
1. مقدمة
تُحدث النماذج اللغوية الكبيرة (LLM) تغييرًا في طريقة إنشاء التطبيقات الذكية. لكنّ إعداد هذه النماذج الفعّالة للاستخدام في العالم الحقيقي قد يكون أمرًا صعبًا. وهي تحتاج إلى قدر كبير من قوة الحوسبة، خاصةً بطاقات الرسومات (وحدات معالجة الرسومات)، وطرق ذكية للتعامل مع العديد من الطلبات في وقت واحد. بالإضافة إلى ذلك، تريد الحفاظ على انخفاض التكاليف وتشغيل تطبيقك بسلاسة بدون تأخير.
سيوضّح لك هذا الدرس التطبيقي حول الترميز كيفية مواجهة هذه التحديات. سنستخدم أداتَين رئيسيتَين:
- vLLM: يمكن اعتبارها محركًا فائق السرعة للنماذج اللغوية الكبيرة. ويجعل نماذجك تعمل بكفاءة أكبر، ما يتيح لها التعامل مع المزيد من الطلبات في الوقت نفسه وتقليل استخدام الذاكرة.
- Google Cloud Run: هذه هي منصة Google بدون خادم. إنّها رائعة لنشر التطبيقات لأنّها تتعامل مع جميع عمليات التوسيع نيابةً عنك، بدءًا من صفر مستخدم إلى آلاف المستخدمين، ثم العودة إلى العدد الأصلي. والأفضل من ذلك أنّ Cloud Run يتيح الآن استخدام وحدات معالجة الرسومات، وهي ضرورية لاستضافة النماذج اللغوية الكبيرة.
توفّر vLLM وCloud Run معًا طريقة فعّالة ومرنة وفعّالة من حيث التكلفة لتشغيل نماذج اللغات الكبيرة. في هذا الدليل، ستنشر نموذجًا مفتوح المصدر، ما يتيحه كواجهة برمجة تطبيقات ويب عادية.
أهداف الدورة التعليمية
- كيفية اختيار حجم النموذج المناسب ومتغيره المناسب للعرض
- كيفية إعداد vLLM لعرض نقاط نهاية متوافقة مع واجهة برمجة التطبيقات من OpenAI
- كيفية إنشاء حاوية لخادم vLLM باستخدام Docker
- كيفية نشر صورة الحاوية إلى Google Artifact Registry
- كيفية نشر الحاوية إلى Cloud Run مع تسريع وحدة معالجة الرسومات
- كيفية اختبار النموذج الذي تم نشره
المتطلبات
- متصفّح، مثل Chrome، للوصول إلى "وحدة تحكّم Google Cloud"
- اتصال موثوق بالإنترنت
- مشروع Google Cloud تم تفعيل الفوترة فيه
- رمز دخول Hugging Face (يمكنك إنشاء رمز هنا إذا لم يكن لديك رمز بعد)
- معرفة أساسية بلغة Python وDocker وواجهة سطر الأوامر
- عقل فضولي وشغف بالتعلّم
2. قبل البدء
إعداد مشروع Google Cloud
يتطلّب هذا الدرس العملي مشروعًا على Google Cloud مع حساب فوترة نشط.
- بالنسبة إلى الجلسات التي يقودها مدرّب: إذا كنت في صف، سيقدّم لك المدرّب معلومات المشروع والفوترة اللازمة. اتّبِع التعليمات التي يقدّمها لك المعلّم لإكمال عملية الإعداد.
- للمتعلّمين المستقلين: إذا كنت تجري هذه العملية بمفردك وليس لديك حساب فوترة نشط حالي، عليك إعداد حساب فوترة باستخدام معلومات الدفع الخاصة بك. راجِع مستندات "فوترة Google Cloud" لإنشاء حساب فوترة جديد وتفعيله لمشروعك.
إنشاء مشروع على Google Cloud
للحفاظ على تنظيم جميع أعمالك في هذا الدرس التطبيقي حول الترميز وفصلها عن المشاريع الأخرى، ستبدأ بإنشاء مشروع جديد على Google Cloud.
لفتح صفحة إنشاء المشروع، انقر على:
أدخِل المعلومات المطلوبة في صفحة إنشاء المشروع:
- اسم المشروع: يمكنك إدخال أي اسم تريده (مثل genai-workshop).
- الموقع الجغرافي: اتركه على بدون مؤسسة
- حساب الفوترة: إذا ظهر هذا الخيار، اختَر "حساب الفوترة التجريبي في Google Cloud Platform" أو حساب الفوترة الخاص بك إذا كنت تفضّل ذلك. إذا لم يظهر لك هذا الخيار، يمكنك الانتقال إلى الخطوة التالية.
انسخ رقم تعريف المشروع الذي تم إنشاؤه، وستحتاج إليه لاحقًا. 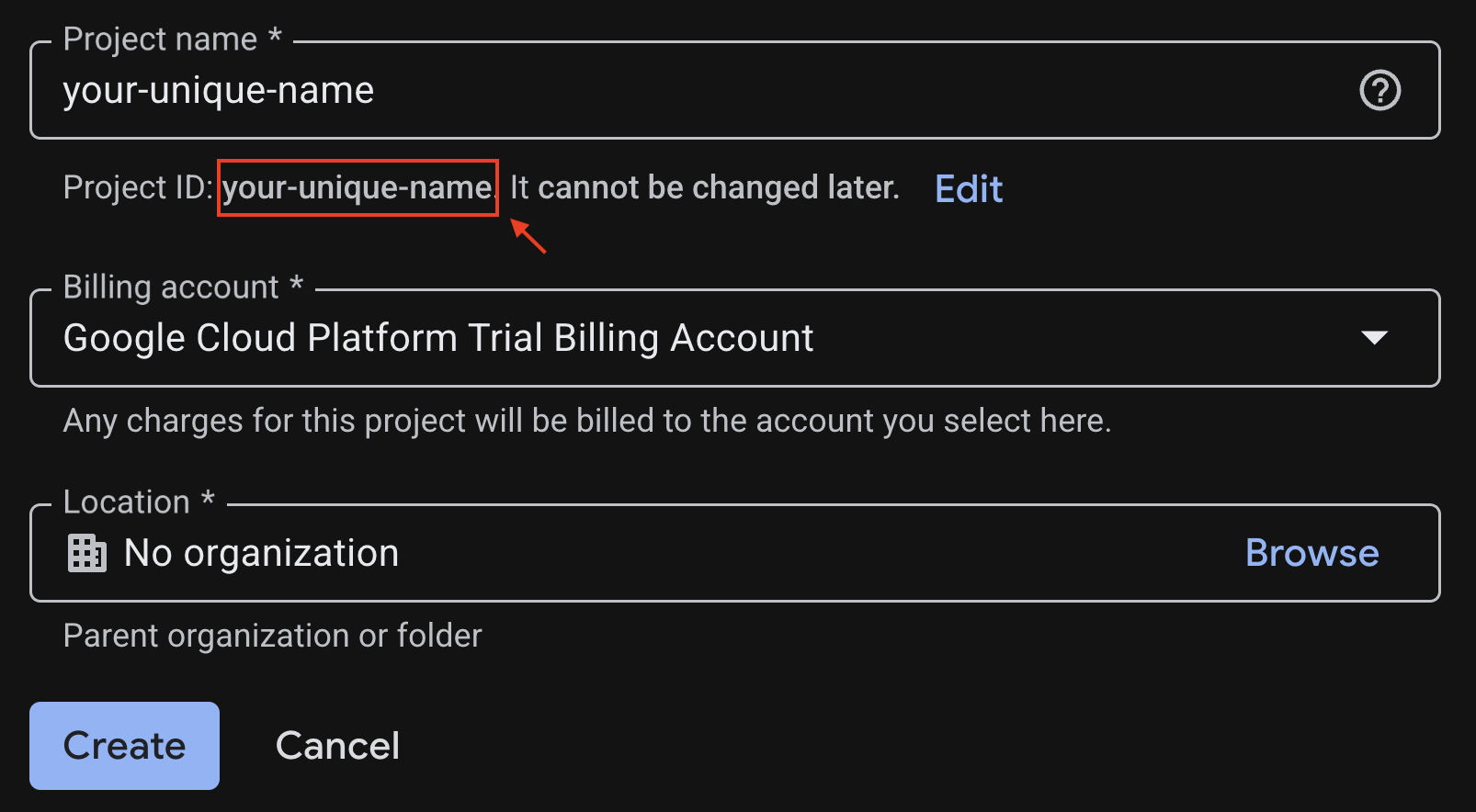
إذا كانت كل المعلومات صحيحة، انقر على الزر إنشاء.
ضبط Cloud Shell
Cloud Shell هي بيئة تم ضبطها مسبقًا وتتضمّن جميع الأدوات التي تحتاج إليها في هذا الدرس التطبيقي حول الترميز. بعد إنشاء مشروعك بنجاح، اتّبِع الخطوات التالية لإعداد Cloud Shell.
تشغيل Cloud Shell
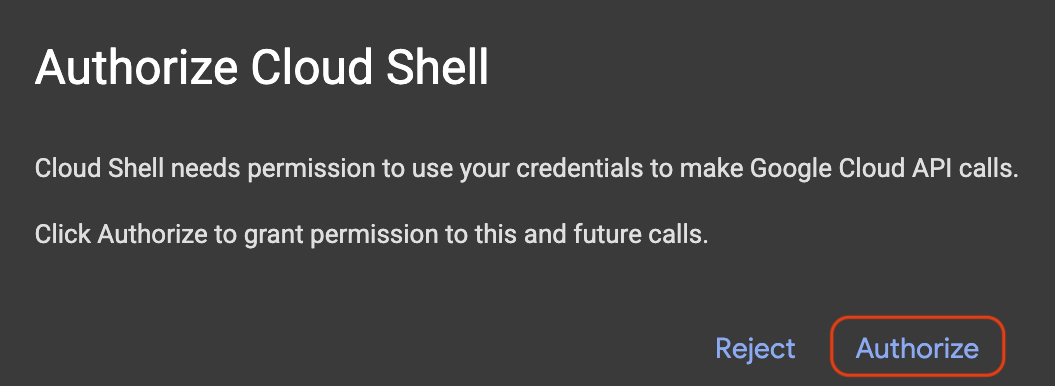
إذا ظهرت نافذة منبثقة تطلب التفويض، انقر على تفويض.
Set Project ID
استبدِل replace-with-your-project-id برقم تعريف مشروعك الفعلي من خطوة إنشاء المشروع أعلاه. نفِّذ الأمر التالي في وحدة Cloud Shell الطرفية لضبط رقم تعريف المشروع الصحيح.
gcloud config set project replace-with-your-project-id
من المفترض أن يظهر لك الآن أنّه تم اختيار المشروع الصحيح في نافذة Cloud Shell. يتم تمييز رقم تعريف المشروع المحدّد باللون الأصفر.

تفعيل واجهات برمجة التطبيقات اللازمة
لاستخدام خدمات Google Cloud، مثل Cloud Run، يجب أولاً تفعيل واجهات برمجة التطبيقات الخاصة بها لمشروعك. نفِّذ الأوامر التالية في Cloud Shell لتفعيل الخدمات اللازمة لهذا الدرس العملي:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3- اختيار النموذج المناسب
يمكنك العثور على العديد من النماذج المفتوحة على مواقع إلكترونية مثل Hugging Face Hub وKaggle. عندما تريد استخدام أحد هذه النماذج على خدمة مثل Google Cloud Run، عليك اختيار نموذج يتناسب مع الموارد المتوفرة لديك (أي وحدة معالجة الرسومات NVIDIA L4).
بالإضافة إلى الحجم، تذكَّر أن تأخذ في الاعتبار ما يمكن للنموذج فعله. فالنماذج ليست متشابهة، ولكل منها مزاياه وعيوبه. على سبيل المثال، يمكن لبعض النماذج التعامل مع أنواع مختلفة من المعلومات المدخلة (مثل الصور والنصوص، وهي ميزة تُعرف باسم إمكانات تعدّد الوسائط)، بينما يمكن للبعض الآخر تذكُّر المزيد من المعلومات ومعالجتها في وقت واحد (ما يعني أنّ لديها قدرة استيعاب أكبر). في كثير من الأحيان، تتضمّن النماذج الأكبر حجمًا إمكانات أكثر تقدّمًا، مثل استدعاء الدوال والتفكير.
من المهم أيضًا التحقّق مما إذا كان النموذج المطلوب متوافقًا مع أداة العرض (vLLM في هذه الحالة). يمكنك الاطّلاع هنا على جميع الطُرز المتوافقة مع vLLM.
لنستكشف الآن Gemma 3، وهي أحدث مجموعة من النماذج اللغوية الكبيرة (LLM) المتاحة للجميع من Google. تتوفّر Gemma 3 بأربعة أحجام مختلفة استنادًا إلى مدى تعقيدها، ويتم قياسها بالمَعلمات: مليار و4 مليارات و12 مليارًا و27 مليارًا.
لكل من هذه الأحجام، ستجد نوعَين رئيسيَّين:
- الإصدار الأساسي (المدرَّب مسبقًا): هذا هو النموذج الأساسي الذي تعلّم من كمية هائلة من البيانات.
- إصدار معدَّل للتعليمات: تم تحسين هذا الإصدار بشكل أكبر لفهم التعليمات أو الأوامر المحدّدة واتّباعها بشكل أفضل.
النماذج الأكبر (4 مليارات و12 مليارًا و27 مليار مَعلمة) هي متعددة الوسائط، ما يعني أنّها يمكنها فهم الصور والنصوص والتعامل معها. ومع ذلك، يركّز أصغر صيغة من نموذج المليار معلَمة على النص فقط.
في هذا الدرس التطبيقي حول الترميز، سنستخدم مليار متغيّر من Gemma 3: gemma-3-1b-it. يساعدك استخدام نموذج أصغر أيضًا في تعلُّم كيفية العمل بموارد محدودة، وهو أمر مهم للحفاظ على انخفاض التكاليف وضمان تشغيل تطبيقك بسلاسة على السحابة الإلكترونية.
4. متغيرات البيئة والأسرار
إنشاء ملف بيئة
قبل المتابعة، من الممارسات الجيدة أن تكون جميع الإعدادات التي ستستخدمها خلال هذا الدرس التطبيقي متوفّرة في مكان واحد. للبدء، افتح الوحدة الطرفية واتّبِع الخطوات التالية:
- أنشئ مجلدًا جديدًا لهذا المشروع.
- انتقِل إلى المجلد الذي تم إنشاؤه حديثًا.
- أنشئ ملف .env فارغًا داخل هذا المجلد (سيحتوي هذا الملف لاحقًا على متغيرات البيئة).
في ما يلي الأمر اللازم لتنفيذ هذه الخطوات:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
بعد ذلك، انسخ المتغيرات المدرَجة أدناه والصِقها في ملف .env الذي أنشأته للتو.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
تذكَّر استبدال قيم العناصر النائبة (your_project_id وyour_region) بمعلومات مشروعك المحدّدة. على سبيل المثال (PROJECT_ID=unique-ai-project وREGION=europe-west4)، يمكنك الاطّلاع هنا على قائمة المناطق التي تتيح استخدام وحدات معالجة الرسومات على Cloud Run.
بعد تعديل ملف.env وحفظه، اكتب هذا الأمر لتحميل متغيرات البيئة هذه إلى جلسة الوحدة الطرفية:
source .env
يمكنك اختبار ما إذا كان قد تم تحميل المتغيّرات بنجاح أم لا من خلال عرض أحد المتغيّرات. على سبيل المثال:
echo $SERVICE_NAME
إذا حصلت على القيمة نفسها التي حدّدتها في ملف .env، يعني ذلك أنّه تم تحميل المتغيّرات بنجاح.
تخزين سرّ في Secret Manager
بالنسبة إلى أي بيانات حساسة، بما في ذلك رموز الوصول وبيانات الاعتماد وكلمات المرور، يُنصح باستخدام خدمة إدارة الأسرار.
قبل استخدام نماذج Gemma 3، يجب أولاً الإقرار بالأحكام والشروط، لأنّها محمية. يمكنك الإقرار بالبنود والشروط من خلال بطاقة نموذج Gamma 3 على Hugging Face Hub.
بعد الحصول على رمز الوصول إلى Hugging Face، انتقِل إلى صفحة Secret Manager وأنشئ سرًا باتّباع هذه التعليمات.
- الانتقال إلى Google Cloud Console
- اختَر المشروع من شريط القائمة المنسدلة في أعلى يمين الصفحة
- ابحث عن Secret Manager في شريط البحث وانقر على هذا الخيار عند ظهوره.
عندما تكون في صفحة Secret Manager:
- انقر على الزر +إنشاء رمز سرّي.
- أدخِل المعلومات التالية:
- الاسم: HF_TOKEN
- قيمة المفتاح السرّي: <your_hf_access_token>
- انقر على الزر إنشاء سر عند الانتهاء.
يجب أن يكون لديك الآن رمز الوصول إلى Hugging Face كبيانات سرية على Google Cloud Secret Manager.
يمكنك اختبار إمكانية الوصول إلى كلمة المرور السرية من خلال تنفيذ الأمر أدناه في الوحدة الطرفية، وسيسترجع هذا الأمر كلمة المرور السرية من Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
من المفترض أن يظهر لك رمز الدخول الذي تم استرداده في نافذة الوحدة الطرفية.
منح إذن الوصول إلى الأسرار لحساب خدمة Cloud Build
بما أنّ المفتاح السري مخزَّن الآن بأمان في Secret Manager،
نفِّذ الأوامر التالية في الوحدة الطرفية لإجراء ذلك:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5- إنشاء حساب خدمة
لتعزيز الأمان وإدارة الوصول بفعالية في بيئة الإنتاج، يجب أن تعمل الخدمات ضمن حسابات خدمة مخصّصة تقتصر بشكل صارم على الأذونات اللازمة لمهامها المحدّدة.
نفِّذ هذا الأمر لإنشاء حساب خدمة
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
يضيف الأمر التالي الإذن اللازم
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. إنشاء صورة على Artifact Registry
تتضمّن هذه الخطوة إنشاء صورة Docker تتضمّن أوزان النموذج وvLLM مثبّتة مسبقًا.
1. إنشاء مستودع Docker على Artifact Registry
لننشئ مستودع Docker في Artifact Registry لنشر الصور التي تم إنشاؤها. نفِّذ الأمر التالي في الوحدة الطرفية:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. تخزين النموذج
استنادًا إلى مستند أفضل الممارسات المتعلّقة بوحدات معالجة الرسومات، يمكنك إما تخزين نماذج تعلُّم الآلة داخل صور الحاويات أو تحسين تحميلها من Cloud Storage.
بالطبع، لكل أسلوب إيجابياته وسلبياته. يمكنك قراءة المستندات لمعرفة المزيد عنها. لتبسيط الأمر، سنخزّن النموذج في صورة الحاوية فقط. يمكنك إجراء ذلك في الجلسة التالية.
3. إنشاء ملف Docker
أنشئ ملفًا باسم Dockerfile وانسخ المحتوى أدناه إليه:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. إنشاء ملف yaml للنشر
بعد ذلك، أنشِئ ملفًا باسم cloudbuild.yaml في الدليل نفسه. يحدّد هذا الملف الخطوات التي يجب أن تتّبعها Cloud Build. انسخ المحتوى التالي والصقه في ملف cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. إرسال الإصدار إلى Cloud Build
انسخ الرمز التالي والصقه ونفِّذه في الوحدة الطرفية:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
يحمّل هذا الأمر الرمز البرمجي (Dockerfile وcloudbuild.yaml) ويمرّر متغيّرات الصدفة كبدائل (_MODEL_NAME و_IMAGE_NAME) ويبدأ عملية الإنشاء.
ستنفّذ Cloud Build الآن الخطوات المحدّدة في cloudbuild.yaml. يمكنك تتبُّع السجلات في نافذة الأوامر أو من خلال النقر على رابط تفاصيل الإصدار في Cloud Console. بعد اكتمال العملية، ستتوفّر صورة الحاوية في مستودع Artifact Registry، وستكون جاهزة للنشر.
6- النشر على Cloud Run
أنت الآن جاهز لنشر الخدمة على Cloud Run. نفِّذ الأمر التالي في الوحدة الطرفية:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. اختبار الخدمة
شغِّل الأمر التالي في الوحدة الطرفية لإنشاء خادم وكيل، حتى تتمكّن من الوصول إلى الخدمة أثناء تشغيلها في المضيف المحلي:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
في نافذة وحدة طرفية جديدة، شغِّل أمر curl التالي في الوحدة الطرفية لاختبار الاتصال
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
إذا ظهرت لك نتيجة مشابهة لما يلي:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. الخاتمة
تهانينا! لقد أكملت هذا الدرس التطبيقي حول الترميز بنجاح. لقد تعلّمت كيفية:
- اختَر حجم نموذج مناسبًا لعملية نشر مستهدَفة.
- إعداد vLLM لعرض واجهة برمجة تطبيقات متوافقة مع OpenAI
- وضع خادم vLLM وأوزان النموذج في حاوية بشكل آمن باستخدام Docker
- إرسال صورة حاوية إلى Google Artifact Registry
- نشر خدمة مسرَّعة بواسطة وحدة معالجة الرسومات على Cloud Run
- اختبار نموذج تمّت المصادقة عليه ونشره
يمكنك استكشاف طرق تفعيل نماذج أخرى رائعة مثل Llama أو Mistral أو Qwen لمواصلة رحلتك التعليمية.
9- تنظيف
لتجنُّب تحمّل رسوم مستقبلية، من المهم حذف الموارد التي أنشأتها. نفِّذ الأوامر التالية لتنظيف مشروعك.
1. احذف خدمة Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. احذف مستودع Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. احذف حساب الخدمة:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. احذف المفتاح السرّي من Secret Manager:
gcloud secrets delete HF_TOKEN --quiet