
1. Panoramica
In questo codelab creerai un'applicazione di ricerca nella knowledge base scalabile. Anziché gestire una complessa pipeline ETL con script e cicli Python per generare incorporamenti vettoriali, utilizzerai AlloyDB AI per gestire la generazione di incorporamenti in modo nativo all'interno del database utilizzando un singolo comando SQL.
Cosa creerai
Un'applicazione di database della knowledge base "consultabile" ad alte prestazioni.
Obiettivi didattici
Imparerai come:
- Esegui il provisioning di un cluster AlloyDB e abilita le estensioni AI.
- Genera dati sintetici (più di 50.000 righe) utilizzando SQL.
- Esegui il backfill degli embedding vettoriali per l'intero set di dati utilizzando l'elaborazione batch.
- Configura i trigger incrementali in tempo reale per incorporare automaticamente i nuovi dati.
- Esegui la ricerca ibrida (vettoriale + filtri SQL) per "Flexing Context".
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: segui il link e abilita le API.
In alternativa, puoi utilizzare il comando gcloud. Consulta la documentazione per i comandi e l'utilizzo di gcloud.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Aspetti da considerare e risoluzione dei problemi
La sindrome del "progetto fantasma" | Hai eseguito |
La barriera di fatturazione | Hai attivato il progetto, ma hai dimenticato l'account di fatturazione. AlloyDB è un motore ad alte prestazioni; non si avvia se il "serbatoio" (fatturazione) è vuoto. |
Ritardo di propagazione dell'API | Hai fatto clic su "Abilita API", ma la riga di comando indica ancora |
Quota Quags | Se utilizzi un account di prova nuovo di zecca, potresti raggiungere una quota regionale per le istanze AlloyDB. Se |
Service Agent"Nascosto" | A volte al service agent AlloyDB non viene concesso automaticamente il ruolo |
3. Configurazione del database
In questo lab utilizzeremo AlloyDB come database per i dati di test. Utilizza i cluster per contenere tutte le risorse, come database e log. Ogni cluster ha un'istanza primaria che fornisce un punto di accesso ai dati. Le tabelle conterranno i dati effettivi.
Creiamo un cluster, un'istanza e una tabella AlloyDB in cui verrà caricato il set di dati di test.
- Fai clic sul pulsante o copia il link riportato di seguito nel browser in cui hai eseguito l'accesso all'utente della console Google Cloud.
- Una volta completato questo passaggio, il repository verrà clonato nell'editor Cloud Shell locale e potrai eseguire il comando riportato di seguito dalla cartella del progetto (è importante assicurarsi di essere nella directory del progetto):
sh run.sh
- Ora utilizza la UI (facendo clic sul link nel terminale o sul link "Anteprima sul web" nel terminale).
- Inserisci i dettagli per l'ID progetto, il cluster e i nomi delle istanze per iniziare.
- Prendi un caffè mentre scorrono i log e leggi qui come funziona dietro le quinte. L'operazione potrebbe richiedere circa 10-15 minuti.
Aspetti da considerare e risoluzione dei problemi
Il problema della "pazienza" | I cluster di database sono un'infrastruttura pesante. Se aggiorni la pagina o termini la sessione Cloud Shell perché "sembra bloccata", potresti ritrovarti con un'istanza "fantasma" di cui è stato eseguito il provisioning parziale e impossibile da eliminare senza un intervento manuale. |
Regione non corrispondente | Se hai abilitato le API in |
Cluster di zombie | Se in precedenza hai utilizzato lo stesso nome per un cluster e non lo hai eliminato, lo script potrebbe indicare che il nome del cluster esiste già. I nomi dei cluster devono essere univoci all'interno di un progetto. |
Timeout di Cloud Shell | Se la pausa caffè dura 30 minuti, Cloud Shell potrebbe entrare in modalità sospensione e disconnettere il processo |
4. Provisioning dello schema
In questo passaggio, tratteremo i seguenti argomenti:
Una volta che il cluster e l'istanza AlloyDB sono in esecuzione, vai all'editor SQL di AlloyDB Studio per attivare le estensioni AI e eseguire il provisioning dello schema.
Potrebbe essere necessario attendere il completamento della creazione dell'istanza. Una volta creato, accedi ad AlloyDB utilizzando le credenziali che hai creato quando hai creato il cluster. Utilizza i seguenti dati per l'autenticazione a PostgreSQL:
- Nome utente : "
postgres" - Database : "
postgres" - Password : "
alloydb" (o quella che hai impostato al momento della creazione)
Una volta eseguita l'autenticazione in AlloyDB Studio, i comandi SQL vengono inseriti nell'editor. Puoi aggiungere più finestre dell'editor utilizzando il segno più a destra dell'ultima finestra.
Inserirai i comandi per AlloyDB nelle finestre dell'editor, utilizzando le opzioni Esegui, Formatta e Cancella in base alle esigenze.
Attiva le estensioni
Per creare questa app, utilizzeremo le estensioni pgvector e google_ml_integration. L'estensione pgvector consente di archiviare e cercare vector embedding. L'estensione google_ml_integration fornisce funzioni che utilizzi per accedere agli endpoint di previsione di Vertex AI per ottenere previsioni in SQL. Abilita queste estensioni eseguendo i seguenti DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Creare una tabella
Abbiamo bisogno di un set di dati per dimostrare la scalabilità. Anziché importare un file CSV, genereremo istantaneamente 50.000 righe di "Articoli della Guida" sintetici utilizzando SQL.
Puoi creare una tabella utilizzando l'istruzione DDL riportata di seguito in AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
La colonna item_vector consentirà l'archiviazione dei valori vettoriali del testo.
Verifica i dati:
SELECT count(*) FROM help_articles;
-- Output: 50000
Abilita i flag di database
Vai alla console di configurazione dell'istanza, fai clic su "Modifica primaria", vai a Configurazione avanzata e fai clic su "Aggiungi flag di database".
In caso contrario, inseriscilo nel menu a discesa dei flag, impostalo su "ON" e aggiorna l'istanza.
In caso contrario, inseriscilo nel menu a discesa dei flag, impostalo su "ON" e aggiorna l'istanza.
Passaggi per configurare i flag di database:
- Nella console Google Cloud, vai alla pagina Cluster.
- Fai clic su un cluster nella colonna Nome risorsa.
- Nella pagina Panoramica, vai a Istanze nel cluster, seleziona un'istanza e poi fai clic su Modifica.
- Aggiungi, modifica o elimina un flag di database dall'istanza:
Aggiungere un flag
- Per aggiungere un flag di database all'istanza, fai clic su Aggiungi flag.
- Seleziona un flag di database dall'elenco Nuovo flag di database.
- Specifica un valore per il flag.
- Fai clic su Fine.
- Fai clic su Aggiorna istanza.
- Verifica che l'estensione google_ml_integration sia la versione 1.5.2 o successive:
Per controllare la versione dell'estensione, esegui questo comando:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Se devi aggiornare l'estensione a un valore superiore, utilizza il comando:
ALTER EXTENSION google_ml_integration UPDATE;
Concedi autorizzazione
- Per consentire a un utente di gestire la generazione dell'incorporamento automatico, concedi le autorizzazioni INSERT, UPDATE e DELETE sulle tabelle google_ml.embed_gen_progress e google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
"postgres" è USER_NAME per cui vengono concesse le autorizzazioni.
- Esegui l'istruzione riportata di seguito per concedere l'esecuzione della funzione "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Concedi il ruolo Utente Vertex AI al service account AlloyDB
Dalla console Google Cloud IAM, concedi al service account AlloyDB (simile a service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accesso al ruolo "Utente Vertex AI". PROJECT_NUMBER conterrà il numero del tuo progetto.
In alternativa, puoi eseguire il comando riportato di seguito dal terminale Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Aspetti da considerare e risoluzione dei problemi
Il ciclo "Amnesia della password" | Se hai utilizzato la configurazione "One Click" e non ricordi la password, vai alla pagina delle informazioni di base dell'istanza nella console e fai clic su "Modifica" per reimpostare la password di |
Errore "Estensione non trovata" | Se |
5. Generazione di vettori "one-shot"
Questo è il fulcro del lab. Invece di scrivere un ciclo Python per elaborare queste 50.000 righe, utilizzeremo la funzione ai.initialize_embeddings.
Questo singolo comando esegue due operazioni:
- Backfill di tutte le righe esistenti.
- Crea un trigger per incorporare automaticamente le righe future.
Esegui la seguente istruzione SQL dall'editor di query AlloyDB
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
Verificare gli incorporamenti
Controlla che la colonna embedding sia ora compilata:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Dovresti vedere un risultato simile al seguente:
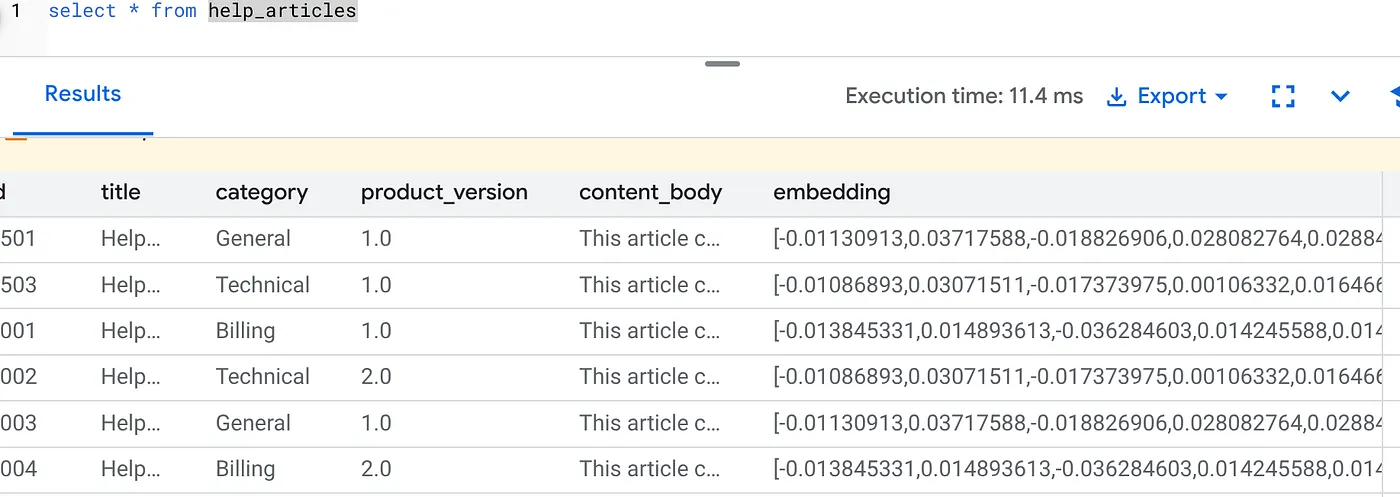
Che cosa è successo?
- Riempiimento su vasta scala:esamina automaticamente le 50.000 righe esistenti e genera gli embedding tramite Vertex AI.
- Automazione:impostando incremental_refresh_mode => 'transactional', AlloyDB configura automaticamente i trigger interni. L'incorporamento di qualsiasi nuova riga inserita in help_articles verrà generato immediatamente.
- Se vuoi, puoi impostare incremental_refresh_mode => "None" in modo da ottenere solo l'estratto per eseguire aggiornamenti collettivi e chiamare manualmente ai.refresh_embeddings() per aggiornare gli incorporamenti di tutte le righe.
Hai appena sostituito una coda Kafka, un worker Python e uno script di migrazione con 6 righe di SQL. Ecco la documentazione ufficiale dettagliata per tutti gli attributi.
Test dell'attivatore in tempo reale
Verifichiamo che l'automazione "Zero Loop" funzioni per i nuovi dati.
- Inserire una nuova riga:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Controlla immediatamente:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Risultato:
Dovresti vedere il vettore generato istantaneamente senza eseguire script esterni.
Ottimizzazione della dimensione del batch
Al momento, AlloyDB imposta la dimensione del batch su 50 per impostazione predefinita. Sebbene le impostazioni predefinite funzionino perfettamente, AlloyDB consente comunque agli utenti di perfezionare la configurazione ideale per il modello e il set di dati unici.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Tuttavia, gli utenti devono essere a conoscenza dei limiti di quota che possono limitare il rendimento. Per esaminare le quote AlloyDB consigliate, consulta la sezione "Prima di iniziare" nella documentazione.
Aspetti da considerare e risoluzione dei problemi
Il divario di propagazione IAM | Hai eseguito il comando IAM |
Mancata corrispondenza delle dimensioni del vettore | La tabella |
6. Ricerca contestuale flessibile
Ora eseguiamo una ricerca ibrida. Combiniamo la comprensione semantica (vettore) con la logica di business (filtri SQL).
Esegui questa query per trovare problemi di fatturazione specifici per la versione 2.0 del prodotto:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Questo è il contesto di flessione. La ricerca "si adatta" per comprendere l'intento dell'utente ("problemi di fatturazione") rispettando i rigidi vincoli aziendali (versione 2.0).
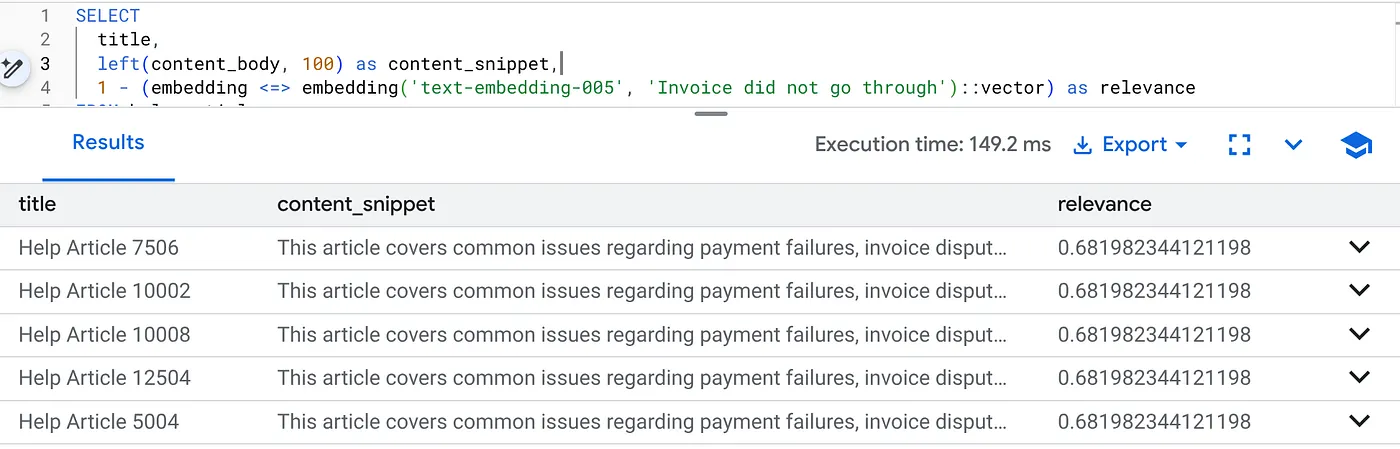
Perché questa soluzione è ideale per le startup e le migrazioni
- Nessun debito di infrastruttura: non hai creato un database vettoriale separato (Pinecone/Milvus). Non hai scritto un job ETL separato. È tutto in Postgres.
- Aggiornamenti in tempo reale: utilizzando la modalità "transazionale", l'indice di ricerca non è mai obsoleto. Nel momento in cui i dati vengono salvati, sono pronti per essere utilizzati con i vettori.
- Scalabilità: AlloyDB è basato sull'infrastruttura di Google. Può gestire la generazione collettiva di milioni di vettori più velocemente di quanto possa fare il tuo script Python.
Aspetti da considerare e risoluzione dei problemi
Gotcha sul rendimento della produzione | Problema: veloce per 50.000 righe. Molto lento per 1 milione di righe se il filtro per categoria non è sufficientemente selettivo.Soluzione:aggiungi un indice vettoriale: per la scalabilità della produzione, devi creare un indice:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);Verifica l'utilizzo dell'indice:esegui |
Il disastro del "Modello non corrispondente" | Problema: hai inizializzato la colonna utilizzando text-embedding-005 nella procedura CALL. Se utilizzi accidentalmente un modello diverso (ad esempio text-embedding-004 o un modello OSS) nell'incorporamento della funzione di query SELECT embedding('model-name', ...), le dimensioni potrebbero corrispondere (768), ma lo spazio vettoriale sarà completamente diverso. La query viene eseguita senza errori, ma i risultati sono completamente irrilevanti (punteggi di pertinenza spazzatura). Risoluzione dei problemi:assicurati che model_id in ai.initialize_embeddings corrisponda esattamente a model_id nella query SELECT. |
Il risultato "Silent Empty" (filtraggio eccessivo) | Problema: la ricerca ibrida è un'operazione "AND". Richiede la corrispondenza semantica E la corrispondenza SQL.Se un utente cerca "Assistenza per la fatturazione", ma la colonna
|
4. Errori di autorizzazione/quota (errore 500) | Problema:la funzione
|
5. Incorporamenti nulli | Problema:se inserisci i dati prima che il modello sia completamente inizializzato o se il worker in background non funziona, alcune righe potrebbero contenere
|
7. Esegui la pulizia
Una volta completato questo lab, non dimenticare di eliminare il cluster e l'istanza AlloyDB.
Dovrebbe liberare spazio nel cluster insieme alle relative istanze.
8. Complimenti
Hai creato un'applicazione di ricerca nella knowledge base scalabile. Anziché gestire una complessa pipeline ETL con script e cicli Python per generare incorporamenti vettoriali, hai utilizzato AlloyDB AI per gestire la generazione di incorporamenti in modo nativo all'interno del database utilizzando un singolo comando SQL.
Argomenti trattati
- Abbiamo eliminato il "ciclo for di Python" per l'elaborazione dei dati.
- Abbiamo generato 50.000 vettori con un comando SQL.
- Abbiamo automatizzato la generazione di vettori futuri con i trigger.
- Abbiamo eseguito la ricerca ibrida.
Passaggi successivi
- Prova con il tuo set di dati.
- Esplora la documentazione di AlloyDB AI.
- Visita il sito web di Code Vipassana per altri workshop.