
1. Wprowadzenie
Duże modele językowe (LLM) zmieniają sposób tworzenia inteligentnych aplikacji. Przygotowanie tych zaawansowanych modeli do użytku w rzeczywistych warunkach może być jednak trudne. Potrzebują one dużej mocy obliczeniowej, zwłaszcza kart graficznych (GPU), oraz inteligentnych sposobów obsługi wielu żądań jednocześnie. Chcesz też ograniczyć koszty i zapewnić płynne działanie aplikacji bez opóźnień.
Z tego ćwiczenia dowiesz się, jak sobie z nimi poradzić. Użyjemy 2 kluczowych narzędzi:
- vLLM to superszybki silnik dla LLM. Dzięki temu modele działają znacznie wydajniej, obsługując więcej żądań naraz i zmniejszając zużycie pamięci.
- Google Cloud Run: to bezserwerowa platforma Google. Jest to świetne rozwiązanie do wdrażania aplikacji, ponieważ automatycznie skaluje zasoby – od zera do tysięcy użytkowników i z powrotem. Co najważniejsze, Cloud Run obsługuje teraz procesory graficzne, które są niezbędne do hostowania LLM.
vLLM i Cloud Run to wydajny, elastyczny i ekonomiczny sposób udostępniania dużych modeli językowych. Z tego przewodnika dowiesz się, jak wdrożyć otwarty model, aby był dostępny jako standardowy interfejs API sieci.
Czego się nauczysz
- Jak wybrać odpowiedni rozmiar i wersję modelu do wyświetlania.
- Jak skonfigurować vLLM do udostępniania punktów końcowych interfejsu API zgodnych z OpenAI.
- Jak konteneryzować serwer vLLM za pomocą Dockera.
- Jak przesłać obraz kontenera do Google Artifact Registry.
- Jak wdrożyć kontener w Cloud Run z akceleracją GPU.
- Jak przetestować wdrożony model.
Czego potrzebujesz
- przeglądarka, np. Chrome, do uzyskiwania dostępu do konsoli Google Cloud;
- stabilne połączenie z internetem,
- Projekt Google Cloud z włączonymi płatnościami
- Token dostępu Hugging Face (jeśli go jeszcze nie masz, możesz go utworzyć tutaj)
- Podstawowa znajomość języka Python, Dockera i interfejsu wiersza poleceń
- ciekawość i chęć do nauki,
2. Zanim zaczniesz
Konfigurowanie projektu Google Cloud
Ten przewodnik wymaga projektu Google Cloud z aktywnym kontem rozliczeniowym.
- W przypadku sesji prowadzonych przez instruktora: jeśli jesteś w klasie, instruktor przekaże Ci niezbędne informacje o projekcie i informacje rozliczeniowe. Aby dokończyć konfigurację, postępuj zgodnie z instrukcjami nauczyciela.
- Dla osób uczących się samodzielnie: jeśli uczysz się samodzielnie i nie masz aktywnego konta rozliczeniowego, musisz je skonfigurować, podając własne informacje o płatności. Aby utworzyć nowe konto rozliczeniowe i włączyć je w projekcie, zapoznaj się z dokumentacją Rozliczeń usługi Google Cloud.
Tworzenie projektu Google Cloud
Aby zachować porządek i oddzielić pracę wykonaną w ramach tego ćwiczenia od innych projektów, zacznij od utworzenia nowego projektu Google Cloud.
Aby otworzyć stronę tworzenia projektu, kliknij:
Na stronie tworzenia projektu wpisz wymagane informacje:
- Nazwa projektu – możesz wpisać dowolną nazwę (np.genai-workshop).
- Lokalizacja – pozostaw Brak organizacji.
- Konto rozliczeniowe – jeśli ta opcja jest widoczna, wybierz „Konto rozliczeniowe w okresie próbnym Google Cloud Platform” lub własne konto rozliczeniowe. Jeśli nie widzisz tej opcji, możesz przejść do następnego kroku.
Skopiuj wygenerowany identyfikator projektu, będzie Ci potrzebny później. 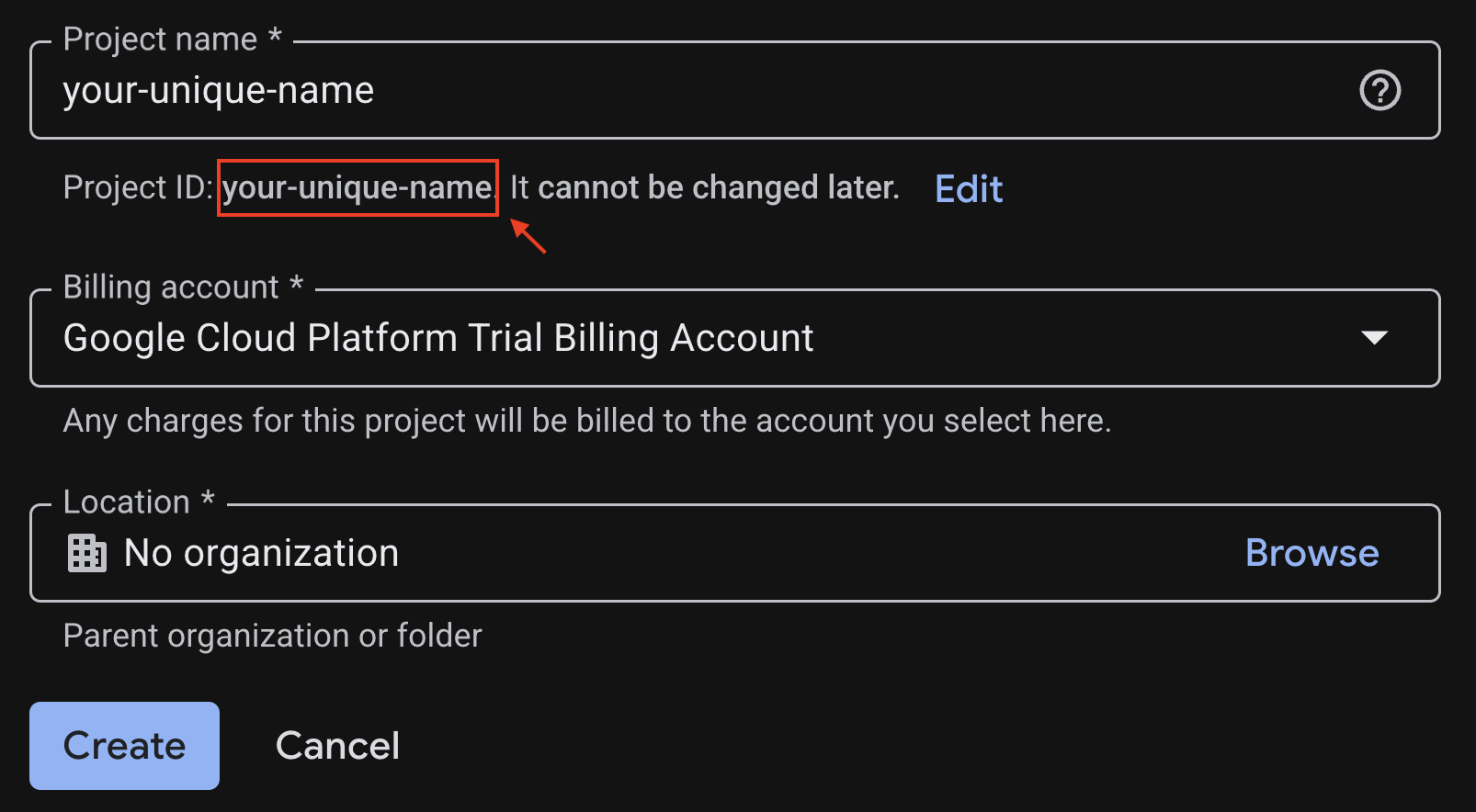
Jeśli wszystko się zgadza, kliknij przycisk Utwórz.
Konfigurowanie Cloud Shell
Cloud Shell to wstępnie skonfigurowane środowisko ze wszystkimi narzędziami potrzebnymi do wykonania tych ćwiczeń z programowania. Po utworzeniu projektu wykonaj te czynności, aby skonfigurować Cloud Shell.
Uruchom Cloud Shell
Aby uruchomić Cloud Shell, kliknij .
Jeśli pojawi się wyskakujące okienko z prośbą o autoryzację, kliknij Autoryzuj.
Ustawianie identyfikatora projektu
Zastąp replace-with-your-project-id rzeczywistym identyfikatorem projektu z kroku tworzenia projektu powyżej. Aby ustawić prawidłowy identyfikator projektu, wykonaj to polecenie w terminalu Cloud Shell.
gcloud config set project replace-with-your-project-id
W terminalu Cloud Shell powinien być teraz wybrany prawidłowy projekt. Wybrany identyfikator projektu jest wyróżniony na żółto.

Włączanie niezbędnych interfejsów API
Aby korzystać z usług Google Cloud, takich jak Cloud Run, musisz najpierw aktywować odpowiednie interfejsy API w swoim projekcie. Aby włączyć usługi niezbędne do tego Codelabu, uruchom w Cloud Shell te polecenia:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Wybór odpowiedniego modelu
Wiele modeli open source znajdziesz w witrynach takich jak Hugging Face Hub i Kaggle. Jeśli chcesz użyć jednego z tych modeli w usłudze takiej jak Google Cloud Run, musisz wybrać model, który pasuje do Twoich zasobów (np. procesora graficznego NVIDIA L4).
Pamiętaj, że oprócz rozmiaru należy wziąć pod uwagę, co model może faktycznie zrobić. Modele nie są takie same – każdy ma swoje zalety i wady. Na przykład niektóre modele mogą obsługiwać różne typy danych wejściowych (np. obrazy i tekst – są to tzw. możliwości multimodalne), a inne mogą zapamiętywać i przetwarzać więcej informacji naraz (czyli mają większe okna kontekstu). Większe modele często mają bardziej zaawansowane funkcje, takie jak wywoływanie funkcji i myślenie.
Ważne jest też sprawdzenie, czy wybrany model jest obsługiwany przez narzędzie do obsługi (w tym przypadku vLLM). Wszystkie modele obsługiwane przez vLLM znajdziesz tutaj.
Przyjrzyjmy się teraz Gemmie 3, czyli najnowszej rodzinie dużych modeli językowych (LLM) od Google, które są dostępne publicznie. Gemma 3 jest dostępna w 4 wersjach różniących się złożonością, która jest mierzona w parametrach: 1 miliard, 4 miliardy, 12 miliardów i aż 27 miliardów.
W przypadku każdego z tych rozmiarów znajdziesz 2 główne typy:
- Wersja podstawowa (wstępnie wytrenowana): to model podstawowy, który został wytrenowany na ogromnej ilości danych.
- Wersja dostosowana do instrukcji: ta wersja została dodatkowo ulepszona, aby lepiej rozumieć i wykonywać konkretne instrukcje lub polecenia.
Większe modele (4 miliardy, 12 miliardów i 27 miliardów parametrów) są wielomodalne, co oznacza, że potrafią rozumieć obrazy i tekst oraz z nimi pracować. Najmniejszy wariant z 1 miliardem parametrów skupia się jednak wyłącznie na tekście.
W tym ćwiczeniu użyjemy 1 miliarda wariantów modelu Gemma 3: gemma-3-1b-it. Korzystanie z mniejszego modelu pomaga też nauczyć się pracy z ograniczonymi zasobami, co jest ważne, aby obniżyć koszty i zapewnić płynne działanie aplikacji w chmurze.
4. Zmienne środowiskowe i obiekty tajne
Tworzenie pliku środowiska
Zanim przejdziemy dalej, warto zebrać w jednym miejscu wszystkie konfiguracje, których będziesz używać podczas tych ćwiczeń z programowania. Aby rozpocząć, otwórz terminal i wykonaj te czynności:
- Utwórz nowy folder dla tego projektu.
- Przejdź do nowo utworzonego folderu.
- Utwórz w tym folderze pusty plik .env (będzie on później zawierać zmienne środowiskowe).
Oto polecenie, które umożliwia wykonanie tych czynności:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Następnie skopiuj zmienne wymienione poniżej i wklej je do utworzonego właśnie pliku.env.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Pamiętaj, aby zastąpić wartości zastępcze (your_project_id i your_region) informacjami o swoim projekcie. Na przykład PROJECT_ID=unique-ai-project i REGION=europe-west4. Listę regionów, w których procesory GPU są obsługiwane w Cloud Run, znajdziesz tutaj.
Po zmodyfikowaniu i zapisaniu pliku.env wpisz to polecenie, aby załadować zmienne środowiskowe do sesji terminala:
source .env
Możesz sprawdzić, czy zmienne zostały wczytane, wyświetlając jedną z nich. Na przykład:
echo $SERVICE_NAME
Jeśli otrzymasz tę samą wartość, którą przypisano w pliku.env, zmienne zostały wczytane prawidłowo.
Przechowywanie obiektu tajnego w usłudze Secret Manager
W przypadku danych wrażliwych, w tym kodów dostępu, danych logowania i haseł, zalecamy korzystanie z menedżera obiektów tajnych.
Przed użyciem modeli Gemma 3 musisz najpierw potwierdzić warunki, ponieważ są one ograniczone. Możesz potwierdzić akceptację warunków korzystania na stronie Gamma 3 Model Card On Hugging Face Hub.
Gdy uzyskasz token dostępu Hugging Face, przejdź na stronę Secret Manager i utwórz obiekt tajny, wykonując te instrukcje.
- Otwórz konsolę Google Cloud
- Wybierz projekt z menu w lewym górnym rogu.
- Na pasku wyszukiwania wpisz Secret Manager i kliknij tę opcję, gdy się pojawi.
Gdy otworzysz stronę Secret Manager:
- Kliknij przycisk +Utwórz obiekt tajny.
- Podaj te informacje:
- Nazwa: HF_TOKEN
- Wartość obiektu tajnego: <your_hf_access_token>
- Gdy skończysz, kliknij przycisk Utwórz obiekt tajny.
Token dostępu Hugging Face powinien być teraz dostępny jako obiekt tajny w Google Cloud Secret Manager.
Możesz przetestować dostęp do obiektu tajnego, wykonując w terminalu to polecenie, które pobierze go z usługi Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
W oknie terminala powinien pojawić się pobrany token dostępu.
Przyznawanie dostępu do obiektu tajnego kontu usługi Cloud Build
Obiekt tajny jest teraz bezpiecznie przechowywany w usłudze Secret Manager.
Aby to zrobić, uruchom w terminalu te polecenia:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Tworzenie konta usługi
Aby zwiększyć bezpieczeństwo i skutecznie zarządzać dostępem w środowisku produkcyjnym, usługi powinny działać na dedykowanych kontach usługi, które są ściśle ograniczone do uprawnień niezbędnych do wykonywania określonych zadań.
Uruchom to polecenie, aby utworzyć konto usługi
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
To polecenie przyznaje niezbędne uprawnienia.
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Tworzenie obrazu w Artifact Registry
Ten krok obejmuje utworzenie obrazu Dockera, który zawiera wagi modelu i wstępnie zainstalowany vLLM.
1. Tworzenie repozytorium Dockera w Artifact Registry
Utwórzmy repozytorium Dockera w Artifact Registry, do którego będziesz przesyłać utworzone obrazy. Uruchom w terminalu to polecenie:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Przechowywanie modelu
Zgodnie z dokumentacją dotyczącą sprawdzonych metod korzystania z GPU możesz przechowywać modele ML w obrazach kontenerów lub zoptymalizować ich wczytywanie z Cloud Storage.
Oczywiście każde podejście ma swoje wady i zalety. Więcej informacji znajdziesz w dokumentacji. Dla uproszczenia model będzie przechowywany w obrazie kontenera. Zrobisz to w następnej sesji.
3. Tworzenie pliku Dockera
Utwórz plik o nazwie Dockerfile i skopiuj do niego poniższą treść:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Utwórz plik yaml wdrożenia
Następnie w tym samym katalogu utwórz plik o nazwie cloudbuild.yaml. Ten plik określa czynności, które ma wykonać Cloud Build. Skopiuj i wklej do pliku cloudbuild.yaml tę treść:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Przesyłanie kompilacji do Cloud Build
Skopiuj i wklej ten kod, a potem uruchom go w terminalu:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
To polecenie przesyła Twój kod (Dockerfile i cloudbuild.yaml), przekazuje zmienne powłoki jako podstawienia (_MODEL_NAME i _IMAGE_NAME) i rozpoczyna kompilację.
Cloud Build wykona teraz kroki zdefiniowane w pliku cloudbuild.yaml. Logi możesz śledzić w terminalu lub klikając link do szczegółów kompilacji w Cloud Console. Po zakończeniu obraz kontenera będzie dostępny w repozytorium Artifact Registry i gotowy do wdrożenia.
6. Wdróż w Cloud Run
Możesz teraz wdrożyć usługę w Cloud Run. Uruchom w terminalu to polecenie:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Testowanie usługi
Aby utworzyć serwer proxy, który umożliwi Ci dostęp do usługi działającej na hoście lokalnym, uruchom w terminalu to polecenie:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
W nowym oknie terminala uruchom to polecenie curl, aby przetestować połączenie.
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Jeśli zobaczysz dane wyjściowe podobne do tych poniżej:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Podsumowanie
Gratulacje! Udało Ci się ukończyć to ćwiczenie w Codelabs. Dowiedziałeś(-aś) się, jak:
- Wybierz odpowiedni rozmiar modelu na potrzeby docelowego wdrożenia.
- Skonfiguruj vLLM do udostępniania interfejsu API zgodnego z OpenAI.
- Bezpiecznie konteneryzuj serwer vLLM i wagi modelu za pomocą Dockera.
- przesłać obraz kontenera do Google Artifact Registry,
- wdrożyć usługę z akceleracją GPU w Cloud Run,
- Testowanie uwierzytelnionego wdrożonego modelu.
Aby kontynuować naukę, możesz wdrożyć inne ciekawe modele, takie jak Llama, Mistral czy Qwen.
9. Czyszczenie
Aby uniknąć przyszłych opłat, usuń utworzone zasoby. Aby zwolnić miejsce w projekcie, uruchom te polecenia.
1. Usuń usługę Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Usuń repozytorium Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Usuń konto usługi:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Usuń obiekt tajny z usługi Secret Manager:
gcloud secrets delete HF_TOKEN --quiet