
۱. مرور کلی
در این آزمایشگاه کد، شما یک برنامه جستجوی پایگاه دانش مقیاسپذیر خواهید ساخت. به جای مدیریت یک خط لوله پیچیده ETL با اسکریپتها و حلقههای پایتون برای تولید جاسازیهای برداری، از AlloyDB AI برای مدیریت تولید جاسازی به صورت بومی در پایگاه داده با استفاده از یک دستور SQL واحد استفاده خواهید کرد.
آنچه خواهید ساخت
یک برنامه پایگاه داده دانش با قابلیت جستجو و عملکرد بالا.
آنچه یاد خواهید گرفت
شما یاد خواهید گرفت که چگونه:
- یک کلاستر AlloyDB تهیه کنید و افزونههای هوش مصنوعی را فعال کنید.
- تولید دادههای مصنوعی (بیش از ۵۰،۰۰۰ ردیف) با استفاده از SQL.
- جاسازیهای برداریِ پُرکنندهی پشت صحنه برای کل مجموعه دادهها با استفاده از پردازش دستهای .
- برای جاسازی خودکار دادههای جدید ، محرکهای افزایشی بلادرنگ (Real-Time Incremental Triggers) را تنظیم کنید.
- جستجوی ترکیبی (فیلترهای برداری + SQL) را برای "متن منعطف" انجام دهید.
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: روی لینک کلیک کنید و API ها را فعال کنید.
به عنوان یک روش جایگزین، میتوانید از دستور gcloud برای این کار استفاده کنید. برای مشاهده دستورات و نحوه استفاده از gcloud به مستندات آن مراجعه کنید.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
اشکالات و عیبیابی
سندرم «پروژه ارواح» | شما |
سنگر بیلینگ | شما پروژه را فعال کردید، اما حساب صورتحساب را فراموش کردید. AlloyDB یک موتور با کارایی بالا است؛ اگر "مخزن بنزین" (صورتحساب) خالی باشد، روشن نمیشود. |
تأخیر انتشار API | شما روی «فعال کردن APIها» کلیک کردهاید، اما خط فرمان هنوز میگوید |
کواگهای سهمیهای | اگر از یک حساب آزمایشی کاملاً جدید استفاده میکنید، ممکن است به سهمیه منطقهای برای نمونههای AlloyDB برسید. اگر |
نماینده خدمات "پنهان" | گاهی اوقات به طور خودکار نقش |
۳. راهاندازی پایگاه داده
در این آزمایش، ما از AlloyDB به عنوان پایگاه داده برای دادههای آزمایشی استفاده خواهیم کرد. این پایگاه داده از خوشهها برای نگهداری تمام منابع، مانند پایگاههای داده و گزارشها، استفاده میکند. هر خوشه یک نمونه اصلی دارد که یک نقطه دسترسی به دادهها را فراهم میکند. جداول، دادههای واقعی را نگهداری میکنند.
بیایید یک کلاستر، نمونه و جدول AlloyDB ایجاد کنیم که مجموعه دادههای آزمایشی در آن بارگذاری شوند.
- روی دکمه کلیک کنید یا لینک زیر را در مرورگر خود که کاربر Google Cloud Console در آن وارد شده است، کپی کنید.
- پس از اتمام این مرحله، مخزن در ویرایشگر پوسته ابری محلی شما کلون میشود و میتوانید دستور زیر را از پوشه پروژه اجرا کنید (مهم است که مطمئن شوید در دایرکتوری پروژه هستید):
sh run.sh
- حالا از رابط کاربری استفاده کنید (با کلیک روی لینک در ترمینال یا کلیک روی لینک «پیشنمایش در وب» در ترمینال).
- برای شروع، اطلاعات مربوط به شناسه پروژه، نام کلاستر و نمونه را وارد کنید.
- در حالی که گزارشها در حال پیمایش هستند، یک قهوه بنوشید و میتوانید در اینجا در مورد چگونگی انجام این کار در پشت صحنه بخوانید. ممکن است حدود ۱۰ تا ۱۵ دقیقه طول بکشد.
اشکالات و عیبیابی
مشکل «صبر» | خوشههای پایگاه داده زیرساختهای سنگینی هستند. اگر صفحه را رفرش کنید یا جلسه Cloud Shell را به دلیل «گیر کردن» از بین ببرید، ممکن است در نهایت با یک نمونه «شبح» مواجه شوید که تا حدی آماده شده و حذف آن بدون مداخله دستی غیرممکن است. |
عدم تطابق منطقه | اگر APIهای خود را در |
خوشههای زامبی | اگر قبلاً از نام یکسانی برای یک خوشه استفاده کرده باشید و آن را حذف نکرده باشید، ممکن است اسکریپت بگوید که نام خوشه از قبل وجود دارد. نام خوشهها باید در یک پروژه منحصر به فرد باشند. |
مهلت زمانی پوسته ابری | اگر زمان استراحت قهوه شما 30 دقیقه طول بکشد، ممکن است Cloud Shell به حالت خواب برود و فرآیند |
۴. تأمین طرحواره
در این مرحله، موارد زیر را پوشش خواهیم داد:
پس از اجرای کلاستر و نمونه AlloyDB، به ویرایشگر SQL در AlloyDB Studio بروید تا افزونههای هوش مصنوعی را فعال کرده و طرحواره را آماده کنید.
ممکن است لازم باشد منتظر بمانید تا نمونه شما به طور کامل ایجاد شود. پس از اتمام این کار، با استفاده از اعتبارنامههایی که هنگام ایجاد خوشه ایجاد کردهاید، وارد AlloyDB شوید. از دادههای زیر برای تأیید اعتبار در PostgreSQL استفاده کنید:
- نام کاربری: "
postgres" - پایگاه داده: "
postgres" - رمز عبور: "
alloydb" (یا هر چیزی که در زمان ایجاد تعیین کردهاید)
پس از اینکه با موفقیت در AlloyDB Studio احراز هویت شدید، دستورات SQL در ویرایشگر وارد میشوند. میتوانید با استفاده از علامت + در سمت راست آخرین پنجره، چندین پنجره ویرایشگر اضافه کنید.
شما میتوانید دستورات AlloyDB را در پنجرههای ویرایشگر وارد کنید و در صورت لزوم از گزینههای Run، Format و Clear استفاده کنید.
فعال کردن افزونهها
برای ساخت این برنامه، از افزونههای pgvector و google_ml_integration استفاده خواهیم کرد. افزونه pgvector به شما امکان ذخیره و جستجوی جاسازیهای برداری را میدهد. افزونه google_ml_integration توابعی را ارائه میدهد که برای دسترسی به نقاط پایانی پیشبینی هوش مصنوعی Vertex برای دریافت پیشبینیها در SQL استفاده میکنید. این افزونهها را با اجرای DDL های زیر فعال کنید :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
ایجاد یک جدول
ما برای نشان دادن مقیاس به یک مجموعه داده نیاز داریم. به جای وارد کردن CSV، ما 50،000 ردیف "مقالات راهنما" مصنوعی را فوراً با استفاده از SQL تولید خواهیم کرد.
شما میتوانید با استفاده از دستور DDL زیر در AlloyDB Studio یک جدول ایجاد کنید:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
ستون item_vector امکان ذخیرهسازی مقادیر برداری متن را فراهم میکند.
دادهها را تأیید کنید:
SELECT count(*) FROM help_articles;
-- Output: 50000
فعال کردن پرچمهای پایگاه داده
به کنسول پیکربندی Instance بروید، روی «ویرایش اولیه» کلیک کنید، به پیکربندی پیشرفته بروید و روی «افزودن پرچمهای پایگاه داده» کلیک کنید.
اگر اینطور نیست، آن را در منوی کشویی پرچمها وارد کنید و آن را روی "روشن" تنظیم کنید و نمونه را بهروزرسانی کنید.
- تأیید کنید که پرچم google_ml_integration.enable_faster_embedding_generation روی روشن تنظیم شده باشد:
اگر اینطور نیست، آن را در منوی کشویی پرچمها وارد کنید و آن را روی "روشن" تنظیم کنید و نمونه را بهروزرسانی کنید.
مراحل پیکربندی پرچمهای پایگاه داده:
- در کنسول گوگل کلود، به صفحه خوشهها (Clusters) بروید.
- روی یک خوشه در ستون نام منبع کلیک کنید.
- در صفحه مرور کلی ، به نمونههای (Instances) در خوشه خود بروید، یک نمونه را انتخاب کنید و سپس روی ویرایش (Edit) کلیک کنید.
- یک پرچم پایگاه داده را از نمونه خود اضافه، تغییر یا حذف کنید:
اضافه کردن پرچم
- برای افزودن یک پرچم پایگاه داده به نمونه خود، روی افزودن پرچم کلیک کنید.
- یک پرچم از فهرست پرچمهای پایگاه داده جدید انتخاب کنید.
- برای پرچم یک مقدار مشخص کنید.
- روی «انجام شد» کلیک کنید.
- روی بهروزرسانی نمونه کلیک کنید.
- تأیید کنید که افزونه google_ml_integration نسخه ۱.۵.۲ یا بالاتر است:
برای بررسی نسخه افزونه خود با دستور زیر:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
اگر نیاز به بهروزرسانی افزونه به نسخه بالاتر دارید، از دستور زیر استفاده کنید:
افزونهی google_ml_integration را تغییر دهید. بهروزرسانی؛
اعطای مجوز
- برای اینکه به یک کاربر اجازه دهید تولید خودکار جاسازی را مدیریت کند، مجوزهای INSERT، UPDATE و DELETE را در جداول google_ml.embed_gen_progress و google_ml.embed_gen_settings اعطا کنید:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
'postgres' نام کاربری است که مجوزها به آن اعطا شده است.
- برای اعطای مجوز اجرا به تابع "embedding"، دستور زیر را اجرا کنید:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
اعطای نقش کاربری Vertex AI به حساب سرویس AlloyDB
از کنسول Google Cloud IAM ، به حساب سرویس AlloyDB (که به این شکل است: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) دسترسی به نقش "Vertex AI User" را بدهید. PROJECT_NUMBER شماره پروژه شما را خواهد داشت.
همچنین میتوانید دستور زیر را از ترمینال Cloud Shell اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
اشکالات و عیبیابی
حلقهی «فراموشی رمز عبور» | اگر از تنظیمات «یک کلیک» استفاده کردهاید و رمز عبور خود را به خاطر نمیآورید، به صفحه اطلاعات اولیه Instance در کنسول بروید و برای تنظیم مجدد رمز عبور |
خطای "افزونه یافت نشد" | اگر |
۵. تولید بردار «یکباره»
این هسته اصلی آزمایش است. به جای نوشتن یک حلقه پایتون برای پردازش این ۵۰،۰۰۰ ردیف، از تابع ai.initialize_embeddings استفاده خواهیم کرد.
این دستور به تنهایی دو کار انجام میدهد:
- تمام ردیفهای موجود را دوباره پر میکند .
- یک تریگر برای جاسازی خودکار ردیفهای آینده ایجاد میکند .
دستور SQL زیر را از ویرایشگر کوئری AlloyDB اجرا کنید.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
تأیید جاسازیها
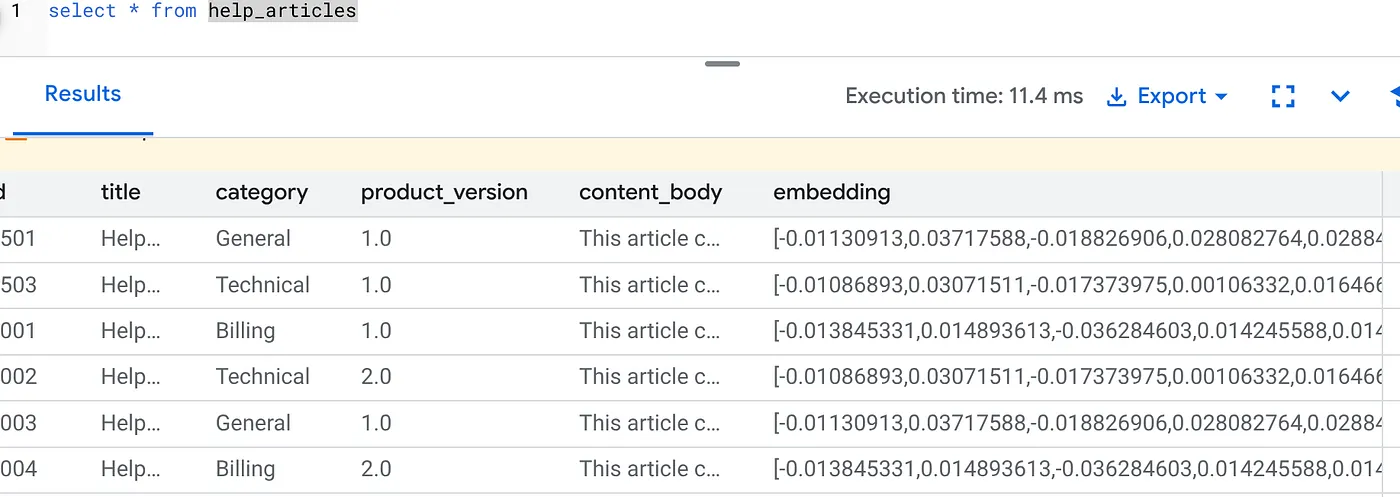
بررسی کنید که ستون embedding اکنون پر شده است:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
شما باید نتیجهای مشابه زیر ببینید:
چی شد؟
- پر کردن مجدد در مقیاس: به طور خودکار ۵۰،۰۰۰ ردیف موجود شما را بررسی میکند و از طریق Vertex AI جاسازیهایی ایجاد میکند.
- اتوماسیون: با تنظیم incremental_refresh_mode => 'transactional'، AlloyDB به طور خودکار محرکهای داخلی را تنظیم میکند. هر ردیف جدیدی که در help_articles وارد شود، جاسازی آن فوراً ایجاد میشود.
- شما میتوانید به صورت اختیاری incremental_refresh_mode => 'None' را تنظیم کنید تا فقط بتوانید دستور مربوط به بهروزرسانیهای انبوه را دریافت کنید و به صورت دستی ai.refresh_embeddings() را برای بهروزرسانی همه جاسازیهای ردیفها فراخوانی کنید.
شما به تازگی یک صف کافکا، یک worker پایتون و یک اسکریپت migration را با ۶ خط SQL جایگزین کردهاید. در اینجا مستندات رسمی دقیق برای همه ویژگیها آمده است.
تست تریگر در لحظه
بیایید بررسی کنیم که اتوماسیون "حلقه صفر" برای دادههای جدید کار میکند.
- درج ردیف جدید:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- فوراً بررسی کنید:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
نتیجه:
شما باید ببینید که بردار فوراً و بدون اجرای هیچ اسکریپت خارجی تولید میشود.
تنظیم اندازه دسته
در حال حاضر، AlloyDB اندازه دسته را به صورت پیشفرض روی ۵۰ تنظیم کرده است. در حالی که مقادیر پیشفرض به طور پیشفرض عالی کار میکنند، AlloyDB همچنان به کاربران این امکان را میدهد که پیکربندی ایدهآل را برای مدل و مجموعه داده منحصر به فرد خود تنظیم کنند.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
با این حال، کاربران باید از محدودیتهای سهمیهبندی که میتواند عملکرد را محدود کند، آگاه باشند. برای بررسی سهمیهبندیهای توصیهشده AlloyDB، به بخش «قبل از شروع» در مستندات مراجعه کنید.
اشکالات و عیبیابی
شکاف انتشار IAM | شما دستور |
عدم تطابق ابعاد برداری | جدول |
۶. انعطافپذیری جستجوی متن
حالا ما یک جستجوی ترکیبی انجام میدهیم. ما درک معنایی (بردار) را با منطق کسبوکار (فیلترهای SQL) ترکیب میکنیم.
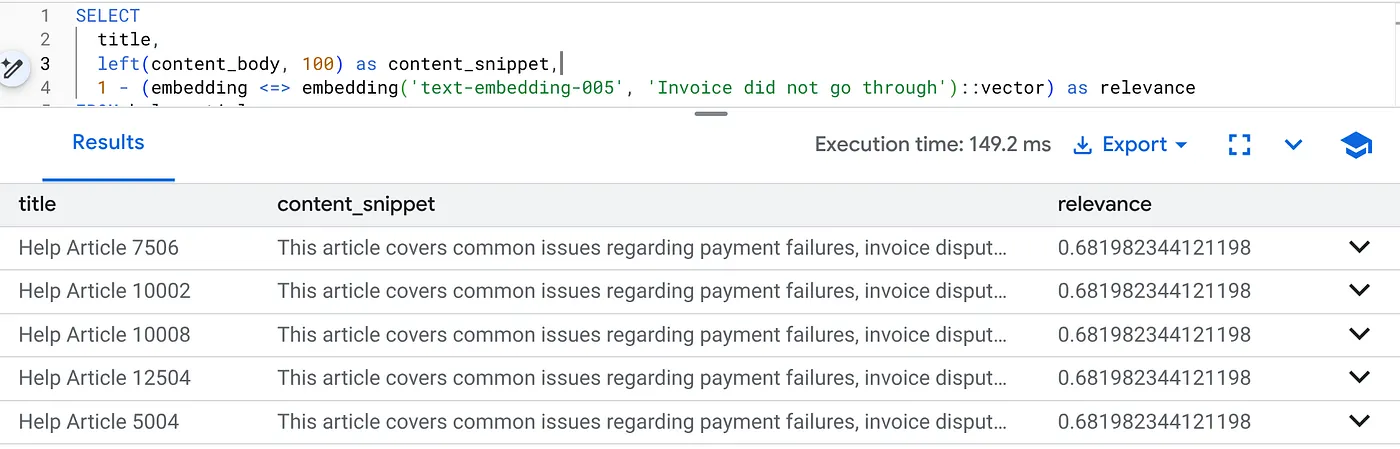
برای یافتن مشکلات صورتحساب مخصوصاً برای نسخه ۲.۰ محصول، این کوئری را اجرا کنید:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
این «متن انعطافپذیر» است. جستجو «منعطف» میشود تا قصد کاربر («مشکلات صورتحساب») را درک کند و در عین حال محدودیتهای سختگیرانه کسبوکار را رعایت کند (نسخه ۲.۰).
چرا این برای استارتاپها و مهاجرتها برنده است؟
- بدهی زیرساخت صفر: شما یک پایگاه داده وکتور جداگانه (Pinecone/Milvus) راهاندازی نکردید. شما یک کار ETL جداگانه ننوشتید. همه چیز در Postgres است.
- بهروزرسانیهای بلادرنگ: با استفاده از حالت «تراکنشی»، فهرست جستجوی شما هرگز قدیمی نمیشود. به محض اینکه دادهها ثبت شوند، آمادهی استفاده هستند.
- مقیاس: AlloyDB بر روی زیرساخت گوگل ساخته شده است. این پایگاه داده میتواند تولید انبوه میلیونها بردار را سریعتر از اسکریپت پایتون شما مدیریت کند.
اشکالات و عیبیابی
عملکرد تولید، مشکل اصلی | مشکل: برای ۵۰،۰۰۰ ردیف سریع است. اگر فیلتر دستهبندی به اندازه کافی انتخابی نباشد، برای ۱ میلیون ردیف بسیار کند است. راه حل: اضافه کردن یک شاخص برداری: برای مقیاس تولید ، باید یک شاخص ایجاد کنید: ایجاد شاخص روی help_articles با استفاده از hnsw (جاسازی vector_cosine_ops)؛ تأیید استفاده از شاخص: |
فاجعه «عدم تطابق مدل» | مشکل: شما ستون را با استفاده از text-embedding-005 در روال CALL مقداردهی اولیه کردهاید. اگر به طور تصادفی از مدل متفاوتی (مثلاً text-embedding-004 یا یک مدل OSS) در تابع SELECT query embedding('model-name', ...) استفاده کنید، ممکن است ابعاد با (768) مطابقت داشته باشند، اما فضای برداری کاملاً متفاوت خواهد بود. پرس و جو بدون خطا اجرا میشود، اما نتایج کاملاً نامربوط هستند (نمرات مربوط به ارتباط نامناسب). عیبیابی: مطمئن شوید که model_id در ai.initialize_embeddings دقیقاً با model_id در پرس و جوی SELECT شما مطابقت دارد. |
نتیجهی «خالی خاموش» (فیلترینگ بیش از حد) | مشکل: جستجوی ترکیبی یک عملیات "و" است. این جستجو به تطبیق معنایی و تطبیق SQL نیاز دارد. اگر کاربری عبارت "کمک در پرداخت" را جستجو کند اما ستون
|
۴. خطاهای مجوز/سهمیه (خطای ۵۰۰) | مشکل: تابع
|
۵. جاسازیهای تهی | مشکل: اگر دادهها را قبل از مقداردهی اولیه کامل مدل وارد کنید یا اگر کارگر پسزمینه با شکست مواجه شود، ممکن است برخی از ردیفها در ستون
|
۷. تمیز کردن
پس از انجام این آزمایش، فراموش نکنید که کلاستر و نمونه alloyDB را حذف کنید.
باید کلاستر را به همراه نمونه(های) آن پاکسازی کند.
۸. تبریک
شما با موفقیت یک برنامه جستجوی پایگاه دانش مقیاسپذیر ساختید. به جای مدیریت یک خط لوله پیچیده ETL با اسکریپتها و حلقههای پایتون برای تولید جاسازیهای برداری، از AlloyDB AI برای مدیریت تولید جاسازی به صورت بومی در پایگاه داده با استفاده از یک دستور SQL واحد استفاده کردید.
آنچه ما پوشش دادیم
- ما «حلقه For پایتون» را برای پردازش دادهها حذف کردیم.
- ما ۵۰،۰۰۰ بردار را با یک دستور SQL تولید کردیم.
- ما تولید بردارهای آینده را با محرکها خودکار کردیم.
- ما جستجوی ترکیبی (Hybrid Search) را انجام دادیم.
مراحل بعدی
- این را با مجموعه داده خودتان امتحان کنید.
- مستندات هوش مصنوعی AlloyDB را بررسی کنید.
- برای کارگاههای بیشتر، به وبسایت Code Vipassana مراجعه کنید.