
1. Einführung
Large Language Models (LLMs) verändern die Art und Weise, wie wir intelligente Anwendungen entwickeln. Es kann jedoch schwierig sein, diese leistungsstarken Modelle für den Einsatz in der Praxis vorzubereiten. Sie benötigen viel Rechenleistung, insbesondere Grafikprozessoren (GPUs), und intelligente Möglichkeiten, viele Anfragen gleichzeitig zu verarbeiten. Außerdem möchten Sie die Kosten niedrig halten und Ihre Anwendung ohne Verzögerungen reibungslos ausführen.
In diesem Codelab erfahren Sie, wie Sie diese Herausforderungen meistern. Wir verwenden zwei wichtige Tools:
- vLLM: Stellen Sie sich das als superschnelle Engine für LLMs vor. Damit können Sie Ihre Modelle viel effizienter ausführen, mehr Anfragen gleichzeitig verarbeiten und den Arbeitsspeicherverbrauch reduzieren.
- Google Cloud Run: Dies ist die serverlose Plattform von Google. Sie eignet sich hervorragend für die Bereitstellung von Anwendungen, da sie die gesamte Skalierung für Sie übernimmt – von null auf Tausende von Nutzern und wieder zurück. Das Beste daran: Cloud Run unterstützt jetzt GPUs, die für das Hosting von LLMs unerlässlich sind.
Zusammen bieten vLLM und Cloud Run eine leistungsstarke, flexible und kostengünstige Möglichkeit, Ihre LLMs bereitzustellen. In dieser Anleitung stellen Sie ein offenes Modell bereit, das als Standard-Web-API verfügbar ist.
Lerninhalte
- Auswahl der richtigen Modellgröße und -variante für die Bereitstellung
- Einrichtung von vLLM zur Bereitstellung von OpenAI-kompatiblen API-Endpunkten
- Containerisierung des vLLM-Servers mit Docker
- Übertragen Ihres Container-Images per Push an Google Artifact Registry
- Bereitstellung des Containers in Cloud Run mit GPU-Beschleunigung
- Testen des bereitgestellten Modells
Voraussetzungen
- Ein Browser wie Chrome für den Zugriff auf die Google Cloud Console
- Eine zuverlässige Internetverbindung
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Ein Hugging Face-Zugriffstoken (erstellen Sie hier eines, falls Sie noch keines haben)
- Grundkenntnisse in Python, Docker und der Befehlszeilenschnittstelle
- Neugier und Lernbereitschaft
2. Vorbereitung
Google Cloud-Projekt einrichten
Für dieses Codelab ist ein Google Cloud-Projekt mit einem aktiven Rechnungskonto erforderlich.
- Für von Kursleitern geführte Sitzungen:Wenn Sie sich in einem Kursraum befinden, stellt Ihnen Ihr Kursleiter die erforderlichen Projekt- und Abrechnungsinformationen zur Verfügung. Folgen Sie der Anleitung Ihres Kursleiters, um die Einrichtung abzuschließen.
- Für unabhängige Lernende:Wenn Sie dieses Codelab selbstständig durcharbeiten und kein aktives Rechnungskonto haben, müssen Sie ein Rechnungskonto mit Ihren eigenen Zahlungsinformationen einrichten. In der Google Cloud-Abrechnungsdokumentation erfahren Sie, wie Sie ein neues Rechnungskonto erstellen und für Ihr Projekt aktivieren.
Google Cloud-Projekt erstellen
Damit Ihre gesamte Arbeit für dieses Codelab organisiert und von anderen Projekten getrennt ist, erstellen Sie zuerst ein neues Google Cloud-Projekt.
Klicken Sie auf „“, um die Seite zum Erstellen von Projekten zu öffnen.
Geben Sie auf der Seite zum Erstellen von Projekten die erforderlichen Informationen ein:
- Projektname : Sie können einen beliebigen Namen eingeben (z. B. „genai-workshop“).
- Standort : Lassen Sie die Einstellung Keine Organisation.
- Rechnungskonto : Wenn diese Option angezeigt wird, wählen Sie „Rechnungskonto für den kostenlosen Testzeitraum von Google Cloud Platform“ oder Ihr eigenes Rechnungskonto aus. Wenn diese Option nicht angezeigt wird, können Sie mit dem nächsten Schritt fortfahren.
Notieren Sie sich die generierte Projekt-ID, da Sie sie später benötigen. 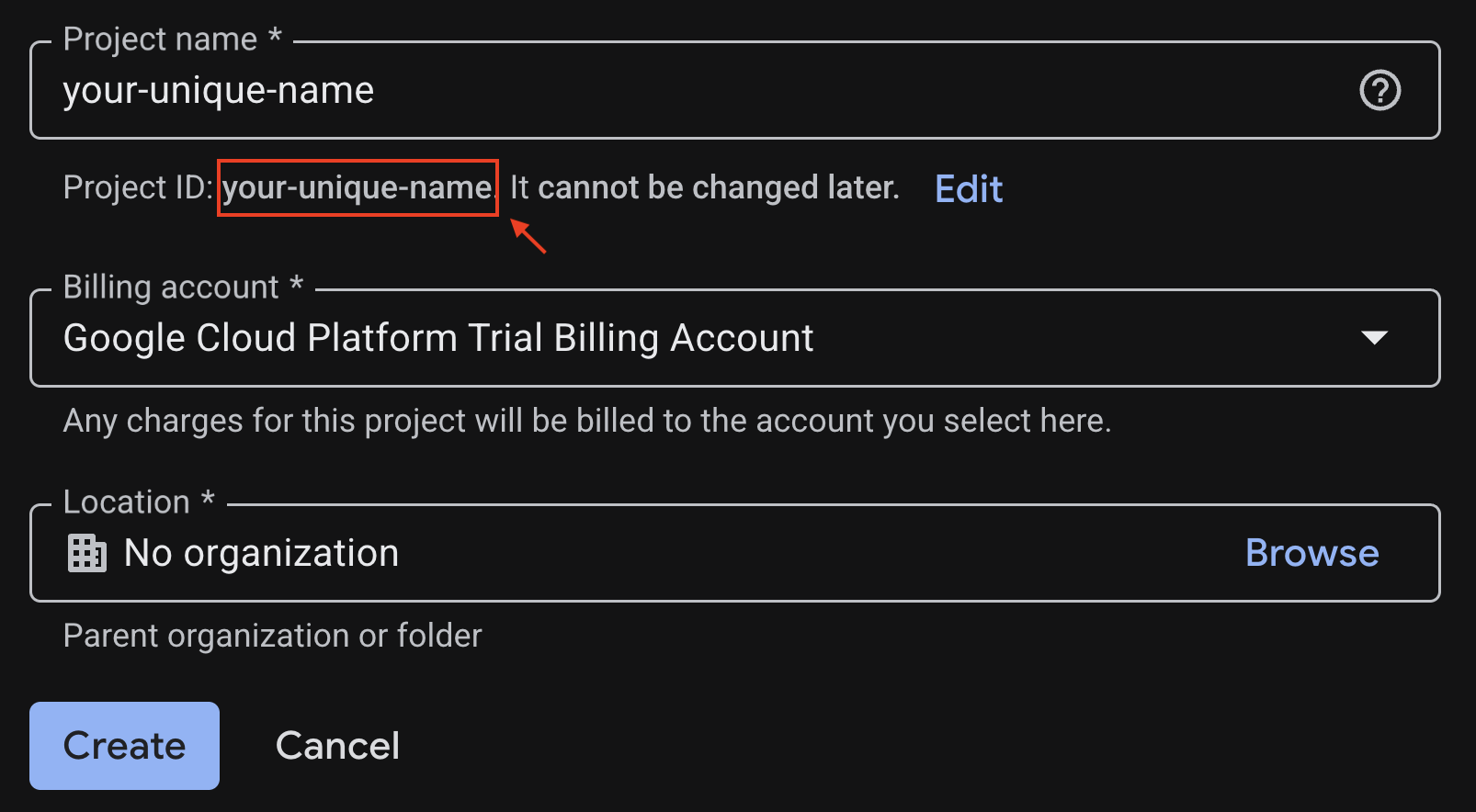
Wenn alles in Ordnung ist, klicken Sie auf die Schaltfläche Erstellen.
Cloud Shell konfigurieren
Cloud Shell ist eine vorkonfigurierte Umgebung mit allen Tools, die Sie für dieses Codelab benötigen. Nachdem Sie Ihr Projekt erfolgreich erstellt haben, führen Sie die folgenden Schritte aus, um Cloud Shell einzurichten.
Cloud Shell starten
Klicken Sie auf „Cloud Shell starten“, um Cloud Shell zu starten:
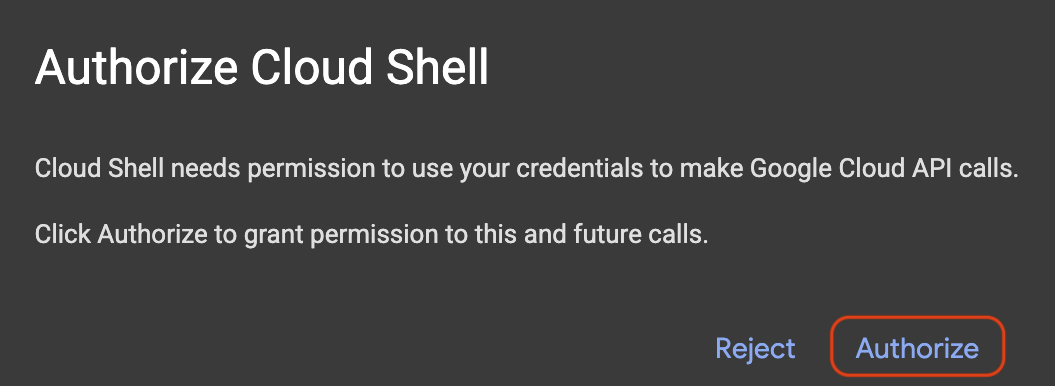
Wenn ein Pop-up zur Autorisierung angezeigt wird, klicken Sie auf Autorisieren.
Projekt-ID festlegen
Ersetzen Sie replace-with-your-project-id durch Ihre tatsächliche Projekt-ID aus dem Schritt zum Erstellen des Projekts oben. Führen Sie den folgenden Befehl im Cloud Shell-Terminal aus, um die richtige Projekt-ID festzulegen.
gcloud config set project replace-with-your-project-id
Sie sollten jetzt sehen, dass das richtige Projekt im Cloud Shell-Terminal ausgewählt ist. Die ausgewählte Projekt-ID ist gelb hervorgehoben.

Erforderliche APIs aktivieren
Wenn Sie Google Cloud-Dienste wie Cloud Run verwenden möchten, müssen Sie zuerst die entsprechenden APIs für Ihr Projekt aktivieren. Führen Sie die folgenden Befehle in Cloud Shell aus, um die für dieses Codelab erforderlichen Dienste zu aktivieren:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Das richtige Modell auswählen
Viele offene Modelle finden Sie auf Websites wie Hugging Face Hub und Kaggle. Wenn Sie eines dieser Modelle in einem Dienst wie Google Cloud Run verwenden möchten, müssen Sie eines auswählen, das zu den verfügbaren Ressourcen passt (d.h. NVIDIA L4-GPU).
Neben der Größe sollten Sie auch berücksichtigen, was das Modell tatsächlich leisten kann. Modelle sind nicht alle gleich. Jedes hat seine eigenen Vor- und Nachteile. Einige Modelle können beispielsweise verschiedene Arten von Eingaben verarbeiten (z. B. Bilder und Text – multimodale Funktionen), während andere mehr Informationen gleichzeitig speichern und verarbeiten können (d. h. sie haben größere Kontextfenster). Größere Modelle haben oft erweiterte Funktionen wie Funktionsaufrufe und „Denken“.
Außerdem ist es wichtig zu prüfen, ob das gewünschte Modell vom Bereitstellungstool unterstützt wird (in diesem Fall vLLM). Hier finden Sie alle Modelle, die von vLLM unterstützt werden hier.
Sehen wir uns nun Gemma 3 an, die neueste Familie von öffentlich verfügbaren Large Language Models (LLMs) von Google. Gemma 3 ist in vier verschiedenen Größen verfügbar, die auf ihrer Komplexität basieren und in Parametern gemessen werden: 1 Milliarde, 4 Milliarden, 12 Milliarden und 27 Milliarden.
Für jede dieser Größen gibt es zwei Haupttypen:
- Eine Basisversion (vortrainiert): Dies ist das Foundation Model, das aus einer riesigen Datenmenge gelernt hat.
- Eine für Anweisungen optimierte Version: Diese Version wurde weiter verfeinert, um bestimmte Anweisungen oder Befehle besser zu verstehen und auszuführen.
Die größeren Modelle (4 Milliarden, 12 Milliarden und 27 Milliarden Parameter) sind multimodal, d. h. sie können sowohl Bilder als auch Text verstehen und verarbeiten. Die kleinste Variante mit 1 Milliarde Parametern konzentriert sich jedoch ausschließlich auf Text.
Für dieses Codelab verwenden wir Varianten von Gemma 3 mit 1 Milliarde Parametern: gemma-3-1b-it. Wenn Sie ein kleineres Modell verwenden, lernen Sie auch, wie Sie mit begrenzten Ressourcen arbeiten können. Das ist wichtig, um die Kosten niedrig zu halten und dafür zu sorgen, dass Ihre App in der Cloud reibungslos ausgeführt wird.
4. Umgebungsvariablen und Secrets
Umgebungsdatei erstellen
Bevor wir fortfahren, ist es ratsam, alle Konfigurationen, die Sie in diesem Codelab verwenden, an einem Ort zu speichern. Öffnen Sie dazu das Terminal und führen Sie die folgenden Schritte aus:
- Erstellen Sie einen neuen Ordner für dieses Projekt.
- Wechseln Sie zum neu erstellten Ordner.
- Erstellen Sie in diesem Ordner eine leere Datei .env (diese Datei enthält später Ihre Umgebungsvariablen).
Hier ist der Befehl, um diese Schritte auszuführen:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Kopieren Sie als Nächstes die unten aufgeführten Variablen und fügen Sie sie in die gerade erstellte Datei .env ein.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Ersetzen Sie die Platzhalterwerte (your_project_id und your_region) durch Ihre spezifischen Projektinformationen. Beispiel: (PROJECT_ID=unique-ai-project und REGION=europe-west4). Hier finden Sie eine Liste der Regionen, die GPUs in Cloud Run unterstützen.
Nachdem Sie die Datei .env bearbeitet und gespeichert haben, geben Sie diesen Befehl ein, um die Umgebungsvariablen in die Terminalsitzung zu laden:
source .env
Sie können testen, ob die Variablen erfolgreich geladen wurden, indem Sie eine der Variablen ausgeben. Beispiel:
echo $SERVICE_NAME
Wenn Sie denselben Wert erhalten, den Sie in der Datei .env zugewiesen haben, wurden die Variablen erfolgreich geladen.
Secret in Secret Manager speichern
Für alle vertraulichen Daten, einschließlich Zugriffscodes, Anmeldedaten und Passwörter, wird die Verwendung eines Secret Managers empfohlen.
Bevor Sie Gemma 3-Modelle verwenden können, müssen Sie die Nutzungsbedingungen akzeptieren, da sie eingeschränkt sind. Sie können die Nutzungsbedingungen über die Gemma 3-Modellkarte im Hugging Face Hub akzeptieren.
Sobald Sie das Hugging Face-Zugriffstoken haben, rufen Sie die Seite „Secret Manager“ auf und erstellen Sie ein Secret. Folgen Sie dazu dieser Anleitung.
- Rufen Sie die Google Cloud Console auf.
- Wählen Sie das Projekt in der Drop-down-Leiste oben links aus.
- Suchen Sie in der Suchleiste nach Secret Manager und klicken Sie auf diese Option, wenn sie angezeigt wird.
Wenn Sie sich auf der Seite „Secret Manager“ befinden:
- Klicken Sie auf die Schaltfläche + Secret erstellen.
- Geben Sie die folgenden Informationen ein:
- Name: HF_TOKEN
- Secret-Wert: <your_hf_access_token>
- Klicken Sie auf die Schaltfläche Secret erstellen , wenn Sie fertig sind.
Das Hugging Face-Zugriffstoken sollte jetzt als Secret in Google Cloud Secret Manager gespeichert sein.
Sie können Ihren Zugriff auf das Secret testen, indem Sie den folgenden Befehl im Terminal ausführen. Mit diesem Befehl wird es aus Secret Manager abgerufen:
gcloud secrets versions access latest --secret=HF_TOKEN
Ihr Zugriffstoken sollte abgerufen und im Terminalfenster angezeigt werden.
Cloud Build-Dienstkonto Zugriff auf Secret gewähren
Da das Secret jetzt sicher in Secret Manager gespeichert ist,
führen Sie die folgenden Befehle im Terminal aus:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Dienstkonto erstellen
Um die Sicherheit zu erhöhen und den Zugriff in einer Produktionsumgebung effektiv zu verwalten, sollten Dienste unter dedizierten Dienstkonten ausgeführt werden, die streng auf die Berechtigungen beschränkt sind, die für ihre spezifischen Aufgaben erforderlich sind.
Führen Sie diesen Befehl aus, um ein Dienstkonto zu erstellen:
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
Mit dem folgenden Befehl wird die erforderliche Berechtigung angehängt:
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Image in Artifact Registry erstellen
In diesem Schritt erstellen Sie ein Docker-Image, das die Modellgewichtungen und ein vorinstalliertes vLLM enthält.
1. Docker-Repository in Artifact Registry erstellen
Erstellen wir ein Docker-Repository in Artifact Registry, um die erstellten Images per Push zu übertragen. Führen Sie im Terminal den folgenden Befehl aus:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Modell speichern
Gemäß der Dokumentation zu Best Practices für GPUs können Sie ML-Modelle entweder in Container-Images speichern oder das Laden aus Cloud Storage optimieren.
Natürlich hat jeder Ansatz seine eigenen Vor- und Nachteile. Weitere Informationen finden Sie in der Dokumentation. Der Einfachheit halber speichern wir das Modell im Container-Image. Das wird in der nächsten Sitzung beschrieben.
3. Dockerfile erstellen
Erstellen Sie eine Datei mit dem Namen Dockerfile und kopieren Sie den folgenden Inhalt hinein:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. YAML-Datei für die Bereitstellung erstellen
Erstellen Sie als Nächstes im selben Verzeichnis eine Datei mit dem Namen cloudbuild.yaml. In dieser Datei werden die Schritte für Cloud Build definiert. Kopieren Sie den folgenden Inhalt und fügen Sie ihn in die Datei „cloudbuild.yaml“ ein:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Build an Cloud Build senden
Kopieren Sie den folgenden Code und führen Sie ihn im Terminal aus:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Mit diesem Befehl wird Ihr Code (Dockerfile und cloudbuild.yaml) hochgeladen, Ihre Shell-Variablen als Ersetzungen (_MODEL_NAME und _IMAGE_NAME) übergeben und der Build gestartet.
Cloud Build führt nun die in cloudbuild.yaml definierten Schritte aus. Sie können die Logs im Terminal verfolgen oder auf den Link zu den Builddetails in der Cloud Console klicken. Nach Abschluss ist das Container-Image in Ihrem Artifact Registry-Repository verfügbar und kann bereitgestellt werden.
6. In Cloud Run bereitstellen
Jetzt können Sie den Dienst in Cloud Run bereitstellen. Führen Sie diesen Befehl im Terminal aus:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Dienst testen
Führen Sie den folgenden Befehl im Terminal aus, um einen Proxy zu erstellen, damit Sie auf den Dienst zugreifen können, während er lokal ausgeführt wird:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
Führen Sie in einem neuen Terminalfenster diesen curl-Befehl im Terminal aus, um die Verbindung zu testen:
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Wenn Sie eine ähnliche Ausgabe wie unten sehen:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Fazit
Glückwunsch! Sie haben dieses Codelab erfolgreich abgeschlossen. Sie haben Folgendes gelernt:
- Auswahl einer geeigneten Modellgröße für eine Zielbereitstellung
- Einrichtung von vLLM zur Bereitstellung einer OpenAI-kompatiblen API
- Sichere Containerisierung des vLLM-Servers und der Modellgewichtungen mit Docker
- Übertragen eines Container-Images per Push an Google Artifact Registry
- Bereitstellung eines GPU-beschleunigten Dienstes in Cloud Run
- Testen eines authentifizierten, bereitgestellten Modells
Sie können auch andere interessante Modelle wie Llama, Mistral oder Qwen bereitstellen, um Ihre Lernreise fortzusetzen.
9. Bereinigen
Um zukünftige Kosten zu vermeiden, müssen Sie die erstellten Ressourcen löschen. Führen Sie die folgenden Befehle aus, um Ihr Projekt zu bereinigen.
1. Cloud Run-Dienst löschen
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Artifact Registry-Repository löschen
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Dienstkonto löschen
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Secret aus Secret Manager löschen
gcloud secrets delete HF_TOKEN --quiet