
1. Übersicht
In diesem Codelab erstellen Sie eine skalierbare Wissensdatenbank-Suchanwendung. Anstatt eine komplexe ETL-Pipeline mit Python-Skripten und ‑Schleifen zu verwalten, um Vektoreinbettungen zu generieren, verwenden Sie AlloyDB AI, um die Generierung von Einbettungen nativ in der Datenbank mit einem einzigen SQL-Befehl zu verarbeiten.
Aufgaben
Eine leistungsstarke, durchsuchbare Wissensdatenbankanwendung.
Lerninhalte
Nach Abschluss können Sie:
- AlloyDB-Cluster bereitstellen und KI-Erweiterungen aktivieren.
- Synthetische Daten (mehr als 50.000 Zeilen) mit SQL generieren
- Füllen Sie Vektoreinbettungen für das gesamte Dataset mithilfe der Batchverarbeitung nach.
- Richten Sie inkrementelle Echtzeittrigger ein, um neue Daten automatisch einzubetten.
- Führen Sie eine hybride Suche (Vektor + SQL-Filter) für „Flexing Context“ durch.
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, können Sie mit dem folgenden Befehl prüfen, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu prüfen, ob der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Folgen Sie dem Link und aktivieren Sie die APIs.
Alternativ können Sie dazu den gcloud-Befehl verwenden. Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Fallstricke und Fehlerbehebung
Das „Geisterprojekt“-Syndrom | Sie haben |
Die Abrechnungsbarrikade | Sie haben das Projekt aktiviert, aber das Rechnungskonto vergessen. AlloyDB ist eine leistungsstarke Engine, die nicht startet, wenn der „Benzintank“ (Abrechnung) leer ist. |
Verzögerung bei der API-Weitergabe | Sie haben auf „APIs aktivieren“ geklickt, aber in der Befehlszeile wird weiterhin |
Kontingent -Quags | Wenn Sie ein brandneues Testkonto verwenden, erreichen Sie möglicherweise ein regionales Kontingent für AlloyDB-Instanzen. Wenn |
Verborgener Kundenservicemitarbeiter | Manchmal wird dem AlloyDB-Dienst-Agenten die Rolle |
3. Datenbank einrichten
In diesem Lab verwenden wir AlloyDB als Datenbank für die Testdaten. Dazu werden Cluster verwendet, in denen alle Ressourcen wie Datenbanken und Logs enthalten sind. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Erstellen wir einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine Tabelle, in die das Test-Dataset geladen wird.
- Klicken Sie auf den Button oder kopieren Sie den Link unten in den Browser, in dem der Google Cloud Console-Nutzer angemeldet ist.
- Sobald dieser Schritt abgeschlossen ist, wird das Repository in Ihren lokalen Cloud Shell-Editor geklont und Sie können den folgenden Befehl über den Projektordner ausführen. Achten Sie darauf, dass Sie sich im Projektverzeichnis befinden:
sh run.sh
- Verwenden Sie jetzt die Benutzeroberfläche (klicken Sie auf den Link im Terminal oder auf den Link „Vorschau im Web“ im Terminal).
- Geben Sie die Details für Projekt-ID, Cluster- und Instanznamen ein, um zu beginnen.
- Holen Sie sich einen Kaffee, während die Logs durchlaufen. Hier können Sie nachlesen, wie das im Hintergrund funktioniert. Das kann etwa 10 bis 15 Minuten dauern.
Fallstricke und Fehlerbehebung
Das Problem mit der Geduld | Datenbankcluster sind eine schwere Infrastruktur. Wenn Sie die Seite aktualisieren oder die Cloud Shell-Sitzung beenden, weil sie „hängt“, kann es passieren, dass eine „Geisterinstanz“ entsteht, die teilweise bereitgestellt wurde und ohne manuellen Eingriff nicht gelöscht werden kann. |
Falsche Region | Wenn Sie Ihre APIs in |
Zombie-Cluster | Wenn Sie zuvor denselben Namen für einen Cluster verwendet und ihn nicht gelöscht haben, wird im Skript möglicherweise angezeigt, dass der Clustername bereits vorhanden ist. Cluster-Namen müssen innerhalb eines Projekts eindeutig sein. |
Cloud Shell-Zeitüberschreitung | Wenn Ihre Kaffeepause 30 Minuten dauert, wird Cloud Shell möglicherweise inaktiv und die Verbindung zum |
4. Schemabereitstellung
In diesem Schritt geht es um Folgendes:
Sobald Ihr AlloyDB-Cluster und Ihre Instanz ausgeführt werden, können Sie im SQL-Editor von AlloyDB Studio die KI-Erweiterungen aktivieren und das Schema bereitstellen.
Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“ (oder das Passwort, das Sie bei der Erstellung festgelegt haben)
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.
Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Tabelle erstellen
Wir benötigen ein Dataset, um die Skalierung zu demonstrieren. Anstatt eine CSV-Datei zu importieren, generieren wir mit SQL sofort 50.000 Zeilen mit synthetischen „Hilfeartikeln“.
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
In der Spalte item_vector können die Vektorwerte des Texts gespeichert werden.
Daten überprüfen:
SELECT count(*) FROM help_articles;
-- Output: 50000
Datenbank-Flags aktivieren
Rufen Sie die Instanzkonfigurationskonsole auf, klicken Sie auf „Primäre Instanz bearbeiten“, rufen Sie die erweiterte Konfiguration auf und klicken Sie auf „Datenbank-Flags hinzufügen“.
Falls nicht, geben Sie sie im Drop-down-Menü für Flags ein, stellen Sie sie auf „ON“ (EIN) ein und aktualisieren Sie die Instanz.
Falls nicht, geben Sie sie im Drop-down-Menü für Flags ein, stellen Sie sie auf „ON“ (EIN) ein und aktualisieren Sie die Instanz.
Schritte zum Konfigurieren von Datenbank-Flags:
- Rufen Sie in der Google Cloud Console die Seite „Cluster“ auf.
- Klicken Sie in der Spalte Ressourcenname auf einen Cluster.
- Rufen Sie auf der Seite Übersicht den Abschnitt Instanzen in Ihrem Cluster auf, wählen Sie eine Instanz aus und klicken Sie dann auf Bearbeiten.
- So fügen Sie ein Datenbankflag für Ihre Instanz hinzu, ändern oder löschen es:
Markierung hinzufügen
- Wenn Sie Ihrer Instanz ein Datenbank-Flag hinzufügen möchten, klicken Sie auf „Flag hinzufügen“.
- Wählen Sie ein Datenbank-Flag aus der Liste „Neues Datenbank-Flag“ aus.
- Geben Sie einen Wert für das Flag an.
- Klicken Sie auf "Fertig".
- Klicken Sie auf Instanz aktualisieren.
- Prüfen Sie, ob die Erweiterung „google_ml_integration“ Version 1.5.2 oder höher hat:
So prüfen Sie die Version Ihrer Erweiterung mit dem folgenden Befehl:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Wenn Sie die Erweiterung auf eine höhere Version aktualisieren müssen, verwenden Sie den folgenden Befehl:
ALTER EXTENSION google_ml_integration UPDATE;
Berechtigung gewähren
- Wenn ein Nutzer die automatische Einbettungserstellung verwalten soll, gewähren Sie ihm die Berechtigungen INSERT, UPDATE und DELETE für die Tabellen google_ml.embed_gen_progress und google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
„postgres“ ist der USER_NAME, für den die Berechtigungen gewährt werden.
- Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Dem AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Fallstricke und Fehlerbehebung
Die „Passwort vergessen“-Schleife | Wenn Sie die Einrichtung mit nur einem Klick verwendet haben und sich nicht an Ihr Passwort erinnern können, rufen Sie in der Konsole die Seite „Instance basic information“ (Grundlegende Informationen zur Instanz) auf und klicken Sie auf „Edit“ (Bearbeiten), um das |
Fehler „Erweiterung nicht gefunden“ | Wenn |
5. Vektorgenerierung mit nur einem Prompt
Das ist der Kern des Labs. Anstatt eine Python-Schleife zum Verarbeiten dieser 50.000 Zeilen zu schreiben, verwenden wir die Funktion ai.initialize_embeddings.
Mit diesem Einzelbefehl wird Folgendes ausgeführt:
- Füllt alle vorhandenen Zeilen auf.
- Erstellt einen Trigger, um zukünftige Zeilen automatisch einzubetten.
Führen Sie die folgende SQL-Anweisung im AlloyDB-Abfrageeditor aus.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
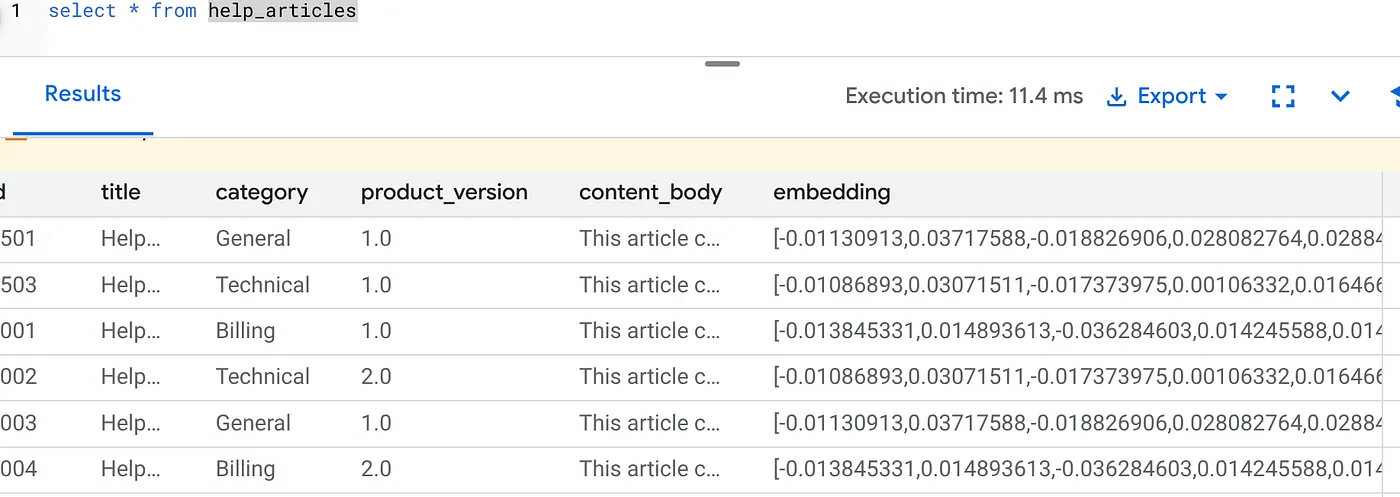
Einbettungen überprüfen
Prüfen Sie, ob die Spalte embedding jetzt ausgefüllt ist:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Das Ergebnis sollte etwa so aussehen:
Was ist gerade passiert?
- Backfill im großen Maßstab:Das Tool durchsucht automatisch Ihre vorhandenen 50.000 Zeilen und generiert Einbettungen über Vertex AI.
- Automatisierung:Wenn Sie „incremental_refresh_mode“ => „transactional“ festlegen, werden die internen Trigger in AlloyDB automatisch eingerichtet. Für jede neue Zeile, die in „help_articles“ eingefügt wird, wird sofort ein Embedding generiert.
- Optional können Sie „incremental_refresh_mode“ => „None“ festlegen, damit Sie nur die Anweisung zum Ausführen von Bulk-Aktualisierungen erhalten und „ai.refresh_embeddings()“ manuell aufrufen müssen, um die Einbettungen aller Zeilen zu aktualisieren.
Sie haben gerade eine Kafka-Warteschlange, einen Python-Worker und ein Migrationsskript durch sechs Zeilen SQL ersetzt. Offizielle Dokumentation für alle Attribute
Echtzeit-Trigger testen
Wir prüfen jetzt, ob die Automatisierung „Zero Loop“ für neue Daten funktioniert.
- Neue Zeile einfügen:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Sofort prüfen:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Ergebnis:
Der Vektor sollte sofort generiert werden, ohne dass ein externes Skript ausgeführt werden muss.
Batchgröße für das Feinabstimmen
Derzeit ist die Batchgröße in AlloyDB standardmäßig auf 50 festgelegt. Die Standardeinstellungen funktionieren zwar sofort, aber mit AlloyDB haben Nutzer weiterhin die Möglichkeit, die perfekte Konfiguration für ihr individuelles Modell und Dataset zu optimieren.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Nutzer müssen jedoch die Kontingentlimits kennen, die die Leistung einschränken können. Die empfohlenen AlloyDB-Kontingente finden Sie im Abschnitt „Vorbereitung“ in der Dokumentation.
Fallstricke und Fehlerbehebung
IAM-Weitergabeverzögerung | Sie haben den IAM-Befehl |
Falsche Vektordimension | Die Tabelle |
6. Kontextsuche flexibler gestalten
Jetzt führen wir eine Hybridsuche durch. Wir kombinieren semantisches Verständnis (Vektor) mit Geschäftslogik (SQL-Filter).
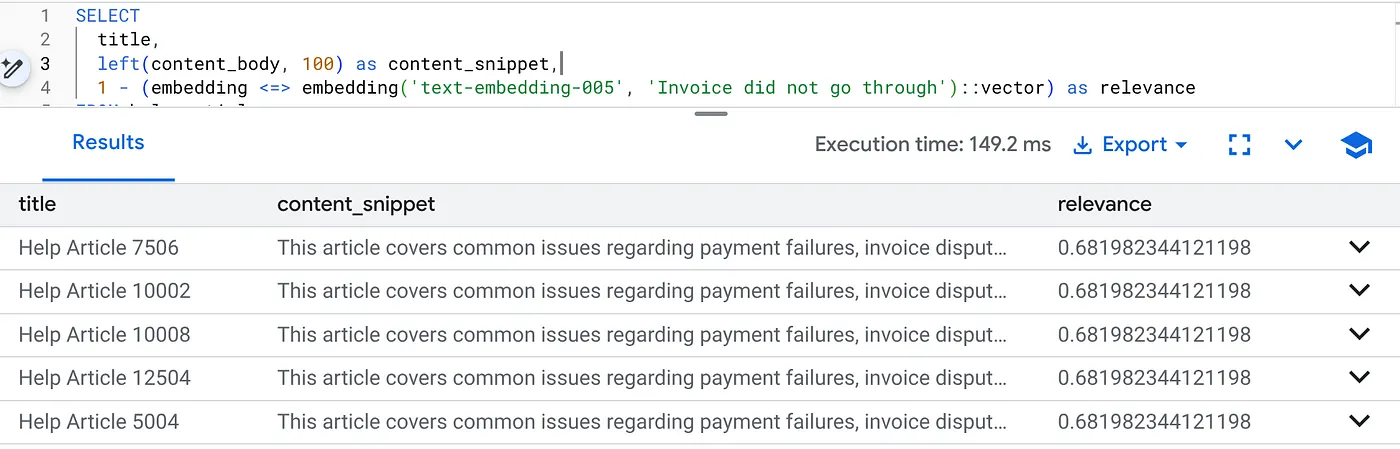
Führen Sie diese Abfrage aus, um Abrechnungsprobleme speziell für Produktversion 2.0 zu finden:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Das ist Flexing Context. Die Suche wird angepasst, um die Intention des Nutzers („Abrechnungsprobleme“) zu verstehen und gleichzeitig die strengen geschäftlichen Einschränkungen (Version 2.0) zu berücksichtigen.
Vorteile für Start-ups und Migrationen
- Keine Infrastrukturschulden: Sie haben keine separate Vektordatenbank (Pinecone/Milvus) hochgefahren. Sie haben keinen separaten ETL-Job geschrieben. Alles ist in Postgres.
- Echtzeit-Updates: Wenn Sie den transaktionalen Modus verwenden, ist Ihr Suchindex immer aktuell. Sobald die Daten übertragen wurden, sind sie vektorisiert.
- Skalierbarkeit: AlloyDB basiert auf der Infrastruktur von Google. Damit können Millionen von Vektoren schneller generiert werden als mit Ihrem Python-Skript.
Fallstricke und Fehlerbehebung
Falle bei der Produktionsleistung | Problem: Schnell für 50.000 Zeilen. Sehr langsam bei 1 Million Zeilen, wenn der Kategoriefilter nicht selektiv genug ist.Lösung:Fügen Sie einen Vektorindex hinzu: Für die Produktionsskalierung müssen Sie einen Index erstellen:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops); Indexnutzung überprüfen:Führen Sie |
Die Katastrophe des „Modellkonflikts“ | Problem: Sie haben die Spalte mit „text-embedding-005“ in der CALL-Prozedur initialisiert. Wenn Sie versehentlich ein anderes Modell (z.B. text-embedding-004 oder ein OSS-Modell) in der SELECT-Abfragefunktion embedding('model-name', ...) verwenden, stimmen die Dimensionen möglicherweise überein (768), aber der Vektorraum ist völlig anders.Die Abfrage wird ohne Fehler ausgeführt, aber die Ergebnisse sind völlig irrelevant (Relevanzwerte ohne Aussagekraft).Fehlerbehebung:Achten Sie darauf, dass die model_id in ai.initialize_embeddings genau mit der model_id in Ihrer SELECT-Abfrage übereinstimmt. |
Das Ergebnis „Silent Empty“ (Überfilterung) | Problem: Die Hybridsuche ist eine „UND“-Operation. Dafür sind Semantic Match UND SQL Match erforderlich.Wenn ein Nutzer nach „Abrechnungshilfe“ sucht, in der Spalte
|
4. Berechtigungs-/Kontingentfehler (Fehler 500) | Problem:Die Funktion
|
5. Nulleinbettungen | Problem:Wenn Sie Daten einfügen, bevor das Modell vollständig initialisiert wurde, oder wenn der Hintergrundworker fehlschlägt, enthalten einige Zeilen möglicherweise
|
7. Bereinigen
Vergessen Sie nicht, den AlloyDB-Cluster und die AlloyDB-Instanz zu löschen, wenn Sie dieses Lab abgeschlossen haben.
Dadurch sollte der Cluster zusammen mit seinen Instanzen bereinigt werden.
8. Glückwunsch
Sie haben erfolgreich eine skalierbare Wissensdatenbank-Suchanwendung erstellt. Anstatt eine komplexe ETL-Pipeline mit Python-Skripten und ‑Schleifen zum Generieren von Vektoreinbettungen zu verwalten, haben Sie AlloyDB AI verwendet, um die Einbettungserstellung nativ in der Datenbank mit einem einzigen SQL-Befehl zu verarbeiten.
Worüber haben wir gesprochen?
- Wir haben die „Python-For-Schleife“ für die Datenverarbeitung abgeschafft.
- Wir haben 50.000 Vektoren mit einem SQL-Befehl generiert.
- Wir haben die zukünftige Vektorgenerierung mit Triggern automatisiert.
- Wir haben die Hybridsuche ausgeführt.
Nächste Schritte
- Probieren Sie es mit Ihrem eigenen Dataset aus.
- AlloyDB AI-Dokumentation
- Weitere Workshops finden Sie auf der Website Code Vipassana.