
1. Visão geral
A TheLook, uma varejista hipotética de roupas de e-commerce, armazena dados sobre clientes, produtos, pedidos, logística, eventos da Web e campanhas de marketing digital no BigQuery. A empresa quer aproveitar a experiência da equipe em SQL e PySpark para analisar esses dados usando o Apache Spark.
Para evitar o provisionamento ou ajuste manual da infraestrutura para o Spark, a TheLook busca uma solução de escalonamento automático que permita que ela se concentre nas cargas de trabalho em vez do gerenciamento de clusters. Além disso, ela quer minimizar o esforço necessário para integrar o Spark e o BigQuery, permanecendo no ambiente do BigQuery Studio.
Neste laboratório, você vai prever se um usuário fará uma compra criando um classificador de regressão logística usando o PySpark e aproveitando a integração nativa do notebook e os recursos de IA do BigQuery Studio para analisar os dados. Você implanta esse modelo em um servidor de inferência e cria um agente para consultar o modelo usando linguagem natural.
Pré-requisitos
Antes de fazer este laboratório, você precisa saber os seguintes conceitos:
- Programação básica em SQL e Python.
- Execução de código Python em um notebook do Jupyter.
- Noções básicas de computação distribuída.
Objetivos
- Usar notebooks do BigQuery Studio para executar um fluxo de trabalho de ciência de dados.
- Criar uma conexão com o Apache Spark usando Google Cloud Serverless para Apache Spark e com tecnologia Spark Connect.
- Usar o Lightning Engine para acelerar as cargas de trabalho do Apache Spark em até 4,3 vezes.
- Carregar dados do BigQuery usando a integração integrada entre o Apache Spark e o BigQuery.
- Analisar os dados usando a geração de código assistida pelo Gemini.
- Realizar a engenharia de atributos usando o framework de processamento de dados do Apache Spark.
- Treinar e avaliar um modelo de classificação usando a biblioteca de machine learning nativa do Apache Spark, MLlib.
- Implantar um servidor de inferência para o modelo de classificação usando Flask e Cloud Run.
- Implantar um agente para consultar o servidor de inferência usando linguagem natural com Agent Engine e o Kit de Desenvolvimento de Agente (ADK).
2. Conectar-se a um ambiente de execução do Colab
Identificar um projeto do Google Cloud
Crie um projeto do Google Cloud. Você pode usar um já existente.
Ativar APIs recomendadas :
Clique aqui para ativar as seguintes APIs:
- aiplatform.googleapis.com
- bigquery.googleapis.com
- bigquerystorage.googleapis.com
- bigqueryunified.googleapis.com
- cloudaicompanion.googleapis.com
- dataproc.googleapis.com
- storage.googleapis.com
- run.googleapis.com
Navegação na interface :
- No console do Google Cloud, acesse o menu de navegação > BigQuery.
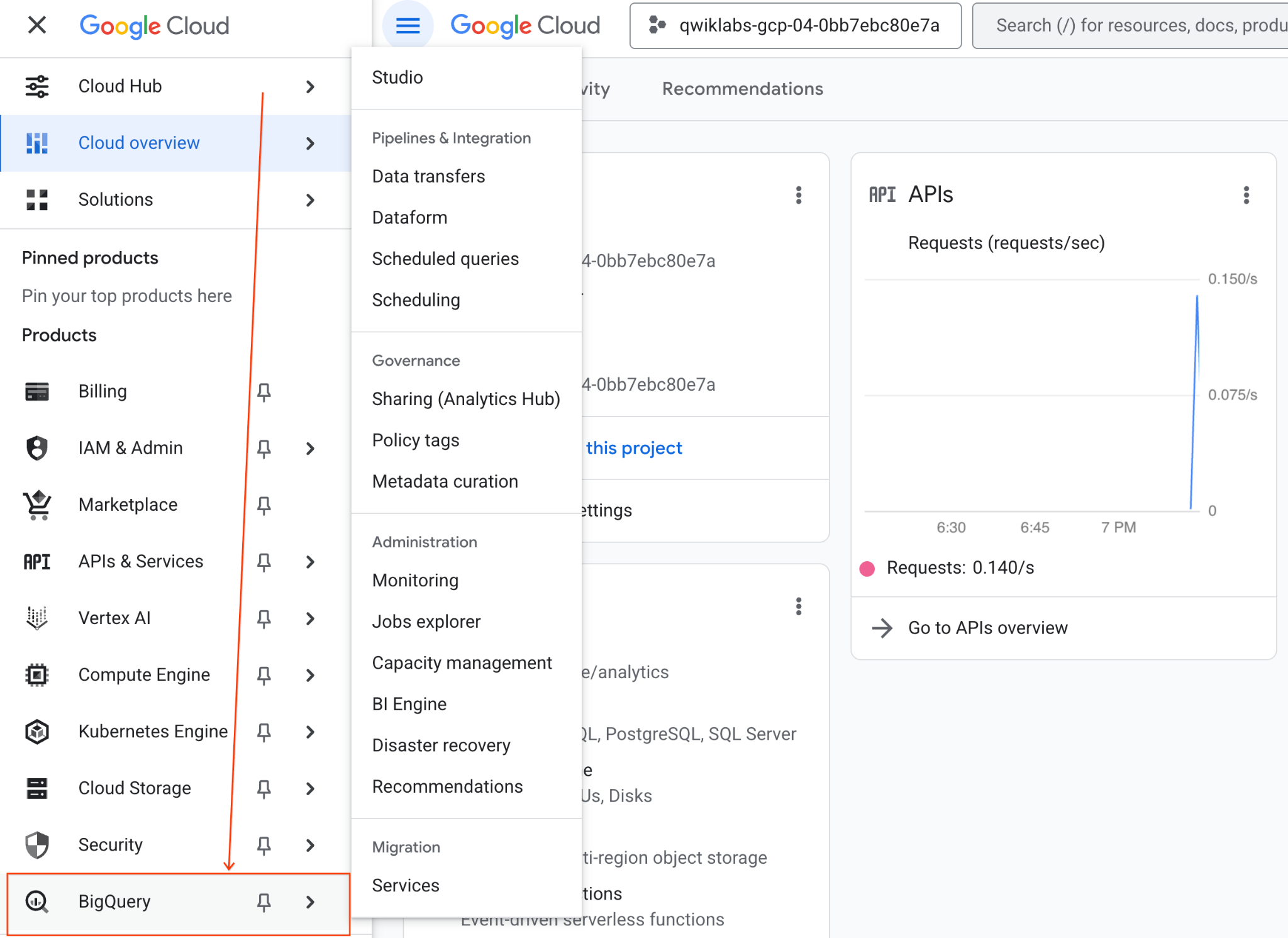
- No painel do BigQuery Studio, clique no botão de seta suspensa, passe o cursor sobre Notebook e selecione Fazer upload.
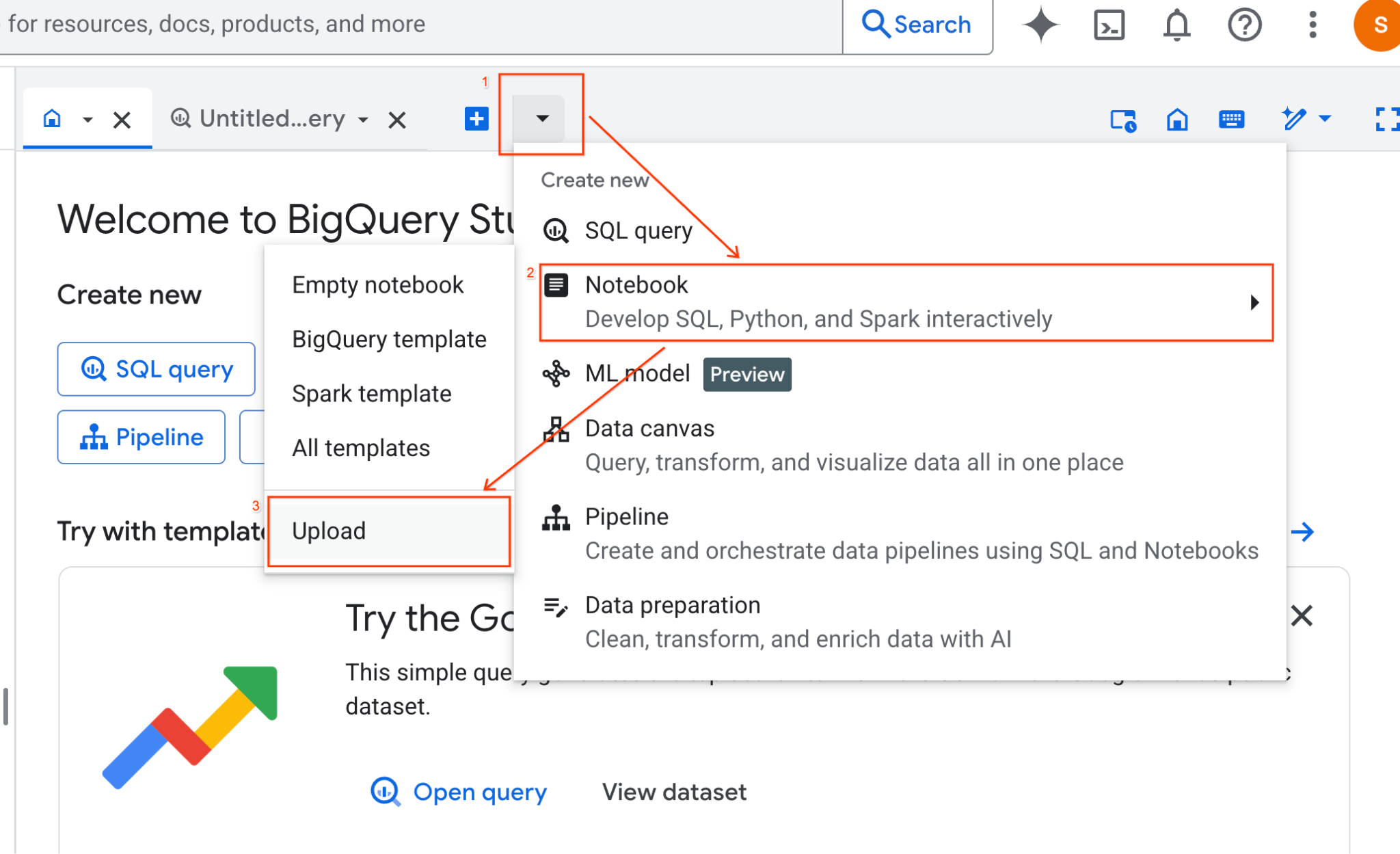
- Selecione o botão de opção URL e insira o seguinte URL:
https://github.com/GoogleCloudPlatform/devrel-demos/blob/main/data-analytics/dataproc-webinar/data-science/Spark_Data_Science.ipynb
- Defina a região como
us-central11e clique em Fazer upload.
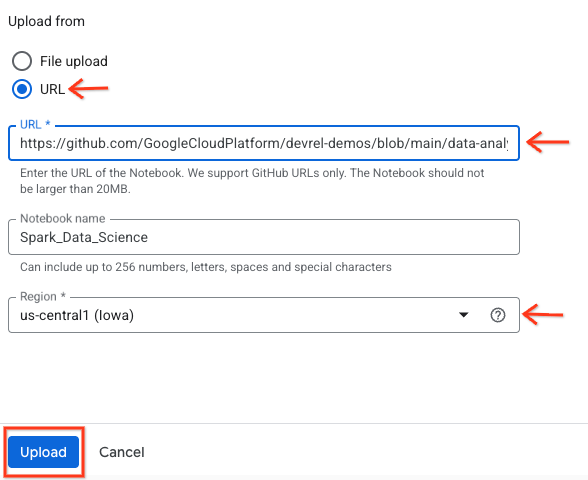
- Para abrir o notebook, clique na seta suspensa no painel Explorer com o nome do ID do projeto. Em seguida, clique no menu suspenso Notebooks. Clique no notebook
Spark_Data_Science.
- Contraia o menu de navegação do BigQuery e o sumário do notebook para ter mais espaço.
3. Conectar-se a um ambiente de execução e executar um código de configuração adicional
- Clique em Conectar. No pop-up, autorize o Colab Enterprise com sua conta de e-mail. O notebook será conectado automaticamente a um ambiente de execução.
- Depois que o ambiente de execução for estabelecido, você verá o seguinte:
- No notebook, role até a seção Configuração. Comece aqui.
4. Executar o código de configuração
Configure seu ambiente com as bibliotecas Python necessárias para concluir o laboratório. Configure o Acesso privado do Google. Criar um bucket de armazenamento Criar um conjunto de dados do BigQuery Copie o ID do projeto para o notebook. Selecione uma região. Para este laboratório, use a região us-central1.
Para executar uma célula de código, passe o cursor dentro do bloco de células e clique na seta.
# Enable APIs
import subprocess
command = [
"gcloud",
"services",
"enable",
"aiplatform.googleapis.com",
"bigquery.googleapis.com",
"bigquerystorage.googleapis.com",
"bigqueryunified.googleapis.com",
"cloudaicompanion.googleapis.com",
"dataproc.googleapis.com",
"run.googleapis.com",
"storage.googleapis.com"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Configure a PROJECT_ID and REGION
PROJECT_ID = "<YOUR_PROJECT_ID>"
REGION = "<YOUR_REGION>"
# Enable Private Google Access
import subprocess
command = [
"gcloud",
"compute",
"networks",
"subnets",
"update",
"default",
f"--region={REGION}",
"--enable-private-ip-google-access"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
# Create a Cloud Storage Bucket
from google.cloud import storage
from google.cloud.exceptions import NotFound
BUCKET_NAME = f"{PROJECT_ID}-demo"
storage_client = storage.Client(project=PROJECT_ID)
try:
bucket = storage_client.get_bucket(BUCKET_NAME)
print(f"Bucket {BUCKET_NAME} already exists.")
except NotFound:
bucket = storage_client.create_bucket(BUCKET_NAME, location=REGION)
print(f"Bucket {BUCKET_NAME} created.")
# Create a BigQuery dataset.
from google.cloud import bigquery
DATASET_ID = f"{PROJECT_ID}.demo"
client = bigquery.Client()
dataset = bigquery.Dataset(DATASET_ID)
dataset.location = REGION
dataset = client.create_dataset(dataset, exists_ok=True)
5. Criar uma conexão com o Google Cloud Serverless para Apache Spark
Usando o Spark Connect, você se conecta a uma sessão do Spark sem servidor para executar jobs interativos do Spark. Você configura o ambiente de execução com o Lightning Engine para ter um desempenho avançado do Spark. O Lightning Engine funciona acelerando as cargas de trabalho usando o Apache Gluten e o Velox.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
session.runtime_config.version = "3.0"
# You can optionally configure Spark properties as well. See https://cloud.google.com/dataproc-serverless/docs/concepts/properties.
session.runtime_config.properties = {
"dataproc.runtime": "premium",
"spark.dataproc.engine": "lightningEngine",
}
# To avoid going over quota in this demo, cap the max number of Spark workers.
session.runtime_config.properties = {
"spark.dynamicAllocation.maxExecutors": "4"
}
spark = (
DataprocSparkSession.builder
.appName("CustomSparkSession")
.dataprocSessionConfig(session)
.getOrCreate()
)
6. Carregar e analisar dados usando o Gemini
Nesta seção, você vai passar pela primeira etapa importante em qualquer projeto de ciência de dados: preparar os dados. Comece carregando dados em um DataFrame do Apache Spark do BigQuery.
# Load the tables
order_items = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.order_items").load()
users = spark.read.format("bigquery").option("table", "bigquery-public-data.thelook_ecommerce.users").load()
# Register temp tables
users.createOrReplaceTempView("users")
order_items.createOrReplaceTempView("order_items")
# Verify temp tables
spark.sql("SELECT * FROM order_items LIMIT 10").show()
Em seguida, use o Gemini para gerar código PySpark para analisar os dados e entender melhor.
Comando 1: usando o PySpark, analise a tabela de usuários e mostre as 10 primeiras linhas.
# prompt: Using PySpark, explore the users table and show the first 10 rows.
users.show(10)
Comando 2: usando o PySpark, analise a tabela order_items e mostre as 10 primeiras linhas.
# prompt: Using PySpark, explore the order_items table and show the first 10 rows.
order_items.show(10)
Comando 3: usando o PySpark, mostre os 5 países mais frequentes na tabela de usuários. Mostre o país e o número de usuários de cada país.
# prompt: Using PySpark, show the top 5 most frequent countries in the users table. Display the country and the number of users from each country.
from pyspark.sql.functions import col, count
users.groupBy("country").agg(count("*").alias("user_count")).orderBy(col("user_count").desc()).limit(5).show()
Comando 4: usando o PySpark, encontre o preço promocional médio dos itens na tabela order_items.
# prompt: Using PySpark, find the average sale price of items in the order_items table.
from pyspark.sql import functions as F
average_sale_price = order_items.agg(F.avg("sale_price").alias("average_sale_price"))
average_sale_price.show()
Comando 5: usando a tabela "users", gere código para plotar o país em relação à origem do tráfego usando uma biblioteca de plotagem adequada.
# prompt: Using the table "users", generate code to plot country vs traffic source using a suitable plotting library.
sql = """
SELECT
country,
traffic_source
FROM
`bigquery-public-data.thelook_ecommerce.users`
WHERE country IS NOT NULL AND traffic_source IS NOT NULL
"""
project_id = "iceberg-summit-2025"
df = pandas_gbq.read_gbq(sql, project_id=project_id, dialect="standard")
import matplotlib.pyplot as plt
import seaborn as sns
# Group by country and traffic_source and count occurrences
df_grouped = df.groupby(['country', 'traffic_source']).size().reset_index(name='count')
# Create a pivot table for easier plotting
pivot_table = df_grouped.pivot(index='country', columns='traffic_source', values='count').fillna(0)
# Plotting
plt.figure(figsize=(15, 8))
pivot_table.plot(kind='bar', stacked=True, figsize=(15, 8))
plt.title('Traffic Source Distribution by Country')
plt.xlabel('Country')
plt.ylabel('Number of Users')
plt.xticks(rotation=90)
plt.legend(title='Traffic Source')
plt.tight_layout()
plt.show()
Comando 6:crie um histograma mostrando a distribuição de "idade", "país", "gênero", "origem_do_tráfego".
# prompt: Create a histogram showing the distribution of "age", "country", "gender", "traffic_source".
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for visualization
users_pd = users.toPandas()
# Create histograms for 'age', 'country', 'gender', 'traffic_source'
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('Distribution of User Attributes')
# Age distribution
axes[0, 0].hist(users_pd['age'].dropna(), bins=20, edgecolor='black')
axes[0, 0].set_title('Age Distribution')
axes[0, 0].set_xlabel('Age')
axes[0, 0].set_ylabel('Number of Users')
# Country distribution
users_pd['country'].value_counts().head(10).plot(kind='bar', ax=axes[0, 1])
axes[0, 1].set_title('Top 10 Countries Distribution')
axes[0, 1].set_xlabel('Country')
axes[0, 1].set_ylabel('Number of Users')
axes[0, 1].tick_params(axis='x', rotation=45)
# Gender distribution
users_pd['gender'].value_counts().plot(kind='bar', ax=axes[1, 0])
axes[1, 0].set_title('Gender Distribution')
axes[1, 0].set_xlabel('Gender')
axes[1, 0].set_ylabel('Number of Users')
axes[1, 0].tick_params(axis='x', rotation=0)
# Traffic Source distribution
users_pd['traffic_source'].value_counts().head(10).plot(kind='bar', ax=axes[1, 1])
axes[1, 1].set_title('Top 10 Traffic Source Distribution')
axes[1, 1].set_xlabel('Traffic Source')
axes[1, 1].set_ylabel('Number of Users')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
7. Preparação de dados e engenharia de atributos
Em seguida, realize a engenharia de atributos nos dados. Selecione as colunas apropriadas, transforme os dados em tipos de dados mais adequados e identifique uma coluna de rótulo.
features = spark.sql("""
SELECT
CAST(u.age AS DOUBLE) AS age,
CAST(hash(u.country) AS BIGINT) * 1.0 AS country_hash,
CAST(hash(u.gender) AS BIGINT) * 1.0 AS gender_hash,
CAST(hash(u.traffic_source) AS BIGINT) * 1.0 AS traffic_source_hash,
CASE WHEN COUNT(oi.id) > 0 THEN 1 ELSE 0 END AS label -- Changed label generation to count order items
FROM users AS u
LEFT JOIN order_items AS oi
ON u.id = oi.user_id
GROUP BY u.id, u.age, u.country, u.gender, u.traffic_source
""")
features.show()
8. Treinar um modelo de regressão logística
Usando o MLlib, você treina um modelo de regressão logística. Primeiro, use um VectorAssembler para converter os dados em um formato de vetor. Em seguida, StandardScaler dimensiona a coluna de recursos para melhorar a performance. Em seguida, crie uma referência a um modelo LogisticRegression e defina hiperparâmetros. Você combina essas etapas em um objeto Pipeline, treina o modelo usando a função fit() e transforma os dados usando a função transform().
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.pipeline import Pipeline
from pyspark.ml.functions import array_to_vector
#Split Train and Test Data (80:20)
train_data, test_data = features.randomSplit([0.8, 0.2], seed=42)
# Initialize VectorAssembler
assembler = VectorAssembler(
inputCols=["age", "country_hash", "gender_hash", "traffic_source_hash"],
outputCol="assembled_features"
)
# Initialize StandardScaler
scaler = StandardScaler(inputCol="assembled_features", outputCol="scaled_features")
# Initialize Logistic Regression model
lr = LogisticRegression(
maxIter=100,
regParam=0.2,
threshold=0.8,
featuresCol="scaled_features",
labelCol="label"
)
# Define pipeline
pipeline = Pipeline(stages=[assembler, scaler, lr])
# Fit the model
pipeline_model = pipeline.fit(train_data)
# Transform the dataset using the trained model
transformed_dataset = pipeline_model.transform(test_data)
transformed_dataset.show()
9. Avaliação do modelo
Avalie o conjunto de dados recém-transformado. Gere a área de métrica de avaliação sob a curva (AUC).
# Model evaluation
eva = BinaryClassificationEvaluator(metricName="areaUnderPR")
aucPR = eva.evaluate(transformed_dataset)
print(f"AUC PR: {aucPR}")
Em seguida, use o Gemini para gerar código PySpark para visualizar a saída do modelo.
Comando 1:gere código para plotar a curva de precisão-recall (PR). Calcule a precisão e o recall das previsões do modelo e mostre a curva de PR usando uma biblioteca de plotagem adequada.
# prompt: Generate code to plot the Precision-Recall (PR) curve. Calculate precision and recall from the model's predictions and display the PR curve using a suitable plotting library.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, auc
# Extract predictions and labels
predictions = transformed_dataset.select("prediction", "label").toPandas()
# Calculate precision and recall
precision, recall, _ = precision_recall_curve(predictions["label"], predictions["prediction"])
# Calculate AUC-PR
pr_auc = auc(recall, precision)
# Plot the PR curve
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, color='blue', lw=2, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
Comando 2:gere código para criar uma visualização da matriz de confusão. Calcule a matriz de confusão das previsões do modelo e mostre-a como um mapa de calor ou uma tabela com contagens de verdadeiros positivos (VP), verdadeiros negativos (VN), falsos positivos (FP) e falsos negativos (FN).
# prompt: Generate code to create a confusion matrix visualization. Calculate the confusion matrix from the model's predictions and display it as a heat map or a table with counts of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Extract predictions and labels
predictions_and_labels = transformed_dataset.select("prediction", "label").toPandas()
# Calculate the confusion matrix
cm = confusion_matrix(predictions_and_labels["label"], predictions_and_labels["prediction"])
# Create a DataFrame for better visualization
cm_df = pd.DataFrame(cm,
index=['Actual Negative', 'Actual Positive'],
columns=['Predicted Negative', 'Predicted Positive'])
# Display the confusion matrix as a table
print("Confusion Matrix:")
print(cm_df)
# Display the confusion matrix as a heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(cm_df, annot=True, fmt='d', cmap='Blues', cbar=False, linewidths=.5)
plt.title('Confusion Matrix')
plt.ylabel('Actual Label')
plt.xlabel('Predicted Label')
plt.show()
# Calculate and display TP, TN, FP, FN
TN, FP, FN, TP = cm.ravel()
print(f"
True Positives (TP): {TP}")
print(f"True Negatives (TN): {TN}")
print(f"False Positives (FP): {FP}")
print(f"False Negatives (FN): {FN}")
10. Gravar previsões no BigQuery
Use o Gemini para gerar código para gravar suas previsões em uma nova tabela no conjunto de dados do BigQuery.
Comando:usando o Spark, grave o conjunto de dados transformado no BigQuery.
# prompt: Using Spark, write the transformed dataset to BigQuery.
transformed_dataset.write.format("bigquery").option("table", f"{PROJECT_ID}.demo.predictions").mode("overwrite").save()
11. Salvar o modelo no Cloud Storage
Usando a funcionalidade nativa do MLlib, salve o modelo no Cloud Storage. O servidor de inferência carrega o modelo daqui.
MODEL_PATH = "models/prediction_model"
pipeline_model.write().overwrite().save(f"gs://{BUCKET_NAME}/{MODEL_PATH}")
12. Criar um servidor de inferência
O Cloud Run é uma ferramenta flexível para executar apps da Web sem servidor. Ele usa contêineres do Docker para oferecer aos usuários a máxima personalização. Para este laboratório, um Dockerfile é configurado para executar um app Flask que alimenta o PySpark. Esse contêiner é executado no Cloud Run para realizar a inferência nos dados de entrada. O código dele pode ser encontrado aqui.
Clone o repositório com o código do servidor de inferência.
!git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
Confira o Dockerfile.
FROM python:3.12-slim
# Install OpenJDK-21 (Required for Spark)
RUN apt-get update && \
apt-get install -y openjdk-21-jre-headless procps && \
rm -rf /var/lib/apt/lists/*
ENV JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64
ENV PORT=8080
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "--workers", "1", "--threads", "8", "--timeout", "0", "main:app"]
Confira o código Python do servidor.
import os
import json
import logging
from flask import Flask, request, jsonify
from google.cloud import storage
from pyspark.ml import PipelineModel
from pyspark.sql import SparkSession
from pyspark.sql.functions import hash, col
# Configure basic logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- Initialization: Spark and Model Loading ---
GCS_BUCKET = os.environ.get("GCS_BUCKET")
GCS_MODEL_PATH = os.environ.get("GCS_MODEL_PATH")
LOCAL_MODEL_PATH = "/tmp/model"
try:
spark = SparkSession.builder \
.appName("CloudRunSparkService") \
.master("local[*]") \
.getOrCreate()
logging.info("Spark Session successfully initialized.")
except Exception as e:
logging.error(f"Failed to initialize Spark Session: {e}")
raise
def download_directory(bucket_name, prefix, local_path):
"""Downloads a directory from GCS to local filesystem."""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blobs = list(bucket.list_blobs(prefix=prefix))
if len(blobs) == 0:
logging.error(f"No files found in GCS bucket {bucket_name} at prefix {prefix}")
return
for blob in blobs:
if blob.name.endswith("/"): continue # Skip directories
# Structure local paths
relative_path = os.path.relpath(blob.name, prefix)
local_file_path = os.path.join(local_path, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
blob.download_to_filename(local_file_path)
print(f"Model downloaded to {local_path}")
# Load model
def load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH):
"""Download and load model on startup to avoid latency per request."""
global MODEL
if not os.path.exists(LOCAL_MODEL_PATH):
download_directory(GCS_BUCKET, GCS_MODEL_PATH, LOCAL_MODEL_PATH)
logging.info(f"Loading PySpark model from {GCS_MODEL_PATH}")
# Load the Spark ML model
try:
MODEL = PipelineModel.load(LOCAL_MODEL_PATH)
logging.info("Spark model loaded successfully.")
except Exception as e:
logging.error(f"Failed to load model: {e}")
raise
# Load Model on Startup
load_model(LOCAL_MODEL_PATH, GCS_BUCKET, GCS_MODEL_PATH)
# --- Flask Application Setup ---
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
"""
Handles incoming POST requests for inference.
Expects JSON data that can be converted into a Spark DataFrame.
"""
if MODEL is None:
return jsonify({"error": "Model failed to load at startup."}), 500
try:
# 1. Get data from the request
data = request.get_json()
# 2. Check length of list
data_len = len(data)
cap = 100
if data_len > cap:
return jsonify({"error": f"Too many records. Count: {data_len}, Max: {cap}"}), 400
# 2. Create Spark DataFrame
df = spark.createDataFrame(data)
# 3. Transform data
input_df = df.select(
col("age").cast("DOUBLE").alias("age"),
(hash(col("country")).cast("BIGINT") * 1.0).alias("country_hash"),
(hash(col("gender")).cast("BIGINT") * 1.0).alias("gender_hash"),
(hash(col("traffic_source")).cast("BIGINT") * 1.0).alias("traffic_source_hash")
)
# 3. Perform Inference
predictions_df = MODEL.transform(input_df)
# 4. Prepare results (collect and serialize)
results = [p.prediction for p in predictions_df.select("prediction").collect()]
# 5. Return JSON response
return jsonify({"predictions": results})
except Exception as e:
logging.error(f"An error occurred during prediction: {e}")
#return jsonify({"error": str(e)}), 500
raise e
# Gunicorn entry point uses 'app' from this file
if __name__ == '__main__':
# Local testing only: Cloud Run uses Gunicorn/CMD command
app.run(host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
Implante o servidor de inferência.
import subprocess
command = [
"gcloud",
"run",
"deploy",
"inference-server",
"--source",
"/content/devrel-demos/data-analytics/dataproc-webinar/data-science/inference-server",
"--region",
f"{REGION}",
"--port",
"8080",
"--memory",
"2Gi",
"--allow-unauthenticated",
"--set-env-vars",
f"GCS_BUCKET={BUCKET_NAME},GCS_MODEL_PATH={MODEL_PATH}",
"--startup-probe",
"tcpSocket.port=8080,initialDelaySeconds=240,failureThreshold=3,timeoutSeconds=240,periodSeconds=240"
]
result = subprocess.run(command, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
Copie o URL do servidor de inferência da saída para uma nova variável. Ele será semelhante a https://inference-server-123456789.us-central1.run.app.
INFERENCE_SERVER_URL = "<YOUR_SERVER_URL>"
Teste o servidor de inferência.
import requests
age = "25.0"
country = "United States"
traffic_source = "Search"
gender = "F"
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
print(response.json())
A saída precisa ser 1.0 ou 0.0.
{'predictions': [1.0]}
13. Configurar um agente
Use o Agent Engine para criar um agente que possa realizar a inferência. O Agent Engine faz parte da plataforma Vertex AI, um conjunto de serviços que permite aos desenvolvedores implantar, gerenciar e escalonar agentes de IA em produção. Ele tem muitas ferramentas, incluindo avaliação de agentes, contextos de sessão e execução de código. Ele oferece suporte a muitos frameworks de agentes conhecidos, incluindo o Kit de Desenvolvimento de Agente (ADK). O ADK é um framework de agente de código aberto que, embora criado e otimizado para uso com o Gemini e o ecossistema do Google, é agnóstico do modelo. Ele foi projetado para tornar o desenvolvimento de agentes mais parecido com o desenvolvimento de software.
Inicialize o cliente da Vertex AI.
import vertexai
from vertexai import agent_engines # For the prebuilt templates
client = vertexai.Client( # For service interactions via client.agent_engines
project=f"{PROJECT_ID}",
location=f"{REGION}",
)
Defina uma função para consultar o modelo implantado.
def predict_purchase(
age: str = "25.0",
country: str = "United States",
traffic_source: str = "Search",
gender: str = "M",
):
"""Predicts whether or not a user will purchase a product.
Args:
age: The age of the user.
country: The country of the user. One of: "China", "Poland", "Germany", "United States", "Spain", "United Kingdom", "España", "Japan", "Brasil", "Colombia", "Belgium", "South Korea", "Austria", "France", "Australia".
Traffic_source: The source of the user's traffic. One of: "Display", "Email", "Search", "Organic", "Facebook".
gender: The gender of the user. One of: "M" or "F".
Returns:
True if the model output is 1.0, False otherwise.
"""
import requests
response = requests.post(
f"{INFERENCE_SERVER_URL}/predict",
json=[{"age": age, "country": country, "traffic_source": traffic_source, "gender": gender}],
headers={"Content-Type": "application/json"}
)
return response.json()
Teste a função transmitindo parâmetros de amostra.
predict_purchase(age=25.0, country="United States", traffic_source="Search", gender="M")
Usando o ADK, defina um agente abaixo e forneça a função predict_purchase como uma ferramenta.
from google.adk.agents import Agent
from vertexai import agent_engines
agent = Agent(
model="gemini-2.5-flash",
name='purchase_prediction_agent',
tools=[predict_purchase]
)
Teste o agente localmente transmitindo uma consulta.
app = agent_engines.AdkApp(agent=agent)
async for event in app.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
Implante o modelo no Agent Engine.
remote_agent = client.agent_engines.create(
agent=app,
config={
"requirements": ["google-cloud-aiplatform[agent_engines,adk]"],
"staging_bucket": f"gs://{BUCKET_NAME}",
"display_name": "purchase-predictor",
"description": "Agent that predicts whether or not a user will purchase a product.",
}
)
Depois de concluir, confira o modelo implantado no console do Cloud.
Consulte o modelo novamente. Agora, ele aponta para o agente implantado em vez da versão local.
async for event in remote_agent.async_stream_query(
user_id="123",
message="Will a 25 yo male from the United States who came from Search make a purchase? Strictly output 'yes' or 'no'.",
):
try:
print(event['content']['parts'][0]['text'])
except:
continue
14. Liberar espaço
Exclua todos os recursos do Google Cloud que você criou. A execução de comandos de limpeza como esse é uma prática recomendada essencial para evitar cobranças futuras.
# Delete the deployed agent.
remote_agent.delete(force=True)
# Delete the inference server.
import subprocess
command = [
"gcloud",
"run",
"services",
"delete",
"inference-server",
"--region",
f"{REGION}",
"--quiet"
]
subprocess.run(command, capture_output=True, text=True)
# Delete the BigQuery dataset.
bigquery_client = bigquery.Client()
bigquery_client.delete_dataset(
f"{PROJECT_ID}.demo", delete_contents=True, not_found_ok=True
)
# Delete the Storage bucket.
storage_client = storage.Client()
bucket = storage_client.get_bucket(BUCKET_NAME)
bucket.delete_blobs(list(bucket.list_blobs()))
bucket.delete()
15. Parabéns!
Parabéns! Neste codelab, você fez o seguinte:
- Usou notebooks do BigQuery Studio para executar um fluxo de trabalho de ciência de dados.
- Criou uma conexão com o Apache Spark usando Google Cloud Serverless para Apache Spark e com tecnologia Spark Connect.
- Usou o Lightning Engine para acelerar as cargas de trabalho do Apache Spark em até 4,3 vezes.
- Carregou dados do BigQuery usando a integração integrada entre o Apache Spark e o BigQuery.
- Analisou os dados usando a geração de código assistida pelo Gemini.
- Realizou a engenharia de atributos usando o framework de processamento de dados do Apache Spark.
- Treinou e avaliou um modelo de classificação usando a biblioteca de machine learning nativa do Apache Spark, MLlib.
- Implantou um servidor de inferência para o modelo de classificação usando o Flask e o Cloud Run.
- Implantou um agente para consultar o servidor de inferência usando linguagem natural com Agent Engine e o Kit de Desenvolvimento de Agente (ADK).
Qual é a próxima etapa?
- Saiba mais sobre o Google Cloud Serverless para Apache Spark.
- Saiba como configurar Cloud Run.
- Leia sobre o Agent Engine.