
1. סקירה כללית
ב-Codelab הזה נסביר איך לבנות אפליקציית חיפוש במאגר ידע שניתן להרחבה. במקום לנהל צינור ETL מורכב עם סקריפטים ולולאות של Python כדי ליצור הטמעות וקטוריות, תשתמשו ב-AlloyDB AI כדי לטפל ביצירת ההטמעות באופן מקורי בתוך מסד הנתונים באמצעות פקודת SQL אחת.
מה תפַתחו
אפליקציית מסד נתונים של מאגר ידע שניתן לחיפוש ובעלת ביצועים גבוהים.
מה תלמדו
במאמר הזה תלמדו איך:
- הקצאת אשכול AlloyDB והפעלת תוספי AI.
- יצירת נתונים סינתטיים (50,000 שורות ומעלה) באמצעות SQL.
- מילוי חוסרים של הטמעות וקטוריות בכל מערך הנתונים באמצעות עיבוד באצווה.
- כדי להטמיע נתונים חדשים באופן אוטומטי, צריך להגדיר טריגרים מצטברים בזמן אמת.
- מבצעים חיפוש היברידי (מסנני וקטור + SQL) לחיפוש 'Flexing Context'.
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט.
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, אפשר לבדוק שכבר בוצע אימות ושהפרויקט מוגדר לפי מזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: לוחצים על הקישור ומפעילים את ממשקי ה-API.
אפשר גם להשתמש בפקודת gcloud. אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
נקודות חשובות ופתרון בעיות
תסמונת הפרויקט הרפאים | הפעלתם את הפקודה |
מחסום החיוב | הפעלתם את הפרויקט, אבל שכחתם להוסיף חשבון לחיוב. AlloyDB הוא מנוע עם ביצועים גבוהים, והוא לא יופעל אם 'מיכל הדלק' (החיוב) ריק. |
השהיה בפרסום ה-API | לחצתם על 'הפעלת ממשקי API', אבל בשורת הפקודה עדיין מופיע |
מכסה Quags | אם אתם משתמשים בחשבון ניסיון חדש לגמרי, יכול להיות שתגיעו למכסה אזורית של מופעי AlloyDB. אם הפעולה |
סוכן שירות 'מוסתר' | לפעמים סוכן השירות של AlloyDB לא מקבל אוטומטית את התפקיד |
3. הגדרת מסד נתונים
בשיעור ה-Lab הזה נשתמש ב-AlloyDB כמסד הנתונים של נתוני הבדיקה. הוא משתמש באשכולות כדי להכיל את כל המשאבים, כמו מסדי נתונים ויומנים. לכל אשכול יש מופע ראשי שמספק נקודת גישה לנתונים. הטבלאות יכילו את הנתונים בפועל.
ניצור אשכול, מכונה וטבלה של AlloyDB שבהם ייטען מערך הנתונים של הבדיקה.
- לוחצים על הלחצן או מעתיקים את הקישור שלמטה לדפדפן שבו המשתמש מחובר למסוף Google Cloud.
- אחרי שתשלימו את השלב הזה, המאגר ישוכפל לעורך המקומי של Cloud Shell ותוכלו להריץ את הפקודה שבהמשך מתוך תיקיית הפרויקט (חשוב לוודא שאתם בספריית הפרויקט):
sh run.sh
- עכשיו משתמשים בממשק המשתמש (לוחצים על הקישור במסוף או על הקישור 'תצוגה מקדימה באינטרנט' במסוף).
- כדי להתחיל, מזינים את הפרטים של מזהה הפרויקט, האשכול ושמות המופעים.
- אתם יכולים ללכת לשתות קפה בזמן שהיומנים מתעדכנים, וכאן תוכלו לקרוא איך זה קורה מאחורי הקלעים. התהליך יימשך כ-10 עד 15 דקות.
נקודות חשובות ופתרון בעיות
בעיית הסבלנות | אשכולות של מסדי נתונים הם תשתית כבדה. אם תרעננו את הדף או תסיימו את הסשן ב-Cloud Shell כי נראה שהוא נתקע, יכול להיות שתקבלו מופע 'רפאים' שהוקצה באופן חלקי ואי אפשר למחוק אותו בלי התערבות ידנית. |
חוסר התאמה באזור | אם הפעלתם את ממשקי ה-API ב- |
Zombie Clusters | אם השתמשתם בעבר באותו שם לאשכול ולא מחקתם אותו, יכול להיות שהסקריפט יציין שהשם של האשכול כבר קיים. שמות האשכולות צריכים להיות ייחודיים בתוך פרויקט. |
פסק זמן ב-Cloud Shell | אם הפסקת הקפה שלכם נמשכת 30 דקות, יכול להיות ש-Cloud Shell יעבור למצב שינה וינתק את התהליך |
4. הקצאת הרשאות לסכימה
בשלב הזה נסביר על:
אחרי שמפעילים את האשכול ואת המכונה של AlloyDB, עוברים אל כלי העריכה של SQL ב-AlloyDB Studio כדי להפעיל את תוספי ה-AI ולספק את הסכימה.
יכול להיות שתצטרכו לחכות עד שהמופע שלכם יסיים את תהליך היצירה. אחרי שיוצרים את האשכול, נכנסים ל-AlloyDB באמצעות פרטי הכניסה שיצרתם. משתמשים בנתונים הבאים כדי לבצע אימות ב-PostgreSQL:
- שם משתמש : "
postgres" - מסד נתונים : "
postgres" - סיסמה:
alloydb(או כל סיסמה שהגדרתם בזמן היצירה)
אחרי שתעברו בהצלחה את תהליך האימות ב-AlloyDB Studio, תוכלו להזין פקודות SQL בכלי העריכה. אפשר להוסיף כמה חלונות של Editor באמצעות סימן הפלוס שמשמאל לחלון האחרון.
מזינים פקודות ל-AlloyDB בחלונות של כלי העריכה, ומשתמשים באפשרויות Run (הפעלה), Format (עיצוב) ו-Clear (ניקוי) לפי הצורך.
הפעלת תוספים
כדי לבנות את האפליקציה הזו, נשתמש בתוספים pgvector ו-google_ml_integration. התוסף pgvector מאפשר לכם לאחסן ולחפש הטמעות של וקטורים. התוסף google_ml_integration מספק פונקציות שמשמשות לגישה לנקודות קצה (endpoints) של חיזוי ב-Vertex AI כדי לקבל חיזויים ב-SQL. מפעילים את התוספים האלה על ידי הפעלת פקודות ה-DDL הבאות:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
צור טבלה
אנחנו צריכים מערך נתונים כדי להדגים את ההיקף. במקום לייבא קובץ CSV, אנחנו ניצור באופן מיידי 50,000 שורות של 'מאמרי עזרה' סינתטיים באמצעות SQL.
אתם יכולים ליצור טבלה באמצעות הצהרת ה-DDL שבהמשך ב-AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
בעמודה item_vector אפשר לאחסן את ערכי הווקטור של הטקסט.
בודקים את הנתונים:
SELECT count(*) FROM help_articles;
-- Output: 50000
הפעלת דגלים של מסד נתונים
עוברים למסוף הגדרות המופע, לוחצים על 'עריכת ראשי', עוברים אל 'הגדרות מתקדמות' ולוחצים על 'הוספת דגלים של מסד נתונים'.
אם לא, מזינים אותו בתפריט הנפתח של הדגלים, מעבירים אותו למצב 'מופעל' ומעדכנים את המופע.
אם לא, מזינים אותו בתפריט הנפתח של הדגלים, מעבירים אותו למצב 'מופעל' ומעדכנים את המופע.
שלבים להגדרת דגלים של מסד נתונים:
- במסוף Google Cloud, עוברים לדף Clusters.
- לוחצים על אשכול בעמודה שם המשאב.
- בדף סקירה כללית, עוברים אל Instances (מופעים) באשכול, בוחרים מופע ולוחצים על Edit (עריכה).
- כדי להוסיף, לשנות או למחוק דגל לניהול מסד נתונים מהמופע:
הוספת דגל
- כדי להוסיף דגל לניהול מסד נתונים למכונה, לוחצים על 'הוספת דגל'.
- בוחרים דגל מהרשימה New database flag (דגל חדש של מסד נתונים).
- מזינים ערך לדגל.
- לוחצים על 'סיום'.
- לוחצים על עדכון המופע.
- מוודאים שהתוסף google_ml_integration הוא בגרסה 1.5.2 ואילך:
כדי לבדוק את גרסת התוסף באמצעות הפקודה הבאה:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
אם צריך לשדרג את התוסף, משתמשים בפקודה:
ALTER EXTENSION google_ml_integration UPDATE;
מתן הרשאה
- כדי לאפשר למשתמש לנהל את יצירת ההטמעה האוטומטית, צריך להעניק לו הרשאות INSERT, UPDATE ו-DELETE בטבלאות google_ml.embed_gen_progress ו-google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
postgres הוא USER_NAME שההרשאות ניתנות לו.
- מריצים את ההצהרה הבאה כדי להעניק הרשאת הפעלה לפונקציה embedding:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
הענקת התפקיד Vertex AI User לחשבון השירות של AlloyDB
במסוף IAM של Google Cloud, מעניקים לחשבון השירות של AlloyDB (שנראה כך: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) גישה לתפקיד Vertex AI User. PROJECT_NUMBER יכיל את מספר הפרויקט.
לחלופין, אפשר להריץ את הפקודה הבאה מ-Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
נקודות חשובות ופתרון בעיות
הלולאה של 'שכחתי את הסיסמה' | אם השתמשתם בהגדרה 'קליק אחד' ואתם לא זוכרים את הסיסמה, אתם יכולים לעבור לדף 'פרטים בסיסיים של מופע' במסוף וללחוץ על 'עריכה' כדי לאפס את הסיסמה |
השגיאה 'התוסף לא נמצא' | אם הפעולה |
5. יצירת וקטורים בשיטת One-Shot
זהו החלק המרכזי של שיעור ה-Lab. במקום לכתוב לולאת Python כדי לעבד את 50,000 השורות האלה, נשתמש בפונקציה ai.initialize_embeddings.
הפקודה הזו מבצעת שתי פעולות:
- Backfills כל השורות הקיימות.
- יצירת טריגר להטמעה אוטומטית של שורות עתידיות.
מריצים את הצהרת ה-SQL שלמטה מ-AlloyDB Query Editor
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
אימות ההטמעות
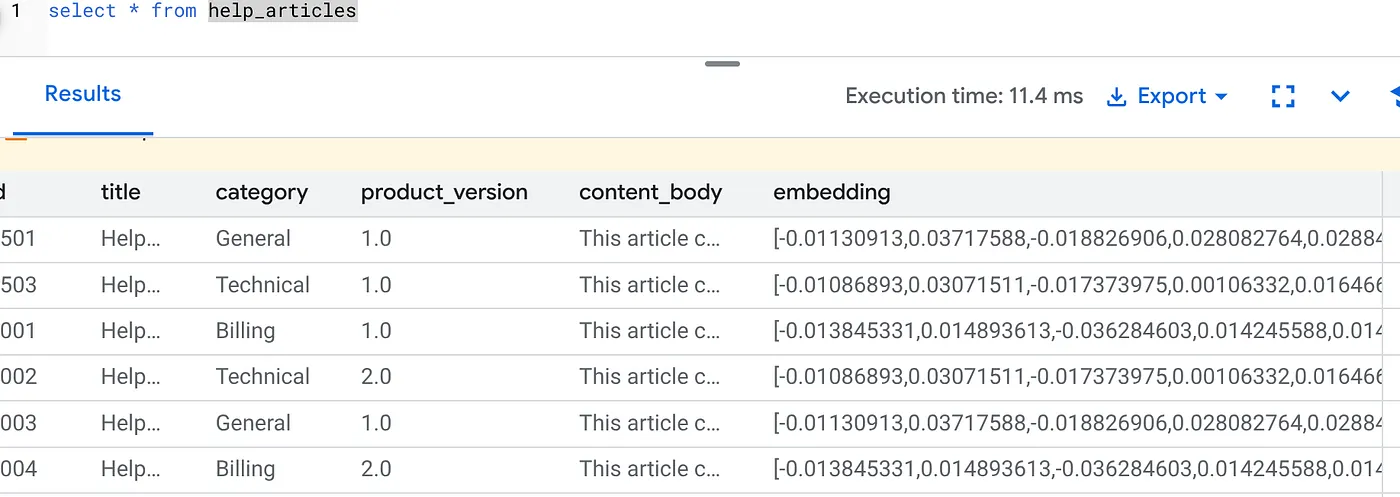
בודקים שהעמודה embedding מאוכלסת עכשיו:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
אמורה להופיע תוצאה דומה לזו שבהמשך:
מה קרה עכשיו?
- מילוי חוסרים בהיקף נרחב: המערכת סורקת אוטומטית את 50,000 השורות הקיימות ויוצרת הטמעות באמצעות Vertex AI.
- אוטומציה: אם מגדירים את הערך incremental_refresh_mode => 'transactional', AlloyDB מגדיר אוטומטית את הטריגרים הפנימיים. כל שורה חדשה שתוכנס לטבלה help_articles תעבור מיד הטמעה.
- אפשר גם להגדיר את incremental_refresh_mode => ‘None' כדי לקבל את ההצהרה רק כדי לבצע עדכונים בכמות גדולה, ולהפעיל באופן ידני את ai.refresh_embeddings() כדי לעדכן את כל ההטמעות של השורות.
החלפתם תור Kafka, תהליך עובד של Python וסקריפט העברה ב-6 שורות של SQL. כאן מופיע תיעוד רשמי מפורט של כל המאפיינים.
בדיקת טריגר בזמן אמת
נבדוק שהאוטומציה 'לולאה אפס' פועלת על נתונים חדשים.
- להוסיף שורה חדשה:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- בדיקה מיידית:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
תוצאה:
הווקטור אמור להיווצר באופן מיידי בלי להריץ סקריפט חיצוני.
גודל האצווה של כוונון
כרגע, גודל אצווה ברירת המחדל ב-AlloyDB הוא 50. הגדרות ברירת המחדל פועלות מצוין, אבל AlloyDB עדיין מאפשר למשתמשים לשנות את ההגדרות כדי להתאים אותן למודל ולמערך הנתונים הייחודיים שלהם.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
עם זאת, חשוב שהמשתמשים יהיו מודעים למגבלות המכסה, שיכולות להגביל את הביצועים. כדי לעיין במכסות המומלצות של AlloyDB, אפשר לעיין בקטע 'לפני שמתחילים' במסמכי התיעוד.
נקודות חשובות ופתרון בעיות
הפער בהפצת IAM | הפעלתם את פקודת ה-IAM |
חוסר התאמה במאפיין הווקטור | הטבלה |
6. חיפוש לפי הקשר
עכשיו נבצע חיפוש היברידי. אנחנו משלבים בין הבנה סמנטית (וקטור) לבין לוגיקה עסקית (מסנני SQL).
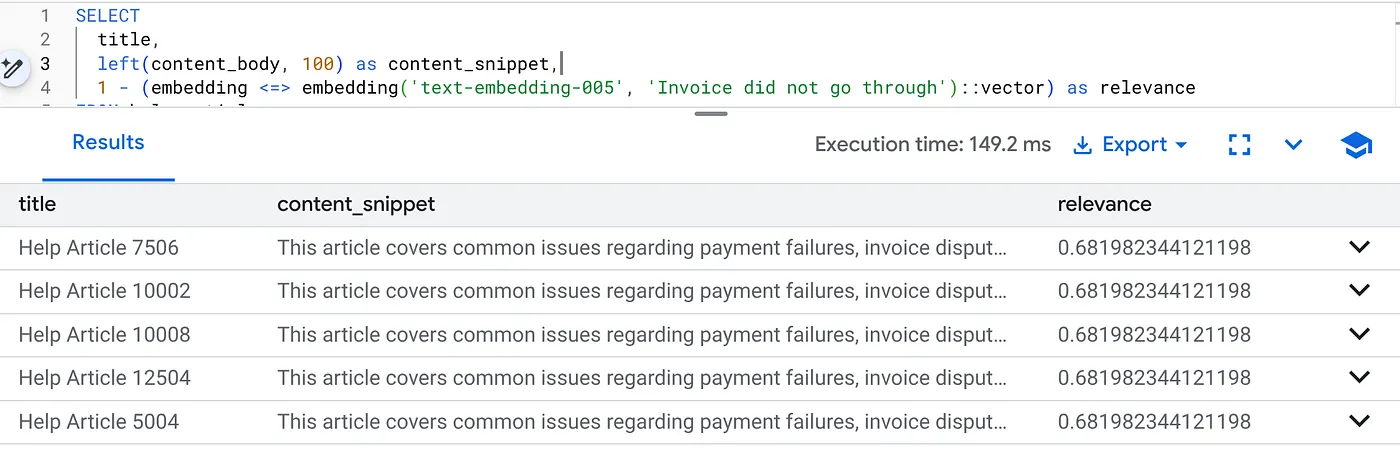
כדי להריץ את השאילתה הזו ולמצוא בעיות בחיוב שקשורות ספציפית לגרסה 2.0 של המוצר:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
זהו הקשר הגמיש. החיפוש "מתגמש" כדי להבין את כוונת המשתמש ("בעיות בחיוב") תוך שמירה על מגבלות עסקיות נוקשות (גרסה 2.0).
למה זה פתרון טוב לסטארטאפים ולהעברות
- אפס חובות בתשתית: לא התחלתם הרצה של מסד נתונים נפרד של וקטורים (Pinecone/Milvus). לא כתבתם משימת ETL נפרדת. הכול נמצא ב-Postgres.
- עדכונים בזמן אמת: באמצעות שימוש במצב 'טרנזקציוני', אינדקס החיפוש שלכם אף פעם לא מתיישן. ברגע שהנתונים נשמרים, הם מוכנים להפוך לווקטורים.
- מדרגיות: AlloyDB מבוסס על התשתית של Google. הוא יכול להתמודד עם יצירה בכמות גדולה של מיליוני וקטורים מהר יותר ממה שסקריפט Python יכול.
נקודות חשובות ופתרון בעיות
בעיה בביצועים של יצירת תוכן | בעיה: מהיר ל-50,000 שורות. הפעולה איטית מאוד עבור מיליון שורות אם מסנן הקטגוריות לא סלקטיבי מספיק. פתרון:מוסיפים אינדקס וקטורי: כדי להשתמש בפתרון בסביבת ייצור, צריך ליצור אינדקס:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);מאמתים את השימוש באינדקס: מריצים את הפקודה |
האסון של חוסר התאמה בין מודלים | בעיה: הפעלתם את העמודה באמצעות text-embedding-005 בהליך CALL. אם משתמשים בטעות במודל אחר (למשל, text-embedding-004 או מודל OSS) בפונקציית ההטמעה של שאילתת ה-SELECT embedding('model-name', ...), יכול להיות שהממדים יהיו זהים (768), אבל מרחב הווקטורים יהיה שונה לחלוטין. השאילתה תפעל ללא שגיאה, אבל התוצאות לא יהיו רלוונטיות בכלל (ציוני רלוונטיות לא מדויקים). פתרון בעיות:מוודאים ש-model_id ב-ai.initialize_embeddings זהה בדיוק ל-model_id בשאילתת ה-SELECT. |
התוצאה Silent Empty (סינון יתר) | בעיה: חיפוש היברידי הוא פעולת AND. היא דורשת התאמה סמנטית והתאמת SQL.אם משתמש מחפש "עזרה בנושא חיוב" אבל בעמודה
|
4. שגיאות הרשאה או שגיאות שקשורות למכסות (שגיאה 500) | בעיה:הפונקציה
|
5. הטמעות מסוג Null | בעיה:אם מוסיפים נתונים לפני שהמודל מאותחל באופן מלא או אם יש כשל בתהליך הרקע, יכול להיות שחלק מהשורות יכילו את הערך
|
7. הסרת המשאבים
אחרי שמסיימים את ה-Lab הזה, חשוב למחוק את אשכול AlloyDB ואת המכונה.
הוא צריך לנקות את האשכול יחד עם המופעים שלו.
8. מזל טוב
יצרתם בהצלחה אפליקציית חיפוש במאגר ידע שניתנת להרחבה. במקום לנהל צינור ETL מורכב עם סקריפטים של Python ולולאות כדי ליצור הטמעות וקטוריות, השתמשתם ב-AlloyDB AI כדי לטפל ביצירת ההטמעות באופן מקורי בתוך מסד הנתונים באמצעות פקודת SQL אחת.
מה למדנו
- ביטלנו את Python For-Loop לעיבוד נתונים.
- יצרנו 50,000 וקטורים באמצעות פקודת SQL אחת.
- הוספנו טריגרים כדי ליצור וקטורים באופן אוטומטי בעתיד.
- ביצענו חיפוש היברידי.
השלבים הבאים
- אתם יכולים לנסות את זה עם קבוצת נתונים משלכם.
- מאמרי העזרה של AlloyDB AI
- באתר Code Vipassana אפשר למצוא סדנאות נוספות.