
1. Introduzione
I modelli linguistici di grandi dimensioni (LLM) stanno cambiando il modo in cui creiamo applicazioni intelligenti. Tuttavia, preparare questi modelli potenti per l'uso nel mondo reale può essere complicato. Richiedono molta potenza di calcolo, in particolare schede grafiche (GPU), e modi intelligenti per gestire molte richieste contemporaneamente. Inoltre, vuoi ridurre i costi e mantenere la tua applicazione in esecuzione senza problemi e senza ritardi.
Questo codelab ti mostrerà come affrontare queste sfide. Utilizzeremo due strumenti chiave:
- vLLM: consideralo un motore super veloce per gli LLM. Rende i tuoi modelli molto più efficienti, gestendo più richieste contemporaneamente e riducendo l'utilizzo della memoria.
- Google Cloud Run: è la piattaforma serverless di Google. È ideale per il deployment delle applicazioni perché gestisce tutta la scalabilità per te, da zero utenti a migliaia e viceversa. La cosa migliore è che Cloud Run ora supporta le GPU, essenziali per l'hosting degli LLM.
Insieme, vLLM e Cloud Run offrono un modo potente, flessibile ed economico per erogare i tuoi LLM. In questa guida, eseguirai il deployment di un modello open, rendendolo disponibile come API web standard.
Obiettivi didattici
- Come scegliere la dimensione e la variante del modello giuste per la pubblicazione.
- Come configurare vLLM per pubblicare endpoint API compatibili con OpenAI.
- Come creare un container del server vLLM con Docker.
- Come eseguire il push dell'immagine container in Google Artifact Registry.
- Come eseguire il deployment del container in Cloud Run con accelerazione della GPU.
- Come testare il modello di cui hai eseguito il deployment.
Che cosa ti serve
- Un browser, ad esempio Chrome, per accedere alla console Google Cloud
- Una connessione a internet affidabile
- Un progetto Google Cloud con la fatturazione abilitata
- Un token di accesso a Hugging Face (creane uno qui se non ne hai ancora uno)
- Una conoscenza di base di Python, Docker e dell'interfaccia a riga di comando
- Una mente curiosa e la voglia di imparare
2. Prima di iniziare
Configurare il progetto Google Cloud
Questo codelab richiede un progetto Google Cloud con un account di fatturazione attivo.
- Per le sessioni guidate da un istruttore:se ti trovi in un'aula, l'istruttore ti fornirà le informazioni sul progetto e i dati di fatturazione necessari. Segui le istruzioni dell'insegnante per completare la configurazione.
- Per gli studenti indipendenti:se stai svolgendo questo codelab in autonomia e non hai un account di fatturazione attivo, dovrai configurarne uno utilizzando i tuoi dati di pagamento. Consulta la documentazione sulla fatturazione Cloud di Google per creare un nuovo account di fatturazione e abilitarlo per il tuo progetto.
Crea un progetto Google Cloud
Per mantenere tutto il lavoro per questo codelab organizzato e separato dagli altri progetti, inizierai creando un nuovo progetto Google Cloud.
Per aprire la pagina di creazione del progetto, fai clic su:
Inserisci le informazioni richieste nella pagina di creazione del progetto:
- Nome progetto : puoi inserire il nome che preferisci (ad es. genai-workshop)
- Località : lascia Nessuna organizzazione
- Account di fatturazione : se viene visualizzata questa opzione, seleziona "Account di fatturazione di prova di Google Cloud Platform" o il tuo account di fatturazione, se preferisci. Se non vedi questa opzione, puoi procedere al passaggio successivo.
Prendi nota dell'ID progetto generato, ti servirà in un secondo momento. 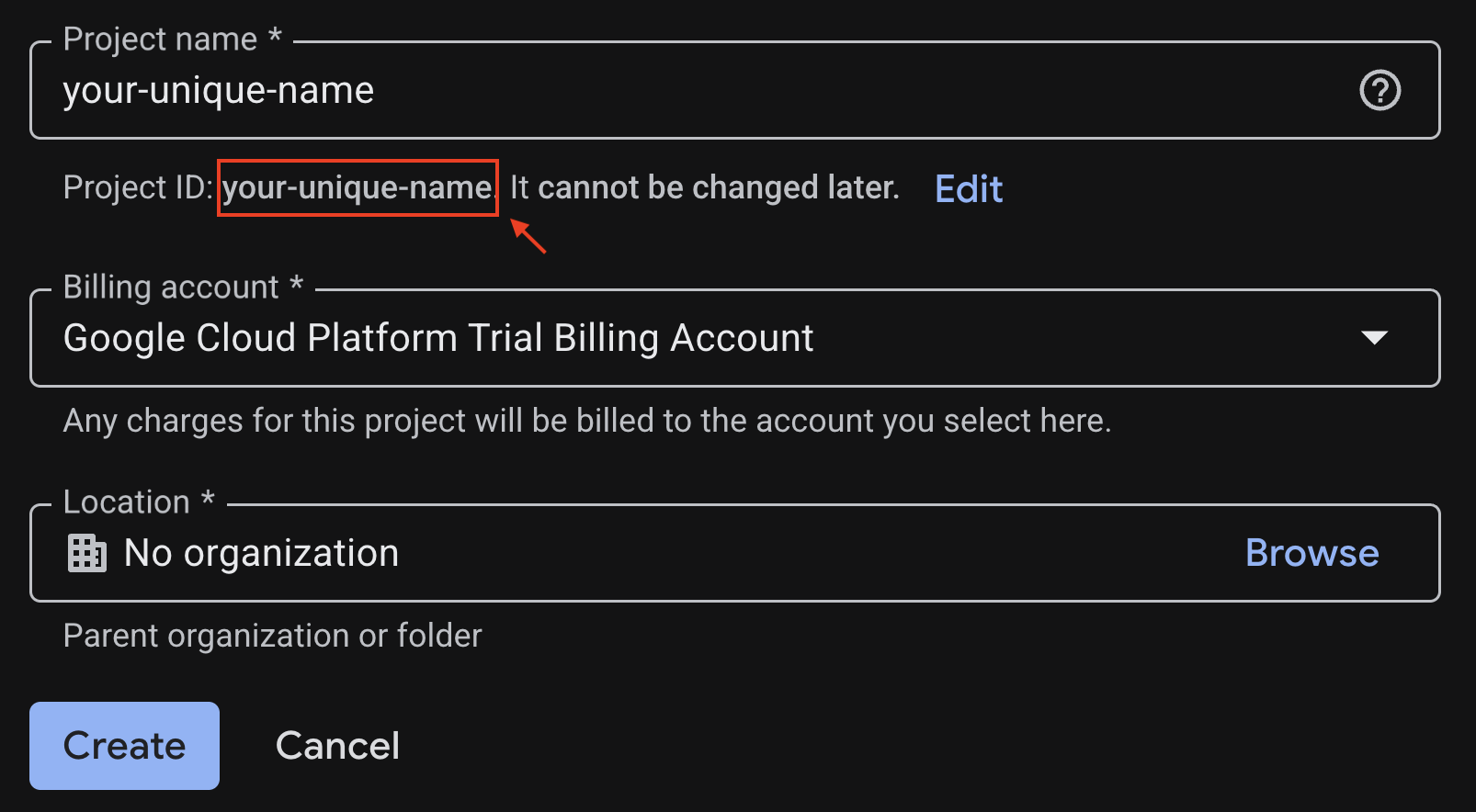
Se è tutto a posto, fai clic sul pulsante Crea.
Configurare Cloud Shell
Cloud Shell è un ambiente preconfigurato con tutti gli strumenti necessari per questo codelab. Una volta creato il progetto, segui questi passaggi per configurare Cloud Shell.
Avviare Cloud Shell
Per avviare Cloud Shell, fai clic su:
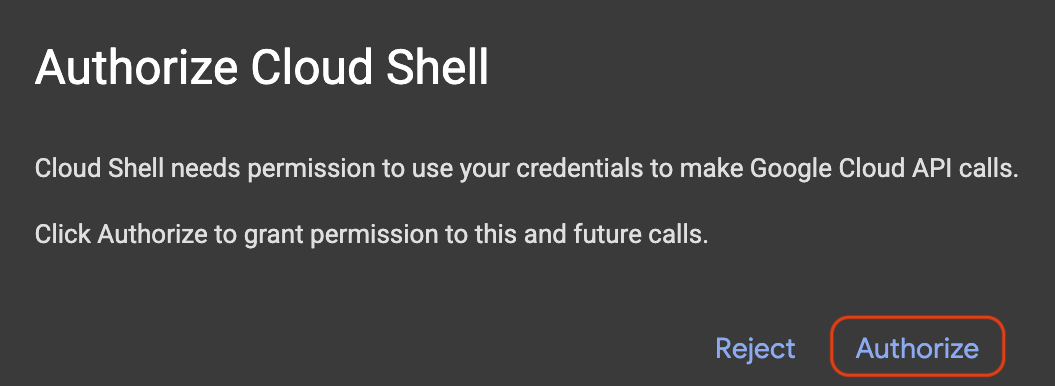
Se viene visualizzato un popup che richiede l'autorizzazione, fai clic su Autorizza.
Impostare l'ID progetto
Sostituisci replace-with-your-project-id con l'ID progetto effettivo del passaggio di creazione del progetto riportato sopra. Esegui il comando seguente nel terminale Cloud Shell per impostare l'ID progetto corretto.
gcloud config set project replace-with-your-project-id
A questo punto dovresti vedere che nel terminale Cloud Shell è selezionato il progetto corretto. L'ID progetto selezionato è evidenziato in giallo.

Abilitare le API necessarie
Per utilizzare i servizi Google Cloud come Cloud Run, devi prima attivare le rispettive API per il tuo progetto. Esegui i seguenti comandi in Cloud Shell per abilitare i servizi necessari per questo codelab:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Scegliere il modello giusto
Puoi trovare molti modelli open su siti web come Hugging Face Hub e Kaggle. Quando vuoi utilizzare uno di questi modelli su un servizio come Google Cloud Run, devi sceglierne uno adatto alle risorse che hai a disposizione (ad es. GPU NVIDIA L4).
Oltre alle dimensioni, ricorda di considerare cosa può fare effettivamente il modello. I modelli non sono tutti uguali; ognuno ha i suoi vantaggi e svantaggi. Ad esempio, alcuni modelli possono gestire diversi tipi di input (come immagini e testo, funzionalità multimodali), mentre altri possono ricordare ed elaborare più informazioni contemporaneamente (il che significa che hanno finestre di contesto più grandi). Spesso, i modelli più grandi avranno funzionalità più avanzate come la chiamata di funzioni e il ragionamento.
È anche importante verificare se il modello che ti interessa è supportato dallo strumento di pubblicazione (in questo caso vLLM). Puoi controllare tutti i modelli supportati da vLLM qui.
Ora esploriamo Gemma 3, la più recente famiglia di modelli linguistici di grandi dimensioni (LLM) di Google disponibili pubblicamente. Gemma 3 è disponibile in quattro scale diverse in base alla loro complessità, misurata in parametri: 1 miliardo, 4 miliardi, 12 miliardi e 27 miliardi.
Per ognuna di queste dimensioni, troverai due tipi principali:
- Una versione di base (preaddestrata): è il modello di base che ha appreso da un'enorme quantità di dati.
- Una versione ottimizzata per le istruzioni: questa versione è stata ulteriormente perfezionata per comprendere e seguire meglio istruzioni o comandi specifici.
I modelli più grandi (4 miliardi, 12 miliardi e 27 miliardi di parametri) sono multimodali, il che significa che possono comprendere e lavorare sia con immagini che con testo. La variante più piccola da 1 miliardo di parametri, tuttavia, si concentra esclusivamente sul testo.
Per questo codelab, utilizzeremo varianti da 1 miliardo di Gemma 3: gemma-3-1b-it. L'utilizzo di un modello più piccolo ti aiuta anche a imparare a lavorare con risorse limitate, il che è importante per ridurre i costi e garantire che la tua app funzioni senza problemi nel cloud.
4. Variabili di ambiente e secret
Creare un file di ambiente
Prima di procedere, è consigliabile avere tutte le configurazioni che utilizzerai in questo codelab in un unico posto. Per iniziare, apri il terminale e segui questi passaggi:
- Crea una nuova cartella per questo progetto.
- Vai alla cartella appena creata.
- Crea un file .env vuoto all'interno di questa cartella (questo file conterrà in seguito le variabili di ambiente)
Ecco il comando per eseguire questi passaggi:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Poi, copia le variabili elencate di seguito e incollale nel file.env che hai appena creato.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Ricorda di sostituire i valori segnaposto (your_project_id e your_region) con le informazioni specifiche del tuo progetto. Ad esempio (PROJECT_ID=unique-ai-project e REGION=europe-west4). Consulta l'elenco delle regioni che supportano le GPU su Cloud Run qui.
Una volta modificato e salvato il file.env, digita questo comando per caricare le variabili di ambiente nella sessione del terminale:
source .env
Puoi verificare se le variabili sono state caricate correttamente o meno eseguendo l'eco di una delle variabili. Ad esempio:
echo $SERVICE_NAME
Se ottieni lo stesso valore che hai assegnato nel .env file, le variabili sono state caricate correttamente.
Archiviare un secret in Secret Manager
Per tutti i dati sensibili, inclusi codici di accesso, credenziali e password, l'approccio consigliato è l'utilizzo di un gestore di secret.
Prima di utilizzare i modelli Gemma 3, devi accettare i Termini e condizioni, poiché sono protetti. Puoi accettare i Termini e condizioni tramite la scheda del modello Gemma 3 su Hugging Face Hub.
Una volta ottenuto il token di accesso a Hugging Face, vai alla pagina Secret Manager e crea un secret seguendo queste istruzioni
- Vai alla console Google Cloud
- Seleziona il progetto dalla barra del menu a discesa in alto a sinistra
- Cerca Secret Manager nella barra di ricerca e fai clic sull'opzione quando viene visualizzata
Quando ti trovi nella pagina Secret Manager:
- Fai clic sul pulsante +Crea secret.
- Compila queste informazioni:
- Nome: HF_TOKEN
- Valore secret: <your_hf_access_token>
- Al termine, fai clic sul pulsante Crea secret.
A questo punto dovresti avere il token di accesso a Hugging Face come secret in Google Cloud Secret Manager.
Puoi testare l'accesso al secret eseguendo il comando riportato di seguito nel terminale. Questo comando lo recupererà da Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
Dovresti vedere il token di accesso recuperato e visualizzato nella finestra del terminale.
Concedere l'accesso al secret al service account Cloud Build
Ora che il secret è archiviato in modo sicuro in Secret Manager,
Esegui questi comandi nel terminale per farlo:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Crea un account di servizio
Per migliorare la sicurezza e gestire l'accesso in modo efficace in un ambiente di produzione, i servizi devono operare con service account dedicati che siano strettamente limitati alle autorizzazioni necessarie per le loro attività specifiche.
Esegui questo comando per creare un service account
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
Il comando seguente associa l'autorizzazione necessaria
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Crea un'immagine in Artifact Registry
Questo passaggio prevede la creazione di un'immagine Docker che include i pesi del modello e vLLM preinstallato.
1. Crea un repository Docker in Artifact Registry
Creiamo un repository Docker in Artifact Registry per eseguire il push delle immagini create. Esegui questo comando nel terminale:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Archiviare il modello
In base alla documentazione sulle best practice per le GPU, puoi archiviare i modelli ML all'interno delle immagini container o ottimizzarne il caricamento da Cloud Storage.
Naturalmente, ogni approccio presenta vantaggi e svantaggi. Puoi leggere la documentazione per saperne di più. Per semplicità, archivieremo il modello nell'immagine container. Lo farai nella prossima sessione.
3. Crea un file Docker
Crea un file denominato Dockerfile e copia al suo interno i contenuti riportati di seguito:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Crea un file YAML per il deployment
Poi, crea un file denominato cloudbuild.yaml nella stessa directory. Questo file definisce i passaggi che Cloud Build deve seguire. Copia e incolla i seguenti contenuti in cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Invia la build a Cloud Build
Copia e incolla il seguente codice ed eseguilo nel terminale:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Questo comando carica il codice (il Dockerfile e cloudbuild.yaml), passa le variabili della shell come sostituzioni (_MODEL_NAME e _IMAGE_NAME) e avvia la build.
Cloud Build eseguirà ora i passaggi definiti in cloudbuild.yaml. Puoi seguire i log nel terminale o facendo clic sul link ai dettagli della build nella console Cloud. Al termine, l'immagine container sarà disponibile nel repository Artifact Registry, pronta per il deployment.
6. Eseguire il deployment in Cloud Run
Ora puoi eseguire il deployment del servizio in Cloud Run. Esegui questo comando nel terminale:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Testare il servizio
Esegui il comando seguente nel terminale per creare un proxy, in modo da poter accedere al servizio in esecuzione in localhost:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
In una nuova finestra del terminale, esegui questo comando curl nel terminale per testare la connessione
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Se vedi un output simile a quello riportato di seguito:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Conclusione
Complimenti! Hai completato correttamente questo codelab. Hai imparato a:
- Scegliere una dimensione del modello appropriata per un deployment di destinazione.
- Configurare vLLM per pubblicare un'API compatibile con OpenAI.
- Creare in modo sicuro un container del server vLLM e dei pesi del modello con Docker.
- Eseguire il push di un'immagine container in Google Artifact Registry.
- Eseguire il deployment di un servizio con accelerazione della GPU in Cloud Run.
- Testare un modello autenticato di cui hai eseguito il deployment.
Non esitare a esplorare il deployment di altri modelli interessanti come Llama, Mistral o Qwen per continuare il tuo percorso di apprendimento.
9. Elimina
Per evitare addebiti futuri, è importante eliminare le risorse che hai creato. Esegui i seguenti comandi per liberare spazio nel progetto.
1. Elimina il servizio Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Elimina il repository Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Elimina il service account:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Elimina il secret da Secret Manager:
gcloud secrets delete HF_TOKEN --quiet