
1. 소개
대규모 언어 모델 (LLM)은 스마트 애플리케이션을 구축하는 방식을 바꾸고 있습니다. 하지만 이러한 강력한 모델을 실제 사용에 맞게 준비하는 것은 까다로울 수 있습니다. 특히 그래픽 카드 (GPU)와 같은 컴퓨팅 성능이 많이 필요하며, 여러 요청을 한 번에 처리할 수 있는 스마트한 방법이 필요합니다. 또한 비용을 절감하고 지연 없이 애플리케이션을 원활하게 실행해야 합니다.
이 Codelab에서는 이러한 문제를 해결하는 방법을 알아봅니다. 두 가지 주요 도구를 사용합니다.
- vLLM: LLM을 위한 매우 빠른 엔진이라고 생각하면 됩니다. 모델이 훨씬 효율적으로 실행되어 한 번에 더 많은 요청을 처리하고 메모리 사용량을 줄입니다.
- Google Cloud Run: Google의 서버리스 플랫폼입니다. 사용자 수가 0명에서 수천 명으로 늘어났다가 다시 줄어드는 등 모든 확장 작업을 처리하므로 애플리케이션을 배포하는 데 매우 유용합니다. 무엇보다도 이제 Cloud Run에서 LLM 호스팅에 필수적인 GPU를 지원합니다.
vLLM과 Cloud Run을 함께 사용하면 강력하고 유연하며 비용 효율적인 방식으로 LLM을 제공할 수 있습니다. 이 가이드에서는 개방형 모델을 배포하여 표준 웹 API로 사용할 수 있도록 합니다.
학습할 내용
- 서빙에 적합한 모델 크기와 변형을 선택하는 방법
- OpenAI 호환 API 엔드포인트를 제공하도록 vLLM을 설정하는 방법
- Docker를 사용하여 vLLM 서버를 컨테이너화하는 방법
- 컨테이너 이미지를 Google Artifact Registry로 푸시하는 방법
- GPU 가속을 사용하여 컨테이너를 Cloud Run에 배포하는 방법
- 배포된 모델을 테스트하는 방법
필요한 항목
- Chrome과 같은 브라우저를 사용하여 Google Cloud 콘솔에 액세스
- 안정적인 인터넷 연결
- 결제가 사용 설정된 Google Cloud 프로젝트
- Hugging Face 액세스 토큰 (아직 없는 경우 여기에서 만드세요)
- Python, Docker, 명령줄 인터페이스에 대한 기본적인 지식
- 호기심과 배우려는 열의
2. 시작하기 전에
Google Cloud 프로젝트 설정
이 Codelab에는 활성 결제 계정이 있는 Google Cloud 프로젝트가 필요합니다.
- 강사 주도 세션: 교실에 있는 경우 강사가 필요한 프로젝트 및 결제 정보를 제공합니다. 강사의 안내에 따라 설정을 완료합니다.
- 독립 학습자: 혼자서 진행하고 기존의 활성 결제 계정이 없는 경우 자신의 결제 정보를 사용하여 결제 계정을 설정해야 합니다. Google Cloud Billing 문서를 참고하여 새 결제 계정을 만들고 프로젝트에 사용 설정하세요.
Google Cloud 프로젝트 만들기
이 Codelab의 모든 작업을 정리하고 다른 프로젝트와 분리하기 위해 새 Google Cloud 프로젝트를 만들어 보겠습니다.
프로젝트 생성 페이지에서 필수 정보를 입력합니다.
- 프로젝트 이름 - 원하는 이름을 입력할 수 있습니다 (예: genai-workshop).
- 위치 - 조직 없음으로 유지
- 결제 계정 - 이 옵션이 표시되면 'Google Cloud Platform 무료 체험판 결제 계정'을 선택하거나 원하는 경우 자체 결제 계정을 선택합니다. 이 옵션이 표시되지 않으면 다음 단계로 진행하면 됩니다.
생성된 프로젝트 ID를 복사해 둡니다. 나중에 필요합니다. 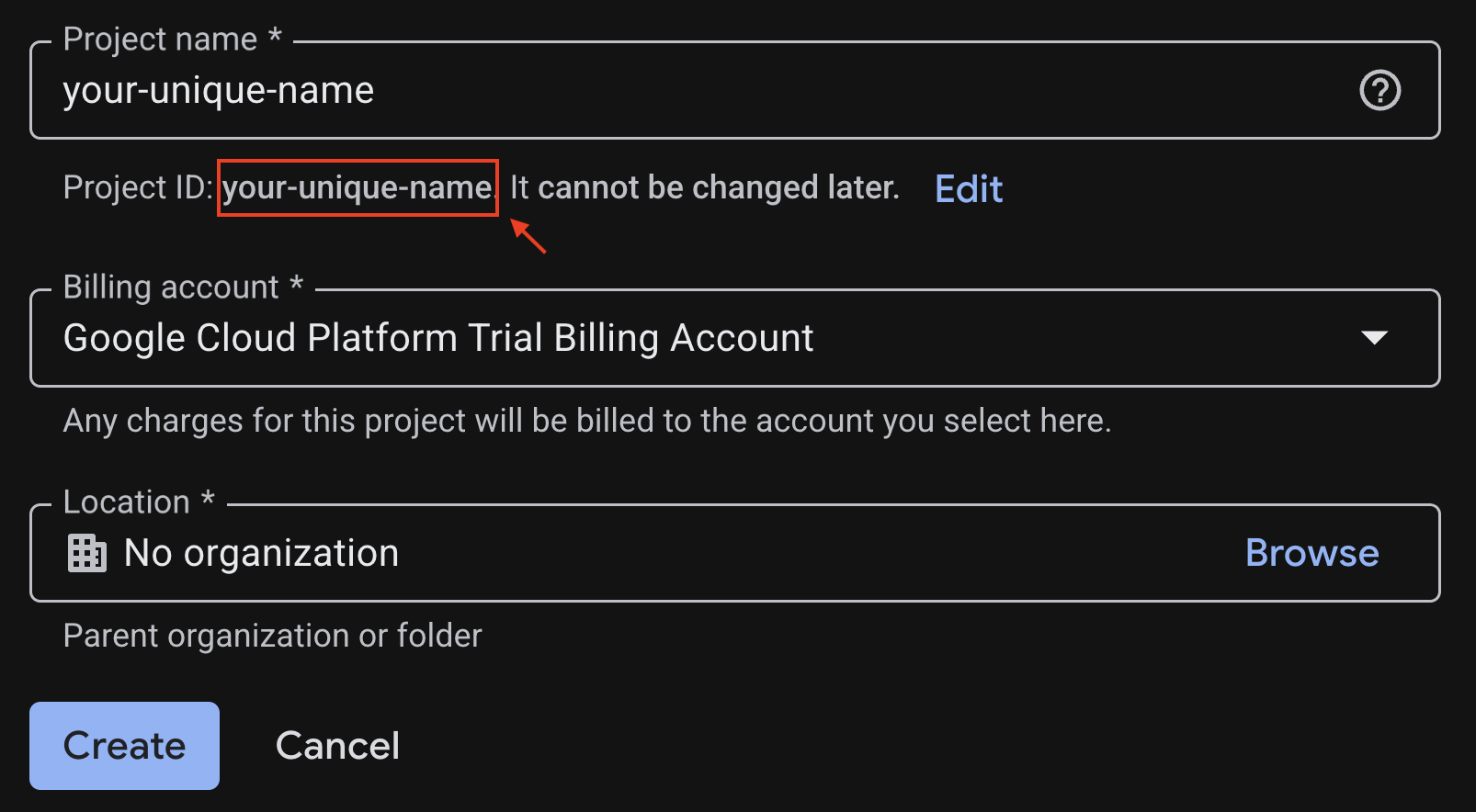
모든 것이 올바르면 만들기 버튼을 클릭합니다.
Cloud Shell 구성
Cloud Shell은 이 Codelab에 필요한 모든 도구가 사전 구성된 환경입니다. 프로젝트가 성공적으로 생성되면 다음 단계에 따라 Cloud Shell을 설정합니다.
Cloud Shell 실행
승인을 요청하는 팝업이 표시되면 승인을 클릭합니다.
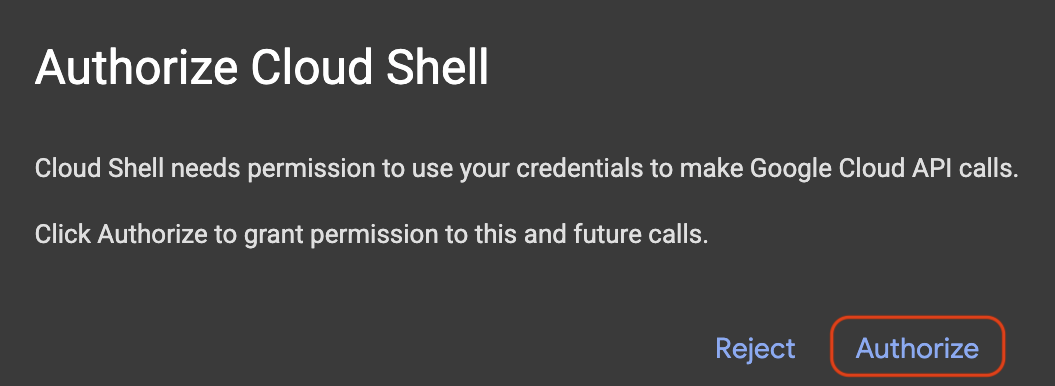
프로젝트 ID 설정
replace-with-your-project-id를 위의 프로젝트 생성 단계에서 가져온 실제 프로젝트 ID로 바꿉니다. Cloud Shell 터미널에서 다음 명령어를 실행하여 올바른 프로젝트 ID를 설정합니다.
gcloud config set project replace-with-your-project-id
이제 Cloud Shell 터미널에서 올바른 프로젝트가 선택되어 있는 것을 확인할 수 있습니다. 선택한 프로젝트 ID가 노란색으로 강조 표시됩니다.

필요한 API 사용 설정
Cloud Run과 같은 Google Cloud 서비스를 사용하려면 먼저 프로젝트에 해당 API를 활성화해야 합니다. Cloud Shell에서 다음 명령어를 실행하여 이 Codelab에 필요한 서비스를 사용 설정합니다.
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. 올바른 모델 선택
Hugging Face Hub, Kaggle과 같은 웹사이트에서 다양한 오픈 모델을 확인할 수 있습니다. Google Cloud Run과 같은 서비스에서 이러한 모델 중 하나를 사용하려면 보유한 리소스 (예: NVIDIA L4 GPU)에 적합한 모델을 선택해야 합니다.
크기뿐만 아니라 모델이 실제로 할 수 있는 작업도 고려해야 합니다. 모델은 모두 동일하지 않으며 각각 장단점이 있습니다. 예를 들어 일부 모델은 다양한 유형의 입력 (예: 이미지 및 텍스트, 멀티모달 기능이라고 함)을 처리할 수 있는 반면, 다른 모델은 한 번에 더 많은 정보를 기억하고 처리할 수 있습니다 (즉, 컨텍스트 윈도우가 더 큼). 대부분의 경우 대규모 모델에는 함수 호출 및 사고와 같은 고급 기능이 있습니다.
원하는 모델이 서빙 도구 (이 경우 vLLM)에서 지원되는지 확인하는 것도 중요합니다. vLLM에서 지원하는 모든 모델은 여기에서 확인할 수 있습니다.
이제 Google의 최신 개방형 대규모 언어 모델 (LLM) 제품군인 Gemma 3를 살펴보겠습니다. Gemma 3는 파라미터로 측정되는 복잡성에 따라 10억, 40억, 120억, 270억의 네 가지 규모로 제공됩니다.
각 크기에는 다음과 같은 두 가지 주요 유형이 있습니다.
- 기본 (사전 학습) 버전: 방대한 양의 데이터로 학습된 파운데이션 모델입니다.
- 명령어에 맞게 조정된 버전: 이 버전은 특정 명령어 또는 요청 사항을 더 잘 이해하고 따르도록 추가로 개선되었습니다.
더 큰 모델 (40억, 120억, 270억 파라미터)은 멀티모달이므로 이미지와 텍스트를 모두 이해하고 사용할 수 있습니다. 하지만 가장 작은 10억 개의 매개변수 변형은 텍스트에만 집중합니다.
이 Codelab에서는 Gemma 3의 10억 개 변형인gemma-3-1b-it을 사용합니다. 작은 모델을 사용하면 제한된 리소스를 사용하는 방법을 배울 수 있으며, 이는 비용을 절감하고 앱이 클라우드에서 원활하게 실행되도록 하는 데 중요합니다.
4. 환경 변수 및 보안 비밀
환경 파일 만들기
계속 진행하기 전에 이 Codelab 전체에서 사용할 모든 구성을 한곳에 모아두는 것이 좋습니다. 시작하려면 터미널을 열고 다음 단계를 따르세요.
- 이 프로젝트의 새 폴더를 만듭니다.
- 새로 만든 폴더로 이동합니다.
- 이 폴더 내에 빈 .env 파일을 만듭니다 (이 파일에는 나중에 환경 변수가 저장됨).
다음은 이러한 단계를 실행하는 명령어입니다.
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
다음으로 아래에 나열된 변수를 복사하여 방금 만든 .env 파일에 붙여넣습니다.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
자리표시자 값 (your_project_id 및 your_region)을 특정 프로젝트 정보로 바꿔야 합니다. 예를 들면 PROJECT_ID=unique-ai-project 및 REGION=europe-west4입니다. 여기에서 Cloud Run에서 GPU를 지원하는 리전 목록을 확인하세요.
.env 파일을 수정하고 저장한 후 다음 명령어를 입력하여 환경 변수를 터미널 세션에 로드합니다.
source .env
변수 중 하나를 에코하여 변수가 성공적으로 로드되었는지 테스트할 수 있습니다. 예를 들면 다음과 같습니다.
echo $SERVICE_NAME
.env 파일에 할당한 값과 동일한 값이 표시되면 변수가 성공적으로 로드된 것입니다.
Secret Manager에 보안 비밀 저장
액세스 코드, 사용자 인증 정보, 비밀번호를 비롯한 민감한 정보의 경우 보안 비밀 관리자를 사용하는 것이 좋습니다.
Gemma 3 모델을 사용하려면 먼저 이용약관을 확인해야 합니다. Hugging Face Hub의 Gamma 3 모델 카드를 통해 이용약관을 확인할 수 있습니다.
Hugging Face 액세스 토큰이 있으면 Secret Manager 페이지로 이동하여 다음 안내에 따라 보안 비밀을 만듭니다.
- Google Cloud 콘솔로 이동
- 왼쪽 상단의 드롭다운 바에서 프로젝트를 선택합니다.
- 검색창에서 Secret Manager를 검색하고 해당 옵션이 표시되면 클릭합니다.
Secret Manager 페이지에서 다음 작업을 할 수 있습니다.
- +보안 비밀 만들기 버튼을 클릭합니다.
- 다음 정보를 입력합니다.
- 이름: HF_TOKEN
- 보안 비밀 값: <your_hf_access_token>
- 완료되면 보안 비밀 만들기 버튼을 클릭합니다.
이제 Google Cloud Secret Manager에 Hugging Face 액세스 토큰이 보안 비밀로 표시됩니다.
터미널에서 아래 명령어를 실행하여 비밀에 대한 액세스를 테스트할 수 있습니다. 이 명령어는 Secret Manager에서 비밀을 가져옵니다.
gcloud secrets versions access latest --secret=HF_TOKEN
액세스 토큰이 검색되어 터미널 창에 표시됩니다.
Cloud Build 서비스 계정에 보안 비밀 액세스 권한 부여
이제 보안 비밀이 Secret Manager에 안전하게 저장되므로
터미널에서 다음 명령어를 실행하여 이 작업을 수행합니다.
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. 서비스 계정 만들기
보안을 강화하고 프로덕션 환경에서 액세스를 효과적으로 관리하려면 서비스가 특정 작업에 필요한 권한으로 엄격하게 제한된 전용 서비스 계정으로 작동해야 합니다.
이 명령어를 실행하여 서비스 계정을 만듭니다.
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
다음 명령어를 사용하면 필요한 권한이 연결됩니다.
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Artifact Registry에 이미지 만들기
이 단계에서는 모델 가중치와 사전 설치된 vLLM이 포함된 Docker 이미지를 만듭니다.
1. Artifact Registry에 Docker 저장소 만들기
빌드된 이미지를 푸시하기 위해 Artifact Registry에 Docker 저장소를 만들어 보겠습니다. 터미널에서 다음 명령어를 실행합니다.
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. 모델 저장
GPU 권장사항 문서에 따라 ML 모델을 컨테이너 이미지 내에 저장하거나 Cloud Storage에서 로드를 최적화할 수 있습니다.
물론 각 접근 방식에는 장단점이 있습니다. 문서를 읽고 자세히 알아보세요. 간단하게 컨테이너 이미지에 모델을 저장하겠습니다. 다음 세션에서 이 작업을 수행합니다.
3. Docker 파일 만들기
Dockerfile이라는 파일을 만들고 아래 내용을 복사하여 붙여넣습니다.
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. 배포용 YAML 파일 만들기
다음으로 동일한 디렉터리에 cloudbuild.yaml라는 파일을 만듭니다. 이 파일은 Cloud Build가 따라야 하는 단계를 정의합니다. 다음 콘텐츠를 복사하여 cloudbuild.yaml에 붙여넣습니다.
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Cloud Build에 빌드를 제출합니다.
다음 코드를 복사하여 터미널에서 실행합니다.
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
이 명령어는 코드를 업로드하고 (Dockerfile 및 cloudbuild.yaml) 셸 변수를 대체로 전달하고 (_MODEL_NAME 및 _IMAGE_NAME) 빌드를 시작합니다.
이제 Cloud Build가 cloudbuild.yaml에 정의된 단계를 실행합니다. 터미널에서 로그를 확인하거나 Cloud 콘솔에서 빌드 세부정보 링크를 클릭하면 됩니다. 완료되면 컨테이너 이미지가 Artifact Registry 저장소에서 제공되어 배포할 수 있습니다.
6. Cloud Run에 배포
이제 서비스를 Cloud Run에 배포할 준비가 되었습니다. 터미널에서 다음 명령어를 실행합니다.
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. 서비스 테스트
터미널에서 다음 명령어를 실행하여 프록시를 만듭니다. 그러면 localhost에서 실행되는 서비스에 액세스할 수 있습니다.
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
새 터미널 창에서 터미널에 다음 curl 명령어를 실행하여 연결을 테스트합니다.
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
아래와 비슷한 출력이 표시되면 다음 단계를 따르세요.
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. 결론
축하합니다. 이 Codelab을 완료했습니다. 지금까지 배운 내용은 다음과 같습니다.
- 타겟 배포에 적합한 모델 크기를 선택합니다.
- OpenAI 호환 API를 제공하도록 vLLM을 설정합니다.
- Docker를 사용하여 vLLM 서버와 모델 가중치를 안전하게 컨테이너화합니다.
- 컨테이너 이미지를 Google Artifact Registry로 푸시합니다.
- GPU 가속 서비스를 Cloud Run에 배포합니다.
- 인증된 배포 모델을 테스트합니다.
Llama, Mistral, Qwen과 같은 다른 흥미로운 모델을 배포하여 학습 여정을 계속 이어가세요.
9. 삭제
향후 요금이 청구되지 않도록 하려면 생성한 리소스를 삭제해야 합니다. 다음 명령어를 실행하여 프로젝트를 정리합니다.
1. Cloud Run 서비스를 삭제합니다.
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Artifact Registry 저장소를 삭제합니다.
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. 서비스 계정을 삭제합니다.
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Secret Manager에서 보안 비밀을 삭제합니다.
gcloud secrets delete HF_TOKEN --quiet