
1. Pengantar
Model Bahasa Besar (LLM) mengubah cara kita membangun aplikasi pintar. Namun, menyiapkan model canggih ini untuk digunakan di dunia nyata bisa jadi rumit. Mereka memerlukan banyak daya komputasi, terutama kartu grafis (GPU), dan cara cerdas untuk menangani banyak permintaan sekaligus. Selain itu, Anda ingin menekan biaya dan memastikan aplikasi berjalan lancar tanpa penundaan.
Codelab ini akan menunjukkan cara mengatasi tantangan ini. Kita akan menggunakan dua alat utama:
- vLLM: Anggap ini sebagai mesin super cepat untuk LLM. Hal ini membuat model Anda berjalan jauh lebih efisien, menangani lebih banyak permintaan sekaligus, dan mengurangi penggunaan memori.
- Google Cloud Run: Ini adalah platform serverless Google. Layanan ini sangat cocok untuk men-deploy aplikasi karena menangani semua penskalaan untuk Anda – dari nol pengguna hingga ribuan, dan kembali lagi. Yang terbaik dari semuanya, Cloud Run kini mendukung GPU, yang penting untuk menghosting LLM.
Bersama-sama, vLLM dan Cloud Run menawarkan cara yang efektif, fleksibel, dan hemat biaya untuk menyajikan LLM Anda. Dalam panduan ini, Anda akan men-deploy model terbuka, sehingga tersedia sebagai API web standar.
Yang akan Anda pelajari
- Cara memilih ukuran dan varian model yang tepat untuk penyajian.
- Cara menyiapkan vLLM untuk menayangkan endpoint API yang kompatibel dengan OpenAI.
- Cara memasukkan server vLLM ke dalam container dengan Docker.
- Cara mengirim image container Anda ke Google Artifact Registry.
- Cara men-deploy container ke Cloud Run dengan akselerasi GPU.
- Cara menguji model yang di-deploy.
Yang Anda butuhkan
- Browser, seperti Chrome, untuk mengakses Konsol Google Cloud
- Koneksi internet yang andal
- Project Google Cloud dengan penagihan diaktifkan
- Token Akses Hugging Face (buat di sini jika Anda belum memilikinya)
- Pemahaman dasar tentang Python, Docker, dan antarmuka command line
- Pikiran yang ingin tahu dan semangat untuk belajar
2. Sebelum Memulai
Siapkan Project Google Cloud
Codelab ini memerlukan Project Google Cloud dengan akun penagihan yang aktif.
- Untuk sesi yang dipandu instruktur: Jika Anda berada di ruang kelas, instruktur akan memberi Anda informasi proyek dan penagihan yang diperlukan. Ikuti petunjuk dari instruktur Anda untuk menyelesaikan penyiapan.
- Untuk pelajar mandiri: Jika Anda melakukannya sendiri dan tidak memiliki akun penagihan aktif, Anda harus menyiapkan akun penagihan menggunakan informasi pembayaran Anda sendiri. Lihat dokumentasi Penagihan Google Cloud untuk membuat akun penagihan baru dan mengaktifkannya untuk project Anda.
Buat project Google Cloud
Untuk menjaga semua pekerjaan Anda untuk codelab ini tetap teratur dan terpisah dari project lain, Anda akan memulai dengan membuat project Google Cloud baru.
Untuk membuka halaman pembuatan project, klik:
Masukkan informasi yang diperlukan di halaman pembuatan project:
- Nama project - Anda dapat memasukkan nama apa pun yang diinginkan (misalnya, genai-workshop)
- Lokasi - biarkan sebagai Tidak Ada Organisasi
- Akun penagihan - Jika opsi ini muncul, pilih "Akun Penagihan Uji Coba Google Cloud Platform" atau akun penagihan Anda sendiri jika Anda mau. Jika Anda tidak melihat opsi ini, Anda dapat melanjutkan ke langkah berikutnya.
Salin Project ID yang dibuat, Anda akan memerlukannya nanti. 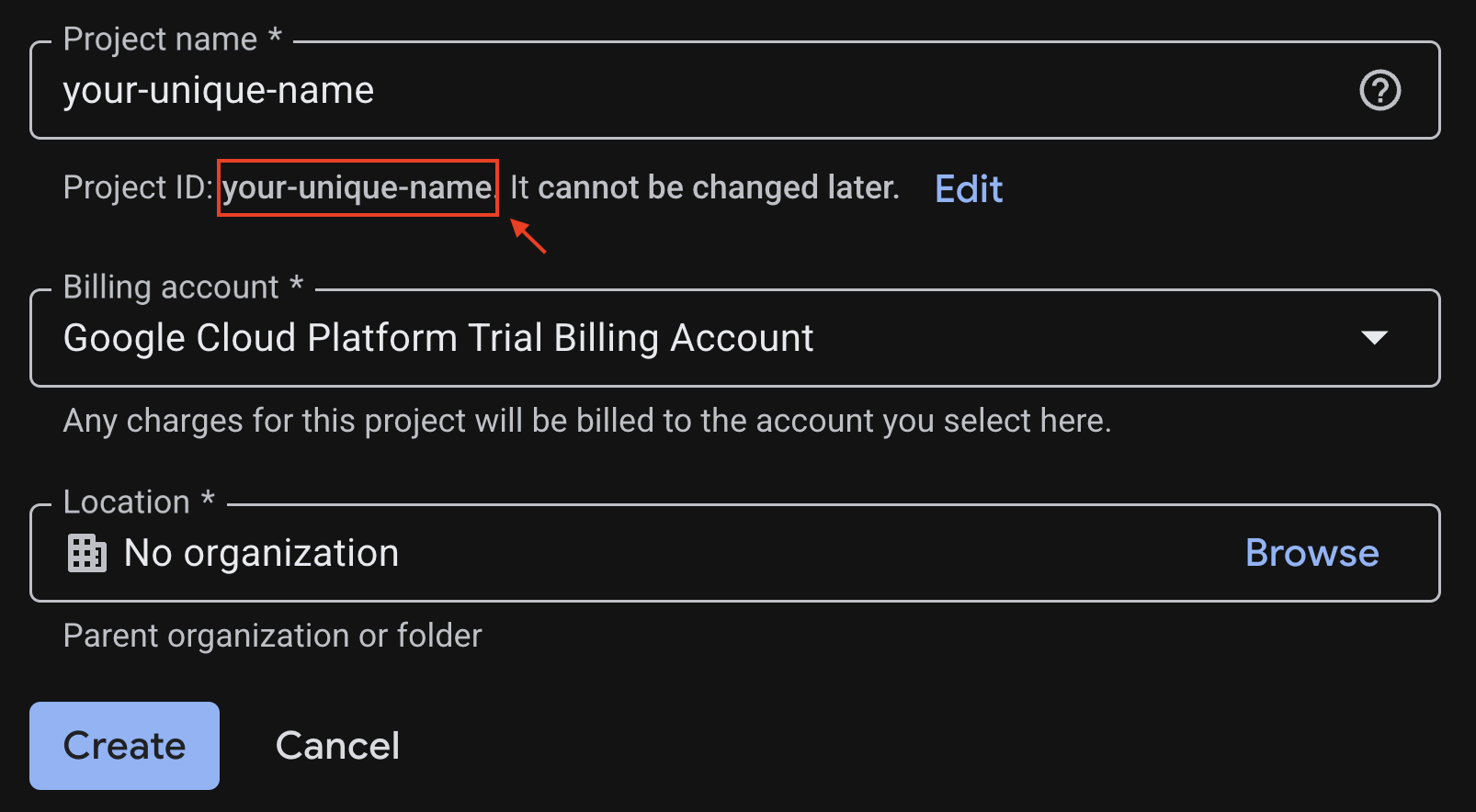
Jika semuanya sudah benar, klik tombol Buat.
Mengonfigurasi Cloud Shell
Cloud Shell adalah lingkungan yang telah dikonfigurasi sebelumnya dengan semua alat yang Anda butuhkan untuk codelab ini. Setelah project Anda berhasil dibuat, lakukan langkah-langkah berikut untuk menyiapkan Cloud Shell.
Luncurkan Cloud Shell
Untuk meluncurkan Cloud Shell, klik:
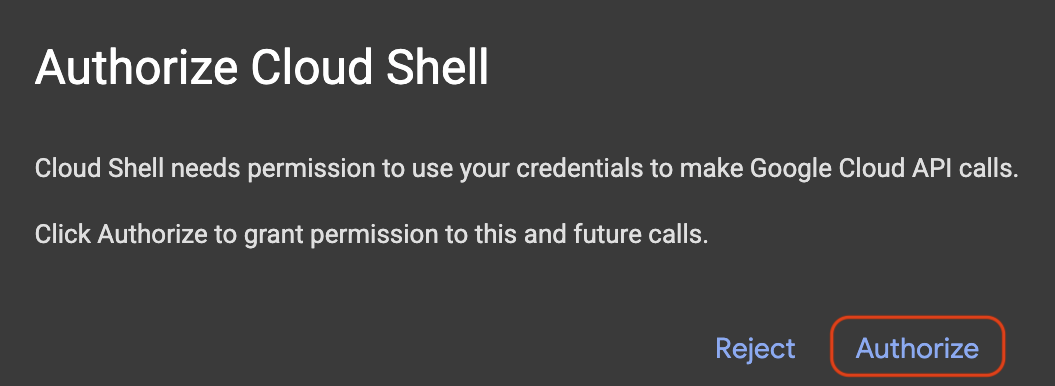
Jika pop-up muncul dan meminta otorisasi, klik Authorize.
Tetapkan ID Project
Ganti replace-with-your-project-id dengan Project ID Anda yang sebenarnya dari langkah pembuatan project di atas. Jalankan perintah berikut di terminal Cloud Shell untuk menetapkan Project ID yang benar.
gcloud config set project replace-with-your-project-id
Sekarang Anda akan melihat bahwa project yang benar telah dipilih di terminal Cloud Shell. Project ID yang dipilih ditandai dengan warna kuning.

Aktifkan API yang diperlukan
Untuk menggunakan layanan Google Cloud seperti Cloud Run, Anda harus mengaktifkan API masing-masing untuk project Anda terlebih dahulu. Jalankan perintah berikut di Cloud Shell untuk mengaktifkan layanan yang diperlukan untuk Codelab ini:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Memilih model yang tepat
Anda dapat menemukan banyak model terbuka di situs seperti Hugging Face Hub dan Kaggle. Saat ingin menggunakan salah satu model ini di layanan seperti Google Cloud Run, Anda harus memilih model yang sesuai dengan resource yang Anda miliki (yaitu GPU NVIDIA L4).
Selain ukuran, ingatlah untuk mempertimbangkan apa yang sebenarnya dapat dilakukan model. Model tidak semuanya sama; masing-masing memiliki kelebihan dan kekurangan. Misalnya, beberapa model dapat menangani berbagai jenis input (seperti gambar dan teks – yang dikenal sebagai kemampuan multimodal), sementara model lainnya dapat mengingat dan memproses lebih banyak informasi sekaligus (artinya, model tersebut memiliki jendela konteks yang lebih besar). Sering kali, model yang lebih besar akan memiliki kemampuan yang lebih canggih seperti panggilan fungsi dan pemikiran.
Penting juga untuk memeriksa apakah model yang Anda inginkan didukung oleh alat penayangan (vLLM dalam kasus ini). Anda dapat memeriksa semua model yang didukung oleh vLLM di sini.
Sekarang, mari kita pelajari Gemma 3, yang merupakan lini Model Bahasa Besar (LLM) terbaru Google yang tersedia secara terbuka. Gemma 3 hadir dalam empat skala berbeda berdasarkan kompleksitasnya, yang diukur dalam parameter: 1 miliar, 4 miliar, 12 miliar, dan 27 miliar.
Untuk setiap ukuran ini, Anda akan menemukan dua jenis utama:
- Versi dasar (terlatih): Ini adalah model dasar yang telah mempelajari sejumlah besar data.
- Versi yang dioptimalkan untuk mengikuti perintah: Versi ini telah dioptimalkan lebih lanjut untuk lebih memahami dan mengikuti petunjuk atau perintah tertentu.
Model yang lebih besar (4 miliar, 12 miliar, dan 27 miliar parameter) bersifat multimodal, yang berarti model ini dapat memahami dan bekerja dengan gambar dan teks. Namun, varian parameter 1 miliar terkecil hanya berfokus pada teks.
Untuk Codelab ini, kita akan menggunakan 1 miliar varian Gemma 3: gemma-3-1b-it. Menggunakan model yang lebih kecil juga membantu Anda mempelajari cara bekerja dengan resource terbatas, yang penting untuk menekan biaya dan memastikan aplikasi Anda berjalan lancar di cloud.
4. Variabel Lingkungan & Secret
Buat file lingkungan
Sebelum melanjutkan, sebaiknya semua konfigurasi yang akan Anda gunakan di seluruh Codelab ini berada di satu tempat. Untuk memulai, buka terminal Anda dan lakukan langkah-langkah berikut:
- Buat folder baru untuk project ini.
- Buka folder yang baru dibuat.
- Buat file .env kosong dalam folder ini (file ini akan menyimpan variabel lingkungan Anda nanti)
Berikut perintah untuk melakukan langkah-langkah tersebut:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Selanjutnya, salin variabel yang tercantum di bawah dan tempelkan ke file.env yang baru saja Anda buat.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Jangan lupa mengganti nilai placeholder (your_project_id dan your_region) dengan informasi project spesifik Anda. Misalnya (PROJECT_ID=unique-ai-project dan REGION=europe-west4). Lihat daftar region yang mendukung GPU di Cloud Run di sini.
Setelah file.env diedit dan disimpan, ketik perintah ini untuk memuat variabel lingkungan tersebut ke dalam sesi terminal:
source .env
Anda dapat menguji apakah variabel berhasil dimuat atau tidak dengan mengulang salah satu variabel. Contoh:
echo $SERVICE_NAME
Jika Anda mendapatkan nilai yang sama dengan yang Anda tetapkan dalam .env file, berarti variabel berhasil dimuat.
Menyimpan secret di Secret Manager
Untuk data sensitif apa pun, termasuk kode akses, kredensial, dan sandi, sebaiknya gunakan pengelola secret.
Sebelum menggunakan model Gemma 3, Anda harus menyetujui persyaratan dan ketentuan terlebih dahulu, karena model ini dibatasi. Anda dapat menyetujui persyaratan dan ketentuan melalui Kartu Model Gamma 3 di Hub Hugging Face.
Setelah Anda memiliki Token Akses Hugging Face, buka halaman Secret Manager dan buat secret dengan mengikuti petunjuk berikut
- Buka Konsol Google Cloud
- Pilih project dari panel dropdown kiri atas
- Telusuri Secret Manager di kotak penelusuran dan klik opsi tersebut saat muncul
Saat Anda berada di halaman Secret Manager:
- Klik tombol +Buat Secret,
- Isi informasi berikut:
- Name: HF_TOKEN
- Secret Value: <your_hf_access_token>
- Klik tombol Buat Secret setelah Anda selesai.
Sekarang Anda akan memiliki Token Akses Hugging Face sebagai secret di Google Cloud Secret Manager.
Anda dapat menguji akses ke secret dengan menjalankan perintah di bawah di terminal. Perintah tersebut akan mengambilnya dari Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
Anda akan melihat Token Akses Anda diambil dan ditampilkan di jendela terminal.
Memberikan akses rahasia ke akun layanan Cloud Build
Karena secret kini disimpan dengan aman di Secret Manager,
Jalankan perintah berikut di terminal untuk melakukannya:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Membuat akun layanan
Untuk meningkatkan keamanan dan mengelola akses secara efektif dalam setelan produksi, layanan harus beroperasi di bawah akun layanan khusus yang dibatasi secara ketat untuk izin yang diperlukan bagi tugas tertentu.
Jalankan perintah ini untuk membuat akun layanan
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
Perintah berikut melampirkan izin yang diperlukan
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Membuat Image di Artifact Registry
Langkah ini melibatkan pembuatan image Docker yang mencakup bobot model dan vLLM yang telah diinstal sebelumnya.
1. Buat repositori Docker di Artifact Registry
Mari buat repositori Docker di Artifact Registry untuk mengirim image yang Anda buat. Jalankan perintah berikut di terminal:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Menyimpan model
Berdasarkan dokumentasi praktik terbaik GPU, Anda dapat menyimpan model ML di dalam image container atau mengoptimalkan pemuatannya dari Cloud Storage.
Tentu saja, setiap pendekatan memiliki kelebihan dan kekurangannya masing-masing. Anda dapat membaca dokumentasi untuk mempelajari lebih lanjut. Untuk mempermudah, kita hanya akan menyimpan model di image container. Anda akan melakukannya di sesi berikutnya.
3. Buat file Docker
Buat file bernama Dockerfile dan salin konten di bawah ke dalamnya:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Membuat file yaml untuk deployment
Selanjutnya, buat file bernama cloudbuild.yaml di direktori yang sama. File ini menentukan langkah-langkah yang harus diikuti Cloud Build. Salin dan tempel konten berikut ke cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Kirim build ke Cloud Build
Salin dan tempel kode berikut, lalu jalankan di terminal:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Perintah ini mengupload kode Anda (Dockerfile dan cloudbuild.yaml), meneruskan variabel shell sebagai penggantian (_MODEL_NAME dan _IMAGE_NAME), serta memulai build.
Cloud Build kini akan mengeksekusi langkah-langkah yang ditentukan dalam cloudbuild.yaml. Anda dapat mengikuti log di terminal atau dengan mengklik link ke detail build di Konsol Cloud. Setelah selesai, image container akan tersedia di repositori Artifact Registry Anda, siap untuk di-deploy.
6. Deploy ke Cloud Run
Sekarang Anda siap men-deploy layanan ke Cloud Run. Jalankan perintah ini di terminal:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Uji layanan
Jalankan perintah berikut di terminal untuk membuat proxy, sehingga Anda dapat mengakses layanan saat berjalan di localhost:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
Di jendela terminal baru, jalankan perintah curl ini di terminal untuk menguji koneksi
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Jika Anda melihat output yang mirip seperti di bawah:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Kesimpulan
Selamat! Anda berhasil menyelesaikan Codelab ini. Anda telah mempelajari cara:
- Pilih ukuran model yang sesuai untuk deployment target.
- Siapkan vLLM untuk menayangkan API yang kompatibel dengan OpenAI.
- Buat container server vLLM dan bobot model dengan aman menggunakan Docker.
- Kirim image container ke Google Artifact Registry.
- Men-deploy layanan yang diakselerasi GPU ke Cloud Run.
- Menguji model yang di-deploy dan diautentikasi.
Jangan ragu untuk mempelajari cara men-deploy model menarik lainnya seperti Llama, Mistral, atau Qwen untuk melanjutkan perjalanan belajar Anda.
9. Pembersihan
Untuk menghindari tagihan di masa mendatang, Anda harus menghapus resource yang Anda buat. Jalankan perintah berikut untuk membersihkan project Anda.
1. Hapus layanan Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Hapus repositori Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Hapus akun layanan:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Hapus secret dari Secret Manager:
gcloud secrets delete HF_TOKEN --quiet