
1. Ringkasan
Dalam codelab ini, Anda akan membuat aplikasi penelusuran Knowledge Base yang skalabel. Daripada mengelola pipeline ETL yang kompleks dengan skrip dan loop Python untuk membuat embedding vektor, Anda akan menggunakan AlloyDB AI untuk menangani pembuatan embedding secara native dalam database menggunakan satu perintah SQL.
Yang akan Anda build
Aplikasi database pusat informasi "yang dapat ditelusuri" berperforma tinggi.
Yang akan Anda pelajari
Anda akan mempelajari cara:
- Sediakan Cluster AlloyDB dan aktifkan ekstensi AI.
- Buat data sintetis (lebih dari 50.000 baris) menggunakan SQL.
- Isi ulang embedding vektor untuk seluruh set data menggunakan Pemrosesan Batch.
- Siapkan Pemicu Inkremental Real-Time untuk menyematkan data baru secara otomatis.
- Lakukan Penelusuran Hybrid (Filter Vektor + SQL) untuk "Flexing Context".
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Aktifkan API yang diperlukan: Ikuti link dan aktifkan API.
Atau, Anda dapat menggunakan perintah gcloud untuk melakukannya. Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Masalah Umum & Pemecahan Masalah
Sindrom "Project Hantu" | Anda menjalankan |
Penghalang Penagihan | Anda telah mengaktifkan project, tetapi lupa menambahkan akun penagihan. AlloyDB adalah mesin berperforma tinggi; AlloyDB tidak akan dimulai jika "tangki bahan bakar" (penagihan) kosong. |
Keterlambatan Penyebaran API | Anda mengklik "Aktifkan API", tetapi command line masih menampilkan |
Quags Kuota | Jika menggunakan akun uji coba yang baru, Anda mungkin mencapai kuota regional untuk instance AlloyDB. Jika |
Agen Layanan"Tersembunyi" | Terkadang, Agen Layanan AlloyDB tidak otomatis diberi peran |
3. Penyiapan database
Di lab ini, kita akan menggunakan AlloyDB sebagai database untuk data pengujian. Cloud SQL menggunakan cluster untuk menyimpan semua resource, seperti database dan log. Setiap cluster memiliki instance utama yang menyediakan titik akses ke data. Tabel akan menyimpan data sebenarnya.
Mari kita buat cluster, instance, dan tabel AlloyDB tempat set data pengujian akan dimuat.
- Klik tombol atau Salin link di bawah ke browser tempat Anda login sebagai pengguna Konsol Google Cloud.
- Setelah langkah ini selesai, repo akan di-clone ke editor Cloud Shell lokal Anda dan Anda akan dapat menjalankan perintah di bawah dari folder project (penting untuk memastikan Anda berada di direktori project):
sh run.sh
- Sekarang gunakan UI (dengan mengklik link di terminal atau mengklik link "preview on web" di terminal.
- Masukkan detail Anda untuk project id, nama cluster, dan nama instance untuk memulai.
- Ambil kopi sambil melihat log yang terus bergulir dan Anda dapat membaca tentang cara kerjanya di balik layar di sini. Proses ini mungkin memerlukan waktu sekitar 10-15 menit.
Masalah Umum & Pemecahan Masalah
Masalah "Kesabaran" | Cluster database adalah infrastruktur yang berat. Jika Anda memuat ulang halaman atau menghentikan sesi Cloud Shell karena "terlihat macet", Anda mungkin akan mendapatkan instance "hantu" yang disediakan sebagian dan tidak dapat dihapus tanpa intervensi manual. |
Ketidakcocokan Region | Jika Anda mengaktifkan API di |
Cluster Zombie | Jika sebelumnya Anda menggunakan nama yang sama untuk cluster dan tidak menghapusnya, skrip mungkin akan menyatakan bahwa nama cluster sudah ada. Nama cluster harus unik dalam project. |
Waktu Tunggu Cloud Shell | Jika istirahat kopi Anda berlangsung selama 30 menit, Cloud Shell mungkin akan memasuki mode tidur dan menghentikan proses |
4. Penyediaan Skema
Pada langkah ini, kita akan membahas hal-hal berikut:
Setelah cluster dan instance AlloyDB Anda berjalan, buka editor SQL AlloyDB Studio untuk mengaktifkan ekstensi AI dan menyediakan skema.
Anda mungkin perlu menunggu hingga instance selesai dibuat. Setelah selesai, login ke AlloyDB menggunakan kredensial yang Anda buat saat membuat cluster. Gunakan data berikut untuk melakukan autentikasi ke PostgreSQL:
- Nama pengguna : "
postgres" - Database : "
postgres" - Sandi : "
alloydb" (atau apa pun yang Anda tetapkan pada saat pembuatan)
Setelah Anda berhasil diautentikasi ke AlloyDB Studio, perintah SQL dimasukkan di Editor. Anda dapat menambahkan beberapa jendela Editor menggunakan tanda plus di sebelah kanan jendela terakhir.
Anda akan memasukkan perintah untuk AlloyDB di jendela editor, menggunakan opsi Jalankan, Format, dan Hapus sesuai kebutuhan.
Mengaktifkan Ekstensi
Untuk membangun aplikasi ini, kita akan menggunakan ekstensi pgvector dan google_ml_integration. Ekstensi pgvector memungkinkan Anda menyimpan dan menelusuri embedding vektor. Ekstensi google_ml_integration menyediakan fungsi yang Anda gunakan untuk mengakses endpoint prediksi Vertex AI guna mendapatkan prediksi di SQL. Aktifkan ekstensi ini dengan menjalankan DDL berikut:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Membuat tabel
Kita memerlukan set data untuk mendemonstrasikan skala. Daripada mengimpor CSV, kita akan membuat 50.000 baris "Artikel Bantuan" sintetis secara instan menggunakan SQL.
Anda dapat membuat tabel menggunakan pernyataan DDL di bawah di AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
Kolom item_vector akan memungkinkan penyimpanan untuk nilai vektor teks.
Verifikasi data:
SELECT count(*) FROM help_articles;
-- Output: 50000
Mengaktifkan Flag Database
Buka konsol Konfigurasi instance, klik "Edit Primary", buka Konfigurasi Lanjutan, lalu klik "Tambahkan Flag Database".
Jika tidak, masukkan di drop-down tanda dan setel ke "AKTIF", lalu perbarui instance.
Jika tidak, masukkan di drop-down tanda dan setel ke "AKTIF", lalu perbarui instance.
Langkah-langkah untuk mengonfigurasi flag database:
- Di Konsol Google Cloud, buka halaman Clusters.
- Klik cluster di kolom Nama Resource.
- Di halaman Overview, buka Instances di cluster Anda, pilih instance, lalu klik Edit.
- Menambahkan, mengubah, atau menghapus flag database dari instance Anda:
Menambahkan tanda
- Untuk menambahkan flag database ke instance, klik Tambahkan flag.
- Pilih flag database dari daftar flag database baru.
- Berikan nilai untuk tanda.
- Klik Selesai.
- Klik Update instance.
- Verifikasi bahwa ekstensi google_ml_integration adalah versi 1.5.2 atau yang lebih tinggi:
Untuk memeriksa versi ekstensi Anda dengan perintah berikut:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Jika Anda perlu mengupgrade ekstensi ke yang lebih tinggi, gunakan perintah:
ALTER EXTENSION google_ml_integration UPDATE;
Berikan Izin
- Untuk mengizinkan pengguna mengelola pembuatan penyematan otomatis, berikan izin INSERT, UPDATE, dan DELETE pada tabel google_ml.embed_gen_progress dan google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
'postgres' adalah USER_NAME yang diberi izin.
- Jalankan pernyataan di bawah untuk memberikan izin eksekusi pada fungsi "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Memberikan PERAN Vertex AI User ke akun layanan AlloyDB
Dari konsol IAM Google Cloud, berikan akses akun layanan AlloyDB (yang terlihat seperti ini: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) ke peran "Pengguna Vertex AI". PROJECT_NUMBER akan memiliki nomor project Anda.
Atau, Anda dapat menjalankan perintah di bawah dari Terminal Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Masalah Umum & Pemecahan Masalah
Loop "Lupa Sandi" | Jika Anda menggunakan penyiapan "Satu Klik" dan tidak dapat mengingat sandi, buka halaman Informasi dasar instance di konsol dan klik "Edit" untuk mereset sandi |
Error "Ekstensi Tidak Ditemukan" | Jika |
5. Pembuatan Vektor "One-Shot"
Ini adalah inti dari lab. Daripada menulis loop Python untuk memproses 50.000 baris ini, kita akan menggunakan fungsi ai.initialize_embeddings.
Satu perintah ini melakukan dua hal:
- Mengisi ulang semua baris yang ada.
- Membuat Pemicu untuk menyematkan baris mendatang secara otomatis.
Jalankan pernyataan SQL di bawah dari Editor Kueri AlloyDB
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
Memverifikasi Embedding
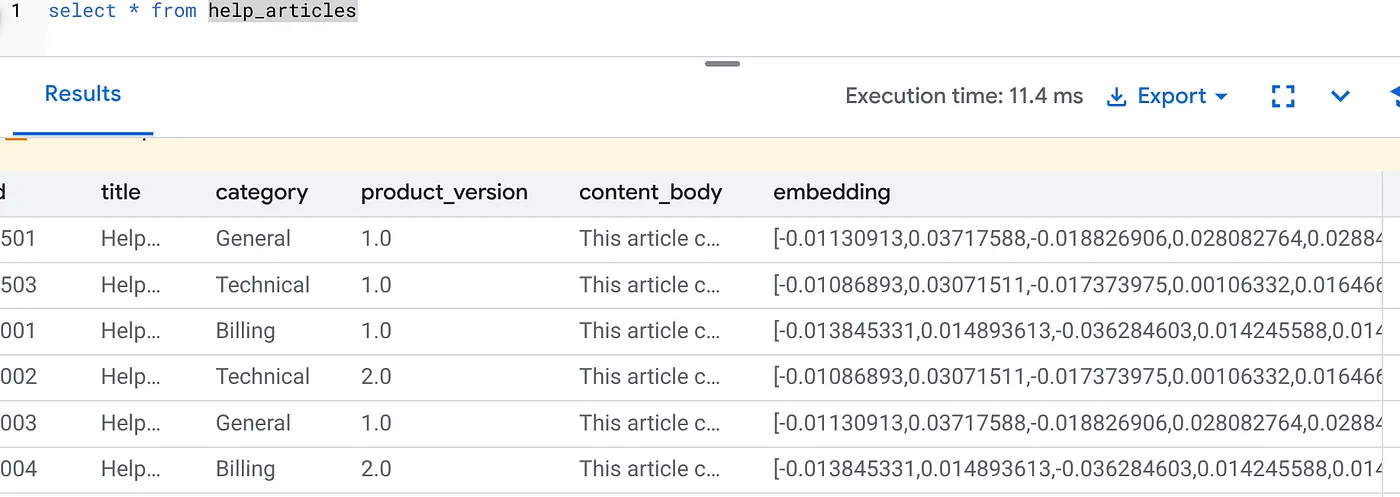
Periksa apakah kolom embedding sudah terisi:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Anda akan melihat hasil yang mirip dengan di bawah ini:
Apa yang baru saja terjadi?
- Pengisian Ulang dalam Skala Besar: Fitur ini secara otomatis memindai 50.000 baris yang ada dan membuat embedding melalui Vertex AI.
- Otomatisasi: Dengan menyetel incremental_refresh_mode => 'transactional', AlloyDB akan otomatis menyiapkan pemicu internal. Setiap baris baru yang dimasukkan ke dalam help_articles akan langsung menghasilkan sematan.
- Anda dapat secara opsional menyetel incremental_refresh_mode => ‘None' sehingga Anda hanya dapat memperoleh pernyataan untuk melakukan update massal dan memanggil ai.refresh_embeddings() secara manual untuk memperbarui semua embedding baris.
Anda baru saja mengganti antrean Kafka, pekerja Python, dan skrip migrasi dengan 6 baris SQL. Berikut adalah dokumentasi resmi mendetail untuk semua atribut.
Pengujian Pemicu Real-Time
Mari kita verifikasi bahwa otomatisasi "Zero Loop" berfungsi untuk data baru.
- Menyisipkan baris baru:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Periksa segera:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Hasil:
Anda akan melihat vektor yang dibuat secara instan tanpa menjalankan skrip eksternal apa pun.
Menyesuaikan Ukuran Batch
Saat ini, AlloyDB menetapkan ukuran batch default ke 50 secara otomatis. Meskipun setelan default berfungsi dengan baik, AlloyDB tetap memberi pengguna kontrol untuk menyesuaikan konfigurasi yang sempurna untuk model dan set data unik Anda.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Namun, pengguna harus mengetahui batas kuota yang dapat membatasi performa. Untuk meninjau kuota AlloyDB yang direkomendasikan, lihat bagian "Sebelum memulai" dalam dokumentasi.
Masalah Umum & Pemecahan Masalah
Kesenjangan Propagasi IAM | Anda menjalankan perintah IAM |
Ketidakcocokan Dimensi Vektor | Tabel |
6. Penelusuran Konteks yang Fleksibel
Sekarang kita melakukan Penelusuran Campuran. Kita menggabungkan pemahaman semantik (Vektor) dengan logika bisnis (Filter SQL).
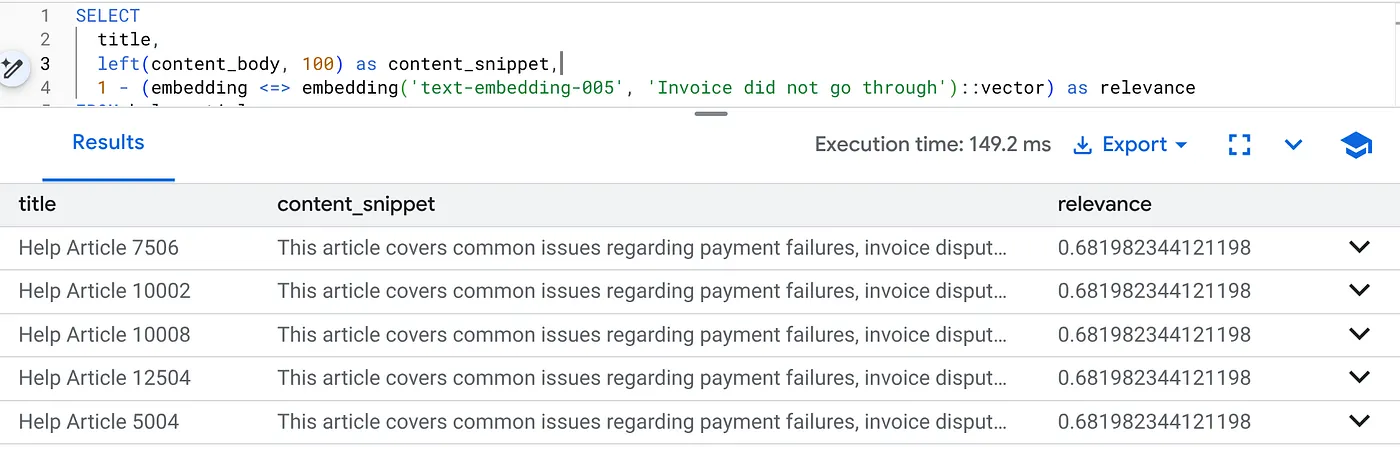
Jalankan kueri ini untuk menemukan masalah penagihan khusus untuk Versi Produk 2.0:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Ini adalah Flexing Context. Penelusuran "menyesuaikan" untuk memahami maksud pengguna ("masalah penagihan") sekaligus mematuhi batasan bisnis yang ketat (Versi 2.0).
Alasan mengapa cara ini lebih unggul untuk Startup & Migrasi
- Utang Infrastruktur Nol: Anda tidak menjalankan DB Vektor terpisah (Pinecone/Milvus). Anda tidak menulis tugas ETL terpisah. Semuanya ada di Postgres.
- Pembaruan Real-Time: Dengan menggunakan mode 'transaksional', indeks penelusuran Anda tidak pernah usang. Saat data di-commit, data tersebut siap vektor.
- Skala: AlloyDB dibangun di infrastruktur Google. Alat ini dapat menangani pembuatan massal jutaan vektor lebih cepat daripada skrip Python Anda.
Masalah Umum & Pemecahan Masalah
Gotcha Performa Produksi | Masalah: Cepat untuk 50.000 baris. Sangat lambat untuk 1 juta baris jika filter kategori tidak cukup selektif.Solusi:Tambahkan Indeks Vektor: Untuk skala produksi, Anda harus membuat indeks:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);Verifikasi Penggunaan Indeks: Jalankan |
Bencana "Ketidakcocokan Model" | Masalah: Anda melakukan inisialisasi kolom menggunakan text-embedding-005 dalam prosedur CALL. Jika Anda secara tidak sengaja menggunakan model yang berbeda (misalnya, text-embedding-004 atau model OSS) dalam penyematan fungsi kueri SELECT embedding('model-name', ...), dimensi mungkin cocok (768), tetapi ruang vektor akan sangat berbeda. Kueri berjalan tanpa error, tetapi hasilnya sama sekali tidak relevan (skor relevansi sampah). Pemecahan masalah:Pastikan model_id di ai.initialize_embeddings sama persis dengan model_id dalam kueri SELECT Anda. |
Hasil "Kosong Senyap" (Pemfilteran Berlebihan) | Masalah: Penelusuran campuran adalah operasi "AND". Fitur ini memerlukan Pencocokan Semantik DAN Pencocokan SQL.Jika pengguna menelusuri "Bantuan penagihan", tetapi kolom
|
4. Error Izin/Kuota (Error 500) | Masalah:Fungsi
|
5. Embedding Null | Masalah:Jika Anda memasukkan data sebelum model diinisialisasi sepenuhnya atau jika pekerja latar belakang gagal, beberapa baris mungkin memiliki
|
7. Pembersihan
Setelah lab ini selesai, jangan lupa untuk menghapus cluster dan instance AlloyDB.
Tindakan ini akan membersihkan cluster beserta instance-nya.
8. Selamat
Anda telah berhasil membuat aplikasi penelusuran Knowledge Base yang skalabel. Alih-alih mengelola pipeline ETL yang kompleks dengan skrip dan loop Python untuk membuat embedding vektor, Anda menggunakan AlloyDB AI untuk menangani pembuatan embedding secara native dalam database menggunakan satu perintah SQL.
Yang kita bahas
- Kita telah menghentikan "Python For-Loop" untuk pemrosesan data.
- Kita membuat 50.000 vektor dengan satu perintah SQL.
- Kami mengotomatiskan pembuatan vektor di masa mendatang dengan pemicu.
- Kami melakukan Penelusuran Campuran.
Langkah Berikutnya
- Coba lakukan ini dengan set data Anda sendiri.
- Pelajari Dokumentasi AI AlloyDB.
- Lihat situs Code Vipassana untuk mengetahui workshop lainnya.