
1. نظرة عامة
في هذا الدرس التطبيقي حول الترميز، ستنشئ تطبيقًا قابلاً للتوسّع للبحث في "قاعدة المعلومات". بدلاً من إدارة مسار معقّد لاستخراج البيانات وتحويلها وتحميلها باستخدام نصوص برمجية وحلقات Python لإنشاء تضمينات المتّجهات، ستستخدم AlloyDB AI للتعامل مع إنشاء عمليات التضمين بشكلٍ أصلي داخل قاعدة البيانات باستخدام أمر SQL واحد.
ما ستنشئه
تطبيق قاعدة بيانات "قابل للبحث" وعالي الأداء لقاعدة المعلومات
أهداف الدورة التعليمية
ستتعرّف على كيفية:
- توفير مجموعة AlloyDB وتفعيل إضافات الذكاء الاصطناعي
- إنشاء بيانات اصطناعية (أكثر من 50,000 صف) باستخدام SQL
- إعادة ملء تضمينات المتجهات لمجموعة البيانات بأكملها باستخدام المعالجة المجمّعة
- إعداد المشغّلات التزايدية في الوقت الفعلي لتضمين البيانات الجديدة تلقائيًا
- إجراء بحث مختلط (متّجه + فلاتر SQL) عن "سياق مرن"
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud. كيفية التحقّق من تفعيل الفوترة في مشروع
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من إكمال عملية المصادقة وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة: اتّبِع الرابط وفعِّل واجهات برمجة التطبيقات.
بدلاً من ذلك، يمكنك استخدام أمر gcloud لهذا الغرض. راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
المشاكل المحتملة وتحديد المشاكل وحلّها
متلازمة "المشروع الوهمي" | نفّذت الأمر |
حاجز الفوترة | لقد فعّلت المشروع، ولكن نسيت حساب الفوترة. AlloyDB هو محرّك عالي الأداء، ولن يبدأ إذا كان "خزان الوقود" (الفوترة) فارغًا. |
تأخّر في نشر واجهة برمجة التطبيقات | نقرت على "تفعيل واجهات برمجة التطبيقات"، ولكن سطر الأوامر لا يزال يعرض |
Quota Quags | إذا كنت تستخدم حسابًا تجريبيًا جديدًا تمامًا، قد تبلغ حصة إقليمية لمثيلات AlloyDB. إذا تعذّر تنفيذ |
وكيل الخدمة"مخفي" | في بعض الأحيان، لا يتم منح دور |
3- إعداد قاعدة البيانات
في هذا التمرين العملي، سنستخدم AlloyDB كقاعدة بيانات لبيانات الاختبار. يستخدم المجموعات للاحتفاظ بجميع الموارد، مثل قواعد البيانات والسجلات. تحتوي كل مجموعة على مثيل أساسي يوفّر نقطة وصول إلى البيانات. ستحتوي الجداول على البيانات الفعلية.
لننشئ مجموعة ومثيل وجدول AlloyDB سيتم تحميل مجموعة البيانات الاختبارية فيها.
- انقر على الزر أو انسخ الرابط أدناه إلى المتصفّح الذي سجّلت فيه الدخول إلى حساب مستخدم Google Cloud Console.
- بعد إكمال هذه الخطوة، سيتم استنساخ المستودع إلى محرّر Cloud Shell المحلي، وستتمكّن من تنفيذ الأمر أدناه من داخل مجلد المشروع (من المهم التأكّد من أنّك في دليل المشروع):
sh run.sh
- استخدِم الآن واجهة المستخدم (من خلال النقر على الرابط في الوحدة الطرفية أو على الرابط "معاينة على الويب" في الوحدة الطرفية).
- أدخِل تفاصيل معرّف المشروع واسمَي المجموعة والآلة الافتراضية لبدء الاستخدام.
- يمكنك تناول القهوة أثناء تصفّح السجلات، ويمكنك الاطّلاع على كيفية تنفيذ ذلك في الخلفية هنا. قد تستغرق هذه العملية من 10 إلى 15 دقيقة تقريبًا.
المشاكل المحتملة وتحديد المشاكل وحلّها
مشكلة "الصبر" | مجموعات قواعد البيانات هي بنية تحتية ثقيلة. إذا أعَدت تحميل الصفحة أو أغلقت جلسة Cloud Shell لأنّها "تبدو عالقة"، قد ينتهي بك الأمر إلى إنشاء آلة افتراضية "وهمية" تم توفيرها جزئيًا ولا يمكن حذفها بدون تدخّل يدوي. |
عدم تطابق المنطقة | إذا فعّلت واجهات برمجة التطبيقات في |
مجموعات الأجهزة غير النشطة | إذا سبق لك استخدام الاسم نفسه لمجموعة ولم تحذفها، قد تشير البرمجة النصية إلى أنّ اسم المجموعة متوفّر حاليًا. يجب أن تكون أسماء المجموعات مختلفة ضمن المشروع الواحد. |
مهلة Cloud Shell | إذا استغرقت استراحة القهوة 30 دقيقة، قد يتم تشغيل وضع السكون في Cloud Shell وفصل عملية |
4. توفير المخطط
في هذه الخطوة، سنتناول ما يلي:
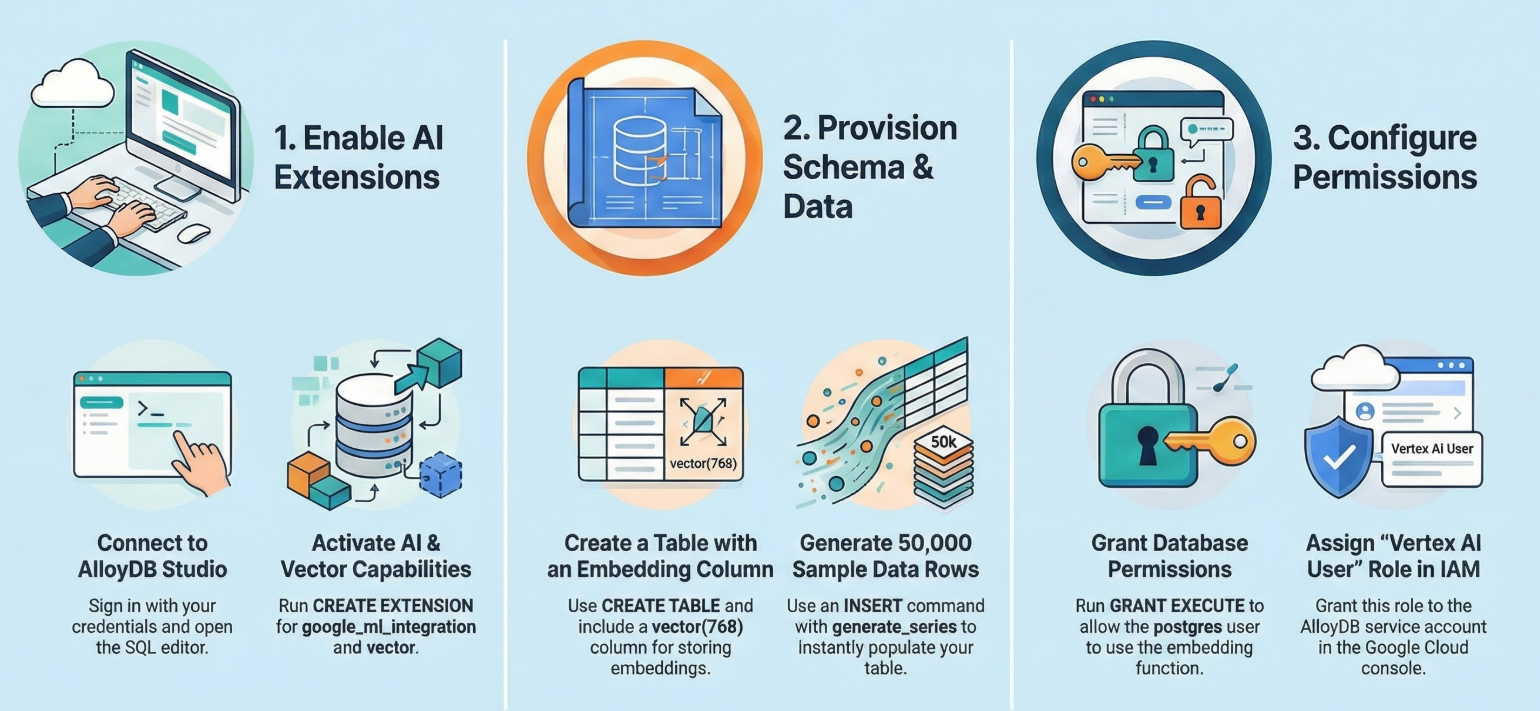
بعد تشغيل مجموعة AlloyDB ومثيلها، انتقِل إلى أداة تعديل لغة الاستعلامات البنيوية (SQL) في AlloyDB Studio لتفعيل إضافات الذكاء الاصطناعي وتوفير المخطط.
قد تحتاج إلى الانتظار إلى حين اكتمال عملية إنشاء الجهاز الظاهري. بعد ذلك، سجِّل الدخول إلى AlloyDB باستخدام بيانات الاعتماد التي أنشأتها عند إنشاء المجموعة. استخدِم البيانات التالية للمصادقة على PostgreSQL:
- اسم المستخدم : "
postgres" - قاعدة البيانات : "
postgres" - كلمة المرور : "
alloydb" (أو أي كلمة مرور تم ضبطها عند إنشاء الحساب)
بعد إكمال عملية المصادقة بنجاح في AlloyDB Studio، يتم إدخال أوامر SQL في "المحرّر". يمكنك إضافة نوافذ "المحرّر" متعددة باستخدام علامة الجمع على يسار النافذة الأخيرة.
ستُدخل أوامر AlloyDB في نوافذ المحرّر، باستخدام الخيارات "تشغيل" و"تنسيق" و"محو" حسب الحاجة.
تفعيل الإضافات
لإنشاء هذا التطبيق، سنستخدم الإضافتين pgvector وgoogle_ml_integration. تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث عنها. توفّر إضافة google_ml_integration وظائف يمكنك استخدامها للوصول إلى نقاط نهاية التوقّع في Vertex AI من أجل الحصول على توقّعات في SQL. فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
إنشاء جدول
نحتاج إلى مجموعة بيانات لتوضيح المقياس. بدلاً من استيراد ملف CSV، سننشئ 50,000 صف من "مقالات المساعدة" الاصطناعية على الفور باستخدام SQL.
يمكنك إنشاء جدول باستخدام عبارة DDL أدناه في AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
سيسمح العمود item_vector بتخزين قيم المتّجه للنص.
تحقَّق من البيانات:
SELECT count(*) FROM help_articles;
-- Output: 50000
تفعيل علامات قاعدة البيانات
انتقِل إلى وحدة تحكّم إعدادات المثيل، وانقر على "تعديل المثيل الأساسي"، ثم انتقِل إلى "الإعدادات المتقدّمة" وانقر على "إضافة علامات قاعدة البيانات".
إذا لم يكن كذلك، أدخِلها في القائمة المنسدلة الخاصة بالعلامات واضبطها على "مفعَّلة" ثم حدِّث المثيل.
إذا لم يكن كذلك، أدخِلها في القائمة المنسدلة الخاصة بالعلامات واضبطها على "مفعَّلة" ثم حدِّث المثيل.
خطوات ضبط علامات قاعدة البيانات:
- في Google Cloud Console، انتقِل إلى صفحة "المجموعات".
- انقر على مجموعة في عمود اسم المورد.
- في صفحة نظرة عامة، انتقِل إلى الآلات الافتراضية في مجموعتك، واختَر آلة افتراضية، ثم انقر على تعديل.
- إضافة علامة قاعدة بيانات أو تعديلها أو حذفها من مثيلك:
إضافة علم
- لإضافة علامة قاعدة بيانات إلى مثيلك، انقر على "إضافة علامة".
- اختَر علامة من قائمة "علامة قاعدة البيانات الجديدة".
- أدخِل قيمة للعَلم.
- انقر على "تم".
- انقر على تعديل الجهاز الافتراضي.
- تأكَّد من أنّ الإصدار 1.5.2 أو إصدار أحدث من إضافة google_ml_integration مثبّت:
للاطّلاع على إصدار الإضافة، استخدِم الأمر التالي:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
إذا كنت بحاجة إلى ترقية الإضافة إلى إصدار أحدث، استخدِم الأمر التالي:
ALTER EXTENSION google_ml_integration UPDATE;
منح الإذن
- للسماح لأحد المستخدمين بإدارة عملية إنشاء عمليات التضمين التلقائي، امنحه أذونات INSERT وUPDATE وDELETE على الجدولَين google_ml.embed_gen_progress وgoogle_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
postgres هو USER_NAME الذي تم منح الأذونات له.
- نفِّذ العبارة أدناه لمنح إذن التنفيذ على الدالة "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
من وحدة تحكّم Google Cloud IAM، امنح حساب خدمة AlloyDB (الذي يبدو على النحو التالي: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) إذن الوصول إلى الدور "مستخدم Vertex AI". سيحتوي PROJECT_NUMBER على رقم مشروعك.
بدلاً من ذلك، يمكنك تنفيذ الأمر أدناه من "وحدة Cloud Shell الطرفية":
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
المشاكل المحتملة وتحديد المشاكل وحلّها
حلقة "فقدان الذاكرة بشأن كلمة المرور" | إذا استخدمت عملية الإعداد "بنقرة واحدة" ولم تتمكّن من تذكُّر كلمة المرور، انتقِل إلى صفحة "المعلومات الأساسية للمثيل" في وحدة التحكّم وانقر على "تعديل" لإعادة ضبط كلمة مرور |
رسالة الخطأ "لم يتم العثور على الإضافة" | إذا تعذّر تنفيذ |
5- إنشاء رسومات متجهة "بطلقة واحدة"
هذا هو جوهر المختبر. بدلاً من كتابة حلقة Python لمعالجة هذه الصفوف البالغ عددها 50,000، سنستخدم الدالة ai.initialize_embeddings.
ينفّذ هذا الأمر الفردي الإجراءَين التاليَين:
- تعبئة جميع الصفوف الحالية
- إنشاء مشغّل لتضمين الصفوف المستقبلية تلقائيًا
نفِّذ عبارة SQL أدناه من "محرّر طلبات البحث" في AlloyDB
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
التحقّق من عمليات التضمين
تأكَّد من أنّه تم الآن ملء العمود embedding:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
يجب أن تظهر لك نتيجة مشابهة لما يلي:
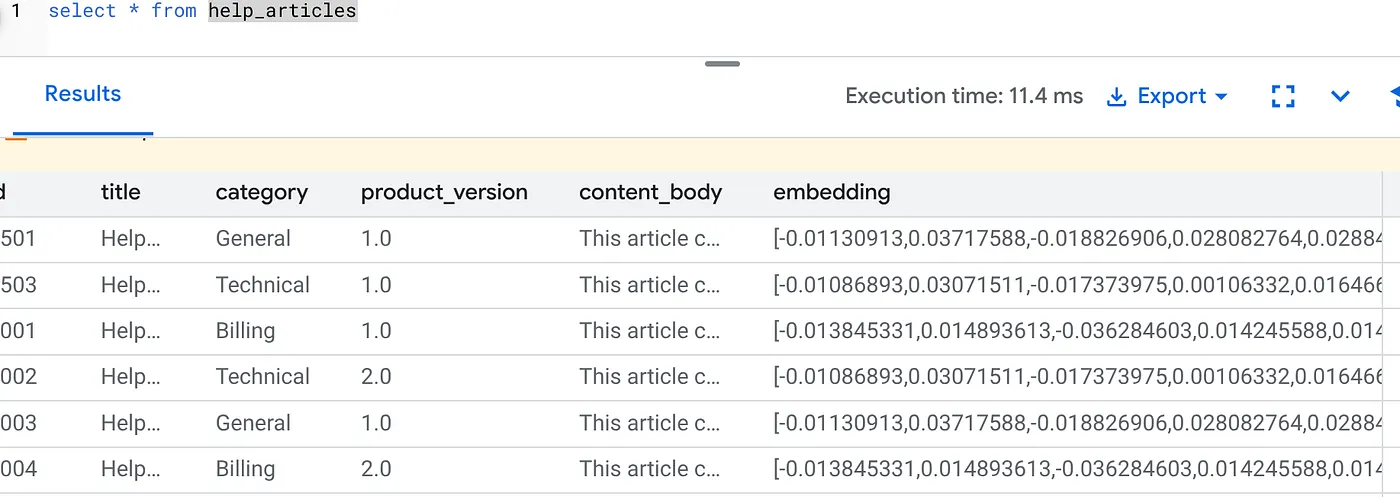
ما الذي حدث للتو؟
- تعبئة البيانات السابقة على نطاق واسع: يتم تلقائيًا البحث في الصفوف الحالية البالغ عددها 50,000 صف وإنشاء عمليات التضمين من خلال Vertex AI.
- التشغيل الآلي: من خلال ضبط incremental_refresh_mode => 'transactional'، تعمل AlloyDB تلقائيًا على إعداد المشغّلات الداخلية. سيتم إنشاء التضمين على الفور لأي صف جديد يتم إدراجه في help_articles.
- يمكنك اختياريًا ضبط incremental_refresh_mode => ‘None' حتى تتمكّن من الحصول على البيان لإجراء تعديلات مجمّعة واستدعاء ai.refresh_embeddings() يدويًا لتعديل جميع تضمينات الصفوف.
لقد استبدلت للتو قائمة انتظار Kafka وعاملاً في Python ونص برمجي لنقل البيانات بـ 6 أسطر من SQL. إليك المستندات الرسمية التفصيلية لجميع السمات.
اختبار المشغّل في الوقت الفعلي
لنتأكّد من أنّ ميزة "التكرار الصفري" التلقائية تعمل مع البيانات الجديدة.
- إدراج صف جديد:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- التحقّق على الفور:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
النتيجة:
من المفترض أن يظهر لك الرسم المتجهي الذي تم إنشاؤه على الفور بدون تشغيل أي نص برمجي خارجي.
حجم الدفعة للضبط
يتم حاليًا ضبط حجم الدفعة تلقائيًا في AlloyDB على 50. على الرغم من أنّ الإعدادات التلقائية تعمل بشكل رائع فور استخدامها، تتيح AlloyDB للمستخدمين التحكّم في ضبط الإعدادات المثالية للنموذج ومجموعة البيانات الفريدَين.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
ومع ذلك، يجب أن يكون المستخدمون على دراية بحدود الحصة التي يمكن أن تحدّ من الأداء. لمراجعة حصص AlloyDB المقترَحة، راجِع القسم "قبل البدء" في المستندات.
المشاكل المحتملة وتحديد المشاكل وحلّها
فجوة نشر إدارة الهوية وإمكانية الوصول | لقد نفّذت أمر |
عدم تطابق سمة المتّجه | تم ضبط الجدول |
6. تعديل "البحث السياقي"
الآن، سننفّذ بحثًا مختلطًا. نحن نجمع بين الفهم الدلالي (المتجه) ومنطق النشاط التجاري (فلاتر SQL).
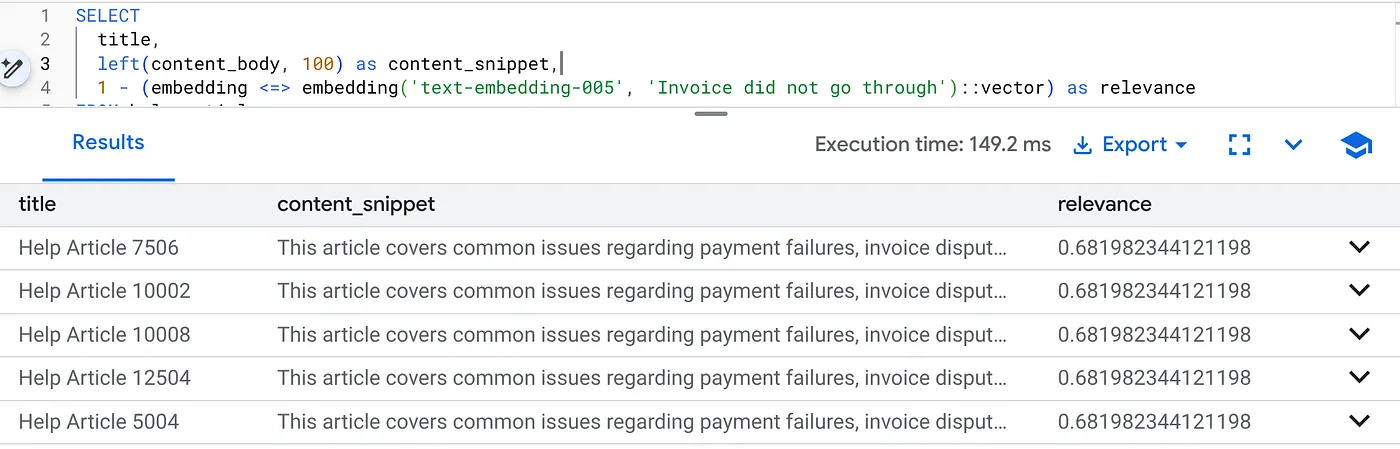
نفِّذ طلب البحث هذا للعثور على مشاكل الفوترة الخاصة بالإصدار 2.0 من المنتج:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
هذه هي ميزة "تكييف السياق". تتكيّف عملية البحث لفهم قصد المستخدم ("مشاكل الفوترة") مع مراعاة القيود الصارمة للنشاط التجاري (الإصدار 2.0).
أسباب أهمية هذه الميزة للشركات الناشئة وعمليات نقل البيانات
- عدم وجود ديون متعلقة بالبنية الأساسية: لم يتم إنشاء قاعدة بيانات متجهات منفصلة (Pinecone/Milvus). لم تكتب مهمة ETL منفصلة. يتم تخزين كل البيانات في Postgres.
- التعديلات في الوقت الفعلي: باستخدام وضع "المعاملات"، لن يصبح فهرس البحث قديمًا أبدًا. عندما يتم إدخال البيانات، تصبح جاهزة للاستخدام كمتجهات.
- قابلية التوسّع: تم إنشاء AlloyDB على بنية Google الأساسية. يمكنه التعامل مع الإنشاء المجمّع لملايين المتجهات بشكل أسرع من أي نص برمجي بلغة Python.
المشاكل المحتملة وتحديد المشاكل وحلّها
مشكلة في أداء الإنتاج | المشكلة: سرعة معالجة 50,000 صف بطيء جدًا لمليون صف إذا لم يكن فلتر الفئة انتقائيًا بدرجة كافية.الحل:أضِف فهرسًا متّجهيًا: بالنسبة إلى نطاق الإنتاج، عليك إنشاء فهرس:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);التحقّق من استخدام الفهرس: شغِّل |
كارثة "عدم تطابق النماذج" | المشكلة: تمّت تهيئة العمود باستخدام text-embedding-005 في إجراء CALL. إذا استخدمت عن طريق الخطأ نموذجًا مختلفًا (مثل text-embedding-004 أو نموذج مفتوح المصدر) في الدالة SELECT query embedding('model-name', ...)، قد تتطابق السمات (768)، ولكن ستكون مساحة المتجهات مختلفة تمامًا. سيتم تنفيذ طلب البحث بدون حدوث خطأ، ولكن ستكون النتائج غير ذات صلة تمامًا (ستكون نتائج قياس الصلة غير صالحة). لتحديد المشاكل وحلّها، تأكَّد من أنّ model_id في ai.initialize_embeddings يتطابق تمامًا مع model_id في طلب البحث SELECT. |
نتيجة "الفراغ الصامت" (الإفراط في الفلترة) | المشكلة: البحث المختلط هو عملية "AND". يتطلّب ذلك المطابقة الدلالية ومطابقة SQL.إذا بحث مستخدم عن "مساعدة بشأن الفوترة" ولكن عمود
|
4. أخطاء الأذونات/الحصص (الخطأ 500) | المشكلة:تُجري الدالة
|
5- التضمينات الخالية | المشكلة:إذا أدرجت بيانات قبل اكتمال تهيئة النموذج بالكامل أو إذا تعذّر على المنفِّذ في الخلفية، قد تحتوي بعض الصفوف على
|
7. تَنظيم
بعد الانتهاء من هذا المختبر، لا تنسَ حذف مجموعة AlloyDB ونسختها.
يجب أن يؤدي ذلك إلى تنظيف المجموعة مع مثيلاتها.
8. تهانينا
لقد أنشأت بنجاح تطبيق بحث قابل للتوسّع في "قاعدة المعلومات". بدلاً من إدارة مسار معقّد لاستخراج البيانات وتحويلها وتحميلها باستخدام نصوص برمجية وحلقات Python لإنشاء تضمينات المتّجهات، استخدمت AlloyDB AI للتعامل مع إنشاء التضمينات بشكلٍ أصلي داخل قاعدة البيانات باستخدام أمر SQL واحد.
المواضيع التي تناولناها
- تخلّصنا من "حلقة التكرار في Python" لمعالجة البيانات.
- لقد أنشأنا 50,000 متّجه باستخدام أمر SQL واحد.
- أتممنا عملية إنشاء المتجهات المستقبلية باستخدام المشغّلات.
- أجرينا عملية "البحث المختلط".
الخطوات التالية
- جرِّب ذلك باستخدام مجموعة البيانات الخاصة بك.
- استكشِف مستندات AlloyDB AI.
- يمكنك الاطّلاع على الموقع الإلكتروني Code Vipassana لمعرفة المزيد من ورش العمل.