
1. Descripción general
En este codelab, compilarás una aplicación de búsqueda en la base de conocimiento escalable. En lugar de administrar una canalización de ETL compleja con secuencias de comandos y bucles de Python para generar embeddings de vectores, usarás AlloyDB AI para controlar la generación de embeddings de forma nativa dentro de la base de datos con un solo comando SQL.
Qué compilarás
Aplicación de base de datos de conocimiento "buscable" y de alto rendimiento.
Qué aprenderás
Aprenderás a hacer lo siguiente:
- Aprovisiona un clúster de AlloyDB y habilita las extensiones de IA.
- Generar datos sintéticos (más de 50,000 filas) con SQL
- Genera incorporaciones de vectores de forma retroactiva para todo el conjunto de datos con el procesamiento por lotes.
- Configura los activadores incrementales en tiempo real para incorporar automáticamente datos nuevos.
- Realiza una búsqueda híbrida (filtros de vectores y SQL) para "Flexing Context".
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando de gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Problemas potenciales y solución de problemas
El síndrome del "Proyecto fantasma" | Ejecutaste |
La barricada de facturación | Habilitaste el proyecto, pero olvidaste la cuenta de facturación. AlloyDB es un motor de alto rendimiento que no se iniciará si el "tanque de combustible" (facturación) está vacío. |
Retraso en la propagación de la API | Hiciste clic en "Habilitar APIs", pero la línea de comandos aún dice |
Cuota de Quags | Si usas una cuenta de prueba nueva, es posible que alcances una cuota regional para las instancias de AlloyDB. Si falla |
Agente de servicio"oculto" | A veces, al agente de servicio de AlloyDB no se le otorga automáticamente el rol de |
3. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para los datos de prueba. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de prueba.
- Haz clic en el botón o copia el siguiente vínculo en el navegador en el que accediste como usuario de la consola de Google Cloud.
- Una vez que se complete este paso, el repo se clonará en tu editor local de Cloud Shell y podrás ejecutar el siguiente comando desde la carpeta del proyecto (es importante que te asegures de estar en el directorio del proyecto):
sh run.sh
- Ahora usa la IU (haz clic en el vínculo de la terminal o en el vínculo "preview on web" de la terminal).
- Ingresa los detalles del ID del proyecto, el clúster y los nombres de las instancias para comenzar.
- Ve a tomar un café mientras se desplazan los registros y puedes leer aquí cómo se hace esto tras bambalinas. Esto puede tardar entre 10 y 15 minutos.
Problemas potenciales y solución de problemas
El problema de la "paciencia" | Los clústeres de bases de datos son una infraestructura pesada. Si actualizas la página o finalizas la sesión de Cloud Shell porque "parece que se detuvo", es posible que termines con una instancia "fantasma" que se aprovisionó parcialmente y que es imposible borrar sin intervención manual. |
Incongruencia de región | Si habilitaste tus APIs en |
Clústeres de zombis | Si antes usaste el mismo nombre para un clúster y no lo borraste, es posible que la secuencia de comandos indique que el nombre del clúster ya existe. Los nombres de los clústeres deben ser únicos dentro de un proyecto. |
Tiempo de espera de Cloud Shell | Si tu descanso para tomar café dura 30 minutos, es posible que Cloud Shell entre en modo de suspensión y desconecte el proceso |
4. Aprovisionamiento de esquemas
En este paso, abordaremos lo siguiente:
Una vez que tengas en funcionamiento tu clúster y tu instancia de AlloyDB, dirígete al editor de SQL de AlloyDB Studio para habilitar las extensiones de IA y aprovisionar el esquema.
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo esté, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña: “
alloydb” (o la que hayas configurado en el momento de la creación)
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Crea una tabla
Necesitamos un conjunto de datos para demostrar la escala. En lugar de importar un archivo CSV, generaremos 50,000 filas de "Artículos de ayuda" sintéticos al instante con SQL.
Puedes crear una tabla con la siguiente declaración DDL en AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
La columna item_vector permitirá el almacenamiento de los valores vectoriales del texto.
Verifica los datos:
SELECT count(*) FROM help_articles;
-- Output: 50000
Cómo habilitar marcas de base de datos
Ve a la consola de configuración de la instancia, haz clic en “Editar principal”, ve a Configuración avanzada y haz clic en “Agregar marcas de base de datos”.
De lo contrario, ingresa el parámetro en el menú desplegable de marcas, configúralo como "ON" y actualiza la instancia.
De lo contrario, ingresa el parámetro en el menú desplegable de marcas, configúralo como "ON" y actualiza la instancia.
Pasos para configurar marcas de bases de datos:
- En la consola de Google Cloud, ve a la página Clústeres.
- Haz clic en un clúster en la columna Nombre del recurso.
- En la página Descripción general, ve a Instancias en tu clúster, selecciona una instancia y, luego, haz clic en Editar.
- Sigue estos pasos para agregar, modificar o borrar una marca de base de datos de tu instancia:
Cómo agregar una marca
- Para agregar una marca de base de datos a tu instancia, haz clic en Agregar marca.
- Selecciona una marca de base de datos de la lista New database flag.
- Proporciona un valor para la marca.
- Haz clic en Listo.
- Haz clic en Actualizar instancia.
- Verifica que la extensión google_ml_integration sea la versión 1.5.2 o una posterior:
Para verificar la versión de tu extensión, usa el siguiente comando:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Si necesitas actualizar la extensión a un valor más alto, usa el siguiente comando:
ALTER EXTENSION google_ml_integration UPDATE;
Otorgar permiso
- Para permitir que un usuario administre la generación automática de incorporaciones, otorga permisos de INSERT, UPDATE y DELETE en las tablas google_ml.embed_gen_progress y google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
"postgres" es el USER_NAME para el que se otorgan los permisos.
- Ejecuta la siguiente instrucción para otorgar permiso de ejecución en la función "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
En la consola de Google Cloud IAM, otorga a la cuenta de servicio de AlloyDB (que se ve así: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acceso al rol "Usuario de Vertex AI". PROJECT_NUMBER tendrá tu número de proyecto.
Como alternativa, puedes ejecutar el siguiente comando desde la terminal de Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Problemas potenciales y solución de problemas
El bucle de "amnesia de contraseña" | Si usaste la configuración "Con un clic" y no recuerdas tu contraseña, ve a la página Información básica de la instancia en la consola y haz clic en "Editar" para restablecer la contraseña de |
El error "No se encontró la extensión" | Si |
5. Generación de vectores "única"
Este es el núcleo del lab. En lugar de escribir un bucle de Python para procesar estas 50,000 filas, usaremos la función ai.initialize_embeddings.
Este único comando realiza dos acciones:
- Reabastece todas las filas existentes.
- Crea un activador para incorporar automáticamente filas futuras.
Ejecuta la siguiente sentencia de SQL desde el editor de consultas de AlloyDB
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
Verifica las incorporaciones
Verifica que la columna embedding ahora esté propagada:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Deberías ver un resultado similar al siguiente:
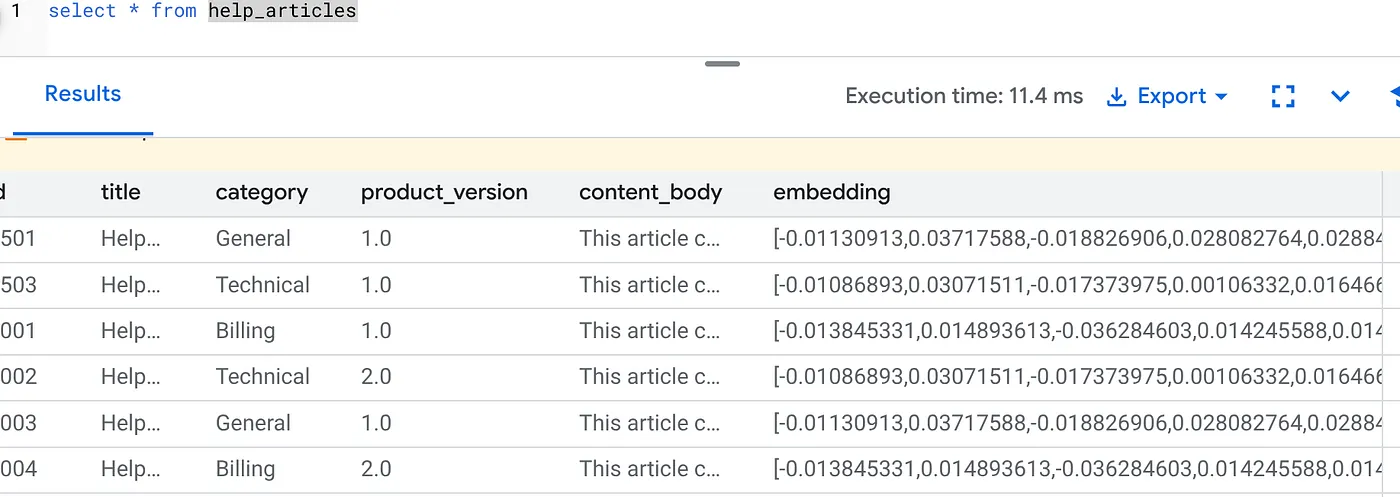
¿Qué pasó?
- Completado a gran escala: Analiza automáticamente tus 50,000 filas existentes y genera incorporaciones a través de Vertex AI.
- Automatización: Si configuras incremental_refresh_mode => "transactional", AlloyDB configura automáticamente los activadores internos. Cualquier fila nueva que se inserte en help_articles tendrá su incorporación generada al instante.
- De manera opcional, puedes establecer incremental_refresh_mode => "None" para que solo puedas obtener la instrucción para realizar actualizaciones masivas y llamar manualmente a ai.refresh_embeddings() para actualizar todas las incorporaciones de filas.
Acabas de reemplazar una cola de Kafka, un trabajador de Python y una secuencia de comandos de migración con 6 líneas de SQL. Aquí se encuentra la documentación oficial detallada de todos los atributos.
Prueba de activador en tiempo real
Verifiquemos que la automatización de "Zero Loop" funcione para los datos nuevos.
- Inserta una fila nueva:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Verifica de inmediato lo siguiente:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Resultado:
Deberías ver el vector generado al instante sin ejecutar ninguna secuencia de comandos externa.
Cómo ajustar el tamaño del lote
Actualmente, AlloyDB establece el tamaño del lote en 50 de forma predeterminada. Si bien los valores predeterminados funcionan muy bien de inmediato, AlloyDB sigue brindando a los usuarios el control para ajustar la configuración perfecta para su modelo y conjunto de datos únicos.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Sin embargo, los usuarios deben tener en cuenta los límites de cuota que pueden restringir el rendimiento. Para revisar las cuotas recomendadas de AlloyDB, consulta la sección "Antes de comenzar" en la documentación.
Problemas potenciales y solución de problemas
La brecha de propagación de IAM | Ejecutaste el comando de IAM |
Vector Dimension Mismatch | La tabla |
6. Flexibilización de la Búsqueda contextual
Ahora realizaremos una búsqueda híbrida. Combinamos la comprensión semántica (Vector) con la lógica empresarial (filtros SQL).
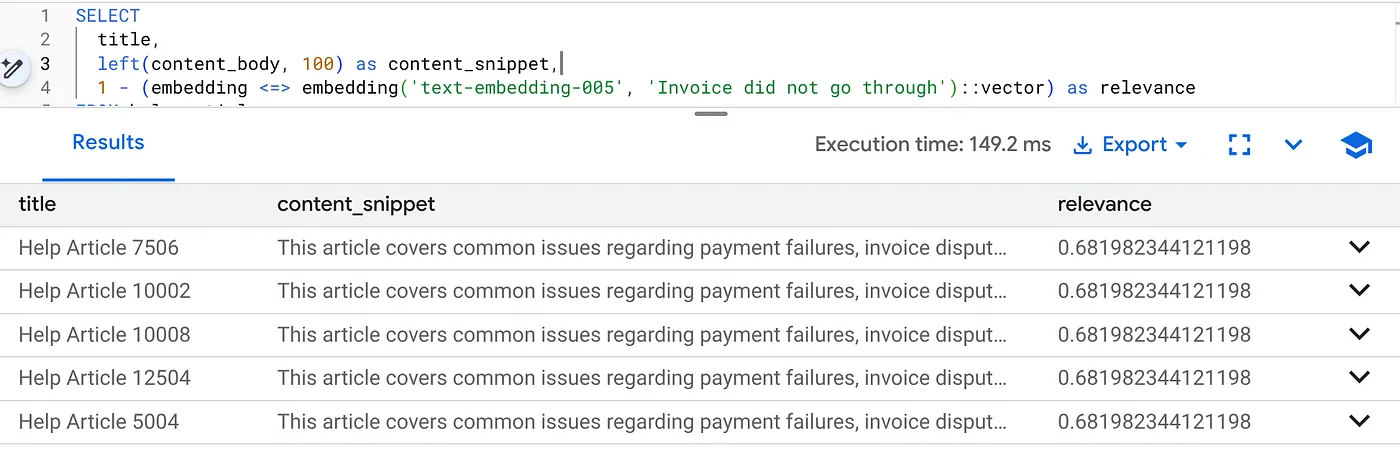
Ejecuta esta consulta para encontrar problemas de facturación específicos de la versión 2.0 del producto:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Este es el contexto de flexibilidad. La búsqueda se "flexibiliza" para comprender la intención del usuario ("problemas de facturación") y, al mismo tiempo, respeta las restricciones comerciales rígidas (versión 2.0).
Por qué esta solución es ideal para las empresas emergentes y las migraciones
- Sin deuda de infraestructura: No iniciaste una base de datos de vectores independiente (Pinecone/Milvus). No escribiste un trabajo de ETL independiente. Todo está en Postgres.
- Actualizaciones en tiempo real: Si usas el modo "transaccional", tu índice de búsqueda nunca estará desactualizado. En el momento en que se confirman los datos, están listos para convertirse en vectores.
- Escalabilidad: AlloyDB se basa en la infraestructura de Google. Puede controlar la generación masiva de millones de vectores más rápido de lo que tu secuencia de comandos de Python podría hacerlo.
Problemas potenciales y solución de problemas
Problema potencial de rendimiento en la producción | Problema: Es rápido para 50,000 filas. Es muy lento para 1 millón de filas si el filtro de categoría no es lo suficientemente selectivo.Solución:Agrega un índice de vectores: Para la escala de producción, debes crear un índice:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);Verifica el uso del índice: Ejecuta |
El desastre de la "incompatibilidad de modelos" | Problema: Inicializaste la columna con text-embedding-005 en el procedimiento CALL. Si usas accidentalmente un modelo diferente (p. ej., text-embedding-004 o un modelo de OSS) en la función de incorporación de la consulta SELECT embedding('model-name', …), es posible que las dimensiones coincidan (768), pero el espacio vectorial será completamente diferente. La consulta se ejecuta sin errores, pero los resultados son completamente irrelevantes (puntuaciones de relevancia basura). Solución de problemas:Asegúrate de que el model_id en ai.initialize_embeddings coincida exactamente con el model_id en tu consulta SELECT. |
El resultado de "Silent Empty" (filtrado excesivo) | Problema: La búsqueda híbrida es una operación "Y". Requiere Semantic Match Y SQL Match.Si un usuario busca "Ayuda con la facturación", pero la columna
|
4. Errores de permisos o de cuota (error 500) | Problema:La función
|
5. Incorporaciones nulas | Problema:Si insertas datos antes de que el modelo se inicialice por completo o si falla el trabajador en segundo plano, es posible que algunas filas tengan
|
7. Limpia
Cuando termines este lab, no olvides borrar el clúster y la instancia de AlloyDB.
Debería limpiar el clúster junto con sus instancias.
8. Felicitaciones
Compilaste correctamente una aplicación de búsqueda de la base de conocimiento escalable. En lugar de administrar una canalización de ETL compleja con bucles y secuencias de comandos de Python para generar embeddings vectoriales, usaste AlloyDB AI para controlar la generación de embeddings de forma nativa dentro de la base de datos con un solo comando SQL.
Temas abordados
- Eliminamos el "bucle for de Python" para el procesamiento de datos.
- Generamos 50,000 vectores con un comando SQL.
- Automatizamos la generación de vectores futuros con activadores.
- Realizamos una búsqueda híbrida.
Próximos pasos
- Prueba esto con tu propio conjunto de datos.
- Explora la documentación de AlloyDB AI.
- Consulta el sitio web de Code Vipassana para ver más talleres.