
۱. مرور کلی
TheLook، یک خردهفروش لباس فرضی تجارت الکترونیک، دادههای مربوط به مشتریان، محصولات، سفارشات، تدارکات، رویدادهای وب و کمپینهای بازاریابی دیجیتال را در BigQuery ذخیره میکند. این شرکت میخواهد از تخصص موجود تیم SQL و PySpark برای تجزیه و تحلیل این دادهها با استفاده از Apache Spark بهره ببرد.
برای جلوگیری از آمادهسازی یا تنظیم دستی زیرساخت برای Spark، TheLook به دنبال یک راهکار مقیاسپذیری خودکار است که به آنها اجازه میدهد به جای مدیریت خوشه، بر حجم کار تمرکز کنند. علاوه بر این، آنها میخواهند تلاش لازم برای ادغام Spark و BigQuery را به حداقل برسانند و در عین حال در محیط BigQuery Studio باقی بمانند.
در این آزمایش، شما با ساخت یک طبقهبندیکننده رگرسیون لجستیک با استفاده از PySpark و بهرهگیری از یکپارچهسازی نوتبوک بومی BigQuery Studio و ویژگیهای هوش مصنوعی برای کاوش دادهها، پیشبینی میکنید که آیا یک کاربر خریدی انجام خواهد داد یا خیر. شما این مدل را در یک سرور استنتاج مستقر میکنید و یک عامل برای پرسوجو از مدل با استفاده از زبان طبیعی ایجاد میکنید.
پیشنیازها
قبل از شروع این آزمایشگاه، باید با موارد زیر آشنا باشید:
- برنامهنویسی مقدماتی SQL و پایتون.
- اجرای کد پایتون در نوتبوک ژوپیتر
- درک اولیه از محاسبات توزیعشده
اهداف
- از دفترچههای BigQuery Studio برای اجرای گردش کار علوم داده استفاده کنید.
- با استفاده از Google Cloud Serverless برای Apache Spark و پشتیبانی شده توسط Spark Connect، یک اتصال به Apache Spark ایجاد کنید.
- از موتور لایتنینگ برای تسریع حجم کار آپاچی اسپارک تا ۴.۳ برابر استفاده کنید.
- با استفاده از یکپارچهسازی داخلی بین آپاچی اسپارک و بیگکوئری، دادهها را از بیگکوئری بارگذاری کنید.
- دادهها را با استفاده از تولید کد با کمک Gemini کاوش کنید.
- مهندسی ویژگیها را با استفاده از چارچوب پردازش داده آپاچی اسپارک انجام دهید.
- با استفاده از کتابخانه یادگیری ماشین بومی Apache Spark، MLlib ، یک مدل طبقهبندی را آموزش داده و ارزیابی کنید.
- استقرار یک سرور استنتاج برای مدل طبقهبندی با استفاده از Flask و Cloud Run
- یک عامل را برای پرسوجو از سرور استنتاج با استفاده از زبان طبیعی با استفاده از موتور عامل و کیت توسعه عامل (ADK) مستقر کنید.
۲. به یک محیط زمان اجرای Colab متصل شوید
شناسایی یک پروژه ابری گوگل
یک پروژه Google Cloud ایجاد کنید . میتوانید از یک پروژه موجود استفاده کنید.
فعال کردن API های پیشنهادی:
برای فعال کردن API های زیر اینجا کلیک کنید:
- aiplatform.googleapis.com
- bigquery.googleapis.com
- bigquerystorage.googleapis.com
- bigqueryunified.googleapis.com
- cloudaicompanion.googleapis.com
- dataproc.googleapis.com
- storage.googleapis.com
- run.googleapis.com
پیمایش رابط کاربری:
- در کنسول گوگل کلود، به منوی ناوبری > BigQuery بروید.
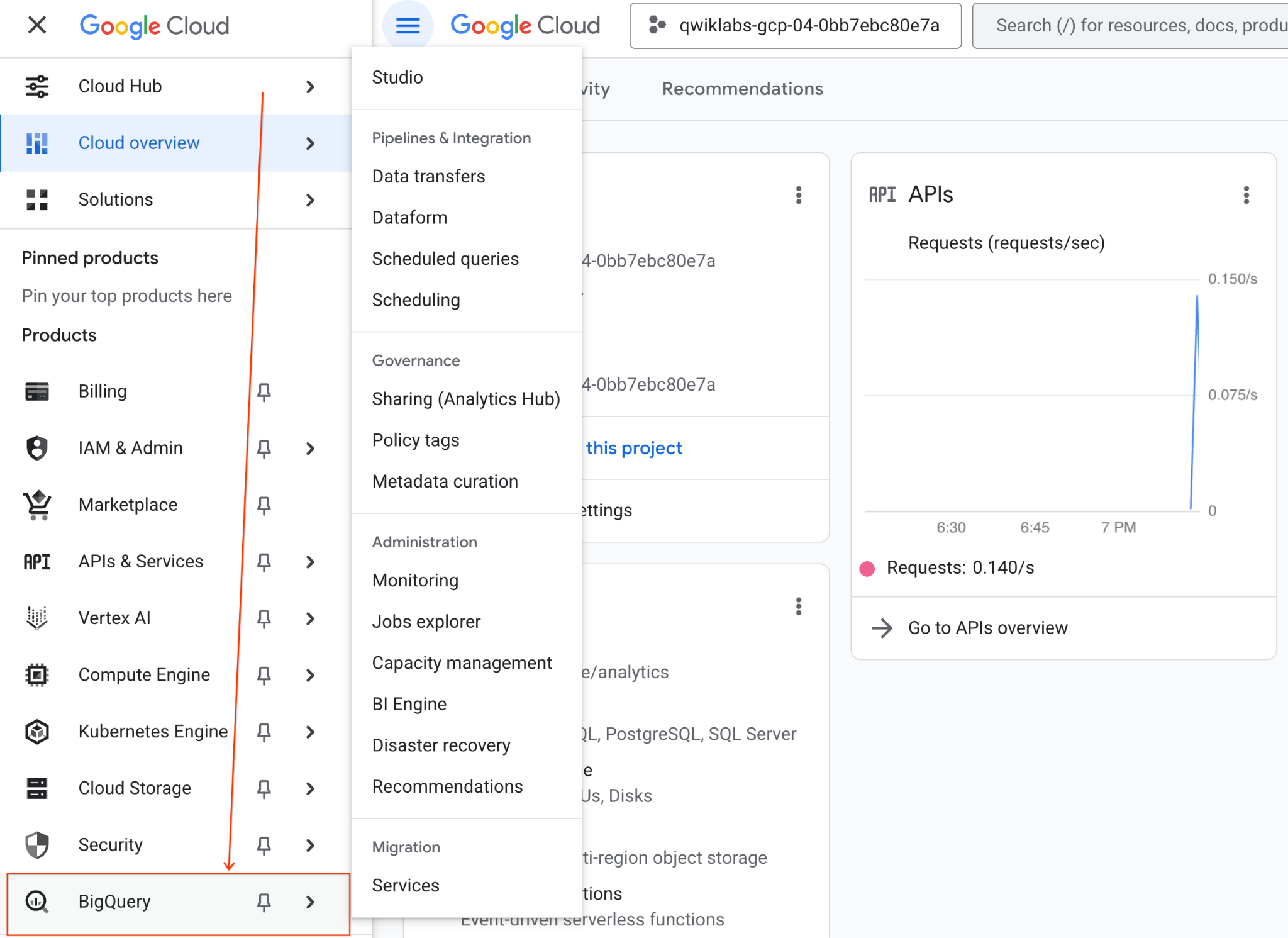
- در پنل BigQuery Studio، روی دکمهی فلش کشویی کلیک کنید، موس را روی Notebook ببرید و سپس Upload را انتخاب کنید.
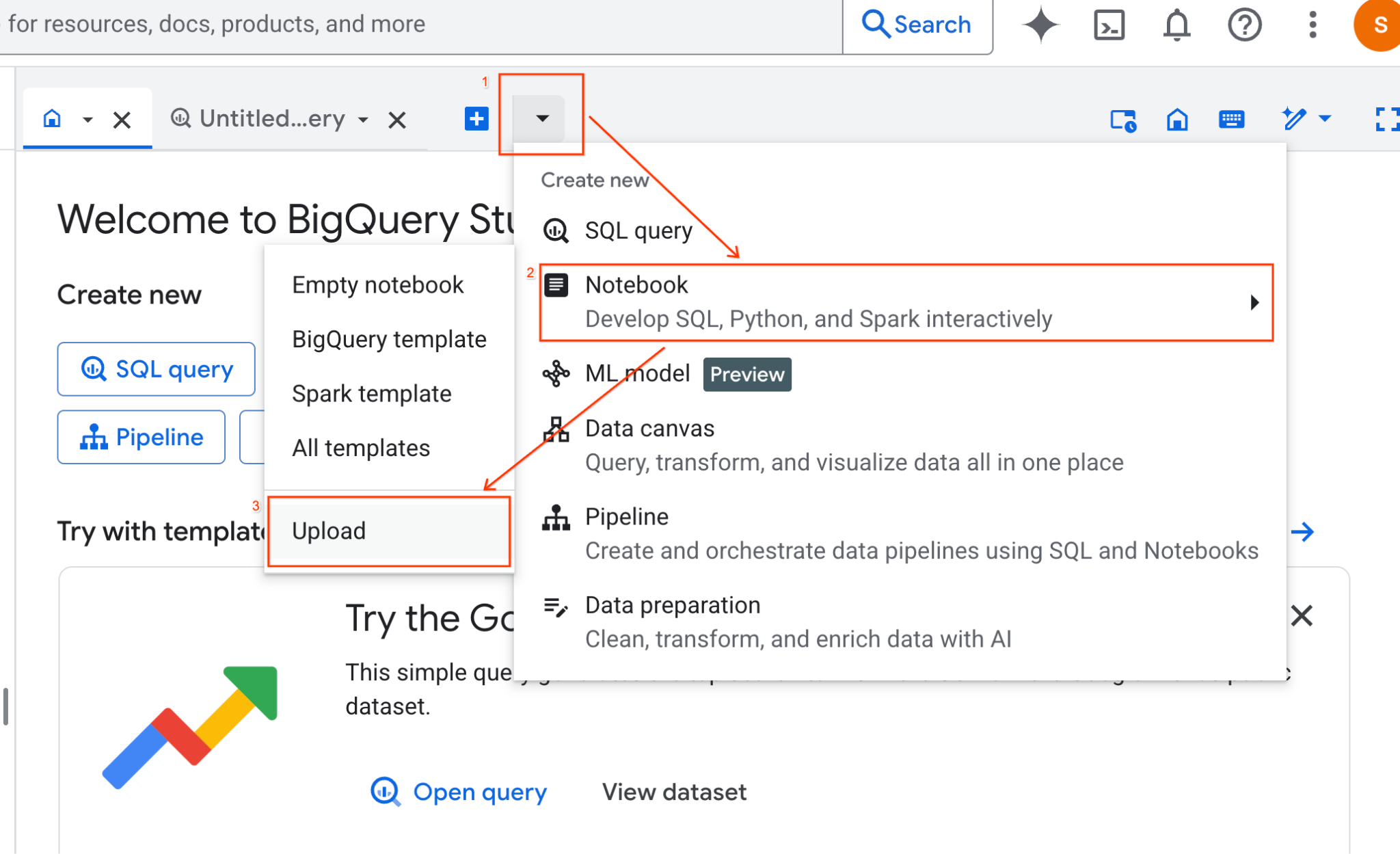
- دکمه رادیویی URL را انتخاب کنید و URL زیر را وارد کنید:
https://github.com/GoogleCloudPlatform/devrel-demos/blob/main/data-analytics/dataproc-webinar/data-science/Spark_Data_Science.ipynb
- منطقه را روی
us-central11تنظیم کنید و روی آپلود کلیک کنید.
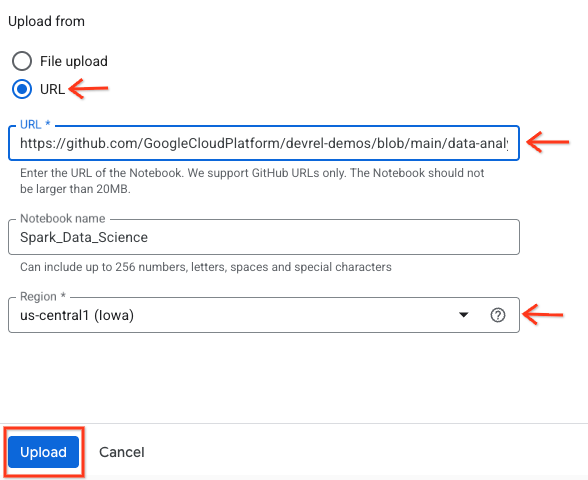
- برای باز کردن دفترچه یادداشت، روی فلش کشویی که در پنل Explorer با نام project-id شما نمایش داده میشود، کلیک کنید. سپس روی منوی کشویی Notebooks کلیک کنید. روی دفترچه یادداشت
Spark_Data_Scienceکلیک کنید.
- برای فضای بیشتر، منوی ناوبری BigQuery و فهرست مطالب دفترچه یادداشت را جمع کنید.
۳. به یک زمان اجرا متصل شوید و کد راهاندازی اضافی را اجرا کنید
- روی اتصال کلیک کنید. در پنجره بازشو، Colab Enterprise را با حساب ایمیل خود مجاز کنید. نوتبوک شما بهطور خودکار به یک زمان اجرا متصل میشود.
- پس از مشخص شدن زمان اجرا، تصویر زیر را مشاهده خواهید کرد:
- در داخل دفترچه یادداشت، به بخش تنظیمات بروید. از اینجا شروع کنید.
۴. اجرای کد راهاندازی
محیط خود را با کتابخانههای پایتون لازم برای تکمیل آزمایش پیکربندی کنید. دسترسی خصوصی به گوگل (Private Google Access) را پیکربندی کنید . یک مخزن ذخیرهسازی (Storage Bucket) ایجاد کنید. یک مجموعه داده BigQuery ایجاد کنید. شناسه پروژه خود را در دفترچه یادداشت کپی کنید. یک منطقه انتخاب کنید. برای این آزمایش، از منطقه us-central1 استفاده کنید.
شما میتوانید با نگه داشتن مکاننما درون بلوک سلول و کلیک روی فلش، یک سلول کد را اجرا کنید.
# Enable APIs
import subprocess
command = [
"gcloud",
"services",
"enable",
"aiplatform.googleapis.com",
"bigquery.googleapis.com",
"bigquerystorage.googleapis.com",
"bigqueryunified.googleapis.com",
"cloudaicompanion.googleapis.com",
"dataproc.googleapis.com",
"run.googleapis.com",
"storage.googleapis.com"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Configure a PROJECT_ID and REGION
PROJECT_ID = "<YOUR_PROJECT_ID>"
REGION = "<YOUR_REGION>"
# Enable Private Google Access
import subprocess
command = [
"gcloud",
"compute",
"networks",
"subnets",
"update",
"default",
f"--region={REGION}",
"--enable-private-ip-google-access"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Create a Cloud Storage Bucket
from google.cloud import storage
from google.cloud.exceptions import NotFound
BUCKET_NAME = f"{PROJECT_ID}-demo"
storage_client = storage.Client(project=PROJECT_ID)
try:
bucket = storage_client.get_bucket(BUCKET_NAME)
print(f"Bucket {BUCKET_NAME} already exists.")
except NotFound:
bucket = storage_client.create_bucket(BUCKET_NAME, location=REGION)
print(f"Bucket {BUCKET_NAME} created.")
# Create a BigQuery dataset.
from google.cloud import bigquery
DATASET_ID = f"{PROJECT_ID}.demo"
client = bigquery.Client()
dataset = bigquery.Dataset(DATASET_ID)
dataset.location = REGION
dataset = client.create_dataset(dataset, exists_ok=True)
۵. برای آپاچی اسپارک، یک اتصال به Google Cloud Serverless ایجاد کنید.
با استفاده از Spark Connect، شما به یک جلسه Spark بدون سرور متصل میشوید تا کارهای Spark تعاملی را اجرا کنید. شما زمان اجرای خود را با Lightning Engine برای عملکرد پیشرفته Spark پیکربندی میکنید. Lightning Engine با شتابدهی به بارهای کاری با استفاده از Apache Gluten و Velox کار میکند.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
session.runtime_config.version = "3.0"
# You can optionally configure Spark properties as well. See https://cloud.google.com/dataproc-serverless/docs/concepts/properties.
session.runtime_config.properties = {
"dataproc.runtime": "premium",
"spark.dataproc.engine": "lightningEngine",
}
# To avoid going over quota in this demo, cap the max number of Spark workers.
session.runtime_config.properties = {
"spark.dynamicAllocation.maxExecutors": "4"
}
spark = (
DataprocSparkSession.builder
.appName("CustomSparkSession")
.dataprocSessionConfig(session)
.getOrCreate()
)
۶. بارگذاری و کاوش دادهها با استفاده از Gemini
در این بخش، شما با اولین گام مهم در هر پروژه علم داده آشنا میشوید: آمادهسازی دادهها. شما با بارگذاری دادهها در یک فریم داده Apache Spark از BigQuery شروع میکنید.
# Load the tables
order_items = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.order_items").load()
users = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.users").load()
# Register temp tables
users.createOrReplaceTempView("users")
order_items.createOrReplaceTempView("order_items")
# Verify temp tables
spark.sql("SELECT * FROM order_items LIMIT 10").show()
سپس، از Gemini برای تولید کد PySpark استفاده میکنید تا دادهها را بررسی کرده و آنها را بهتر درک کنید.
اعلان ۱ : با استفاده از PySpark، جدول کاربران را بررسی کرده و ۱۰ ردیف اول را نمایش دهید.
# prompt: Using PySpark, explore the users table and show the first 10 rows.
users.show(10)
اعلان ۲ : با استفاده از PySpark، جدول order_items را بررسی کرده و ۱۰ ردیف اول را نمایش دهید.
# prompt: Using PySpark, explore the order_items table and show the first 10 rows.
order_items.show(10)
سوال ۳ : با استفاده از PySpark، پنج کشور پراستفاده در جدول کاربران را نمایش دهید. کشور و تعداد کاربران هر کشور را نمایش دهید.
# prompt: Using PySpark, show the top 5 most frequent countries in the users table. Display the country and the number of users from each country.
from pyspark.sql.functions import col, count
users.groupBy("country").agg(count("*").alias("user_count")).orderBy(col("user_count").desc()).limit(5).show()
سوال ۴ : با استفاده از PySpark، میانگین قیمت فروش اقلام را در جدول order_items پیدا کنید.
# prompt: Using PySpark, find the average sale price of items in the order_items table.
from pyspark.sql import functions as F
average_sale_price = order_items.agg(F.avg("sale_price").alias("average_sale_price"))
average_sale_price.show()
نکته ۵ : با استفاده از جدول "users"، کدی برای رسم نمودار کشور در مقابل منبع ترافیک با استفاده از یک کتابخانه رسم نمودار مناسب تولید کنید.
# prompt: Using the table "users", generate code to plot country vs traffic source using a suitable plotting library.
sql = """
SELECT
country,
traffic_source
FROM
`bigquery-public-data.thelook_ecommerce.users`
WHERE country IS NOT NULL AND traffic_source IS NOT NULL
"""
project_id = "iceberg-summit-2025"
df = pandas_gbq.read_gbq(sql, project_id=project_id, dialect="standard")
import matplotlib.pyplot as plt
import seaborn as sns
# Group by country and traffic_source and count occurrences
df_grouped = df.groupby(['country', 'traffic_source']).size().reset_index(name='count')
# Create a pivot table for easier plotting
pivot_table = df_grouped.pivot(index='country', columns='traffic_source', values='count').fillna(0)
# Plotting
plt.figure(figsize=(15, 8))
pivot_table.plot(kind='bar', stacked=True, figsize=(15, 8))
plt.title('Traffic Source Distribution by Country')
plt.xlabel('Country')
plt.ylabel('Number of Users')
plt.xticks(rotation=90)
plt.legend(title='Traffic Source')
plt.tight_layout()
plt.show()
نکته ۶: یک هیستوگرام ایجاد کنید که توزیع «سن»، «کشور»، «جنسیت» و «منبع ترافیک» را نشان دهد.
# prompt: Create a histogram showing the distribution of "age", "country", "gender", "traffic_source".
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for visualization
users_pd = users.toPandas()
# Create histograms for 'age', 'country', 'gender', 'traffic_source'
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('Distribution of User Attributes')
# Age distribution
axes[0, 0].hist(users_pd['age'].dropna(), bins=20, edgecolor='black')
axes[0, 0].set_title('Age Distribution')
axes[0, 0].set_xlabel('Age')
axes[0, 0].set_ylabel('Number of Users')
# Country distribution
users_pd['country'].value_counts().head(10).plot(kind='bar', ax=axes[0, 1])
axes[0, 1].set_title('Top 10 Countries Distribution')
axes[0, 1].set_xlabel('Country')
axes[0, 1].set_ylabel('Number of Users')
axes[0, 1].tick_params(axis='x', rotation=45)
# Gender distribution
users_pd['gender'].value_counts().plot(kind='bar', ax=axes[1, 0])
axes[1, 0].set_title('Gender Distribution')
axes[1, 0].set_xlabel('Gender')
axes[1, 0].set_ylabel('Number of Users')
axes[1, 0].tick_params(axis='x', rotation=0)
# Traffic Source distribution
users_pd['traffic_source'].value_counts().head(10).plot(kind='bar', ax=axes[1, 1])
axes[1, 1].set_title('Top 10 Traffic Source Distribution')
axes[1, 1].set_xlabel('Traffic Source')
axes[1, 1].set_ylabel('Number of Users')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
۷. آمادهسازی دادهها و مهندسی ویژگیها
در مرحله بعد، شما مهندسی ویژگی را روی دادهها انجام میدهید. ستونهای مناسب را انتخاب میکنید، دادهها را به انواع داده مناسبتر تبدیل میکنید و یک ستون برچسب شناسایی میکنید.
features = spark.sql("""
SELECT
CAST(u.age AS DOUBLE) AS age,
CAST(hash(u.country) AS BIGINT) * 1.0 AS country_hash,
CAST(hash(u.gender) AS BIGINT) * 1.0 AS gender_hash,
CAST(hash(u.traffic_source) AS BIGINT) * 1.0 AS traffic_source_hash,
CASE WHEN COUNT(oi.id) > 0 THEN 1 ELSE 0 END AS label -- Changed label generation to count order items
FROM users AS u
LEFT JOIN order_items AS oi
ON u.id = oi.user_id
GROUP BY u.id, u.age, u.country, u.gender, u.traffic_source
""")
features.show()
۸. آموزش یک مدل رگرسیون لجستیک
با استفاده از MLlib، شما یک مدل رگرسیون لجستیک را آموزش میدهید. ابتدا، از یک VectorAssembler برای تبدیل دادهها به فرمت برداری استفاده میکنید. سپس، StandardScaler ستون ویژگیها را برای عملکرد بهتر مقیاسبندی میکند. سپس، یک ارجاع به یک مدل LogisticRegression ایجاد میکنید و ابرپارامترها را تعریف میکنید. شما این مراحل را در یک شیء Pipeline ترکیب میکنید، مدل را با استفاده از تابع fit() آموزش میدهید و دادهها را با استفاده از تابع transform() تبدیل میکنید.
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.pipeline import Pipeline
from pyspark.ml.functions import array_to_vector
#Split Train and Test Data (80:20)
train_data, test_data = features.randomSplit([0.8, 0.2], seed=42)
# Initialize VectorAssembler
assembler = VectorAssembler(
inputCols=["age", "country_hash", "gender_hash", "traffic_source_hash"],
outputCol="assembled_features"
)
# Initialize StandardScaler
scaler = StandardScaler(inputCol="assembled_features", outputCol="scaled_features")
# Initialize Logistic Regression model
lr = LogisticRegression(
maxIter=100,
regParam=0.2,
threshold=0.8,
featuresCol="scaled_features",
labelCol="label"
)
# Define pipeline
pipeline = Pipeline(stages=[assembler, scaler, lr])
# Fit the model
pipeline_model = pipeline.fit(train_data)
# Transform the dataset using the trained model
transformed_dataset = pipeline_model.transform(test_data)
transformed_dataset.show()
۹. ارزیابی مدل
مجموعه داده تازه تبدیل شده خود را ارزیابی کنید. معیار ارزیابی مساحت زیر منحنی (AUC) را ایجاد کنید.
# Model evaluation
eva = BinaryClassificationEvaluator(metricName="areaUnderPR")
aucPR = eva.evaluate(transformed_dataset)
print(f"AUC PR: {aucPR}")
سپس، از Gemini برای تولید کد PySpark استفاده کنید تا خروجی مدل خود را تجسم کنید.
نکته ۱: کدی برای رسم منحنی دقت-فراخوانی (PR) ایجاد کنید. دقت و فراخوانی را از پیشبینیهای مدل محاسبه کنید و منحنی PR را با استفاده از یک کتابخانه رسم مناسب نمایش دهید.
# prompt: Generate code to plot the Precision-Recall (PR) curve. Calculate precision and recall from the model's predictions and display the PR curve using a suitable plotting library.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, auc
# Extract predictions and labels
predictions = transformed_dataset.select("prediction", "label").toPandas()
# Calculate precision and recall
precision, recall, _ = precision_recall_curve(predictions["label"], predictions["prediction"])
# Calculate AUC-PR
pr_auc = auc(recall, precision)
# Plot the PR curve
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, color='blue', lw=2, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
سوال ۲: کدی برای ایجاد تجسم ماتریس درهمریختگی ایجاد کنید. ماتریس درهمریختگی را از پیشبینیهای مدل محاسبه کنید و آن را به صورت یک نقشه حرارتی یا جدولی با تعداد مثبتهای واقعی (TP)، منفیهای واقعی (TN)، مثبتهای کاذب (FP) و منفیهای کاذب (FN) نمایش دهید.
# prompt: Generate code to create a confusion matrix visualization. Calculate the confusion matrix from the model's predictions and display it as a heat map or a table with counts of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Extract predictions and labels
predictions_and_labels = transformed_dataset.select("prediction", "label").toPandas()
# Calculate the confusion matrix
cm = confusion_matrix(predictions_and_labels["label"], predictions_and_labels["prediction"])
# Create a DataFrame for better visualization
cm_df = pd.DataFrame(cm,
index=['Actual Negative', 'Actual Positive'],
columns=['Predicted Negative', 'Predicted Positive'])
# Display the confusion matrix as a table
print("Confusion Matrix:")
print(cm_df)
# Display the confusion matrix as a heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(cm_df, annot=True, fmt='d', cmap='Blues', cbar=False, linewidths=.5)
plt.title('Confusion Matrix')
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
plt.show()
# Calculate and display TP, TN, FP, FN
TN, FP, FN, TP = cm.ravel()
print(f"
True Positives (TP): {TP}")
print(f"True Negatives (TN): {TN}")
print(f"False Positives (FP): {FP}")
print(f"False Negatives (FN): {FN}")
۱۰. پیشبینیها را در BigQuery بنویسید
از Gemini برای تولید کدی استفاده کنید که پیشبینیهای شما را در یک جدول جدید در مجموعه دادههای BigQuery شما بنویسد.
سوال: با استفاده از Spark، مجموعه داده تبدیلشده را در BigQuery بنویسید.
# prompt: Using Spark, write the transformed dataset to BigQuery.
transformed_dataset.write.format("bigquery").option("table", f"{PROJECT_ID}.demo.predictions").mode("overwrite").save()
۱۱. مدل را در فضای ذخیرهسازی ابری ذخیره کنید
با استفاده از قابلیتهای بومی MLlib، مدل خود را در فضای ذخیرهسازی ابری ذخیره کنید. سرور استنتاج، مدل را از اینجا بارگذاری میکند.
MODEL_PATH = "models/prediction_model"
pipeline_model.write().overwrite().save(f"gs://{BUCKET_NAME}/{MODEL_PATH}")
۱۲. ایجاد یک سرور استنتاج
Cloud Run ابزاری انعطافپذیر برای اجرای برنامههای وب بدون سرور است. این ابزار از کانتینرهای Docker برای ارائه حداکثر قابلیت سفارشیسازی به کاربران استفاده میکند. برای این آزمایش، یک Dockerfile پیکربندی شده است تا یک برنامه Flask را که از PySpark پشتیبانی میکند، اجرا کند. این کانتینر روی Cloud Run اجرا میشود تا استنتاج روی دادههای ورودی را انجام دهد. کد آن را میتوانید اینجا پیدا کنید.
مخزن را با کد سرور استنتاج کلون کنید.
!git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
فایل داکر را مشاهده کنید.
FROM python:3.12-slim
# Install OpenJDK-21 (Required for Spark)
RUN apt-get update && \
apt-get install -y openjdk-21-jre-headless procps && \
rm -rf /var/lib/apt/lists/*
ENV JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64
ENV PORT=8080
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "--workers", "1", "--threads", "8", "--timeout", "0", "main:app"]
کد پایتون مربوط به سرور را مشاهده کنید.
import os
import json
import logging
from flask import Flask, request, jsonify
from google.cloud import storage
from pyspark.ml import PipelineModel
from pyspark.sql import SparkSession
from pyspark.sql.functions import hash, col
# Configure basic logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- Initialization: Spark and Model Loading ---
GCS_BUCKET = os.environ.get("GCS_BUCKET")
GCS_MODEL_PATH = os.environ.get("GCS_MODEL_PATH")
LOCAL_MODEL_PATH = "/tmp/model"
try:
spark = SparkSession.builder \
.appName("CloudRunSparkService") \
.master("local[*]") \
.getOrCreate()
logging.info("Spark Session successfully initialized.")
except Exception as e:
logging.error(f"Failed to initialize Spark Session: {e}")
raise
def download_directory(bucket_name, prefix, local_path):
"""Downloads a directory from GCS to local filesystem."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blobs = list(bucket.list_blobs(prefix=prefix))
if len(blobs) == 0:
logging.error(f"No files found in GCS bucket {bucket_name} at prefix {prefix}")
return
for blob in blobs:
if blob.name.endswith("/"): continue # Skip directories
# Structure local paths
relative_path = os.path.relpath(blob.name, prefix)
local_file_path = os.path.join(local_path, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
blob.download_to_filename(local_file_path)
print(f"Model downloaded to {local_path}")
# Load model
def load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH):
"""Download and load model on startup to avoid latency per request."""
global MODEL
if not os.path.exists(LOCAL_MODEL_PATH):
download_directory(GCS_BUCKET, GCS_MODEL_PATH, LOCAL_MODEL_PATH)
logging.info(f"Loading PySpark model from {GCS_MODEL_PATH}")
# Load the Spark ML model
try:
MODEL = PipelineModel.load(LOCAL_MODEL_PATH)
logging.info("Spark model loaded successfully.")
except Exception as e:
logging.error(f"Failed to load model: {e}")
raise
# Load Model on Startup
load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH)
# --- Flask Application Setup ---
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
"""
Handles incoming POST requests for inference.
Expects JSON data that can be converted into a Spark DataFrame.
"""
if MODEL is None:
return jsonify({"error": "Model failed to load at startup."}), 500
try:
# 1. Get data from the request
data = request.get_json()
# 2. Check length of list
data_len = len(data)
cap = 100
if data_len > cap:
return jsonify({"error": f"Too many records. Count: {data_len}, Max: {cap}"}), 400
# 2. Create Spark DataFrame
df = spark.createDataFrame(data)
# 3. Transform data
input_df = df.select(
col("age").cast("DOUBLE").alias("age"),
(hash(col("country")).cast("BIGINT") * 1.0).alias("country_hash"),
(hash(col("gender")).cast("BIGINT") * 1.0).alias("gender_hash"),
(hash(col("traffic_source")).cast("BIGINT") * 1.0).alias("traffic_source_hash")
)
# 3. Perform Inference
predictions_df = MODEL.transform(input_df)
# 4. Prepare results (collect and serialize)
results = [p.prediction for p in predictions_df.select("prediction").collect()]
# 5. Return JSON response
return jsonify({"predictions": results})
except Exception as e:
logging.error(f"An error occurred during prediction: {e}")
#return jsonify({"error": str(e)}), 500
raise e
# Gunicorn entry point uses 'app' from this file
if __name__ == '__main__':
# Local testing only: Cloud Run uses Gunicorn/CMD command
app.run(host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
سرور استنتاج را مستقر کنید.
import subprocess
command = [
"gcloud",
"run",
"deploy",
"inference-server",
"--source",
"/content/devrel-demos/data-analytics/dataproc-webinar/data-science/inference-server",
"--region",
f"{REGION}",
"--port",
"8080",
"--memory",
"2Gi",
"--allow-unauthenticated",
"--set-env-vars",
f"GCS_BUCKET={BUCKET_NAME},GCS_MODEL_PATH={MODEL_PATH}",
"--startup-probe",
"tcpSocket.port=8080,initialDelaySeconds=240,failureThreshold=3,timeoutSeconds=240,periodSeconds=240"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
آدرس اینترنتی سرور استنتاج را از خروجی در یک متغیر جدید کپی کنید. این آدرس مشابه https://inference-server-123456789.us-central1.run.app.
INFERENCE_SERVER_URL = "<YOUR_SERVER_URL>"
سرور استنتاج را آزمایش کنید.
import requests
age = "25.0"
country = "United States"
traffic_source = "Search"
gender = "F"
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
print(response.json())
خروجی باید 1.0 یا 0.0 باشد.
{'predictions': [1.0]}
۱۳. پیکربندی یک عامل
از Agent Engine برای ایجاد عاملی که میتواند استنتاج انجام دهد استفاده کنید. Agent Engine بخشی از پلتفرم هوش مصنوعی Vertex است، مجموعهای از خدمات که توسعهدهندگان را قادر میسازد تا عاملهای هوش مصنوعی را در محیط تولید مستقر، مدیریت و مقیاسبندی کنند. این پلتفرم ابزارهای زیادی از جمله ارزیابی عاملها، زمینههای جلسه و اجرای کد دارد. از بسیاری از چارچوبهای عاملمحور محبوب، از جمله کیت توسعه عامل (ADK) پشتیبانی میکند. ADK یک چارچوب عاملمحور متنباز است که اگرچه برای استفاده با Gemini و اکوسیستم گوگل ساخته و بهینه شده است، اما مستقل از مدل است. این چارچوب به گونهای طراحی شده است که توسعه عامل را بیشتر شبیه توسعه نرمافزار کند.
کلاینت Vertex AI را مقداردهی اولیه کنید.
import vertexai
from vertexai import agent_engines # For the prebuilt templates
client = vertexai.Client( # For service interactions via client.agent_engines
project=f"{PROJECT_ID}",
location=f"{REGION}",
)
تابعی برای پرسوجو از مدل پیادهسازیشده تعریف کنید.
def predict_purchase(
age: str = "25.0",
country: str = "United States",
traffic_source: str = "Search",
gender: str = "M",
):
"""Predicts whether or not a user will purchase a product.
Args:
age: The age of the user.
country: The country of the user. One of: "China", "Poland", "Germany", "United States", "Spain", "United Kingdom", "España", "Japan", "Brasil", "Colombia", "Belgium", "South Korea", "Austria", "France", "Australia".
Traffic_source: The source of the user's traffic. One of: "Display", "Email", "Search", "Organic", "Facebook".
gender: The gender of the user. One of: "M" or "F".
Returns:
True if the model output is 1.0, False otherwise.
"""
import requests
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
return response.json()
تابع را با ارسال پارامترهای نمونه آزمایش کنید.
predict_purchase(age=25.0, country="United States", traffic_source="Search", gender="M")
با استفاده از ADK، یک عامل زیر را تعریف کنید و تابع predict_purchase را به عنوان ابزار ارائه دهید.
from google.adk.agents import Agent
from vertexai import agent_engines
agent = Agent(
model="gemini-2.5-flash",
name='purchase_prediction_agent',
tools=[predict_purchase]
)
با ارسال یک کوئری، عامل را به صورت محلی آزمایش کنید.
app = agent_engines.AdkApp(agent=agent)
async for event in app.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
مدل را روی Agent Engine مستقر کنید.
remote_agent = client.agent_engines.create(
agent=app,
config={
"requirements": ["google-cloud-aiplatform[agent_engines,adk]"],
"staging_bucket": f"gs://{BUCKET_NAME}",
"display_name": "purchase-predictor",
"description": "Agent that predicts whether or not a user will purchase a product.",
}
)
پس از اتمام، مدل مستقر شده را در Cloud Console مشاهده کنید.
دوباره مدل را کوئری کنید. اکنون این به جای نسخه محلی، به عامل مستقر شده اشاره میکند.
async for event in remote_agent.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
۱۴. تمیز کردن
تمام منابع Google Cloud که ایجاد کردهاید را حذف کنید. اجرای دستورات پاکسازی مانند این، بهترین روش برای جلوگیری از هزینههای آینده است.
# Delete the deployed agent.
remote_agent.delete(force=True)
# Delete the inference server.
import subprocess
command = [
"gcloud",
"run",
"services",
"delete",
"inference-server",
"--region",
f"{REGION}",
"--quiet"
]
subprocess.run(command, capture_output=True, text=True)
# Delete the BigQuery dataset.
bigquery_client = bigquery.Client()
bigquery_client.delete_dataset(
f"{PROJECT_ID}.demo", delete_contents=True, not_found_ok=True
)
# Delete the Storage bucket.
storage_client = storage.Client()
bucket = storage_client.get_bucket(BUCKET_NAME)
bucket.delete_blobs(list(bucket.list_blobs()))
bucket.delete()
۱۵. تبریک میگویم!
شما موفق شدید! در این آزمایشگاه کد، موارد زیر را انجام دادید:
- از نوتبوکهای BigQuery Studio برای اجرای یک گردش کار علوم داده استفاده کردم.
- با استفاده از Google Cloud Serverless برای Apache Spark و با پشتیبانی Spark Connect، یک اتصال به Apache Spark ایجاد کردم.
- از موتور لایتنینگ برای تسریع حجم کار آپاچی اسپارک تا ۴.۳ برابر استفاده شد.
- با استفاده از یکپارچهسازی داخلی بین آپاچی اسپارک و بیگکوئری، دادهها از بیگکوئری بارگذاری شدند.
- دادهها را با استفاده از تولید کد با کمک Gemini کاوش کرد.
- مهندسی ویژگی را با استفاده از چارچوب پردازش داده آپاچی اسپارک انجام دادم.
- با استفاده از کتابخانه یادگیری ماشین بومی Apache Spark، MLlib ، یک مدل طبقهبندی آموزش داده و ارزیابی شد.
- یک سرور استنتاج برای مدل طبقهبندی با استفاده از Flask و Cloud Run مستقر شد.
- یک عامل برای پرسوجو از سرور استنتاج با استفاده از زبان طبیعی با موتور عامل و کیت توسعه عامل (ADK) مستقر شد.
بعدش چی؟
- درباره Google Cloud Serverless برای Apache Spark بیشتر بدانید.
- نحوه پیکربندی Cloud Run را ببینید.
- درباره Agent Engine بیشتر بخوانید.