
1. 개요
이 Codelab에서는 확장 가능한 기술 자료 검색 애플리케이션을 빌드합니다. 벡터 임베딩을 생성하기 위해 Python 스크립트와 루프를 사용하여 복잡한 ETL 파이프라인을 관리하는 대신 AlloyDB AI를 사용하여 단일 SQL 명령어를 통해 데이터베이스 내에서 기본적으로 임베딩 생성을 처리합니다.
빌드할 항목
고성능 '검색 가능한' 기술 자료 데이터베이스 애플리케이션
학습할 내용
다음을 수행하는 방법을 배우게 됩니다.
- AlloyDB 클러스터를 프로비저닝하고 AI 확장 프로그램을 사용 설정합니다.
- SQL을 사용하여 합성 데이터 (50,000개 이상의 행)를 생성합니다.
- 일괄 처리를 사용하여 전체 데이터 세트의 벡터 임베딩을 채웁니다.
- 실시간 증분 트리거를 설정하여 새 데이터를 자동 삽입합니다.
- '컨텍스트 유연성'에 대해 하이브리드 검색 (벡터 + SQL 필터)을 실행합니다.
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API 사용 설정: 링크를 따라 API를 사용 설정합니다.
또는 gcloud 명령어를 사용할 수 있습니다. gcloud 명령어 및 사용법은 문서를 참조하세요.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
주의사항 및 문제 해결
'유령 프로젝트' 증후군 |
|
결제 바리케이드 | 프로젝트를 사용 설정했지만 결제 계정을 잊었습니다. AlloyDB는 고성능 엔진이므로 '연료 탱크' (결제)가 비어 있으면 시작되지 않습니다. |
API 전파 지연 | 'API 사용 설정'을 클릭했지만 명령줄에 여전히 |
할당량 Quags | 새 체험판 계정을 사용하는 경우 AlloyDB 인스턴스의 리전별 할당량에 도달할 수 있습니다. |
'숨겨진' 서비스 에이전트 | AlloyDB 서비스 에이전트에는 |
3. 데이터베이스 설정
이 실습에서는 AlloyDB를 테스트 데이터의 데이터베이스로 사용합니다. 클러스터를 사용하여 데이터베이스, 로그와 같은 모든 리소스를 보유합니다. 각 클러스터에는 데이터에 대한 액세스 포인트를 제공하는 기본 인스턴스가 있습니다. 테이블에는 실제 데이터가 저장됩니다.
테스트 데이터 세트가 로드될 AlloyDB 클러스터, 인스턴스, 테이블을 만들어 보겠습니다.
- 아래 버튼을 클릭하거나 Google Cloud 콘솔 사용자가 로그인한 브라우저에 링크를 복사합니다.
- 이 단계를 완료하면 저장소가 로컬 Cloud Shell 편집기에 클론되고 프로젝트 폴더에서 아래 명령어를 실행할 수 있습니다 (프로젝트 디렉터리에 있는지 확인하는 것이 중요함).
sh run.sh
- 이제 UI를 사용하여 터미널에서 링크를 클릭하거나 터미널에서 '웹에서 미리보기' 링크를 클릭합니다.
- 시작하려면 프로젝트 ID, 클러스터, 인스턴스 이름을 입력하세요.
- 로그가 스크롤되는 동안 커피를 마시세요. 여기에서 백그라운드에서 이 작업이 어떻게 이루어지는지 확인할 수 있습니다. 10~15분 정도 걸릴 수 있습니다.
주의사항 및 문제 해결
'인내심' 문제 | 데이터베이스 클러스터는 무거운 인프라입니다. 페이지를 새로고침하거나 '멈춘 것 같아' Cloud Shell 세션을 종료하면 부분적으로 프로비저닝되어 수동 개입 없이는 삭제할 수 없는 '고스트' 인스턴스가 생성될 수 있습니다. |
리전 불일치 |
|
좀비 클러스터 | 이전에 클러스터에 동일한 이름을 사용했고 삭제하지 않은 경우 스크립트에서 클러스터 이름이 이미 있다고 표시할 수 있습니다. 클러스터 이름은 프로젝트 내에서 고유해야 합니다. |
Cloud Shell 시간 제한 | 커피를 마시는 데 30분이 걸리면 Cloud Shell이 절전 모드로 전환되어 |
4. 스키마 프로비저닝
이 단계에서는 다음 내용을 다룹니다.
AlloyDB 클러스터와 인스턴스가 실행되면 AlloyDB Studio SQL 편집기로 이동하여 AI 확장 프로그램을 사용 설정하고 스키마를 프로비저닝합니다.
인스턴스 생성이 완료될 때까지 기다려야 할 수 있습니다. 준비가 되면 클러스터를 만들 때 만든 사용자 인증 정보를 사용하여 AlloyDB에 로그인합니다. PostgreSQL에 인증하려면 다음 데이터를 사용하세요.
- 사용자 이름 : '
postgres' - 데이터베이스 : '
postgres' - 비밀번호 : '
alloydb' (또는 생성 시 설정한 비밀번호)
AlloyDB Studio에 인증되면 편집기에 SQL 명령어가 입력됩니다. 마지막 창 오른쪽에 있는 더하기 기호를 사용하여 여러 편집기 창을 추가할 수 있습니다.
필요에 따라 실행, 형식 지정, 지우기 옵션을 사용하여 편집기 창에 AlloyDB 명령어를 입력합니다.
확장 프로그램 사용 설정
이 앱을 빌드하기 위해 확장 프로그램 pgvector 및 google_ml_integration를 사용합니다. pgvector 확장 프로그램을 사용하면 벡터 임베딩을 저장하고 검색할 수 있습니다. google_ml_integration 확장 프로그램은 SQL에서 예측을 수행하기 위해 Vertex AI 예측 엔드포인트에 액세스하는 데 사용하는 함수를 제공합니다. 다음 DDL을 실행하여 이러한 확장 프로그램을 사용 설정합니다.
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
테이블 만들기
규모를 보여주려면 데이터 세트가 필요합니다. CSV를 가져오는 대신 SQL을 사용하여 50,000개의 합성 '도움말' 행을 즉시 생성합니다.
AlloyDB Studio에서 아래 DDL 문을 사용하여 테이블을 만들 수 있습니다.
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
item_vector 열은 텍스트의 벡터 값을 저장할 수 있습니다.
데이터 확인:
SELECT count(*) FROM help_articles;
-- Output: 50000
데이터베이스 플래그 사용 설정
인스턴스 구성 콘솔로 이동하여 '기본 수정'을 클릭하고 고급 구성으로 이동하여 '데이터베이스 플래그 추가'를 클릭합니다.
그렇지 않은 경우 플래그 드롭다운에 입력하고 '사용'으로 설정한 후 인스턴스를 업데이트합니다.
그렇지 않은 경우 플래그 드롭다운에 입력하고 '사용'으로 설정한 후 인스턴스를 업데이트합니다.
데이터베이스 플래그 구성 단계:
- Google Cloud 콘솔에서 클러스터 페이지로 이동합니다.
- 리소스 이름 열에서 클러스터를 클릭합니다.
- 개요 페이지에서 클러스터의 인스턴스로 이동하여 인스턴스를 선택한 다음 수정을 클릭합니다.
- 인스턴스에서 데이터베이스 플래그를 추가, 수정 또는 삭제합니다.
플래그 추가
- 인스턴스에 데이터베이스 플래그를 추가하려면 '플래그 추가'를 클릭합니다.
- '새 데이터베이스 플래그' 목록에서 플래그를 선택합니다.
- 플래그 값을 입력합니다.
- 완료를 클릭합니다.
- 인스턴스 업데이트를 클릭합니다.
- google_ml_integration 확장 프로그램이 버전 1.5.2 이상인지 확인합니다.
다음 명령어를 사용하여 확장 프로그램 버전을 확인합니다.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
확장 프로그램을 더 높은 버전으로 업데이트해야 하는 경우 다음 명령어를 사용합니다.
ALTER EXTENSION google_ml_integration UPDATE;
권한 부여
- 사용자가 자동 임베딩 생성을 관리하도록 하려면 google_ml.embed_gen_progress 및 google_ml.embed_gen_settings 테이블에 INSERT, UPDATE, DELETE 권한을 부여하세요.
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
'postgres'는 권한이 부여된 USER_NAME입니다.
- 아래 문을 실행하여 'embedding' 함수에 대한 실행 권한을 부여합니다.
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB 서비스 계정에 Vertex AI 사용자 역할 부여
Google Cloud IAM 콘솔에서 AlloyDB 서비스 계정 (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)에 'Vertex AI 사용자' 역할에 대한 액세스 권한을 부여합니다. PROJECT_NUMBER에는 프로젝트 번호가 표시됩니다.
또는 Cloud Shell 터미널에서 아래 명령어를 실행할 수 있습니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
주의사항 및 문제 해결
'비밀번호 기억 상실증' 루프 | '원클릭' 설정을 사용했고 비밀번호가 기억나지 않는 경우 콘솔의 인스턴스 기본 정보 페이지로 이동하여 '수정'을 클릭하여 |
'확장 프로그램을 찾을 수 없음' 오류 |
|
5. '원샷' 벡터 생성
이 부분이 실습의 핵심입니다. 이러한 50,000개의 행을 처리하기 위해 Python 루프를 작성하는 대신 ai.initialize_embeddings 함수를 사용합니다.
이 단일 명령어는 다음 두 가지 작업을 실행합니다.
- 기존 행을 모두 채웁니다.
- 향후 행을 자동 삽입하는 트리거를 만듭니다.
AlloyDB 쿼리 편집기에서 아래 SQL 문을 실행합니다.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
임베딩 확인
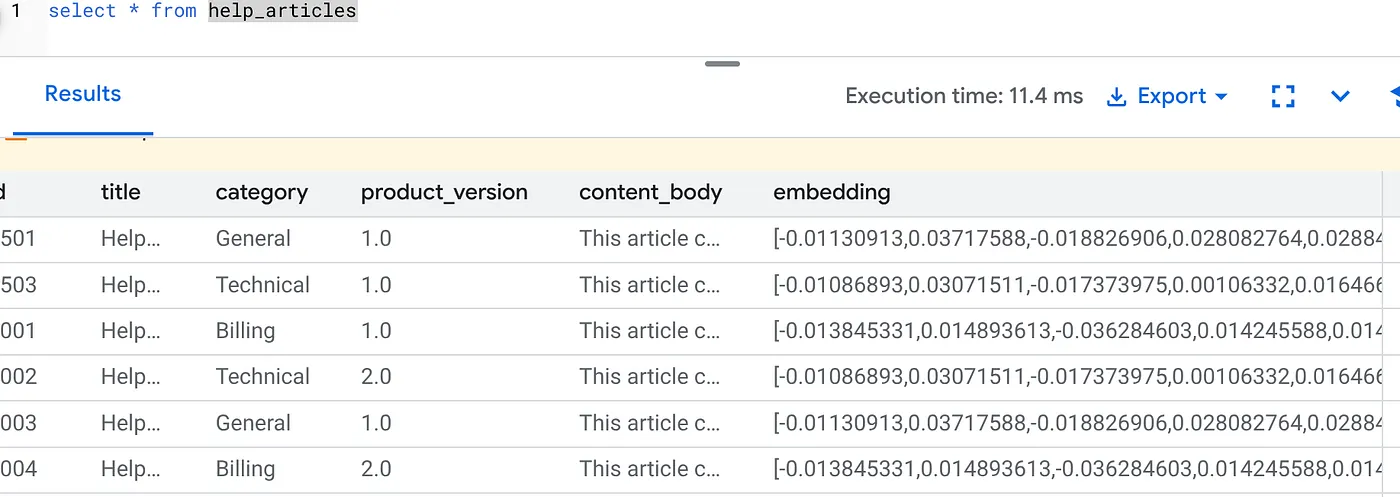
embedding 열이 채워졌는지 확인합니다.
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
아래와 비슷한 결과가 표시됩니다.
무슨 일이 일어난 거지?
- 대규모 백필: 기존 50,000개 행을 자동으로 스윕하고 Vertex AI를 통해 임베딩을 생성합니다.
- 자동화: incremental_refresh_mode => 'transactional'을 설정하면 AlloyDB가 내부 트리거를 자동으로 설정합니다. help_articles에 삽입된 새 행은 즉시 삽입됩니다.
- 선택적으로 incremental_refresh_mode => 'None'을 설정하여 일괄 업데이트를 실행하는 명령문만 가져오고 모든 행 임베딩을 업데이트하기 위해 ai.refresh_embeddings()를 수동으로 호출할 수 있습니다.
Kafka 대기열, Python 작업자, 마이그레이션 스크립트를 SQL 6줄로 대체했습니다. 모든 속성에 대한 자세한 공식 문서는 여기에서 확인할 수 있습니다.
실시간 트리거 테스트
'제로 루프' 자동화가 새 데이터에 대해 작동하는지 확인해 보겠습니다.
- 새 행 삽입:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- 즉시 확인:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
결과:
외부 스크립트를 실행하지 않고도 벡터가 즉시 생성됩니다.
배치 크기 조정
현재 AlloyDB는 기본적으로 배치 크기를 50으로 설정합니다. 기본값은 바로 사용할 수 있지만 AlloyDB에서는 사용자가 고유한 모델과 데이터 세트에 맞게 완벽한 구성을 조정할 수 있습니다.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
하지만 사용자는 성능을 제한할 수 있는 할당량 한도를 알고 있어야 합니다. 권장되는 AlloyDB 할당량을 검토하려면 문서의 '시작하기 전에' 섹션을 참고하세요.
주의사항 및 문제 해결
IAM 전파 격차 |
|
벡터 차원 불일치 |
|
6. 유연한 컨텍스트 검색
이제 하이브리드 검색을 실행합니다. 시맨틱 이해 (벡터)와 비즈니스 로직 (SQL 필터)을 결합합니다.
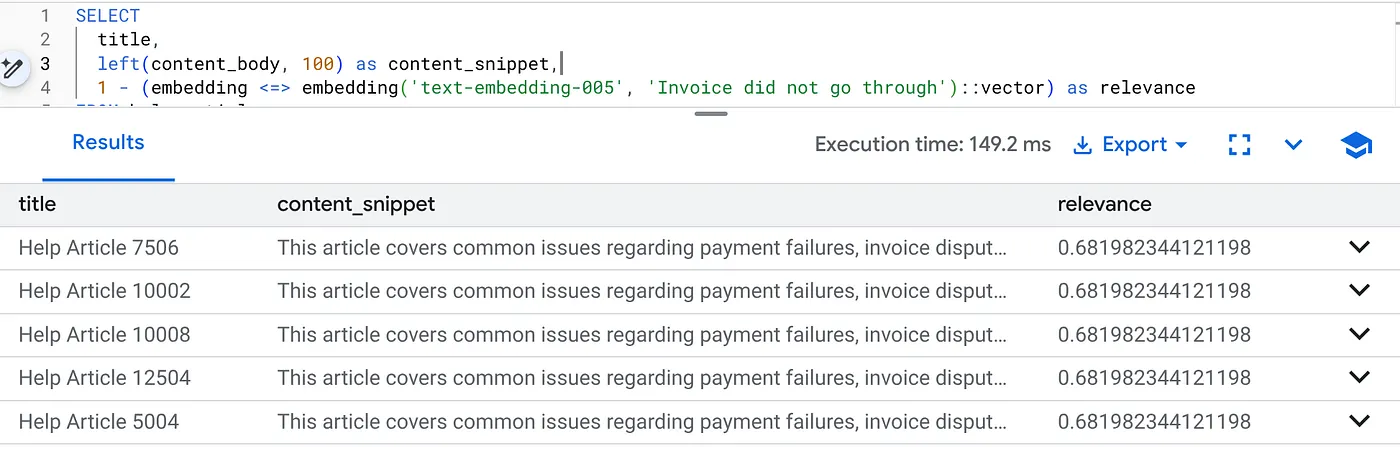
다음 쿼리를 실행하여 제품 버전 2.0의 결제 문제를 찾습니다.
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
이것이 플렉싱 컨텍스트입니다. 검색은 엄격한 비즈니스 제약 조건(버전 2.0)을 준수하면서 사용자의 의도('결제 문제')를 이해하기 위해 '유연하게' 작동합니다.
스타트업 및 이전에 적합한 이유
- 인프라 부채 제로: 별도의 벡터 DB (Pinecone/Milvus)를 가동하지 않았습니다. 별도의 ETL 작업을 작성하지 않았습니다. 모든 데이터는 Postgres에 있습니다.
- 실시간 업데이트: '트랜잭션' 모드를 사용하면 검색 색인이 오래되지 않습니다. 데이터가 커밋되는 순간 벡터 준비가 완료됩니다.
- 확장성: AlloyDB는 Google 인프라를 기반으로 구축됩니다. 수백만 개의 벡터를 Python 스크립트보다 훨씬 빠르게 대량으로 생성할 수 있습니다.
주의사항 및 문제 해결
프로덕션 성능 문제 | 문제: 50,000개 행에 대해 빠릅니다. 카테고리 필터가 충분히 선택적이지 않은 경우 백만 개의 행에 대해 매우 느립니다. 해결 방법: 벡터 색인 추가: 프로덕션 규모의 경우 색인을 만들어야 합니다. CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);색인 사용 확인: |
'모델 불일치' 재난 | 문제: CALL 절에서 text-embedding-005를 사용하여 열을 초기화했습니다. SELECT 쿼리 함수 embedding('model-name', ...)에서 실수로 다른 모델(예: text-embedding-004 또는 OSS 모델)을 사용하면 차원은 일치 (768)할 수 있지만 벡터 공간은 완전히 달라집니다. 쿼리는 오류 없이 실행되지만 결과는 완전히 관련이 없습니다 (가비지 관련성 점수). 문제 해결: ai.initialize_embeddings의 model_id가 SELECT 쿼리의 model_id와 정확히 일치하는지 확인합니다. |
'무음 빈' 결과 (과도한 필터링) | 문제: 하이브리드 검색은 'AND' 작업입니다. 의미 일치 및 SQL 일치가 필요합니다.사용자가 '결제 도움말'을 검색했지만
|
4. 권한/할당량 오류 (500 오류) | 문제:
|
5. Null 임베딩 | 문제:모델이 완전히 초기화되기 전에 데이터를 삽입하거나 백그라운드 작업자가 실패하면 일부 행의
|
7. 삭제
이 실습을 완료한 후에는 AlloyDB 클러스터와 인스턴스를 삭제해야 합니다.
인스턴스와 함께 클러스터를 정리해야 합니다.
8. 축하합니다
확장 가능한 기술 자료 검색 애플리케이션을 성공적으로 빌드했습니다. 벡터 임베딩을 생성하기 위해 Python 스크립트와 루프를 사용하여 복잡한 ETL 파이프라인을 관리하는 대신 AlloyDB AI를 사용하여 단일 SQL 명령어를 통해 데이터베이스 내에서 기본적으로 임베딩 생성을 처리했습니다.
학습한 내용
- 데이터 처리를 위해 'Python For-Loop'를 종료했습니다.
- SQL 명령어 하나로 50,000개의 벡터를 생성했습니다.
- 트리거를 사용하여 향후 벡터 생성을 자동화했습니다.
- 하이브리드 검색을 실행했습니다.
다음 단계
- 자체 데이터 세트로 사용해 보세요.
- AlloyDB AI 문서를 살펴봅니다.
- 더 많은 워크숍은 Code Vipassana 웹사이트를 확인하세요.