
1. Übersicht
TheLook, ein fiktiver E-Commerce-Bekleidungshändler, speichert Daten zu Kunden, Produkten, Bestellungen, Logistik, Webereignissen und digitalen Marketingkampagnen in BigQuery. Das Unternehmen möchte das vorhandene SQL- und PySpark-Know-how des Teams nutzen, um diese Daten mit Apache Spark zu analysieren.
Um die manuelle Infrastrukturbereitstellung oder Feinabstimmung für Spark zu vermeiden, sucht TheLook nach einer Autoscaling-Lösung, mit der sich das Unternehmen auf Arbeitslasten anstatt auf die Clusterverwaltung konzentrieren kann. Außerdem möchten sie den Aufwand für die Integration von Spark und BigQuery minimieren und dabei die BigQuery Studio-Umgebung nicht verlassen.
In diesem Lab sagen Sie voraus, ob ein Nutzer einen Kauf tätigen wird. Dazu erstellen Sie mit PySpark einen Klassifikator für die logistische Regression und nutzen die native Notebook-Integration und die KI-Funktionen von BigQuery Studio, um die Daten zu untersuchen. Sie stellen dieses Modell auf einem Inferenzserver bereit und erstellen einen Agent, um das Modell mit natürlicher Sprache abzufragen.
Voraussetzungen
Für dieses Lab sollten Sie folgende Konzepte kennen:
- Grundlegende Kenntnisse der Programmierung mit SQL und Python
- Ausführen von Python-Code in einem Jupyter-Notebook
- Grundlegendes Verständnis von verteilten Rechnersystemen
Lernziele
- BigQuery Studio-Notebooks verwenden, um einen Data Science-Workflow auszuführen
- Erstellen Sie eine Verbindung zu Apache Spark mit Google Cloud Serverless for Apache Spark und Spark Connect.
- Mit Lightning Engine können Sie Apache Spark-Arbeitslasten um das bis zu 4,3‑Fache beschleunigen.
- Daten aus BigQuery laden, indem Sie die integrierte Integration zwischen Apache Spark und BigQuery verwenden.
- Daten mit Gemini-basierter Codegenerierung analysieren
- Feature Engineering mit dem Datenverarbeitungs-Framework von Apache Spark durchführen
- Ein Klassifizierungsmodell mit der nativen Bibliothek für maschinelles Lernen von Apache Spark, MLlib, trainieren und bewerten.
- Inferenzserver für das Klassifizierungsmodell mit Flask und Cloud Run bereitstellen
- Stellen Sie einen Agenten bereit, um den Inferenzserver mit natürlicher Sprache abzufragen. Verwenden Sie dazu die Agent Engine und das Agent Development Kit (ADK).
2. Verbindung zu einer Colab-Laufzeitumgebung herstellen
Google Cloud-Projekt identifizieren
Erstellen Sie ein Google Cloud-Projekt. Sie können auch ein vorhandenes Konto verwenden.
Empfohlene APIs aktivieren:
Klicken Sie hier, um die folgenden APIs zu aktivieren:
- aiplatform.googleapis.com
- bigquery.googleapis.com
- bigquerystorage.googleapis.com
- bigqueryunified.googleapis.com
- cloudaicompanion.googleapis.com
- dataproc.googleapis.com
- storage.googleapis.com
- run.googleapis.com
Auf der Benutzeroberfläche navigieren:
- Klicken Sie in der Google Cloud Console auf das Navigationsmenü > „BigQuery“.
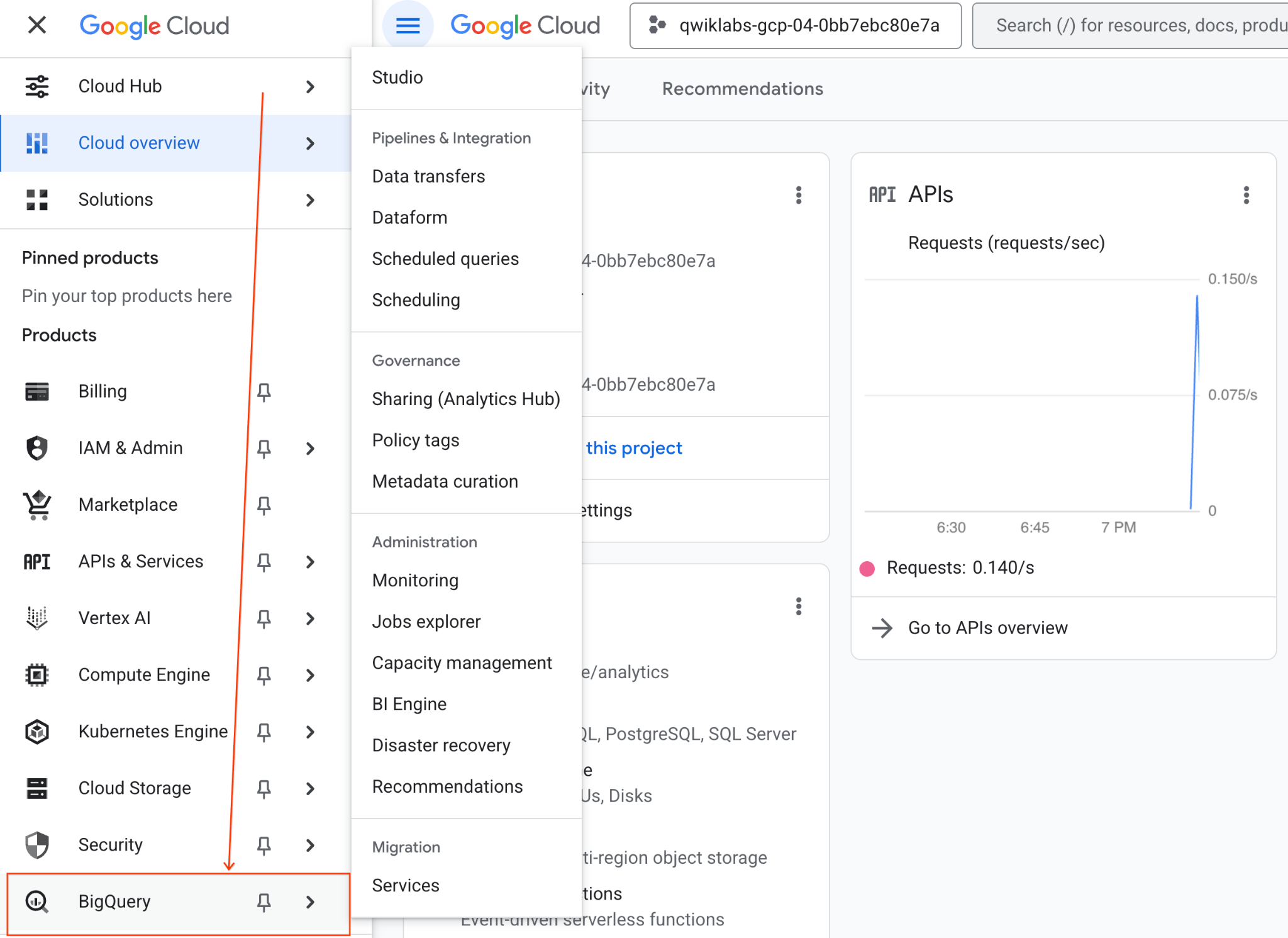
- Klicken Sie im Bereich „BigQuery Studio“ auf den Drop-down-Pfeil, bewegen Sie den Mauszeiger auf „Notebook“ und wählen Sie „Hochladen“ aus.
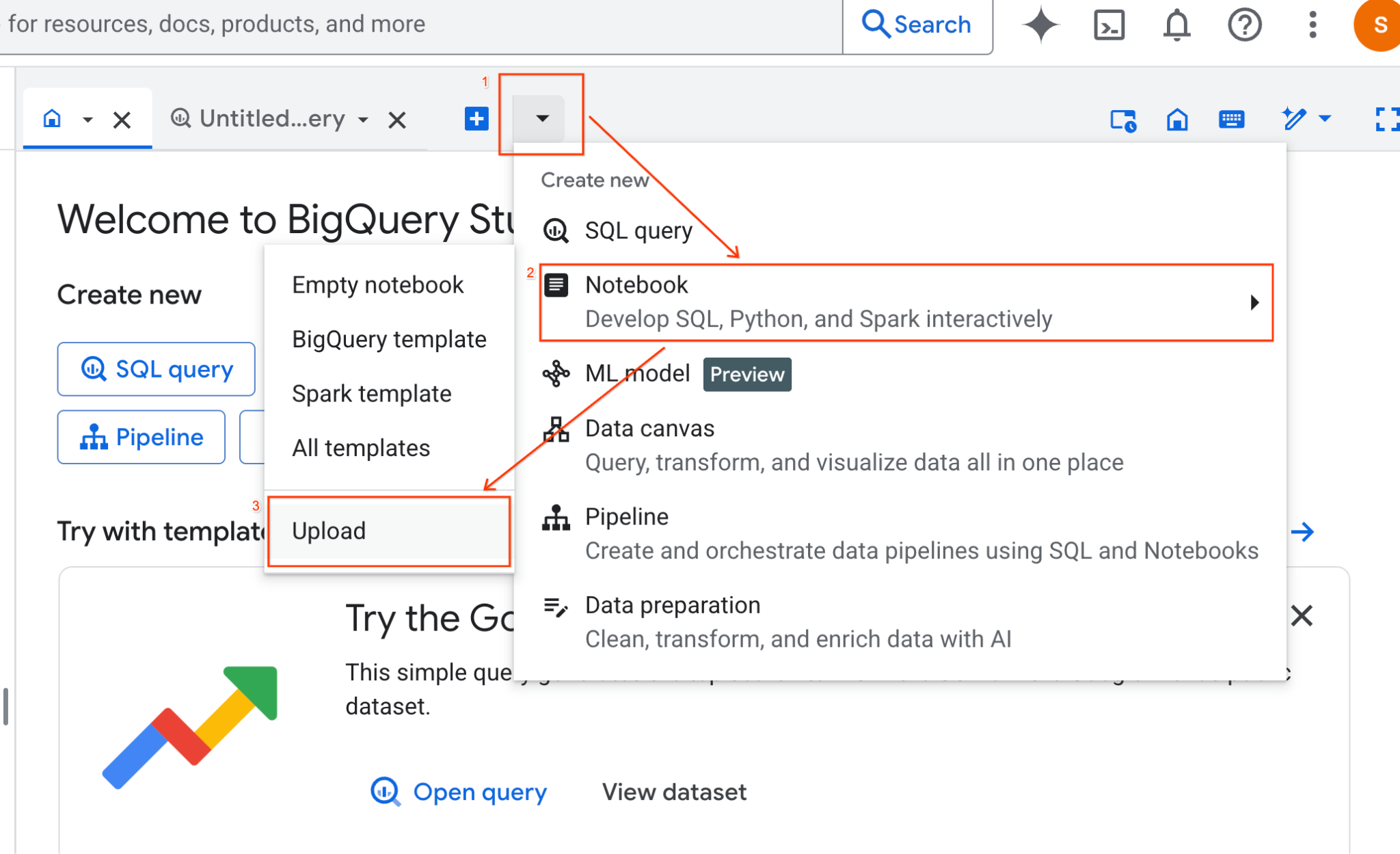
- Wählen Sie das Optionsfeld „URL“ aus und geben Sie die folgende URL ein:
https://github.com/GoogleCloudPlatform/devrel-demos/blob/main/data-analytics/dataproc-webinar/data-science/Spark_Data_Science.ipynb
- Legen Sie als Region
us-central11fest und klicken Sie auf Hochladen.
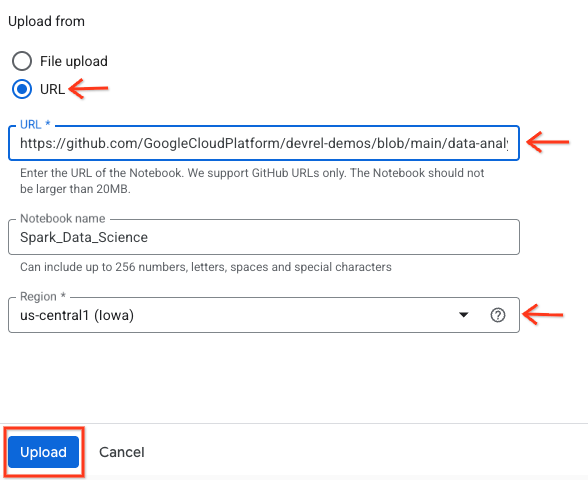
- Klicken Sie im Bereich Explorer auf den Drop-down-Pfeil mit dem Namen Ihrer Projekt-ID, um das Notebook zu öffnen. Klicken Sie dann auf das Drop-down-Menü für Notebooks. Klicken Sie auf das Notebook
Spark_Data_Science.
- Minimieren Sie das BigQuery-Navigationsmenü und das Inhaltsverzeichnis des Notebooks, um mehr Platz zu schaffen.
3. Mit einer Laufzeit verbinden und zusätzlichen Einrichtungscode ausführen
- Klicken Sie auf Verbinden. Autorisieren Sie Colab Enterprise im Pop-up-Fenster mit Ihrem E-Mail-Konto. Ihr Notebook wird automatisch mit einer Laufzeit verbunden.
- Sobald die Laufzeitumgebung eingerichtet ist, wird Folgendes angezeigt:
- Scrollen Sie im Notebook zum Abschnitt Einrichtung. Beginnen Sie hier.
4. Einrichtungscode ausführen
Konfigurieren Sie Ihre Umgebung mit den erforderlichen Python-Bibliotheken, um das Lab abzuschließen. Privaten Google-Zugriff konfigurieren. einen Cloud Storage-Bucket erstellen BigQuery-Dataset erstellen Kopieren Sie Ihre Projekt-ID in das Notebook. Wählen Sie eine Region aus. Verwenden Sie für dieses Lab die Region us-central1.
Sie können eine Codezelle ausführen, indem Sie den Mauszeiger in den Zellenblock bewegen und auf den Pfeil klicken.
# Enable APIs
import subprocess
command = [
"gcloud",
"services",
"enable",
"aiplatform.googleapis.com",
"bigquery.googleapis.com",
"bigquerystorage.googleapis.com",
"bigqueryunified.googleapis.com",
"cloudaicompanion.googleapis.com",
"dataproc.googleapis.com",
"run.googleapis.com",
"storage.googleapis.com"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Configure a PROJECT_ID and REGION
PROJECT_ID = "<YOUR_PROJECT_ID>"
REGION = "<YOUR_REGION>"
# Enable Private Google Access
import subprocess
command = [
"gcloud",
"compute",
"networks",
"subnets",
"update",
"default",
f"--region={REGION}",
"--enable-private-ip-google-access"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Create a Cloud Storage Bucket
from google.cloud import storage
from google.cloud.exceptions import NotFound
BUCKET_NAME = f"{PROJECT_ID}-demo"
storage_client = storage.Client(project=PROJECT_ID)
try:
bucket = storage_client.get_bucket(BUCKET_NAME)
print(f"Bucket {BUCKET_NAME} already exists.")
except NotFound:
bucket = storage_client.create_bucket(BUCKET_NAME, location=REGION)
print(f"Bucket {BUCKET_NAME} created.")
# Create a BigQuery dataset.
from google.cloud import bigquery
DATASET_ID = f"{PROJECT_ID}.demo"
client = bigquery.Client()
dataset = bigquery.Dataset(DATASET_ID)
dataset.location = REGION
dataset = client.create_dataset(dataset, exists_ok=True)
5. Verbindung zu Google Cloud Serverless for Apache Spark herstellen
Mit Spark Connect stellen Sie eine Verbindung zu einer serverlosen Spark-Sitzung her, um interaktive Spark-Jobs auszuführen. Sie konfigurieren Ihre Laufzeit mit der Lightning Engine für eine erweiterte Spark-Leistung. Lightning Engine beschleunigt Arbeitslasten mit Apache Gluten und Velox.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
session.runtime_config.version = "3.0"
# You can optionally configure Spark properties as well. See https://cloud.google.com/dataproc-serverless/docs/concepts/properties.
session.runtime_config.properties = {
"dataproc.runtime": "premium",
"spark.dataproc.engine": "lightningEngine",
}
# To avoid going over quota in this demo, cap the max number of Spark workers.
session.runtime_config.properties = {
"spark.dynamicAllocation.maxExecutors": "4"
}
spark = (
DataprocSparkSession.builder
.appName("CustomSparkSession")
.dataprocSessionConfig(session)
.getOrCreate()
)
6. Daten mit Gemini laden und analysieren
In diesem Abschnitt durchlaufen Sie den ersten wichtigen Schritt in jedem Data-Science-Projekt: die Vorbereitung Ihrer Daten. Zuerst laden Sie Daten aus BigQuery in einen Apache Spark-DataFrame.
# Load the tables
order_items = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.order_items").load()
users = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.users").load()
# Register temp tables
users.createOrReplaceTempView("users")
order_items.createOrReplaceTempView("order_items")
# Verify temp tables
spark.sql("SELECT * FROM order_items LIMIT 10").show()
Anschließend verwenden Sie Gemini, um PySpark-Code zu generieren, mit dem Sie die Daten untersuchen und besser verstehen können.
Prompt 1: Untersuche die Tabelle „users“ mit PySpark und zeige die ersten 10 Zeilen an.
# prompt: Using PySpark, explore the users table and show the first 10 rows.
users.show(10)
Prompt 2: Untersuche die Tabelle „order_items“ mit PySpark und zeige die ersten 10 Zeilen an.
# prompt: Using PySpark, explore the order_items table and show the first 10 rows.
order_items.show(10)
Prompt 3: Zeigen Sie mit PySpark die fünf häufigsten Länder in der Tabelle „users“ an. Land und Anzahl der Nutzer aus jedem Land anzeigen
# prompt: Using PySpark, show the top 5 most frequent countries in the users table. Display the country and the number of users from each country.
from pyspark.sql.functions import col, count
users.groupBy("country").agg(count("*").alias("user_count")).orderBy(col("user_count").desc()).limit(5).show()
Prompt 4: Ermitteln Sie mit PySpark den durchschnittlichen Verkaufspreis von Artikeln in der Tabelle „order_items“.
# prompt: Using PySpark, find the average sale price of items in the order_items table.
from pyspark.sql import functions as F
average_sale_price = order_items.agg(F.avg("sale_price").alias("average_sale_price"))
average_sale_price.show()
Prompt 5: Generiere anhand der Tabelle „users“ Code, um Land und Traffic-Quelle mit einer geeigneten Plotting-Bibliothek darzustellen.
# prompt: Using the table "users", generate code to plot country vs traffic source using a suitable plotting library.
sql = """
SELECT
country,
traffic_source
FROM
`bigquery-public-data.thelook_ecommerce.users`
WHERE country IS NOT NULL AND traffic_source IS NOT NULL
"""
project_id = "iceberg-summit-2025"
df = pandas_gbq.read_gbq(sql, project_id=project_id, dialect="standard")
import matplotlib.pyplot as plt
import seaborn as sns
# Group by country and traffic_source and count occurrences
df_grouped = df.groupby(['country', 'traffic_source']).size().reset_index(name='count')
# Create a pivot table for easier plotting
pivot_table = df_grouped.pivot(index='country', columns='traffic_source', values='count').fillna(0)
# Plotting
plt.figure(figsize=(15, 8))
pivot_table.plot(kind='bar', stacked=True, figsize=(15, 8))
plt.title('Traffic Source Distribution by Country')
plt.xlabel('Country')
plt.ylabel('Number of Users')
plt.xticks(rotation=90)
plt.legend(title='Traffic Source')
plt.tight_layout()
plt.show()
Prompt 6:Erstelle ein Histogramm mit der Verteilung von „Alter“, „Land“, „Geschlecht“ und „traffic_source“.
# prompt: Create a histogram showing the distribution of "age", "country", "gender", "traffic_source".
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for visualization
users_pd = users.toPandas()
# Create histograms for 'age', 'country', 'gender', 'traffic_source'
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('Distribution of User Attributes')
# Age distribution
axes[0, 0].hist(users_pd['age'].dropna(), bins=20, edgecolor='black')
axes[0, 0].set_title('Age Distribution')
axes[0, 0].set_xlabel('Age')
axes[0, 0].set_ylabel('Number of Users')
# Country distribution
users_pd['country'].value_counts().head(10).plot(kind='bar', ax=axes[0, 1])
axes[0, 1].set_title('Top 10 Countries Distribution')
axes[0, 1].set_xlabel('Country')
axes[0, 1].set_ylabel('Number of Users')
axes[0, 1].tick_params(axis='x', rotation=45)
# Gender distribution
users_pd['gender'].value_counts().plot(kind='bar', ax=axes[1, 0])
axes[1, 0].set_title('Gender Distribution')
axes[1, 0].set_xlabel('Gender')
axes[1, 0].set_ylabel('Number of Users')
axes[1, 0].tick_params(axis='x', rotation=0)
# Traffic Source distribution
users_pd['traffic_source'].value_counts().head(10).plot(kind='bar', ax=axes[1, 1])
axes[1, 1].set_title('Top 10 Traffic Source Distribution')
axes[1, 1].set_xlabel('Traffic Source')
axes[1, 1].set_ylabel('Number of Users')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
7. Datenvorbereitung und Feature Engineering
Als Nächstes führen Sie Feature Engineering für die Daten durch. Wählen Sie die entsprechenden Spalten aus, wandeln Sie die Daten in geeignetere Datentypen um und legen Sie eine Labelspalte fest.
features = spark.sql("""
SELECT
CAST(u.age AS DOUBLE) AS age,
CAST(hash(u.country) AS BIGINT) * 1.0 AS country_hash,
CAST(hash(u.gender) AS BIGINT) * 1.0 AS gender_hash,
CAST(hash(u.traffic_source) AS BIGINT) * 1.0 AS traffic_source_hash,
CASE WHEN COUNT(oi.id) > 0 THEN 1 ELSE 0 END AS label -- Changed label generation to count order items
FROM users AS u
LEFT JOIN order_items AS oi
ON u.id = oi.user_id
GROUP BY u.id, u.age, u.country, u.gender, u.traffic_source
""")
features.show()
8. Logistisches Regressionsmodell trainieren
Mit MLlib trainieren Sie ein logistisches Regressionsmodell. Zuerst verwenden Sie ein VectorAssembler, um die Daten in ein Vektorformat zu konvertieren. Anschließend wird die Spalte „Features“ von StandardScaler skaliert, um die Leistung zu verbessern. Anschließend erstellen Sie einen Verweis auf ein LogisticRegression-Modell und definieren Hyperparameter. Sie fassen diese Schritte in einem Pipeline-Objekt zusammen, trainieren das Modell mit der Funktion fit() und transformieren die Daten mit der Funktion transform().
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.pipeline import Pipeline
from pyspark.ml.functions import array_to_vector
#Split Train and Test Data (80:20)
train_data, test_data = features.randomSplit([0.8, 0.2], seed=42)
# Initialize VectorAssembler
assembler = VectorAssembler(
inputCols=["age", "country_hash", "gender_hash", "traffic_source_hash"],
outputCol="assembled_features"
)
# Initialize StandardScaler
scaler = StandardScaler(inputCol="assembled_features", outputCol="scaled_features")
# Initialize Logistic Regression model
lr = LogisticRegression(
maxIter=100,
regParam=0.2,
threshold=0.8,
featuresCol="scaled_features",
labelCol="label"
)
# Define pipeline
pipeline = Pipeline(stages=[assembler, scaler, lr])
# Fit the model
pipeline_model = pipeline.fit(train_data)
# Transform the dataset using the trained model
transformed_dataset = pipeline_model.transform(test_data)
transformed_dataset.show()
9. Modellbewertung
Werten Sie das neu transformierte Dataset aus. Generieren Sie den Messwert Fläche unter der Kurve (Area Under the Curve, AUC).
# Model evaluation
eva = BinaryClassificationEvaluator(metricName="areaUnderPR")
aucPR = eva.evaluate(transformed_dataset)
print(f"AUC PR: {aucPR}")
Verwenden Sie dann Gemini, um PySpark-Code zum Visualisieren der Modellausgabe zu generieren.
Prompt 1:Generiere Code zum Erstellen eines Diagramms der Precision-/Recall-Kurve (PR). Berechnen Sie Precision und Recall anhand der Vorhersagen des Modells und stellen Sie die PR-Kurve mit einer geeigneten Plotting-Bibliothek dar.
# prompt: Generate code to plot the Precision-Recall (PR) curve. Calculate precision and recall from the model's predictions and display the PR curve using a suitable plotting library.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, auc
# Extract predictions and labels
predictions = transformed_dataset.select("prediction", "label").toPandas()
# Calculate precision and recall
precision, recall, _ = precision_recall_curve(predictions["label"], predictions["prediction"])
# Calculate AUC-PR
pr_auc = auc(recall, precision)
# Plot the PR curve
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, color='blue', lw=2, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
Prompt 2:Generieren Sie Code zum Erstellen einer Visualisierung der Konfusionsmatrix. Berechnen Sie die Wahrheitsmatrix anhand der Vorhersagen des Modells und stellen Sie sie als Heatmap oder Tabelle mit der Anzahl der richtig positiven (TP), richtig negativen (TN), falsch positiven (FP) und falsch negativen (FN) Ergebnisse dar.
# prompt: Generate code to create a confusion matrix visualization. Calculate the confusion matrix from the model's predictions and display it as a heat map or a table with counts of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Extract predictions and labels
predictions_and_labels = transformed_dataset.select("prediction", "label").toPandas()
# Calculate the confusion matrix
cm = confusion_matrix(predictions_and_labels["label"], predictions_and_labels["prediction"])
# Create a DataFrame for better visualization
cm_df = pd.DataFrame(cm,
index=['Actual Negative', 'Actual Positive'],
columns=['Predicted Negative', 'Predicted Positive'])
# Display the confusion matrix as a table
print("Confusion Matrix:")
print(cm_df)
# Display the confusion matrix as a heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(cm_df, annot=True, fmt='d', cmap='Blues', cbar=False, linewidths=.5)
plt.title('Confusion Matrix')
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
plt.show()
# Calculate and display TP, TN, FP, FN
TN, FP, FN, TP = cm.ravel()
print(f"
True Positives (TP): {TP}")
print(f"True Negatives (TN): {TN}")
print(f"False Positives (FP): {FP}")
print(f"False Negatives (FN): {FN}")
10. Vorhersagen in BigQuery schreiben
Mit Gemini können Sie Code generieren, um Ihre Vorhersagen in eine neue Tabelle in Ihrem BigQuery-Dataset zu schreiben.
Aufforderung:Schreiben Sie das transformierte Dataset mit Spark in BigQuery.
# prompt: Using Spark, write the transformed dataset to BigQuery.
transformed_dataset.write.format("bigquery").option("table", f"{PROJECT_ID}.demo.predictions").mode("overwrite").save()
11. Modell in Cloud Storage speichern
Speichern Sie Ihr Modell mit den nativen Funktionen von MLlib in Cloud Storage. Der Inferenzserver lädt das Modell von hier.
MODEL_PATH = "models/prediction_model"
pipeline_model.write().overwrite().save(f"gs://{BUCKET_NAME}/{MODEL_PATH}")
12. Inferenzserver erstellen
Cloud Run ist ein flexibles Tool zum Ausführen serverloser Webanwendungen. Es verwendet Docker-Container, um Nutzern maximale Anpassungsmöglichkeiten zu bieten. In diesem Lab ist ein Dockerfile für die Ausführung einer Flask-App konfiguriert, die PySpark unterstützt. Dieser Container wird in Cloud Run ausgeführt, um die Inferenz für Eingabedaten durchzuführen. Den Code dafür finden Sie hier.
Klonen Sie das Repository mit dem Code des Inferenzservers.
!git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
Rufen Sie das Dockerfile auf.
FROM python:3.12-slim
# Install OpenJDK-21 (Required for Spark)
RUN apt-get update && \
apt-get install -y openjdk-21-jre-headless procps && \
rm -rf /var/lib/apt/lists/*
ENV JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64
ENV PORT=8080
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "--workers", "1", "--threads", "8", "--timeout", "0", "main:app"]
Sehen Sie sich den Python-Code für den Server an.
import os
import json
import logging
from flask import Flask, request, jsonify
from google.cloud import storage
from pyspark.ml import PipelineModel
from pyspark.sql import SparkSession
from pyspark.sql.functions import hash, col
# Configure basic logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- Initialization: Spark and Model Loading ---
GCS_BUCKET = os.environ.get("GCS_BUCKET")
GCS_MODEL_PATH = os.environ.get("GCS_MODEL_PATH")
LOCAL_MODEL_PATH = "/tmp/model"
try:
spark = SparkSession.builder \
.appName("CloudRunSparkService") \
.master("local[*]") \
.getOrCreate()
logging.info("Spark Session successfully initialized.")
except Exception as e:
logging.error(f"Failed to initialize Spark Session: {e}")
raise
def download_directory(bucket_name, prefix, local_path):
"""Downloads a directory from GCS to local filesystem."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blobs = list(bucket.list_blobs(prefix=prefix))
if len(blobs) == 0:
logging.error(f"No files found in GCS bucket {bucket_name} at prefix {prefix}")
return
for blob in blobs:
if blob.name.endswith("/"): continue # Skip directories
# Structure local paths
relative_path = os.path.relpath(blob.name, prefix)
local_file_path = os.path.join(local_path, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
blob.download_to_filename(local_file_path)
print(f"Model downloaded to {local_path}")
# Load model
def load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH):
"""Download and load model on startup to avoid latency per request."""
global MODEL
if not os.path.exists(LOCAL_MODEL_PATH):
download_directory(GCS_BUCKET, GCS_MODEL_PATH, LOCAL_MODEL_PATH)
logging.info(f"Loading PySpark model from {GCS_MODEL_PATH}")
# Load the Spark ML model
try:
MODEL = PipelineModel.load(LOCAL_MODEL_PATH)
logging.info("Spark model loaded successfully.")
except Exception as e:
logging.error(f"Failed to load model: {e}")
raise
# Load Model on Startup
load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH)
# --- Flask Application Setup ---
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
"""
Handles incoming POST requests for inference.
Expects JSON data that can be converted into a Spark DataFrame.
"""
if MODEL is None:
return jsonify({"error": "Model failed to load at startup."}), 500
try:
# 1. Get data from the request
data = request.get_json()
# 2. Check length of list
data_len = len(data)
cap = 100
if data_len > cap:
return jsonify({"error": f"Too many records. Count: {data_len}, Max: {cap}"}), 400
# 2. Create Spark DataFrame
df = spark.createDataFrame(data)
# 3. Transform data
input_df = df.select(
col("age").cast("DOUBLE").alias("age"),
(hash(col("country")).cast("BIGINT") * 1.0).alias("country_hash"),
(hash(col("gender")).cast("BIGINT") * 1.0).alias("gender_hash"),
(hash(col("traffic_source")).cast("BIGINT") * 1.0).alias("traffic_source_hash")
)
# 3. Perform Inference
predictions_df = MODEL.transform(input_df)
# 4. Prepare results (collect and serialize)
results = [p.prediction for p in predictions_df.select("prediction").collect()]
# 5. Return JSON response
return jsonify({"predictions": results})
except Exception as e:
logging.error(f"An error occurred during prediction: {e}")
#return jsonify({"error": str(e)}), 500
raise e
# Gunicorn entry point uses 'app' from this file
if __name__ == '__main__':
# Local testing only: Cloud Run uses Gunicorn/CMD command
app.run(host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
Stellen Sie den Inferenzserver bereit.
import subprocess
command = [
"gcloud",
"run",
"deploy",
"inference-server",
"--source",
"/content/devrel-demos/data-analytics/dataproc-webinar/data-science/inference-server",
"--region",
f"{REGION}",
"--port",
"8080",
"--memory",
"2Gi",
"--allow-unauthenticated",
"--set-env-vars",
f"GCS_BUCKET={BUCKET_NAME},GCS_MODEL_PATH={MODEL_PATH}",
"--startup-probe",
"tcpSocket.port=8080,initialDelaySeconds=240,failureThreshold=3,timeoutSeconds=240,periodSeconds=240"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
Kopieren Sie die URL des Inferenzservers aus der Ausgabe in eine neue Variable. Es ähnelt https://inference-server-123456789.us-central1.run.app..
INFERENCE_SERVER_URL = "<YOUR_SERVER_URL>"
Inferenzserver testen
import requests
age = "25.0"
country = "United States"
traffic_source = "Search"
gender = "F"
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
print(response.json())
Die Ausgabe sollte 1.0 oder 0.0 sein.
{'predictions': [1.0]}
13. Agent konfigurieren
Mit Agent Engine können Sie einen Agenten erstellen, der Inferenz durchführen kann. Agent Engine ist Teil der Vertex AI-Plattform, einer Reihe von Diensten, mit denen Entwickler KI-Agenten in der Produktion bereitstellen, verwalten und skalieren können. Es bietet viele Tools, darunter die Möglichkeit, Agents, Sitzungskontexte und die Codeausführung zu bewerten. Es unterstützt viele beliebte agentische Frameworks, darunter das Agent Development Kit (ADK). Das ADK ist ein Open-Source-Framework, das zwar für die Verwendung mit Gemini und dem Google-Ökosystem entwickelt und optimiert wurde, aber modellunabhängig ist. Es soll die Entwicklung von Agenten eher wie die Softwareentwicklung gestalten.
Vertex AI-Client initialisieren
import vertexai
from vertexai import agent_engines # For the prebuilt templates
client = vertexai.Client( # For service interactions via client.agent_engines
project=f"{PROJECT_ID}",
location=f"{REGION}",
)
Definieren Sie eine Funktion zum Abfragen des bereitgestellten Modells.
def predict_purchase(
age: str = "25.0",
country: str = "United States",
traffic_source: str = "Search",
gender: str = "M",
):
"""Predicts whether or not a user will purchase a product.
Args:
age: The age of the user.
country: The country of the user. One of: "China", "Poland", "Germany", "United States", "Spain", "United Kingdom", "España", "Japan", "Brasil", "Colombia", "Belgium", "South Korea", "Austria", "France", "Australia".
Traffic_source: The source of the user's traffic. One of: "Display", "Email", "Search", "Organic", "Facebook".
gender: The gender of the user. One of: "M" or "F".
Returns:
True if the model output is 1.0, False otherwise.
"""
import requests
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
return response.json()
Testen Sie die Funktion, indem Sie Beispielparameter übergeben.
predict_purchase(age=25.0, country="United States", traffic_source="Search", gender="M")
Definieren Sie unten einen KI-Agenten mit dem ADK und stellen Sie die Funktion predict_purchase als Tool bereit.
from google.adk.agents import Agent
from vertexai import agent_engines
agent = Agent(
model="gemini-2.5-flash",
name='purchase_prediction_agent',
tools=[predict_purchase]
)
Testen Sie den Agenten lokal, indem Sie eine Anfrage übergeben.
app = agent_engines.AdkApp(agent=agent)
async for event in app.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
Stellen Sie das Modell in Agent Engine bereit.
remote_agent = client.agent_engines.create(
agent=app,
config={
"requirements": ["google-cloud-aiplatform[agent_engines,adk]"],
"staging_bucket": f"gs://{BUCKET_NAME}",
"display_name": "purchase-predictor",
"description": "Agent that predicts whether or not a user will purchase a product.",
}
)
Rufen Sie das bereitgestellte Modell in der Cloud Console auf.
Stellen Sie dem Modell noch einmal eine Frage. Sie verweist jetzt auf den bereitgestellten Agenten anstelle der lokalen Version.
async for event in remote_agent.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
14. Bereinigen
Löschen Sie alle von Ihnen erstellten Google Cloud-Ressourcen. Das Ausführen solcher Bereinigungsbefehle ist eine wichtige Best Practice, um zukünftige Gebühren zu vermeiden.
# Delete the deployed agent.
remote_agent.delete(force=True)
# Delete the inference server.
import subprocess
command = [
"gcloud",
"run",
"services",
"delete",
"inference-server",
"--region",
f"{REGION}",
"--quiet"
]
subprocess.run(command, capture_output=True, text=True)
# Delete the BigQuery dataset.
bigquery_client = bigquery.Client()
bigquery_client.delete_dataset(
f"{PROJECT_ID}.demo", delete_contents=True, not_found_ok=True
)
# Delete the Storage bucket.
storage_client = storage.Client()
bucket = storage_client.get_bucket(BUCKET_NAME)
bucket.delete_blobs(list(bucket.list_blobs()))
bucket.delete()
15. Glückwunsch!
Geschafft! In diesem Codelab haben Sie Folgendes getan:
- BigQuery Studio-Notebooks zum Ausführen eines Data Science-Workflows verwendet
- Sie haben eine Verbindung zu Apache Spark mit Google Cloud Serverless for Apache Spark erstellt, die auf Spark Connect basiert.
- Mit der Lightning Engine können Sie Apache Spark-Arbeitslasten um das bis zu 4,3‑Fache beschleunigen.
- Daten aus BigQuery mithilfe der integrierten Integration zwischen Apache Spark und BigQuery geladen.
- Daten mit Gemini-Unterstützung analysiert.
- Feature Engineering mit dem Datenverarbeitungs-Framework von Apache Spark durchgeführt.
- Sie haben ein Klassifizierungsmodell mit der nativen Bibliothek für maschinelles Lernen von Apache Spark, MLlib, trainiert und ausgewertet.
- Sie haben einen Inferenzserver für das Klassifizierungsmodell mit Flask und Cloud Run bereitgestellt.
- Sie haben einen Agenten bereitgestellt, um den Inferenzserver mit natürlicher Sprache abzufragen. Dazu haben Sie die Agent Engine und das Agent Development Kit (ADK) verwendet.