI.GENERATE(
prompt=> ('Create a description in an epic tone for this pet based on these media: ', additional_media ),
connection_id => 'us-central1.pet-connection',
endpoint => 'gemini-2.5-flash',
output_schema => 'description STRING').description
FROM petverse.pets ) AS aigen
WHERE p.Id = aigen.Id
AND p.MediaDescription IS NULL
AND p.additional_media IS NOT NULL
数分後、クリエイティブな説明が表示されます。
10. エンベディングを作成する
セマンティック検索で使用するプロフィール写真、説明、趣味のエンベディングを保存するテーブルを作成します。ベクトル検索を使用して、ペット間の類似性を検出します。
SET @@location='us-central1';
CREATE OR REPLACE MODEL petverse.multimodalembedding
REMOTE WITH CONNECTION `us-central1.pet-connection`
OPTIONS(ENDPOINT = 'multimodalembedding@001');
CREATE TABLE IF NOT EXISTS petverse.profile_embeddings
AS
SELECT *
FROM ML.GENERATE_EMBEDDING(
MODEL petverse.multimodalembedding,
(
SELECT profile_picture as content,
Id
FROM petverse.pets)
);
CREATE OR REPLACE MODEL petverse.textembedding
REMOTE WITH CONNECTION `us-central1.pet-connection`
OPTIONS (ENDPOINT = 'text-embedding-005');
CREATE OR REPLACE TABLE petverse.text_embeddings AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL petverse.textembedding,
(
SELECT CONCAT(AdoptionStory, ' . This pet\'s hobby is: ', Hobby, ' and their nickname(s) is: ', COALESCE(Nicknames, Name)) AS content,
Id, Name
FROM petverse.pets
WHERE LENGTH(AdoptionStory) > 0 AND LENGTH(Hobby) > 0
)
)
WHERE LENGTH(ml_generate_embedding_status) = 0;
[結果] タブで新しいテーブルを確認します。
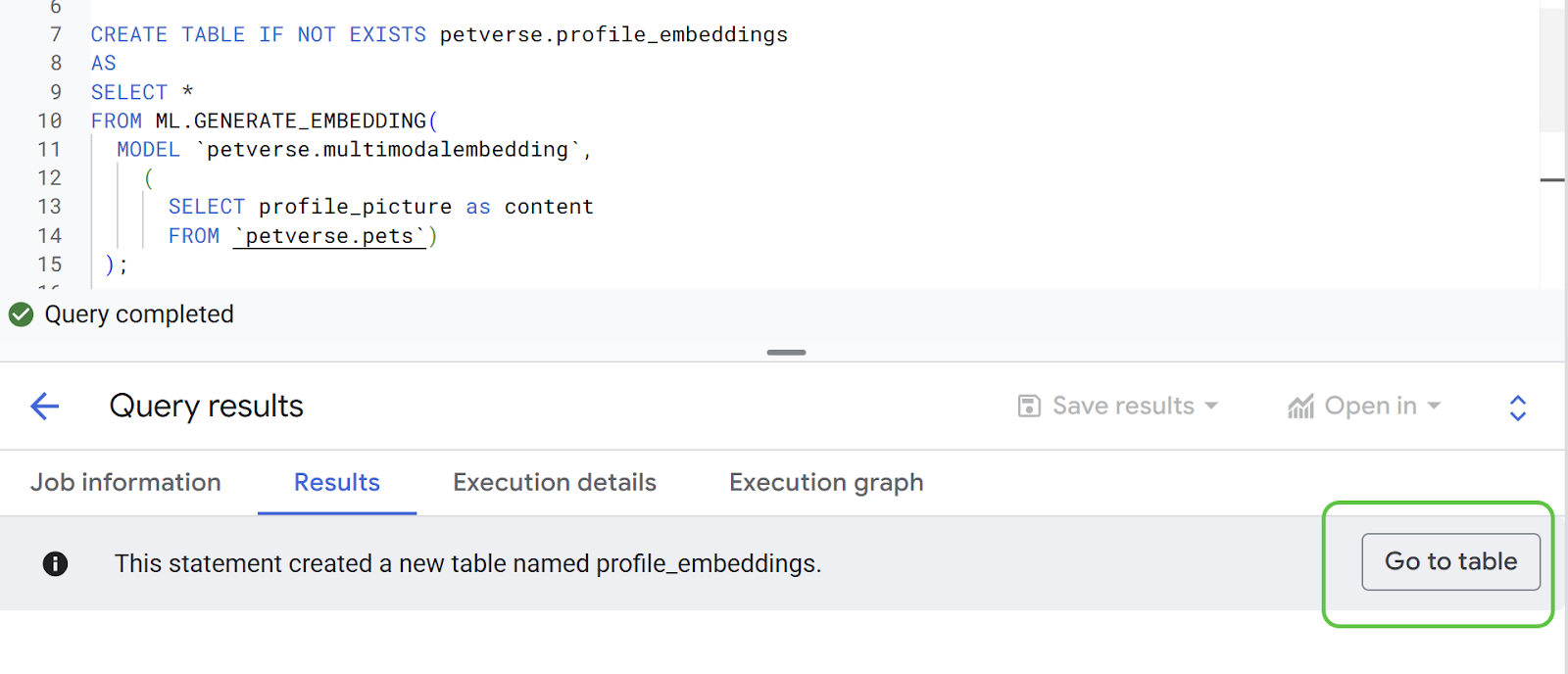
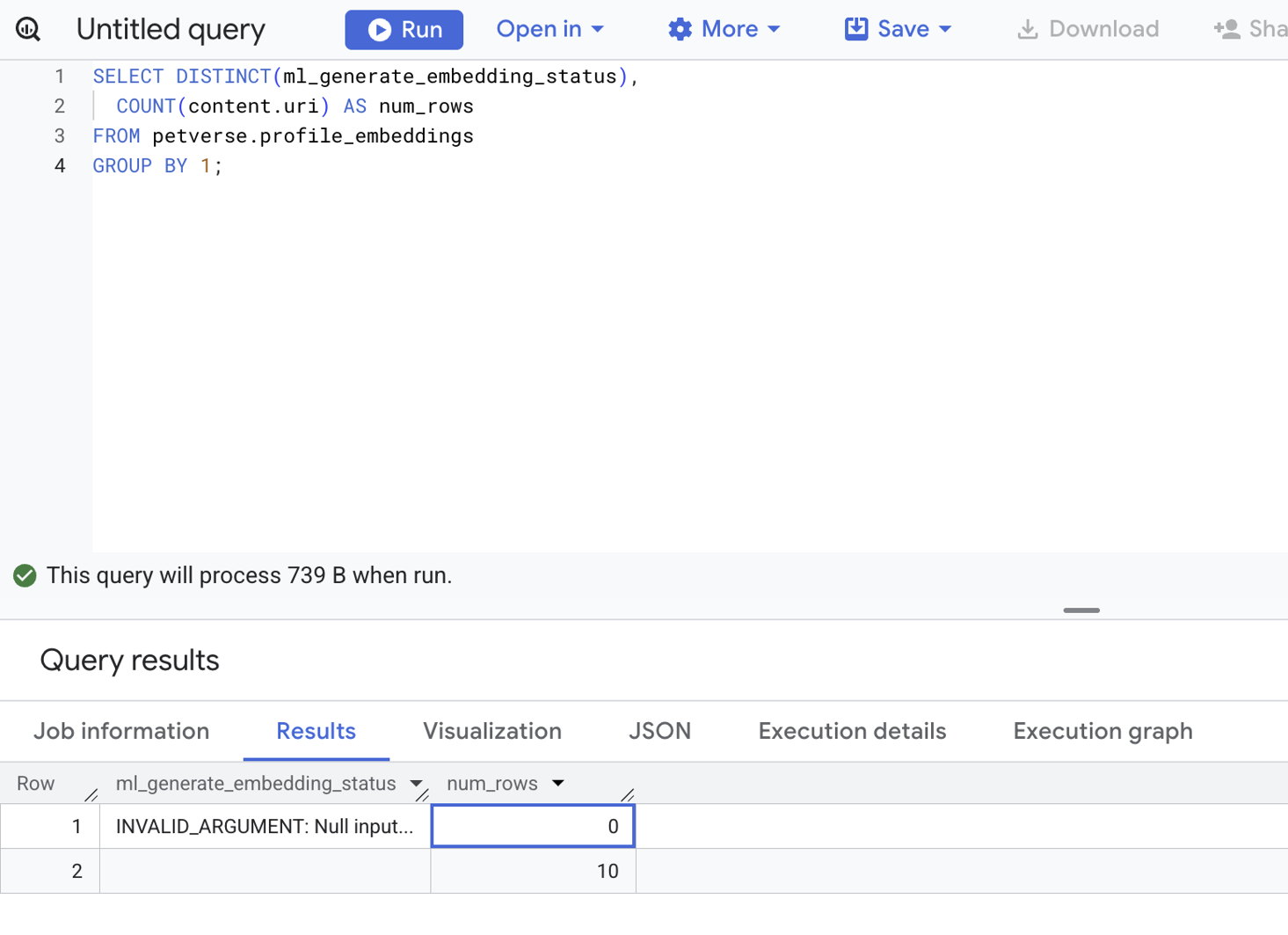
次のステートメントを使用して、すべてのエンベディングのステータスを確認します。
SELECT DISTINCT(ml_generate_embedding_status),
COUNT(content.uri) AS num_rows
FROM petverse.profile_embeddings
GROUP BY 1;
エラーがある場合は、空白以外のステータスで表示されます。これは正しい出力です。エラーのあるレコードはありません。
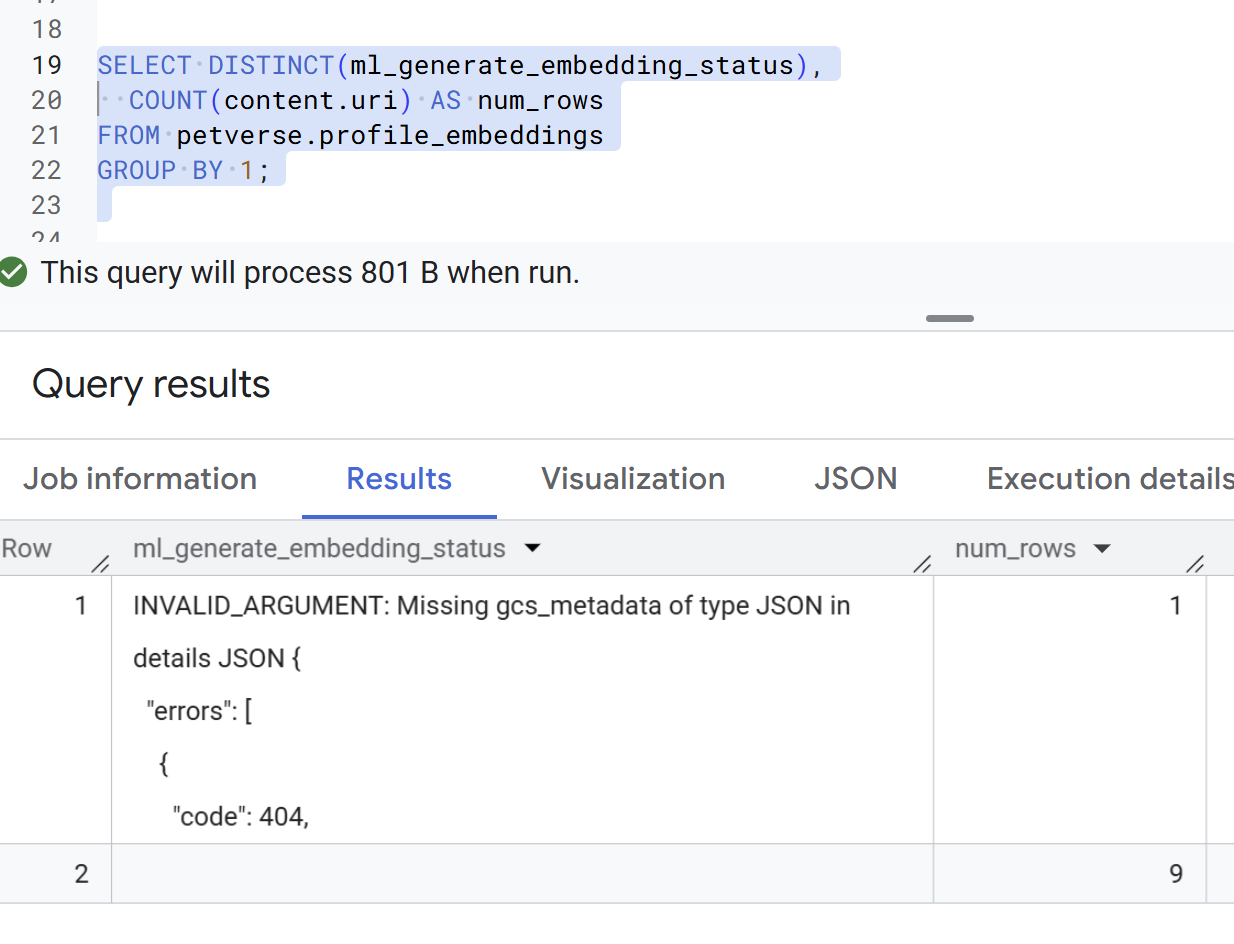
エラーのあるレコードの例を次に示します。これらは想定されていませんが、次の手順に進む前に修正する必要があります。
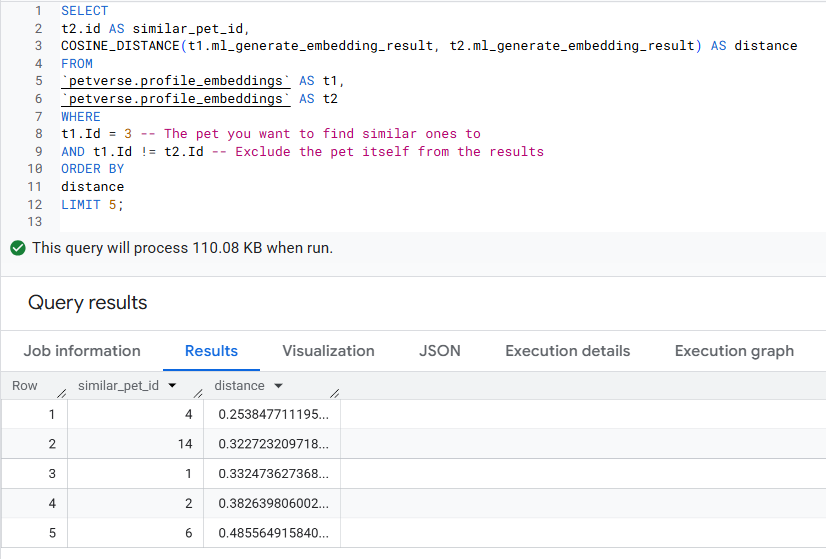
類似のペットを探す
デフォルトのデータセットには、同様のペットが含まれています。Pixel(ID: 3)と SQL(ID: 4)の 2 つの例を次に示します。

エンベディング間の距離を使用して、類似したペットを計算できます。
SELECT
t2.id AS similar_pet_id,
COSINE_DISTANCE(t1.ml_generate_embedding_result, t2.ml_generate_embedding_result) AS distance
FROM
petverse.profile_embeddings AS t1,
petverse.profile_embeddings AS t2
WHERE
t1.Id = 3 -- The pet you want to find similar ones to
AND t1.Id != t2.Id -- Exclude the pet itself from the results
AND t1.content.uri IS NOT NULL
AND t2.content.uri IS NOT NULL
ORDER BY
distance
LIMIT 5;
類似する写真の ID が返されます。これにより、写真内のすべてのものが含まれます。この例では、Pixel と SQL は類似しており、次に類似しているペットは Joel(ID: 14)です。
参考までに、Joel の写真をご覧ください。

セマンティック検索を試す
VECTOR_SEARCH 関数を使用すると、テキスト エンベディング全体でセマンティック検索を実行できます。このテーブルが大きくなる場合は、エンベディングのインデックスを作成する必要があります。
SELECT query.query, base.content, base.Name
FROM VECTOR_SEARCH(
TABLE `petverse.text_embeddings`, 'ml_generate_embedding_result',
(
SELECT ml_generate_embedding_result, content AS query
FROM ML.GENERATE_EMBEDDING(
MODEL `petverse.textembedding`,
(SELECT 'Pets who like to relax' AS content))
),
top_k => 5, options => '{"fraction_lists_to_search": 0.50}')
ORDER BY distance DESC
セマンティック検索キーワード(Pets who like to relax)とパラメータ fraction_lists_to_search を変更して、どうなるか確認してみてください。これらの関数の詳細については、こちらをご覧ください。
11. プロフィール ページのバイブ コーディング
Cloud Shell で Gemini CLI を使用して、シンプルなデモ ウェブ アプリケーションを迅速に作成します。このウェブ アプリケーションでは、Petverse の実現方法を示すために、プロンプトが簡略化されています。
Cloud Shell に戻ります。コンソールを全画面表示にすると、より快適に操作できます。
初期化スクリプトを実行して、環境変数が設定されていることを確認し、このプロジェクトを格納するディレクトリを作成して、Gemini CLI を実行します。
~/petverse-setup.sh
mkdir petverse-profiles
cd petverse-profiles
gemini
Gemini の CLI が表示されます。
次のプロンプトのバケット名を置き換えます。
プロンプトを Gemini コマンドラインに貼り付けます。
You are a fullstack engineer creating an application to display the profiles of cats, dogs and other pets stored in BigQuery. The table where these are stored is called pets, in the dataset petverse.
1.Application Requirements: Display the pets with their profile picture, all the other information in the Pets table, and other media that may be available. The pictures are in a GCS bucket, the field in the table pets profile_picture.uri contains the URI for the storage bucket of that profile picture. The field additional_media is an array of objectref that contains multiple URI to different media stored in a GCS bucket.
Important: In the code, in the values for the URIs retrieved from BigQuery, replace gs://<<YOUR_PROJECT_ID>>-petverse/ with https://storage.mtls.cloud.google.com/<<YOUR_PROJECT_ID>>-petverse/ as follows: replace('gs://', 'https://storage.mtls.cloud.google.com/'). Use the python library. Media can be pictures, videos and audio. Consider these formats in the code. Some pets may not have profile pictures or additional media.
2.Hosting: Create a web application hosted in a single container and service in Cloud Run, use the following syntax to deploy it using IAP. IMPORTANT: DO NOT ADD IAM AUTHENTICATION AND DO NOT ALLOW UNAUTHENTICATED: gcloud beta run deploy SERVICE_NAME --region=REGION --image=IMAGE_URL --no-allow-unauthenticated --iap
3.Database access: Display similar pets based on a similarity between embeddings in table petverse.profile_embeddings.
Here's the schema for the pets table in CSV format (Field name, type, mode):
Id,INTEGER,NULLABLE
Name,STRING,NULLABLE
Species,STRING,NULLABLE
Breed,STRING,NULLABLE
Nationality,STRING,NULLABLE
Nicknames,STRING,NULLABLE
Hobby,STRING,NULLABLE
AdoptionStory,STRING,NULLABLE
FavoriteFood,STRING,NULLABLE
FavoriteToy,STRING,NULLABLE
profile_picture,RECORD,NULLABLE
additional_media,RECORD,REPEATED
profile_embeddings,FLOAT,REPEATED
Here's a sample query to check for similarity:
SELECT
t2.id AS similar_pet_id,
COSINE_DISTANCE(t1.ml_generate_embedding_result, t2.ml_generate_embedding_result) AS distance
FROM
petverse.profile_embeddings AS t1,
petverse.profile_embeddings AS t2
WHERE
t1.Id = 3 -- The pet you want to find similar ones to
AND t1.Id != t2.Id -- Exclude the pet itself from the results
AND t1.content.uri IS NOT NULL
AND t2.content.uri IS NOT NULL
ORDER BY
distance
LIMIT 5;
Complement the profile of each pet with a description. Here's an example of the access to such table:
SELECT Name, MediaDescription from petverse.pets;
4.For each access to BigQuery, show the SQL statement that is used in the console logs.
5.Search functionality: Add a search bar for a semantic search for pets. There's a text embedding for the Adoption story, the pet's past-time or hobby and their nicknames in the table: petverse.text_embeddings . This is a sample of semantic search:
SELECT query.query, base.content, base.Name FROM VECTOR_SEARCH(TABLE `petverse.text_embeddings`, 'ml_generate_embedding_result', ( SELECT ml_generate_embedding_result, content AS query FROM ML.GENERATE_EMBEDDING(MODEL `petverse.textembedding`,(SELECT 'Pets who like to relax' AS content))), top_k => 5, options => '{"fraction_lists_to_search": 0.50}') ORDER BY distance DESC
6.Use Python for the backend. Generate the deployment scripts for an authenticated service using IAP with the flags --no-allow-unauthenticated --iap
7. Make the UI look like a modern art museum.
8. Use the gunicorn library. Validate version dependencies.
これがあなたの冒険です。プランが表示され、途中で確認を求められます。
コードとデプロイが最初の試行で機能する可能性はほとんどありません。Gemini CLI が正しくなるまで、反復処理する必要があります。
プロセスがループに陥っている場合は、Ctrl/Command + C で停止し、問題を調査して、もう一度プロンプトを表示します。
CLI の動作を理解するために、各確認メッセージを 1 つずつ注意深く読むことをおすすめします。
数分後、アプリケーションを実行できるようになります。コンソールがフリーズしたように見えることがあります。
gunicorn を使用して、新しい Cloud Shell タブでアプリケーションを手動で試すことができます。プロジェクトが設定されていることを確認します。
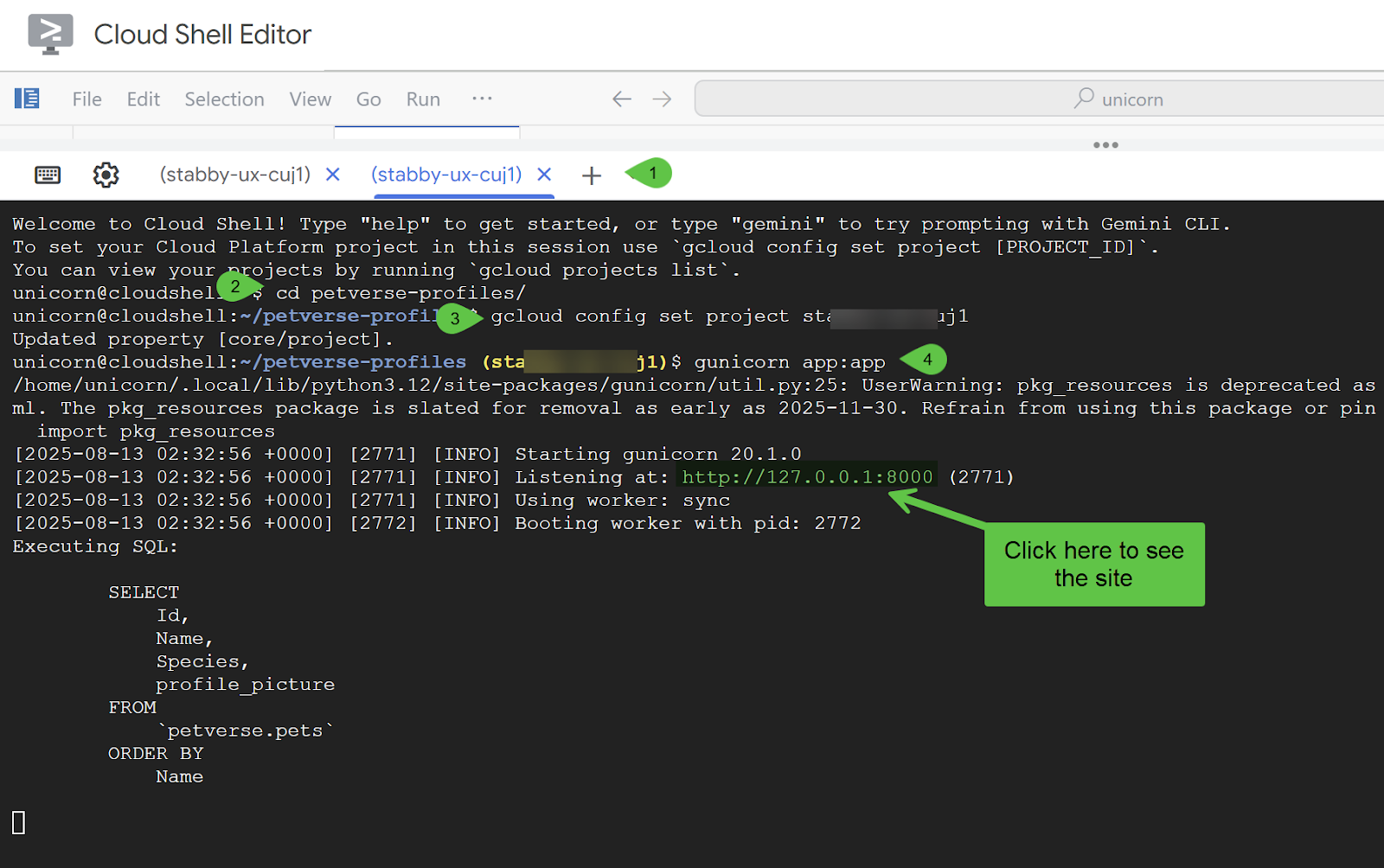
新しいサイトが表示されます(このサイトとは異なる場合があります)。動作しないものがある場合は、ローカルで実行されている Cloud Shell コマンドラインでエラーとデバッグログを確認できます。
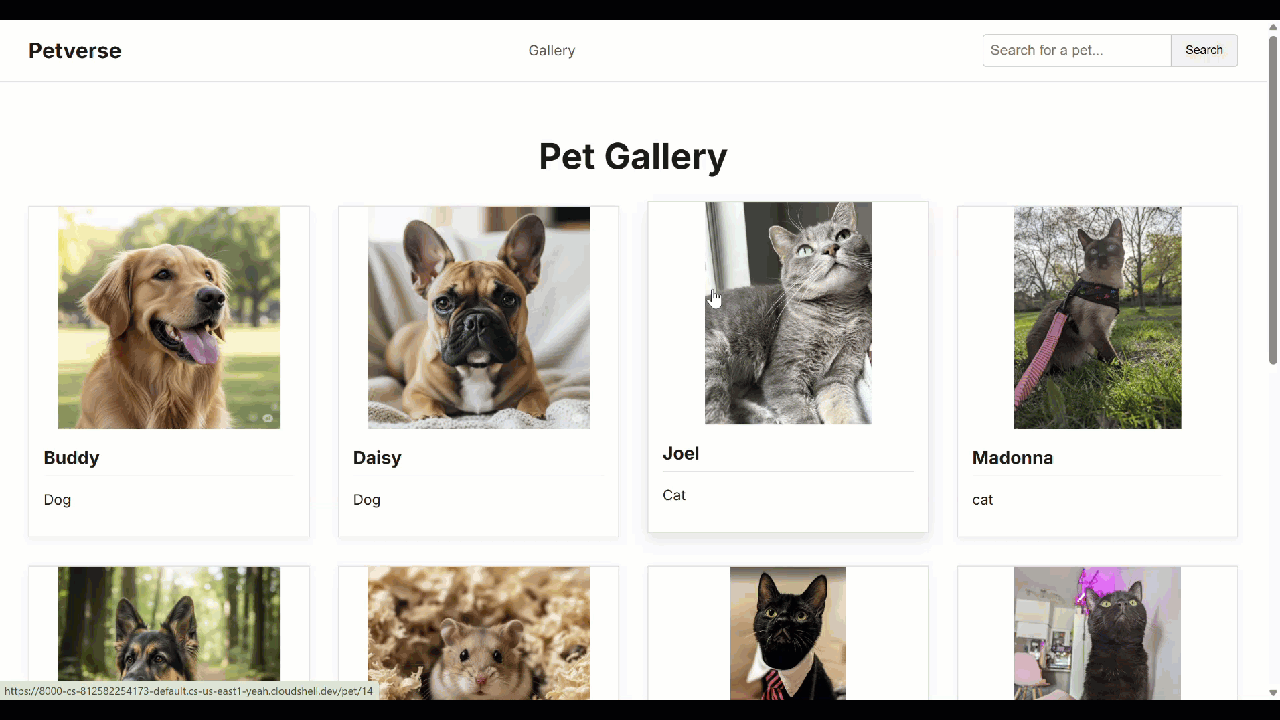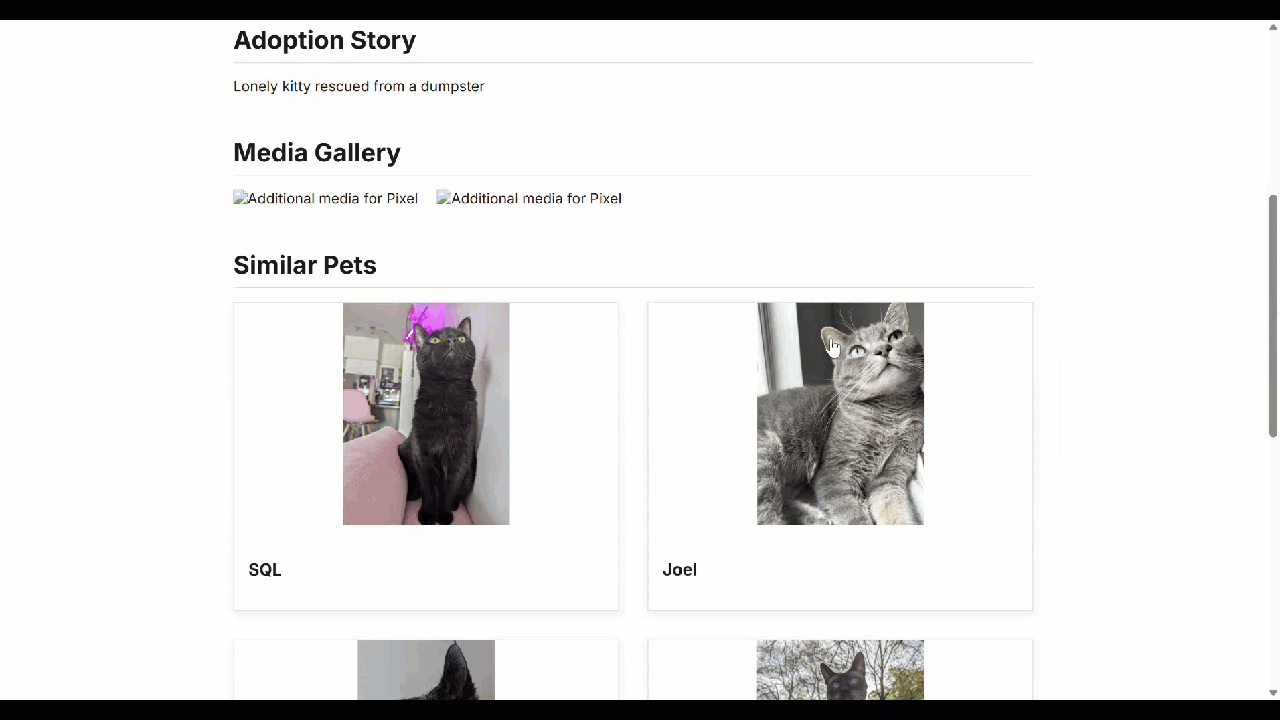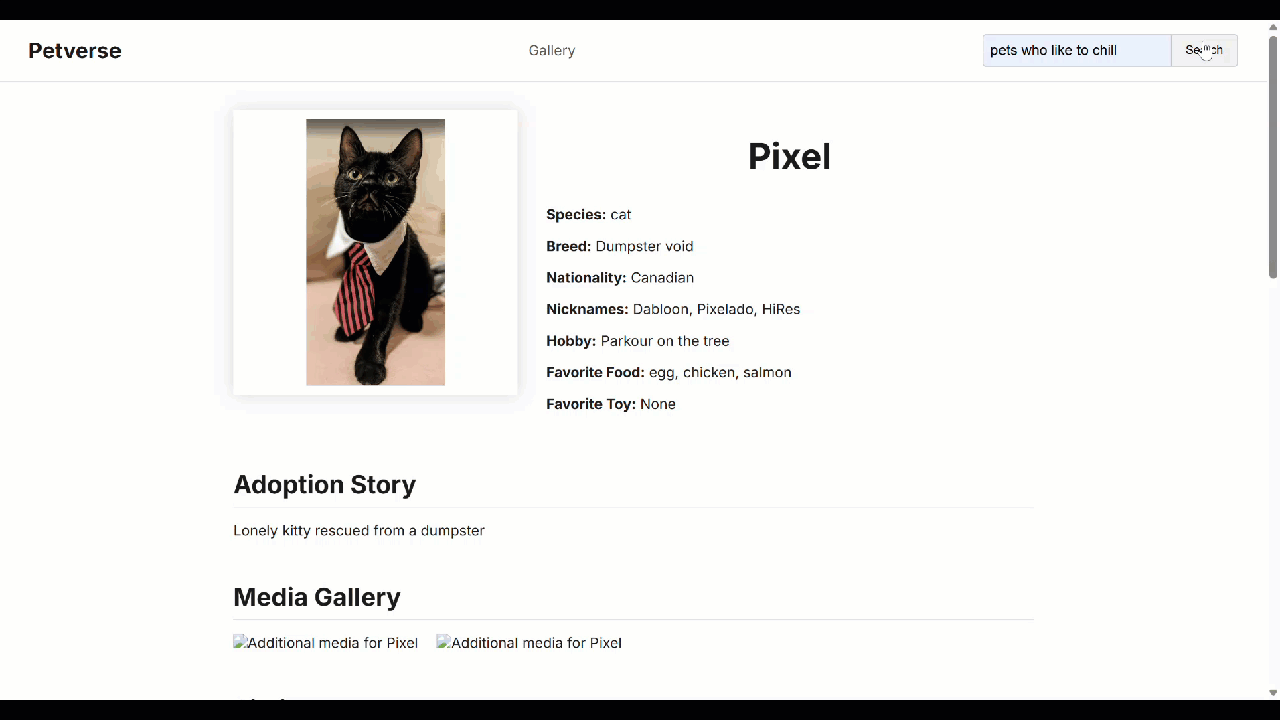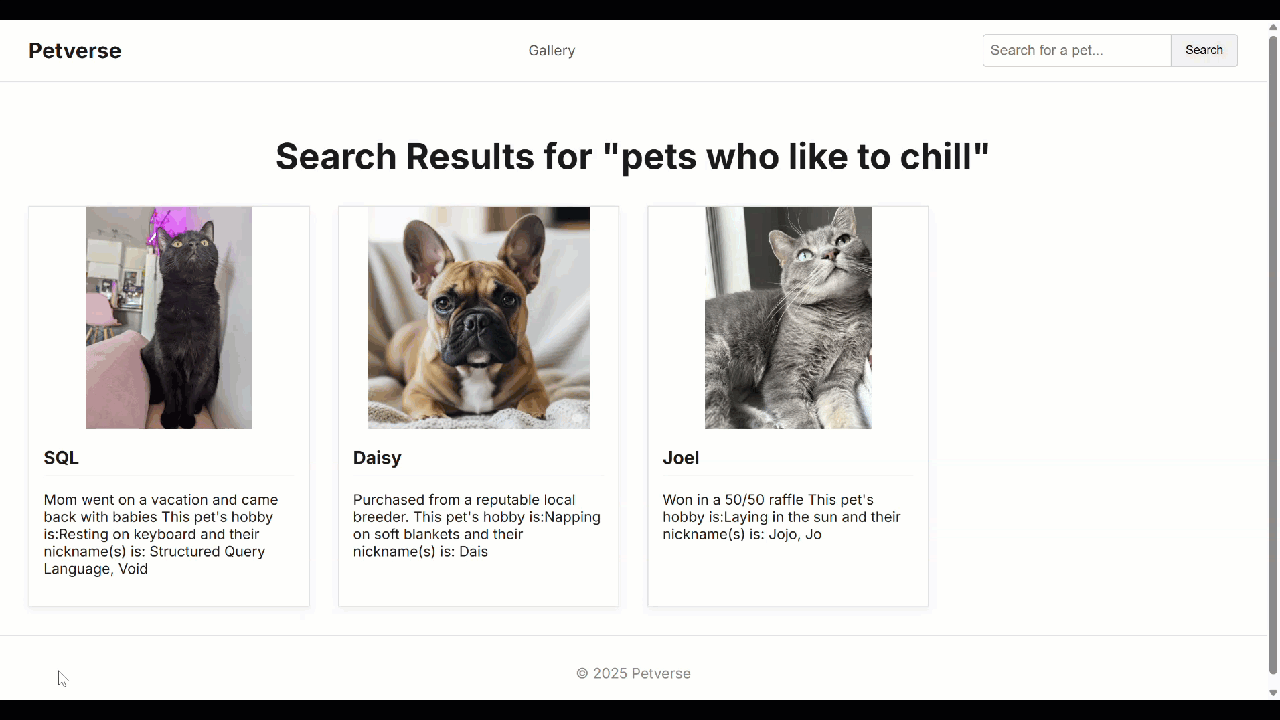
問題がなければ、必要に応じてアプリケーションを Cloud Run にデプロイできます。
プロジェクトが組織に属している場合は、こちらの手順に沿って IAP を構成してください。プロジェクトが組織の一部でない場合は、代わりにこちらの手順に沿ってアプリケーションへのアクセスを保護できます。特に本番環境の設定では、認証されていないアクセスを許可しないことをおすすめします。
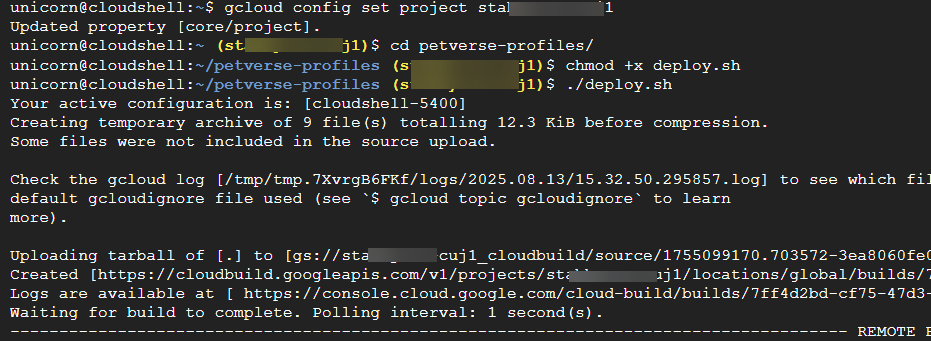
デプロイが成功すると、Cloud Run コンソールで Cloud Run アプリケーションが実行されていることがわかります。
アクセスが IAP のみであることを確認します。[Edit Policy] を使用して、ユーザーをバインディングに追加し、[Save] をクリックします。
IAP バインディングが伝播するまで数分待ってから、上部の URL をクリックします。サイトが表示されます。
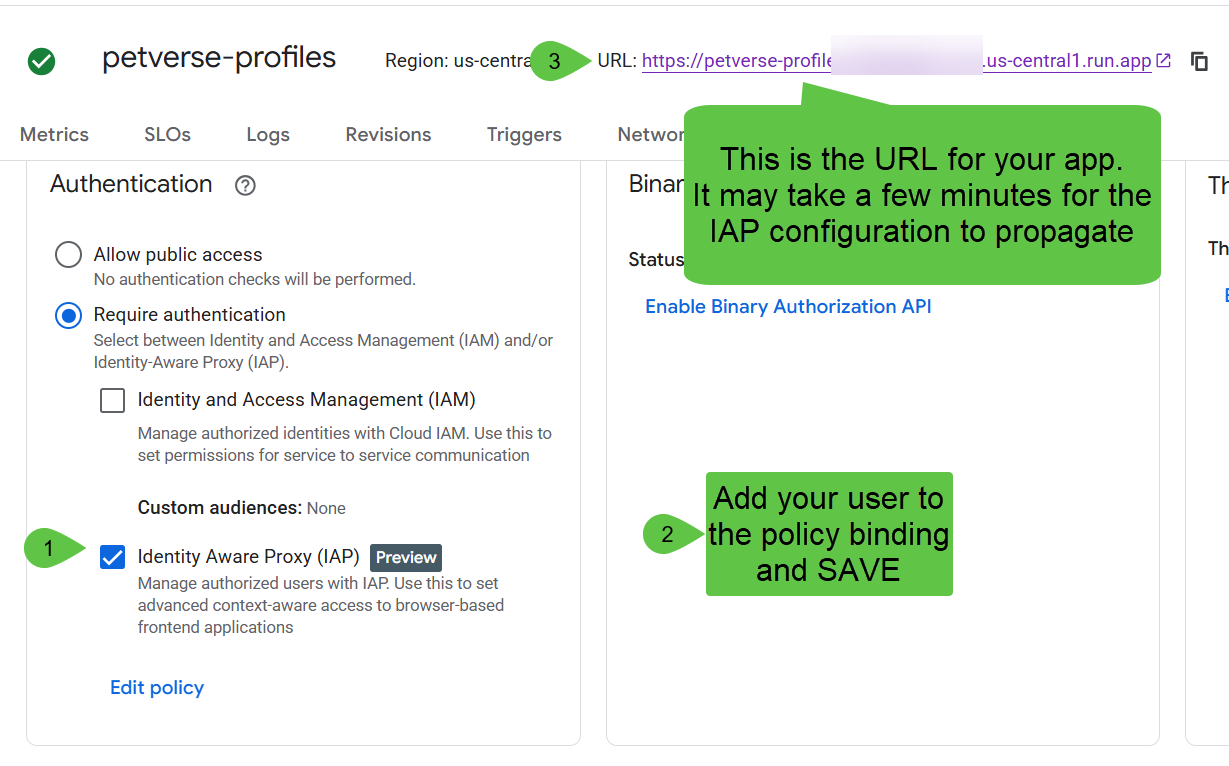
12. クリーンアップ
このステップでは、この Codelab で作成したリソースを削除します。
Cloud Run サービスを削除します(必要に応じて、サービス名とリージョンを調整します)。
gcloud run services delete petverse-profiles --region us-central1
すべての BigQuery アセットを削除します。
bq rm -f petverse
gcloud bigquery connections delete pet-connection --location=us-central1