
1. Introduction
Les grands modèles de langage (LLM) révolutionnent la façon dont nous créons des applications intelligentes. Cependant, préparer ces modèles puissants pour une utilisation réelle peut s'avérer délicat. Ils ont besoin d'une grande puissance de calcul, en particulier de cartes graphiques (GPU), et de moyens intelligents pour gérer de nombreuses requêtes à la fois. De plus, vous devez réduire les coûts et assurer le bon fonctionnement de votre application sans délai.
Cet atelier de programmation vous explique comment relever ces défis. Nous allons utiliser deux outils clés :
- vLLM : il s'agit d'un moteur ultrarapide pour les LLM. Il permet à vos modèles de s'exécuter de manière beaucoup plus efficace, en gérant davantage de requêtes à la fois et en réduisant l'utilisation de la mémoire.
- Google Cloud Run : il s'agit de la plate-forme sans serveur de Google. Elle est idéale pour déployer des applications, car elle gère automatiquement le scaling, de zéro à des milliers d'utilisateurs, et inversement. Mieux encore, Cloud Run est désormais compatible avec les GPU, qui sont essentiels pour héberger des LLM.
Ensemble, vLLM et Cloud Run offrent un moyen puissant, flexible et économique de mettre en service vos LLM. Dans ce guide, vous allez déployer un modèle ouvert et le rendre disponible en tant qu'API Web standard.
Points abordés
- Comment choisir la taille et la variante de modèle appropriées pour la mise en service
- Comment configurer vLLM pour mettre en service des points de terminaison d'API compatibles avec OpenAI
- Comment conteneuriser le serveur vLLM avec Docker
- Comment transférer votre image de conteneur vers Google Artifact Registry
- Comment déployer le conteneur sur Cloud Run avec l'accélération du GPU
- Comment tester votre modèle déployé
Prérequis
- Un navigateur, tel que Chrome, pour accéder à la console Google Cloud
- Une connexion Internet fiable
- Un projet Google Cloud avec facturation activée
- Un jeton d'accès Hugging Face (créez-en un ici si vous n'en avez pas encore)
- Des connaissances de base en Python, Docker et interface de ligne de commande
- Un esprit curieux et une soif d'apprendre
2. Avant de commencer
Configurer un projet Google Cloud
Cet atelier de programmation nécessite un projet Google Cloud associé à un compte de facturation actif.
- Pour les sessions animées par un formateur : si vous êtes en classe, votre formateur vous fournira les informations de facturation et de projet nécessaires. Suivez les instructions de votre formateur pour effectuer la configuration.
- Pour les apprenants autonomes : si vous effectuez cette opération seul et que vous ne disposez pas d'un compte de facturation actif, vous devez en configurer un à l'aide de vos propres informations de paiement. Consultez la documentation sur la facturation Google Cloud pour créer un compte de facturation et l'activer pour votre projet.
Créer un projet Google Cloud
Pour que tout votre travail pour cet atelier de programmation soit organisé et séparé des autres projets, vous allez commencer par créer un projet Google Cloud.
Pour ouvrir la page de création de projet, cliquez sur :
Saisissez les informations requises sur la page de création de projet :
- Nom du projet : vous pouvez saisir le nom de votre choix (par exemple, genai-workshop)
- Emplacement : laissez le paramètre défini sur Aucune organisation
- Compte de facturation : si cette option s'affiche, sélectionnez "Compte de facturation en période d'essai Google Cloud Platform" ou votre propre compte de facturation si vous le préférez. Si cette option ne s'affiche pas, vous pouvez passer à l'étape suivante.
Notez l'ID du projet généré, vous en aurez besoin plus tard. 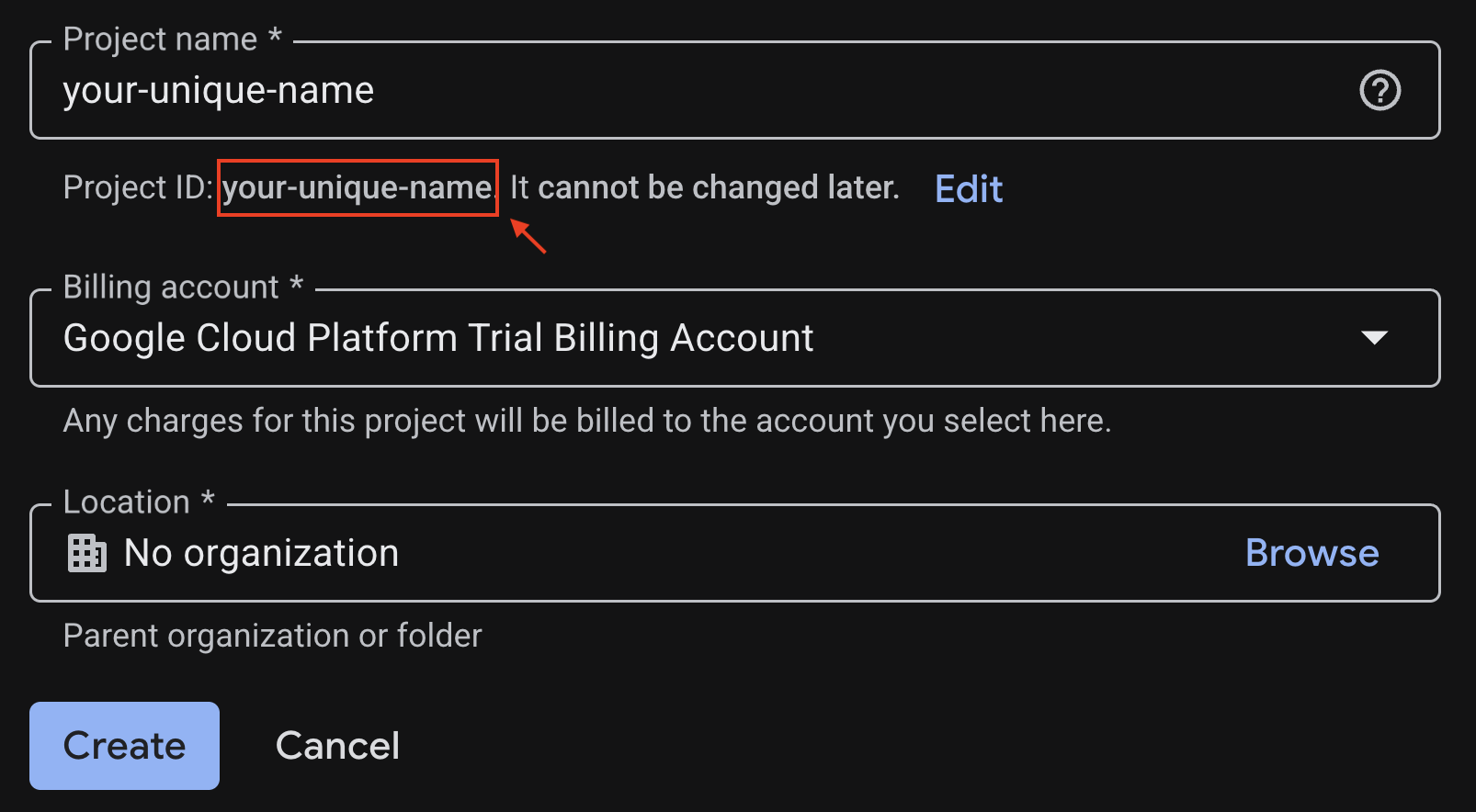
Si tout est correct, cliquez sur le bouton Créer.
Configurer Cloud Shell
Cloud Shell est un environnement préconfiguré avec tous les outils dont vous avez besoin pour cet atelier de programmation. Une fois votre projet créé, procédez comme suit pour configurer Cloud Shell.
Lancer Cloud Shell
Pour lancer Cloud Shell, cliquez sur :
Si un pop-up s'affiche pour vous demander une autorisation, cliquez sur Autoriser.
Définir l'ID du projet
Remplacez replace-with-your-project-id par l'ID de projet réel de l'étape de création de projet ci-dessus. Exécutez la commande suivante dans le terminal Cloud Shell pour définir l'ID du projet correct.
gcloud config set project replace-with-your-project-id
Vous devriez maintenant voir que le bon projet est sélectionné dans le terminal Cloud Shell. L'ID du projet sélectionné est mis en surbrillance en jaune.

Activer les API nécessaires
Pour utiliser des services Google Cloud tels que Cloud Run, vous devez d'abord activer leurs API respectives pour votre projet. Exécutez les commandes suivantes dans Cloud Shell pour activer les services nécessaires à cet atelier de programmation :
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Choisir le bon modèle
Vous trouverez de nombreux modèles ouverts sur des sites Web tels que Hugging Face Hub et Kaggle. Lorsque vous souhaitez utiliser l'un de ces modèles sur un service tel que Google Cloud Run, vous devez en choisir un qui correspond aux ressources dont vous disposez (c'est-à-dire un GPU NVIDIA L4).
Au-delà de la taille, n'oubliez pas de tenir compte de ce que le modèle peut réellement faire. Les modèles ne sont pas tous identiques. Chacun a ses propres avantages et inconvénients. Par exemple, certains modèles peuvent gérer différents types d'entrées (comme des images et du texte, ce que l'on appelle des capacités multimodales), tandis que d'autres peuvent mémoriser et traiter plus d'informations à la fois (ce qui signifie qu'ils ont des fenêtres de contexte plus grandes). Souvent, les modèles plus volumineux disposent de fonctionnalités plus avancées, telles que l'appel de fonctions et la réflexion.
Il est également important de vérifier si l'outil de mise en service (vLLM dans ce cas) est compatible avec le modèle souhaité. Vous pouvez consulter tous les modèles compatibles avec vLLM ici.
Découvrons maintenant Gemma 3, la dernière gamme de grands modèles de langage (LLM) disponibles publiquement de Google. Gemma 3 est disponible en quatre échelles différentes en fonction de sa complexité, mesurée en paramètres : 1 milliard, 4 milliards, 12 milliards et 27 milliards.
Pour chacune de ces tailles, vous trouverez deux types principaux :
- Une version de base (pré-entraînée) : il s'agit du modèle de fondation qui a appris à partir d'une quantité massive de données.
- Une version ajustée aux instructions : cette version a été affinée pour mieux comprendre et suivre des instructions ou des commandes spécifiques.
Les modèles plus volumineux (4 milliards, 12 milliards et 27 milliards de paramètres) sont multimodaux, ce qui signifie qu'ils peuvent comprendre et traiter à la fois des images et du texte. La plus petite variante de 1 milliard de paramètres, quant à elle, se concentre uniquement sur le texte.
Pour cet atelier de programmation, nous allons utiliser 1 milliard de variantes de Gemma 3 : gemma-3-1b-it. L'utilisation d'un modèle plus petit vous permet également d'apprendre à travailler avec des ressources limitées, ce qui est important pour réduire les coûts et garantir le bon fonctionnement de votre application dans le cloud.
4. Variables d'environnement et secrets
Créer un fichier d'environnement
Avant de continuer, il est recommandé de regrouper toutes les configurations que vous utiliserez tout au long de cet atelier de programmation. Pour commencer, ouvrez votre terminal et procédez comme suit :
- Créez un dossier pour ce projet.
- Accédez au dossier que vous venez de créer.
- Créez un fichier .env vide dans ce dossier (ce fichier contiendra ultérieurement vos variables d'environnement)
Voici la commande à exécuter pour effectuer ces étapes :
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Ensuite, copiez les variables listées ci-dessous et collez-les dans le fichier.env que vous venez de créer.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
N'oubliez pas de remplacer les valeurs des espaces réservés (your_project_id et your_region) par les informations spécifiques à votre projet. Par exemple (PROJECT_ID=unique-ai-project et REGION=europe-west4). Consultez la liste des régions compatibles avec les GPU sur Cloud Run ici.
Une fois le fichier.env modifié et enregistré, saisissez cette commande pour charger ces variables d'environnement dans la session de terminal :
source .env
Vous pouvez vérifier si les variables sont chargées ou non en écho à l'une d'elles. Exemple :
echo $SERVICE_NAME
Si vous obtenez la même valeur que celle que vous avez attribuée dans le .env file, les variables sont chargées.
Stocker un secret dans Secret Manager
Pour toutes les données sensibles, y compris les codes d'accès, les identifiants et les mots de passe, il est recommandé d'utiliser un gestionnaire de secrets.
Avant d'utiliser les modèles Gemma 3, vous devez d'abord accepter les conditions d'utilisation, car elles sont limitées. Vous pouvez accepter les conditions d'utilisation via la fiche de modèle Gamma 3 sur Hugging Face Hub.
Une fois que vous disposez du jeton d'accès Hugging Face, accédez à la page Secret Manager et créez un secret en suivant ces instructions.
- Accédez à la console Google Cloud.
- Sélectionnez le projet dans le menu déroulant en haut à gauche.
- Recherchez Secret Manager dans la barre de recherche et cliquez sur cette option lorsqu'elle s'affiche.
Lorsque vous êtes sur la page Secret Manager :
- Cliquez sur le bouton +Créer un secret.
- Renseignez les informations suivantes :
- Nom : HF_TOKEN
- Valeur du secret : <your_hf_access_token>
- Cliquez sur le bouton Créer un secret lorsque vous avez terminé.
Vous devriez maintenant disposer du jeton d'accès Hugging Face en tant que secret dans Google Cloud Secret Manager.
Vous pouvez tester votre accès au secret en exécutant la commande ci-dessous dans le terminal. Cette commande le récupérera à partir de Secret Manager :
gcloud secrets versions access latest --secret=HF_TOKEN
Votre jeton d'accès doit être récupéré et affiché dans la fenêtre du terminal.
Accorder l'accès secret au compte de service Cloud Build
Le secret étant désormais stocké de manière sécurisée dans Secret Manager,
exécutez ces commandes dans le terminal :
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Créer un compte de service
Pour améliorer la sécurité et gérer efficacement l'accès dans un environnement de production, les services doivent fonctionner sous des comptes de service dédiés, strictement limités aux autorisations nécessaires à leurs tâches spécifiques.
Exécutez cette commande pour créer un compte de service :
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
La commande suivante associe l'autorisation nécessaire :
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Créer une image dans Artifact Registry
Cette étape consiste à créer une image Docker qui inclut les pondérations du modèle et un vLLM préinstallé.
1. Créer un dépôt Docker dans Artifact Registry
Créons un dépôt Docker dans Artifact Registry pour transférer vos images créées. Exécutez la commande suivante dans le terminal :
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Stocker le modèle
Selon la documentation sur les bonnes pratiques concernant les GPU, vous pouvez stocker des modèles de ML dans des images de conteneurs ou optimiser leur chargement à partir de Cloud Storage.
Bien sûr, chaque approche a ses propres avantages et inconvénients. Pour en savoir plus, consultez la documentation. Par souci de simplicité, nous allons simplement stocker le modèle dans l'image de conteneur. Vous le ferez lors de la session suivante.
3. Créer un fichier Docker
Créez un fichier nommé Dockerfile et copiez-y le contenu ci-dessous :
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Créer un fichier YAML pour le déploiement
Ensuite, créez un fichier nommé cloudbuild.yaml dans le même répertoire. Ce fichier définit les étapes à suivre pour Cloud Build. Copiez et collez le contenu suivant dans cloudbuild.yaml :
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Envoyer la compilation à Cloud Build
Copiez et collez le code suivant, puis exécutez-le dans le terminal :
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Cette commande importe votre code (les fichiers Dockerfile et cloudbuild.yaml), transmet vos variables shell en tant que substitutions (_MODEL_NAME et _IMAGE_NAME) et démarre la compilation.
Cloud Build exécute maintenant les étapes définies dans cloudbuild.yaml. Vous pouvez suivre les journaux dans votre terminal ou en cliquant sur le lien vers les détails de la compilation dans la console Cloud. Une fois l'opération terminée, l'image de conteneur est disponible dans votre dépôt Artifact Registry, prête à être déployée.
6. Déployer une application sur Cloud Run
Vous êtes maintenant prêt à déployer le service sur Cloud Run. Exécutez cette commande dans le terminal :
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Tester le service
Exécutez la commande suivante dans le terminal pour créer un proxy, afin de pouvoir accéder au service lorsqu'il s'exécute en localhost :
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
Dans une nouvelle fenêtre de terminal, exécutez cette commande curl dans le terminal pour tester la connexion :
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Si vous voyez un résultat semblable à celui-ci :
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Conclusion
Félicitations ! Vous avez terminé cet atelier de programmation. Vous avez appris à :
- Choisir une taille de modèle appropriée pour un déploiement cible
- Configurer vLLM pour mettre en service une API compatible avec OpenAI
- Conteneuriser de manière sécurisée le serveur vLLM et les pondérations du modèle avec Docker
- Transférer une image de conteneur vers Google Artifact Registry
- Déployer un service accéléré par GPU sur Cloud Run
- Tester un modèle déployé et authentifié
N'hésitez pas à déployer d'autres modèles intéressants tels que Llama, Mistral ou Qwen pour poursuivre votre apprentissage.
9. Effectuer un nettoyage
Pour éviter que des frais ne vous soient facturés à l'avenir, il est important de supprimer les ressources que vous avez créées. Exécutez les commandes suivantes pour nettoyer votre projet.
1. Supprimez le service Cloud Run :
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Supprimez le dépôt Artifact Registry :
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Supprimez le compte de service :
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Supprimez le secret de Secret Manager :
gcloud secrets delete HF_TOKEN --quiet