
1. 概要
この Codelab では、スケーラブルなナレッジベース検索アプリケーションを構築します。Python スクリプトとループを使用して複雑な ETL パイプラインを管理し、ベクトル エンベディングを生成する代わりに、AlloyDB AI を使用して、単一の SQL コマンドを使用してデータベース内でエンベディング生成をネイティブに処理します。
作成するアプリの概要
高パフォーマンスの「検索可能」なナレッジベース データベース アプリケーション。
学習内容
ここでは以下について学びます。
- AlloyDB クラスタをプロビジョニングし、AI 拡張機能を有効にします。
- SQL を使用して合成データ(50,000 行以上)を生成します。
- バッチ処理を使用して、データセット全体のベクトル エンベディングをバックフィルします。
- リアルタイムの増分トリガーを設定して、新しいデータを自動的に埋め込みます。
- 「Flexing Context」のハイブリッド検索(ベクトル + SQL フィルタ)を実行します。
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/embeddings-at-scale-with-alloydb/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にする: リンクにアクセスして、API を有効にします。
または、この操作に gcloud コマンドを使用することもできます。gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
注意点とトラブルシューティング
「ゴースト プロジェクト」症候群 |
|
請求のバリケード | プロジェクトを有効にしたが、請求先アカウントを忘れた。AlloyDB は高性能エンジンです。ガソリン タンク(課金)が空の場合、起動しません。 |
API 伝播の遅延 | [API を有効にする] をクリックしたのに、コマンドラインに |
割り当て Quags | 新しいトライアル アカウントを使用している場合は、AlloyDB インスタンスのリージョン割り当てに達する可能性があります。 |
「非表示」のサービス エージェント | AlloyDB サービス エージェントに |
3. データベースの設定
このラボでは、テストデータのデータベースとして AlloyDB を使用します。クラスタを使用して、データベースやログなどのすべてのリソースを保持します。各クラスタには、データへのアクセス ポイントを提供するプライマリ インスタンスがあります。テーブルには実際のデータが格納されます。
テスト データセットを読み込む AlloyDB クラスタ、インスタンス、テーブルを作成しましょう。
- ボタンをクリックするか、以下のリンクを Google Cloud コンソールのユーザーがログインしているブラウザにコピーします。
- この手順が完了すると、リポジトリがローカルの Cloud Shell エディタにクローンされ、プロジェクト フォルダから次のコマンドを実行できるようになります(プロジェクト ディレクトリにいることを確認することが重要です)。
sh run.sh
- UI を使用します(ターミナルのリンクをクリックするか、ターミナルの [ウェブでプレビュー] リンクをクリックします)。
- プロジェクト ID、クラスタ名、インスタンス名の詳細を入力して、開始します。
- ログがスクロールしている間にコーヒーを飲んで休憩しましょう。この処理がバックグラウンドでどのように行われているかについては、こちらをご覧ください。10 ~ 15 分ほどかかることがあります。
注意点とトラブルシューティング
「忍耐」の問題 | データベース クラスタは重いインフラストラクチャです。ページを更新したり、「フリーズした」ように見える Cloud Shell セッションを強制終了したりすると、部分的にプロビジョニングされた「ゴースト」インスタンスが作成され、手動で介入しないと削除できなくなる可能性があります。 |
リージョンが一致しない |
|
ゾンビ クラスタ | 以前にクラスタに同じ名前を使用し、削除していない場合、スクリプトでクラスタ名がすでに存在すると表示されることがあります。クラスタ名はプロジェクト内で一意にする必要があります。 |
Cloud Shell のタイムアウト | コーヒーブレイクに 30 分かかると、Cloud Shell がスリープ状態になり、 |
4. スキーマのプロビジョニング
このステップでは、次の内容について説明します。
AlloyDB クラスタとインスタンスが実行されたら、AlloyDB Studio SQL エディタに移動して AI 拡張機能を有効にし、スキーマをプロビジョニングします。
インスタンスの作成が完了するまで待つ必要がある場合があります。準備ができたら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。PostgreSQL の認証には次のデータを使用します。
- ユーザー名: 「
postgres」 - データベース: 「
postgres」 - パスワード: 「
alloydb」(または作成時に設定したパスワード)
AlloyDB Studio への認証が成功すると、エディタに SQL コマンドが入力されます。最後のウィンドウの右にあるプラス記号を使用して、複数のエディタ ウィンドウを追加できます。
必要に応じて [実行]、[形式]、[クリア] オプションを使用して、エディタ ウィンドウに AlloyDB のコマンドを入力します。
拡張機能を有効にする
このアプリのビルドには、拡張機能 pgvector と google_ml_integration を使用します。pgvector 拡張機能を使用すると、ベクトル エンベディングを保存して検索できます。google_ml_integration 拡張機能は、Vertex AI 予測エンドポイントにアクセスして SQL で予測を取得するために使用する関数を提供します。次の DDL を実行して、これらの拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
テーブルを作成する
スケーリングを実証するには、データセットが必要です。CSV をインポートする代わりに、SQL を使用して 50,000 行の合成「ヘルプ記事」を即座に生成します。
AlloyDB Studio で次の DDL ステートメントを使用してテーブルを作成できます。
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
item_vector 列には、テキストのベクトル値を格納できます。
データを確認します。
SELECT count(*) FROM help_articles;
-- Output: 50000
データベース フラグを有効にする
インスタンス構成コンソールに移動し、[プライマリを編集] をクリックして、[高度な構成] に移動し、[データベース フラグを追加] をクリックします。
表示されていない場合は、フラグのプルダウンに入力して [オン] に設定し、インスタンスを更新します。
表示されていない場合は、フラグのプルダウンに入力して [オン] に設定し、インスタンスを更新します。
データベース フラグを構成する手順:
- Google Cloud コンソールで、[クラスタ] ページに移動します。
- [リソース名] 列でクラスタをクリックします。
- [概要] ページで、クラスタ内の [インスタンス] に移動し、インスタンスを選択して [編集] をクリックします。
- インスタンスに対してデータベース フラグの追加、変更、または削除を行います。
フラグを追加する
- インスタンスにデータベース フラグを追加するには、[フラグを追加] をクリックします。
- [新しいデータベース フラグ] リストからフラグを選択します。
- フラグの値を指定します。
- [完了] をクリックします。
- [インスタンスを更新] をクリックします。
- google_ml_integration 拡張機能のバージョンが 1.5.2 以降であることを確認します。
拡張機能のバージョンを確認するには、次のコマンドを使用します。
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
拡張機能を上位に更新する必要がある場合は、次のコマンドを使用します。
ALTER EXTENSION google_ml_integration UPDATE;
権限を付与
- ユーザーが自動エンベディング生成を管理できるようにするには、google_ml.embed_gen_progress テーブルと google_ml.embed_gen_settings テーブルに対する INSERT、UPDATE、DELETE の各権限を付与します。
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
「postgres」は、権限が付与される USER_NAME です。
- 次のステートメントを実行して、「embedding」関数に対する実行権限を付与します。
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB サービス アカウントに Vertex AI ユーザーロールを付与する
Google Cloud IAM コンソールで、AlloyDB サービス アカウント(service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com のような形式)に「Vertex AI ユーザー」ロールへのアクセス権を付与します。PROJECT_NUMBER にはプロジェクト番号が設定されます。
または、Cloud Shell ターミナルから次のコマンドを実行することもできます。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
注意点とトラブルシューティング
「パスワード忘れ」ループ | 「ワンクリック」設定を使用していて、パスワードを忘れた場合は、コンソールのインスタンスの基本情報ページに移動し、[編集] をクリックして |
「拡張機能が見つかりません」というエラー |
|
5. 「ワンショット」ベクトル生成
これがラボの核心です。これらの 50,000 行を処理する Python ループを記述する代わりに、ai.initialize_embeddings 関数を使用します。
この単一のコマンドは、次の 2 つの処理を行います。
- 既存のすべての行をバックフィルします。
- トリガーを作成して、今後の行を自動的に埋め込みます。
AlloyDB クエリエディタから次の SQL ステートメントを実行します。
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
エンベディングを確認する
embedding 列にデータが入力されていることを確認します。
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
次のような結果が表示されます。
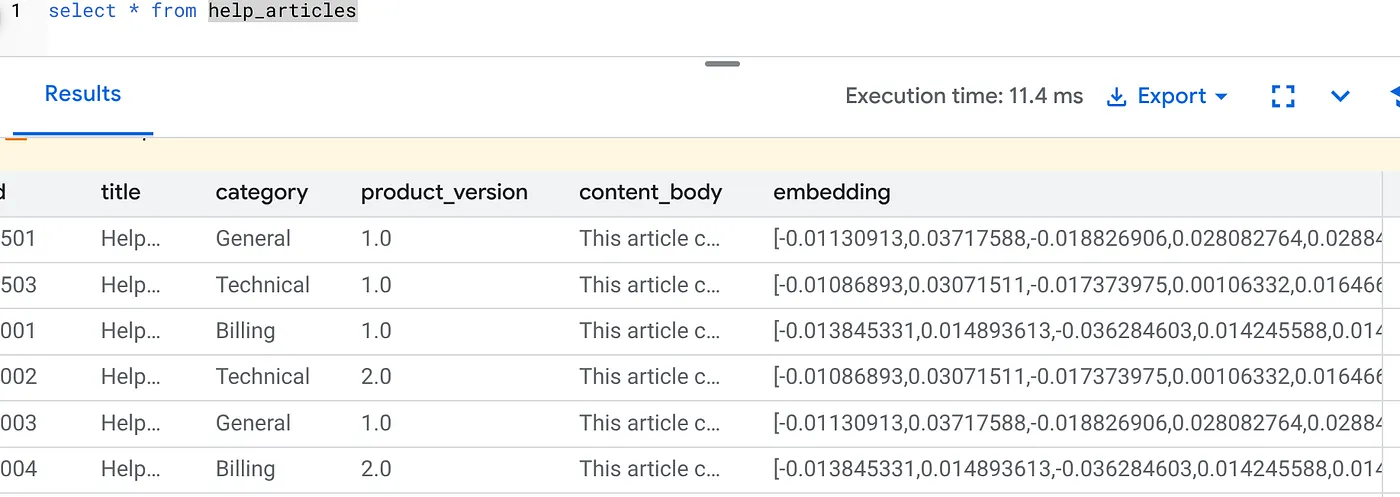
何が起こったのか
- 大規模なバックフィル: 既存の 50,000 行を自動的にスキャンし、Vertex AI を介してエンベディングを生成します。
- 自動化: incremental_refresh_mode => 'transactional' を設定すると、AlloyDB は内部トリガーを自動的に設定します。help_articles に挿入された新しい行は、すぐにエンベディングが生成されます。
- 必要に応じて、incremental_refresh_mode => ‘None' を設定して、一括更新を行うステートメントのみを取得し、すべての行のエンベディングを更新するために ai.refresh_embeddings() を手動で呼び出すことができます。
Kafka キュー、Python ワーカー、移行スクリプトを 6 行の SQL に置き換えました。すべての属性の詳細な公式ドキュメントをご覧ください。
リアルタイム トリガー テスト
「Zero Loop」自動化が新しいデータで機能することを確認しましょう。
- 新しい行を挿入する:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- すぐに確認する:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
結果:
外部スクリプトを実行しなくても、ベクトルがすぐに生成されます。
バッチサイズのチューニング
現在、AlloyDB はデフォルトでバッチサイズを 50 に設定しています。デフォルトはすぐに使用できますが、AlloyDB では、ユーザーが独自のモデルとデータセットに最適な構成を調整することもできます。
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
ただし、パフォーマンスを制限する可能性のある割り当て上限に注意する必要があります。推奨される AlloyDB 割り当てを確認するには、ドキュメントの「始める前に」セクションをご覧ください。
注意点とトラブルシューティング
IAM 伝播のギャップ |
|
ベクトル ディメンションの不一致 |
|
6. コンテキスト検索の柔軟性
次に、ハイブリッド検索を実行します。セマンティック理解(ベクトル)とビジネス ロジック(SQL フィルタ)を組み合わせます。
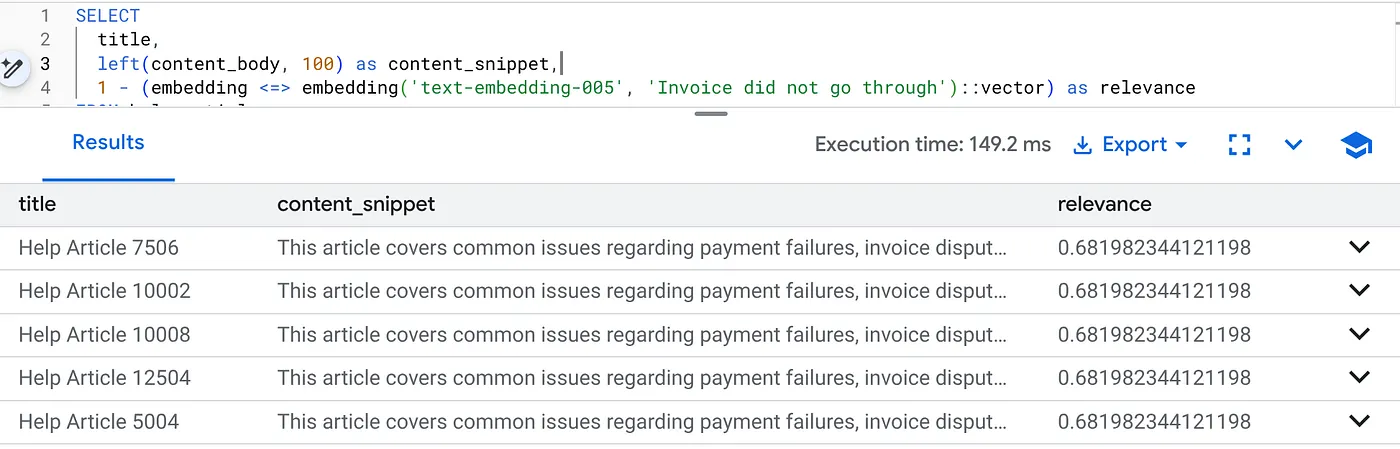
次のクエリを実行して、プロダクト バージョン 2.0 固有の請求に関する問題を見つけます。
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
これが Flexing Context です。検索は、厳格なビジネス制約(バージョン 2.0)を尊重しながら、ユーザーの意図(「請求に関する問題」)を理解するように「柔軟に対応」します。
スタートアップと移行に最適な理由
- インフラストラクチャの負債ゼロ: 別のベクトル DB(Pinecone/Milvus)をスピンアップしていません。別の ETL ジョブを作成していない。すべて Postgres にあります。
- リアルタイム更新: 「トランザクション」モードを使用すると、検索インデックスが古くなることはありません。データがコミットされると、すぐにベクトル化できます。
- スケーラビリティ: AlloyDB は Google のインフラストラクチャ上に構築されています。数百万のベクトルの一括生成を、Python スクリプトよりも高速に処理できます。
注意点とトラブルシューティング
本番環境のパフォーマンスに関する問題 | 問題: 50,000 行の処理が高速。カテゴリ フィルタが十分に選択的でない場合、100 万行の処理に非常に時間がかかる。解決策: ベクトル インデックスを追加する。本番環境の規模では、インデックスを作成する必要があります。CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);インデックスの使用状況を確認する。 |
「モデルの不一致」という障害 | 問題: CALL プロシージャで text-embedding-005 を使用して列を初期化しました。SELECT クエリ関数 embedding('model-name', ...) で別のモデル(text-embedding-004 や OSS モデルなど)を誤って使用すると、ディメンションは一致する(768)可能性がありますが、ベクトル空間はまったく異なります。クエリはエラーなしで実行されますが、結果はまったく無関係になります(関連性のスコアが低い)。トラブルシューティング:ai.initialize_embeddings の model_id が SELECT クエリの model_id と完全に一致していることを確認します。 |
「Silent Empty」の結果(フィルタリングのしすぎ) | 問題: ハイブリッド検索は「AND」演算です。セマンティック一致と SQL 一致が必要です。ユーザーが「Billing help」を検索しても、
|
4. 権限/割り当てエラー(500 エラー) | 問題:
|
5. Null エンベディング | 問題:モデルが完全に初期化される前にデータを挿入した場合、またはバックグラウンド ワーカーが失敗した場合、一部の行の
|
7. クリーンアップ
このラボが完了したら、alloyDB クラスタとインスタンスを削除することを忘れないでください。
クラスタとそのインスタンスをクリーンアップする必要があります。
8. 完了
スケーラブルなナレッジベース検索アプリケーションを正常に構築しました。Python スクリプトとループを使用して複雑な ETL パイプラインを管理し、ベクトル エンベディングを生成する代わりに、AlloyDB AI を使用して、単一の SQL コマンドを使用してデータベース内でエンベディング生成をネイティブに処理しました。
学習した内容
- データ処理用の「Python For-Loop」を削除しました。
- 1 つの SQL コマンドで 50,000 個のベクトルを生成しました。
- トリガーを使用して、今後のベクトルの生成を自動化しました。
- ハイブリッド検索を実施しました。
次のステップ
- ご自身のデータセットで試してみてください。
- AlloyDB AI のドキュメントをご覧ください。
- 他のワークショップについては、Code Vipassana のウェブサイトをご覧ください。