
1. Giới thiệu
Các mô hình ngôn ngữ lớn (LLM) đang thay đổi cách chúng ta xây dựng các ứng dụng thông minh. Tuy nhiên, việc chuẩn bị các mô hình mạnh mẽ này để sử dụng trong thế giới thực có thể gặp nhiều khó khăn. Chúng cần nhiều sức mạnh tính toán, đặc biệt là card đồ hoạ (GPU) và các cách thông minh để xử lý nhiều yêu cầu cùng một lúc. Ngoài ra, bạn muốn giảm chi phí và đảm bảo ứng dụng chạy mượt mà mà không bị chậm trễ.
Lớp học lập trình này sẽ hướng dẫn bạn cách giải quyết những thách thức này! Chúng ta sẽ sử dụng hai công cụ chính:
- vLLM: Hãy coi đây là một công cụ siêu nhanh dành cho LLM. Công cụ này giúp các mô hình của bạn chạy hiệu quả hơn nhiều, xử lý nhiều yêu cầu cùng một lúc và giảm mức sử dụng bộ nhớ.
- Google Cloud Run: Đây là nền tảng không máy chủ của Google. Nền tảng này rất phù hợp để triển khai ứng dụng vì xử lý tất cả các hoạt động mở rộng quy mô cho bạn – từ 0 người dùng đến hàng nghìn người dùng và ngược lại. Điều tuyệt vời nhất là Cloud Run hiện hỗ trợ GPU, đây là yếu tố cần thiết để lưu trữ LLM!
Cùng nhau, vLLM và Cloud Run mang đến một cách mạnh mẽ, linh hoạt và tiết kiệm chi phí để phân phát LLM. Trong hướng dẫn này, bạn sẽ triển khai một mô hình mở, giúp mô hình này hoạt động dưới dạng một API web tiêu chuẩn.
Kiến thức bạn sẽ học được
- Cách chọn kích thước và biến thể mô hình phù hợp để phân phát.
- Cách thiết lập vLLM để phân phát các điểm cuối API tương thích với OpenAI.
- Cách đóng gói máy chủ vLLM bằng Docker.
- Cách đẩy hình ảnh vùng chứa lên Google Artifact Registry.
- Cách triển khai vùng chứa lên Cloud Run bằng tính năng tăng tốc GPU.
- Cách kiểm thử mô hình đã triển khai.
Bạn cần có
- Một trình duyệt, chẳng hạn như Chrome, để truy cập vào Google Cloud Console
- Kết nối Internet ổn định
- Một dự án trên Google Cloud đã bật tính năng thanh toán
- Mã truy cập Hugging Face (tạo một mã truy cập tại đây nếu bạn chưa có)
- Nắm vững kiến thức cơ bản về Python, Docker và giao diện dòng lệnh
- Một tâm trí tò mò và sẵn sàng học hỏi
2. Trước khi bắt đầu
Thiết lập dự án trên Google Cloud
Lớp học lập trình này yêu cầu một dự án trên Google Cloud có tài khoản thanh toán đang hoạt động.
- Đối với các buổi học do người hướng dẫn dẫn dắt: Nếu bạn đang ở trong một lớp học, người hướng dẫn sẽ cung cấp cho bạn thông tin dự án và thông tin thanh toán cần thiết. Hãy làm theo hướng dẫn của người hướng dẫn để hoàn tất quá trình thiết lập.
- Đối với người học độc lập: Nếu bạn đang tự học và không có tài khoản thanh toán đang hoạt động, bạn sẽ cần thiết lập một tài khoản thanh toán bằng thông tin thanh toán của riêng mình. Hãy tham khảo tài liệu Thanh toán trên Google Cloud để tạo một tài khoản thanh toán mới và bật tài khoản đó cho dự án của bạn.
Tạo một dự án trên Google Cloud
Để sắp xếp và tách biệt tất cả công việc của bạn cho lớp học lập trình này với các dự án khác, bạn sẽ bắt đầu bằng cách tạo một dự án mới trên Google Cloud.
Để mở trang tạo dự án, hãy nhấp vào:
Nhập thông tin bắt buộc trên trang tạo dự án:
- Tên dự án – bạn có thể nhập bất kỳ tên nào bạn muốn (ví dụ: genai-workshop)
- Vị trí – để nguyên là Không có tổ chức
- Tài khoản thanh toán – Nếu tuỳ chọn này xuất hiện, hãy chọn "Tài khoản thanh toán dùng thử Google Cloud Platform" hoặc tài khoản thanh toán của riêng bạn nếu bạn muốn. Nếu không thấy tuỳ chọn này, bạn có thể chuyển sang bước tiếp theo.
Sao chép Mã dự án đã tạo, bạn sẽ cần mã này sau. 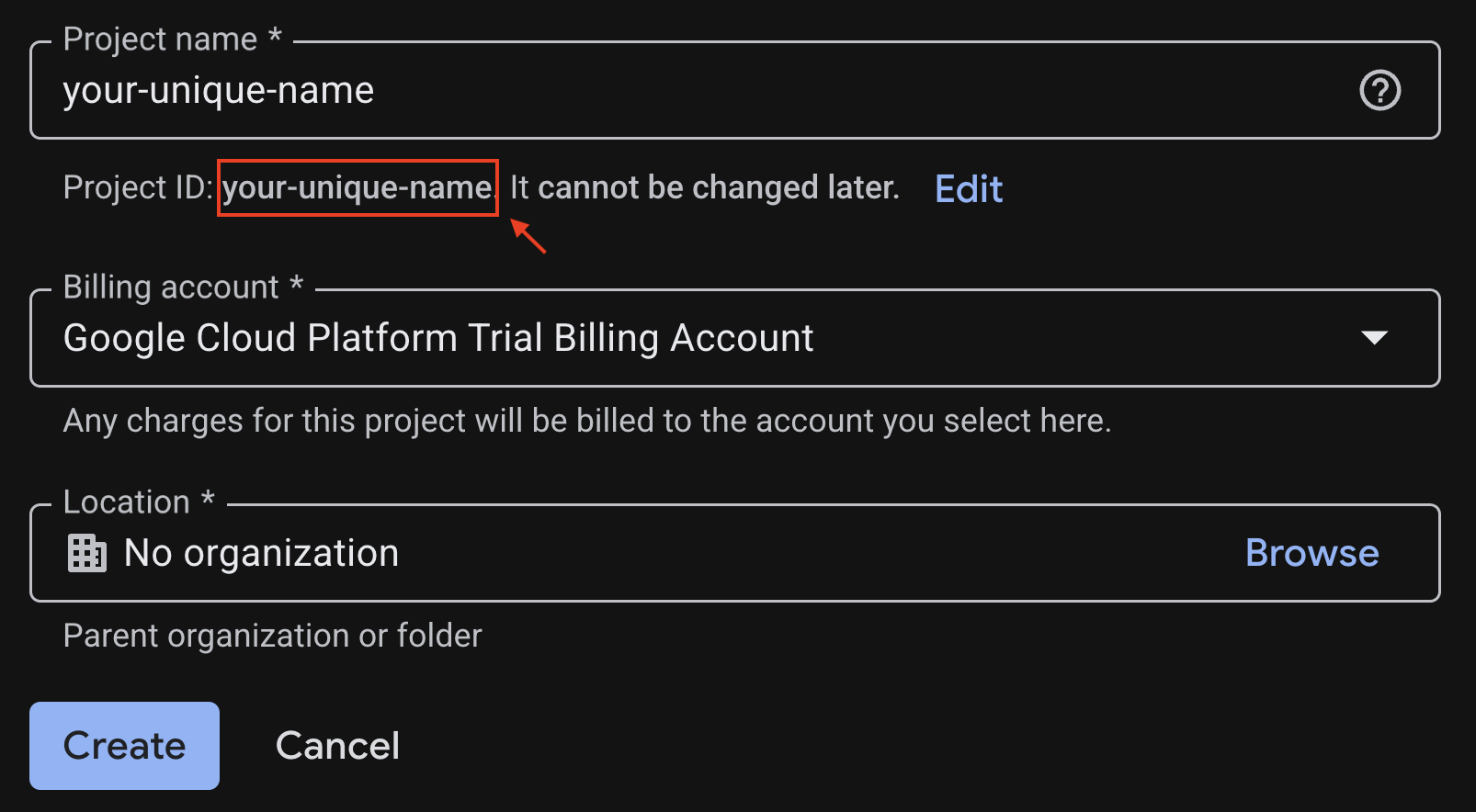
Nếu mọi thứ đều ổn, hãy nhấp vào nút Tạo.
Định cấu hình Cloud Shell
Cloud Shell là một môi trường được định cấu hình sẵn với tất cả các công cụ bạn cần cho lớp học lập trình này. Sau khi tạo dự án thành công, hãy thực hiện các bước sau để thiết lập Cloud Shell.
Khởi chạy Cloud Shell
Để khởi chạy Cloud Shell, hãy nhấp vào:
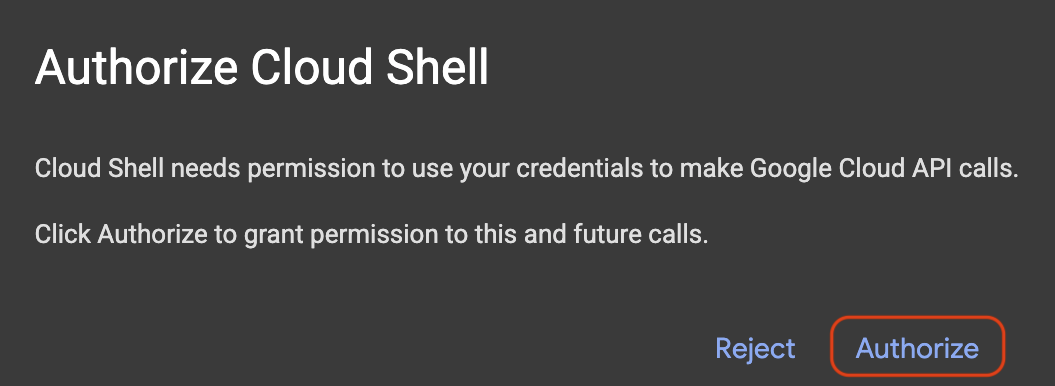
Nếu một cửa sổ bật lên xuất hiện yêu cầu uỷ quyền, hãy nhấp vào Uỷ quyền.
Đặt mã dự án
Thay thế replace-with-your-project-id bằng Mã dự án thực tế của bạn trong bước tạo dự án ở trên. Thực thi lệnh sau trong cửa sổ dòng lệnh Cloud Shell để đặt Mã dự án chính xác.
gcloud config set project replace-with-your-project-id
Bây giờ, bạn sẽ thấy dự án chính xác được chọn trong cửa sổ dòng lệnh Cloud Shell. Mã dự án đã chọn được đánh dấu màu vàng.

Bật các API cần thiết
Để sử dụng các dịch vụ của Google Cloud như Cloud Run, trước tiên, bạn phải kích hoạt các API tương ứng cho dự án của mình. Chạy các lệnh sau trong Cloud Shell để bật các dịch vụ cần thiết cho lớp học lập trình này:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. Chọn mô hình phù hợp
Bạn có thể tìm thấy nhiều mô hình mở trên các trang web như Hugging Face Hub và Kaggle. Khi muốn sử dụng một trong những mô hình này trên một dịch vụ như Google Cloud Run, bạn cần chọn một mô hình phù hợp với các tài nguyên mà bạn có (tức là GPU NVIDIA L4).
Ngoài kích thước, hãy nhớ cân nhắc những gì mô hình thực sự có thể làm. Các mô hình không giống nhau; mỗi mô hình đều có những ưu điểm và nhược điểm riêng. Ví dụ: một số mô hình có thể xử lý nhiều loại dữ liệu đầu vào (như hình ảnh và văn bản – được gọi là khả năng đa phương thức), trong khi những mô hình khác có thể ghi nhớ và xử lý nhiều thông tin hơn cùng một lúc (nghĩa là chúng có cửa sổ ngữ cảnh lớn hơn). Thông thường, các mô hình lớn hơn sẽ có nhiều khả năng nâng cao hơn như gọi hàm và suy nghĩ.
Bạn cũng cần kiểm tra xem công cụ phân phát có hỗ trợ mô hình mong muốn của bạn hay không (trong trường hợp này là vLLM). Bạn có thể kiểm tra tất cả các mô hình được vLLM hỗ trợ tại đây.
Bây giờ, hãy khám phá Gemma 3, đây là dòng mô hình ngôn ngữ lớn (LLM) mới nhất của Google được cung cấp công khai. Gemma 3 có 4 quy mô khác nhau dựa trên độ phức tạp, được đo bằng tham số: 1 tỷ, 4 tỷ, 12 tỷ và 27 tỷ.
Đối với mỗi kích thước này, bạn sẽ tìm thấy 2 loại chính:
- Phiên bản cơ sở (được huấn luyện trước): Đây là mô hình nền tảng đã học được từ một lượng lớn dữ liệu.
- Phiên bản được điều chỉnh theo hướng dẫn: Phiên bản này đã được tinh chỉnh thêm để hiểu rõ hơn và làm theo các hướng dẫn hoặc lệnh cụ thể.
Các mô hình lớn hơn (4 tỷ, 12 tỷ và 27 tỷ tham số) là đa phương thức, nghĩa là chúng có thể hiểu và xử lý cả hình ảnh và văn bản. Tuy nhiên, biến thể nhỏ nhất có 1 tỷ tham số chỉ tập trung vào văn bản.
Đối với lớp học lập trình này, chúng ta sẽ sử dụng 1 tỷ biến thể của Gemma 3: gemma-3-1b-it. Việc sử dụng một mô hình nhỏ hơn cũng giúp bạn tìm hiểu cách làm việc với các tài nguyên hạn chế, điều này rất quan trọng để giảm chi phí và đảm bảo ứng dụng của bạn chạy mượt mà trên đám mây.
4. Biến môi trường và khoá bí mật
Tạo tệp môi trường
Trước khi tiếp tục, bạn nên tập hợp tất cả các cấu hình mà bạn sẽ sử dụng trong suốt lớp học lập trình này ở một nơi. Để bắt đầu, hãy mở cửa sổ dòng lệnh và thực hiện các bước sau:
- Tạo một thư mục mới cho dự án này.
- Chuyển đến thư mục mới tạo.
- Tạo một tệp .env trống trong thư mục này (tệp này sẽ chứa các biến môi trường của bạn sau này)
Sau đây là lệnh để thực hiện các bước đó:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
Tiếp theo, sao chép các biến được liệt kê bên dưới và dán vào tệp.env mà bạn vừa tạo.
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Hãy nhớ thay thế các giá trị giữ chỗ (your_project_id và your_region) bằng thông tin dự án cụ thể của bạn. Ví dụ: (PROJECT_ID=unique-ai-project và REGION=europe-west4). Hãy xem danh sách các khu vực hỗ trợ GPU trên Cloud Run tại đây.
Sau khi chỉnh sửa và lưu tệp.env, hãy nhập lệnh này để tải các biến môi trường đó vào phiên dòng lệnh:
source .env
Bạn có thể kiểm tra xem các biến có được tải thành công hay không bằng cách lặp lại một trong các biến. Ví dụ:
echo $SERVICE_NAME
Nếu bạn nhận được cùng một giá trị như giá trị bạn đã chỉ định trong tệp.env, thì các biến sẽ được tải thành công.
Lưu trữ khoá bí mật trên Secret Manager
Đối với mọi dữ liệu nhạy cảm, bao gồm cả mã truy cập, thông tin đăng nhập và mật khẩu, bạn nên sử dụng trình quản lý khoá bí mật.
Trước khi sử dụng các mô hình Gemma 3, bạn phải xác nhận các điều khoản và điều kiện vì các mô hình này được kiểm soát. Bạn có thể xác nhận các điều khoản và điều kiện thông qua Thẻ mô hình Gamma 3 trên Hugging Face Hub.
Sau khi có Mã truy cập Hugging Face, hãy chuyển đến trang Secret Manager và tạo một khoá bí mật bằng cách làm theo các hướng dẫn sau
- Chuyển đến Google Cloud Console
- Chọn dự án trong thanh trình đơn thả xuống ở trên cùng bên trái
- Tìm kiếm Secret Manager trong thanh tìm kiếm và nhấp vào tuỳ chọn đó khi xuất hiện
Khi bạn ở trang Secret Manager:
- Nhấp vào nút +Tạo khoá bí mật,
- Điền thông tin sau:
- Tên: HF_TOKEN
- Giá trị khoá bí mật: <your_hf_access_token>
- Nhấp vào nút Tạo khoá bí mật sau khi bạn hoàn tất.
Bây giờ, bạn sẽ có Mã truy cập Hugging Face dưới dạng một khoá bí mật trên Google Cloud Secret Manager.
Bạn có thể kiểm tra quyền truy cập vào khoá bí mật bằng cách thực thi lệnh bên dưới trong cửa sổ dòng lệnh. Lệnh đó sẽ truy xuất khoá bí mật từ Secret Manager:
gcloud secrets versions access latest --secret=HF_TOKEN
Bạn sẽ thấy Mã truy cập của mình được truy xuất và hiển thị trong cửa sổ dòng lệnh.
Cấp quyền truy cập vào khoá bí mật cho tài khoản dịch vụ Cloud Build
Vì khoá bí mật hiện được lưu trữ an toàn trên Secret Manager,
Chạy các lệnh sau trong cửa sổ dòng lệnh để thực hiện việc đó:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. Tạo một tài khoản dịch vụ
Để tăng cường tính bảo mật và quản lý quyền truy cập một cách hiệu quả trong môi trường hoạt động thực tế, các dịch vụ phải hoạt động trong các tài khoản dịch vụ riêng biệt, chỉ được giới hạn ở các quyền cần thiết cho các tác vụ cụ thể của chúng.
Chạy lệnh này để tạo một tài khoản dịch vụ
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
Lệnh sau đây sẽ đính kèm quyền cần thiết
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. Tạo hình ảnh trên Artifact Registry
Bước này liên quan đến việc tạo một hình ảnh Docker bao gồm trọng số mô hình và vLLM được cài đặt sẵn.
1. Tạo kho lưu trữ Docker trên Artifact Registry
Hãy tạo một kho lưu trữ Docker trong Artifact Registry để đẩy các hình ảnh đã tạo. Chạy lệnh sau trong cửa sổ dòng lệnh:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
2. Lưu trữ mô hình
Dựa trên tài liệu về các phương pháp hay nhất cho GPU, bạn có thể lưu trữ các mô hình ML bên trong hình ảnh vùng chứa hoặc tối ưu hoá việc tải các mô hình đó từ Cloud Storage.
Tất nhiên, mỗi phương pháp đều có những ưu điểm và nhược điểm riêng. Bạn có thể đọc tài liệu để tìm hiểu thêm về các phương pháp này. Để đơn giản, chúng ta sẽ chỉ lưu trữ mô hình trong hình ảnh vùng chứa. Bạn sẽ thực hiện việc đó trong phiên tiếp theo.
3. Tạo tệp Docker
Tạo một tệp có tên là Dockerfile và sao chép nội dung bên dưới vào tệp đó:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. Tạo tệp yaml để triển khai
Tiếp theo, tạo một tệp có tên là cloudbuild.yaml trong cùng một thư mục. Tệp này xác định các bước mà Cloud Build sẽ làm theo. Sao chép và dán nội dung sau vào cloudbuild.yaml:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. Gửi bản dựng đến Cloud Build
Sao chép và dán mã sau rồi chạy mã đó trong cửa sổ dòng lệnh:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
Lệnh này tải mã của bạn lên (Dockerfile và cloudbuild.yaml), truyền các biến dòng lệnh của bạn dưới dạng các giá trị thay thế (_MODEL_NAME và _IMAGE_NAME) và bắt đầu bản dựng.
Cloud Build sẽ thực thi các bước được xác định trong cloudbuild.yaml. Bạn có thể theo dõi nhật ký trong cửa sổ dòng lệnh hoặc bằng cách nhấp vào đường liên kết đến thông tin chi tiết về bản dựng trong Cloud Console. Sau khi hoàn tất, hình ảnh vùng chứa sẽ có trong kho lưu trữ Artifact Registry, sẵn sàng để triển khai.
6. Triển khai lên Cloud Run
Bây giờ, bạn đã sẵn sàng triển khai dịch vụ lên Cloud Run. Thực thi lệnh này trong cửa sổ dòng lệnh:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. Kiểm thử dịch vụ
Chạy lệnh sau trong cửa sổ dòng lệnh để tạo một proxy, nhờ đó bạn có thể truy cập vào dịch vụ khi dịch vụ đang chạy trong localhost:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
Trong một cửa sổ dòng lệnh mới, hãy chạy lệnh curl này trong cửa sổ dòng lệnh để kiểm thử kết nối
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
Nếu bạn thấy kết quả tương tự như bên dưới:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. Kết luận
Xin chúc mừng! Bạn đã hoàn tất thành công lớp học lập trình này. Bạn đã tìm hiểu cách:
- Chọn kích thước mô hình phù hợp cho một hoạt động triển khai mục tiêu.
- Thiết lập vLLM để phân phát một API tương thích với OpenAI.
- Đóng gói an toàn máy chủ vLLM và trọng số mô hình bằng Docker.
- Đẩy hình ảnh vùng chứa lên Google Artifact Registry.
- Triển khai một dịch vụ được tăng tốc bằng GPU lên Cloud Run.
- Kiểm thử một mô hình đã triển khai được xác thực.
Bạn có thể thoải mái khám phá cách triển khai các mô hình thú vị khác như Llama, Mistral hoặc Qwen để tiếp tục hành trình học tập!
9. Dọn dẹp
Để tránh phát sinh các khoản phí trong tương lai, bạn cần xoá các tài nguyên mà bạn đã tạo. Chạy các lệnh sau để dọn dẹp dự án của bạn.
1. Xoá dịch vụ Cloud Run:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
2. Xoá kho lưu trữ Artifact Registry:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. Xoá tài khoản dịch vụ:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. Xoá khoá bí mật khỏi Secret Manager:
gcloud secrets delete HF_TOKEN --quiet