
1. खास जानकारी
इस कोडलैब में, आपको एक ऐसा नॉलेज बेस सर्च ऐप्लिकेशन बनाने का तरीका बताया जाएगा जिसे आसानी से बढ़ाया जा सकता है. वेक्टर एंबेडिंग जनरेट करने के लिए, Python स्क्रिप्ट और लूप के साथ जटिल ईटीएल पाइपलाइन को मैनेज करने के बजाय, AlloyDB AI का इस्तेमाल किया जाएगा. इससे, एक ही एसक्यूएल कमांड का इस्तेमाल करके, डेटाबेस में एंबेडिंग जनरेट की जा सकेंगी.
आपको क्या बनाना है
यह एक ऐसा डेटाबेस ऐप्लिकेशन है जिसमें नॉलेज बेस को "खोजा जा सकता है" और जिसकी परफ़ॉर्मेंस बहुत अच्छी होती है.
आपको क्या सीखने को मिलेगा
आपको इनके बारे में जानकारी मिलेगी:
- AlloyDB क्लस्टर को प्रोविज़न करें और एआई एक्सटेंशन चालू करें.
- एसक्यूएल का इस्तेमाल करके सिंथेटिक डेटा (50,000 से ज़्यादा लाइनें) जनरेट करें.
- बैच प्रोसेसिंग का इस्तेमाल करके, पूरे डेटासेट के लिए वेक्टर एम्बेडिंग को बैकफ़िल करें.
- नए डेटा को अपने-आप एम्बेड करने के लिए, रीयल-टाइम इंक्रीमेंटल ट्रिगर सेट अप करें.
- "Flexing Context" के लिए, हाइब्रिड सर्च (वेक्टर + SQL फ़िल्टर) करें.
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें: लिंक पर जाएं और एपीआई चालू करें.
इसके अलावा, इसके लिए gcloud कमांड का इस्तेमाल किया जा सकता है. gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
समस्याएं और उन्हें हल करने का तरीका
"घोस्ट प्रोजेक्ट" सिंड्रोम | आपने |
बिलिंग बैरिकेड | आपने प्रोजेक्ट चालू किया है, लेकिन बिलिंग खाते की जानकारी नहीं दी है. AlloyDB एक हाई-परफ़ॉर्मेंस इंजन है. अगर "गैस टैंक" (बिलिंग) खाली है, तो यह शुरू नहीं होगा. |
एपीआई के डेटा को अपडेट होने में लगने वाला समय | आपने "एपीआई चालू करें" पर क्लिक किया है, लेकिन कमांड लाइन में अब भी |
कोटा Quags | अगर आपने नया ट्रायल खाता इस्तेमाल करना शुरू किया है, तो हो सकता है कि आप AlloyDB इंस्टेंस के लिए क्षेत्र के हिसाब से तय किए गए कोटे तक पहुंच जाएं. अगर |
"छिपा हुआ" सर्विस एजेंट | कभी-कभी, AlloyDB सेवा एजेंट को |
3. डेटाबेस सेटअप करना
इस लैब में, हम टेस्ट डेटा के लिए AlloyDB का इस्तेमाल करेंगे. यह सभी संसाधनों को सेव करने के लिए, क्लस्टर का इस्तेमाल करता है. जैसे, डेटाबेस और लॉग. हर क्लस्टर में एक प्राइमरी इंस्टेंस होता है, जो डेटा का ऐक्सेस पॉइंट उपलब्ध कराता है. टेबल में असल डेटा होगा.
आइए, एक AlloyDB क्लस्टर, इंस्टेंस, और टेबल बनाएं. इसमें टेस्ट डेटासेट लोड किया जाएगा.
- Google Cloud Console के उस ब्राउज़र में नीचे दिए गए बटन पर क्लिक करें या लिंक को कॉपी करें जहां आपने उपयोगकर्ता के तौर पर लॉग इन किया है.
- यह चरण पूरा होने के बाद, repo को आपके लोकल Cloud Shell एडिटर में क्लोन कर दिया जाएगा. इसके बाद, प्रोजेक्ट फ़ोल्डर में जाकर नीचे दिए गए कमांड को चलाया जा सकेगा. यह पक्का करना ज़रूरी है कि आप प्रोजेक्ट डायरेक्ट्री में हों:
sh run.sh
- अब यूज़र इंटरफ़ेस (टर्मिनल में लिंक पर क्लिक करके या टर्मिनल में "वेब पर झलक देखें" लिंक पर क्लिक करके) का इस्तेमाल करें.
- शुरू करने के लिए, प्रोजेक्ट आईडी, क्लस्टर, और इंस्टेंस के नाम डालें.
- जब तक लॉग स्क्रोल होते हैं, तब तक जाकर कॉफ़ी ले आएं. यहां पर्दे के पीछे होने वाली प्रोसेस के बारे में पढ़ा जा सकता है. इसमें करीब 10 से 15 मिनट लग सकते हैं.
समस्याएं और उन्हें हल करने का तरीका
"धैर्य" की समस्या | डेटाबेस क्लस्टर, एक बड़ा इन्फ़्रास्ट्रक्चर होता है. अगर आपने पेज को रीफ़्रेश किया या Cloud Shell सेशन को बंद किया, क्योंकि वह "स्टक हो गया है", तो हो सकता है कि आपको एक "घोस्ट" इंस्टेंस मिले. यह इंस्टेंस आंशिक रूप से उपलब्ध कराया गया होता है और इसे मैन्युअल तरीके से बंद किए बिना मिटाना मुमकिन नहीं होता. |
क्षेत्र की जानकारी मेल नहीं खाती | अगर आपने |
ज़ॉम्बी क्लस्टर | अगर आपने किसी क्लस्टर के लिए पहले भी इसी नाम का इस्तेमाल किया था और उसे मिटाया नहीं है, तो स्क्रिप्ट में यह मैसेज दिख सकता है कि क्लस्टर का नाम पहले से मौजूद है. किसी प्रोजेक्ट में क्लस्टर के नाम अलग-अलग होने चाहिए. |
Cloud Shell का टाइम आउट होना | अगर आपका कॉफ़ी ब्रेक 30 मिनट का है, तो Cloud Shell स्लीप मोड में जा सकता है और |
4. स्कीमा प्रोविज़निंग
इस चरण में, हम इन विषयों के बारे में जानकारी देंगे:
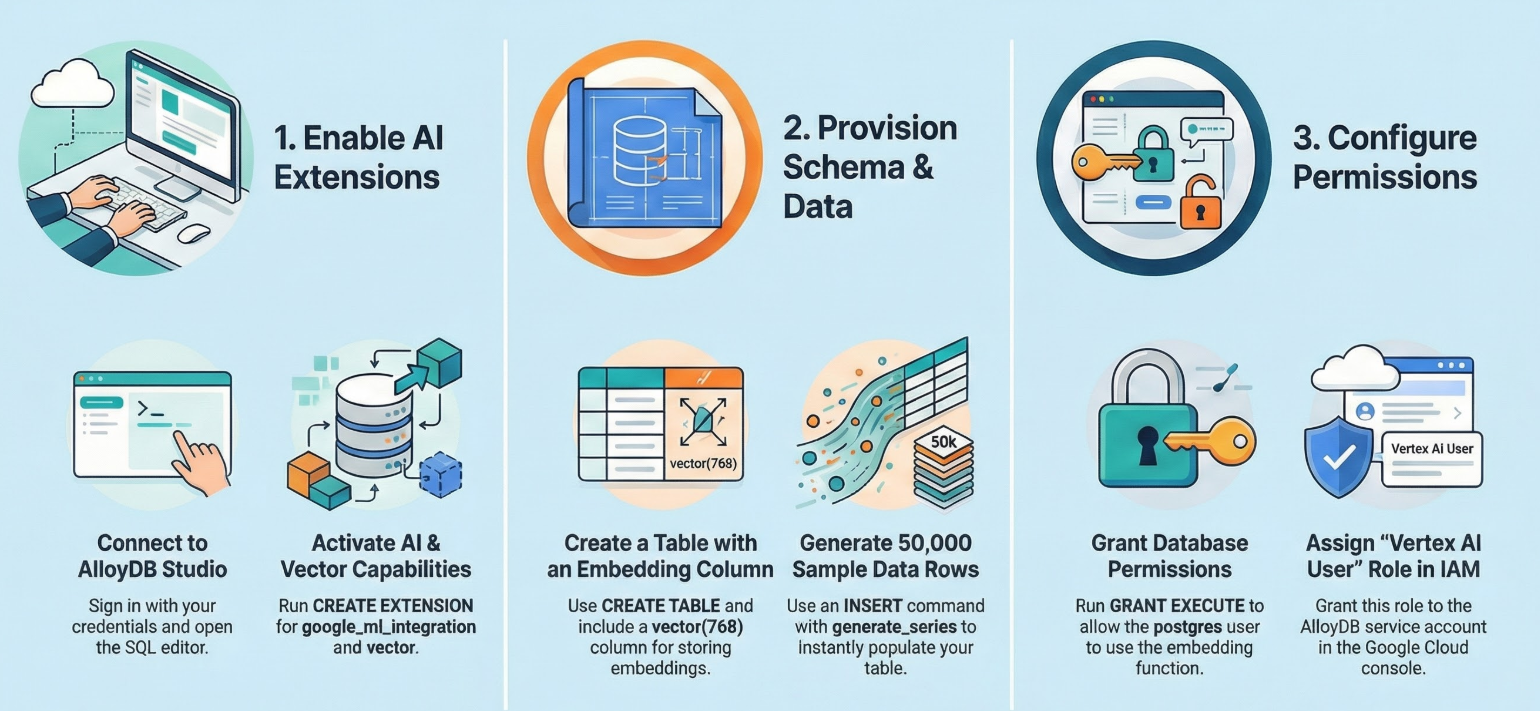
AlloyDB क्लस्टर और इंस्टेंस चालू होने के बाद, AlloyDB Studio के एसक्यूएल एडिटर पर जाएं. यहां एआई एक्सटेंशन चालू करें और स्कीमा उपलब्ध कराएं.
आपको इंस्टेंस बनने तक इंतज़ार करना पड़ सकता है. इसके बाद, क्लस्टर बनाते समय बनाए गए क्रेडेंशियल का इस्तेमाल करके, AlloyDB में साइन इन करें. PostgreSQL में पुष्टि करने के लिए, इस डेटा का इस्तेमाल करें:
- उपयोगकर्ता नाम : "
postgres" - डेटाबेस : "
postgres" - पासवर्ड : "
alloydb" (या खाता बनाते समय सेट किया गया पासवर्ड)
AlloyDB Studio में पुष्टि हो जाने के बाद, SQL कमांड को एडिटर में डाला जाता है. आखिरी विंडो के दाईं ओर मौजूद प्लस आइकॉन का इस्तेमाल करके, एक से ज़्यादा Editor विंडो जोड़ी जा सकती हैं.
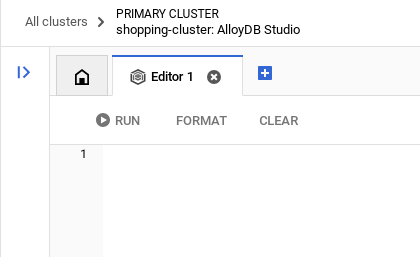
AlloyDB के लिए एडिटर विंडो में कमांड डालें. इसके लिए, ज़रूरत के हिसाब से Run, Format, और Clear विकल्पों का इस्तेमाल करें.
एक्सटेंशन चालू करना
इस ऐप्लिकेशन को बनाने के लिए, हम pgvector और google_ml_integration एक्सटेंशन का इस्तेमाल करेंगे. pgvector एक्सटेंशन की मदद से, वेक्टर एम्बेडिंग को सेव और खोजा जा सकता है. google_ml_integration एक्सटेंशन, ऐसे फ़ंक्शन उपलब्ध कराता है जिनका इस्तेमाल करके, Vertex AI के अनुमान लगाने वाले एंडपॉइंट को ऐक्सेस किया जा सकता है. इससे एसक्यूएल में अनुमान मिलते हैं. इन एक्सटेंशन को चालू करें. इसके लिए, ये DDL चलाएं:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
एक टेबल बनाओ
स्केल दिखाने के लिए, हमें एक डेटासेट की ज़रूरत है. हम CSV फ़ाइल इंपोर्ट करने के बजाय, SQL का इस्तेमाल करके तुरंत 50,000 नकली "सहायता लेख" जनरेट करेंगे.
AlloyDB Studio में, नीचे दिए गए डीडीएल स्टेटमेंट का इस्तेमाल करके टेबल बनाई जा सकती है:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
item_vector कॉलम में, टेक्स्ट की वेक्टर वैल्यू सेव की जा सकेंगी.
डेटा की पुष्टि करें:
SELECT count(*) FROM help_articles;
-- Output: 50000
डेटाबेस फ़्लैग चालू करना
इंस्टेंस कॉन्फ़िगरेशन कंसोल पर जाएं. इसके बाद, "प्राइमरी में बदलाव करें" पर क्लिक करें. इसके बाद, ऐडवांस कॉन्फ़िगरेशन पर जाएं और "डेटाबेस फ़्लैग जोड़ें" पर क्लिक करें.
अगर ऐसा नहीं है, तो फ़्लैग ड्रॉप-डाउन में जाकर इसे "चालू है" पर सेट करें और इंस्टेंस को अपडेट करें.
अगर ऐसा नहीं है, तो फ़्लैग ड्रॉप-डाउन में जाकर इसे "चालू है" पर सेट करें और इंस्टेंस को अपडेट करें.
डेटाबेस फ़्लैग कॉन्फ़िगर करने का तरीका:
- Google Cloud Console में, क्लस्टर पेज पर जाएं.
- संसाधन का नाम कॉलम में, किसी क्लस्टर पर क्लिक करें.
- खास जानकारी पेज पर, अपने क्लस्टर में मौजूद उदाहरण पर जाएं. इसके बाद, कोई उदाहरण चुनें और बदलाव करें पर क्लिक करें.
- अपने इंस्टेंस में डेटाबेस फ़्लैग जोड़ना, उसमें बदलाव करना या उसे मिटाना:
कोई फ़्लैग जोड़ना
- अपने इंस्टेंस में डेटाबेस फ़्लैग जोड़ने के लिए, फ़्लैग जोड़ें पर क्लिक करें.
- 'नया डेटाबेस फ़्लैग' सूची से कोई फ़्लैग चुनें.
- फ़्लैग के लिए कोई वैल्यू दें.
- 'हो गया' पर क्लिक करें.
- अपडेट इंस्टेंस पर क्लिक करें.
- पुष्टि करें कि google_ml_integration एक्सटेंशन का वर्शन 1.5.2 या उसके बाद का हो:
एक्सटेंशन का वर्शन देखने के लिए, यह कमांड इस्तेमाल करें:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
अगर आपको एक्सटेंशन को ज़्यादा समय के लिए अपडेट करना है, तो इस कमांड का इस्तेमाल करें:
ALTER EXTENSION google_ml_integration UPDATE;
अनुमति दें
- किसी उपयोगकर्ता को अपने-आप जनरेट होने वाले एम्बेड मैनेज करने की अनुमति देने के लिए, google_ml.embed_gen_progress और google_ml.embed_gen_settings टेबल पर INSERT, UPDATE, और DELETE की अनुमतियां दें:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
‘postgres' वह USER_NAME है जिसके लिए अनुमतियां दी गई हैं.
- "embedding" फ़ंक्शन पर 'execute' की अनुमति देने के लिए, नीचे दिया गया स्टेटमेंट चलाएं:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB सेवा खाते को Vertex AI उपयोगकर्ता की भूमिका असाइन करना
Google Cloud IAM Console में जाकर, AlloyDB सेवा खाते को "Vertex AI User" की भूमिका का ऐक्सेस दें. यह सेवा खाता इस तरह दिखता है: service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com. PROJECT_NUMBER में आपका प्रोजेक्ट नंबर होगा.
इसके अलावा, Cloud Shell टर्मिनल से यह कमांड भी चलाई जा सकती है:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
समस्याएं और उन्हें हल करने का तरीका
"पासवर्ड भूल जाना" लूप | अगर आपने "एक क्लिक" सेटअप का इस्तेमाल किया है और आपको अपना पासवर्ड याद नहीं है, तो कंसोल में इंस्टेंस की बुनियादी जानकारी वाले पेज पर जाएं. इसके बाद, |
"एक्सटेंशन नहीं मिला" गड़बड़ी | अगर |
5. "वन-शॉट" वेक्टर जनरेशन
यह लैब का मुख्य हिस्सा है. इन 50,000 लाइनों को प्रोसेस करने के लिए, Python लूप लिखने के बजाय, हम ai.initialize_embeddings फ़ंक्शन का इस्तेमाल करेंगे.
इस एक कमांड से दो काम होते हैं:
- बैकफ़िल सभी मौजूदा पंक्तियों को करता है.
- ट्रिगर बनाता है, ताकि आने वाली पंक्तियां अपने-आप एम्बेड हो जाएं.
AlloyDB क्वेरी एडिटर में जाकर, यहां दिया गया एसक्यूएल स्टेटमेंट चलाएं
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
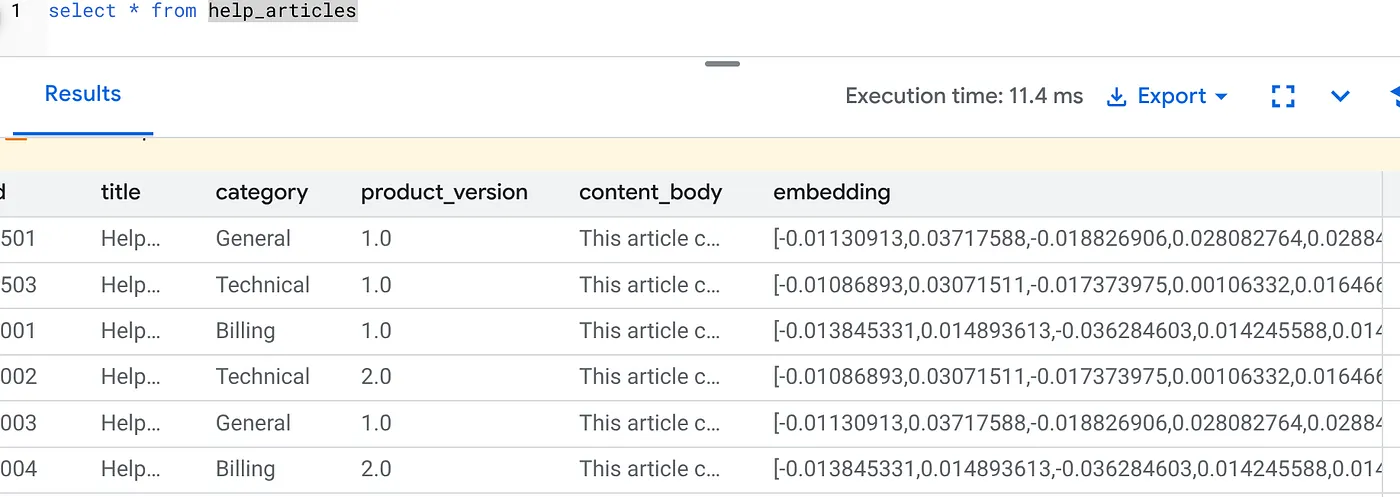
एम्बेड किए गए कॉन्टेंट की पुष्टि करना
देखें कि embedding कॉलम में अब वैल्यू मौजूद है या नहीं:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
आपको नीचे दिए गए नतीजे जैसा कोई नतीजा दिखेगा:
यह क्या हुआ?
- बड़े पैमाने पर बैकफ़िल करना: यह सुविधा, आपकी मौजूदा 50,000 लाइनों को अपने-आप स्कैन करती है और Vertex AI के ज़रिए एंबेडिंग जनरेट करती है.
- ऑटोमेशन: incremental_refresh_mode => 'transactional' सेट करने पर, AlloyDB अपने-आप इंटरनल ट्रिगर सेट अप कर देता है. help_articles टेबल में जोड़ी गई किसी भी नई लाइन का एम्बेडिंग तुरंत जनरेट हो जाएगा.
- आपके पास incremental_refresh_mode => ‘None' को सेट करने का विकल्प होता है. इससे आपको सिर्फ़ एक स्टेटमेंट मिलता है, ताकि एक साथ कई अपडेट किए जा सकें. साथ ही, सभी लाइनों की एम्बेडिंग को अपडेट करने के लिए, ai.refresh_embeddings() को मैन्युअल तरीके से कॉल किया जा सके.
आपने सिर्फ़ छह लाइनों के SQL कोड का इस्तेमाल करके, Kafka queue, Python वर्कर, और माइग्रेशन स्क्रिप्ट को बदल दिया है. सभी एट्रिब्यूट के बारे में पूरी जानकारी देने वाला आधिकारिक दस्तावेज़ यहां दिया गया है.
रीयल-टाइम ट्रिगर टेस्ट
आइए, पुष्टि करते हैं कि "ज़ीरो लूप" ऑटोमेशन की सुविधा, नए डेटा के लिए काम करती है.
- नई लाइन जोड़ना:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- तुरंत जांच करें:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
नतीजा:
आपको किसी बाहरी स्क्रिप्ट को चलाए बिना, जनरेट किया गया वेक्टर तुरंत दिखना चाहिए.
ट्यूनिंग बैच का साइज़
फ़िलहाल, AlloyDB में बैच का डिफ़ॉल्ट साइज़ 50 होता है. डिफ़ॉल्ट सेटिंग, बिना किसी बदलाव के ही बेहतरीन तरीके से काम करती हैं. हालांकि, AlloyDB उपयोगकर्ताओं को यह कंट्रोल देता है कि वे अपने यूनीक मॉडल और डेटासेट के लिए, सबसे सही कॉन्फ़िगरेशन सेट कर सकें.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
हालांकि, उपयोगकर्ताओं को कोटे की सीमाओं के बारे में पता होना चाहिए, क्योंकि इससे परफ़ॉर्मेंस सीमित हो सकती है. AlloyDB के लिए सुझाए गए कोटे देखने के लिए, दस्तावेज़ में "शुरू करने से पहले" सेक्शन देखें.
समस्याएं और उन्हें हल करने का तरीका
IAM के लागू होने में लगने वाला समय | आपने |
वेक्टर डाइमेंशन मेल नहीं खाते | कॉलम content_body पर, |
6. कॉन्टेक्स्ट के हिसाब से खोज करने की सुविधा
अब हम हाइब्रिड सर्च करते हैं. हम सिमैंटिक अंडरस्टैंडिंग (वेक्टर) को कारोबारी नियम (एसक्यूएल फ़िल्टर) के साथ जोड़ते हैं.
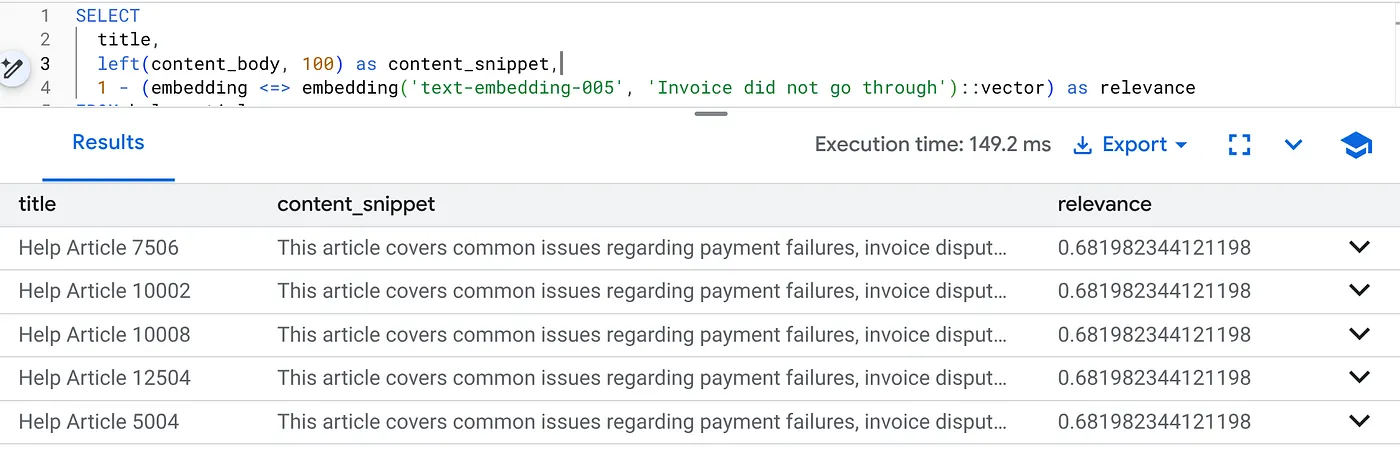
बिलिंग से जुड़ी समस्याओं का पता लगाने के लिए, यह क्वेरी चलाएं. यह क्वेरी खास तौर पर, प्रॉडक्ट के वर्शन 2.0 के लिए है:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
यह फ़्लेक्सिंग कॉन्टेक्स्ट है. खोज के दौरान, कारोबार से जुड़ी शर्तों (वर्शन 2.0) का पालन करते हुए, उपयोगकर्ता के मकसद ("बिलिंग से जुड़ी समस्याएं") को समझने की कोशिश की जाती है.
स्टार्टअप और माइग्रेशन के लिए यह क्यों फ़ायदेमंद है
- इंफ़्रास्ट्रक्चर से जुड़ी कोई समस्या नहीं: आपने अलग से कोई वेक्टर डेटाबेस (Pinecone/Milvus) नहीं बनाया है. आपने कोई अलग ईटीएल जॉब नहीं लिखी है. यह सब Postgres में है.
- रीयल-टाइम अपडेट: 'लेन-देन' मोड का इस्तेमाल करने पर, आपका खोज इंडेक्स कभी पुराना नहीं होता. डेटा को सेव करते ही, वह वेक्टर सर्च के लिए तैयार हो जाता है.
- स्केल: AlloyDB को Google के इंफ़्रास्ट्रक्चर पर बनाया गया है. यह लाखों वेक्टर को आपकी Python स्क्रिप्ट की तुलना में ज़्यादा तेज़ी से जनरेट कर सकता है.
समस्याएं और उन्हें हल करने का तरीका
Production Performance Gotcha | समस्या: 50,000 लाइनों के लिए तेज़. अगर कैटेगरी फ़िल्टर में ज़रूरत के मुताबिक विकल्प नहीं चुने गए हैं, तो 10 लाख पंक्तियों के लिए क्वेरी बहुत धीरे-धीरे प्रोसेस होती है.समाधान:वेक्टर इंडेक्स जोड़ें: प्रोडक्शन स्केल के लिए, आपको एक इंडेक्स बनाना होगा:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);इंडेक्स के इस्तेमाल की पुष्टि करें: यह पक्का करने के लिए |
"मॉडल मिसमैच" की समस्या | समस्या: आपने CALL प्रोसीजर में text-embedding-005 का इस्तेमाल करके कॉलम को शुरू किया है. अगर आपने SELECT क्वेरी फ़ंक्शन embedding('model-name', ...) में गलती से किसी दूसरे मॉडल (जैसे, text-embedding-004 या कोई ओएसएस मॉडल) का इस्तेमाल किया है, तो हो सकता है कि डाइमेंशन मैच हो जाएं (768). हालांकि, वेक्टर स्पेस पूरी तरह से अलग होगा. क्वेरी बिना किसी गड़बड़ी के चलती है, लेकिन नतीजे पूरी तरह से काम के नहीं होते (रिलेवेंस स्कोर बेकार होते हैं). समस्या हल करने का तरीका:पक्का करें कि ai.initialize_embeddings में मौजूद model_id, आपकी SELECT क्वेरी में मौजूद model_id से पूरी तरह मेल खाता हो. |
"साइलेंट ऐंड एम्टी" नतीजा (ज़्यादा फ़िल्टरिंग) | समस्या: हाइब्रिड सर्च, "AND" ऑपरेशन है. इसके लिए, सिमैंटिक मैच और एसक्यूएल मैच ज़रूरी है. अगर कोई उपयोगकर्ता "बिलिंग से जुड़ी मदद" खोजता है, लेकिन
|
4. अनुमति/कोटा से जुड़ी गड़बड़ियां (500 गड़बड़ी) | समस्या:
|
5. शून्य एम्बेडिंग | समस्या:अगर मॉडल के पूरी तरह से शुरू होने से पहले डेटा डाला जाता है या बैकग्राउंड वर्कर काम नहीं करता है, तो हो सकता है कि कुछ लाइनों में
|
7. व्यवस्थित करें
इस लैब को पूरा करने के बाद, alloyDB क्लस्टर और इंस्टेंस को मिटाना न भूलें.
इससे क्लस्टर और उसके इंस्टेंस मिट जाएंगे.
8. बधाई हो
आपने एक ऐसा खोज ऐप्लिकेशन बना लिया है जो ज़रूरत के हिसाब से नॉलेज बेस को बड़ा कर सकता है. वेक्टर एम्बेडिंग जनरेट करने के लिए, Python स्क्रिप्ट और लूप के साथ जटिल ईटीएल पाइपलाइन को मैनेज करने के बजाय, आपने AlloyDB AI का इस्तेमाल किया. इससे, एक ही एसक्यूएल कमांड का इस्तेमाल करके, डेटाबेस में एम्बेडिंग जनरेट की जा सकती हैं.
हमने क्या-क्या कवर किया
- हमने डेटा प्रोसेसिंग के लिए "Python For-Loop" को बंद कर दिया है.
- हमने एक एसक्यूएल कमांड की मदद से 50,000 वेक्टर जनरेट किए.
- हमने ट्रिगर की मदद से, आने वाले समय में वेक्टर जनरेट करने की प्रोसेस को ऑटोमेट किया है.
- हमने हाइब्रिड सर्च की.
अगले चरण
- अपने डेटासेट के साथ इसे आज़माएं.
- AlloyDB AI के दस्तावेज़ देखें.
- ज़्यादा वर्कशॉप के लिए, Code Vipassana की वेबसाइट देखें.