
1. परिचय
लार्ज लैंग्वेज मॉडल (एलएलएम) की मदद से, स्मार्ट ऐप्लिकेशन बनाने के तरीके में बदलाव हो रहा है. हालांकि, इन शक्तिशाली मॉडल को असल दुनिया में इस्तेमाल करने के लिए तैयार करना मुश्किल हो सकता है. इसके लिए, बहुत ज़्यादा कंप्यूटिंग पावर की ज़रूरत होती है. खास तौर पर, ग्राफ़िक्स कार्ड (जीपीयू) की. साथ ही, एक साथ कई अनुरोधों को मैनेज करने के लिए स्मार्ट तरीकों की भी ज़रूरत होती है. साथ ही, आपको लागत कम रखनी है और अपने ऐप्लिकेशन को बिना किसी रुकावट के चलाना है.
इस कोडलैब में, आपको इन चुनौतियों से निपटने का तरीका बताया जाएगा! हम दो मुख्य टूल का इस्तेमाल करेंगे:
- vLLM: इसे एलएलएम के लिए बहुत तेज़ इंजन माना जाता है. इससे आपके मॉडल ज़्यादा बेहतर तरीके से काम करते हैं. साथ ही, एक साथ कई अनुरोधों को हैंडल करते हैं और मेमोरी का इस्तेमाल कम करते हैं.
- Google Cloud Run: यह Google का सर्वरलेस प्लैटफ़ॉर्म है. यह ऐप्लिकेशन डिप्लॉय करने के लिए बहुत अच्छा है, क्योंकि यह आपके लिए सभी स्केलिंग को मैनेज करता है. जैसे, शून्य उपयोगकर्ताओं से लेकर हज़ारों उपयोगकर्ताओं तक और फिर से कम उपयोगकर्ताओं तक. सबसे अच्छी बात यह है कि Cloud Run अब जीपीयू के साथ काम करता है. एलएलएम को होस्ट करने के लिए जीपीयू ज़रूरी होते हैं!
vLLM और Cloud Run, दोनों मिलकर एलएलएम को सर्व करने का एक बेहतर, फ़्लेक्सिबल, और किफ़ायती तरीका उपलब्ध कराते हैं. इस गाइड में, आपको एक ओपन मॉडल डिप्लॉय करने का तरीका बताया जाएगा. इससे यह मॉडल, स्टैंडर्ड वेब एपीआई के तौर पर उपलब्ध हो जाएगा.
आपको क्या सीखने को मिलेगा
- विज्ञापन दिखाने के लिए, मॉडल का सही साइज़ और वैरिएंट कैसे चुनें.
- OpenAI के साथ काम करने वाले एपीआई एंडपॉइंट को उपलब्ध कराने के लिए, vLLM को सेट अप करने का तरीका.
- Docker की मदद से, vLLM सर्वर को कंटेनर में बदलने का तरीका.
- कंटेनर इमेज को Google Artifact Registry में पुश करने का तरीका.
- जीपीयू ऐक्सेलरेटर की मदद से, कंटेनर को Cloud Run पर डिप्लॉय करने का तरीका.
- डिप्लॉय किए गए मॉडल की जांच करने का तरीका.
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud Console को ऐक्सेस करने के लिए, Chrome जैसे ब्राउज़र का इस्तेमाल करें
- एक अच्छा इंटरनेट कनेक्शन
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- Hugging Face का ऐक्सेस टोकन. अगर आपके पास अब तक कोई ऐक्सेस टोकन नहीं है, तो यहां जाकर एक टोकन बनाएं
- Python, Docker, और कमांड लाइन इंटरफ़ेस के बारे में बुनियादी जानकारी
- चीज़ें जानने की दिलचस्पी और सीखने की इच्छा
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट सेट अप करना
इस कोडलैब के लिए, चालू बिलिंग खाते वाला Google Cloud प्रोजेक्ट ज़रूरी है.
- शिक्षक की निगरानी में होने वाले सेशन के लिए: अगर आप किसी क्लासरूम में हैं, तो आपका शिक्षक आपको ज़रूरी प्रोजेक्ट और बिलिंग की जानकारी देगा. सेट अप पूरा करने के लिए, अपने शिक्षक के निर्देशों का पालन करें.
- खुद से सीखने वाले लोगों के लिए: अगर आपको यह सुविधा खुद से इस्तेमाल करनी है और आपके पास कोई चालू बिलिंग खाता नहीं है, तो आपको अपनी पेमेंट की जानकारी का इस्तेमाल करके एक बिलिंग खाता सेट अप करना होगा. नया बिलिंग खाता बनाने और उसे अपने प्रोजेक्ट के लिए चालू करने के लिए, Google Cloud Billing का दस्तावेज़ पढ़ें.
Google Cloud प्रोजेक्ट बनाना
इस कोडलैब के सभी काम को व्यवस्थित रखने और अन्य प्रोजेक्ट से अलग रखने के लिए, आपको एक नया Google Cloud प्रोजेक्ट बनाना होगा.
प्रोजेक्ट बनाने वाला पेज खोलने के लिए, इस पर क्लिक करें:
प्रोजेक्ट बनाने वाले पेज पर, ज़रूरी जानकारी डालें:
- प्रोजेक्ट का नाम - अपनी पसंद का कोई भी नाम डाला जा सकता है. जैसे, genai-workshop
- जगह की जानकारी - इसे कोई संगठन नहीं के तौर पर छोड़ दें
- बिलिंग खाता - अगर यह विकल्प दिखता है, तो "Google Cloud Platform का ट्रायल बिलिंग खाता" चुनें. इसके अलावा, अगर आपको कोई और विकल्प चुनना है, तो अपना बिलिंग खाता चुनें. अगर आपको यह विकल्प नहीं दिखता है, तो अगले चरण पर जाएं.
जनरेट किए गए प्रोजेक्ट आईडी को कॉपी करें. आपको इसकी ज़रूरत बाद में पड़ेगी. 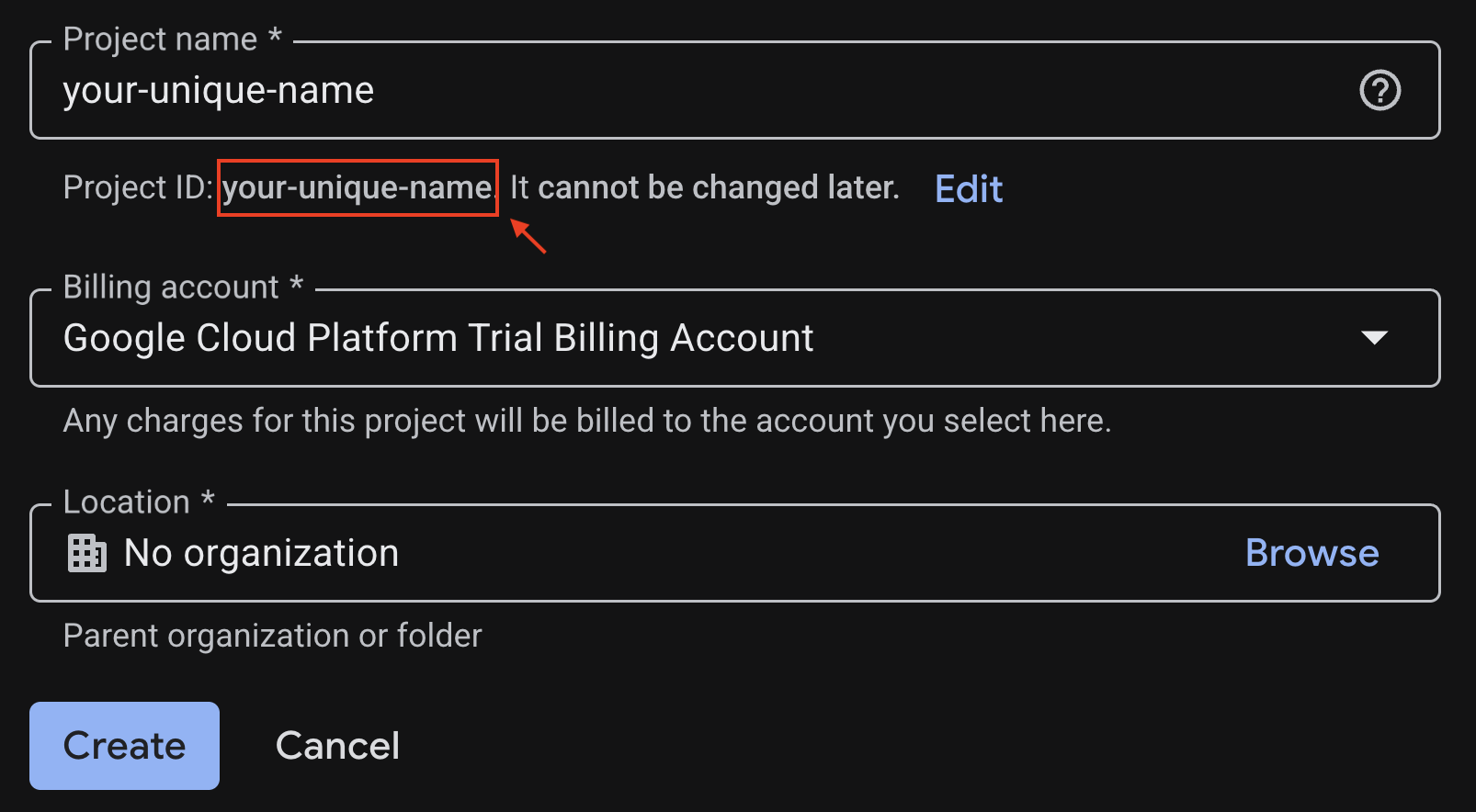
अगर सब कुछ ठीक है, तो बनाएं बटन पर क्लिक करें.
Cloud Shell को कॉन्फ़िगर करना
Cloud Shell एक पहले से कॉन्फ़िगर किया गया एनवायरमेंट है. इसमें इस कोडलैब के लिए ज़रूरी सभी टूल मौजूद हैं. प्रोजेक्ट बन जाने के बाद, Cloud Shell को सेट अप करने के लिए, यह तरीका अपनाएं.
Cloud Shell लॉन्च करें
Cloud Shell लॉन्च करने के लिए, इस पर क्लिक करें:
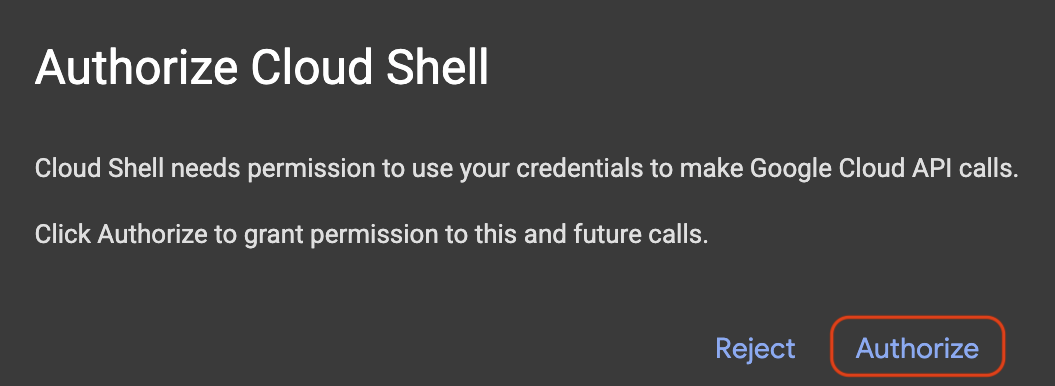
अगर आपको अनुमति देने के लिए कोई पॉप-अप दिखता है, तो अनुमति दें पर क्लिक करें.
प्रोजेक्ट आईडी सेट करें
replace-with-your-project-id की जगह, ऊपर दिए गए प्रोजेक्ट बनाने के चरण में मिला अपना असल प्रोजेक्ट आईडी डालें. सही प्रोजेक्ट आईडी सेट करने के लिए, Cloud Shell टर्मिनल में यह कमांड चलाएं.
gcloud config set project replace-with-your-project-id
अब आपको Cloud Shell टर्मिनल में, सही प्रोजेक्ट चुना हुआ दिखेगा. चुना गया प्रोजेक्ट आईडी, पीले रंग में हाइलाइट किया जाता है.

ज़रूरी एपीआई चालू करना
Cloud Run जैसी Google Cloud सेवाओं का इस्तेमाल करने के लिए, आपको पहले अपने प्रोजेक्ट के लिए उनसे जुड़े एपीआई चालू करने होंगे. इस कोडलैब के लिए ज़रूरी सेवाएं चालू करने के लिए, Cloud Shell में ये कमांड चलाएं:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. सही मॉडल चुनना
आपको Hugging Face Hub और Kaggle जैसी वेबसाइटों पर कई ओपन मॉडल मिल सकते हैं. अगर आपको Google Cloud Run जैसी किसी सेवा पर इनमें से किसी मॉडल का इस्तेमाल करना है, तो आपको ऐसा मॉडल चुनना होगा जो आपके पास मौजूद संसाधनों (जैसे, NVIDIA L4 GPU) के साथ काम करता हो.
सिर्फ़ साइज़ ही नहीं, यह भी ध्यान रखें कि मॉडल असल में क्या कर सकता है. सभी मॉडल एक जैसे नहीं होते. हर मॉडल के अपने फ़ायदे और कमियां होती हैं. उदाहरण के लिए, कुछ मॉडल अलग-अलग तरह के इनपुट को प्रोसेस कर सकते हैं. जैसे, इमेज और टेक्स्ट. इसे मल्टीमॉडल क्षमताएं कहा जाता है. वहीं, कुछ मॉडल एक साथ ज़्यादा जानकारी को याद रख सकते हैं और उसे प्रोसेस कर सकते हैं. इसका मतलब है कि उनके पास कॉन्टेक्स्ट विंडो बड़ी होती हैं. अक्सर, बड़े मॉडल में फ़ंक्शन कॉलिंग और सोचने जैसी बेहतर सुविधाएं होती हैं.
यह भी देखना ज़रूरी है कि आपका पसंदीदा मॉडल, सर्वर करने वाले टूल (इस मामले में vLLM) के साथ काम करता है या नहीं. vLLM के साथ काम करने वाले सभी मॉडल यहां देखे जा सकते हैं.
अब हम Gemma 3 के बारे में जानते हैं. यह Google के ओपन सोर्स लार्ज लैंग्वेज मॉडल (एलएलएम) का नया ग्रुप है. Gemma 3, चार अलग-अलग स्केल में उपलब्ध है. ये स्केल, मॉडल की जटिलता के आधार पर तय किए जाते हैं. इनकी माप पैरामीटर में की जाती है: 100 करोड़, 400 करोड़, 1200 करोड़, और 2700 करोड़.
इनमें से हर साइज़ के लिए, आपको दो मुख्य टाइप दिखेंगे:
- बुनियादी (पहले से ट्रेन किया गया) वर्शन: यह बुनियादी मॉडल है, जिसे बड़े पैमाने पर डेटा से सीखा गया है.
- निर्देशों के हिसाब से तैयार किया गया वर्शन: इस वर्शन को और बेहतर बनाया गया है, ताकि यह खास निर्देशों या कमांड को बेहतर तरीके से समझ सके और उनका पालन कर सके.
बड़े मॉडल (400 करोड़, 1200 करोड़, और 2700 करोड़ पैरामीटर) मल्टीमॉडल होते हैं. इसका मतलब है कि ये इमेज और टेक्स्ट, दोनों को समझ सकते हैं और उनके साथ काम कर सकते हैं. हालांकि, सबसे छोटा 100 करोड़ पैरामीटर वाला वैरिएंट सिर्फ़ टेक्स्ट पर फ़ोकस करता है.
इस कोडलैब के लिए, हम Gemma 3 के 100 करोड़ वैरिएंट का इस्तेमाल करेंगे: gemma-3-1b-it. छोटे मॉडल का इस्तेमाल करने से, आपको यह भी पता चलता है कि सीमित संसाधनों के साथ कैसे काम किया जाता है. यह लागत को कम रखने और यह पक्का करने के लिए ज़रूरी है कि आपका ऐप्लिकेशन क्लाउड में आसानी से काम करे.
4. एनवायरमेंट वैरिएबल और सीक्रेट
एनवायरमेंट फ़ाइल बनाना
आगे बढ़ने से पहले, यह अच्छा तरीका है कि इस कोडलैब में इस्तेमाल किए जाने वाले सभी कॉन्फ़िगरेशन को एक जगह पर रखा जाए. शुरू करने के लिए, अपना टर्मिनल खोलें और यह तरीका अपनाएं:
- इस प्रोजेक्ट के लिए, एक नया फ़ोल्डर बनाएं.
- अभी बनाए गए फ़ोल्डर पर जाएं.
- इस फ़ोल्डर में एक खाली .env फ़ाइल बनाएं. इस फ़ाइल में बाद में आपके एनवायरमेंट वैरिएबल सेव किए जाएंगे
यहां उन चरणों को पूरा करने के लिए कमांड दी गई है:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
इसके बाद, यहां दिए गए वैरिएबल को कॉपी करें और उन्हें अभी बनाई गई .env फ़ाइल में चिपकाएं.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
प्लेसहोल्डर वैल्यू (your_project_id और your_region) को अपने प्रोजेक्ट की जानकारी से बदलना न भूलें. उदाहरण के लिए (PROJECT_ID=unique-ai-project और REGION=europe-west4). उन इलाकों की सूची यहां देखें जहां Cloud Run पर जीपीयू इस्तेमाल किए जा सकते हैं.
.env फ़ाइल में बदलाव करने और उसे सेव करने के बाद, एनवायरमेंट वैरिएबल को टर्मिनल सेशन में लोड करने के लिए, यह कमांड टाइप करें:
source .env
वैरिएबल में से किसी एक को इको करके, यह टेस्ट किया जा सकता है कि वैरिएबल लोड हुए हैं या नहीं. उदाहरण के लिए:
echo $SERVICE_NAME
अगर आपको वही वैल्यू मिलती है जो आपने .env फ़ाइल में असाइन की थी, तो इसका मतलब है कि वैरिएबल लोड हो गए हैं.
Secret Manager में कोई सीक्रेट सेव करना
हमारा सुझाव है कि ऐक्सेस कोड, क्रेडेंशियल, और पासवर्ड जैसे संवेदनशील डेटा के लिए, सीक्रेट मैनेजर का इस्तेमाल करें.
Gemma 3 मॉडल का इस्तेमाल करने से पहले, आपको नियम और शर्तों को स्वीकार करना होगा. ऐसा इसलिए, क्योंकि ये मॉडल सीमित तौर पर उपलब्ध हैं. Hugging Face Hub पर मौजूद Gamma 3 मॉडल कार्ड के ज़रिए, नियमों और शर्तों को स्वीकार किया जा सकता है.
Hugging Face का ऐक्सेस टोकन मिलने के बाद, Secret Manager पेज पर जाएं और इन निर्देशों का पालन करके सीक्रेट बनाएं
- Google Cloud Console पर जाएं
- सबसे ऊपर बाईं ओर मौजूद ड्रॉपडाउन बार से प्रोजेक्ट चुनें
- खोज बार में Secret Manager खोजें और दिखने पर उस विकल्प पर क्लिक करें
Secret Manager पेज पर जाकर:
- +नया सीक्रेट बनाएं बटन पर क्लिक करें,
- यह जानकारी भरें:
- Name: HF_TOKEN
- सीक्रेट वैल्यू: <your_hf_access_token>
- काम पूरा होने के बाद, सीक्रेट बनाएं बटन पर क्लिक करें.
अब आपके पास Google Cloud Secret Manager पर, Hugging Face का ऐक्सेस टोकन सीक्रेट के तौर पर होना चाहिए.
टर्मिनल में नीचे दी गई कमांड को चलाकर, सीक्रेट को ऐक्सेस करने की सुविधा की जांच की जा सकती है. यह कमांड, सीक्रेट मैनेजर से सीक्रेट को वापस पाएगी:
gcloud secrets versions access latest --secret=HF_TOKEN
आपको टर्मिनल विंडो में, ऐक्सेस टोकन वापस मिलते हुए और दिखते हुए दिखना चाहिए.
Cloud Build सेवा खाते को सीक्रेट का ऐक्सेस देना
सीक्रेट को अब Secret Manager में सुरक्षित तरीके से सेव किया जाता है.
इसके लिए, टर्मिनल में ये कमांड चलाएं:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. सेवा खाता बनाना
सुरक्षा को बेहतर बनाने और प्रोडक्शन सेटिंग में ऐक्सेस को असरदार तरीके से मैनेज करने के लिए, सेवाओं को खास सेवा खातों के तहत काम करना चाहिए. इन खातों को सिर्फ़ उन अनुमतियों तक सीमित रखा जाना चाहिए जो उनके खास कामों के लिए ज़रूरी हैं.
सेवा खाता बनाने के लिए, यह कमांड चलाएं
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
नीचे दी गई कमांड से, ज़रूरी अनुमति अटैच की जा सकती है
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Artifact Registry पर इमेज बनाना
इस चरण में, एक Docker इमेज बनाई जाती है. इसमें मॉडल के वेट और पहले से इंस्टॉल किया गया vLLM शामिल होता है.
1. Artifact Registry पर Docker डेटा स्टोर करने की जगह बनाना
बनाई गई इमेज को पुश करने के लिए, Artifact Registry में एक Docker रिपॉज़िटरी बनाते हैं. टर्मिनल में यह कमांड चलाएं:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. मॉडल सेव करना
जीपीयू के सबसे सही तरीकों के बारे में जानकारी देने वाले दस्तावेज़ के आधार पर, एमएल मॉडल को कंटेनर इमेज में सेव किया जा सकता है या Cloud Storage से लोड करने के लिए ऑप्टिमाइज़ किया जा सकता है.
हर तरीके के अपने फ़ायदे और नुकसान होते हैं. इनके बारे में ज़्यादा जानने के लिए, दस्तावेज़ पढ़ें. आसान बनाने के लिए, हम मॉडल को सिर्फ़ कंटेनर इमेज में सेव करेंगे. अगले सेशन में आपको यह करना होगा.
3. डॉकर फ़ाइल बनाना
Dockerfile नाम की एक फ़ाइल बनाएं और इसमें यहां दिया गया कॉन्टेंट कॉपी करें:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. डिप्लॉयमेंट के लिए yaml फ़ाइल बनाना
इसके बाद, उसी डायरेक्ट्री में cloudbuild.yaml नाम की एक फ़ाइल बनाएं. इस फ़ाइल में, Cloud Build के लिए ज़रूरी चरणों के बारे में बताया गया है. नीचे दिए गए कॉन्टेंट को कॉपी करें और cloudbuild.yaml में चिपकाएं:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Cloud Build को बिल्ड सबमिट करना
यहां दिए गए कोड को कॉपी करके चिपकाएं और इसे टर्मिनल में चलाएं:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
यह कमांड, आपके कोड (Dockerfile और cloudbuild.yaml) को अपलोड करती है. साथ ही, आपके शेल वैरिएबल को सबस्टिट्यूशन (_MODEL_NAME और _IMAGE_NAME) के तौर पर पास करती है और बिल्ड शुरू करती है.
अब Cloud Build, cloudbuild.yaml में तय किए गए चरणों को पूरा करेगा. अपने टर्मिनल में लॉग को फ़ॉलो किया जा सकता है. इसके अलावा, Cloud Console में बिल्ड की जानकारी के लिंक पर क्लिक करके भी लॉग को फ़ॉलो किया जा सकता है. यह प्रोसेस पूरी होने के बाद, कंटेनर इमेज आपकी Artifact Registry रिपॉज़िटरी में उपलब्ध होगी. अब इसे डिप्लॉय किया जा सकता है.
6. Cloud Run पर डिप्लॉय करें
अब सेवा को Cloud Run पर डिप्लॉय किया जा सकता है. टर्मिनल में यह कमांड चलाएं:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. सेवा को आज़माना
टर्मिनल में यह कमांड चलाकर एक प्रॉक्सी बनाएं, ताकि आप सेवा को वैसे ही ऐक्सेस कर सकें जैसे वह localhost में चल रही है:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
कनेक्शन की जांच करने के लिए, नई टर्मिनल विंडो में टर्मिनल में यह curl कमांड चलाएं
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
अगर आपको नीचे दिए गए उदाहरण जैसा आउटपुट दिखता है, तो:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. नतीजा
बधाई हो! आपने इस कोडलैब को पूरा कर लिया है. आपने इनके बारे में जाना:
- टारगेट डिप्लॉयमेंट के लिए, मॉडल का सही साइज़ चुनें.
- OpenAI के साथ काम करने वाले एपीआई को इस्तेमाल करने के लिए, vLLM सेट अप करें.
- Docker की मदद से, vLLM सर्वर और मॉडल वेट को सुरक्षित तरीके से कंटेनर में रखें.
- कंटेनर इमेज को Google Artifact Registry में पुश करें.
- Cloud Run पर, जीपीयू ऐक्सेलरेटेड सेवा डिप्लॉय करें.
- पुष्टि किए गए और डिप्लॉय किए गए मॉडल की जांच करना.
सीखने की अपनी यात्रा को जारी रखने के लिए, Llama, Mistral या Qwen जैसे अन्य बेहतरीन मॉडल को बेझिझक डिप्लॉय करें!
9. क्लीन अप करें
आने वाले समय में शुल्क से बचने के लिए, बनाए गए संसाधनों को मिटाना ज़रूरी है. अपने प्रोजेक्ट को क्लीन अप करने के लिए, ये कमांड चलाएं.
1. Cloud Run सेवा मिटाएं:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Artifact Registry रिपॉज़िटरी मिटाएं:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. सेवा खाता मिटाने के लिए:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Secret Manager से सीक्रेट मिटाएं:
gcloud secrets delete HF_TOKEN --quiet