
1. บทนำ
โมเดลภาษาขนาดใหญ่ (LLM) กำลังเปลี่ยนแปลงวิธีสร้างแอปพลิเคชันอัจฉริยะ แต่การเตรียมโมเดลที่มีประสิทธิภาพเหล่านี้ให้พร้อมใช้งานในโลกแห่งความเป็นจริงอาจเป็นเรื่องยาก ซึ่งต้องใช้พลังการประมวลผลจำนวนมาก โดยเฉพาะการ์ดกราฟิก (GPU) และวิธีอัจฉริยะในการจัดการคำขอจำนวนมากพร้อมกัน นอกจากนี้ คุณยังต้องการควบคุมค่าใช้จ่ายและให้แอปพลิเคชันทำงานได้อย่างราบรื่นโดยไม่ล่าช้า
Codelab นี้จะแสดงวิธีรับมือกับความท้าทายเหล่านี้ เราจะใช้เครื่องมือสำคัญ 2 อย่าง ได้แก่
- vLLM: คิดว่านี่เป็นเหมือนเครื่องยนต์ที่เร็วสุดๆ สำหรับ LLM ซึ่งจะช่วยให้โมเดลทำงานได้อย่างมีประสิทธิภาพมากขึ้น จัดการคำขอได้มากขึ้นในครั้งเดียว และลดการใช้หน่วยความจำ
- Google Cloud Run: แพลตฟอร์มแบบ Serverless ของ Google เหมาะอย่างยิ่งสำหรับการติดตั้งใช้งานแอปพลิเคชัน เนื่องจากจะจัดการการปรับขนาดทั้งหมดให้คุณ ตั้งแต่ผู้ใช้ 0 คนไปจนถึงหลายพันคน และกลับมาอีกครั้ง และที่สำคัญที่สุดคือ Cloud Run รองรับ GPU แล้ว ซึ่งจำเป็นอย่างยิ่งสำหรับการโฮสต์ LLM
เมื่อใช้ร่วมกัน vLLM และ Cloud Run จะมอบวิธีที่มีประสิทธิภาพ ยืดหยุ่น และคุ้มค่าในการแสดง LLM ในคู่มือนี้ คุณจะได้ติดตั้งใช้งานโมเดลแบบเปิดเพื่อให้พร้อมใช้งานเป็นเว็บ API มาตรฐาน
สิ่งที่คุณจะได้เรียนรู้
- วิธีเลือกขนาดและรูปแบบโมเดลที่เหมาะสมสำหรับการแสดง
- วิธีกำหนดค่า vLLM เพื่อให้บริการปลายทาง API ที่เข้ากันได้กับ OpenAI
- วิธีสร้างคอนเทนเนอร์เซิร์ฟเวอร์ vLLM ด้วย Docker
- วิธีพุชอิมเมจคอนเทนเนอร์ไปยัง Google Artifact Registry
- วิธีทำให้คอนเทนเนอร์ใช้งานได้กับ Cloud Run โดยใช้การเร่งความเร็วด้วย GPU
- วิธีทดสอบโมเดลที่ใช้งานจริง
สิ่งที่คุณต้องมี
- เบราว์เซอร์ เช่น Chrome เพื่อเข้าถึงคอนโซล Google Cloud
- การเชื่อมต่ออินเทอร์เน็ตที่เสถียร
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- โทเค็นเพื่อการเข้าถึง Hugging Face (สร้างโทเค็นที่นี่หากยังไม่มี)
- มีความคุ้นเคยพื้นฐานกับ Python, Docker และอินเทอร์เฟซบรรทัดคำสั่ง
- มีความใฝ่รู้และกระตือรือร้นที่จะเรียนรู้
2. ก่อนที่คุณจะเริ่มต้น
ตั้งค่าโปรเจ็กต์ Google Cloud
Codelab นี้กำหนดให้ต้องมีโปรเจ็กต์ Google Cloud ที่มีบัญชีสำหรับการเรียกเก็บเงินที่ใช้งานอยู่
- สำหรับเซสชันที่มีผู้สอน: หากอยู่ในห้องเรียน ผู้สอนจะให้ข้อมูลโปรเจ็กต์และข้อมูลสำหรับการเรียกเก็บเงินที่จำเป็นแก่คุณ ทำตามวิธีการจากผู้สอนเพื่อตั้งค่าให้เสร็จสมบูรณ์
- สำหรับผู้เรียนอิสระ: หากคุณกำลังดำเนินการนี้ด้วยตนเองและไม่มีบัญชีสำหรับการเรียกเก็บเงินที่ใช้งานอยู่ คุณจะต้องตั้งค่าบัญชีสำหรับการเรียกเก็บเงินโดยใช้ข้อมูลการชำระเงินของคุณเอง โปรดดูเอกสารประกอบการเรียกเก็บเงินใน Cloud ของ Google Cloud เพื่อสร้างบัญชีสำหรับการเรียกเก็บเงินใหม่และเปิดใช้สำหรับโปรเจ็กต์
สร้างโปรเจ็กต์ Google Cloud
คุณจะเริ่มต้นด้วยการสร้างโปรเจ็กต์ Google Cloud ใหม่เพื่อให้งานทั้งหมดใน Codelab นี้เป็นระเบียบและแยกจากโปรเจ็กต์อื่นๆ
หากต้องการเปิดหน้าการสร้างโปรเจ็กต์ ให้คลิก
ป้อนข้อมูลที่จำเป็นในหน้าการสร้างโปรเจ็กต์
- ชื่อโปรเจ็กต์ - คุณป้อนชื่อใดก็ได้ตามต้องการ (เช่น genai-workshop)
- สถานที่ - ปล่อยไว้เป็นไม่มีองค์กร
- บัญชีสำหรับการเรียกเก็บเงิน - หากตัวเลือกนี้ปรากฏขึ้น ให้เลือก "บัญชีสำหรับการเรียกเก็บเงินของ Google Cloud Platform เวอร์ชันทดลองใช้งาน" หรือบัญชีสำหรับการเรียกเก็บเงินของคุณเองหากต้องการ หากไม่เห็นตัวเลือกนี้ ให้ไปที่ขั้นตอนถัดไป
คัดลอกรหัสโปรเจ็กต์ที่สร้างขึ้นไว้ คุณจะต้องใช้รหัสนี้ในภายหลัง 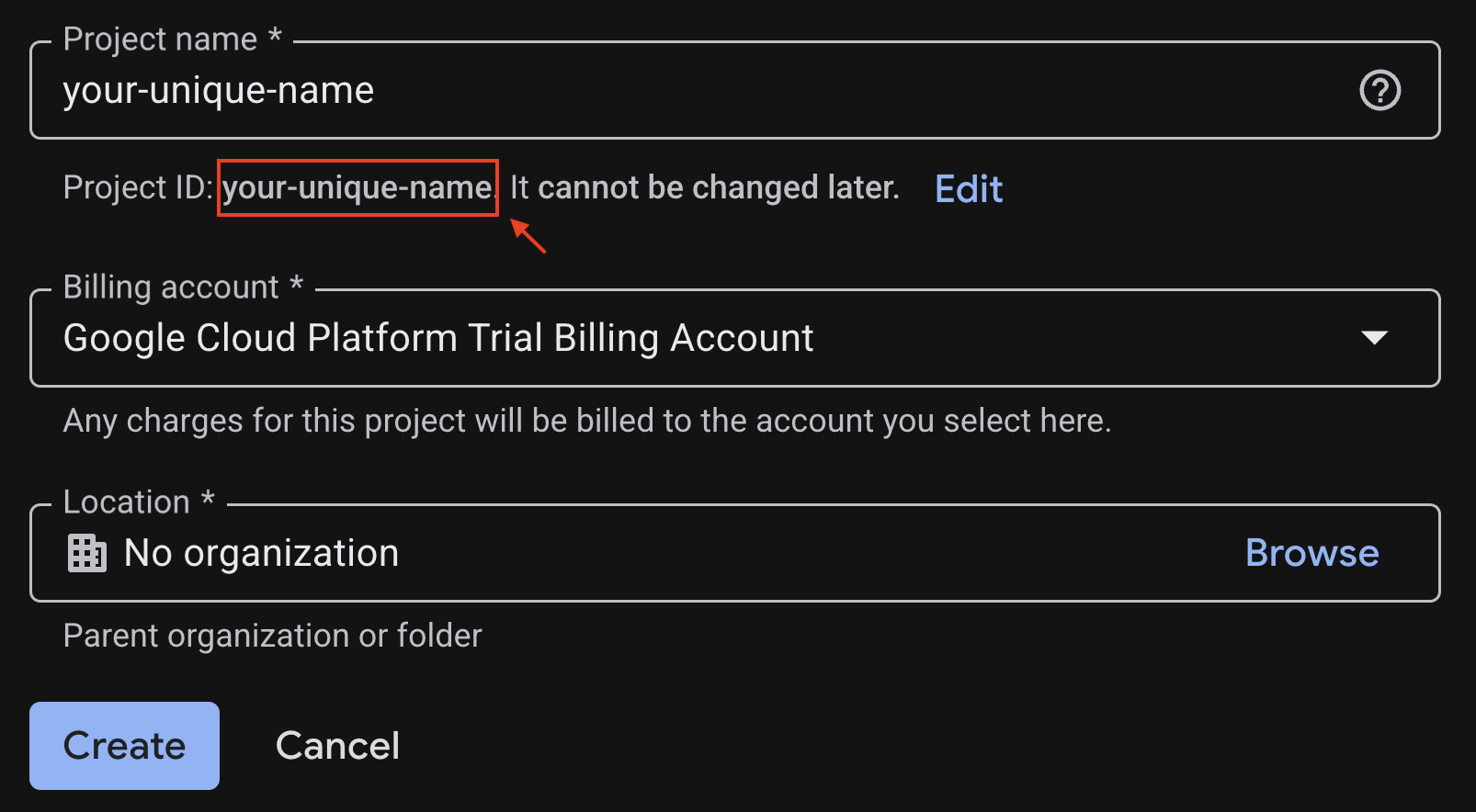
หากทุกอย่างเรียบร้อยดี ให้คลิกปุ่มสร้าง
กำหนดค่า Cloud Shell
Cloud Shell เป็นสภาพแวดล้อมที่กำหนดค่าไว้ล่วงหน้าซึ่งมีเครื่องมือทั้งหมดที่คุณต้องการสำหรับ Codelab นี้ เมื่อสร้างโปรเจ็กต์เรียบร้อยแล้ว ให้ทำตามขั้นตอนต่อไปนี้เพื่อตั้งค่า Cloud Shell
เปิดใช้ Cloud Shell
หากต้องการเปิดใช้ Cloud Shell ให้คลิก
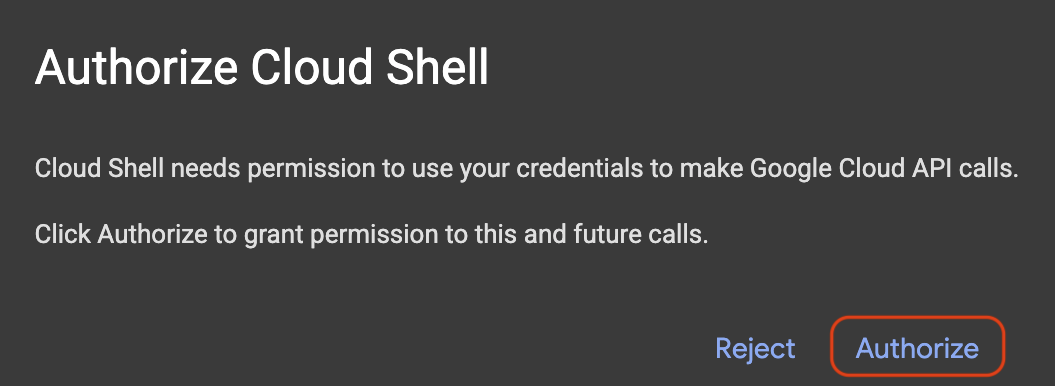
หากป๊อปอัปปรากฏขึ้นเพื่อขอการให้สิทธิ์ ให้คลิกให้สิทธิ์
ตั้งค่ารหัสโปรเจ็กต์
แทนที่ replace-with-your-project-id ด้วยรหัสโปรเจ็กต์จริงจากขั้นตอนการสร้างโปรเจ็กต์ด้านบน เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล Cloud Shell เพื่อตั้งค่ารหัสโปรเจ็กต์ที่ถูกต้อง
gcloud config set project replace-with-your-project-id
ตอนนี้คุณควรเห็นว่าได้เลือกโปรเจ็กต์ที่ถูกต้องภายในเทอร์มินัล Cloud Shell แล้ว รหัสโปรเจ็กต์ที่เลือกจะไฮไลต์เป็นสีเหลือง

เปิดใช้ API ที่จำเป็น
หากต้องการใช้บริการของ Google Cloud เช่น Cloud Run คุณต้องเปิดใช้งาน API ที่เกี่ยวข้องสำหรับโปรเจ็กต์ก่อน เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อเปิดใช้บริการที่จำเป็นสำหรับ Codelab นี้
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. การเลือกรุ่นที่เหมาะสม
คุณสามารถค้นหาโมเดลแบบเปิดได้มากมายในเว็บไซต์ต่างๆ เช่น Hugging Face Hub และ Kaggle เมื่อต้องการใช้โมเดลเหล่านี้ในบริการอย่าง Google Cloud Run คุณต้องเลือกโมเดลที่เหมาะกับทรัพยากรที่คุณมี (เช่น GPU NVIDIA L4)
นอกเหนือจากขนาดแล้ว อย่าลืมพิจารณาว่าโมเดลทำอะไรได้บ้าง โมเดลแต่ละรายการไม่เหมือนกัน โดยแต่ละรายการมีข้อดีและข้อเสียของตัวเอง เช่น โมเดลบางรุ่นสามารถจัดการอินพุตประเภทต่างๆ (เช่น รูปภาพและข้อความ ซึ่งเรียกว่าความสามารถแบบมัลติโมดัล) ในขณะที่โมเดลอื่นๆ สามารถจดจำและประมวลผลข้อมูลได้มากขึ้นในครั้งเดียว (ซึ่งหมายความว่ามีหน้าต่างบริบทที่ใหญ่ขึ้น) โดยทั่วไปแล้ว โมเดลขนาดใหญ่จะมีขีดความสามารถขั้นสูงกว่า เช่น การเรียกใช้ฟังก์ชันและการคิด
นอกจากนี้ คุณควรตรวจสอบด้วยว่าเครื่องมือการแสดง (vLLM ในกรณีนี้) รองรับโมเดลที่ต้องการหรือไม่ คุณตรวจสอบโมเดลทั้งหมดที่ vLLM รองรับได้ที่นี่
ตอนนี้เรามาดู Gemma 3 ซึ่งเป็นโมเดลภาษาขนาดใหญ่ (LLM) ตระกูลล่าสุดของ Google ที่พร้อมให้บริการแบบเปิด Gemma 3 มี 4 ขนาดที่แตกต่างกันตามความซับซ้อน โดยวัดจากพารามิเตอร์ ได้แก่ 1 พันล้าน 4 พันล้าน 1.2 หมื่นล้าน และ 2.7 หมื่นล้าน
สำหรับขนาดแต่ละขนาด คุณจะเห็น 2 ประเภทหลัก ได้แก่
- เวอร์ชันพื้นฐาน (ที่ฝึกไว้ล่วงหน้า): โมเดลพื้นฐานที่เรียนรู้จากข้อมูลจำนวนมหาศาล
- เวอร์ชันที่ปรับแต่งตามคำสั่ง: เวอร์ชันนี้ได้รับการปรับแต่งเพิ่มเติมเพื่อให้เข้าใจและทำตามคำสั่งหรือคอมมานด์ที่เฉพาะเจาะจงได้ดียิ่งขึ้น
โมเดลขนาดใหญ่ (พารามิเตอร์ 4 พันล้าน, 1.2 หมื่นล้าน และ 2.7 หมื่นล้าน) เป็นโมเดลหลายรูปแบบ ซึ่งหมายความว่าโมเดลเหล่านี้สามารถเข้าใจและทำงานร่วมกับทั้งรูปภาพและข้อความได้ อย่างไรก็ตาม โมเดลที่มีพารามิเตอร์ 1 พันล้านรายการซึ่งมีขนาดเล็กที่สุดจะเน้นที่ข้อความเท่านั้น
สำหรับ Codelab นี้ เราจะใช้ Gemma 3 รูปแบบ 1 พันล้าน: gemma-3-1b-it การใช้โมเดลขนาดเล็กยังช่วยให้คุณเรียนรู้วิธีทำงานกับทรัพยากรที่จำกัด ซึ่งเป็นสิ่งสำคัญในการควบคุมค่าใช้จ่ายและทำให้มั่นใจว่าแอปจะทำงานได้อย่างราบรื่นในระบบคลาวด์
4. ตัวแปรสภาพแวดล้อมและข้อมูลลับ
สร้างไฟล์สภาพแวดล้อม
ก่อนที่เราจะดำเนินการต่อ แนวทางปฏิบัติที่ดีคือการกำหนดค่าทั้งหมดที่คุณจะใช้ตลอด Codelab นี้ไว้ในที่เดียว หากต้องการเริ่มต้นใช้งาน ให้เปิดเทอร์มินัลแล้วทำตามขั้นตอนต่อไปนี้
- สร้างโฟลเดอร์ใหม่สำหรับโปรเจ็กต์นี้
- ไปที่โฟลเดอร์ที่สร้างขึ้นใหม่
- สร้างไฟล์ .env ที่ว่างเปล่าภายในโฟลเดอร์นี้ (ไฟล์นี้จะเก็บตัวแปรสภาพแวดล้อมในภายหลัง)
คำสั่งสำหรับทำตามขั้นตอนดังกล่าวมีดังนี้
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
จากนั้นคัดลอกตัวแปรที่แสดงด้านล่างและวางลงในไฟล์ .env ที่คุณเพิ่งสร้าง
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
อย่าลืมแทนที่ค่าตัวยึดตำแหน่ง (your_project_id และ your_region) ด้วยข้อมูลโปรเจ็กต์ที่เฉพาะเจาะจง เช่น (PROJECT_ID=unique-ai-project และ REGION=europe-west4) ดูรายการภูมิภาคที่รองรับ GPU ใน Cloud Run ได้ที่นี่
เมื่อแก้ไขและบันทึกไฟล์.env แล้ว ให้พิมพ์คำสั่งนี้เพื่อโหลดตัวแปรสภาพแวดล้อมเหล่านั้นลงในเซสชันเทอร์มินัล
source .env
คุณสามารถทดสอบว่าตัวแปรโหลดสําเร็จหรือไม่โดยการแสดงตัวแปรใดตัวแปรหนึ่ง เช่น
echo $SERVICE_NAME
หากคุณได้รับค่าเดียวกันกับที่กำหนดไว้ในไฟล์ .env แสดงว่าโหลดตัวแปรสำเร็จแล้ว
จัดเก็บข้อมูลลับใน Secret Manager
สำหรับข้อมูลที่ละเอียดอ่อน รวมถึงรหัสการเข้าถึง ข้อมูลเข้าสู่ระบบ และรหัสผ่าน เราขอแนะนำให้ใช้ Secret Manager
ก่อนใช้โมเดล Gemma 3 คุณต้องรับทราบข้อกำหนดและเงื่อนไขก่อน เนื่องจากโมเดลนี้ต้องมีการควบคุมการเข้าถึง คุณสามารถรับทราบข้อกำหนดและเงื่อนไขได้ผ่านการ์ดโมเดล Gamma 3 ใน Hugging Face Hub
เมื่อมีโทเค็นการเข้าถึง Hugging Face แล้ว ให้ไปที่หน้า Secret Manager แล้วสร้างข้อมูลลับโดยทำตามวิธีการต่อไปนี้
- ไปที่คอนโซล Google Cloud
- เลือกโปรเจ็กต์จากแถบเมนูแบบเลื่อนลงด้านซ้ายบน
- ค้นหา Secret Manager ในแถบค้นหา แล้วคลิกตัวเลือกดังกล่าวเมื่อปรากฏขึ้น
เมื่ออยู่ในหน้า Secret Manager ให้ทำดังนี้
- คลิกปุ่ม +สร้าง Secret
- กรอกข้อมูลต่อไปนี้
- ชื่อ: HF_TOKEN
- ค่าข้อมูลลับ: <your_hf_access_token>
- คลิกปุ่มสร้างข้อมูลลับเมื่อเสร็จแล้ว
ตอนนี้คุณควรมีโทเค็นการเข้าถึง Hugging Face เป็นข้อมูลลับใน Secret Manager ของ Google Cloud
คุณทดสอบการเข้าถึงข้อมูลลับได้โดยการเรียกใช้คำสั่งด้านล่างในเทอร์มินัล ซึ่งคำสั่งดังกล่าวจะดึงข้อมูลลับจาก Secret Manager
gcloud secrets versions access latest --secret=HF_TOKEN
คุณควรเห็นว่าระบบกำลังดึงข้อมูลโทเค็นเพื่อการเข้าถึงและแสดงในหน้าต่างเทอร์มินัล
ให้สิทธิ์เข้าถึงข้อมูลลับแก่บัญชีบริการ Cloud Build
เนื่องจากตอนนี้ระบบจัดเก็บข้อมูลลับไว้อย่างปลอดภัยใน Secret Manager แล้ว
เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อดำเนินการดังกล่าว
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. สร้างบัญชีบริการ
เพื่อเพิ่มความปลอดภัยและจัดการการเข้าถึงอย่างมีประสิทธิภาพในการตั้งค่าการใช้งานจริง บริการควรทำงานภายใต้บัญชีบริการเฉพาะซึ่งจำกัดสิทธิ์อย่างเคร่งครัดเฉพาะสิทธิ์ที่จำเป็นสำหรับงานที่เฉพาะเจาะจง
เรียกใช้คำสั่งนี้เพื่อสร้างบัญชีบริการ
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
คำสั่งต่อไปนี้จะแนบสิทธิ์ที่จำเป็น
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. สร้างอิมเมจใน Artifact Registry
ขั้นตอนนี้เกี่ยวข้องกับการสร้างอิมเมจ Docker ที่มีน้ำหนักของโมเดลและ vLLM ที่ติดตั้งไว้ล่วงหน้า
1. สร้างที่เก็บ Docker ใน Artifact Registry
มาสร้างที่เก็บ Docker ใน Artifact Registry เพื่อพุชอิมเมจที่สร้างขึ้นกัน เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. การจัดเก็บโมเดล
คุณสามารถจัดเก็บโมเดล ML ภายในอิมเมจคอนเทนเนอร์หรือเพิ่มประสิทธิภาพการโหลดจาก Cloud Storage ได้โดยอิงตามเอกสารประกอบแนวทางปฏิบัติแนะนำเกี่ยวกับ GPU
แน่นอนว่าแต่ละวิธีก็มีข้อดีและข้อเสียของตัวเอง คุณสามารถอ่านเอกสารประกอบเพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์เหล่านี้ เพื่อความสะดวก เราจะจัดเก็บโมเดลไว้ในอิมเมจคอนเทนเนอร์ คุณจะดำเนินการดังกล่าวในเซสชันถัดไป
3. สร้างไฟล์ Docker
สร้างไฟล์ชื่อ Dockerfile แล้วคัดลอกเนื้อหาด้านล่างลงในไฟล์
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. สร้างไฟล์ yaml สำหรับการติดตั้งใช้งาน
จากนั้นสร้างไฟล์ชื่อ cloudbuild.yaml ในไดเรกทอรีเดียวกัน ไฟล์นี้จะกำหนดขั้นตอนที่ Cloud Build จะต้องทำตาม คัดลอกและวางเนื้อหาต่อไปนี้ลงใน cloudbuild.yaml
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. ส่งบิลด์ไปยัง Cloud Build
คัดลอกและวางโค้ดต่อไปนี้ แล้วดำเนินการในเทอร์มินัล
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
คำสั่งนี้จะอัปโหลดโค้ด (Dockerfile และ cloudbuild.yaml) ส่งตัวแปร Shell เป็นการแทนที่ (_MODEL_NAME และ _IMAGE_NAME) และเริ่มบิลด์
ตอนนี้ Cloud Build จะดำเนินการตามขั้นตอนที่กำหนดไว้ใน cloudbuild.yaml คุณสามารถติดตามบันทึกในเทอร์มินัลหรือโดยคลิกลิงก์ไปยังรายละเอียดการสร้างใน Cloud Console เมื่อสร้างเสร็จแล้ว อิมเมจคอนเทนเนอร์จะพร้อมใช้งานในที่เก็บ Artifact Registry และพร้อมสำหรับการติดตั้งใช้งาน
6. ทำให้ใช้งานได้กับ Cloud Run
ตอนนี้คุณพร้อมที่จะทำให้บริการใช้งานได้ใน Cloud Run แล้ว เรียกใช้คำสั่งนี้ในเทอร์มินัล
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. ทดสอบบริการ
เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อสร้างพร็อกซี เพื่อให้คุณเข้าถึงบริการได้ขณะที่บริการทำงานใน localhost
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
ในหน้าต่างเทอร์มินัลใหม่ ให้เรียกใช้curlคำสั่งนี้ในเทอร์มินัลเพื่อทดสอบการเชื่อมต่อ
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
หากเห็นเอาต์พุตที่คล้ายกับด้านล่าง
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. บทสรุป
ยินดีด้วย คุณทำ Codelab นี้เสร็จเรียบร้อยแล้ว คุณได้เรียนรู้วิธีต่อไปนี้
- เลือกขนาดโมเดลที่เหมาะสมสำหรับการติดตั้งใช้งานเป้าหมาย
- ตั้งค่า vLLM เพื่อให้บริการ API ที่เข้ากันได้กับ OpenAI
- สร้างคอนเทนเนอร์เซิร์ฟเวอร์ vLLM และน้ำหนักของโมเดลอย่างปลอดภัยด้วย Docker
- พุชอิมเมจคอนเทนเนอร์ไปยัง Google Artifact Registry
- ทำให้บริการที่เร่งด้วย GPU ใช้งานได้ใน Cloud Run
- ทดสอบโมเดลที่ได้รับการตรวจสอบสิทธิ์และติดตั้งใช้งานแล้ว
คุณสามารถสำรวจการติดตั้งใช้งานโมเดลอื่นๆ ที่น่าสนใจ เช่น Llama, Mistral หรือ Qwen เพื่อเรียนรู้ต่อไปได้
9. ล้างข้อมูล
คุณควรลบทรัพยากรที่สร้างขึ้นเพื่อหลีกเลี่ยงการเรียกเก็บเงินในอนาคต เรียกใช้คำสั่งต่อไปนี้เพื่อล้างข้อมูลในโปรเจ็กต์
1. ลบบริการ Cloud Run
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. ลบที่เก็บของ Artifact Registry
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. ลบบัญชีบริการ
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. ลบข้อมูลลับจาก Secret Manager
gcloud secrets delete HF_TOKEN --quiet