
1. はじめに
大規模言語モデル(LLM)は、スマート アプリケーションの構築方法を変えています。しかし、これらの強力なモデルを実世界で使用できるようにするのは難しい場合があります。そのため、高いコンピューティング能力、特にグラフィック カード(GPU)と、多くのリクエストを一度に処理するスマートな方法が必要です。また、費用を抑え、アプリケーションを遅延なくスムーズに実行したいと考えています。
この Codelab では、これらの課題に取り組む方法について説明します。ここでは、次の 2 つの主要なツールを使用します。
- vLLM: LLM の超高速エンジンと考えてください。これにより、モデルの実行効率が大幅に向上し、一度に処理できるリクエストの数が増え、メモリ使用量が削減されます。
- Google Cloud Run: Google のサーバーレス プラットフォームです。ゼロから数千人、そしてまたゼロに戻るまで、すべてのスケーリングを処理するため、アプリケーションのデプロイに最適です。さらに、Cloud Run は GPU をサポートするようになりました。これは、LLM のホスティングに不可欠です。
vLLM と Cloud Run を組み合わせることで、LLM を提供するための強力で柔軟かつ費用対効果の高い方法を実現できます。このガイドでは、オープンモデルをデプロイして、標準のウェブ API として使用できるようにします。
学習内容
- サービングに適したモデルサイズとバリアントを選択する方法。
- OpenAI 互換の API エンドポイントを提供するように vLLM を設定する方法。
- Docker を使用して vLLM サーバーをコンテナ化する方法。
- コンテナ イメージを Google Artifact Registry に push する方法。
- GPU アクセラレーションを使用してコンテナを Cloud Run にデプロイする方法。
- デプロイされたモデルをテストする方法。
必要なもの
- Google Cloud コンソールにアクセスするためのブラウザ(Chrome など)
- 信頼できるインターネット接続
- 課金が有効になっている Google Cloud プロジェクト
- Hugging Face アクセス トークン(まだお持ちでない場合は、こちらで作成してください)
- Python、Docker、コマンドライン インターフェースに関する基本的な知識
- 好奇心と学習意欲
2. 始める前に
Google Cloud プロジェクトを設定する
この Codelab には、有効な請求先アカウントを持つ Google Cloud プロジェクトが必要です。
- 講師主導のセッションの場合: 教室にいる場合は、講師から必要なプロジェクトとお支払い情報が提供されます。講師の指示に沿ってセットアップを完了します。
- 個人で学習する場合: 既存の有効な請求先アカウントがない場合は、ご自身の支払い情報を使用して請求先アカウントを設定する必要があります。新しい請求先アカウントを作成してプロジェクトで有効にするには、Google Cloud Billing のドキュメントをご覧ください。
Google Cloud プロジェクトを作成する
この Codelab の作業をすべて整理し、他のプロジェクトと分離するため、まず新しい Google Cloud プロジェクトを作成します。
プロジェクトの作成ページで、必要な情報を入力します。
- プロジェクト名 - 任意の名前を入力できます(例: genai-workshop)。
- Location - [No Organization] のままにします。
- 請求先アカウント - このオプションが表示されたら、[Google Cloud Platform トライアルの請求先アカウント] を選択するか、必要に応じて独自の請求先アカウントを選択します。このオプションが表示されない場合は、次のステップに進みます。
生成されたプロジェクト ID をコピーします。この ID は後で必要になります。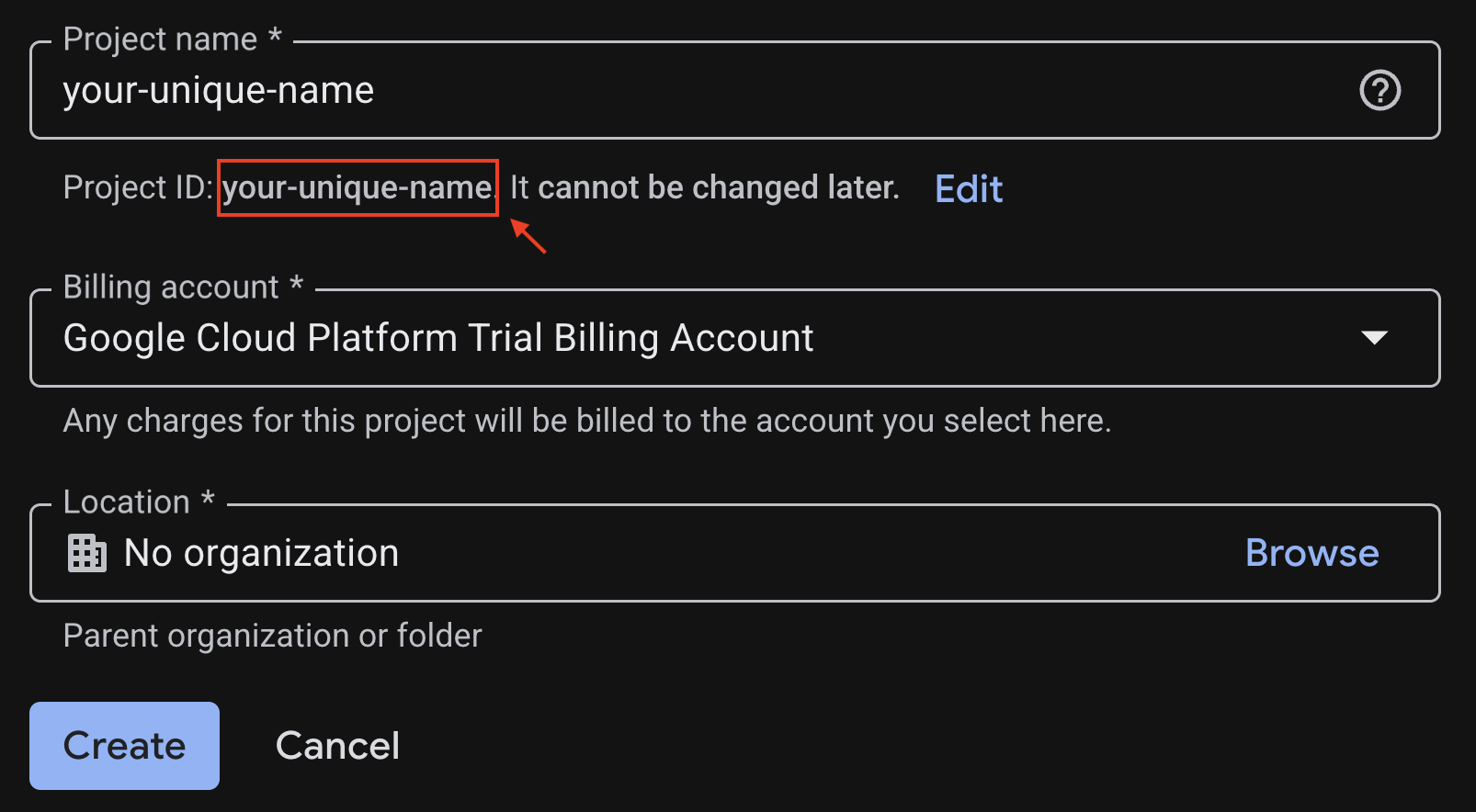
問題がなければ、[作成] ボタンをクリックします。
Cloud Shell を構成する
Cloud Shell は、この Codelab に必要なツールがすべてプリインストールされた環境です。プロジェクトが正常に作成されたら、次の手順で Cloud Shell を設定します。
Cloud Shell を起動する
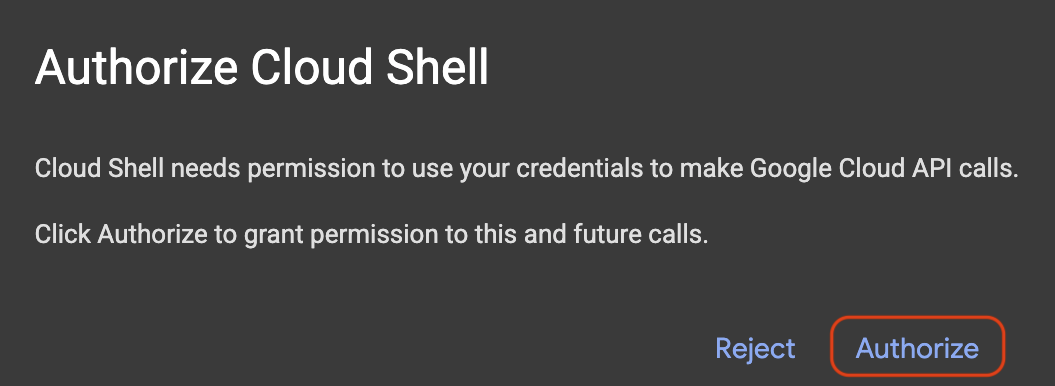
Cloud Shell を起動するには、[] をクリックします。
承認を求めるポップアップが表示された場合は、[承認] をクリックします。
プロジェクト ID を設定
replace-with-your-project-id は、上記のプロジェクト作成ステップで取得した実際のプロジェクト ID に置き換えます。Cloud Shell ターミナルで次のコマンドを実行して、正しいプロジェクト ID を設定します。
gcloud config set project replace-with-your-project-id
これで、Cloud Shell ターミナルで正しいプロジェクトが選択されていることがわかります。選択したプロジェクト ID が黄色でハイライト表示されます。

必要な API を有効にする
Cloud Run などの Google Cloud サービスを使用するには、まずプロジェクトでそれぞれの API を有効にする必要があります。Cloud Shell で次のコマンドを実行して、この Codelab に必要なサービスを有効にします。
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. 適切なモデルを選択する
Hugging Face Hub や Kaggle などのウェブサイトで、多くのオープンモデルを見つけることができます。Google Cloud Run などのサービスでこれらのモデルのいずれかを使用する場合は、使用可能なリソース(NVIDIA L4 GPU など)に適合するモデルを選択する必要があります。
サイズだけでなく、モデルが実際に何ができるかを考慮することも忘れないでください。モデルはすべて同じではありません。それぞれに独自の長所と短所があります。たとえば、画像やテキストなど、さまざまな種類の入力を処理できるモデル(マルチモーダル機能)もあれば、一度に多くの情報を記憶して処理できるモデル(コンテキスト ウィンドウが大きい)もあります。多くの場合、大規模なモデルには、関数呼び出しや思考などの高度な機能が備わっています。
目的のモデルがサービング ツール(この場合は vLLM)でサポートされているかどうかを確認することも重要です。vLLM でサポートされているすべてのモデルは、こちらで確認できます。
次に、Google の最新のオープンな大規模言語モデル(LLM)ファミリーである Gemma 3 について説明します。Gemma 3 には、複雑さに基づいて 4 つの異なるスケールがあります。複雑さはパラメータで測定され、10 億、40 億、120 億、270 億の 4 つのスケールがあります。
これらのサイズには、主に次の 2 種類があります。
- ベース(事前トレーニング済み)バージョン: 大量のデータから学習した基盤モデルです。
- 指示に合わせて調整されたバージョン: このバージョンは、特定の指示やコマンドをよりよく理解して実行できるように、さらに改良されています。
大規模なモデル(40 億、120 億、270 億のパラメータ)はマルチモーダルです。つまり、画像とテキストの両方を理解して処理できます。ただし、最小の 10 億パラメータ バリアントはテキストのみに焦点を当てています。
この Codelab では、Gemma 3 の 10 億個のバリアントである gemma-3-1b-it を使用します。小規模なモデルを使用すると、リソースが限られた環境での作業方法を学ぶこともできます。これは、費用を抑え、アプリがクラウドでスムーズに動作するようにするために重要です。
4. 環境変数とシークレット
環境ファイルを作成する
先に進む前に、この Codelab で使用するすべての構成を 1 か所にまとめておくことをおすすめします。まず、ターミナルを開いて次の手順を行います。
- このプロジェクトの新しいフォルダを作成します。
- 新しく作成したフォルダに移動します。
- このフォルダ内に空の .env ファイルを作成します(このファイルには後で環境変数が格納されます)。
これらの手順を実行するコマンドは次のとおりです。
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
次に、以下の変数をコピーして、作成した .env ファイルに貼り付けます。
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
プレースホルダの値(your_project_id と your_region)は、実際のプロジェクト情報に置き換えてください。たとえば、PROJECT_ID=unique-ai-project と REGION=europe-west4 です。Cloud Run で GPU をサポートするリージョンのリストについては、こちらをご覧ください。
.env ファイルを編集して保存したら、次のコマンドを入力して、これらの環境変数をターミナル セッションに読み込みます。
source .env
変数の 1 つをエコーすることで、変数が正常に読み込まれたかどうかをテストできます。次に例を示します。
echo $SERVICE_NAME
.env ファイルで割り当てた値と同じ値が返された場合は、変数が正常に読み込まれています。
Secret Manager に Secret を保存する
アクセスコード、認証情報、パスワードなどの機密データについては、Secret Manager を使用することをおすすめします。
Gemma 3 モデルを使用する前に、利用規約に同意する必要があります。利用規約は、Hugging Face Hub の Gamma 3 モデルカードで確認できます。
Hugging Face アクセス トークンを取得したら、Secret Manager ページに移動し、次の手順に沿ってシークレットを作成します。
- Google Cloud コンソールに移動します。
- 左上のプルダウン バーからプロジェクトを選択します。
- 検索バーで Secret Manager を検索し、表示されたらそのオプションをクリックします。
[Secret Manager] ページに移動します。
- [+ シークレットを作成] ボタンをクリックします。
- 以下の情報を入力します。
- 名前: HF_TOKEN
- シークレット値: <your_hf_access_token>
- 完了したら、[シークレットを作成] ボタンをクリックします。
これで、Hugging Face アクセス トークンが Google Cloud Secret Manager のシークレットとして登録されました。
ターミナルで次のコマンドを実行して、シークレットへのアクセスをテストできます。このコマンドは、Secret Manager からシークレットを取得します。
gcloud secrets versions access latest --secret=HF_TOKEN
アクセス トークンが取得され、ターミナル ウィンドウに表示されます。
Cloud Build サービス アカウントにシークレットへのアクセス権を付与する
シークレットは Secret Manager に安全に保存されるため、
ターミナルで次のコマンドを実行します。
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. サービス アカウントを作成する
セキュリティを強化し、本番環境でアクセスを効果的に管理するには、サービスは特定のタスクに必要な権限に厳密に制限された専用のサービス アカウントで動作する必要があります。
このコマンドを実行してサービス アカウントを作成します。
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
次のコマンドは、必要な権限を付与します。
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Artifact Registry にイメージを作成する
このステップでは、モデルの重みと事前インストールされた vLLM を含む Docker イメージを作成します。
1. Artifact Registry に Docker リポジトリを作成する
ビルドしたイメージを push するために、Artifact Registry に Docker リポジトリを作成しましょう。ターミナルで、次のコマンドを実行します。
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. モデルの保存
GPU のベスト プラクティスに関するドキュメントに基づいて、ML モデルをコンテナ イメージ内に保存するか、Cloud Storage からの読み込みを最適化できます。
もちろん、どの方法にも長所と短所があります。詳しくは、ドキュメントをご覧ください。わかりやすくするために、モデルをコンテナ イメージに保存します。これは次のセッションで行います。
3. Docker ファイルを作成する
Dockerfile という名前のファイルを作成し、次の内容をコピーします。
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. デプロイ用の YAML ファイルを作成する
次に、同じディレクトリに cloudbuild.yaml という名前のファイルを作成します。このファイルには、Cloud Build が実行するステップが記述されます。次の内容をコピーして cloudbuild.yaml に貼り付けます。
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Cloud Build にビルドを送信する
次のコードをコピーしてターミナルに貼り付け、実行します。
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
このコマンドは、コード(Dockerfile と cloudbuild.yaml)をアップロードし、シェル変数(_MODEL_NAME と _IMAGE_NAME)を置換として渡し、ビルドを開始します。
Cloud Build は、cloudbuild.yaml で定義されたステップを実行します。ログは、ターミナルで確認するか、Cloud Console のビルドの詳細へのリンクをクリックして確認できます。完了すると、コンテナ イメージが Artifact Registry リポジトリで使用可能になり、デプロイの準備が整います。
6. Cloud Run にデプロイする
これで、サービスを Cloud Run にデプロイする準備が整いました。ターミナルで次のコマンドを実行します。
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. サービスをテストする
ターミナルで次のコマンドを実行してプロキシを作成し、localhost で実行されているサービスにアクセスできるようにします。
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
新しいターミナル ウィンドウで、ターミナルで次の curl コマンドを実行して接続をテストします。
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
次のような出力が表示された場合:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. まとめ
おめでとうございます!この Codelab は終了です。具体的には、以下の方法について学習しました。
- ターゲット デプロイに適したモデルサイズを選択します。
- OpenAI 互換 API を提供するように vLLM を設定します。
- Docker を使用して vLLM サーバーとモデルの重みを安全にコンテナ化します。
- コンテナ イメージを Google Artifact Registry に push する。
- GPU アクセラレーション サービスを Cloud Run にデプロイする。
- 認証済みのデプロイ済みモデルをテストする。
Llama、Mistral、Qwen などの他のエキサイティングなモデルのデプロイを試して、学習を続けてください。
9. クリーンアップ
今後課金されないようにするには、作成したリソースを削除することが重要です。次のコマンドを実行して、プロジェクトをクリーンアップします。
1. Cloud Run サービスを削除します。
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Artifact Registry リポジトリを削除します。
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. サービス アカウントを削除します。
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Secret Manager からシークレットを削除します。
gcloud secrets delete HF_TOKEN --quiet