
1. Ringkasan
TheLook, retailer pakaian eCommerce hipotetis, menyimpan data tentang pelanggan, produk, pesanan, logistik, peristiwa web, dan kampanye pemasaran digital di BigQuery. Perusahaan ingin memanfaatkan keahlian SQL dan PySpark yang dimiliki tim untuk menganalisis data ini menggunakan Apache Spark.
Untuk menghindari penyediaan atau penyesuaian infrastruktur manual untuk Spark, TheLook mencari solusi penskalaan otomatis yang memungkinkan mereka berfokus pada workload, bukan pengelolaan cluster. Selain itu, mereka ingin meminimalkan upaya yang diperlukan untuk mengintegrasikan Spark dan BigQuery sambil tetap berada dalam lingkungan BigQuery Studio.
Di lab ini, Anda akan memprediksi apakah pengguna akan melakukan pembelian atau tidak dengan membangun Pengklasifikasi Regresi Logistik menggunakan PySpark dan memanfaatkan integrasi notebook native serta fitur AI BigQuery Studio untuk menjelajahi data. Anda men-deploy model ini ke server inferensi dan membuat agen untuk membuat kueri model menggunakan bahasa alami.
Prasyarat
Sebelum memulai lab ini, Anda sebaiknya sudah mengetahui:
- Pemrograman SQL dan Python dasar.
- Menjalankan kode Python di notebook Jupyter.
- Pemahaman dasar tentang komputasi terdistribusi
Tujuan
- Gunakan notebook BigQuery Studio untuk menjalankan alur kerja data science.
- Buat koneksi ke Apache Spark menggunakan Google Cloud Serverless untuk Apache Spark dan didukung oleh Spark Connect.
- Gunakan Lightning Engine untuk mempercepat workload Apache Spark hingga 4,3x.
- Muat data dari BigQuery menggunakan integrasi bawaan antara Apache Spark dan BigQuery.
- Jelajahi data menggunakan pembuatan kode yang dibantu Gemini.
- Lakukan rekayasa fitur menggunakan framework pemrosesan data Apache Spark.
- Latih dan evaluasi model klasifikasi menggunakan library machine learning native Apache Spark, MLlib.
- Deploy server inferensi untuk model klasifikasi menggunakan Flask dan Cloud Run
- Men-deploy agen untuk membuat kueri server inferensi menggunakan bahasa alami dengan Agent Engine dan Agent Development Kit (ADK),
2. Menghubungkan ke lingkungan runtime Colab
Mengidentifikasi Project Google Cloud
Buat project Google Cloud. Anda dapat menggunakan yang sudah ada.
Aktifkan API yang direkomendasikan:
Klik di sini untuk mengaktifkan API berikut:
- aiplatform.googleapis.com
- bigquery.googleapis.com
- bigquerystorage.googleapis.com
- bigqueryunified.googleapis.com
- cloudaicompanion.googleapis.com
- dataproc.googleapis.com
- storage.googleapis.com
- run.googleapis.com
Navigasi UI:
- Di Konsol Google Cloud, buka Navigation menu > BigQuery.
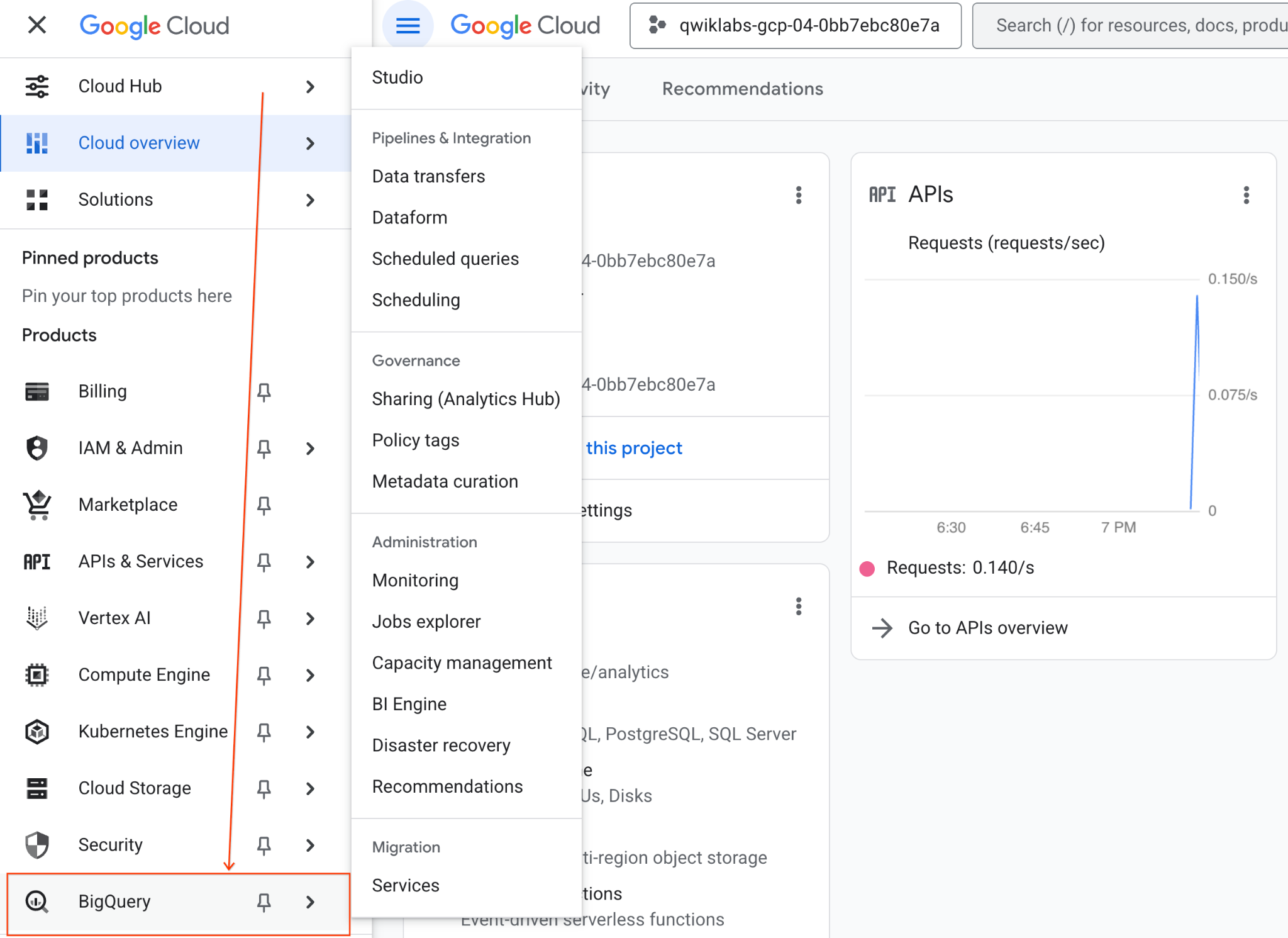
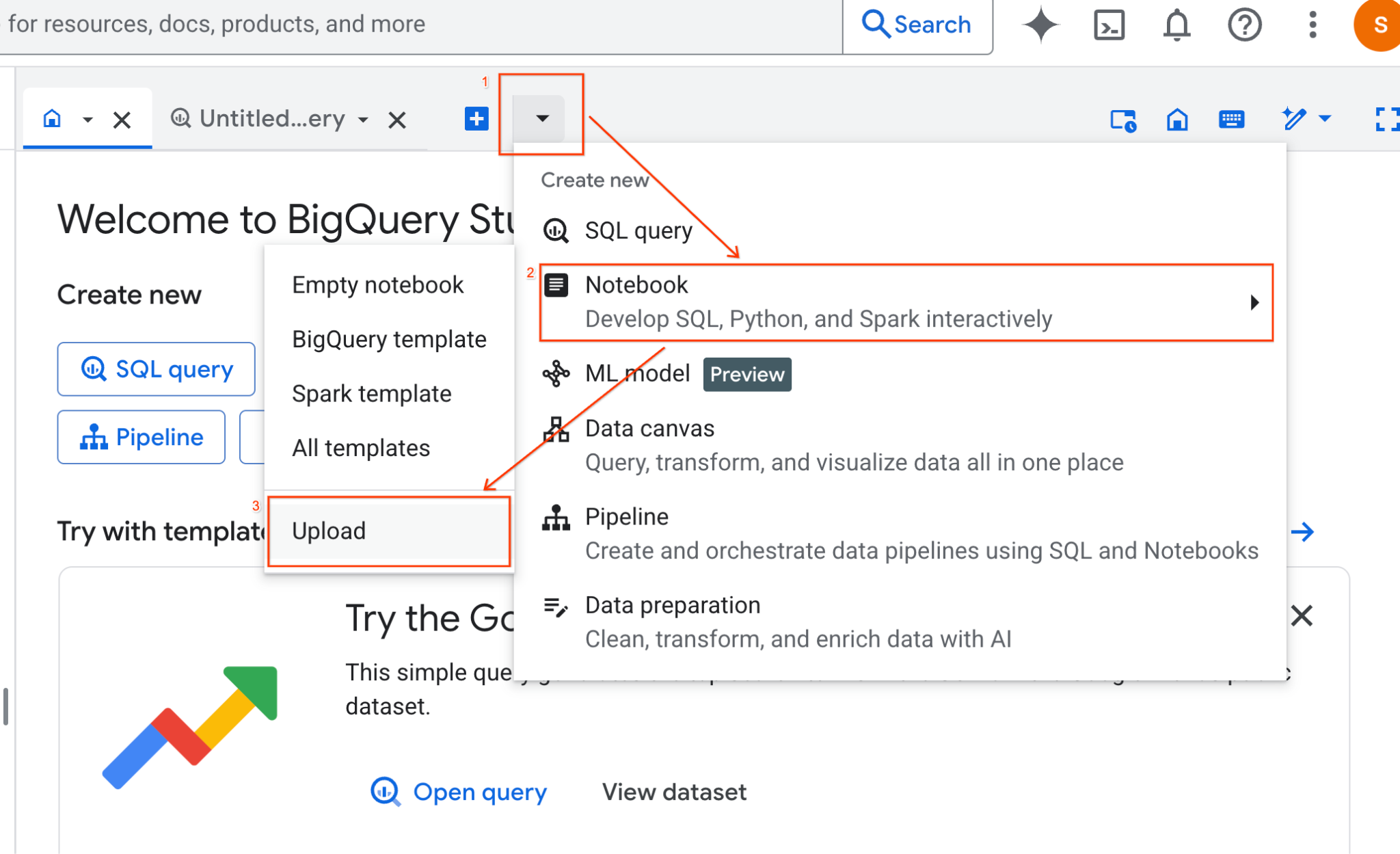
- Di panel BigQuery Studio, klik tombol panah dropdown, arahkan kursor ke Notebook, lalu pilih Upload.
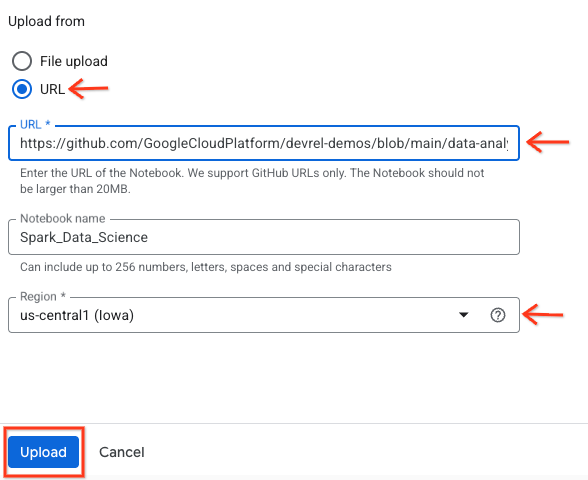
- Pilih tombol pilihan URL, lalu masukkan URL berikut:
https://github.com/GoogleCloudPlatform/devrel-demos/blob/main/data-analytics/dataproc-webinar/data-science/Spark_Data_Science.ipynb
- Tetapkan region ke
us-central11, lalu klik Upload.
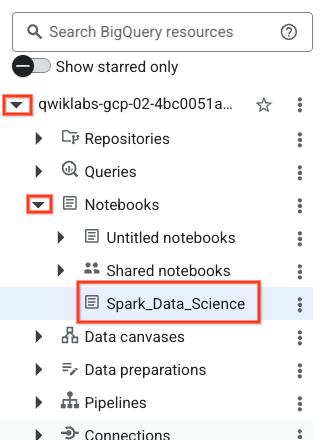
- Untuk membuka notebook, klik panah dropdown di panel Explorer dengan nama project-id Anda. Kemudian, klik dropdown untuk Notebooks. Klik notebook
Spark_Data_Science.
- Ciutkan menu navigasi BigQuery dan Daftar Isi notebook untuk mendapatkan lebih banyak ruang.
3. Menghubungkan ke runtime dan menjalankan kode penyiapan tambahan
- Klik Hubungkan. Di jendela pop-up, beri otorisasi Colab Enterprise dengan akun email Anda. Notebook Anda akan otomatis terhubung ke runtime.
- Setelah runtime ditetapkan, Anda akan melihat hal berikut:
- Di dalam notebook, scroll ke bagian Setup. Mulai di sini.
4. Menjalankan kode penyiapan
Konfigurasi lingkungan Anda dengan library Python yang diperlukan untuk menyelesaikan lab. Konfigurasi Akses Google Pribadi. Buat bucket Storage. Membuat set data BigQuery. Salin project ID Anda ke dalam notebook. Pilih region. Untuk lab ini, gunakan region us-central1.
Anda dapat menjalankan sel kode dengan mengarahkan kursor ke dalam blok sel dan mengklik panah.
# Enable APIs
import subprocess
command = [
"gcloud",
"services",
"enable",
"aiplatform.googleapis.com",
"bigquery.googleapis.com",
"bigquerystorage.googleapis.com",
"bigqueryunified.googleapis.com",
"cloudaicompanion.googleapis.com",
"dataproc.googleapis.com",
"run.googleapis.com",
"storage.googleapis.com"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Configure a PROJECT_ID and REGION
PROJECT_ID = "<YOUR_PROJECT_ID>"
REGION = "<YOUR_REGION>"
# Enable Private Google Access
import subprocess
command = [
"gcloud",
"compute",
"networks",
"subnets",
"update",
"default",
f"--region={REGION}",
"--enable-private-ip-google-access"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Create a Cloud Storage Bucket
from google.cloud import storage
from google.cloud.exceptions import NotFound
BUCKET_NAME = f"{PROJECT_ID}-demo"
storage_client = storage.Client(project=PROJECT_ID)
try:
bucket = storage_client.get_bucket(BUCKET_NAME)
print(f"Bucket {BUCKET_NAME} already exists.")
except NotFound:
bucket = storage_client.create_bucket(BUCKET_NAME, location=REGION)
print(f"Bucket {BUCKET_NAME} created.")
# Create a BigQuery dataset.
from google.cloud import bigquery
DATASET_ID = f"{PROJECT_ID}.demo"
client = bigquery.Client()
dataset = bigquery.Dataset(DATASET_ID)
dataset.location = REGION
dataset = client.create_dataset(dataset, exists_ok=True)
5. Buat koneksi ke Google Cloud Serverless untuk Apache Spark
Dengan menggunakan Spark Connect, Anda terhubung ke sesi Spark serverless untuk menjalankan tugas Spark interaktif. Anda mengonfigurasi runtime dengan Lightning Engine untuk performa Spark tingkat lanjut. Lightning Engine bekerja dengan mempercepat workload menggunakan Apache Gluten dan Velox.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
session.runtime_config.version = "3.0"
# You can optionally configure Spark properties as well. See https://cloud.google.com/dataproc-serverless/docs/concepts/properties.
session.runtime_config.properties = {
"dataproc.runtime": "premium",
"spark.dataproc.engine": "lightningEngine",
}
# To avoid going over quota in this demo, cap the max number of Spark workers.
session.runtime_config.properties = {
"spark.dynamicAllocation.maxExecutors": "4"
}
spark = (
DataprocSparkSession.builder
.appName("CustomSparkSession")
.dataprocSessionConfig(session)
.getOrCreate()
)
6. Memuat dan menjelajahi data menggunakan Gemini
Di bagian ini, Anda akan mempelajari langkah penting pertama dalam setiap project ilmu data: menyiapkan data. Anda mulai dengan memuat data ke dalam dataframe Apache Spark dari BigQuery.
# Load the tables
order_items = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.order_items").load()
users = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.users").load()
# Register temp tables
users.createOrReplaceTempView("users")
order_items.createOrReplaceTempView("order_items")
# Verify temp tables
spark.sql("SELECT * FROM order_items LIMIT 10").show()
Kemudian, Anda menggunakan Gemini untuk membuat kode PySpark guna menjelajahi data dan memahaminya dengan lebih baik.
Perintah 1: Menggunakan PySpark, jelajahi tabel pengguna dan tampilkan 10 baris pertama.
# prompt: Using PySpark, explore the users table and show the first 10 rows.
users.show(10)
Perintah 2: Dengan menggunakan PySpark, jelajahi tabel order_items dan tampilkan 10 baris pertama.
# prompt: Using PySpark, explore the order_items table and show the first 10 rows.
order_items.show(10)
Perintah 3: Menggunakan PySpark, tunjukkan 5 negara yang paling sering muncul di tabel pengguna. Tampilkan negara dan jumlah pengguna dari setiap negara.
# prompt: Using PySpark, show the top 5 most frequent countries in the users table. Display the country and the number of users from each country.
from pyspark.sql.functions import col, count
users.groupBy("country").agg(count("*").alias("user_count")).orderBy(col("user_count").desc()).limit(5).show()
Perintah 4: Dengan menggunakan PySpark, temukan harga jual rata-rata item dalam tabel order_items.
# prompt: Using PySpark, find the average sale price of items in the order_items table.
from pyspark.sql import functions as F
average_sale_price = order_items.agg(F.avg("sale_price").alias("average_sale_price"))
average_sale_price.show()
Perintah 5: Dengan menggunakan tabel "users", buat kode untuk memetakan negara vs. sumber traffic menggunakan library pemetaan yang sesuai.
# prompt: Using the table "users", generate code to plot country vs traffic source using a suitable plotting library.
sql = """
SELECT
country,
traffic_source
FROM
`bigquery-public-data.thelook_ecommerce.users`
WHERE country IS NOT NULL AND traffic_source IS NOT NULL
"""
project_id = "iceberg-summit-2025"
df = pandas_gbq.read_gbq(sql, project_id=project_id, dialect="standard")
import matplotlib.pyplot as plt
import seaborn as sns
# Group by country and traffic_source and count occurrences
df_grouped = df.groupby(['country', 'traffic_source']).size().reset_index(name='count')
# Create a pivot table for easier plotting
pivot_table = df_grouped.pivot(index='country', columns='traffic_source', values='count').fillna(0)
# Plotting
plt.figure(figsize=(15, 8))
pivot_table.plot(kind='bar', stacked=True, figsize=(15, 8))
plt.title('Traffic Source Distribution by Country')
plt.xlabel('Country')
plt.ylabel('Number of Users')
plt.xticks(rotation=90)
plt.legend(title='Traffic Source')
plt.tight_layout()
plt.show()
Perintah 6: Buat histogram yang menunjukkan distribusi "usia", "negara", "gender", "traffic_source".
# prompt: Create a histogram showing the distribution of "age", "country", "gender", "traffic_source".
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for visualization
users_pd = users.toPandas()
# Create histograms for 'age', 'country', 'gender', 'traffic_source'
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('Distribution of User Attributes')
# Age distribution
axes[0, 0].hist(users_pd['age'].dropna(), bins=20, edgecolor='black')
axes[0, 0].set_title('Age Distribution')
axes[0, 0].set_xlabel('Age')
axes[0, 0].set_ylabel('Number of Users')
# Country distribution
users_pd['country'].value_counts().head(10).plot(kind='bar', ax=axes[0, 1])
axes[0, 1].set_title('Top 10 Countries Distribution')
axes[0, 1].set_xlabel('Country')
axes[0, 1].set_ylabel('Number of Users')
axes[0, 1].tick_params(axis='x', rotation=45)
# Gender distribution
users_pd['gender'].value_counts().plot(kind='bar', ax=axes[1, 0])
axes[1, 0].set_title('Gender Distribution')
axes[1, 0].set_xlabel('Gender')
axes[1, 0].set_ylabel('Number of Users')
axes[1, 0].tick_params(axis='x', rotation=0)
# Traffic Source distribution
users_pd['traffic_source'].value_counts().head(10).plot(kind='bar', ax=axes[1, 1])
axes[1, 1].set_title('Top 10 Traffic Source Distribution')
axes[1, 1].set_xlabel('Traffic Source')
axes[1, 1].set_ylabel('Number of Users')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
7. Persiapan data dan rekayasa fitur
Selanjutnya, Anda melakukan rekayasa fitur pada data. Pilih kolom yang sesuai, ubah data menjadi jenis data yang lebih sesuai, dan identifikasi kolom label.
features = spark.sql("""
SELECT
CAST(u.age AS DOUBLE) AS age,
CAST(hash(u.country) AS BIGINT) * 1.0 AS country_hash,
CAST(hash(u.gender) AS BIGINT) * 1.0 AS gender_hash,
CAST(hash(u.traffic_source) AS BIGINT) * 1.0 AS traffic_source_hash,
CASE WHEN COUNT(oi.id) > 0 THEN 1 ELSE 0 END AS label -- Changed label generation to count order items
FROM users AS u
LEFT JOIN order_items AS oi
ON u.id = oi.user_id
GROUP BY u.id, u.age, u.country, u.gender, u.traffic_source
""")
features.show()
8. Melatih model regresi logistik
Dengan MLlib, Anda melatih model regresi logistik. Pertama, Anda menggunakan VectorAssembler untuk mengonversi data menjadi format vektor. Kemudian, StandardScaler menskalakan kolom fitur untuk performa yang lebih baik. Kemudian, Anda membuat referensi ke model LogisticRegression dan menentukan hyperparameter. Anda menggabungkan langkah-langkah ini ke dalam objek Pipeline, melatih model menggunakan fungsi fit(), dan mengubah data menggunakan fungsi transform().
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.pipeline import Pipeline
from pyspark.ml.functions import array_to_vector
#Split Train and Test Data (80:20)
train_data, test_data = features.randomSplit([0.8, 0.2], seed=42)
# Initialize VectorAssembler
assembler = VectorAssembler(
inputCols=["age", "country_hash", "gender_hash", "traffic_source_hash"],
outputCol="assembled_features"
)
# Initialize StandardScaler
scaler = StandardScaler(inputCol="assembled_features", outputCol="scaled_features")
# Initialize Logistic Regression model
lr = LogisticRegression(
maxIter=100,
regParam=0.2,
threshold=0.8,
featuresCol="scaled_features",
labelCol="label"
)
# Define pipeline
pipeline = Pipeline(stages=[assembler, scaler, lr])
# Fit the model
pipeline_model = pipeline.fit(train_data)
# Transform the dataset using the trained model
transformed_dataset = pipeline_model.transform(test_data)
transformed_dataset.show()
9. Evaluasi model
Evaluasi set data yang baru diubah. Buat metrik evaluasi area di bawah kurva (AUC).
# Model evaluation
eva = BinaryClassificationEvaluator(metricName="areaUnderPR")
aucPR = eva.evaluate(transformed_dataset)
print(f"AUC PR: {aucPR}")
Kemudian, gunakan Gemini untuk membuat kode PySpark guna memvisualisasikan output model Anda.
Perintah 1: Buat kode untuk memetakan kurva Presisi-Recall (PR). Hitung presisi dan perolehan dari prediksi model dan tampilkan kurva PR menggunakan library plotting yang sesuai.
# prompt: Generate code to plot the Precision-Recall (PR) curve. Calculate precision and recall from the model's predictions and display the PR curve using a suitable plotting library.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, auc
# Extract predictions and labels
predictions = transformed_dataset.select("prediction", "label").toPandas()
# Calculate precision and recall
precision, recall, _ = precision_recall_curve(predictions["label"], predictions["prediction"])
# Calculate AUC-PR
pr_auc = auc(recall, precision)
# Plot the PR curve
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, color='blue', lw=2, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
Perintah 2: Buat kode untuk membuat visualisasi matriks kebingungan. Hitung matriks konfusi dari prediksi model dan tampilkan sebagai peta panas atau tabel dengan jumlah positif benar (TP), negatif benar (TN), positif palsu (FP), dan negatif palsu (FN).
# prompt: Generate code to create a confusion matrix visualization. Calculate the confusion matrix from the model's predictions and display it as a heat map or a table with counts of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Extract predictions and labels
predictions_and_labels = transformed_dataset.select("prediction", "label").toPandas()
# Calculate the confusion matrix
cm = confusion_matrix(predictions_and_labels["label"], predictions_and_labels["prediction"])
# Create a DataFrame for better visualization
cm_df = pd.DataFrame(cm,
index=['Actual Negative', 'Actual Positive'],
columns=['Predicted Negative', 'Predicted Positive'])
# Display the confusion matrix as a table
print("Confusion Matrix:")
print(cm_df)
# Display the confusion matrix as a heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(cm_df, annot=True, fmt='d', cmap='Blues', cbar=False, linewidths=.5)
plt.title('Confusion Matrix')
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
plt.show()
# Calculate and display TP, TN, FP, FN
TN, FP, FN, TP = cm.ravel()
print(f"
True Positives (TP): {TP}")
print(f"True Negatives (TN): {TN}")
print(f"False Positives (FP): {FP}")
print(f"False Negatives (FN): {FN}")
10. Menulis prediksi ke BigQuery
Gunakan Gemini untuk membuat kode guna menulis prediksi Anda ke tabel baru di set data BigQuery.
Perintah: Menggunakan Spark, tulis set data yang telah diubah ke BigQuery.
# prompt: Using Spark, write the transformed dataset to BigQuery.
transformed_dataset.write.format("bigquery").option("table", f"{PROJECT_ID}.demo.predictions").mode("overwrite").save()
11. Menyimpan model ke Cloud Storage
Dengan menggunakan fungsi bawaan MLlib, simpan model Anda ke Cloud Storage. Server inferensi memuat model dari sini.
MODEL_PATH = "models/prediction_model"
pipeline_model.write().overwrite().save(f"gs://{BUCKET_NAME}/{MODEL_PATH}")
12. Membuat server inferensi
Cloud Run adalah alat yang fleksibel untuk menjalankan aplikasi web serverless. Menggunakan container Docker untuk memberikan penyesuaian maksimum kepada pengguna. Untuk lab ini, Dockerfile dikonfigurasi untuk menjalankan aplikasi Flask yang mendukung PySpark. Container ini berjalan di Cloud Run untuk melakukan inferensi pada data input. Kodenya dapat ditemukan di sini.
Clone repositori dengan kode server inferensi.
!git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
Lihat Dockerfile.
FROM python:3.12-slim
# Install OpenJDK-21 (Required for Spark)
RUN apt-get update && \
apt-get install -y openjdk-21-jre-headless procps && \
rm -rf /var/lib/apt/lists/*
ENV JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64
ENV PORT=8080
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "--workers", "1", "--threads", "8", "--timeout", "0", "main:app"]
Lihat kode Python untuk server.
import os
import json
import logging
from flask import Flask, request, jsonify
from google.cloud import storage
from pyspark.ml import PipelineModel
from pyspark.sql import SparkSession
from pyspark.sql.functions import hash, col
# Configure basic logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- Initialization: Spark and Model Loading ---
GCS_BUCKET = os.environ.get("GCS_BUCKET")
GCS_MODEL_PATH = os.environ.get("GCS_MODEL_PATH")
LOCAL_MODEL_PATH = "/tmp/model"
try:
spark = SparkSession.builder \
.appName("CloudRunSparkService") \
.master("local[*]") \
.getOrCreate()
logging.info("Spark Session successfully initialized.")
except Exception as e:
logging.error(f"Failed to initialize Spark Session: {e}")
raise
def download_directory(bucket_name, prefix, local_path):
"""Downloads a directory from GCS to local filesystem."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blobs = list(bucket.list_blobs(prefix=prefix))
if len(blobs) == 0:
logging.error(f"No files found in GCS bucket {bucket_name} at prefix {prefix}")
return
for blob in blobs:
if blob.name.endswith("/"): continue # Skip directories
# Structure local paths
relative_path = os.path.relpath(blob.name, prefix)
local_file_path = os.path.join(local_path, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
blob.download_to_filename(local_file_path)
print(f"Model downloaded to {local_path}")
# Load model
def load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH):
"""Download and load model on startup to avoid latency per request."""
global MODEL
if not os.path.exists(LOCAL_MODEL_PATH):
download_directory(GCS_BUCKET, GCS_MODEL_PATH, LOCAL_MODEL_PATH)
logging.info(f"Loading PySpark model from {GCS_MODEL_PATH}")
# Load the Spark ML model
try:
MODEL = PipelineModel.load(LOCAL_MODEL_PATH)
logging.info("Spark model loaded successfully.")
except Exception as e:
logging.error(f"Failed to load model: {e}")
raise
# Load Model on Startup
load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH)
# --- Flask Application Setup ---
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
"""
Handles incoming POST requests for inference.
Expects JSON data that can be converted into a Spark DataFrame.
"""
if MODEL is None:
return jsonify({"error": "Model failed to load at startup."}), 500
try:
# 1. Get data from the request
data = request.get_json()
# 2. Check length of list
data_len = len(data)
cap = 100
if data_len > cap:
return jsonify({"error": f"Too many records. Count: {data_len}, Max: {cap}"}), 400
# 2. Create Spark DataFrame
df = spark.createDataFrame(data)
# 3. Transform data
input_df = df.select(
col("age").cast("DOUBLE").alias("age"),
(hash(col("country")).cast("BIGINT") * 1.0).alias("country_hash"),
(hash(col("gender")).cast("BIGINT") * 1.0).alias("gender_hash"),
(hash(col("traffic_source")).cast("BIGINT") * 1.0).alias("traffic_source_hash")
)
# 3. Perform Inference
predictions_df = MODEL.transform(input_df)
# 4. Prepare results (collect and serialize)
results = [p.prediction for p in predictions_df.select("prediction").collect()]
# 5. Return JSON response
return jsonify({"predictions": results})
except Exception as e:
logging.error(f"An error occurred during prediction: {e}")
#return jsonify({"error": str(e)}), 500
raise e
# Gunicorn entry point uses 'app' from this file
if __name__ == '__main__':
# Local testing only: Cloud Run uses Gunicorn/CMD command
app.run(host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
Deploy server inferensi.
import subprocess
command = [
"gcloud",
"run",
"deploy",
"inference-server",
"--source",
"/content/devrel-demos/data-analytics/dataproc-webinar/data-science/inference-server",
"--region",
f"{REGION}",
"--port",
"8080",
"--memory",
"2Gi",
"--allow-unauthenticated",
"--set-env-vars",
f"GCS_BUCKET={BUCKET_NAME},GCS_MODEL_PATH={MODEL_PATH}",
"--startup-probe",
"tcpSocket.port=8080,initialDelaySeconds=240,failureThreshold=3,timeoutSeconds=240,periodSeconds=240"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
Salin URL server inferensi dari output ke dalam variabel baru. Tampilannya akan mirip dengan https://inference-server-123456789.us-central1.run.app.
INFERENCE_SERVER_URL = "<YOUR_SERVER_URL>"
Uji server inferensi.
import requests
age = "25.0"
country = "United States"
traffic_source = "Search"
gender = "F"
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
print(response.json())
Output harus berupa 1.0 atau 0.0.
{'predictions': [1.0]}
13. Mengonfigurasi agen
Gunakan Agent Engine untuk membuat agen yang dapat melakukan inferensi. Agent Engine adalah bagian dari Vertex AI Platform, serangkaian layanan yang memungkinkan developer men-deploy, mengelola, dan menskalakan agen AI dalam produksi. Alat ini memiliki banyak alat, termasuk alat untuk mengevaluasi agen, konteks sesi, dan eksekusi kode. Layanan ini mendukung banyak framework agentik populer, termasuk Agent Development Kit (ADK). ADK adalah framework agentik open source yang, meskipun dibangun dan dioptimalkan untuk digunakan dengan Gemini dan ekosistem Google, bersifat agnostik terhadap model. ADK dirancang agar pengembangan agen terasa lebih seperti pengembangan software.
Lakukan inisialisasi klien Vertex AI.
import vertexai
from vertexai import agent_engines # For the prebuilt templates
client = vertexai.Client( # For service interactions via client.agent_engines
project=f"{PROJECT_ID}",
location=f"{REGION}",
)
Tentukan fungsi untuk membuat kueri model yang di-deploy.
def predict_purchase(
age: str = "25.0",
country: str = "United States",
traffic_source: str = "Search",
gender: str = "M",
):
"""Predicts whether or not a user will purchase a product.
Args:
age: The age of the user.
country: The country of the user. One of: "China", "Poland", "Germany", "United States", "Spain", "United Kingdom", "España", "Japan", "Brasil", "Colombia", "Belgium", "South Korea", "Austria", "France", "Australia".
Traffic_source: The source of the user's traffic. One of: "Display", "Email", "Search", "Organic", "Facebook".
gender: The gender of the user. One of: "M" or "F".
Returns:
True if the model output is 1.0, False otherwise.
"""
import requests
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
return response.json()
Uji fungsi dengan meneruskan parameter sampel.
predict_purchase(age=25.0, country="United States", traffic_source="Search", gender="M")
Dengan menggunakan ADK, tentukan agen di bawah dan berikan fungsi predict_purchase sebagai alat.
from google.adk.agents import Agent
from vertexai import agent_engines
agent = Agent(
model="gemini-2.5-flash",
name='purchase_prediction_agent',
tools=[predict_purchase]
)
Uji agen secara lokal dengan meneruskan kueri.
app = agent_engines.AdkApp(agent=agent)
async for event in app.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
Deploy model ke Agent Engine.
remote_agent = client.agent_engines.create(
agent=app,
config={
"requirements": ["google-cloud-aiplatform[agent_engines,adk]"],
"staging_bucket": f"gs://{BUCKET_NAME}",
"display_name": "purchase-predictor",
"description": "Agent that predicts whether or not a user will purchase a product.",
}
)
Setelah selesai, lihat model yang di-deploy di Konsol Cloud.
Buat kueri model lagi. Sekarang, ini mengarah ke agen yang di-deploy, bukan versi lokal.
async for event in remote_agent.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
14. Pembersihan
Hapus semua resource Google Cloud yang Anda buat. Menjalankan perintah pembersihan seperti ini adalah praktik terbaik yang penting untuk menghindari timbulnya biaya di masa mendatang.
# Delete the deployed agent.
remote_agent.delete(force=True)
# Delete the inference server.
import subprocess
command = [
"gcloud",
"run",
"services",
"delete",
"inference-server",
"--region",
f"{REGION}",
"--quiet"
]
subprocess.run(command, capture_output=True, text=True)
# Delete the BigQuery dataset.
bigquery_client = bigquery.Client()
bigquery_client.delete_dataset(
f"{PROJECT_ID}.demo", delete_contents=True, not_found_ok=True
)
# Delete the Storage bucket.
storage_client = storage.Client()
bucket = storage_client.get_bucket(BUCKET_NAME)
bucket.delete_blobs(list(bucket.list_blobs()))
bucket.delete()
15. Selamat!
Anda berhasil! Dalam codelab ini, Anda telah melakukan hal berikut:
- Menggunakan notebook BigQuery Studio untuk menjalankan alur kerja data science.
- Membuat koneksi ke Apache Spark menggunakan Google Cloud Serverless untuk Apache Spark dan didukung oleh Spark Connect.
- Menggunakan Lightning Engine untuk mempercepat workload Apache Spark hingga 4,3x.
- Memuat data dari BigQuery menggunakan integrasi bawaan antara Apache Spark dan BigQuery.
- Menjelajahi data menggunakan pembuatan kode yang dibantu Gemini.
- Melakukan rekayasa fitur menggunakan framework pemrosesan data Apache Spark.
- Melatih dan mengevaluasi model klasifikasi menggunakan library machine learning native Apache Spark, MLlib.
- Men-deploy server inferensi untuk model klasifikasi menggunakan Flask dan Cloud Run
- Men-deploy agen untuk membuat kueri server inferensi menggunakan bahasa alami dengan Agent Engine dan Agent Development Kit (ADK),
Apa selanjutnya?
- Pelajari lebih lanjut Google Cloud Serverless untuk Apache Spark.
- Lihat cara mengonfigurasi Cloud Run.
- Pelajari Agent Engine.