
1. Introdução
Os modelos de linguagem grandes (LLMs) estão mudando a forma como criamos aplicativos inteligentes. No entanto, preparar esses modelos avançados para uso no mundo real pode ser complicado. Eles precisam de muito poder de computação, especialmente placas de vídeo (GPUs), e maneiras inteligentes de processar muitas solicitações de uma só vez. Além disso, você quer manter os custos baixos e o aplicativo funcionando sem problemas e sem atrasos.
Este codelab mostra como enfrentar esses desafios. Vamos usar duas ferramentas principais:
- vLLM: pense nisso como um mecanismo super-rápido para LLMs. Ele faz com que seus modelos sejam executados com muito mais eficiência, processando mais solicitações de uma só vez e reduzindo o uso de memória.
- Google Cloud Run: essa é a plataforma sem servidor do Google. Ela é fantástica para implantar aplicativos porque processa todo o escalonamento para você, de zero a milhares de usuários e vice-versa. O melhor de tudo é que o Cloud Run agora oferece suporte a GPUs, que são essenciais para hospedar LLMs.
Juntos, o vLLM e o Cloud Run oferecem uma maneira eficiente, flexível e econômica de disponibilizar seus LLMs. Neste guia, você vai implantar um modelo aberto, disponibilizando-o como uma API da Web padrão.
O que você vai aprender
- Como escolher o tamanho e a variante do modelo certos para disponibilização.
- Como configurar o vLLM para disponibilizar endpoints de API compatíveis com o OpenAI.
- Como conteinerizar o servidor vLLM com o Docker.
- Como enviar a imagem do contêiner para o Google Artifact Registry.
- Como implantar o contêiner no Cloud Run com aceleração de GPU.
- Como testar o modelo implantado.
O que você precisa
- Um navegador, como o Chrome, para acessar o console do Google Cloud.
- Uma conexão de Internet confiável.
- Um projeto do Google Cloud com o faturamento ativado.
- Um token de acesso do Hugging Face (crie um aqui se ainda não tiver um).
- Conhecimentos básicos sobre Python, Docker e a interface de linha de comando.
- Uma mente curiosa e vontade de aprender.
2. Antes de começar
Configurar o projeto do Google Cloud
Este codelab requer um projeto do Google Cloud com uma conta de faturamento ativa.
- Para sessões ministradas por instrutor:se você estiver em uma sala de aula, o instrutor vai fornecer as informações necessárias sobre o projeto e as informações de faturamento. Siga as instruções do professor para concluir a configuração.
- Para aprendizes independentes:se você estiver fazendo isso por conta própria e não tiver uma conta de faturamento ativa, será necessário configurar uma conta de faturamento usando suas próprias informações de pagamento. Consulte a documentação do Cloud Billing do Google Cloud para criar uma conta de faturamento e ativá-la para seu projeto.
Criar um projeto na nuvem do Google Cloud
Para manter todo o trabalho deste codelab organizado e separado de outros projetos, comece criando um novo projeto na nuvem do Google.
Para abrir a página de criação do projeto, clique em:
Insira as informações necessárias na página de criação do projeto:
- Nome do projeto : você pode inserir qualquer nome desejado (por exemplo, workshop de IA generativa).
- Local : deixe como Nenhuma organização.
- Conta de faturamento : se essa opção aparecer, selecione "Conta de faturamento de teste do Google Cloud Platform" ou sua própria conta de faturamento, se preferir. Se essa opção não aparecer, prossiga para a próxima etapa.
Copie o ID do projeto gerado. Você vai precisar dele mais tarde. 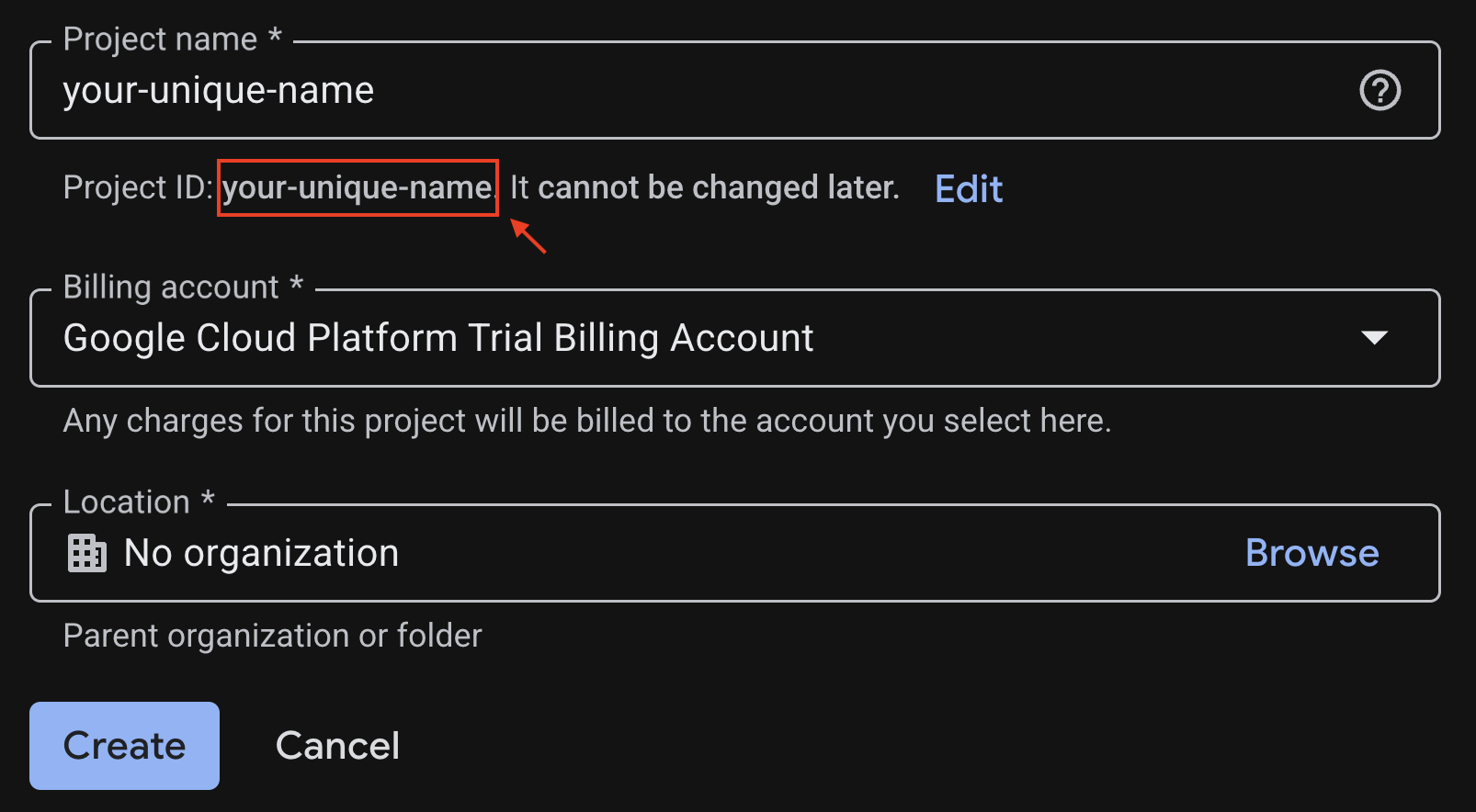
Se tudo estiver bem, clique no botão Criar.
Configurar o Cloud Shell
O Cloud Shell é um ambiente pré-configurado com todas as ferramentas necessárias para este codelab. Depois que o projeto for criado, siga estas etapas para configurar o Cloud Shell.
Iniciar o Cloud Shell
Para iniciar o Cloud Shell, clique em:
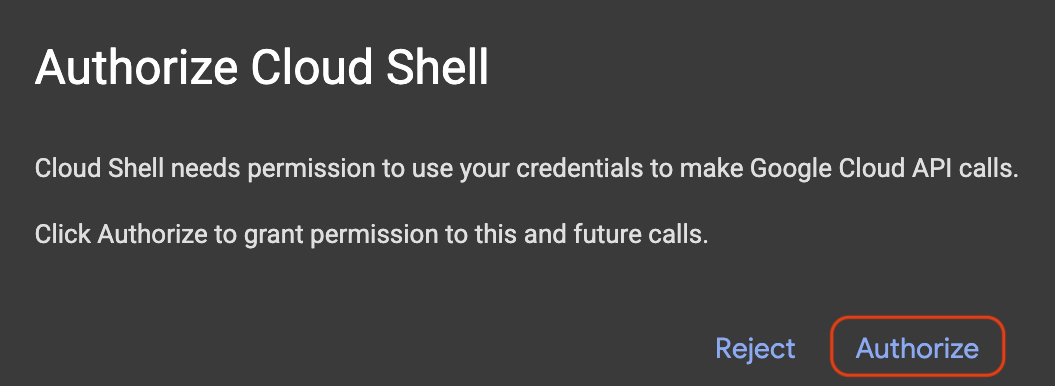
Se um pop-up aparecer pedindo autorização, clique em Autorizar.
Definir o ID do projeto
Substitua replace-with-your-project-id pelo ID do projeto real da etapa de criação do projeto acima. Execute o comando a seguir no terminal do Cloud Shell para definir o ID do projeto correto.
gcloud config set project replace-with-your-project-id
Agora você verá que o projeto correto está selecionado no terminal do Cloud Shell. O ID do projeto selecionado está destacado em amarelo.

Ativar as APIs necessárias
Para usar os serviços do Google Cloud, como o Cloud Run, primeiro ative as APIs respectivas para seu projeto. Execute os comandos a seguir no Cloud Shell para ativar os serviços necessários para este codelab:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Como escolher o modelo certo
Você pode encontrar muitos modelos abertos em sites como o Hugging Face Hub e o Kaggle. Quando quiser usar um desses modelos em um serviço como o Google Cloud Run, escolha um que se ajuste aos recursos disponíveis (ou seja, GPU NVIDIA L4).
Além do tamanho, lembre-se de considerar o que o modelo pode fazer. Os modelos não são todos iguais. Cada um tem suas vantagens e desvantagens. Por exemplo, alguns modelos podem processar diferentes tipos de entrada (como imagens e texto, conhecidos como recursos multimodais), enquanto outros podem lembrar e processar mais informações de uma só vez (o que significa que eles têm janelas de contexto maiores). Muitas vezes, modelos maiores têm recursos mais avançados, como chamada de função e pensamento.
Também é importante verificar se o modelo desejado é compatível com a ferramenta de disponibilização (vLLM, neste caso). Confira todos os modelos compatíveis com o vLLM aqui.
Agora, vamos explorar o Gemma 3, que é a mais nova família de modelos de linguagem grandes (LLMs) disponíveis abertamente do Google. O Gemma 3 vem em quatro escalas diferentes com base na complexidade, medida em parâmetros: 1 bilhão, 4 bilhões, 12 bilhões e 27 bilhões.
Para cada um desses tamanhos, você encontrará dois tipos principais:
- Uma versão básica (pré-treinada): esse é o modelo fundamental que aprendeu com uma grande quantidade de dados.
- Uma versão ajustada para instruções: essa versão foi refinada ainda mais para entender e seguir melhor instruções ou comandos específicos.
Os modelos maiores (4 bilhões, 12 bilhões e 27 bilhões de parâmetros) são multimodais, o que significa que eles podem entender e trabalhar com imagens e texto. No entanto, a variante menor de 1 bilhão de parâmetros se concentra apenas no texto.
Para este codelab, vamos usar variantes de 1 bilhão do Gemma 3: gemma-3-1b-it. Usar um modelo menor também ajuda a aprender a trabalhar com recursos limitados, o que é importante para manter os custos baixos e garantir que o app seja executado sem problemas na nuvem.
4. Variáveis de ambiente e secrets
Criar um arquivo de ambiente
Antes de prosseguir, é recomendável ter todas as configurações que você vai usar neste codelab em um só lugar. Para começar, abra o terminal e siga estas etapas:
- Crie uma nova pasta para este projeto.
- Navegue até a pasta recém-criada.
- Crie um arquivo .env vazio nessa pasta. Esse arquivo vai conter suas variáveis de ambiente.
Use este comando para executar essas etapas:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Em seguida, copie as variáveis listadas abaixo e cole-as no arquivo.env que você acabou de criar.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Lembre-se de substituir os valores do marcador de posição (your_project_id e your_region) pelas informações específicas do projeto. Por exemplo, (PROJECT_ID=unique-ai-project e REGION=europe-west4). Confira a lista de regiões que oferecem suporte a GPUs no Cloud Run aqui.
Depois que o arquivo.env for editado e salvo, digite este comando para carregar essas variáveis de ambiente na sessão do terminal:
source .env
Você pode testar se as variáveis foram carregadas ou não ecoando uma delas. Por exemplo:
echo $SERVICE_NAME
Se você receber o mesmo valor atribuído no .env file, as variáveis serão carregadas.
Armazenar um secret no Secret Manager
Para dados sensíveis, incluindo códigos de acesso, credenciais e senhas, a abordagem recomendada é usar um gerenciador de secrets.
Antes de usar os modelos do Gemma 3, você precisa reconhecer os Termos e Condições, já que eles são protegidos. Você pode reconhecer os Termos e Condições no cartão do modelo Gemma 3 no Hugging Face Hub.
Depois de ter o token de acesso do Hugging Face, acesse a página do Secret Manager e crie um secret seguindo estas instruções.
- Acesse o console do Google Cloud.
- Selecione o projeto na barra suspensa no canto superior esquerdo.
- Pesquise Secret Manager na barra de pesquisa e clique nessa opção quando ela aparecer.
Quando você estiver na página do Secret Manager:
- Clique no botão +Criar secret.
- Preencha estas informações:
- Nome: HF_TOKEN
- Valor da chave secreta: <your_hf_access_token>
- Clique no botão Criar secret quando terminar.
Agora você tem o token de acesso do Hugging Face como um secret no Google Cloud Secret Manager.
Você pode testar seu acesso ao secret executando o comando abaixo no terminal. Esse comando vai recuperá-lo do Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
O token de acesso será recuperado e mostrado na janela do terminal.
Conceder acesso secreto à conta de serviço do Cloud Build
Como o secret agora está armazenado com segurança no Secret Manager,
Execute estes comandos no terminal para fazer isso:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Crie uma conta de serviço
Para aumentar a segurança e gerenciar o acesso de maneira eficaz em um ambiente de produção, os serviços precisam operar em contas de serviço dedicadas que são estritamente limitadas às permissões necessárias para as tarefas específicas.
Execute este comando para criar uma conta de serviço.
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
O comando a seguir anexa a permissão necessária.
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Criar uma imagem no Artifact Registry
Esta etapa envolve a criação de uma imagem Docker que inclui os pesos do modelo e um vLLM pré-instalado.
1. Criar um repositório do Docker no Artifact Registry
Vamos criar um repositório do Docker no Artifact Registry para enviar as imagens criadas. Execute o seguinte comando no terminal:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Armazenar o modelo
Com base na documentação de práticas recomendadas de GPU, você pode armazenar modelos de ML dentro de imagens de contêiner ou otimizar o carregamento deles no Cloud Storage.
É claro que cada abordagem tem seus prós e contras. Leia a documentação para saber mais sobre elas. Para simplificar, vamos armazenar o modelo na imagem do contêiner. Você vai fazer isso na próxima sessão.
3. Criar um arquivo do Docker
Crie um arquivo chamado Dockerfile e copie o conteúdo abaixo nele:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Criar um arquivo YAML para implantação
Em seguida, crie um arquivo chamado cloudbuild.yaml no mesmo diretório. Esse arquivo define as etapas que o Cloud Build precisa seguir. Copie e cole o conteúdo abaixo em cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Enviar a compilação para o Cloud Build
Copie e cole o código a seguir e execute-o no terminal:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Esse comando faz o upload do código (o Dockerfile e o cloudbuild.yaml), transmite as variáveis de shell como substituições (_MODEL_NAME e _IMAGE_NAME) e inicia a compilação.
O Cloud Build vai executar as etapas definidas em cloudbuild.yaml. Você pode acompanhar os registros no terminal ou clicando no link para os detalhes da compilação no console do Cloud. Quando terminar, a imagem do contêiner estará disponível no repositório do Artifact Registry, pronta para implantação.
6. Implantar no Cloud Run
Agora você está pronto para implantar o serviço no Cloud Run. Execute este comando no terminal:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Testar o serviço
Execute o comando a seguir no terminal para criar um proxy, para que você possa acessar o serviço em execução no localhost:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
Em uma nova janela de terminal, execute este comando curl no terminal para testar a conexão.
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Se você vir uma saída semelhante à abaixo:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Conclusão
Parabéns! Você concluiu este codelab. Você aprendeu a:
- Escolher um tamanho de modelo adequado para uma implantação de destino.
- Configurar o vLLM para disponibilizar uma API compatível com o OpenAI.
- Conteinerizar com segurança o servidor vLLM e os pesos do modelo com o Docker.
- Enviar uma imagem de contêiner para o Google Artifact Registry.
- Implantar um serviço acelerado por GPU no Cloud Run.
- Testar um modelo autenticado e implantado.
Fique à vontade para implantar outros modelos interessantes, como Llama, Mistral ou Qwen, para continuar sua jornada de aprendizado.
9. Limpeza
Para evitar cobranças futuras, é importante excluir os recursos criados. Execute os comandos a seguir para limpar o projeto.
1. Exclua o serviço do Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Exclua o repositório do Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Exclua a conta de serviço:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Exclua o secret do Secret Manager:
gcloud secrets delete HF_TOKEN --quiet