
1. Introducción
Los modelos de lenguaje grandes (LLM) están cambiando la forma en que compilamos aplicaciones inteligentes. Sin embargo, preparar estos modelos potentes para el uso en el mundo real puede ser complicado. Necesitan mucha potencia de procesamiento, en especial tarjetas gráficas (GPU), y formas inteligentes de controlar muchas solicitudes a la vez. Además, debes mantener los costos bajos y tu aplicación funcionando sin problemas ni demoras.
En este codelab, se muestra cómo abordar estos desafíos. Usaremos dos herramientas clave:
- vLLM: Piensa en esto como un motor superrápido para LLM. Hace que tus modelos se ejecuten de manera mucho más eficiente, controlando más solicitudes a la vez y reduciendo el uso de memoria.
- Google Cloud Run: Esta es la plataforma sin servidores de Google. Es fantástica para implementar aplicaciones porque controla todo el ajuste de escala por ti, desde cero usuarios hasta miles, y viceversa. Lo mejor de todo es que Cloud Run ahora admite GPUs, que son esenciales para alojar LLM.
En conjunto, vLLM y Cloud Run ofrecen una forma potente, flexible y rentable de entregar tus LLM. En esta guía, implementarás un modelo abierto, lo que lo hará disponible como una API web estándar.
Qué aprenderás
- Cómo elegir el tamaño y la variante de modelo adecuados para la entrega
- Cómo configurar vLLM para entregar extremos de API compatibles con OpenAI
- Cómo organizar en contenedores el servidor vLLM con Docker
- Cómo enviar tu imagen de contenedor a Google Artifact Registry
- Cómo implementar el contenedor en Cloud Run con aceleración de GPU
- Cómo probar el modelo implementado
Requisitos
- Un navegador, como Chrome, para acceder a la consola de Google Cloud
- Una conexión a Internet confiable
- Un proyecto de Google Cloud con la facturación habilitada
- Un token de acceso de Hugging Face (crea uno aquí si aún no lo tienes)
- Conocimientos básicos sobre Python, Docker y la interfaz de línea de comandos
- Una mente curiosa y ganas de aprender
2. Antes de comenzar
Configura el proyecto de Google Cloud
Este codelab requiere un proyecto de Google Cloud con una cuenta de facturación activa.
- Para sesiones dirigidas por un instructor: Si estás en un aula, el instructor te proporcionará la información necesaria sobre el proyecto y la facturación. Sigue las instrucciones del instructor para completar la configuración.
- Para estudiantes independientes: Si lo haces por tu cuenta y no tienes una cuenta de facturación activa existente, deberás configurar una con tu información de pago. Consulta la documentación de Facturación de Google Cloud para crear una cuenta de facturación nueva y habilitarla para tu proyecto.
Crea un proyecto de Google Cloud
Para mantener todo tu trabajo de este codelab organizado y separado de otros proyectos, comenzarás por crear un proyecto nuevo de Google Cloud.
Para abrir la página de creación del proyecto, haz clic en .
Ingresa la información requerida en la página de creación del proyecto:
- Nombre del proyecto : Puedes ingresar el nombre que desees (p. ej., genai-workshop).
- Ubicación: Déjalo como Sin organización.
- Cuenta de facturación : Si aparece esta opción, selecciona "Cuenta de facturación de prueba de Google Cloud Platform" o tu propia cuenta de facturación si lo prefieres. Si no ves esta opción, puedes continuar con el siguiente paso.
Copia el ID del proyecto generado, ya que lo necesitarás más adelante. 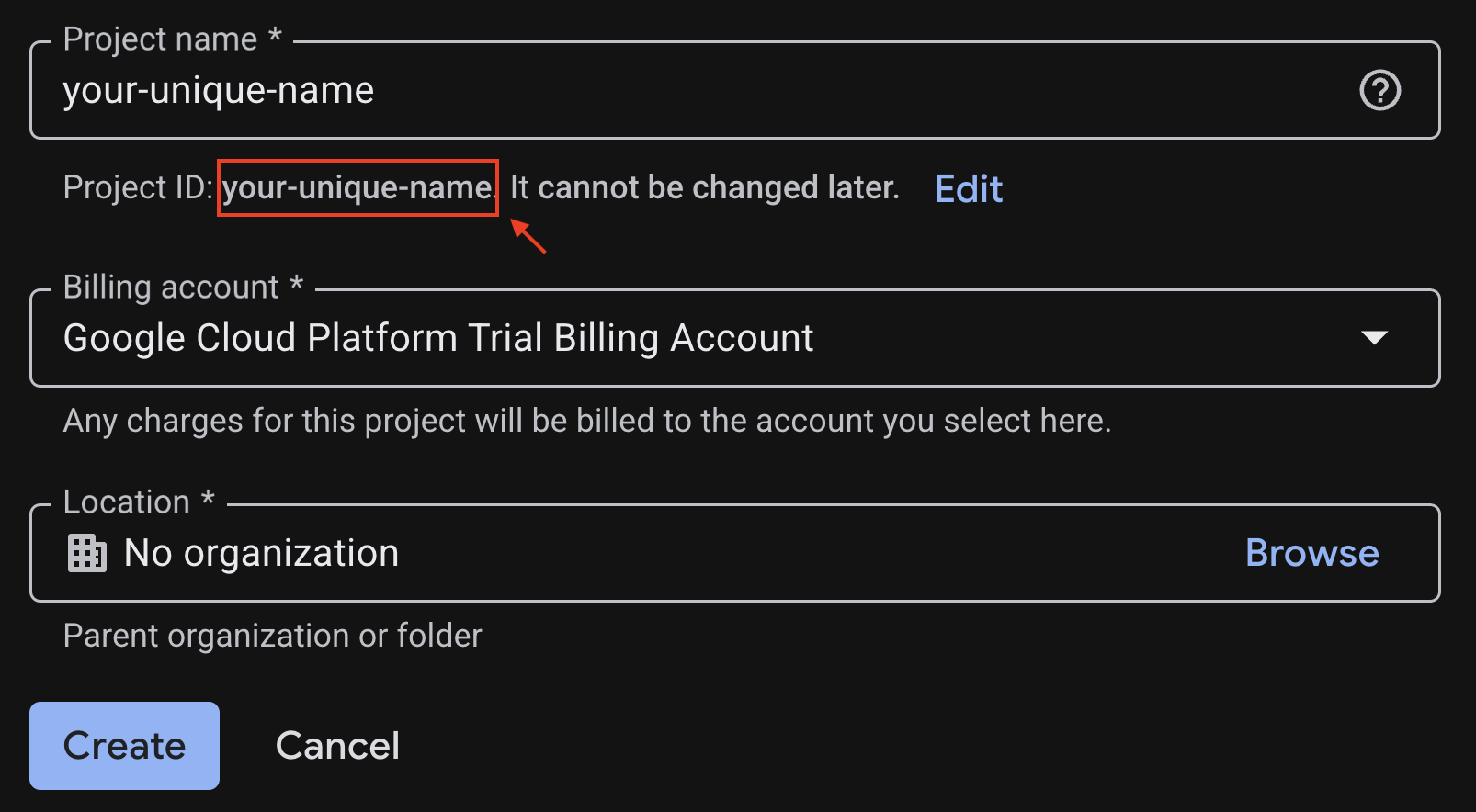
Si todo está bien, haz clic en el botón Crear.
Configura Cloud Shell
Cloud Shell es un entorno preconfigurado con todas las herramientas que necesitas para este codelab. Una vez que se cree el proyecto correctamente, sigue estos pasos para configurar Cloud Shell.
Inicia Cloud Shell
Para iniciar Cloud Shell, haz clic en .
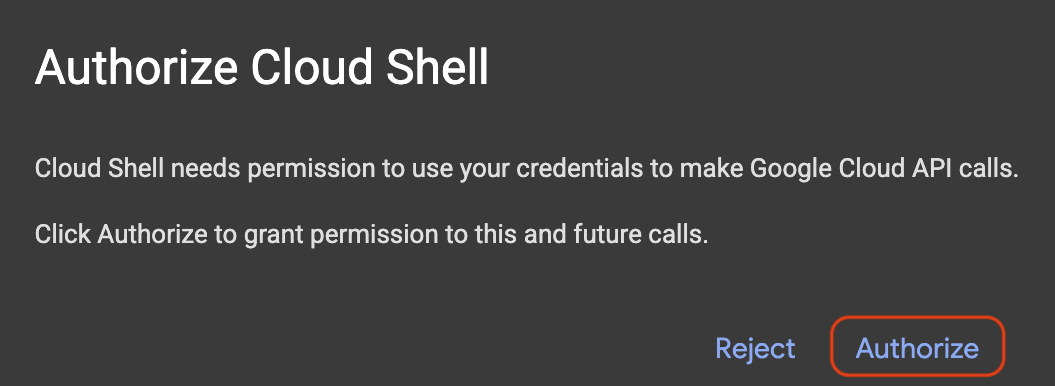
Si aparece una ventana emergente que solicita autorización, haz clic en Autorizar.
Configura el ID del proyecto
Reemplaza replace-with-your-project-id por el ID del proyecto real del paso de creación del proyecto anterior. Ejecuta el siguiente comando en la terminal de Cloud Shell para configurar el ID del proyecto correcto.
gcloud config set project replace-with-your-project-id
Ahora deberías ver que se seleccionó el proyecto correcto en la terminal de Cloud Shell. El ID del proyecto seleccionado se destaca en amarillo.

Habilita las APIs necesarias
Para usar los servicios de Google Cloud, como Cloud Run, primero debes activar sus APIs respectivas para tu proyecto. Ejecuta los siguientes comandos en Cloud Shell para habilitar los servicios necesarios para este codelab:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Elige el modelo adecuado
Puedes encontrar muchos modelos abiertos en sitios web como Hugging Face Hub y Kaggle. Cuando quieras usar uno de estos modelos en un servicio como Google Cloud Run, debes elegir uno que se ajuste a los recursos que tienes (es decir, la GPU L4 de NVIDIA).
Además del tamaño, recuerda considerar lo que el modelo puede hacer. Los modelos no son todos iguales; cada uno tiene sus propias ventajas y desventajas. Por ejemplo, algunos modelos pueden controlar diferentes tipos de entrada (como imágenes y texto, conocidas como capacidades multimodales), mientras que otros pueden recordar y procesar más información a la vez (lo que significa que tienen ventanas de contexto más grandes). A menudo, los modelos más grandes tendrán capacidades más avanzadas, como la llamada a funciones y el pensamiento.
También es importante verificar si la herramienta de entrega (vLLM en este caso) admite el modelo deseado. Puedes consultar todos los modelos compatibles con vLLM aquí.
Ahora, exploremos Gemma 3, que es la familia más reciente de modelos de lenguaje grandes (LLM) disponibles abiertamente de Google. Gemma 3 viene en cuatro escalas diferentes según su complejidad, medida en parámetros: 1,000 millones, 4,000 millones, 12,000 millones y 27,000 millones.
Para cada uno de estos tamaños, encontrarás dos tipos principales:
- Una versión base (entrenada previamente): Este es el modelo fundamental que aprendió de una gran cantidad de datos.
- Una versión ajustada por instrucciones: Esta versión se perfeccionó aún más para comprender y seguir mejor las instrucciones o los comandos específicos.
Los modelos más grandes (4,000 millones, 12,000 millones y 27,000 millones de parámetros) son multimodales, lo que significa que pueden comprender y trabajar con imágenes y texto. Sin embargo, la variante más pequeña de 1, 000 millones de parámetros se enfoca únicamente en el texto.
Para este codelab, usaremos 1,000 millones de variantes de Gemma 3: gemma-3-1b-it. Usar un modelo más pequeño también te ayuda a aprender a trabajar con recursos limitados, lo que es importante para mantener los costos bajos y asegurarte de que tu app se ejecute sin problemas en la nube.
4. Variables de entorno y Secrets
Crea un archivo de entorno
Antes de continuar, es una buena práctica tener todas las configuraciones que usarás durante este codelab en un solo lugar. Para comenzar, abre la terminal y sigue estos pasos:
- Crea una carpeta nueva para este proyecto.
- Navega a la carpeta recién creada.
- Crea un archivo .env vacío dentro de esta carpeta (este archivo contendrá más adelante tus variables de entorno).
Este es el comando para realizar esos pasos:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
A continuación, copia las variables que se indican a continuación y pégalas en el archivo.env que acabas de crear.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Recuerda reemplazar los valores de marcador de posición (your_project_id y your_region) por la información específica de tu proyecto. Por ejemplo (PROJECT_ID=unique-ai-project y REGION=europe-west4). Consulta la lista de regiones que admiten GPUs en Cloud Run aquí.
Una vez que se edite y guarde el archivo.env, escribe este comando para cargar esas variables de entorno en la sesión de la terminal:
source .env
Puedes probar si las variables se cargaron correctamente o no haciendo eco de una de las variables. Por ejemplo:
echo $SERVICE_NAME
Si obtienes el mismo valor que asignaste en el archivo.env, las variables se cargan correctamente.
Almacena un secreto en Secret Manager
Para cualquier dato sensible, incluidos códigos de acceso, credenciales y contraseñas, se recomienda usar un administrador de secretos.
Antes de usar los modelos de Gemma 3, primero debes aceptar los Términos y Condiciones, ya que están protegidos. Puedes aceptar los Términos y Condiciones a través de la tarjeta de modelo de Gamma 3 en Hugging Face Hub.
Una vez que tengas el token de acceso de Hugging Face, ve a la página de Secret Manager y crea un secreto siguiendo estas instrucciones.
- Ve a la consola de Google Cloud.
- Selecciona el proyecto en la barra desplegable superior izquierda.
- Busca Secret Manager en la barra de búsqueda y haz clic en esa opción cuando aparezca.
Cuando estés en la página de Secret Manager, haz lo siguiente:
- Haz clic en el botón +Crear secreto.
- Completa esta información:
- Nombre: HF_TOKEN
- Valor secreto: <your_hf_access_token>
- Cuando termines, haz clic en el botón Crear secreto.
Ahora deberías tener el token de acceso de Hugging Face como un secreto en Google Cloud Secret Manager.
Para probar tu acceso al secreto, ejecuta el siguiente comando en la terminal. Ese comando lo recuperará de Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
Deberías ver que se recupera y se muestra tu token de acceso en la ventana de la terminal.
Otorga acceso secreto a la cuenta de servicio de Cloud Build
Como el secreto ahora se almacena de forma segura en Secret Manager,
Ejecuta estos comandos en la terminal para hacerlo:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Crea una cuenta de servicio
Para mejorar la seguridad y administrar el acceso de manera eficaz en un entorno de producción, los servicios deben operar con cuentas de servicio dedicadas que se limiten estrictamente a los permisos necesarios para sus tareas específicas.
Ejecuta este comando para crear una cuenta de servicio.
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
El siguiente comando conecta el permiso necesario.
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Crea una imagen en Artifact Registry
Este paso implica crear una imagen de Docker que incluya los pesos del modelo y un vLLM preinstalado.
1. Crea un repositorio de Docker en Artifact Registry
Creemos un repositorio de Docker en Artifact Registry para enviar tus imágenes compiladas. Ejecuta el siguiente comando en la terminal:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Almacena el modelo
Según la documentación de prácticas recomendadas para GPU, puedes almacenar modelos de AA dentro de imágenes de contenedor o optimizar la carga desde Cloud Storage.
Por supuesto, cada enfoque tiene sus propias ventajas y desventajas. Puedes leer la documentación para obtener más información al respecto. Para simplificar, solo almacenaremos el modelo en la imagen del contenedor. Lo harás en la siguiente sesión.
3. Crea un archivo de Docker
Crea un archivo llamado Dockerfile y copia el siguiente contenido:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Crea un archivo yaml para la implementación
A continuación, crea un archivo llamado cloudbuild.yaml en el mismo directorio. Este archivo define los pasos que debe seguir Cloud Build. Copia y pega el siguiente contenido en cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Envía la compilación a Cloud Build
Copia y pega el siguiente código y ejecútalo en la terminal:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Este comando sube tu código (el Dockerfile y cloudbuild.yaml), pasa tus variables de shell como sustituciones (_MODEL_NAME y _IMAGE_NAME) y comienza la compilación.
Cloud Build ahora ejecutará los pasos definidos en cloudbuild.yaml. Puedes seguir los registros en tu terminal o haciendo clic en el vínculo a los detalles de la compilación en la consola de Cloud. Una vez que finalice, la imagen del contenedor estará disponible en tu repositorio de Artifact Registry, lista para la implementación.
6. Implementa en Cloud Run
Ahora está todo listo para implementar el servicio en Cloud Run. Ejecuta este comando en la terminal:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Prueba el servicio
Ejecuta el siguiente comando en la terminal para crear un proxy, de modo que puedas acceder al servicio mientras se ejecuta en localhost:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
En una ventana de terminal nueva, ejecuta este comando curl en la terminal para probar la conexión.
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Si ves un resultado similar al siguiente:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Conclusión
¡Felicitaciones! Completaste correctamente este codelab. Aprendiste todo esto:
- Elige un tamaño de modelo adecuado para una implementación de destino.
- Configura vLLM para entregar una API compatible con OpenAI.
- Organiza en contenedores de forma segura el servidor vLLM y los pesos del modelo con Docker.
- Envía una imagen de contenedor a Google Artifact Registry.
- Implementa un servicio acelerado por GPU en Cloud Run.
- Prueba un modelo autenticado e implementado.
No dudes en explorar la implementación de otros modelos interesantes, como Llama, Mistral o Qwen, para continuar tu recorrido de aprendizaje.
9. Limpieza
Para evitar cargos futuros, es importante borrar los recursos que creaste. Ejecuta los siguientes comandos para limpiar tu proyecto.
1. Borra el servicio de Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Borra el repositorio de Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Borra la cuenta de servicio:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Borra el secreto de Secret Manager:
gcloud secrets delete HF_TOKEN --quiet