
1. Введение
Большие языковые модели (LLM) меняют подход к созданию интеллектуальных приложений. Однако подготовка этих мощных моделей к реальному применению может быть непростой задачей. Для их работы требуется много вычислительной мощности, особенно графических карт (GPU), и продуманные способы обработки множества запросов одновременно. Кроме того, важно снизить затраты и обеспечить бесперебойную работу приложения без задержек.
В этом практическом занятии вы узнаете, как решать эти задачи! Мы будем использовать два ключевых инструмента:
- vLLM : Представьте это как сверхбыстрый движок для LLM-моделей. Он значительно повышает эффективность работы ваших моделей, обрабатывая больше запросов одновременно и сокращая использование памяти.
- Google Cloud Run : это бессерверная платформа от Google. Она отлично подходит для развертывания приложений, поскольку берет на себя все масштабирование — от нуля пользователей до тысяч и обратно. И самое главное, Cloud Run теперь поддерживает графические процессоры (GPU) , которые необходимы для размещения LLM-приложений!
Вместе vLLM и Cloud Run предлагают мощный, гибкий и экономически эффективный способ обслуживания ваших LLM-моделей. В этом руководстве вы развернете открытую модель, сделав ее доступной в качестве стандартного веб-API.
Что вы узнаете
- Как выбрать подходящий размер и вариант модели для сервировки.
- Как настроить vLLM для обслуживания API-интерфейсов, совместимых с OpenAI.
- Как контейнеризировать сервер vLLM с помощью Docker.
- Как загрузить образ контейнера в реестр артефактов Google.
- Как развернуть контейнер в Cloud Run с ускорением на графическом процессоре.
- Как протестировать развернутую модель.
Что вам понадобится
- Для доступа к консоли Google Cloud потребуется браузер, например Chrome.
- надежное интернет-соединение
- Проект Google Cloud с включенной функцией выставления счетов.
- Токен доступа «Обнимающее лицо» (создайте его здесь , если у вас его еще нет).
- Базовые знания Python, Docker и интерфейса командной строки.
- Любознательный ум и стремление к обучению.
2. Перед началом работы
Настройка проекта Google Cloud
Для выполнения этого практического задания необходим проект Google Cloud с активным платежным аккаунтом.
- Для занятий под руководством преподавателя: если вы занимаетесь в классе, ваш преподаватель предоставит вам необходимую информацию для проекта и выставления счетов. Следуйте инструкциям преподавателя, чтобы завершить настройку.
- Для самостоятельного обучения: Если вы делаете это самостоятельно и у вас нет действующего платёжного аккаунта, вам потребуется создать платёжный аккаунт, используя свои собственные платежные данные. Обратитесь к документации Google Cloud Billing, чтобы создать новый платёжный аккаунт и активировать его для вашего проекта.
Создайте проект в Google Cloud.
Чтобы упорядочить всю вашу работу по этому практическому заданию и отделить ее от других проектов, начните с создания нового проекта в Google Cloud.
Чтобы открыть страницу создания проекта, нажмите:
Введите необходимую информацию на странице создания проекта:
- Название проекта — вы можете ввести любое желаемое название (например, genai-workshop).
- Местоположение - укажите « Без организации»
- Платежный аккаунт — если этот параметр отображается, выберите «Платежный аккаунт пробной версии Google Cloud Platform» или свой собственный платежный аккаунт, если хотите. Если этот параметр отсутствует, перейдите к следующему шагу.
Скопируйте сгенерированный идентификатор проекта , он понадобится вам позже. 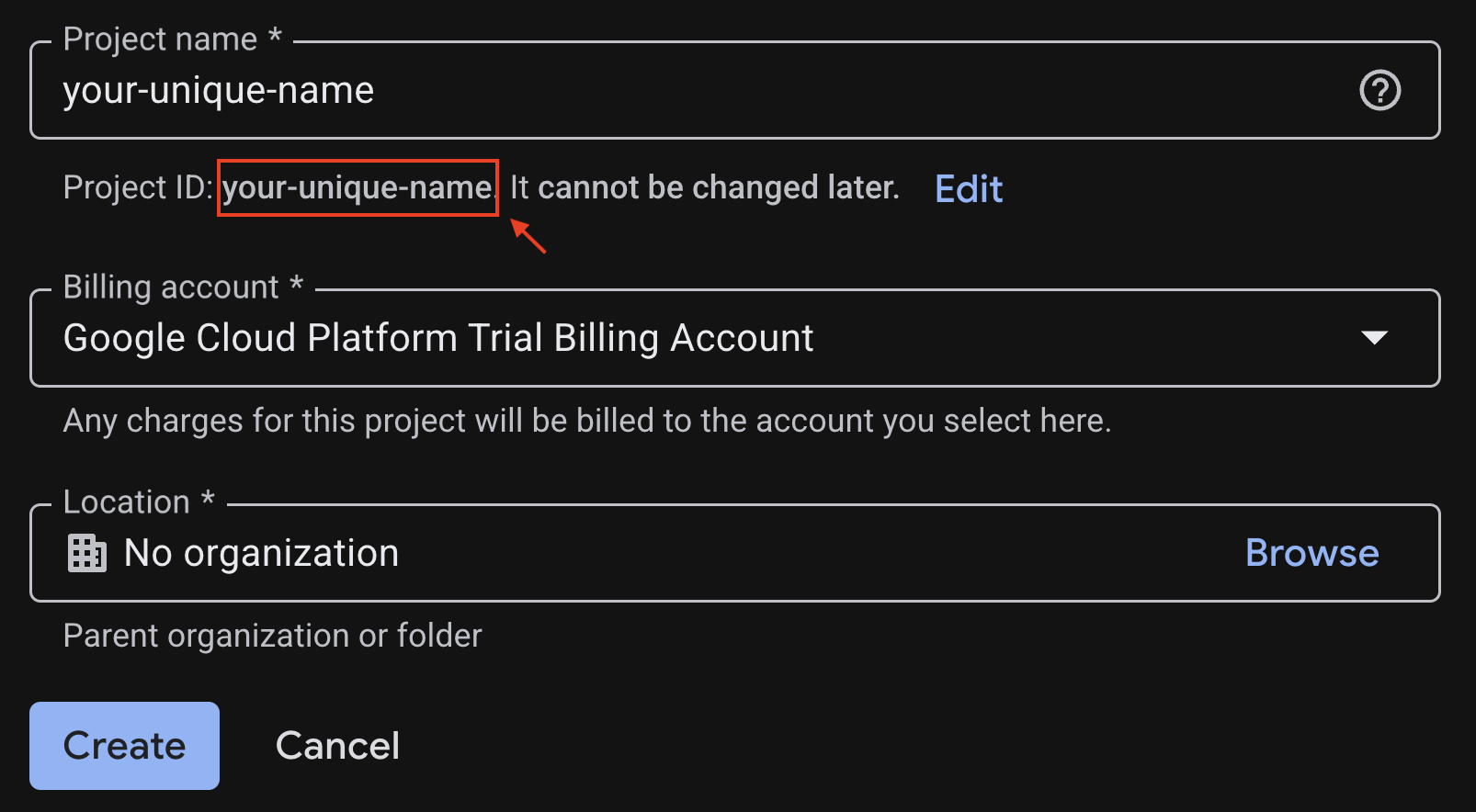
Если все в порядке, нажмите кнопку «Создать» .
Настройка Cloud Shell
Cloud Shell — это предварительно настроенная среда со всеми необходимыми инструментами для выполнения этого практического задания. После успешного создания проекта выполните следующие шаги для настройки Cloud Shell .
Запустить Cloud Shell
Чтобы запустить Cloud Shell, нажмите:
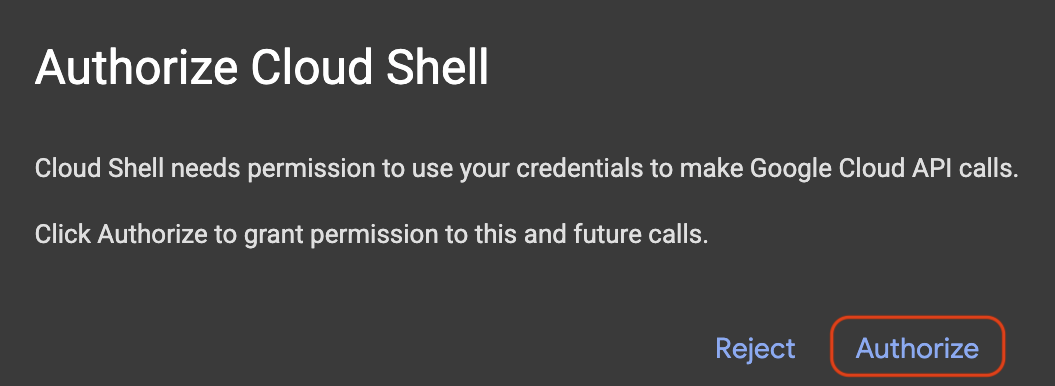
Если появится всплывающее окно с запросом авторизации, нажмите «Авторизовать» .
Установить идентификатор проекта
Замените replace-with-your-project-id на фактический идентификатор вашего проекта, полученный на этапе создания проекта, описанном выше. Выполните следующую команду в терминале Cloud Shell, чтобы установить правильный идентификатор проекта .
gcloud config set project replace-with-your-project-id
Теперь вы должны увидеть, что в терминале Cloud Shell выбран правильный проект. Идентификатор выбранного проекта выделен желтым цветом.

Включите необходимые API.
To use Google Cloud services like Cloud Run, you must first activate their respective APIs for your project. Run the following commands in Cloud Shell to enable the necessary services for this Codelab:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Выбор подходящей модели
You can find many open models on websites like Hugging Face Hub and Kaggle . When you want to use one of these models on a service like Google Cloud Run, you need to pick one that fits the resources you have (ie NVIDIA L4 GPU).
Помимо размера, важно учитывать и реальные возможности модели. Модели не все одинаковы; у каждой есть свои преимущества и недостатки. Например, некоторые модели могут обрабатывать разные типы входных данных (например, изображения и текст — это называется мультимодальными возможностями), в то время как другие могут запоминать и обрабатывать больше информации одновременно (то есть у них больше контекстных окон). Часто более крупные модели обладают более продвинутыми возможностями, такими как вызов функций и способность к логическому мышлению .
Также важно проверить, поддерживается ли желаемая вами модель инструментом развертывания (в данном случае vLLM). Список всех моделей, поддерживаемых vLLM, можно посмотреть здесь .
Теперь давайте рассмотрим Gemma 3 — новейшее семейство открытых языковых моделей (LLM) от Google. Gemma 3 представлена в четырех различных масштабах, основанных на сложности, измеряемой в параметрах : 1 миллиард, 4 миллиарда, 12 миллиардов и внушительные 27 миллиардов.
Для каждого из этих размеров существуют два основных типа:
- Базовая (предварительно обученная) версия: это фундаментальная модель, которая обучалась на огромном объеме данных.
- Версия, оптимизированная для удобства использования: Эта версия была дополнительно усовершенствована для лучшего понимания и выполнения конкретных инструкций или команд.
Более крупные модели (4 миллиарда, 12 миллиардов и 27 миллиардов параметров) являются мультимодальными , что означает, что они могут понимать и работать как с изображениями, так и с текстом. Однако самый маленький вариант с 1 миллиардом параметров ориентирован исключительно на текст.
Для этого практического занятия мы будем использовать 1 миллиард вариантов Gemma 3: gemma-3-1b-it . Использование меньшей модели также помогает научиться работать с ограниченными ресурсами, что важно для снижения затрат и обеспечения бесперебойной работы вашего приложения в облаке.
4. Переменные окружающей среды и секреты
Создайте файл среды.
Прежде чем продолжить, рекомендуется собрать все необходимые для работы в этом руководстве настройки в одном месте. Для начала откройте терминал и выполните следующие действия:
- Создайте новую папку для этого проекта.
- Перейдите в только что созданную папку.
- Создайте пустой файл .env в этой папке (в этом файле позже будут храниться ваши переменные окружения).
Вот команда для выполнения этих шагов:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Далее скопируйте перечисленные ниже переменные и вставьте их в только что созданный файл .env .
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Не забудьте заменить значения-заполнители ( your_project_id и your_region ) информацией о вашем конкретном проекте. Например ( PROJECT_ID=unique-ai-project и REGION=europe-west4 ). Список регионов, поддерживающих графические процессоры в Cloud Run, можно посмотреть здесь.
После редактирования и сохранения файла .env введите следующую команду, чтобы загрузить эти переменные среды в сеанс терминала:
source .env
Проверить успешность загрузки переменных можно, выведя одну из них на экран. Например:
echo $SERVICE_NAME
Если вы получите то же значение, что и в файле .env , значит, переменные загружены успешно.
Сохраните секрет в Secret Manager.
Для защиты любых конфиденциальных данных, включая коды доступа, учетные данные и пароли, рекомендуется использовать менеджер секретов.
Перед использованием моделей Gemma 3 необходимо ознакомиться с условиями использования, поскольку доступ к ним ограничен. Ознакомиться с условиями можно через карточку модели Gamma 3 на сайте Hugging Face Hub .
Получив токен доступа Hugging Face, перейдите на страницу Secret Manager и создайте секрет, следуя этим инструкциям.
- Перейдите в консоль Google Cloud.
- Выберите проект из выпадающего списка в верхнем левом углу.
- Введите в строку поиска «Secret Manager» и нажмите на появившуюся опцию.
Когда вы окажетесь на странице «Секретный менеджер»:
- Нажмите кнопку «+Создать секрет» .
- Заполните следующие поля:
- Имя : HF_TOKEN
- Секретное значение : <ваш_токен_доступа_к_HF>
- После завершения нажмите кнопку «Создать секрет» .
Теперь у вас должен быть токен доступа Hugging Face в качестве секрета в Google Cloud Secret Manager .
Вы можете проверить свой доступ к секрету, выполнив в терминале следующую команду; эта команда получит его из Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
В окне терминала вы должны увидеть, как извлекается и отображается ваш токен доступа.
Предоставить секретный доступ к учетной записи службы Cloud Build.
Поскольку секрет теперь надежно хранится в Secret Manager,
Для этого выполните следующие команды в терминале:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Создайте учетную запись службы.
Для повышения безопасности и эффективного управления доступом в производственной среде сервисы должны работать под выделенными учетными записями, строго ограниченными правами, необходимыми для выполнения их конкретных задач.
Выполните эту команду для создания учетной записи службы.
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
Следующая команда добавит необходимые разрешения.
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Создайте образ в реестре артефактов.
На этом этапе создается образ Docker, включающий веса модели и предварительно установленный vLLM.
1. Создайте репозиторий Docker в реестре артефактов.
Давайте создадим репозиторий Docker в Artifact Registry для отправки собранных образов. Выполните следующую команду в терминале:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Сохранение модели
Согласно документации по передовым методам использования графических процессоров , вы можете либо хранить модели машинного обучения внутри образов контейнеров , либо оптимизировать их загрузку из облачного хранилища .
Конечно, у каждого подхода есть свои преимущества и недостатки. Вы можете ознакомиться с документацией, чтобы узнать о них подробнее. Для простоты мы просто сохраним модель в образе контейнера. Вы сделаете это на следующем занятии.
3. Создайте файл Docker.
Создайте файл с именем Dockerfile и скопируйте в него следующее содержимое:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Создайте YAML-файл для развертывания.
Далее создайте в той же директории файл с именем cloudbuild.yaml . Этот файл определяет шаги, которые должна выполнить Cloud Build. Скопируйте и вставьте следующее содержимое в файл cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Отправьте сборку в Cloud Build.
Скопируйте и вставьте следующий код и запустите его в терминале:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Эта команда загружает ваш код ( Dockerfile и cloudbuild.yaml ), передает ваши переменные оболочки в качестве подстановок ( _MODEL_NAME и _IMAGE_NAME ) и запускает сборку.
Cloud Build теперь выполнит шаги, определенные в cloudbuild.yaml . Вы можете следить за логами в терминале или перейти по ссылке к подробной информации о сборке в консоли Cloud. После завершения образ контейнера будет доступен в вашем репозитории Artifact Registry и готов к развертыванию.
6. Развертывание в облаке.
Теперь вы готовы развернуть сервис в Cloud Run. Выполните следующую команду в терминале:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Проверьте работу сервиса.
Выполните следующую команду в терминале, чтобы создать прокси-сервер и получить доступ к сервису, работающему на локальном хосте:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
В новом окне терминала выполните следующую команду curl для проверки соединения.
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Если вы видите результат, аналогичный приведенному ниже:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Заключение
Поздравляем! Вы успешно завершили этот практический урок. Вы научились:
- Выберите подходящий размер модели для целевого развертывания.
- Настройте vLLM для предоставления API, совместимого с OpenAI.
- Надежно контейнеризируйте сервер vLLM и веса модели с помощью Docker.
- Загрузите образ контейнера в реестр артефактов Google.
- Разверните сервис с ускорением на графическом процессоре в Cloud Run.
- Протестируйте аутентифицированную, развернутую модель.
Не стесняйтесь изучать и другие интересные модели, такие как Llama, Mistral или Qwen, чтобы продолжить свое обучение!
9. Уборка
Чтобы избежать дополнительных расходов в будущем, важно удалить созданные вами ресурсы. Выполните следующие команды для очистки проекта.
1. Удалите службу Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Удалите репозиторий реестра артефактов:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Удалите учетную запись службы:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Удалите секрет из Secret Manager:
gcloud secrets delete HF_TOKEN --quiet