
1. Présentation
Dans cet atelier de programmation, vous allez créer une application de recherche dans une base de connaissances évolutive. Au lieu de gérer un pipeline ETL complexe avec des scripts et des boucles Python pour générer des embeddings vectoriels, vous utiliserez AlloyDB AI pour gérer la génération d'embeddings de manière native dans la base de données à l'aide d'une seule commande SQL.
Ce que vous allez faire
Application de base de données de base de connaissances "consultable" et hautes performances.
Points abordés
Vous allez apprendre à effectuer les tâches suivantes :
- Provisionnez un cluster AlloyDB et activez les extensions d'IA.
- Générez des données synthétiques (plus de 50 000 lignes) à l'aide de SQL.
- Remplissez les embeddings vectoriels pour l'ensemble de l'ensemble de données à l'aide du traitement par lot.
- Configurez des déclencheurs incrémentaux en temps réel pour intégrer automatiquement de nouvelles données.
- Effectuez une recherche hybride (vecteur + filtres SQL) pour "Flexing Context".
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : suivez ce lien et activez les API.
Vous pouvez également utiliser la commande gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Problèmes et dépannage
Syndrome du projet fantôme | Vous avez exécuté |
Barricade de facturation | Vous avez activé le projet, mais vous avez oublié le compte de facturation. AlloyDB est un moteur hautes performances. Il ne démarrera pas si le "réservoir" (la facturation) est vide. |
Latence de propagation de l'API | Vous avez cliqué sur "Activer les API", mais la ligne de commande indique toujours |
Quags de quota | Si vous utilisez un tout nouveau compte d'essai, vous pouvez atteindre un quota régional pour les instances AlloyDB. Si |
Agent du service"Caché" | Il arrive que l'agent de service AlloyDB ne reçoive pas automatiquement le rôle |
3. Configuration de la base de données
Dans cet atelier, nous allons utiliser AlloyDB comme base de données pour les données de test. Il utilise des clusters pour contenir toutes les ressources, telles que les bases de données et les journaux. Chaque cluster possède une instance principale qui fournit un point d'accès aux données. Les tables contiennent les données réelles.
Commençons par créer un cluster, une instance et une table AlloyDB dans lesquels l'ensemble de données de test sera chargé.
- Cliquez sur le bouton ou copiez le lien ci-dessous dans le navigateur dans lequel l'utilisateur de la console Google Cloud est connecté.
- Une fois cette étape terminée, le dépôt sera cloné dans votre éditeur Cloud Shell local. Vous pourrez ensuite exécuter la commande ci-dessous à partir du dossier du projet (assurez-vous d'être dans le répertoire du projet) :
sh run.sh
- Utilisez maintenant l'UI (en cliquant sur le lien dans le terminal ou sur le lien "Prévisualiser sur le Web" dans le terminal).
- Saisissez les informations requises pour l'ID de projet, ainsi que les noms du cluster et de l'instance pour commencer.
- Allez prendre un café pendant que les journaux défilent. Pour en savoir plus sur le fonctionnement en coulisses, cliquez ici. Cette opération peut prendre entre 10 et 15 minutes.
Problèmes et dépannage
Le problème de la patience | Les clusters de bases de données sont une infrastructure lourde. Si vous actualisez la page ou mettez fin à la session Cloud Shell parce qu'elle semble bloquée, vous risquez de vous retrouver avec une instance "fantôme" partiellement provisionnée et impossible à supprimer sans intervention manuelle. |
Région non concordante | Si vous avez activé vos API dans |
Clusters de zombies | Si vous avez déjà utilisé le même nom pour un cluster et que vous ne l'avez pas supprimé, le script peut indiquer que le nom du cluster existe déjà. Les noms de clusters doivent être uniques dans un projet. |
Délai d'inactivité de Cloud Shell | Si votre pause-café dure 30 minutes, Cloud Shell peut se mettre en veille et déconnecter le processus |
4. Provisionnement de schémas
Au cours de cette étape, nous allons aborder les points suivants :
Une fois votre cluster et votre instance AlloyDB en cours d'exécution, accédez à l'éditeur SQL AlloyDB Studio pour activer les extensions d'IA et provisionner le schéma.
Vous devrez peut-être patienter jusqu'à ce que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb" (ou celui que vous avez défini lors de la création)
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
Vous saisirez des commandes pour AlloyDB dans des fenêtres d'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Activer les extensions
Pour créer cette application, nous allons utiliser les extensions pgvector et google_ml_integration. L'extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivants :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Créer une table
Nous avons besoin d'un ensemble de données pour illustrer l'échelle. Au lieu d'importer un fichier CSV, nous allons générer instantanément 50 000 lignes d'"articles d'aide" synthétiques à l'aide de SQL.
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
La colonne item_vector permettra de stocker les valeurs vectorielles du texte.
Vérifiez les données :
SELECT count(*) FROM help_articles;
-- Output: 50000
Activer les indicateurs de base de données
Accédez à la console de configuration de l'instance, cliquez sur "Modifier le primaire", accédez à la configuration avancée, puis cliquez sur "Ajouter des flags de base de données".
Si ce n'est pas le cas, saisissez-le dans le menu déroulant des indicateurs, définissez-le sur "ON" (Activé), puis mettez à jour l'instance.
Si ce n'est pas le cas, saisissez-le dans le menu déroulant des indicateurs, définissez-le sur "ON" (Activé), puis mettez à jour l'instance.
Étapes à suivre pour configurer les options de base de données :
- Dans la console Google Cloud, accédez à la page "Clusters".
- Cliquez sur un cluster dans la colonne Nom de la ressource.
- Sur la page Présentation, accédez à Instances dans votre cluster, sélectionnez une instance, puis cliquez sur Modifier.
- Ajoutez, modifiez ou supprimez un indicateur de base de données de votre instance :
Ajouter une option
- Pour ajouter un indicateur de base de données à votre instance, cliquez sur Ajouter un indicateur.
- Sélectionnez un indicateur dans la liste "Nouvel indicateur de base de données".
- Indiquez une valeur pour l'option.
- Cliquez sur "OK".
- Cliquez sur Mettre à jour l'instance.
- Vérifiez que l'extension google_ml_integration est de version 1.5.2 ou ultérieure :
Pour vérifier la version de votre extension, exécutez la commande suivante :
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Si vous devez mettre à jour l'extension vers une version ultérieure, utilisez la commande suivante :
ALTER EXTENSION google_ml_integration UPDATE;
Accorder l'autorisation
- Pour autoriser un utilisateur à gérer la génération d'intégrations automatiques, accordez-lui les autorisations INSERT, UPDATE et DELETE sur les tables google_ml.embed_gen_progress et google_ml.embed_gen_settings :
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
"postgres" est le USER_NAME pour lequel les autorisations sont accordées.
- Exécutez l'instruction ci-dessous pour accorder l'exécution de la fonction "embedding" :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Attribuer le RÔLE Utilisateur Vertex AI au compte de service AlloyDB
Dans la console Google Cloud IAM, accordez au compte de service AlloyDB (qui ressemble à ceci : service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accès au rôle "Utilisateur Vertex AI". PROJECT_NUMBER correspondra au numéro de votre projet.
Vous pouvez également exécuter la commande ci-dessous à partir du terminal Cloud Shell :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Problèmes et dépannage
La boucle "Password Amnesia" | Si vous avez utilisé la configuration "En un clic" et que vous ne vous souvenez plus de votre mot de passe, accédez à la page "Informations de base sur l'instance" dans la console, puis cliquez sur "Modifier" pour réinitialiser le mot de passe |
Erreur "Extension introuvable" | Si |
5. Génération de vecteurs "one-shot"
C'est le cœur de l'atelier. Au lieu d'écrire une boucle Python pour traiter ces 50 000 lignes, nous allons utiliser la fonction ai.initialize_embeddings.
Cette commande unique effectue deux opérations :
- Remplissez toutes les lignes existantes.
- Créez un déclencheur pour intégrer automatiquement les futures lignes.
Exécutez l'instruction SQL ci-dessous à partir de l'éditeur de requête AlloyDB.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
Vérifier les embeddings
Vérifiez que la colonne embedding est désormais renseignée :
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Vous devriez obtenir un résultat semblable à celui-ci :
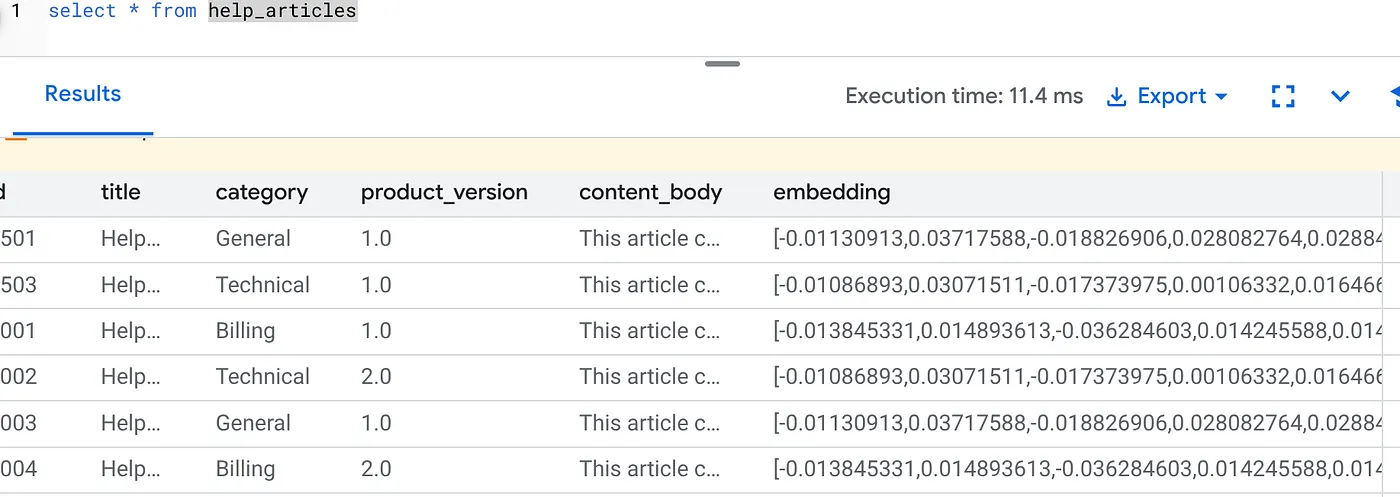
Que s'est-il passé ?
- Remplissage à grande échelle : il parcourt automatiquement vos 50 000 lignes existantes et génère des embeddings via Vertex AI.
- Automatisation : en définissant incremental_refresh_mode => 'transactional', AlloyDB configure automatiquement les déclencheurs internes. L'intégration de toute nouvelle ligne insérée dans help_articles sera générée instantanément.
- Vous pouvez éventuellement définir incremental_refresh_mode => 'None' pour n'obtenir que l'instruction permettant d'effectuer des mises à jour groupées et appeler manuellement ai.refresh_embeddings() pour mettre à jour les embeddings de toutes les lignes.
Vous venez de remplacer une file d'attente Kafka, un worker Python et un script de migration par six lignes de code SQL. Vous trouverez la documentation officielle détaillée pour tous les attributs.
Test de déclencheur en temps réel
Vérifions que l'automatisation "Zero Loop" fonctionne pour les nouvelles données.
- Insérer une ligne :
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Vérifier immédiatement :
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Résultat
Le vecteur généré devrait s'afficher instantanément, sans que vous ayez à exécuter de script externe.
Ajuster la taille du lot
Actuellement, la taille de lot par défaut d'AlloyDB est de 50. Bien que les paramètres par défaut fonctionnent parfaitement, AlloyDB permet aux utilisateurs de définir la configuration idéale pour leur modèle et leur ensemble de données uniques.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Toutefois, les utilisateurs doivent être conscients des limites de quota qui peuvent limiter les performances. Pour consulter les quotas AlloyDB recommandés, reportez-vous à la section "Avant de commencer" de la documentation.
Problèmes et dépannage
Délai de propagation IAM | Vous avez exécuté la commande IAM |
Incompatibilité de la dimension du vecteur | La table |
6. Flexing Context Search
Nous allons maintenant effectuer une recherche hybride. Nous combinons la compréhension sémantique (vecteurs) et la logique métier (filtres SQL).
Exécutez cette requête pour trouver les problèmes de facturation spécifiques à la version 2.0 du produit :
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
C'est le contexte de flexion. La recherche "s'adapte" pour comprendre l'intention de l'utilisateur ("problèmes de facturation") tout en respectant les contraintes commerciales strictes (version 2.0).
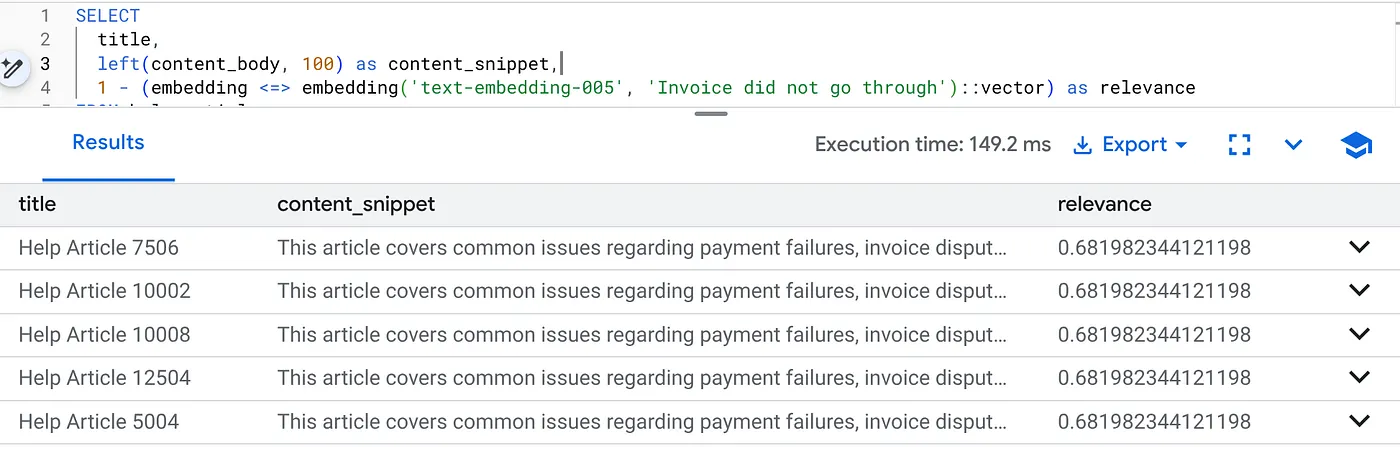
Pourquoi cette solution est-elle idéale pour les start-up et les migrations ?
- Aucune dette d'infrastructure : vous n'avez pas créé de base de données vectorielle distincte (Pinecone/Milvus). Vous n'avez pas écrit de job ETL distinct. Tout est dans Postgres.
- Mises à jour en temps réel : en utilisant le mode "transactionnel", votre index de recherche n'est jamais obsolète. Dès que les données sont validées, elles sont prêtes à être vectorisées.
- Évolutivité : AlloyDB est basé sur l'infrastructure de Google. Il peut générer des millions de vecteurs en masse plus rapidement que votre script Python.
Problèmes et dépannage
Problèmes de performances en production | Problème : rapide pour 50 000 lignes. Très lent pour un million de lignes si le filtre de catégorie n'est pas assez sélectif. Solution : ajoutez un index vectoriel. Pour une échelle de production, vous devez créer un index : CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops) ; Vérifiez l'utilisation de l'index : exécutez |
La catastrophe de la "non-concordance des modèles" | Problème : vous avez initialisé la colonne à l'aide de text-embedding-005 dans la procédure CALL. Si vous utilisez accidentellement un autre modèle (par exemple, text-embedding-004 ou un modèle OSS) dans la fonction de requête SELECT embedding('model-name', ...), les dimensions peuvent correspondre (768), mais l'espace vectoriel sera totalement différent. La requête s'exécute sans erreur, mais les résultats sont complètement hors sujet (scores de pertinence inutiles). Dépannage : assurez-vous que model_id dans ai.initialize_embeddings correspond exactement à model_id dans votre requête SELECT. |
Résultat "Silent Empty" (surfiltrage) | Problème : la recherche hybride est une opération "AND". Elle nécessite une correspondance sémantique ET une correspondance SQL.Si un utilisateur recherche "Aide sur la facturation", mais que la colonne
|
4. Erreurs d'autorisation/de quota (erreur 500) | Problème : la fonction
|
5. Embeddings nuls | Problème : si vous insérez des données avant que le modèle soit entièrement initialisé ou si le nœud de calcul en arrière-plan échoue, certaines lignes peuvent contenir
|
7. Effectuer un nettoyage
Une fois cet atelier terminé, n'oubliez pas de supprimer le cluster et l'instance AlloyDB.
Il devrait nettoyer le cluster ainsi que ses instances.
8. Félicitations
Vous avez créé une application de recherche dans la base de connaissances évolutive. Au lieu de gérer un pipeline ETL complexe avec des scripts et des boucles Python pour générer des embeddings vectoriels, vous avez utilisé AlloyDB AI pour gérer la génération d'embeddings de manière native dans la base de données à l'aide d'une seule commande SQL.
Ce que vous avez appris
- Nous avons supprimé la boucle "Python For" pour le traitement des données.
- Nous avons généré 50 000 vecteurs avec une seule commande SQL.
- Nous avons automatisé la génération de futurs vecteurs avec des déclencheurs.
- Nous avons effectué une recherche hybride.
Étapes suivantes
- Essayez avec votre propre ensemble de données.
- Consultez la documentation AlloyDB AI.
- Pour découvrir d'autres ateliers, consultez le site Web Code Vipassana.