
1. Przegląd
TheLook, hipotetyczny sprzedawca odzieży online, przechowuje w BigQuery dane o klientach, produktach, zamówieniach, logistyce, zdarzeniach internetowych i kampaniach marketingu cyfrowego. Firma chce wykorzystać dotychczasową wiedzę zespołu na temat SQL i PySpark do analizowania tych danych za pomocą Apache Spark.
Aby uniknąć ręcznego konfigurowania infrastruktury lub dostrajania Spark, TheLook szuka rozwiązania z autoskalowaniem, które pozwoli jej skupić się na zadaniach, a nie na zarządzaniu klastrem. Dodatkowo firma chce zminimalizować wysiłek wymagany do zintegrowania Spark i BigQuery, pozostając w środowisku BigQuery Studio.
W tym laboratorium przewidzisz, czy użytkownik dokona zakupu, tworząc klasyfikator regresji logistycznej za pomocą PySpark i wykorzystując natywną integrację notatników i funkcje AI w BigQuery Studio do eksplorowania danych. Wdrożysz ten model na serwerze wnioskowania i utworzysz agenta, który będzie wykonywał zapytania do modelu w języku naturalnym.
Wymagania wstępne
Zanim zaczniesz ten moduł, musisz:
- znać podstawy programowania w SQL i Pythonie;
- wiedzieć, jak uruchamiać kod Pythona w notatniku Jupyter;
- mieć podstawową wiedzę na temat przetwarzania rozproszonego.
Cele
- Używanie notatników BigQuery Studio do przeprowadzania przepływu pracy związanego z analizą danych.
- Tworzenie połączenia z Apache Spark za pomocą Google Cloud Serverless for Apache Spark i Spark Connect.
- Używanie Lightning Engine do przyspieszenia zadań Apache Spark nawet 4,3-krotnie.
- Wczytywanie danych z BigQuery za pomocą wbudowanej integracji Apache Spark i BigQuery.
- Eksplorowanie danych za pomocą generowania kodu wspomaganego przez Gemini.
- Inżynieria cech za pomocą platformy przetwarzania danych Apache Spark.
- Trenowanie i ocenianie modelu klasyfikacji za pomocą natywnej biblioteki uczenia maszynowego Apache Spark, MLlib.
- Wdrażanie serwera wnioskowania dla modelu klasyfikacji za pomocą Flask i Cloud Run.
- Wdrażanie agenta, który będzie wykonywał zapytania do serwera wnioskowania w języku naturalnym za pomocą Agent Engine i pakietu Agent Development Kit (ADK).
2. Łączenie się ze środowiskiem wykonawczym Colab
Wybieranie projektu Google Cloud
Utwórz projekt Google Cloud. Możesz użyć istniejącego projektu.
Włącz zalecane interfejsy API:
Kliknij tutaj, aby włączyć te interfejsy API:
- aiplatform.googleapis.com
- bigquery.googleapis.com
- bigquerystorage.googleapis.com
- bigqueryunified.googleapis.com
- cloudaicompanion.googleapis.com
- dataproc.googleapis.com
- storage.googleapis.com
- run.googleapis.com
Nawigacja w interfejsie:
- W konsoli Google Cloud otwórz Menu nawigacyjne > BigQuery.
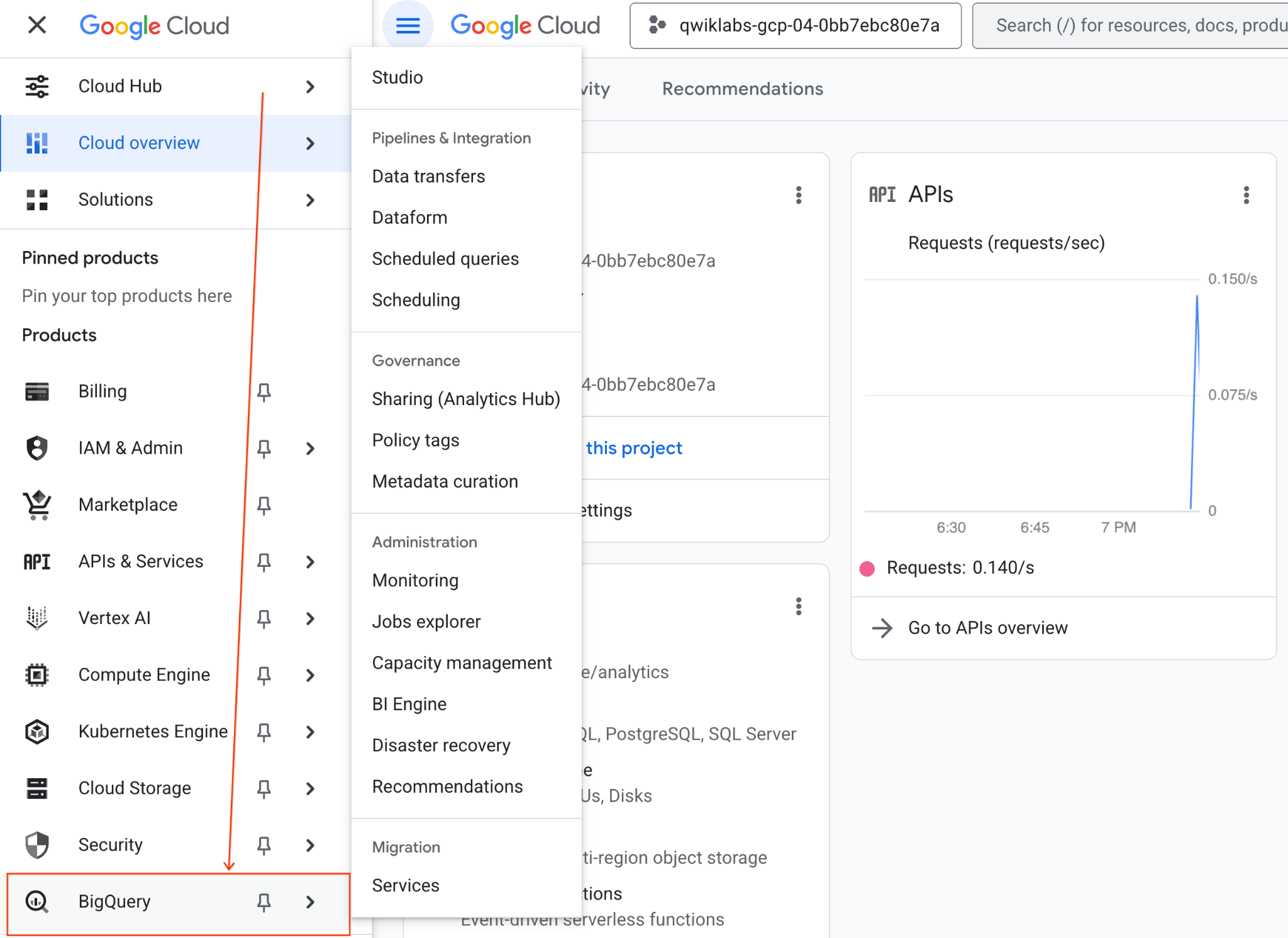
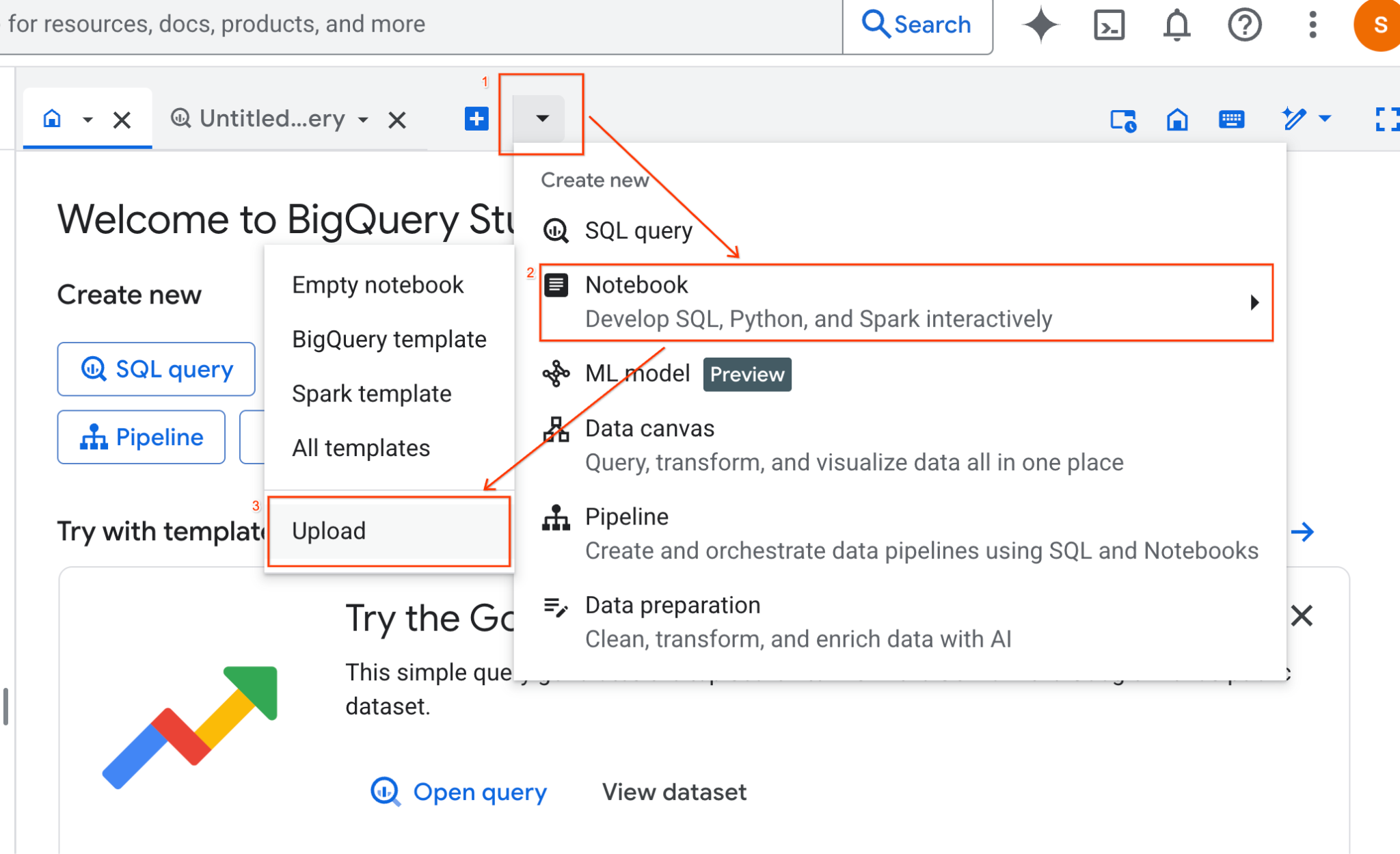
- W panelu BigQuery Studio kliknij przycisk strzałki menu, najedź kursorem na Notatnik i kliknij Prześlij.
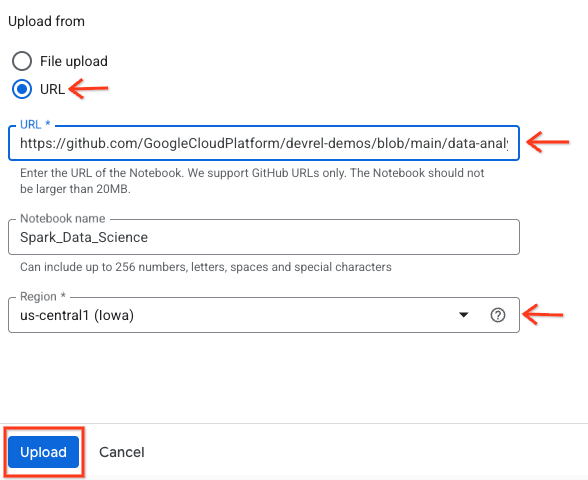
- Wybierz przycisk opcji URL i wpisz następujący adres URL:
https://github.com/GoogleCloudPlatform/devrel-demos/blob/main/data-analytics/dataproc-webinar/data-science/Spark_Data_Science.ipynb
- Ustaw region na
us-central11i kliknij Prześlij.
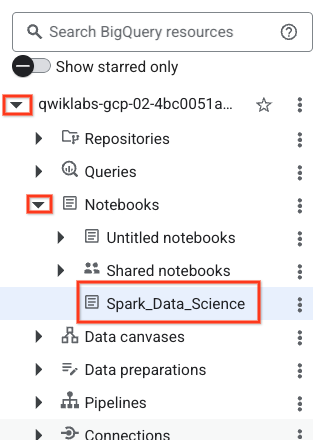
- Aby otworzyć notatnik, kliknij strzałkę menu w panelu Eksplorator z nazwą identyfikatora projektu. Następnie kliknij menu Notatniki. Kliknij notatnik
Spark_Data_Science.
- Aby uzyskać więcej miejsca, zwiń menu nawigacyjne BigQuery i spis treści notatnika.
3. Łączenie się ze środowiskiem wykonawczym i uruchamianie dodatkowego kodu konfiguracji
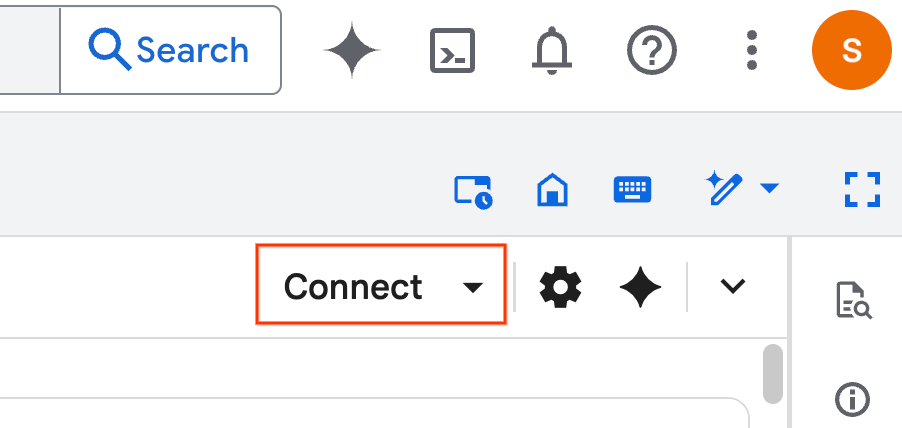
- Kliknij Połącz. W wyskakującym okienku autoryzuj Colab Enterprise za pomocą swojego adresu e-mail. Notatnik automatycznie połączy się ze środowiskiem wykonawczym.
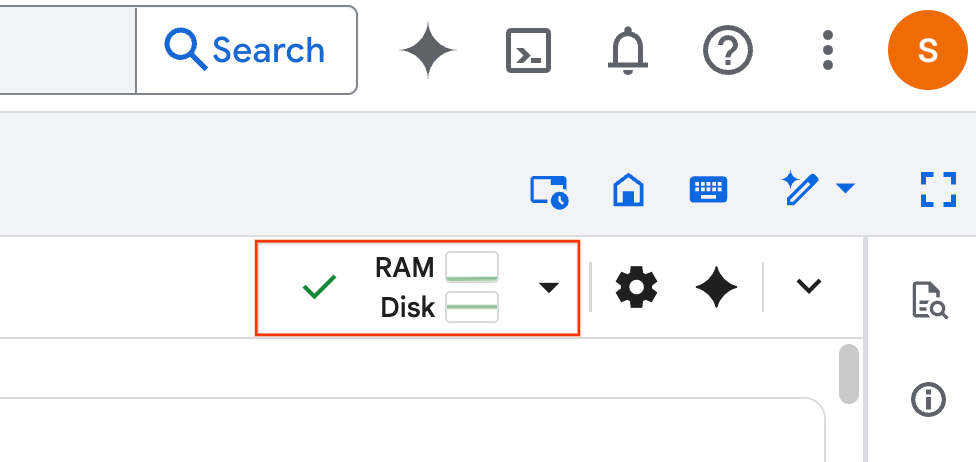
- Po utworzeniu środowiska wykonawczego zobaczysz te informacje:
- W notatniku przewiń do sekcji Konfiguracja. Zacznij tutaj.
4. Uruchamianie kodu konfiguracji
Skonfiguruj środowisko za pomocą niezbędnych bibliotek Pythona, aby ukończyć moduł. Skonfiguruj prywatny dostęp do Google. Utwórz zasobnik Cloud Storage. Utwórz zbiór danych BigQuery. Skopiuj identyfikator projektu do notatnika. Wybierz region. W tym laboratorium użyj regionu us-central1.
Aby wykonać komórkę z kodem, najedź kursorem na blok komórki i kliknij strzałkę.
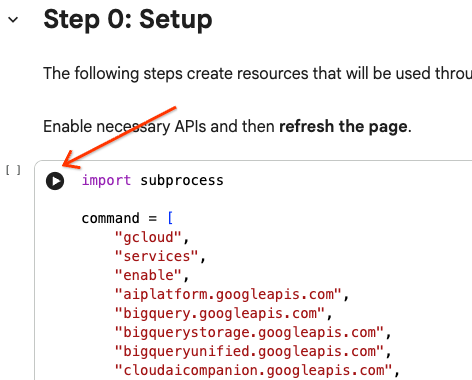
# Enable APIs
import subprocess
command = [
"gcloud",
"services",
"enable",
"aiplatform.googleapis.com",
"bigquery.googleapis.com",
"bigquerystorage.googleapis.com",
"bigqueryunified.googleapis.com",
"cloudaicompanion.googleapis.com",
"dataproc.googleapis.com",
"run.googleapis.com",
"storage.googleapis.com"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Configure a PROJECT_ID and REGION
PROJECT_ID = "<YOUR_PROJECT_ID>"
REGION = "<YOUR_REGION>"
# Enable Private Google Access
import subprocess
command = [
"gcloud",
"compute",
"networks",
"subnets",
"update",
"default",
f"--region={REGION}",
"--enable-private-ip-google-access"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Create a Cloud Storage Bucket
from google.cloud import storage
from google.cloud.exceptions import NotFound
BUCKET_NAME = f"{PROJECT_ID}-demo"
storage_client = storage.Client(project=PROJECT_ID)
try:
bucket = storage_client.get_bucket(BUCKET_NAME)
print(f"Bucket {BUCKET_NAME} already exists.")
except NotFound:
bucket = storage_client.create_bucket(BUCKET_NAME, location=REGION)
print(f"Bucket {BUCKET_NAME} created.")
# Create a BigQuery dataset.
from google.cloud import bigquery
DATASET_ID = f"{PROJECT_ID}.demo"
client = bigquery.Client()
dataset = bigquery.Dataset(DATASET_ID)
dataset.location = REGION
dataset = client.create_dataset(dataset, exists_ok=True)
5. Tworzenie połączenia z Google Cloud Serverless for Apache Spark
Za pomocą Spark Connect możesz połączyć się z sesją Serverless Spark, aby uruchamiać interaktywne zadania Spark. Skonfiguruj środowisko wykonawcze za pomocą Lightning Engine, aby uzyskać zaawansowaną wydajność Spark. Lightning Engine przyspiesza zadania za pomocą Apache Gluten i Velox.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
session.runtime_config.version = "3.0"
# You can optionally configure Spark properties as well. See https://cloud.google.com/dataproc-serverless/docs/concepts/properties.
session.runtime_config.properties = {
"dataproc.runtime": "premium",
"spark.dataproc.engine": "lightningEngine",
}
# To avoid going over quota in this demo, cap the max number of Spark workers.
session.runtime_config.properties = {
"spark.dynamicAllocation.maxExecutors": "4"
}
spark = (
DataprocSparkSession.builder
.appName("CustomSparkSession")
.dataprocSessionConfig(session)
.getOrCreate()
)
6. Wczytywanie i eksplorowanie danych za pomocą Gemini
W tej sekcji wykonasz pierwszy ważny krok w każdym projekcie związanym z analizą danych: przygotowanie danych. Zacznij od wczytania danych do ramki danych Apache Spark z BigQuery.
# Load the tables
order_items = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.order_items").load()
users = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.users").load()
# Register temp tables
users.createOrReplaceTempView("users")
order_items.createOrReplaceTempView("order_items")
# Verify temp tables
spark.sql("SELECT * FROM order_items LIMIT 10").show()
Następnie użyj Gemini, aby wygenerować kod PySpark do eksplorowania danych i lepszego ich zrozumienia.
Prompt 1: za pomocą PySpark eksploruj tabelę users i wyświetl pierwsze 10 wierszy.
# prompt: Using PySpark, explore the users table and show the first 10 rows.
users.show(10)
Prompt 2: za pomocą PySpark eksploruj tabelę order_items i wyświetl pierwsze 10 wierszy.
# prompt: Using PySpark, explore the order_items table and show the first 10 rows.
order_items.show(10)
Prompt 3: za pomocą PySpark wyświetl 5 najczęściej występujących krajów w tabeli users. Wyświetl kraj i liczbę użytkowników z każdego kraju.
# prompt: Using PySpark, show the top 5 most frequent countries in the users table. Display the country and the number of users from each country.
from pyspark.sql.functions import col, count
users.groupBy("country").agg(count("*").alias("user_count")).orderBy(col("user_count").desc()).limit(5).show()
Prompt 4: za pomocą PySpark znajdź średnią cenę sprzedaży produktów w tabeli order_items.
# prompt: Using PySpark, find the average sale price of items in the order_items table.
from pyspark.sql import functions as F
average_sale_price = order_items.agg(F.avg("sale_price").alias("average_sale_price"))
average_sale_price.show()
Prompt 5: za pomocą tabeli "users" wygeneruj kod do wykreślenia zależności między krajem a źródłem wizyty za pomocą odpowiedniej biblioteki do tworzenia wykresów.
# prompt: Using the table "users", generate code to plot country vs traffic source using a suitable plotting library.
sql = """
SELECT
country,
traffic_source
FROM
`bigquery-public-data.thelook_ecommerce.users`
WHERE country IS NOT NULL AND traffic_source IS NOT NULL
"""
project_id = "iceberg-summit-2025"
df = pandas_gbq.read_gbq(sql, project_id=project_id, dialect="standard")
import matplotlib.pyplot as plt
import seaborn as sns
# Group by country and traffic_source and count occurrences
df_grouped = df.groupby(['country', 'traffic_source']).size().reset_index(name='count')
# Create a pivot table for easier plotting
pivot_table = df_grouped.pivot(index='country', columns='traffic_source', values='count').fillna(0)
# Plotting
plt.figure(figsize=(15, 8))
pivot_table.plot(kind='bar', stacked=True, figsize=(15, 8))
plt.title('Traffic Source Distribution by Country')
plt.xlabel('Country')
plt.ylabel('Number of Users')
plt.xticks(rotation=90)
plt.legend(title='Traffic Source')
plt.tight_layout()
plt.show()
Prompt 6: utwórz histogram przedstawiający rozkład „wieku”, „kraju”, „płci” i „źródła ruchu”.
# prompt: Create a histogram showing the distribution of "age", "country", "gender", "traffic_source".
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for visualization
users_pd = users.toPandas()
# Create histograms for 'age', 'country', 'gender', 'traffic_source'
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('Distribution of User Attributes')
# Age distribution
axes[0, 0].hist(users_pd['age'].dropna(), bins=20, edgecolor='black')
axes[0, 0].set_title('Age Distribution')
axes[0, 0].set_xlabel('Age')
axes[0, 0].set_ylabel('Number of Users')
# Country distribution
users_pd['country'].value_counts().head(10).plot(kind='bar', ax=axes[0, 1])
axes[0, 1].set_title('Top 10 Countries Distribution')
axes[0, 1].set_xlabel('Country')
axes[0, 1].set_ylabel('Number of Users')
axes[0, 1].tick_params(axis='x', rotation=45)
# Gender distribution
users_pd['gender'].value_counts().plot(kind='bar', ax=axes[1, 0])
axes[1, 0].set_title('Gender Distribution')
axes[1, 0].set_xlabel('Gender')
axes[1, 0].set_ylabel('Number of Users')
axes[1, 0].tick_params(axis='x', rotation=0)
# Traffic Source distribution
users_pd['traffic_source'].value_counts().head(10).plot(kind='bar', ax=axes[1, 1])
axes[1, 1].set_title('Top 10 Traffic Source Distribution')
axes[1, 1].set_xlabel('Traffic Source')
axes[1, 1].set_ylabel('Number of Users')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
7. Przygotowywanie danych i inżynieria cech
Następnie przeprowadzisz inżynierię cech na danych. Wybierz odpowiednie kolumny, przekształć dane w bardziej odpowiednie typy danych i określ kolumnę etykiety.
features = spark.sql("""
SELECT
CAST(u.age AS DOUBLE) AS age,
CAST(hash(u.country) AS BIGINT) * 1.0 AS country_hash,
CAST(hash(u.gender) AS BIGINT) * 1.0 AS gender_hash,
CAST(hash(u.traffic_source) AS BIGINT) * 1.0 AS traffic_source_hash,
CASE WHEN COUNT(oi.id) > 0 THEN 1 ELSE 0 END AS label -- Changed label generation to count order items
FROM users AS u
LEFT JOIN order_items AS oi
ON u.id = oi.user_id
GROUP BY u.id, u.age, u.country, u.gender, u.traffic_source
""")
features.show()
8. Trenowanie modelu regresji logistycznej
Za pomocą MLlib wytrenujesz model regresji logistycznej. Najpierw użyjesz VectorAssembler, aby przekonwertować dane na format wektorowy. Następnie StandardScaler skaluje kolumnę cech, aby zwiększyć wydajność. Następnie utworzysz odniesienie do modelu LogisticRegression i zdefiniujesz hiperparametry. Połączysz te kroki w obiekt Pipeline, wytrenujesz model za pomocą funkcji fit() i przekształcisz dane za pomocą funkcji transform().
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.pipeline import Pipeline
from pyspark.ml.functions import array_to_vector
#Split Train and Test Data (80:20)
train_data, test_data = features.randomSplit([0.8, 0.2], seed=42)
# Initialize VectorAssembler
assembler = VectorAssembler(
inputCols=["age", "country_hash", "gender_hash", "traffic_source_hash"],
outputCol="assembled_features"
)
# Initialize StandardScaler
scaler = StandardScaler(inputCol="assembled_features", outputCol="scaled_features")
# Initialize Logistic Regression model
lr = LogisticRegression(
maxIter=100,
regParam=0.2,
threshold=0.8,
featuresCol="scaled_features",
labelCol="label"
)
# Define pipeline
pipeline = Pipeline(stages=[assembler, scaler, lr])
# Fit the model
pipeline_model = pipeline.fit(train_data)
# Transform the dataset using the trained model
transformed_dataset = pipeline_model.transform(test_data)
transformed_dataset.show()
9. Ocena modelu
Oceń nowo przekształcony zbiór danych. Wygeneruj obszar pod krzywą (AUC) jako miarę oceny.
# Model evaluation
eva = BinaryClassificationEvaluator(metricName="areaUnderPR")
aucPR = eva.evaluate(transformed_dataset)
print(f"AUC PR: {aucPR}")
Następnie użyj Gemini, aby wygenerować kod PySpark do wizualizacji danych wyjściowych modelu.
Prompt 1: wygeneruj kod do wykreślenia krzywej precyzji i czułości (PR). Oblicz precyzję i czułość na podstawie prognoz modelu i wyświetl krzywą PR za pomocą odpowiedniej biblioteki do tworzenia wykresów.
# prompt: Generate code to plot the Precision-Recall (PR) curve. Calculate precision and recall from the model's predictions and display the PR curve using a suitable plotting library.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, auc
# Extract predictions and labels
predictions = transformed_dataset.select("prediction", "label").toPandas()
# Calculate precision and recall
precision, recall, _ = precision_recall_curve(predictions["label"], predictions["prediction"])
# Calculate AUC-PR
pr_auc = auc(recall, precision)
# Plot the PR curve
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, color='blue', lw=2, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
Prompt 2: wygeneruj kod do utworzenia wizualizacji tablicy pomyłek. Oblicz macierz pomyłek na podstawie prognoz modelu i wyświetl ją jako mapę termiczną lub tabelę z liczbą wyników prawdziwie pozytywnych (TP), prawdziwie negatywnych (TN), fałszywie pozytywnych (FP) i fałszywie negatywnych (FN).
# prompt: Generate code to create a confusion matrix visualization. Calculate the confusion matrix from the model's predictions and display it as a heat map or a table with counts of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Extract predictions and labels
predictions_and_labels = transformed_dataset.select("prediction", "label").toPandas()
# Calculate the confusion matrix
cm = confusion_matrix(predictions_and_labels["label"], predictions_and_labels["prediction"])
# Create a DataFrame for better visualization
cm_df = pd.DataFrame(cm,
index=['Actual Negative', 'Actual Positive'],
columns=['Predicted Negative', 'Predicted Positive'])
# Display the confusion matrix as a table
print("Confusion Matrix:")
print(cm_df)
# Display the confusion matrix as a heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(cm_df, annot=True, fmt='d', cmap='Blues', cbar=False, linewidths=.5)
plt.title('Confusion Matrix')
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
plt.show()
# Calculate and display TP, TN, FP, FN
TN, FP, FN, TP = cm.ravel()
print(f"
True Positives (TP): {TP}")
print(f"True Negatives (TN): {TN}")
print(f"False Positives (FP): {FP}")
print(f"False Negatives (FN): {FN}")
10. Zapisywanie prognoz w BigQuery
Użyj Gemini, aby wygenerować kod do zapisywania prognoz w nowej tabeli w zbiorze danych BigQuery.
Prompt: za pomocą Spark zapisz przekształcony zbiór danych w BigQuery.
# prompt: Using Spark, write the transformed dataset to BigQuery.
transformed_dataset.write.format("bigquery").option("table", f"{PROJECT_ID}.demo.predictions").mode("overwrite").save()
11. Zapisywanie modelu w Cloud Storage
Za pomocą natywnej funkcji MLlib zapisz model w Cloud Storage. Serwer wnioskowania wczytuje model z tego miejsca.
MODEL_PATH = "models/prediction_model"
pipeline_model.write().overwrite().save(f"gs://{BUCKET_NAME}/{MODEL_PATH}")
12. Tworzenie serwera wnioskowania
Cloud Run to elastyczne narzędzie do uruchamiania bezserwerowych aplikacji internetowych. Używa kontenerów Dockera, aby zapewnić użytkownikom maksymalną możliwość dostosowania. W tym module plik Dockerfile jest skonfigurowany do uruchamiania aplikacji Flask obsługującej PySpark. Ten kontener działa w Cloud Run, aby przeprowadzać wnioskowanie na podstawie danych wejściowych. Kod do niego znajdziesz tutaj.
Sklonuj repozytorium z kodem serwera wnioskowania.
!git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
Wyświetl plik Dockerfile.
FROM python:3.12-slim
# Install OpenJDK-21 (Required for Spark)
RUN apt-get update && \
apt-get install -y openjdk-21-jre-headless procps && \
rm -rf /var/lib/apt/lists/*
ENV JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64
ENV PORT=8080
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "--workers", "1", "--threads", "8", "--timeout", "0", "main:app"]
Wyświetl kod Pythona dla serwera.
import os
import json
import logging
from flask import Flask, request, jsonify
from google.cloud import storage
from pyspark.ml import PipelineModel
from pyspark.sql import SparkSession
from pyspark.sql.functions import hash, col
# Configure basic logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- Initialization: Spark and Model Loading ---
GCS_BUCKET = os.environ.get("GCS_BUCKET")
GCS_MODEL_PATH = os.environ.get("GCS_MODEL_PATH")
LOCAL_MODEL_PATH = "/tmp/model"
try:
spark = SparkSession.builder \
.appName("CloudRunSparkService") \
.master("local[*]") \
.getOrCreate()
logging.info("Spark Session successfully initialized.")
except Exception as e:
logging.error(f"Failed to initialize Spark Session: {e}")
raise
def download_directory(bucket_name, prefix, local_path):
"""Downloads a directory from GCS to local filesystem."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blobs = list(bucket.list_blobs(prefix=prefix))
if len(blobs) == 0:
logging.error(f"No files found in GCS bucket {bucket_name} at prefix {prefix}")
return
for blob in blobs:
if blob.name.endswith("/"): continue # Skip directories
# Structure local paths
relative_path = os.path.relpath(blob.name, prefix)
local_file_path = os.path.join(local_path, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
blob.download_to_filename(local_file_path)
print(f"Model downloaded to {local_path}")
# Load model
def load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH):
"""Download and load model on startup to avoid latency per request."""
global MODEL
if not os.path.exists(LOCAL_MODEL_PATH):
download_directory(GCS_BUCKET, GCS_MODEL_PATH, LOCAL_MODEL_PATH)
logging.info(f"Loading PySpark model from {GCS_MODEL_PATH}")
# Load the Spark ML model
try:
MODEL = PipelineModel.load(LOCAL_MODEL_PATH)
logging.info("Spark model loaded successfully.")
except Exception as e:
logging.error(f"Failed to load model: {e}")
raise
# Load Model on Startup
load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH)
# --- Flask Application Setup ---
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
"""
Handles incoming POST requests for inference.
Expects JSON data that can be converted into a Spark DataFrame.
"""
if MODEL is None:
return jsonify({"error": "Model failed to load at startup."}), 500
try:
# 1. Get data from the request
data = request.get_json()
# 2. Check length of list
data_len = len(data)
cap = 100
if data_len > cap:
return jsonify({"error": f"Too many records. Count: {data_len}, Max: {cap}"}), 400
# 2. Create Spark DataFrame
df = spark.createDataFrame(data)
# 3. Transform data
input_df = df.select(
col("age").cast("DOUBLE").alias("age"),
(hash(col("country")).cast("BIGINT") * 1.0).alias("country_hash"),
(hash(col("gender")).cast("BIGINT") * 1.0).alias("gender_hash"),
(hash(col("traffic_source")).cast("BIGINT") * 1.0).alias("traffic_source_hash")
)
# 3. Perform Inference
predictions_df = MODEL.transform(input_df)
# 4. Prepare results (collect and serialize)
results = [p.prediction for p in predictions_df.select("prediction").collect()]
# 5. Return JSON response
return jsonify({"predictions": results})
except Exception as e:
logging.error(f"An error occurred during prediction: {e}")
#return jsonify({"error": str(e)}), 500
raise e
# Gunicorn entry point uses 'app' from this file
if __name__ == '__main__':
# Local testing only: Cloud Run uses Gunicorn/CMD command
app.run(host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
Wdróż serwer wnioskowania.
import subprocess
command = [
"gcloud",
"run",
"deploy",
"inference-server",
"--source",
"/content/devrel-demos/data-analytics/dataproc-webinar/data-science/inference-server",
"--region",
f"{REGION}",
"--port",
"8080",
"--memory",
"2Gi",
"--allow-unauthenticated",
"--set-env-vars",
f"GCS_BUCKET={BUCKET_NAME},GCS_MODEL_PATH={MODEL_PATH}",
"--startup-probe",
"tcpSocket.port=8080,initialDelaySeconds=240,failureThreshold=3,timeoutSeconds=240,periodSeconds=240"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
Skopiuj adres URL serwera wnioskowania z danych wyjściowych do nowej zmiennej. Będzie on podobny do https://inference-server-123456789.us-central1.run.app.
INFERENCE_SERVER_URL = "<YOUR_SERVER_URL>"
Przetestuj serwer wnioskowania.
import requests
age = "25.0"
country = "United States"
traffic_source = "Search"
gender = "F"
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
print(response.json())
Dane wyjściowe powinny mieć wartość 1.0 lub 0.0.
{'predictions': [1.0]}
13. Konfigurowanie agenta
Użyj Agent Engine, aby utworzyć agenta, który może przeprowadzać wnioskowanie. Agent Engine jest częścią platformy Vertex AI, czyli zestawu usług, które umożliwiają programistom wdrażanie agentów AI w środowisku produkcyjnym, zarządzanie nimi i ich skalowanie. Ma wiele narzędzi, w tym narzędzia do oceniania agentów, konteksty sesji i wykonywanie kodu. Obsługuje wiele popularnych platform agentów, w tym pakiet Agent Development Kit (ADK). ADK to platforma agentów typu open source, która jest tworzona i optymalizowana pod kątem używania z Gemini i ekosystemem Google, ale nie jest zależna od modelu. Została zaprojektowana tak, aby tworzenie agentów przypominało tworzenie oprogramowania.
Zainicjuj klienta Vertex AI.
import vertexai
from vertexai import agent_engines # For the prebuilt templates
client = vertexai.Client( # For service interactions via client.agent_engines
project=f"{PROJECT_ID}",
location=f"{REGION}",
)
Zdefiniuj funkcję do wykonywania zapytań do wdrożonego modelu.
def predict_purchase(
age: str = "25.0",
country: str = "United States",
traffic_source: str = "Search",
gender: str = "M",
):
"""Predicts whether or not a user will purchase a product.
Args:
age: The age of the user.
country: The country of the user. One of: "China", "Poland", "Germany", "United States", "Spain", "United Kingdom", "España", "Japan", "Brasil", "Colombia", "Belgium", "South Korea", "Austria", "France", "Australia".
Traffic_source: The source of the user's traffic. One of: "Display", "Email", "Search", "Organic", "Facebook".
gender: The gender of the user. One of: "M" or "F".
Returns:
True if the model output is 1.0, False otherwise.
"""
import requests
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
return response.json()
Przetestuj funkcję, przekazując przykładowe parametry.
predict_purchase(age=25.0, country="United States", traffic_source="Search", gender="M")
Za pomocą ADK zdefiniuj poniżej agenta i podaj funkcję predict_purchase jako narzędzie.
from google.adk.agents import Agent
from vertexai import agent_engines
agent = Agent(
model="gemini-2.5-flash",
name='purchase_prediction_agent',
tools=[predict_purchase]
)
Przetestuj agenta lokalnie, przekazując zapytanie.
app = agent_engines.AdkApp(agent=agent)
async for event in app.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
Wdróż model w Agent Engine.
remote_agent = client.agent_engines.create(
agent=app,
config={
"requirements": ["google-cloud-aiplatform[agent_engines,adk]"],
"staging_bucket": f"gs://{BUCKET_NAME}",
"display_name": "purchase-predictor",
"description": "Agent that predicts whether or not a user will purchase a product.",
}
)
Gdy skończysz, wyświetl wdrożony model w konsoli Cloud.
Ponownie wykonaj zapytanie do modelu. Teraz wskazuje on wdrożonego agenta, a nie wersję lokalną.
async for event in remote_agent.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
14. Zwalnianie miejsca
Usuń wszystkie utworzone zasoby Google Cloud. Uruchamianie poleceń czyszczenia, takich jak to, jest kluczową sprawdzoną metodą, która pozwala uniknąć przyszłych opłat.
# Delete the deployed agent.
remote_agent.delete(force=True)
# Delete the inference server.
import subprocess
command = [
"gcloud",
"run",
"services",
"delete",
"inference-server",
"--region",
f"{REGION}",
"--quiet"
]
subprocess.run(command, capture_output=True, text=True)
# Delete the BigQuery dataset.
bigquery_client = bigquery.Client()
bigquery_client.delete_dataset(
f"{PROJECT_ID}.demo", delete_contents=True, not_found_ok=True
)
# Delete the Storage bucket.
storage_client = storage.Client()
bucket = storage_client.get_bucket(BUCKET_NAME)
bucket.delete_blobs(list(bucket.list_blobs()))
bucket.delete()
15. Gratulacje!
Udało Ci się! W tym ćwiczeniu wykonaliśmy te czynności:
- Używanie notatników BigQuery Studio do przeprowadzania przepływu pracy związanego z analizą danych.
- Tworzenie połączenia z Apache Spark za pomocą Google Cloud Serverless for Apache Spark i Spark Connect.
- Używanie Lightning Engine do przyspieszenia zadań Apache Spark nawet 4,3-krotnie.
- Wczytywanie danych z BigQuery za pomocą wbudowanej integracji Apache Spark i BigQuery.
- Eksplorowanie danych za pomocą generowania kodu wspomaganego przez Gemini.
- Inżynieria cech za pomocą platformy przetwarzania danych Apache Spark.
- Trenowanie i ocenianie modelu klasyfikacji za pomocą natywnej biblioteki uczenia maszynowego Apache Spark, MLlib.
- Wdrażanie serwera wnioskowania dla modelu klasyfikacji za pomocą Flask i Cloud Run
- Wdrażanie agenta, który będzie wykonywał zapytania do serwera wnioskowania w języku naturalnym za pomocą Agent Engine i pakietu Agent Development Kit (ADK).
Co dalej?
- Dowiedz się więcej o Google Cloud Serverless for Apache Spark.
- Zobacz, jak skonfigurować Cloud Run.
- Przeczytaj więcej o Agent Engine.