
1. نظرة عامة
تخزّن شركة TheLook، وهي بائع تجزئة افتراضي للملابس يستخدم التجارة الإلكترونية، بيانات العملاء والمنتجات والطلبات والخدمات اللوجستية وأحداث الويب وحملات التسويق الرقمي في BigQuery. تريد الشركة الاستفادة من خبرة الفريق الحالية في SQL وPySpark لتحليل هذه البيانات باستخدام Apache Spark.
لتجنُّب توفير البنية الأساسية أو ضبطها يدويًا في Spark، تبحث شركة TheLook عن حلّ للتدرّج التلقائي يتيح لها التركيز على أحمال العمل بدلاً من إدارة المجموعات. بالإضافة إلى ذلك، يريدون تقليل الجهد المطلوب لدمج Spark وBigQuery مع البقاء ضمن بيئة BigQuery Studio.
في هذا المختبر، ستتوقّع ما إذا كان المستخدم سيجري عملية شراء من خلال إنشاء مصنّف الانحدار اللوجستي باستخدام PySpark والاستفادة من ميزة دمج دفاتر الملاحظات الأصلية وميزات الذكاء الاصطناعي في BigQuery Studio لاستكشاف البيانات. يمكنك نشر هذا النموذج على خادم استنتاج وإنشاء وكيل لتوجيه طلب بحث إلى النموذج باستخدام اللغة الطبيعية.
المتطلبات الأساسية
قبل بدء هذا الدرس التطبيقي، يجب أن تكون على دراية بما يلي:
- معرفة أساسية بلغة SQL ولغة البرمجة Python
- تشغيل رمز Python البرمجي في دفتر Jupyter
- فهم أساسي للحوسبة الموزّعة
الأهداف
- استخدِم دفاتر ملاحظات BigQuery Studio لتنفيذ سير عمل علوم البيانات.
- أنشئ اتصالاً بـ Apache Spark باستخدام الحوسبة بدون خادم من Google Cloud لـ Apache Spark والمستند إلى Spark Connect.
- استخدِم Lightning Engine لتسريع مهام Apache Spark بما يصل إلى 4.3 مرّة.
- يمكنك تحميل البيانات من BigQuery باستخدام عملية الدمج المضمّنة بين Apache Spark وBigQuery.
- استكشاف البيانات باستخدام ميزة إنشاء الرموز البرمجية بمساعدة Gemini
- إجراء هندسة الخصائص باستخدام إطار معالجة البيانات في Apache Spark
- تدريب نموذج تصنيف وتقييمه باستخدام مكتبة تعلُّم الآلة الأصلية في Apache Spark، وهي MLlib
- نشر خادم استنتاج لنموذج التصنيف باستخدام Flask و Cloud Run
- نشر وكيل لتوجيه طلب بحث إلى خادم الاستنتاج باستخدام لغة طبيعية من خلال Agent Engine وAgent Development Kit (ADK)
2. الاتصال ببيئة تشغيل Colab
تحديد مشروع على Google Cloud
أنشئ مشروعًا على Google Cloud. يمكنك استخدام حساب حالي.
تفعيل واجهات برمجة التطبيقات المقترَحة:
انقر هنا لتفعيل واجهات برمجة التطبيقات التالية:
- aiplatform.googleapis.com
- bigquery.googleapis.com
- bigquerystorage.googleapis.com
- bigqueryunified.googleapis.com
- cloudaicompanion.googleapis.com
- dataproc.googleapis.com
- storage.googleapis.com
- run.googleapis.com
التنقّل في واجهة المستخدم:
- في Google Cloud Console، انتقِل إلى "قائمة التنقّل" > BigQuery.
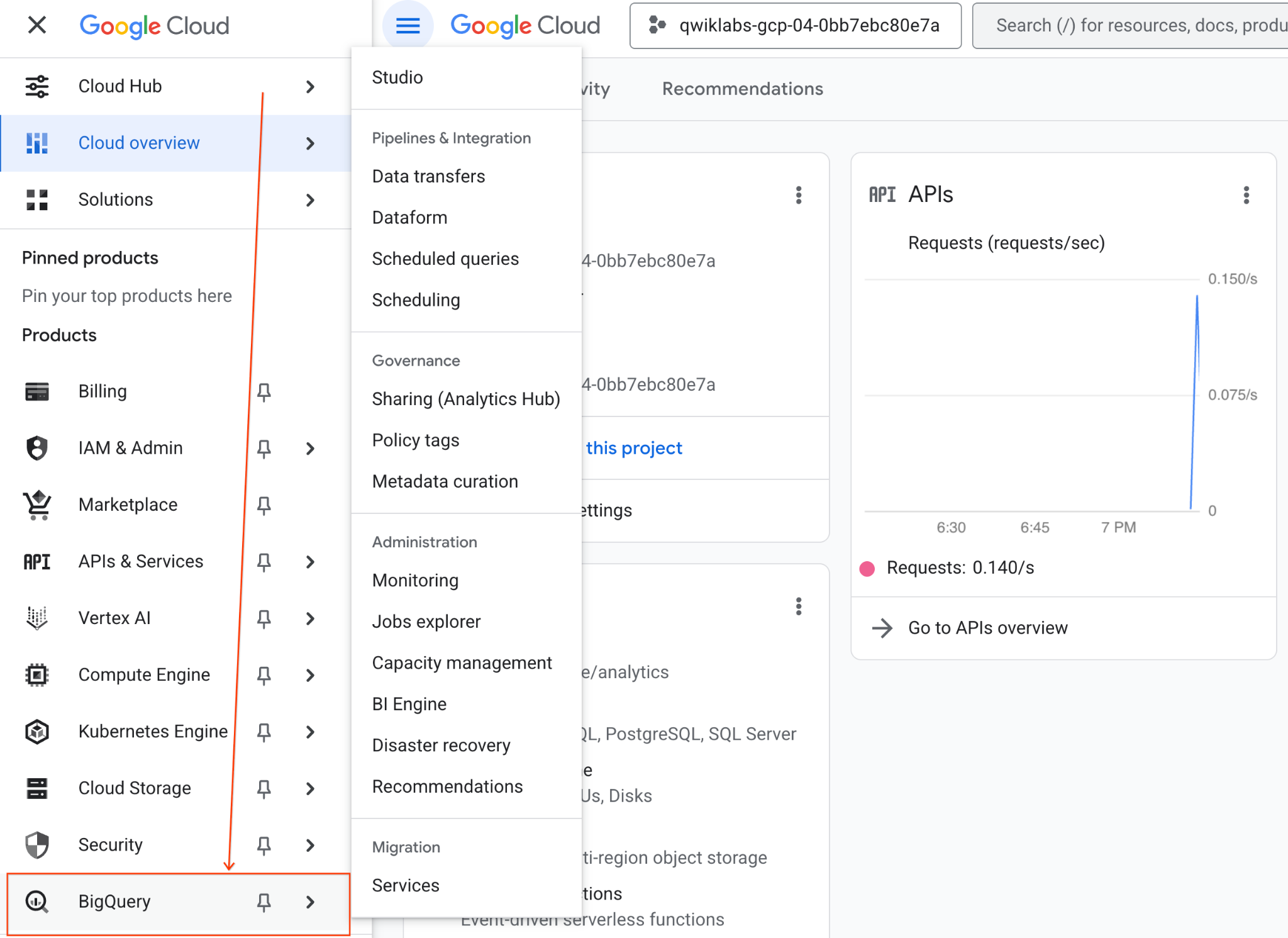
- في لوحة BigQuery Studio، انقر على زر السهم المتّجه للأسفل في القائمة المنسدلة، ثم مرِّر مؤشر الماوس فوق "دفتر الملاحظات"، ثم انقر على "تحميل".
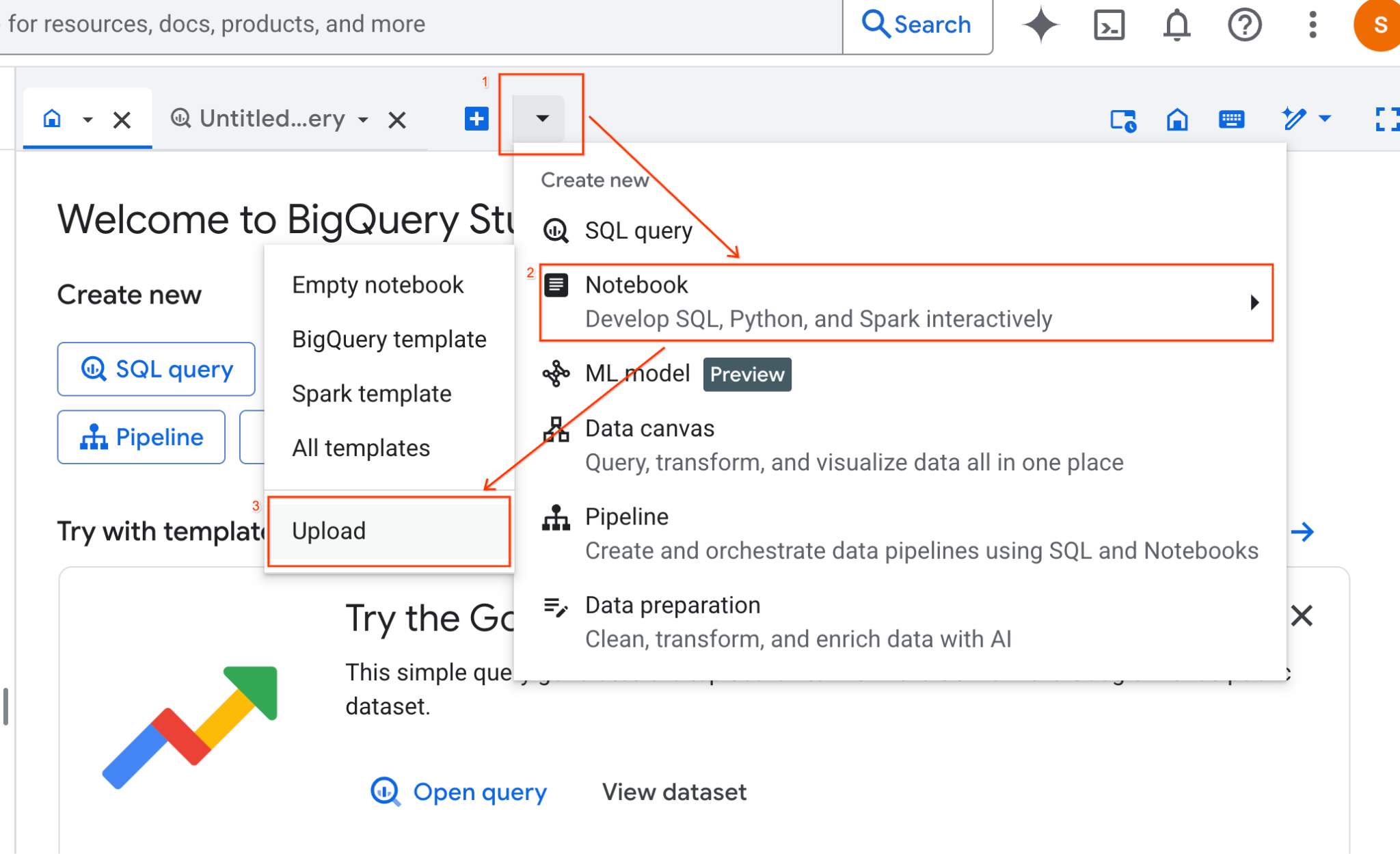
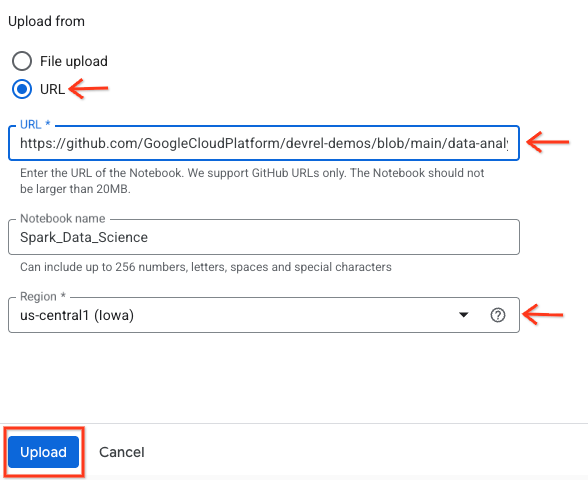
- انقر على زر اختيار عنوان URL وأدخِل عنوان URL التالي:
https://github.com/GoogleCloudPlatform/devrel-demos/blob/main/data-analytics/dataproc-webinar/data-science/Spark_Data_Science.ipynb
- اضبط المنطقة على
us-central11وانقر على تحميل.
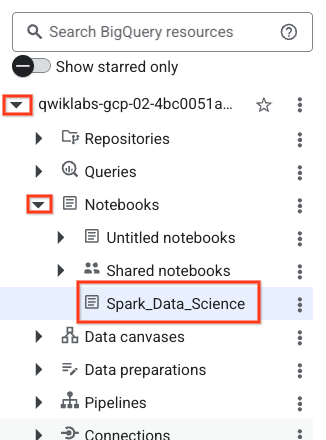
- لفتح دفتر الملاحظات، انقر على السهم المنسدل في جزء Explorer الذي يحمل اسم project-id. بعد ذلك، انقر على القائمة المنسدلة دفاتر الملاحظات. انقر على دفتر الملاحظات
Spark_Data_Science.
- يمكنك تصغير قائمة التنقّل في BigQuery وجدول المحتويات الخاص بدفتر الملاحظات لتوفير مساحة أكبر.
3- الاتصال ببيئة تشغيل وتنفيذ رمز إعداد إضافي
- انقر على ربط. في النافذة المنبثقة، امنح Colab Enterprise الإذن بالوصول إلى حساب بريدك الإلكتروني. سيتم ربط ورقة الملاحظات تلقائيًا بوقت تشغيل.
- بعد إنشاء وقت التشغيل، سيظهر لك ما يلي:
- ضمن دفتر الملاحظات، انتقِل إلى قسم الإعداد. يمكنك البدء من هنا.
4. تشغيل رمز الإعداد
اضبط بيئتك باستخدام مكتبات Python اللازمة لإكمال الدرس التطبيقي. إعداد الوصول الخاص إلى Google أنشئ حزمة Storage. أنشئ مجموعة بيانات في BigQuery. انسخ رقم تعريف مشروعك إلى دفتر الملاحظات. اختَر منطقة. في هذا التمرين العملي، استخدِم المنطقة us-central1.
يمكنك تنفيذ خلية تعليمات برمجية من خلال تمرير مؤشر الماوس داخل حزمة الخلية والنقر على السهم.
# Enable APIs
import subprocess
command = [
"gcloud",
"services",
"enable",
"aiplatform.googleapis.com",
"bigquery.googleapis.com",
"bigquerystorage.googleapis.com",
"bigqueryunified.googleapis.com",
"cloudaicompanion.googleapis.com",
"dataproc.googleapis.com",
"run.googleapis.com",
"storage.googleapis.com"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Configure a PROJECT_ID and REGION
PROJECT_ID = "<YOUR_PROJECT_ID>"
REGION = "<YOUR_REGION>"
# Enable Private Google Access
import subprocess
command = [
"gcloud",
"compute",
"networks",
"subnets",
"update",
"default",
f"--region={REGION}",
"--enable-private-ip-google-access"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Create a Cloud Storage Bucket
from google.cloud import storage
from google.cloud.exceptions import NotFound
BUCKET_NAME = f"{PROJECT_ID}-demo"
storage_client = storage.Client(project=PROJECT_ID)
try:
bucket = storage_client.get_bucket(BUCKET_NAME)
print(f"Bucket {BUCKET_NAME} already exists.")
except NotFound:
bucket = storage_client.create_bucket(BUCKET_NAME, location=REGION)
print(f"Bucket {BUCKET_NAME} created.")
# Create a BigQuery dataset.
from google.cloud import bigquery
DATASET_ID = f"{PROJECT_ID}.demo"
client = bigquery.Client()
dataset = bigquery.Dataset(DATASET_ID)
dataset.location = REGION
dataset = client.create_dataset(dataset, exists_ok=True)
5- إنشاء اتصال بخدمة "الحوسبة بدون خادم من Google Cloud لـ Apache Spark"
باستخدام Spark Connect، يمكنك الاتصال بجلسة Spark بدون خادم لتشغيل مهام Spark التفاعلية. يمكنك ضبط وقت التشغيل باستخدام Lightning Engine لتحقيق أداء متقدّم في Spark. تعمل Lightning Engine من خلال تسريع أحمال العمل باستخدام Apache Gluten وVelox.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
session.runtime_config.version = "3.0"
# You can optionally configure Spark properties as well. See https://cloud.google.com/dataproc-serverless/docs/concepts/properties.
session.runtime_config.properties = {
"dataproc.runtime": "premium",
"spark.dataproc.engine": "lightningEngine",
}
# To avoid going over quota in this demo, cap the max number of Spark workers.
session.runtime_config.properties = {
"spark.dynamicAllocation.maxExecutors": "4"
}
spark = (
DataprocSparkSession.builder
.appName("CustomSparkSession")
.dataprocSessionConfig(session)
.getOrCreate()
)
6. تحميل البيانات واستكشافها باستخدام Gemini
في هذا القسم، ستتدرّب على الخطوة الأولى المهمة في أي مشروع لعلم البيانات، وهي إعداد البيانات. تبدأ بتحميل البيانات إلى إطار بيانات Apache Spark من BigQuery.
# Load the tables
order_items = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.order_items").load()
users = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.users").load()
# Register temp tables
users.createOrReplaceTempView("users")
order_items.createOrReplaceTempView("order_items")
# Verify temp tables
spark.sql("SELECT * FROM order_items LIMIT 10").show()
بعد ذلك، يمكنك استخدام Gemini لإنشاء رمز PySpark لاستكشاف البيانات وفهمها بشكل أفضل.
الطلب 1: باستخدام PySpark، استكشِف جدول المستخدمين واعرض الصفوف العشرة الأولى.
# prompt: Using PySpark, explore the users table and show the first 10 rows.
users.show(10)
الطلب 2: باستخدام PySpark، استكشِف جدول order_items واعرض أول 10 صفوف.
# prompt: Using PySpark, explore the order_items table and show the first 10 rows.
order_items.show(10)
الطلب 3: باستخدام PySpark، اعرض أعلى 5 بلدان تكرارًا في جدول المستخدمين. عرض البلد وعدد المستخدمين من كل بلد
# prompt: Using PySpark, show the top 5 most frequent countries in the users table. Display the country and the number of users from each country.
from pyspark.sql.functions import col, count
users.groupBy("country").agg(count("*").alias("user_count")).orderBy(col("user_count").desc()).limit(5).show()
الطلب 4: باستخدام PySpark، ابحث عن متوسط سعر بيع السلع في جدول order_items.
# prompt: Using PySpark, find the average sale price of items in the order_items table.
from pyspark.sql import functions as F
average_sale_price = order_items.agg(F.avg("sale_price").alias("average_sale_price"))
average_sale_price.show()
الطلب 5: باستخدام الجدول "المستخدمون"، أنشئ رمزًا برمجيًا لرسم البلد مقابل مصدر الزيارات باستخدام مكتبة رسم مناسبة.
# prompt: Using the table "users", generate code to plot country vs traffic source using a suitable plotting library.
sql = """
SELECT
country,
traffic_source
FROM
`bigquery-public-data.thelook_ecommerce.users`
WHERE country IS NOT NULL AND traffic_source IS NOT NULL
"""
project_id = "iceberg-summit-2025"
df = pandas_gbq.read_gbq(sql, project_id=project_id, dialect="standard")
import matplotlib.pyplot as plt
import seaborn as sns
# Group by country and traffic_source and count occurrences
df_grouped = df.groupby(['country', 'traffic_source']).size().reset_index(name='count')
# Create a pivot table for easier plotting
pivot_table = df_grouped.pivot(index='country', columns='traffic_source', values='count').fillna(0)
# Plotting
plt.figure(figsize=(15, 8))
pivot_table.plot(kind='bar', stacked=True, figsize=(15, 8))
plt.title('Traffic Source Distribution by Country')
plt.xlabel('Country')
plt.ylabel('Number of Users')
plt.xticks(rotation=90)
plt.legend(title='Traffic Source')
plt.tight_layout()
plt.show()
الطلب 6: أنشئ مدرجًا تكراريًا يعرض توزيع "العمر" و"البلد" و"الجنس" و"مصدر الزيارات".
# prompt: Create a histogram showing the distribution of "age", "country", "gender", "traffic_source".
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for visualization
users_pd = users.toPandas()
# Create histograms for 'age', 'country', 'gender', 'traffic_source'
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('Distribution of User Attributes')
# Age distribution
axes[0, 0].hist(users_pd['age'].dropna(), bins=20, edgecolor='black')
axes[0, 0].set_title('Age Distribution')
axes[0, 0].set_xlabel('Age')
axes[0, 0].set_ylabel('Number of Users')
# Country distribution
users_pd['country'].value_counts().head(10).plot(kind='bar', ax=axes[0, 1])
axes[0, 1].set_title('Top 10 Countries Distribution')
axes[0, 1].set_xlabel('Country')
axes[0, 1].set_ylabel('Number of Users')
axes[0, 1].tick_params(axis='x', rotation=45)
# Gender distribution
users_pd['gender'].value_counts().plot(kind='bar', ax=axes[1, 0])
axes[1, 0].set_title('Gender Distribution')
axes[1, 0].set_xlabel('Gender')
axes[1, 0].set_ylabel('Number of Users')
axes[1, 0].tick_params(axis='x', rotation=0)
# Traffic Source distribution
users_pd['traffic_source'].value_counts().head(10).plot(kind='bar', ax=axes[1, 1])
axes[1, 1].set_title('Top 10 Traffic Source Distribution')
axes[1, 1].set_xlabel('Traffic Source')
axes[1, 1].set_ylabel('Number of Users')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
7. إعداد البيانات وهندسة الخصائص
بعد ذلك، يمكنك إجراء هندسة الخصائص على البيانات. اختَر الأعمدة المناسبة، وحوِّل البيانات إلى أنواع بيانات أكثر ملاءمة، وحدِّد عمود تصنيف.
features = spark.sql("""
SELECT
CAST(u.age AS DOUBLE) AS age,
CAST(hash(u.country) AS BIGINT) * 1.0 AS country_hash,
CAST(hash(u.gender) AS BIGINT) * 1.0 AS gender_hash,
CAST(hash(u.traffic_source) AS BIGINT) * 1.0 AS traffic_source_hash,
CASE WHEN COUNT(oi.id) > 0 THEN 1 ELSE 0 END AS label -- Changed label generation to count order items
FROM users AS u
LEFT JOIN order_items AS oi
ON u.id = oi.user_id
GROUP BY u.id, u.age, u.country, u.gender, u.traffic_source
""")
features.show()
8. تدريب نموذج انحدار لوجستي
باستخدام MLlib، يمكنك تدريب نموذج انحدار لوجستي. أولاً، عليك استخدام VectorAssembler لتحويل البيانات إلى تنسيق متّجه. بعد ذلك، تعمل StandardScaler على توسيع نطاق عمود الميزات لتحسين الأداء. بعد ذلك، يمكنك إنشاء مرجع لنموذج LogisticRegression وتحديد المَعلمات الفائقة. يمكنك دمج هذه الخطوات في عنصر Pipeline، وتدريب النموذج باستخدام الدالة fit()، وتحويل البيانات باستخدام الدالة transform().
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.pipeline import Pipeline
from pyspark.ml.functions import array_to_vector
#Split Train and Test Data (80:20)
train_data, test_data = features.randomSplit([0.8, 0.2], seed=42)
# Initialize VectorAssembler
assembler = VectorAssembler(
inputCols=["age", "country_hash", "gender_hash", "traffic_source_hash"],
outputCol="assembled_features"
)
# Initialize StandardScaler
scaler = StandardScaler(inputCol="assembled_features", outputCol="scaled_features")
# Initialize Logistic Regression model
lr = LogisticRegression(
maxIter=100,
regParam=0.2,
threshold=0.8,
featuresCol="scaled_features",
labelCol="label"
)
# Define pipeline
pipeline = Pipeline(stages=[assembler, scaler, lr])
# Fit the model
pipeline_model = pipeline.fit(train_data)
# Transform the dataset using the trained model
transformed_dataset = pipeline_model.transform(test_data)
transformed_dataset.show()
9- تقييم النماذج
قيِّم مجموعة البيانات التي تم تحويلها حديثًا. إنشاء مقياس التقييم المساحة تحت المنحنى (AUC)
# Model evaluation
eva = BinaryClassificationEvaluator(metricName="areaUnderPR")
aucPR = eva.evaluate(transformed_dataset)
print(f"AUC PR: {aucPR}")
بعد ذلك، استخدِم Gemini لإنشاء رمز PySpark لتصوّر مخرجات النموذج.
الطلب 1: إنشاء رمز لرسم منحنى الدقة والاستدعاء احسب مقياس صحة النموذج ومقياس المراجعة من توقّعات النموذج واعرض منحنى الدقة والاستدعاء باستخدام مكتبة رسم بياني مناسبة.
# prompt: Generate code to plot the Precision-Recall (PR) curve. Calculate precision and recall from the model's predictions and display the PR curve using a suitable plotting library.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, auc
# Extract predictions and labels
predictions = transformed_dataset.select("prediction", "label").toPandas()
# Calculate precision and recall
precision, recall, _ = precision_recall_curve(predictions["label"], predictions["prediction"])
# Calculate AUC-PR
pr_auc = auc(recall, precision)
# Plot the PR curve
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, color='blue', lw=2, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
الطلب 2: إنشاء رمز لإنشاء تصور لمصفوفة نجاح التوقعات. احتسِب مصفوفة نجاح التوقعات من توقّعات النموذج واعرضها كخريطة التمثيل اللوني أو جدول يتضمّن أعداد النتائج الموجبة الصحيحة (TP) والنتائج السالبة الصحيحة (TN) والنتائج الموجبة الخاطئة (FP) والنتائج السالبة الخاطئة (FN).
# prompt: Generate code to create a confusion matrix visualization. Calculate the confusion matrix from the model's predictions and display it as a heat map or a table with counts of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Extract predictions and labels
predictions_and_labels = transformed_dataset.select("prediction", "label").toPandas()
# Calculate the confusion matrix
cm = confusion_matrix(predictions_and_labels["label"], predictions_and_labels["prediction"])
# Create a DataFrame for better visualization
cm_df = pd.DataFrame(cm,
index=['Actual Negative', 'Actual Positive'],
columns=['Predicted Negative', 'Predicted Positive'])
# Display the confusion matrix as a table
print("Confusion Matrix:")
print(cm_df)
# Display the confusion matrix as a heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(cm_df, annot=True, fmt='d', cmap='Blues', cbar=False, linewidths=.5)
plt.title('Confusion Matrix')
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
plt.show()
# Calculate and display TP, TN, FP, FN
TN, FP, FN, TP = cm.ravel()
print(f"
True Positives (TP): {TP}")
print(f"True Negatives (TN): {TN}")
print(f"False Positives (FP): {FP}")
print(f"False Negatives (FN): {FN}")
10. كتابة التوقّعات في BigQuery
استخدِم Gemini لإنشاء رمز برمجي لكتابة توقّعاتك في جدول جديد في مجموعة بيانات BigQuery.
الطلب: باستخدام Spark، اكتب مجموعة البيانات المحوَّلة إلى BigQuery.
# prompt: Using Spark, write the transformed dataset to BigQuery.
transformed_dataset.write.format("bigquery").option("table", f"{PROJECT_ID}.demo.predictions").mode("overwrite").save()
11. حفظ النموذج في Cloud Storage
باستخدام الوظائف الأصلية في MLlib، احفظ نموذجك في Cloud Storage. يحمّل خادم الاستدلال النموذج من هنا.
MODEL_PATH = "models/prediction_model"
pipeline_model.write().overwrite().save(f"gs://{BUCKET_NAME}/{MODEL_PATH}")
12. إنشاء خادم استنتاج
Cloud Run هي أداة مرنة لتشغيل تطبيقات الويب بدون خادم. يستخدم حاويات Docker لتزويد المستخدمين بأقصى قدر من التخصيص. في هذا المختبر، تم ضبط Dockerfile لتشغيل تطبيق Flask الذي يشغّل PySpark. يتم تشغيل هذه الحاوية على Cloud Run لإجراء استنتاج بشأن بيانات الإدخال. يمكنك العثور على الرمز الخاص به هنا.
استنسِخ المستودع الذي يتضمّن رمز خادم الاستنتاج.
!git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
عرض ملف Dockerfile
FROM python:3.12-slim
# Install OpenJDK-21 (Required for Spark)
RUN apt-get update && \
apt-get install -y openjdk-21-jre-headless procps && \
rm -rf /var/lib/apt/lists/*
ENV JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64
ENV PORT=8080
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "--workers", "1", "--threads", "8", "--timeout", "0", "main:app"]
اطّلِع على رمز Python البرمجي للخادم.
import os
import json
import logging
from flask import Flask, request, jsonify
from google.cloud import storage
from pyspark.ml import PipelineModel
from pyspark.sql import SparkSession
from pyspark.sql.functions import hash, col
# Configure basic logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- Initialization: Spark and Model Loading ---
GCS_BUCKET = os.environ.get("GCS_BUCKET")
GCS_MODEL_PATH = os.environ.get("GCS_MODEL_PATH")
LOCAL_MODEL_PATH = "/tmp/model"
try:
spark = SparkSession.builder \
.appName("CloudRunSparkService") \
.master("local[*]") \
.getOrCreate()
logging.info("Spark Session successfully initialized.")
except Exception as e:
logging.error(f"Failed to initialize Spark Session: {e}")
raise
def download_directory(bucket_name, prefix, local_path):
"""Downloads a directory from GCS to local filesystem."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blobs = list(bucket.list_blobs(prefix=prefix))
if len(blobs) == 0:
logging.error(f"No files found in GCS bucket {bucket_name} at prefix {prefix}")
return
for blob in blobs:
if blob.name.endswith("/"): continue # Skip directories
# Structure local paths
relative_path = os.path.relpath(blob.name, prefix)
local_file_path = os.path.join(local_path, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
blob.download_to_filename(local_file_path)
print(f"Model downloaded to {local_path}")
# Load model
def load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH):
"""Download and load model on startup to avoid latency per request."""
global MODEL
if not os.path.exists(LOCAL_MODEL_PATH):
download_directory(GCS_BUCKET, GCS_MODEL_PATH, LOCAL_MODEL_PATH)
logging.info(f"Loading PySpark model from {GCS_MODEL_PATH}")
# Load the Spark ML model
try:
MODEL = PipelineModel.load(LOCAL_MODEL_PATH)
logging.info("Spark model loaded successfully.")
except Exception as e:
logging.error(f"Failed to load model: {e}")
raise
# Load Model on Startup
load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH)
# --- Flask Application Setup ---
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
"""
Handles incoming POST requests for inference.
Expects JSON data that can be converted into a Spark DataFrame.
"""
if MODEL is None:
return jsonify({"error": "Model failed to load at startup."}), 500
try:
# 1. Get data from the request
data = request.get_json()
# 2. Check length of list
data_len = len(data)
cap = 100
if data_len > cap:
return jsonify({"error": f"Too many records. Count: {data_len}, Max: {cap}"}), 400
# 2. Create Spark DataFrame
df = spark.createDataFrame(data)
# 3. Transform data
input_df = df.select(
col("age").cast("DOUBLE").alias("age"),
(hash(col("country")).cast("BIGINT") * 1.0).alias("country_hash"),
(hash(col("gender")).cast("BIGINT") * 1.0).alias("gender_hash"),
(hash(col("traffic_source")).cast("BIGINT") * 1.0).alias("traffic_source_hash")
)
# 3. Perform Inference
predictions_df = MODEL.transform(input_df)
# 4. Prepare results (collect and serialize)
results = [p.prediction for p in predictions_df.select("prediction").collect()]
# 5. Return JSON response
return jsonify({"predictions": results})
except Exception as e:
logging.error(f"An error occurred during prediction: {e}")
#return jsonify({"error": str(e)}), 500
raise e
# Gunicorn entry point uses 'app' from this file
if __name__ == '__main__':
# Local testing only: Cloud Run uses Gunicorn/CMD command
app.run(host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
انشر خادم الاستنتاج.
import subprocess
command = [
"gcloud",
"run",
"deploy",
"inference-server",
"--source",
"/content/devrel-demos/data-analytics/dataproc-webinar/data-science/inference-server",
"--region",
f"{REGION}",
"--port",
"8080",
"--memory",
"2Gi",
"--allow-unauthenticated",
"--set-env-vars",
f"GCS_BUCKET={BUCKET_NAME},GCS_MODEL_PATH={MODEL_PATH}",
"--startup-probe",
"tcpSocket.port=8080,initialDelaySeconds=240,failureThreshold=3,timeoutSeconds=240,periodSeconds=240"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
انسخ عنوان URL لخادم الاستدلال من الناتج إلى متغيّر جديد. سيكون مشابهًا لـ https://inference-server-123456789.us-central1.run.app.
INFERENCE_SERVER_URL = "<YOUR_SERVER_URL>"
اختبِر خادم الاستدلال.
import requests
age = "25.0"
country = "United States"
traffic_source = "Search"
gender = "F"
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
print(response.json())
يجب أن تكون النتيجة 1.0 أو 0.0.
{'predictions': [1.0]}
13. إعداد وكيل
استخدِم Agent Engine لإنشاء وكيل يمكنه إجراء الاستدلال. Agent Engine هو جزء من Vertex AI Platform، وهي مجموعة من الخدمات التي تتيح للمطوّرين تفعيل وكلاء الذكاء الاصطناعي وإدارتهم وتوسيع نطاقهم في مرحلة الإنتاج. تتضمّن هذه المنصة العديد من الأدوات، بما في ذلك تقييم الوكلاء وسياقات الجلسات وتنفيذ الرموز البرمجية. يتوافق مع العديد من أُطر العمل الشائعة المستندة إلى الوكلاء، بما في ذلك حزمة تطوير الوكلاء (ADK). ADK هو إطار عمل مفتوح المصدر يستند إلى الوكلاء، وعلى الرغم من أنّه مصمَّم ومحسَّن للاستخدام مع Gemini ومنظومة Google المتكاملة، إلا أنّه لا يعتمد على نموذج معيّن. وقد صُمِّم لجعل عملية تطوير الوكيل تبدو أشبه بعملية تطوير البرامج.
إعداد برنامج Vertex AI
import vertexai
from vertexai import agent_engines # For the prebuilt templates
client = vertexai.Client( # For service interactions via client.agent_engines
project=f"{PROJECT_ID}",
location=f"{REGION}",
)
حدِّد دالة للاستعلام عن النموذج الذي تم نشره.
def predict_purchase(
age: str = "25.0",
country: str = "United States",
traffic_source: str = "Search",
gender: str = "M",
):
"""Predicts whether or not a user will purchase a product.
Args:
age: The age of the user.
country: The country of the user. One of: "China", "Poland", "Germany", "United States", "Spain", "United Kingdom", "España", "Japan", "Brasil", "Colombia", "Belgium", "South Korea", "Austria", "France", "Australia".
Traffic_source: The source of the user's traffic. One of: "Display", "Email", "Search", "Organic", "Facebook".
gender: The gender of the user. One of: "M" or "F".
Returns:
True if the model output is 1.0, False otherwise.
"""
import requests
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
return response.json()
اختبِر الدالة من خلال إدخال مَعلمات نموذجية.
predict_purchase(age=25.0, country="United States", traffic_source="Search", gender="M")
باستخدام ADK، حدِّد وكيلًا أدناه وقدِّم الدالة predict_purchase كأداة.
from google.adk.agents import Agent
from vertexai import agent_engines
agent = Agent(
model="gemini-2.5-flash",
name='purchase_prediction_agent',
tools=[predict_purchase]
)
اختبِر الوكيل محليًا من خلال إدخال طلب بحث.
app = agent_engines.AdkApp(agent=agent)
async for event in app.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
انشر النموذج في Agent Engine.
remote_agent = client.agent_engines.create(
agent=app,
config={
"requirements": ["google-cloud-aiplatform[agent_engines,adk]"],
"staging_bucket": f"gs://{BUCKET_NAME}",
"display_name": "purchase-predictor",
"description": "Agent that predicts whether or not a user will purchase a product.",
}
)
بعد الانتهاء، يمكنك عرض النموذج الذي تم نشره في Cloud Console.
أرسِل الطلب إلى النموذج مرة أخرى. يشير هذا الآن إلى الوكيل الذي تم نشره بدلاً من الإصدار المحلي.
async for event in remote_agent.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
14. تَنظيم
احذف جميع موارد Google Cloud التي أنشأتها. يُعدّ تنفيذ أوامر التنظيف هذه من أفضل الممارسات الضرورية لتجنُّب تحمّل رسوم مستقبلية.
# Delete the deployed agent.
remote_agent.delete(force=True)
# Delete the inference server.
import subprocess
command = [
"gcloud",
"run",
"services",
"delete",
"inference-server",
"--region",
f"{REGION}",
"--quiet"
]
subprocess.run(command, capture_output=True, text=True)
# Delete the BigQuery dataset.
bigquery_client = bigquery.Client()
bigquery_client.delete_dataset(
f"{PROJECT_ID}.demo", delete_contents=True, not_found_ok=True
)
# Delete the Storage bucket.
storage_client = storage.Client()
bucket = storage_client.get_bucket(BUCKET_NAME)
bucket.delete_blobs(list(bucket.list_blobs()))
bucket.delete()
15. تهانينا!
أحسنت! في هذا الدرس التطبيقي حول الترميز، نفّذت ما يلي:
- استخدام دفاتر ملاحظات BigQuery Studio لتنفيذ سير عمل علوم البيانات
- تم إنشاء اتصال بـ Apache Spark باستخدام الحوسبة بدون خادم من Google Cloud لـ Apache Spark والمستند إلى Spark Connect.
- استخدام Lightning Engine لتسريع مهام Apache Spark بما يصل إلى 4.3 مرة
- تم تحميل البيانات من BigQuery باستخدام عملية التكامل المضمّنة بين Apache Spark وBigQuery.
- استكشاف البيانات باستخدام ميزة إنشاء الرموز البرمجية بمساعدة Gemini
- تم تنفيذ هندسة الخصائص باستخدام إطار عمل معالجة البيانات في Apache Spark.
- تدريب نموذج تصنيف وتقييمه باستخدام مكتبة تعلُّم الآلة الأصلية في Apache Spark، أي MLlib
- نشر خادم استنتاج لنموذج التصنيف باستخدام Flask و Cloud Run
- نشر وكيل لتوجيه طلب بحث إلى خادم الاستنتاج باستخدام لغة طبيعية من خلال Agent Engine وAgent Development Kit (ADK)
ما هي الخطوات التالية؟
- مزيد من المعلومات عن الحوسبة بدون خادم من Google Cloud لـ Apache Spark
- تعرَّف على كيفية ضبط Cloud Run.
- يمكنك الاطّلاع على مزيد من المعلومات حول Agent Engine.