
1. 简介
大语言模型 (LLM) 正在改变我们构建智能应用的方式。但要让这些强大的模型做好在现实世界中使用的准备可能很棘手。它们需要大量的计算能力,尤其是图形卡 (GPU),以及智能的方式来同时处理许多请求。此外,您还希望降低费用,并确保应用顺畅运行,不会出现延迟。
此 Codelab 将向您展示如何应对这些挑战!我们将使用两个关键工具:
- vLLM:您可以将其视为 LLM 的超快速引擎。它可以让您的模型更高效地运行,同时处理更多请求并减少内存使用量。
- Google Cloud Run:这是 Google 的无服务器平台。它非常适合部署应用,因为它会为您处理所有扩缩操作,从零用户到数千用户,然后再缩减。最重要的是,Cloud Run 现在支持 GPU,这对于托管 LLM 至关重要!
vLLM 和 Cloud Run 共同提供了一种强大、灵活且经济高效的方式来提供 LLM。在本指南中,您将部署一个开放模型,使其作为标准 Web API 提供。
学习内容
- 如何选择合适的模型大小和变体以进行服务。
- 如何设置 vLLM 以提供与 OpenAI 兼容的 API 端点。
- 如何使用 Docker 将 vLLM 服务器容器化。
- 如何将容器映像推送到 Google Artifact Registry。
- 如何使用 GPU 加速功能将容器部署到 Cloud Run。
- 如何测试已部署的模型。
所需条件
- 浏览器(例如 Chrome),用于访问 Google Cloud 控制台
- 可靠的互联网连接
- 启用了结算功能的 Google Cloud 项目
- Hugging Face 访问令牌(如果您还没有,请在此处创建一个 )
- 基本熟悉 Python、Docker 和命令行界面
- 好奇心强,渴望学习
2. 准备工作
设置 Google Cloud 项目
此 Codelab 需要一个启用了结算账号的 Google Cloud 项目。
- 对于讲师指导的课程: 如果您在课堂上,讲师会为您提供必要的项目和结算信息。请按照讲师的说明完成设置。
- 对于独立学习者: 如果您是自行完成此 Codelab,并且没有现有的有效结算账号,则需要使用自己的支付信息设置结算账号。请参阅 Google Cloud Billing 文档,以创建新的结算账号并为您的项目启用该账号。
创建 Google Cloud 项目
为了让您在此 Codelab 中的所有工作井井有条,并与其他项目分开,您将首先创建一个新的 Google Cloud 项目。
在项目创建页面上输入所需信息:
- 项目名称 - 您可以输入所需的任何名称(例如 genai-workshop)
- 位置 \- 将其保留为无组织
- 结算账号 - 如果显示此选项,请选择“Google Cloud Platform 试用结算账号”,或者如果您愿意,也可以选择自己的结算账号。如果您没有看到此选项,可以继续执行下一步。
记下生成的项目 ID,您稍后会用到它。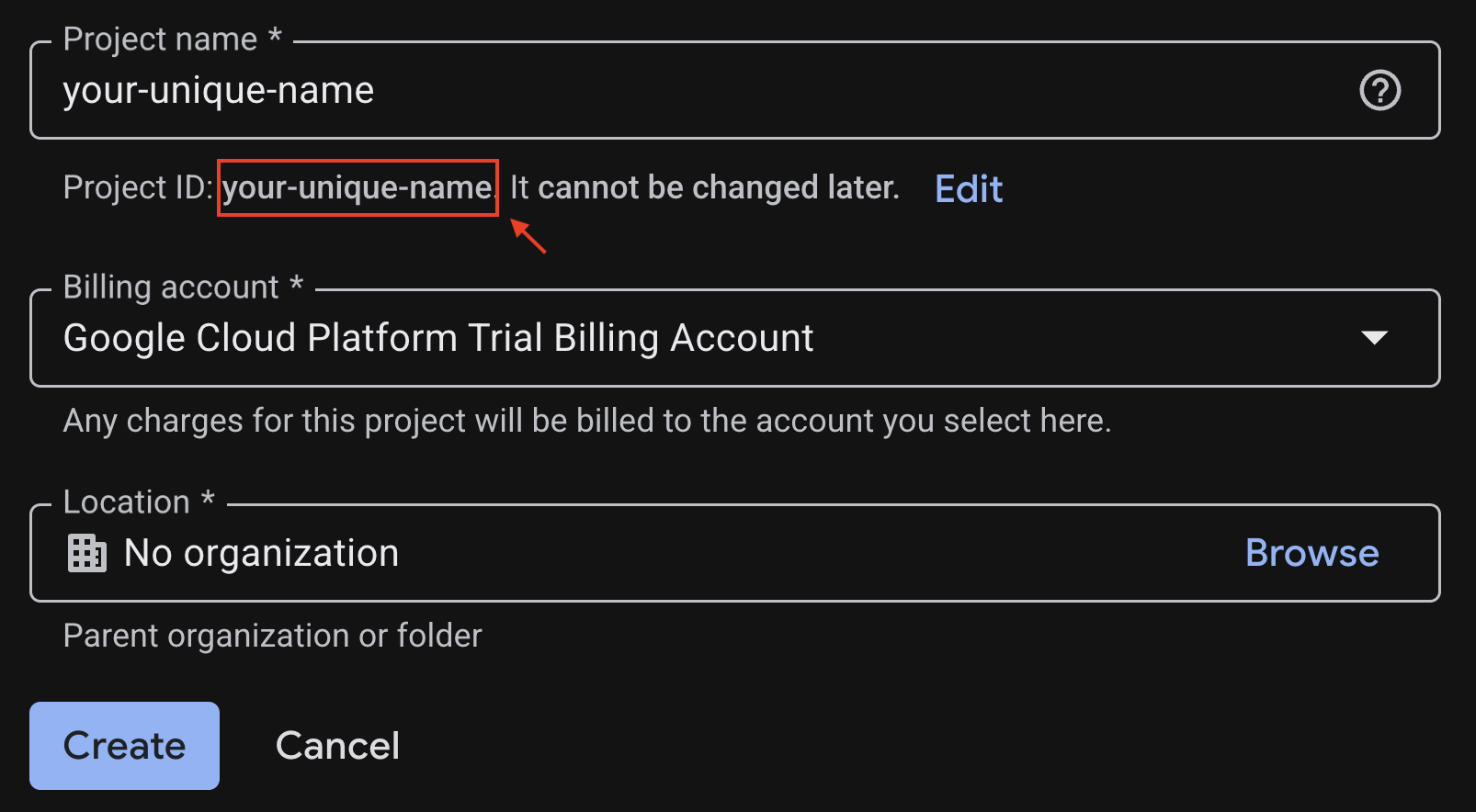
如果一切正常,请点击创建 按钮。
配置 Cloud Shell
Cloud Shell 是一个预配置的环境,其中包含此 Codelab 所需的所有工具。成功创建项目后,请按照以下步骤设置 Cloud Shell 。
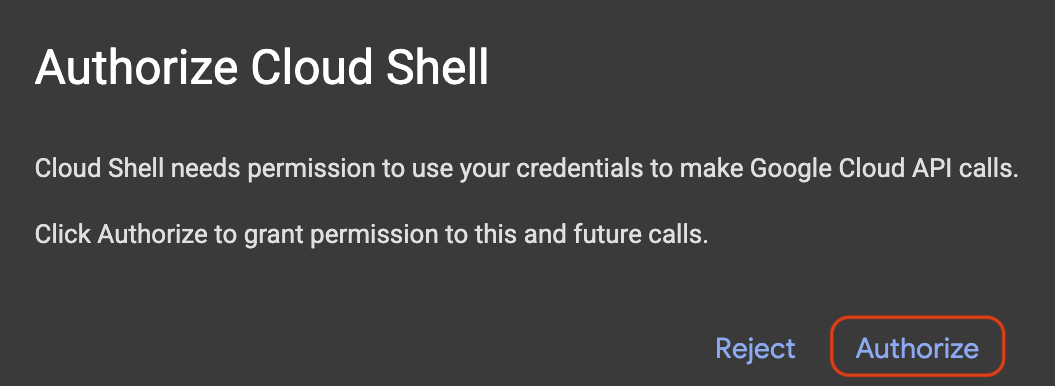
启动 Cloud Shell
如果系统弹出授权提示,请点击授权 。
设置项目 ID
将 replace-with-your-project-id 替换为上面项目创建步骤中的实际项目 ID。在 Cloud Shell 终端中执行以下命令,以设置正确的项目 ID 。
gcloud config set project replace-with-your-project-id
您现在应该会在 Cloud Shell 终端中看到已选择正确的项目。所选项目 ID 以黄色突出显示。

启用必要的 API
如需使用 Cloud Run 等 Google Cloud 服务,您必须先为项目启用其各自的 API。在 Cloud Shell 中运行以下命令,为此 Codelab 启用必要服务:
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
3. 选择合适的模型
您可以在 Hugging Face Hub 和 Kaggle 等网站上找到许多开放模型。如果您想在 Google Cloud Run 等服务中使用其中一个模型,则需要选择一个适合您拥有的资源(即 NVIDIA L4 GPU)的模型。
除了大小之外,请务必考虑模型实际可以执行的操作。模型并非完全相同;每个模型都有自己的优点和缺点。例如,某些模型可以处理不同类型的输入(例如图片和文本,称为多模态功能),而其他模型可以一次记住和处理更多信息(这意味着它们具有更大的上下文窗口)。通常,较大的模型将具有更高级的功能,例如 函数调用 和 思考。
此外,检查服务工具(在本例中为 vLLM)是否支持所需模型也很重要。您可以在此处查看 vLLM 支持的所有模型 here。
现在,我们来探索 Gemma 3,这是 Google 最新的开放式大语言模型 (LLM) 系列。Gemma 3 根据其复杂性(以 参数 衡量)分为四种不同的规模:10 亿、40 亿、120 亿和 270 亿。
对于每种规模,您都会找到两种主要类型:
- 基本(预训练)版本:这是从海量数据中学习的基础模型。
- 指令微调版本:此版本经过进一步优化,可以更好地理解和遵循特定指令或命令。
较大的模型(40 亿、120 亿和 270 亿个参数)是多模态的,这意味着它们可以理解和处理图片和文本。不过,最小的 10 亿个参数变体仅专注于文本。
在此 Codelab 中,我们将使用 Gemma 3 的 10 亿个变体: gemma-3-1b-it。使用较小的模型还有助于您了解如何使用有限的资源,这对于降低费用并确保应用在云端顺畅运行非常重要。
4. 环境变量和密钥
创建环境文件
在继续之前,最好将您在此 Codelab 中使用的所有配置放在一个位置。如需开始,请打开终端并执行以下步骤:
- 为此项目创建一个新文件夹 。
- 进入新创建的文件夹。
- 在此文件夹中创建一个空的 .env 文件(此文件稍后将保存您的环境变量)
以下是执行这些步骤的命令:
mkdir vllm-gemma3 && cd vllm-gemma3 && cloudshell edit .env
接下来,复制下面列出的变量,并将其粘贴到您刚刚创建的 .env 文件 中。
PROJECT_ID=your_project_id
REGION=your_region
MODEL_PROVIDER=google
MODEL_VARIANT=gemma-3-1b-it
MODEL_NAME=${MODEL_PROVIDER}/${MODEL_VARIANT}
AR_REPO_NAME=vllm-gemma3-repo
SERVICE_NAME=${MODEL_VARIANT}-service
IMAGE_NAME=${REGION}-docker.pkg.dev/${PROJECT_ID}/${AR_REPO_NAME}/${SERVICE_NAME}
SERVICE_ACC_NAME=${SERVICE_NAME}-sa
SERVICE_ACC_EMAIL=${SERVICE_ACC_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
请务必将占位值(your_project_id 和 your_region)替换为您的具体项目信息。例如(PROJECT_ID=unique-ai-project 和 REGION=europe-west4)。如需查看 Cloud Run 上支持 GPU 的区域列表,请点击此处。
修改并保存 .env 文件 后,输入以下命令将这些环境变量加载到终端会话中:
source .env
您可以通过回显其中一个变量来测试变量是否已成功加载。例如:
echo $SERVICE_NAME
如果您获得的值与您在 .env 文件 中分配的值相同,则表示变量已成功加载。
在 Secret Manager 上存储密钥
对于任何敏感数据(包括访问代码、凭据和密码),建议使用密钥管理器。
在使用 Gemma 3 模型之前,您必须先确认相关条款及条件,因为这些模型是受限的。您可以通过 Hugging Face Hub 上的 Gamma 3 模型卡片 确认相关条款及条件。
获得 Hugging Face 访问令牌后,请前往 Secret Manager 页面,然后按照以下说明创建一个密钥
- 前往 Google Cloud 控制台
- 从左上角的下拉栏中选择项目
- 在搜索栏中搜索 Secret Manager ,然后在显示该选项时点击它
当您位于 Secret Manager 页面时:
- 点击 +创建密钥 按钮,
- 填写以下信息:
- 名称:HF_TOKEN
- 密钥值: <your_hf_access_token>
- 完成后,点击创建密钥 按钮。
您现在应该在 Google Cloud Secret Manager 上拥有一个 Hugging Face 访问令牌作为密钥。
您可以通过在终端中执行以下命令来测试对密钥的访问权限,该命令将从 Secret Manager 中检索密钥:
gcloud secrets versions access latest --secret=HF_TOKEN
您应该会在终端窗口中看到检索并显示的访问令牌。
向 Cloud Build 服务账号授予 Secret 访问权限
由于密钥现在安全地存储在 Secret Manager 中,
请在终端中运行以下命令来执行此操作:
# Get the project number
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format='value(projectNumber)')
# Grant Cloud Build access to the Hugging Face Token secret
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${PROJECT_NUMBER}@cloudbuild.gserviceaccount.com" \
--role="roles/secretmanager.secretAccessor"
5. 创建服务账号
为了提高安全性并在生产环境中有效管理访问权限,服务应在专用服务账号下运行,这些账号严格限制为仅具有其特定任务所需的权限。
运行此命令以创建服务账号
gcloud iam service-accounts create $SERVICE_ACC_NAME --display-name='Cloud Run vLLM Model Serving SA'
以下命令会附加必要的权限
gcloud secrets add-iam-policy-binding HF_TOKEN \
--member="serviceAccount:${SERVICE_ACC_EMAIL}" \
--role="roles/secretmanager.secretAccessor"
6. 在 Artifact Registry 上创建映像
此步骤涉及创建一个 Docker 映像,其中包含模型权重和预安装的 vLLM。
1. 在 Artifact Registry 上创建 Docker 代码库
让我们在 Artifact Registry 中创建一个 Docker 代码库,用于推送构建的映像。在终端中运行以下命令:
gcloud artifacts repositories create ${AR_REPO_NAME} \
--repository-format docker \
--location ${REGION}
**2. 存储模型
根据 GPU 最佳实践文档,您可以将机器学习模型存储在 容器映像中,也可以 优化从 Cloud Storage 加载机器学习模型。
当然,每种方法都有自己的优点和缺点。您可以阅读文档,详细了解这些方法。为简单起见,我们将仅将模型存储在容器映像中。您将在下一会话中执行此操作。
3. 创建 Docker 文件
创建一个名为 Dockerfile 的文件,并将以下内容复制到该文件中:
FROM vllm/vllm-openai:v0.16.0
ARG MODEL_NAME
ARG HF_TOKEN
ENV HF_HOME=/model-cache
ENV MODEL_NAME=${MODEL_NAME}
# Use the HF_TOKEN argument to log in and download the model
RUN huggingface-cli login --token ${HF_TOKEN} && \
huggingface-cli download ${MODEL_NAME}
# Prevent vLLM from trying to download the model again at runtime
ENV HF_HUB_OFFLINE=1
EXPOSE 8080
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server \
--port ${PORT:-8080} \
--model ${MODEL_NAME} \
--gpu-memory-utilization 0.90 \
${MAX_MODEL_LEN:+--max-model-len "$MAX_MODEL_LEN"}
4. 创建用于部署的 YAML 文件
接下来,在同一目录中创建一个名为 cloudbuild.yaml 的文件。此文件定义了 Cloud Build 要遵循的步骤。将以下内容复制并粘贴到 cloudbuild.yaml 中:
steps:
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- '-c'
- |
docker build \
--build-arg MODEL_NAME=${_MODEL_NAME} \
--build-arg HF_TOKEN=$$HF_TOKEN_SECRET \
-t ${_IMAGE_NAME} .
secretEnv: ['HF_TOKEN_SECRET']
images:
- '${_IMAGE_NAME}'
availableSecrets:
secretManager:
- versionName: projects/${PROJECT_ID}/secrets/HF_TOKEN/versions/latest
env: 'HF_TOKEN_SECRET'
5. 将构建提交到 Cloud Build
复制并粘贴以下代码,然后在终端中运行它:
gcloud builds submit . \
--config=cloudbuild.yaml \
--region=${REGION} \
--substitutions=_MODEL_NAME=${MODEL_NAME},_IMAGE_NAME=${IMAGE_NAME}
此命令会上传您的代码(Dockerfile 和 cloudbuild.yaml),将您的 shell 变量作为替换项(_MODEL_NAME 和 _IMAGE_NAME)传递,并启动构建。
Cloud Build 现在将执行 cloudbuild.yaml 中定义的步骤。您可以在终端中跟踪日志,也可以点击 Cloud 控制台中的构建详细信息链接。完成后,容器映像将显示在 Artifact Registry 代码库中,可供部署。
6. 部署到 Cloud Run
现在,您可以将服务部署到 Cloud Run。在终端中执行以下命令:
gcloud run deploy ${SERVICE_NAME} \
--image ${IMAGE_NAME} \
--region ${REGION} \
--service-account ${SERVICE_ACC_EMAIL} \
--gpu 1 \
--gpu-type nvidia-l4 \
--cpu 4 \
--memory 16Gi \
--max-instances 3 \
--concurrency 80 \
--no-allow-unauthenticated
7. 测试服务
在终端中运行以下命令以创建代理,以便您可以在 localhost 中运行服务时访问该服务:
gcloud run services proxy ${SERVICE_NAME} --region ${REGION}
在新的终端窗口中,在终端中运行此 curl 命令以测试连接
curl -X POST http://localhost:8080/v1/completions \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-3-1b-it",
"prompt": "Cloud Run is a ",
"max_tokens": 128,
"temperature": 0.90
}'
如果您看到类似于以下内容的输出:
{"id":"cmpl-e96d05d2893d42939c1780d44233defa","object":"text_completion","created":1746870778,"model":"google/gemma-3-1b-it","choices":[{"index":0,"text":"100% managed Kubernetes service. It's a great option for many use cases.\n\nHere's a breakdown of key features and considerations:\n\n* **Managed Kubernetes:** This means Google handles the underlying infrastructure, including scaling, patching, and maintenance. You don't need to worry about managing Kubernetes clusters.\n* **Serverless:** You only pay for the compute time your application actually uses. No charges when your code isn't running.\n* **Scalability:** Cloud Run automatically scales your application based on demand. You can easily scale up or down to handle fluctuating traffic.\n*","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":6,"total_tokens":134,"completion_tokens":128,"prompt_tokens_details":null}}
8. 总结
恭喜!您已成功完成此 Codelab。您已学习了:
- 为目标部署选择合适的模型大小。
- 设置 vLLM 以提供与 OpenAI 兼容的 API。
- 使用 Docker 安全地将 vLLM 服务器和模型权重容器化。
- 将容器映像推送到 Google Artifact Registry。
- 将 GPU 加速服务部署到 Cloud Run。
- 测试经过身份验证的已部署模型。
欢迎探索部署其他令人兴奋的模型(例如 Llama、Mistral 或 Qwen),继续您的学习之旅!
9. 清理
为避免日后产生费用,请务必删除您创建的资源。运行以下命令以清理您的项目。
1. 删除 Cloud Run 服务:
gcloud run services delete ${SERVICE_NAME} --region=${REGION} --quiet
**2. 删除 Artifact Registry 代码库:
gcloud artifacts repositories delete ${AR_REPO_NAME} --location=${REGION} --quiet
3. 删除服务账号:
gcloud iam service-accounts delete ${SERVICE_ACC_EMAIL} --quiet
4. 从 Secret Manager 中删除密钥:
gcloud secrets delete HF_TOKEN --quiet