
۱. مقدمه
مدلهای زبان بزرگ (LLM) در حال تغییر نحوه ساخت برنامههای هوشمند هستند. اما آمادهسازی این مدلهای قدرتمند برای استفاده در دنیای واقعی میتواند دشوار باشد. آنها به قدرت محاسباتی زیادی، به خصوص کارتهای گرافیک (GPU) و روشهای هوشمند برای مدیریت همزمان بسیاری از درخواستها نیاز دارند. به علاوه، شما میخواهید هزینهها را پایین نگه دارید و برنامهتان بدون تأخیر و به راحتی اجرا شود.
این Codelab به شما نشان میدهد که چگونه با این چالشها مقابله کنید! ما از دو ابزار کلیدی استفاده خواهیم کرد:
- vLLM : این را به عنوان یک موتور فوق سریع برای LLMها در نظر بگیرید. این موتور باعث میشود مدلهای شما بسیار کارآمدتر اجرا شوند، درخواستهای بیشتری را به طور همزمان مدیریت کنند و استفاده از حافظه را کاهش دهند.
- Google Cloud Run : این پلتفرم بدون سرور گوگل است. برای استقرار برنامهها فوقالعاده است زیرا تمام مقیاسبندی را برای شما مدیریت میکند - از صفر کاربر تا هزاران کاربر و دوباره به پایین. از همه بهتر، Cloud Run اکنون از GPUها پشتیبانی میکند که برای میزبانی LLMها ضروری هستند!
vLLM و Cloud Run در کنار هم، روشی قدرتمند، انعطافپذیر و مقرونبهصرفه برای خدمترسانی به LLM های شما ارائه میدهند. در این راهنما، شما یک مدل باز را پیادهسازی خواهید کرد و آن را به عنوان یک API وب استاندارد در دسترس قرار خواهید داد.
آنچه یاد خواهید گرفت
- نحوه انتخاب اندازه و نوع مدل مناسب برای سرو.
- نحوه تنظیم vLLM برای ارائه خدمات به نقاط پایانی API سازگار با OpenAI.
- نحوه کانتینرایز کردن سرور vLLM با Docker.
- چگونه تصویر کانتینر خود را به Google Artifact Registry ارسال کنیم.
- نحوه استقرار کانتینر در Cloud Run با شتابدهنده GPU.
- چگونه مدل پیادهسازی شده خود را آزمایش کنید.
آنچه نیاز دارید
- یک مرورگر، مانند کروم، برای دسترسی به کنسول ابری گوگل
- یک اتصال اینترنتی قابل اعتماد
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- یک توکن دسترسی به چهره در آغوش (اگر هنوز یکی ندارید، اینجا ایجاد کنید)
- آشنایی اولیه با پایتون، داکر و رابط خط فرمان
- ذهن کنجکاو و اشتیاق به یادگیری
۲. قبل از شروع
راهاندازی پروژه ابری گوگل
این آزمایشگاه کد به یک پروژه ابری گوگل با یک حساب پرداخت فعال نیاز دارد.
- برای جلسات تحت هدایت مربی: اگر در کلاس درس هستید، مربی شما اطلاعات لازم در مورد پروژه و صورتحساب را در اختیار شما قرار میدهد. برای تکمیل تنظیمات، دستورالعملهای مربی خود را دنبال کنید.
- برای زبانآموزان مستقل: اگر این کار را به تنهایی انجام میدهید و حساب پرداخت فعالی ندارید، باید با استفاده از اطلاعات پرداخت خود، یک حساب پرداخت راهاندازی کنید. برای ایجاد یک حساب پرداخت جدید و فعال کردن آن برای پروژه خود، به مستندات Google Cloud Billing مراجعه کنید.
ایجاد یک پروژه گوگل کلود
برای اینکه تمام کارهایتان برای این آزمایشگاه کد، سازماندهی شده و از سایر پروژهها جدا باشد، با ایجاد یک پروژه جدید Google Cloud شروع خواهید کرد.
برای باز کردن صفحه ایجاد پروژه، روی کلیک کنید.
اطلاعات مورد نیاز را در صفحه ایجاد پروژه وارد کنید:
- نام پروژه - میتوانید هر نامی که میخواهید وارد کنید (مثلاً genai-workshop)
- مکان - آن را بدون سازمان رها کنید
- حساب صورتحساب - اگر این گزینه ظاهر شد، «حساب صورتحساب آزمایشی پلتفرم ابری گوگل» یا در صورت تمایل، حساب صورتحساب خودتان را انتخاب کنید. اگر این گزینه را نمیبینید، میتوانید به مرحله بعدی بروید.
شناسه پروژه تولید شده را کپی کنید، بعداً به آن نیاز خواهید داشت. 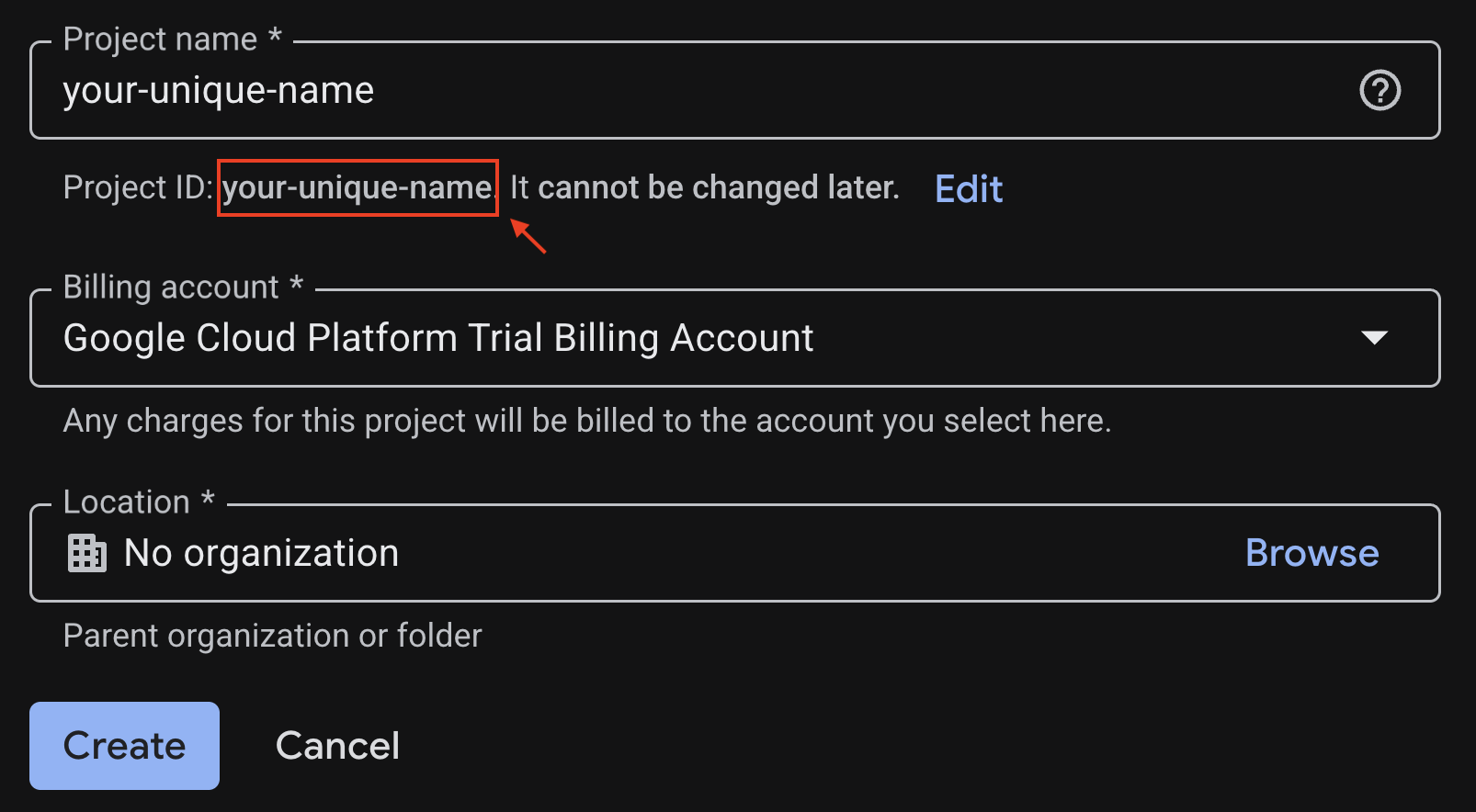
اگر همه چیز درست است، روی دکمه ایجاد کلیک کنید.
پیکربندی Cloud Shell
Cloud Shell یک محیط از پیش پیکربندی شده با تمام ابزارهای مورد نیاز برای این codelab است. پس از ایجاد موفقیتآمیز پروژه، مراحل زیر را برای راهاندازی Cloud Shell انجام دهید.
راه اندازی پوسته ابری
برای اجرای Cloud Shell، روی کلیک کنید.
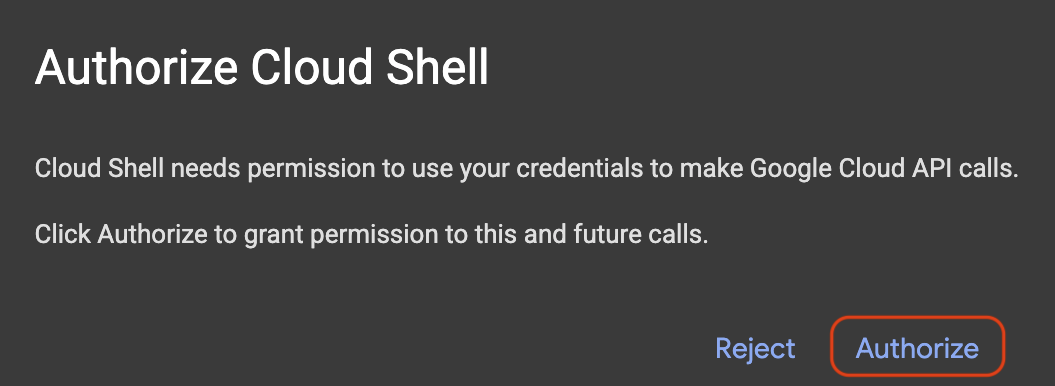
اگر پنجرهای ظاهر شد که درخواست مجوز میکرد، روی «مجوز» کلیک کنید.
تنظیم شناسه پروژه
replace-with-your-project-id با شناسه پروژه واقعی خود که در مرحله ایجاد پروژه در بالا به دست آوردهاید، جایگزین کنید. دستور زیر را در ترمینال Cloud Shell اجرا کنید تا شناسه پروژه صحیح تنظیم شود.
gcloud config set project replace-with-your-project-id
اکنون باید ببینید که پروژه صحیح در ترمینال Cloud Shell انتخاب شده است. شناسه پروژه انتخاب شده با رنگ زرد برجسته شده است.

فعال کردن API های لازم
برای استفاده از سرویسهای گوگل کلود مانند کلود ران، ابتدا باید APIهای مربوطه را برای پروژه خود فعال کنید. دستورات زیر را در کلود شل اجرا کنید تا سرویسهای لازم برای این Codelab فعال شوند:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
۳. انتخاب مدل مناسب
میتوانید مدلهای باز زیادی را در وبسایتهایی مانند Hugging Face Hub و Kaggle پیدا کنید. وقتی میخواهید از یکی از این مدلها در سرویسی مانند Google Cloud Run استفاده کنید، باید مدلی را انتخاب کنید که با منابعی که در اختیار دارید (مثلاً NVIDIA L4 GPU) متناسب باشد.
فراتر از اندازه، به یاد داشته باشید که در نظر بگیرید مدل واقعاً چه کاری میتواند انجام دهد. همه مدلها یکسان نیستند؛ هر کدام مزایا و معایب خاص خود را دارند. به عنوان مثال، برخی از مدلها میتوانند انواع مختلف ورودی (مانند تصاویر و متن - که به عنوان قابلیتهای چندوجهی شناخته میشوند) را مدیریت کنند، در حالی که برخی دیگر میتوانند اطلاعات بیشتری را به طور همزمان به خاطر بسپارند و پردازش کنند (به این معنی که پنجرههای زمینه بزرگتری دارند). اغلب، مدلهای بزرگتر قابلیتهای پیشرفتهتری مانند فراخوانی تابع و تفکر خواهند داشت.
همچنین بررسی اینکه آیا مدل مورد نظر شما توسط ابزار ارائه دهنده (در این مورد vLLM) پشتیبانی میشود یا خیر، مهم است. میتوانید تمام مدلهایی را که توسط vLLM پشتیبانی میشوند، اینجا بررسی کنید.
حال، بیایید Gemma 3 را بررسی کنیم، که جدیدترین خانواده مدلهای زبان بزرگ (LLM) گوگل است که به صورت عمومی در دسترس قرار دارند. Gemma 3 بر اساس پیچیدگی آنها، در چهار مقیاس مختلف ارائه میشود که با پارامترهای زیر اندازهگیری میشوند: ۱ میلیارد، ۴ میلیارد، ۱۲ میلیارد و عدد عظیم ۲۷ میلیارد.
برای هر یک از این اندازهها، دو نوع اصلی پیدا خواهید کرد:
- یک نسخه پایه (از پیش آموزشدیده): این مدل بنیادی است که از حجم عظیمی از دادهها یاد گرفته است.
- نسخهای با دستورالعمل تنظیمشده: این نسخه بیشتر اصلاح شده است تا دستورالعملها یا فرامین خاص را بهتر درک و دنبال کند.
مدلهای بزرگتر (۴ میلیارد، ۱۲ میلیارد و ۲۷ میلیارد پارامتر) چندوجهی هستند، به این معنی که میتوانند هم تصاویر و هم متن را درک کرده و با آنها کار کنند. با این حال، کوچکترین نوع ۱ میلیارد پارامتر، صرفاً بر متن تمرکز دارد.
برای این Codelab، ما از ۱ میلیارد نوع Gemma 3 استفاده خواهیم کرد: gemma-3-1b-it . استفاده از یک مدل کوچکتر همچنین به شما کمک میکند تا یاد بگیرید چگونه با منابع محدود کار کنید، که برای کاهش هزینهها و اطمینان از عملکرد روان برنامه شما در فضای ابری مهم است.
۴. متغیرهای محیطی و رمزها
ایجاد یک فایل محیطی
قبل از ادامه، بهتر است تمام تنظیماتی که در طول این Codelab استفاده خواهید کرد را در یک مکان داشته باشید. برای شروع، ترمینال خود را باز کنید و این مراحل را انجام دهید:
- یک پوشه جدید برای این پروژه ایجاد کنید .
- به پوشه تازه ایجاد شده بروید.
- یک فایل .env خالی درون این پوشه ایجاد کنید (این فایل بعداً متغیرهای محیطی شما را در خود نگه میدارد)
دستور انجام این مراحل به صورت زیر است:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
در مرحله بعد، متغیرهای ذکر شده در زیر را کپی کرده و آنها را در فایل .env که تازه ایجاد کردهاید، جایگذاری کنید.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
به یاد داشته باشید که مقادیر جایگزین ( your_project_id و your_region ) را با اطلاعات خاص پروژه خود جایگزین کنید. برای مثال ( PROJECT_ID=unique-ai-project و REGION=europe-west4 ). لیست مناطقی که از GPUها در Cloud Run پشتیبانی میکنند را اینجا ببینید.
پس از ویرایش و ذخیره فایل .env ، این دستور را برای بارگذاری متغیرهای محیطی در بخش ترمینال تایپ کنید:
source .env
شما میتوانید با تکرار یکی از متغیرها، بررسی کنید که آیا متغیرها با موفقیت بارگذاری شدهاند یا خیر. برای مثال:
echo $SERVICE_NAME
اگر همان مقداری را که در فایل .env اختصاص دادهاید، دریافت کنید، متغیرها با موفقیت بارگذاری شدهاند.
یک راز را در Secret Manager ذخیره کنید
برای هرگونه اطلاعات حساس، از جمله کدهای دسترسی، اعتبارنامهها و رمزهای عبور، استفاده از یک مدیر مخفی رویکرد پیشنهادی است.
قبل از استفاده از مدلهای Gemma 3، ابتدا باید شرایط و ضوابط را بپذیرید، زیرا آنها دارای مجوز هستند. میتوانید شرایط و ضوابط را از طریق کارت مدل Gamma 3 در Hugging Face Hub تأیید کنید.
وقتی توکن دسترسی به چهره در آغوش گرفته را داشتید، به صفحه مدیریت راز بروید و با دنبال کردن این دستورالعملها، یک راز ایجاد کنید.
- به کنسول ابری گوگل بروید
- پروژه را از نوار کشویی بالا سمت چپ انتخاب کنید
- در نوار جستجو عبارت Secret Manager را جستجو کنید و وقتی گزینه مورد نظر ظاهر شد، روی آن کلیک کنید.
وقتی که شما آن صفحه مدیر مخفی هستید:
- روی دکمه +ایجاد رمز کلیک کنید،
- این اطلاعات را پر کنید:
- نام : HF_TOKEN
- مقدار مخفی : <your_hf_access_token>
- پس از اتمام کار، روی دکمهی «ایجاد راز» کلیک کنید.
اکنون باید توکن دسترسی به چهره در آغوش گرفته را به عنوان یک راز در Google Cloud Secret Manager داشته باشید.
شما میتوانید با اجرای دستور زیر در ترمینال، دسترسی خود به فایل مخفی را آزمایش کنید، این دستور آن را از Secret Manager بازیابی میکند:
gcloud secrets versions access latest --secret=HF_TOKEN
باید ببینید که توکن دسترسی شما بازیابی شده و در پنجره ترمینال نمایش داده میشود.
اعطای دسترسی مخفی به حساب سرویس Cloud Build
از آنجایی که این راز اکنون به طور ایمن در Secret Manager ذخیره شده است،
برای انجام این کار، این دستورات را در ترمینال اجرا کنید:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
۵. یک حساب کاربری سرویس ایجاد کنید
برای افزایش امنیت و مدیریت مؤثر دسترسی در محیط عملیاتی، سرویسها باید تحت حسابهای کاربری اختصاصی سرویس عمل کنند که کاملاً محدود به مجوزهای لازم برای وظایف خاص خود هستند.
برای ایجاد یک حساب کاربری سرویس، این دستور را اجرا کنید
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
دستور زیر دسترسی لازم را ضمیمه میکند
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
۶. ایجاد یک تصویر در رجیستری مصنوعات
این مرحله شامل ایجاد یک تصویر داکر است که شامل وزنهای مدل و یک vLLM از پیش نصب شده است.
۱. یک مخزن داکر در رجیستری Artifact ایجاد کنید
بیایید یک مخزن داکر در رجیستری Artifact برای قرار دادن ایمیجهای ساخته شده خود ایجاد کنیم. دستور زیر را در ترمینال اجرا کنید:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
۲. ذخیره مدل
بر اساس مستندات بهترین شیوههای GPU ، میتوانید مدلهای ML را درون تصاویر کانتینر ذخیره کنید یا بارگذاری آنها را از فضای ذخیرهسازی ابری بهینه کنید .
البته، هر رویکرد مزایا و معایب خاص خود را دارد. میتوانید برای کسب اطلاعات بیشتر در مورد آنها، مستندات را مطالعه کنید. برای سادگی، ما فقط مدل را در تصویر کانتینر ذخیره میکنیم. شما این کار را در جلسه بعدی انجام خواهید داد.
۳. یک فایل داکر ایجاد کنید
یک فایل با نام Dockerfile ایجاد کنید و محتویات زیر را در آن کپی کنید:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
۴. یک فایل yaml برای استقرار ایجاد کنید
سپس، فایلی با نام cloudbuild.yaml در همان دایرکتوری ایجاد کنید. این فایل مراحل ساخت Cloud را تعریف میکند. محتوای زیر را کپی کرده و در cloudbuild.yaml قرار دهید:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
۵. ساخت را به Cloud Build ارسال کنید
کد زیر را کپی و در ترمینال پیست کنید و اجرا کنید:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
این دستور کد شما ( Dockerfile و cloudbuild.yaml ) را آپلود میکند، متغیرهای پوسته شما را به عنوان جایگزین ( _MODEL_NAME و _IMAGE_NAME ) ارسال میکند و ساخت را آغاز میکند.
Cloud Build اکنون مراحل تعریف شده در cloudbuild.yaml را اجرا خواهد کرد. میتوانید گزارشها را در ترمینال خود یا با کلیک روی پیوند به جزئیات ساخت در Cloud Console دنبال کنید. پس از اتمام، تصویر کانتینر در مخزن Artifact Registry شما، آماده برای استقرار، در دسترس خواهد بود.
۶. استقرار در Cloud Run
اکنون آمادهاید تا سرویس را در Cloud Run مستقر کنید. این دستور را در ترمینال اجرا کنید:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
۷. سرویس را آزمایش کنید
دستور زیر را در ترمینال اجرا کنید تا یک پروکسی ایجاد شود و بتوانید به سرویس در حال اجرا در localhost دسترسی داشته باشید:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
در یک پنجره ترمینال جدید، این دستور curl را در ترمینال اجرا کنید تا اتصال را آزمایش کنید
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
اگر خروجی مشابه زیر را مشاهده کردید:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
۸. نتیجهگیری
تبریک! شما با موفقیت این Codelab را به پایان رساندید. شما یاد گرفتید که چگونه:
- اندازه مدل مناسبی را برای استقرار هدف انتخاب کنید.
- vLLM را طوری تنظیم کنید که یک API سازگار با OpenAI ارائه دهد.
- سرور vLLM و وزنهای مدل را با Docker به طور ایمن کانتینریزه کنید.
- یک تصویر کانتینر را به Google Artifact Registry ارسال کنید.
- یک سرویس شتابدهندهی GPU را روی Cloud Run مستقر کنید.
- یک مدل مستقر و احراز هویت شده را آزمایش کنید.
برای ادامهی مسیر یادگیریتان، میتوانید مدلهای هیجانانگیز دیگری مانند لاما، میسترال یا کوئن را امتحان کنید!
۹. تمیز کردن
برای جلوگیری از هزینههای بعدی، حذف منابعی که ایجاد کردهاید بسیار مهم است. برای پاکسازی پروژه خود، دستورات زیر را اجرا کنید.
۱. سرویس Cloud Run را حذف کنید:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
۲. مخزن رجیستری Artifact را حذف کنید:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
۳. حساب سرویس را حذف کنید:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
۴. فایل مخفی را از Secret Manager حذف کنید:
gcloud secrets delete HF_TOKEN --quiet