
1. מבוא
מודלים גדולים של שפה (LLM) משנים את הדרך שבה אנחנו מפתחים אפליקציות חכמות. אבל יכול להיות מסובך להכין את המודלים המתקדמים האלה לשימוש בעולם האמיתי. הם צריכים הרבה כוח מחשוב, במיוחד כרטיסים גרפיים (GPU), ודרכים חכמות לטפל בהרבה בקשות בבת אחת. בנוסף, אתם רוצים לצמצם את העלויות ולהפעיל את האפליקציה בצורה חלקה ללא עיכובים.
ב-Codelab הזה נסביר איך להתמודד עם האתגרים האלה. נשתמש בשני כלים מרכזיים:
- vLLM: אפשר לחשוב על זה כמנוע מהיר במיוחד ל-LLM. הוא מאפשר להריץ את המודלים בצורה יעילה יותר, לטפל ביותר בקשות בו-זמנית ולצמצם את השימוש בזיכרון.
- Google Cloud Run: הפלטפורמה של Google ללא שרת. הוא מצוין לפריסת אפליקציות כי הוא מטפל בכל ההתאמות של המשאבים – מאפס משתמשים ועד אלפים, ובחזרה. והכי חשוב, עכשיו יש תמיכה במעבדי GPU ב-Cloud Run, שהם חיוניים לאירוח של מודלים גדולים של שפה (LLM)!
השילוב של vLLM ו-Cloud Run מאפשר לכם להפעיל מודלים גדולים של שפה בצורה יעילה, גמישה וחסכונית. במדריך הזה נסביר איך לפרוס מודל פתוח ולהפוך אותו לזמין כ-API רגיל לאינטרנט.
מה תלמדו
- איך בוחרים את הגודל והגרסה המתאימים של המודל להצגה.
- איך מגדירים את vLLM כדי להכניס לשימוש בסביבת הייצור נקודות קצה ל-API שתואמות ל-OpenAI.
- איך יוצרים קונטיינר לשרת vLLM באמצעות Docker.
- איך לדחוף את קובץ האימג' של קונטיינר אל Google Artifact Registry.
- איך פורסים את הקונטיינר ב-Cloud Run עם האצת GPU.
- איך בודקים את המודל שפרסתם.
מה תצטרכו
- דפדפן, כמו Chrome, כדי לגשת למסוף Google Cloud
- חיבור אמין לאינטרנט
- פרויקט ב-Google Cloud שהחיוב בו מופעל
- אסימון גישה של Hugging Face (אם עדיין אין לכם, אפשר ליצור אותו כאן)
- היכרות בסיסית עם Python, Docker וממשק שורת הפקודה
- סקרנות ורצון ללמוד
2. לפני שתתחיל
הגדרת פרויקט ב-Google Cloud
כדי לבצע את ה-codelab הזה, צריך פרויקט ב-Google Cloud עם חשבון חיוב פעיל.
- בסדנאות בהנחיית מדריך: אם אתם בכיתה, המדריך יספק לכם את פרטי הפרויקט והחיוב הנדרשים. פועלים לפי ההוראות של המורה כדי להשלים את ההגדרה.
- ללומדים עצמאיים: אם אתם עושים זאת בעצמכם ואין לכם חשבון חיוב פעיל, תצטרכו להגדיר חשבון חיוב באמצעות פרטי התשלום שלכם. כדי ליצור חשבון לחיוב חדש ולהפעיל אותו בפרויקט, אפשר לעיין במסמכי החיוב ב-Cloud ב-Google.
יצירת פרויקט ב-Google Cloud
כדי לשמור על סדר בעבודה שלכם ב-Codelab הזה ולהפריד אותה מפרויקטים אחרים, תתחילו ביצירת פרויקט חדש ב-Google Cloud.
כדי לפתוח את הדף ליצירת פרויקט, לוחצים על:
מזינים את המידע הנדרש בדף ליצירת פרויקט:
- שם הפרויקט – אפשר להזין כל שם שרוצים (לדוגמה: genai-workshop)
- מיקום – משאירים את האפשרות ללא ארגון
- חשבון לחיוב – אם האפשרות הזו מופיעה, בוחרים באפשרות 'חשבון לחיוב לניסיון ב-Google Cloud Platform' או בחשבון לחיוב משלכם, אם אתם מעדיפים. אם האפשרות הזו לא מופיעה, אפשר להמשיך לשלב הבא.
מעתיקים את מזהה הפרויקט שנוצר. תצטרכו אותו בהמשך. 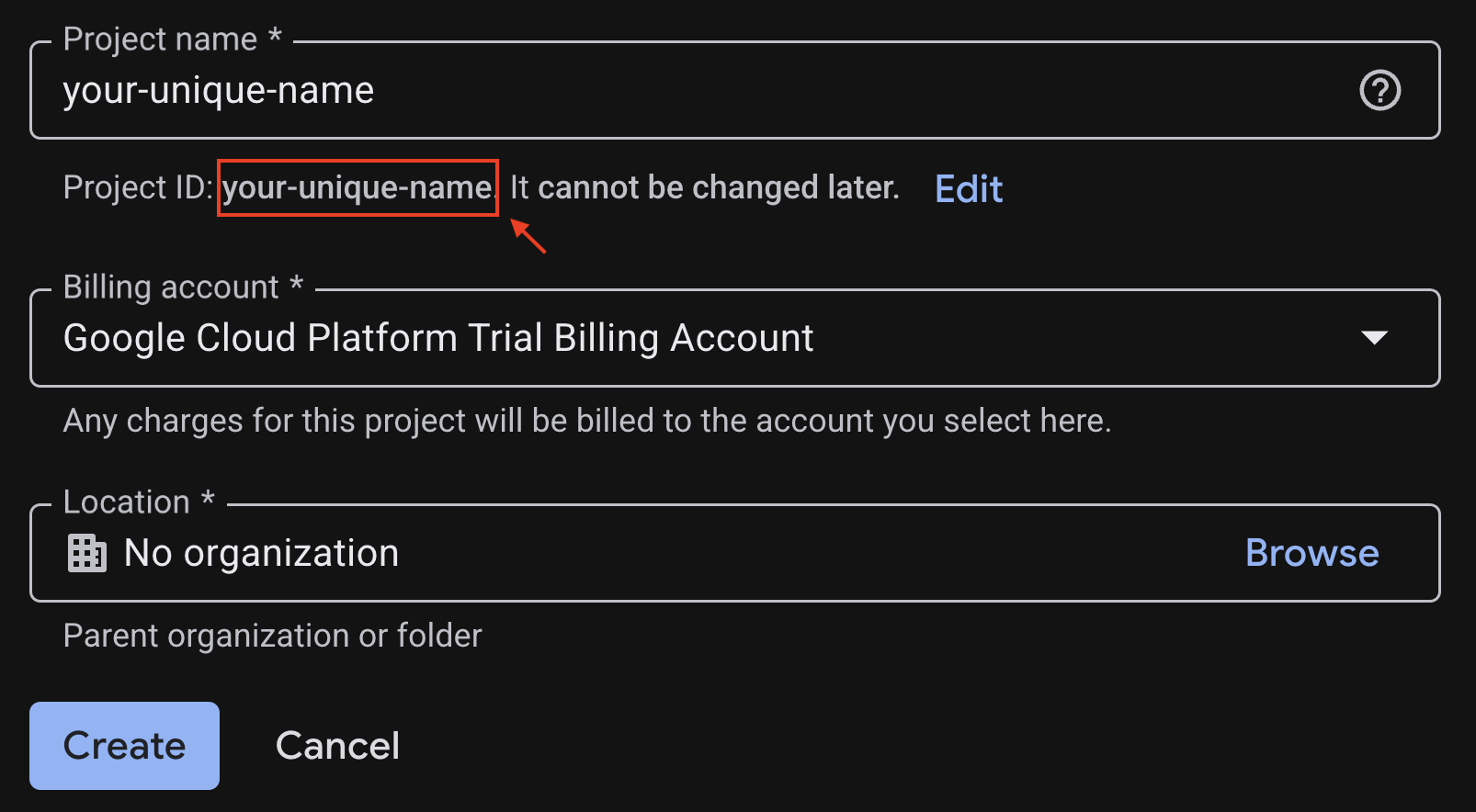
אם הכול בסדר, לוחצים על הלחצן יצירה.
הגדרת Cloud Shell
Cloud Shell היא סביבה שהוגדרה מראש עם כל הכלים שצריך ל-Codelab הזה. אחרי שהפרויקט נוצר בהצלחה, מבצעים את השלבים הבאים כדי להגדיר את Cloud Shell.
הפעלת Cloud Shell
כדי להפעיל את Cloud Shell, לוחצים על:
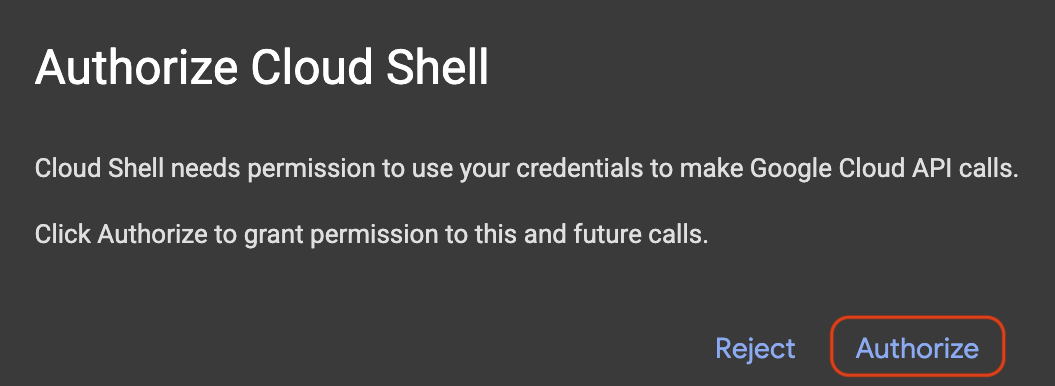
אם מופיע חלון קופץ עם בקשה לאישור, לוחצים על אישור.
הגדרת מזהה פרויקט
מחליפים את replace-with-your-project-id במזהה הפרויקט האמיתי מהשלב של יצירת הפרויקט שמופיע למעלה. מריצים את הפקודה הבאה במסוף Cloud Shell כדי להגדיר את מזהה הפרויקט הנכון.
gcloud config set project replace-with-your-project-id
עכשיו אמור להופיע במסוף Cloud Shell הפרויקט הנכון. מזהה הפרויקט שנבחר מסומן בצבע צהוב.

הפעלה של ממשקי API נדרשים
כדי להשתמש בשירותי Google Cloud כמו Cloud Run, צריך קודם להפעיל את ממשקי ה-API המתאימים לפרויקט. מריצים את הפקודות הבאות ב-Cloud Shell כדי להפעיל את השירותים הנדרשים ל-Codelab הזה:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. בחירת המודל המתאים
אפשר למצוא הרבה מודלים פתוחים באתרים כמו Hugging Face Hub ו-Kaggle. אם רוצים להשתמש באחד מהמודלים האלה בשירות כמו Google Cloud Run, צריך לבחור מודל שמתאים למשאבים שיש לכם (כלומר, NVIDIA L4 GPU).
מעבר לגודל, חשוב לזכור מה המודל יכול לעשות בפועל. המודלים לא זהים, ולכל אחד מהם יש יתרונות וחסרונות משלו. לדוגמה, יש מודלים שיכולים להתמודד עם סוגים שונים של קלט (כמו תמונות וטקסט – יכולות שנקראות מולטימודאליות), ויש מודלים שיכולים לזכור ולעבד יותר מידע בבת אחת (כלומר, יש להם חלונות הקשר גדולים יותר). לרוב, למודלים גדולים יותר יש יכולות מתקדמות יותר כמו קריאה לפונקציות וחשיבה.
חשוב גם לבדוק אם כלי ההגשה (vLLM במקרה הזה) תומך במודל הרצוי. כאן אפשר לראות את כל המודלים שנתמכים על ידי vLLM.
עכשיו נסביר על Gemma 3, משפחת מודלים חדשה של מודלי שפה גדולים (LLM) שזמינים לכולם. יש ארבעה גדלים שונים של Gemma 3, בהתאם למורכבות שלהם, שנמדדת בפרמטרים: מיליארד, 4 מיליארד, 12 מיליארד ו-27 מיליארד.
לכל אחד מהגדלים האלה יש שני סוגים עיקריים:
- גרסת בסיס (שעברה אימון מראש): זהו מודל הבסיס שלמד מכמות עצומה של נתונים.
- גרסה שעברה כוונון להוראות: הגרסה הזו עברה שיפור נוסף כדי להבין ולבצע הוראות או פקודות ספציפיות בצורה טובה יותר.
המודלים הגדולים יותר (4 מיליארד, 12 מיליארד ו-27 מיליארד פרמטרים) הם מולטי-מודאליים, כלומר הם יכולים להבין ולעבוד עם תמונות ועם טקסט. עם זאת, הווריאנט הקטן ביותר של מיליארד פרמטרים מתמקד רק בטקסט.
בשיעור Codelab הזה נשתמש בוריאנטים של Gemma 3 עם מיליארד פרמטרים: gemma-3-1b-it. שימוש במודל קטן יותר גם עוזר לכם ללמוד איך לעבוד עם משאבים מוגבלים, וזה חשוב כדי לצמצם את העלויות ולוודא שהאפליקציה פועלת בצורה חלקה בענן.
4. משתני סביבה וסודות
יצירת קובץ סביבה
לפני שנמשיך, מומלץ לרכז את כל ההגדרות שבהן תשתמשו במהלך ה-Codelab במקום אחד. כדי להתחיל, פותחים את הטרמינל ומבצעים את השלבים הבאים:
- יוצרים תיקייה חדשה לפרויקט הזה.
- עוברים לתיקייה החדשה שנוצרה.
- יוצרים קובץ .env ריק בתיקייה הזו (הקובץ הזה יכיל בהמשך את משתני הסביבה)
זו הפקודה לביצוע השלבים האלה:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
לאחר מכן, מעתיקים את המשתנים שמופיעים בהמשך ומדביקים אותם בקובץ .env שיצרתם.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
חשוב לזכור להחליף את ערכי הפלייסהולדר (your_project_id ו-your_region) בפרטי הפרויקט הספציפיים שלכם. לדוגמה (PROJECT_ID=unique-ai-project ו-REGION=europe-west4). כאן אפשר לראות את רשימת האזורים שתומכים ב-GPU ב-Cloud Run.
אחרי שעורכים ושומרים את קובץ .env, מקלידים את הפקודה הבאה כדי לטעון את משתני הסביבה האלה בסשן הטרמינל:
source .env
כדי לבדוק אם המשתנים נטענו בהצלחה, אפשר להדפיס את אחד המשתנים. לדוגמה:
echo $SERVICE_NAME
אם מקבלים את אותו ערך שהוקצה בקובץ .env, סימן שהמשתנים נטענו בהצלחה.
אחסון סוד ב-Secret Manager
הגישה המומלצת לנתונים רגישים, כולל קודי גישה, פרטי כניסה וסיסמאות, היא באמצעות כלי לניהול סודות.
כדי להשתמש במודלים של Gemma 3, צריך קודם לאשר את התנאים וההגבלות, כי הגישה אליהם מוגבלת. אפשר לאשר את התנאים וההגבלות דרך כרטיס המודל Gamma 3 ב-Hugging Face Hub.
אחרי שמקבלים את טוקן הגישה של Hugging Face, עוברים לדף Secret Manager ויוצרים סוד לפי ההוראות הבאות:
- עוברים אל מסוף Google Cloud
- בוחרים את הפרויקט מהתפריט הנפתח בפינה הימנית העליונה
- בסרגל החיפוש, מחפשים את Secret Manager ולוחצים על האפשרות הזו כשהיא מופיעה.
כשנמצאים בדף Secret Manager:
- לוחצים על הלחצן +Create Secret (יצירת סוד).
- ממלאים את הפרטים הבאים:
- שם: HF_TOKEN
- Secret Value: <your_hf_access_token>
- בסיום, לוחצים על הלחצן יצירת סוד.
עכשיו טוקן הגישה של Hugging Face אמור להיות סוד ב-Google Cloud Secret Manager.
כדי לבדוק את הגישה לסוד, מריצים את הפקודה הבאה בטרמינל. הפקודה הזו תאחזר את הסוד מ-Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
טוקן הגישה אמור להישלף ולהופיע בחלון המסוף.
מתן גישה לסוד לחשבון השירות ב-Cloud Build
הסוד מאוחסן עכשיו בצורה מאובטחת ב-Secret Manager,
כדי לעשות זאת, מריצים את הפקודות הבאות במסוף:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. יצירה של חשבון שירות
כדי לשפר את האבטחה ולנהל את הגישה בצורה יעילה בסביבת ייצור, השירותים צריכים לפעול במסגרת חשבונות שירות ייעודיים שמוגבלים להרשאות הנדרשות למשימות הספציפיות שלהם.
מריצים את הפקודה הבאה כדי ליצור חשבון שירות
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
הפקודה הבאה מצרפת את ההרשאה הנדרשת
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. יצירת תמונה ב-Artifact Registry
בשלב הזה יוצרים קובץ אימג' של Docker שכולל את משקלי המודל ואת vLLM שהותקן מראש.
1. יצירת מאגר Docker ב-Artifact Registry
בשלב הבא ניצור מאגר Docker ב-Artifact Registry כדי להעביר אליו בדחיפה את קובצי האימג' שיצרנו. מריצים את הפקודה הבאה במסוף:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. שמירת המודל
בהתאם לשיטות המומלצות לשימוש ב-GPU, אפשר לאחסן מודלים של ML בתוך תמונות של קונטיינרים או לטעון אותם מ-Cloud Storage בצורה אופטימלית.
כמובן שלכל גישה יש יתרונות וחסרונות משלה. ניתן לקרוא את מאמרי העזרה כדי ללמוד עליהם. לצורך פשטות, נאחסן את המודל בקובץ אימג' של קונטיינר. תעשו את זה בביקור הבא.
3. יצירת קובץ Docker
יוצרים קובץ בשם Dockerfile ומעתיקים אליו את התוכן שבהמשך:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. יצירת קובץ YAML לפריסה
לאחר מכן, יוצרים קובץ בשם cloudbuild.yaml באותה ספרייה. הקובץ הזה מגדיר את השלבים ש-Cloud Build צריך לבצע. מעתיקים את התוכן הבא ומדביקים אותו בקובץ cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. שליחת ה-build ל-Cloud Build
מעתיקים ומדביקים את הקוד הבא ומפעילים אותו במסוף:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
הפקודה הזו מעלה את הקוד (Dockerfile ו-cloudbuild.yaml), מעבירה את משתני ה-shell כתחליפים (_MODEL_NAME ו-_IMAGE_NAME) ומתחילה את ה-build.
Cloud Build יבצע עכשיו את השלבים שמוגדרים ב-cloudbuild.yaml. אפשר לעקוב אחרי היומנים במסוף או ללחוץ על הקישור לפרטי הבנייה ב-Cloud Console. בסיום התהליך, קובץ האימג' של הקונטיינר יהיה זמין במאגר של Artifact Registry, ויהיה מוכן לפריסה.
6. פריסה ב-Cloud Run
עכשיו אפשר לפרוס את השירות ב-Cloud Run. מריצים את הפקודה הבאה במסוף:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. בדיקת השירות
כדי ליצור פרוקסי שדרכו תוכלו לגשת לשירות כשהוא פועל ב-localhost, מריצים את הפקודה הבאה בטרמינל:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
בחלון טרמינל חדש, מריצים את הפקודה curl הבאה בטרמינל כדי לבדוק את החיבור
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
אם הפלט שמוצג לכם דומה לזה שמופיע בהמשך:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. סיכום
מעולה! סיימת בהצלחה את ה-Codelab הזה. למדתם איך:
- בוחרים גודל מודל שמתאים לפריסה המיועדת.
- הגדרת vLLM להכניס לשימוש בסביבת הייצור API שתואם ל-OpenAI.
- יצירת קונטיינרים מאובטחים לשרת vLLM ולמשקלי המודל באמצעות Docker.
- העברה בדחיפה של קובץ אימג' של קונטיינר אל Google Artifact Registry.
- פריסת שירות מבוסס-GPU ב-Cloud Run.
- בדיקת מודל מאומת שנפרס.
אתם מוזמנים לנסות לפרוס מודלים מעניינים אחרים כמו Llama, Mistral או Qwen כדי להמשיך את תהליך הלמידה.
9. הסרת המשאבים
כדי להימנע מחיובים עתידיים, חשוב למחוק את המשאבים שיצרתם. מריצים את הפקודות הבאות כדי לנקות את הפרויקט.
1. מחיקת שירות Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. מחיקת מאגר Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. מוחקים את חשבון השירות:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. מחיקת הסוד מ-Secret Manager:
gcloud secrets delete HF_TOKEN --quiet