
1. Przegląd
W tym ćwiczeniu utworzysz skalowalną aplikację do wyszukiwania w bazie wiedzy. Zamiast zarządzać złożoną potokiem ETL z użyciem skryptów i pętli w Pythonie do generowania wektorów dystrybucyjnych, możesz używać AlloyDB AI do obsługi generowania wektorów dystrybucyjnych natywnie w bazie danych za pomocą jednego polecenia SQL.
Co utworzysz
Wydajna aplikacja bazy danych „z możliwością wyszukiwania” w bazie wiedzy.
Czego się nauczysz
Zapoznasz się z tymi zagadnieniami:
- Aprowizuj klaster AlloyDB i włącz rozszerzenia AI.
- Generowanie danych syntetycznych (ponad 50 tys. wierszy) za pomocą SQL.
- Wypełnij wektoryzacje całego zbioru danych za pomocą przetwarzania wsadowego.
- Skonfiguruj aktywatory przyrostowe w czasie rzeczywistym, aby automatycznie osadzać nowe dane.
- Wykonywanie wyszukiwania hybrydowego (wektorowego + filtrów SQL) dla hasła „Flexing Context”.
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: kliknij link i włącz interfejsy API.
Możesz też użyć do tego polecenia gcloud. Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Pułapki i rozwiązywanie problemów
Syndrom „projektu widma” | Uruchomiono polecenie |
Bariera rozliczeniowa | Projekt został włączony, ale zapomniano o koncie rozliczeniowym. AlloyDB to silnik o wysokiej wydajności, który nie uruchomi się, jeśli „zbiornik paliwa” (płatności) jest pusty. |
Opóźnienie propagacji interfejsu API | Kliknięto „Włącz interfejsy API”, ale w wierszu poleceń nadal wyświetla się |
Quota Quags | Jeśli korzystasz z nowego konta próbnego, możesz osiągnąć regionalny limit instancji AlloyDB. Jeśli |
Ukryty agent usługi | Czasami agentowi usługi AlloyDB nie jest automatycznie przyznawana rola |
3. Konfiguracja bazy danych
W tym module użyjemy AlloyDB jako bazy danych do przechowywania danych testowych. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję główną, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie załadowany testowy zbiór danych.
- Kliknij przycisk lub skopiuj poniższy link do przeglądarki, w której zalogowany jest użytkownik konsoli Google Cloud.
- Po wykonaniu tego kroku repozytorium zostanie sklonowane do lokalnego edytora Cloud Shell i będziesz mieć możliwość uruchomienia poniższego polecenia z folderu projektu (ważne jest, aby upewnić się, że jesteś w katalogu projektu):
sh run.sh
- Teraz użyj interfejsu (kliknij link w terminalu lub link „Podgląd w internecie” w terminalu).
- Aby rozpocząć, wpisz szczegóły identyfikatora projektu, klastra i nazw instancji.
- Idź na kawę, podczas gdy dzienniki będą się przewijać. Tutaj możesz przeczytać, jak to działa w tle. Może to potrwać około 10–15 minut.
Pułapki i rozwiązywanie problemów
Problem z „cierpliwością” | Klastry baz danych to rozbudowana infrastruktura. Jeśli odświeżysz stronę lub zakończysz sesję Cloud Shell, ponieważ „utknęła”, możesz skończyć z „duchem” instancji, która jest częściowo udostępniona i niemożliwa do usunięcia bez ręcznej interwencji. |
Niezgodny region | Jeśli interfejsy API zostały włączone w regionie |
Zombie Clusters | Jeśli wcześniej używasz tej samej nazwy klastra i nie została ona usunięta, skrypt może wyświetlić komunikat, że nazwa klastra już istnieje. Nazwy klastrów muszą być unikalne w projekcie. |
Limit czasu Cloud Shell | Jeśli przerwa na kawę trwa 30 minut, Cloud Shell może przejść w stan uśpienia i odłączyć proces |
4. Provisioning schematu
W tym kroku omówimy:
Gdy klaster i instancja AlloyDB będą działać, przejdź do edytora SQL w AlloyDB Studio, aby włączyć rozszerzenia AI i udostępnić schemat.
Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb” (lub inne hasło ustawione podczas tworzenia)
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wpisywane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.
Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, używając w razie potrzeby opcji Uruchom, Formatuj i Wyczyść.
Włączanie rozszerzeń
Do utworzenia tej aplikacji użyjemy rozszerzeń pgvector i google_ml_integration. Rozszerzenie pgvector umożliwia przechowywanie wektorów dystrybucyjnych i wyszukiwanie ich. Rozszerzenie google_ml_integration udostępnia funkcje, których możesz używać do uzyskiwania dostępu do punktów końcowych prognozowania Vertex AI w celu uzyskiwania prognoz w SQL. Włącz te rozszerzenia, uruchamiając te DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Tworzenie tabeli
Aby zademonstrować skalę, potrzebujemy zbioru danych. Zamiast importować plik CSV, wygenerujemy natychmiast 50 tys. wierszy syntetycznych „artykułów pomocy” za pomocą SQL.
Tabelę możesz utworzyć za pomocą poniższej instrukcji DDL w AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
Kolumna item_vector będzie przechowywać wartości wektorowe tekstu.
Sprawdź dane:
SELECT count(*) FROM help_articles;
-- Output: 50000
Włączanie flag bazy danych
Otwórz konsolę konfiguracji instancji, kliknij „Edytuj podstawową”, przejdź do konfiguracji zaawansowanej i kliknij „Dodaj flagi bazy danych”.
Jeśli nie, wpisz go w menu flag i ustaw go na „WŁĄCZONY”, a następnie zaktualizuj instancję.
Jeśli nie, wpisz go w menu flag i ustaw go na „WŁĄCZONY”, a następnie zaktualizuj instancję.
Czynności konfigurowania flag bazy danych:
- W konsoli Google Cloud otwórz stronę Klastry.
- W kolumnie Nazwa zasobu kliknij klaster.
- Na stronie Przegląd w sekcji Instancje w klastrze wybierz instancję, a następnie kliknij Edytuj.
- Dodawanie, modyfikowanie i usuwanie flagi bazy danych z instancji:
Dodawanie flagi
- Aby dodać do instancji flagę bazy danych, kliknij Dodaj flagę.
- Wybierz flagę z listy Nowa flaga bazy danych.
- Podaj wartość flagi.
- Kliknij Gotowe.
- Kliknij Zaktualizuj instancję.
- Sprawdź, czy rozszerzenie google_ml_integration ma wersję 1.5.2 lub nowszą:
Aby sprawdzić wersję rozszerzenia, użyj tego polecenia:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Jeśli chcesz uaktualnić rozszerzenie do wyższej wersji, użyj polecenia:
ALTER EXTENSION google_ml_integration UPDATE;
Przyznaj uprawnienia
- Aby umożliwić użytkownikowi zarządzanie generowaniem automatycznego osadzania, przyznaj mu uprawnienia INSERT, UPDATE i DELETE w tabelach google_ml.embed_gen_progress i google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
„postgres” to USER_NAME, dla którego przyznano uprawnienia.
- Aby przyznać uprawnienia do wykonywania funkcji „embedding”, uruchom to polecenie:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Przyznawanie roli Użytkownik Vertex AI kontu usługi AlloyDB
W konsoli IAM Google Cloud przyznaj kontu usługi AlloyDB (które wygląda tak: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) dostęp do roli „Użytkownik Vertex AI”. Zmienna PROJECT_NUMBER będzie zawierać numer Twojego projektu.
Możesz też uruchomić to polecenie w terminalu Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Pułapki i rozwiązywanie problemów
Pętla „amnezji hasła” | Jeśli używasz konfiguracji „Jedno kliknięcie” i nie pamiętasz hasła, otwórz stronę podstawowych informacji o instancji w konsoli i kliknij „Edytuj”, aby zresetować hasło |
Błąd „Nie znaleziono rozszerzenia” | Jeśli |
5. Generowanie wektorów „One-Shot”
To jest główna część modułu. Zamiast pisać pętlę w Pythonie do przetworzenia tych 50 tys. wierszy, użyjemy funkcji ai.initialize_embeddings.
To jedno polecenie wykonuje 2 działania:
- Wypełnia wszystkie istniejące wiersze.
- Tworzy aktywator, który automatycznie osadza przyszłe wiersze.
Uruchom poniższą instrukcję SQL w edytorze zapytań AlloyDB.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
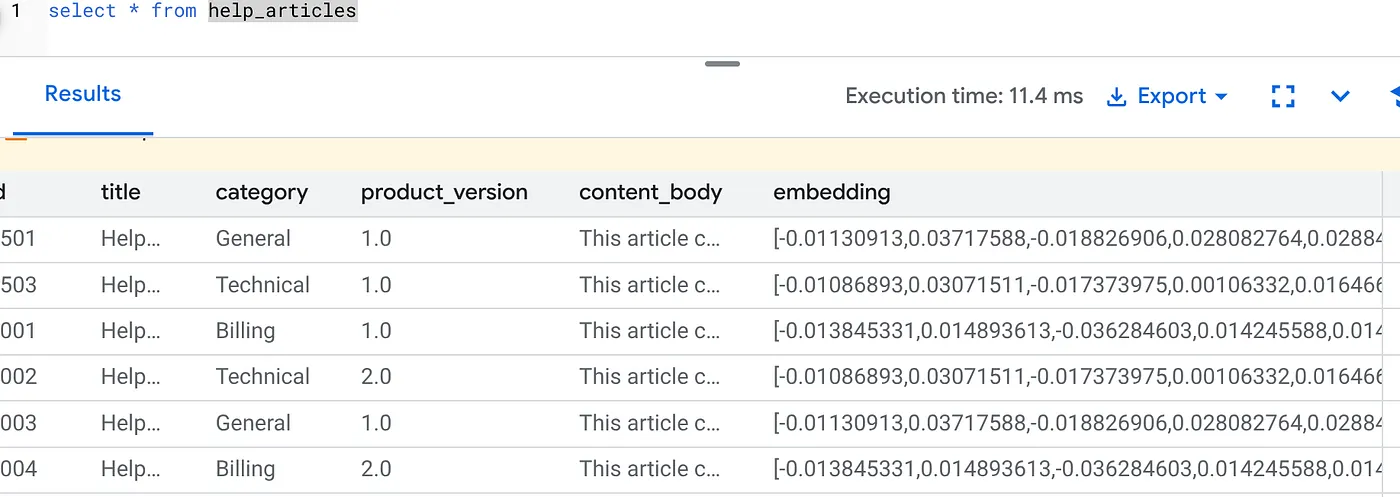
Sprawdzanie wektorów dystrybucyjnych
Sprawdź, czy kolumna embedding jest teraz wypełniona:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Wynik powinien być podobny do tego poniżej:
Co się właśnie stało?
- Wypełnianie wsteczne na dużą skalę: automatycznie przeszukuje istniejące 50 tys. wierszy i generuje wektory dystrybucyjne za pomocą Vertex AI.
- Automatyzacja: ustawiając incremental_refresh_mode => 'transactional', AlloyDB automatycznie konfiguruje wewnętrzne reguły. Każdy nowy wiersz wstawiony do tabeli help_articles będzie miał natychmiast wygenerowane osadzenie.
- Opcjonalnie możesz ustawić incremental_refresh_mode => „None”, aby otrzymywać tylko instrukcje do przeprowadzania zbiorczych aktualizacji i ręcznie wywoływać ai.refresh_embeddings() w celu aktualizowania wszystkich wektorów wierszy.
Zastąpiliśmy kolejkę Kafka, proces roboczy Pythona i skrypt migracji 6 wierszami kodu SQL. Szczegółową oficjalną dokumentację wszystkich atrybutów znajdziesz tutaj.
Test reguły działającej w czasie rzeczywistym
Sprawdźmy, czy automatyzacja „Zero Loop” działa w przypadku nowych danych.
- Wstawianie nowego wiersza:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Sprawdź od razu:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Wynik:
Wektor powinien zostać wygenerowany natychmiast bez uruchamiania zewnętrznego skryptu.
Dostrajanie wielkości wsadu
Obecnie AlloyDB domyślnie ustawia wielkość wsadu na 50. Ustawienia domyślne działają świetnie od razu po wyjęciu z pudełka, ale AlloyDB nadal daje użytkownikom możliwość dostosowania idealnej konfiguracji do ich unikalnego modelu i zbioru danych.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Użytkownicy muszą jednak pamiętać o limitach, które mogą ograniczać wydajność. Aby sprawdzić zalecane limity AlloyDB, zapoznaj się z sekcją „Zanim zaczniesz” w dokumentacji.
Pułapki i rozwiązywanie problemów
Opóźnienie propagacji uprawnień | Uruchomiono polecenie |
Niezgodność wymiarów wektora | Tabela |
6. Elastyczne wyszukiwanie kontekstowe
Teraz przeprowadzamy wyszukiwanie hybrydowe. Łączymy zrozumienie semantyczne (wektor) z logiką biznesową (filtry SQL).
Uruchom to zapytanie, aby znaleźć problemy z płatnościami dotyczące konkretnie wersji 2.0 produktu:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
To jest kontekst elastyczny. Wyszukiwarka „dopasowuje się” do intencji użytkownika („problemy z płatnościami”), zachowując jednocześnie sztywne ograniczenia biznesowe (wersja 2.0).
Dlaczego ta strategia jest korzystna dla startupów i migracji
- Brak długu infrastrukturalnego: nie musisz uruchamiać osobnej bazy danych wektorów (Pinecone/Milvus). Nie napisano osobnego zadania ETL. Wszystko jest w PostgreSQL.
- Aktualizacje w czasie rzeczywistym: w trybie „transakcyjnym” indeks wyszukiwania nigdy nie jest nieaktualny. Gdy dane zostaną zatwierdzone, są gotowe do przekształcenia w wektory.
- Skalowalność: AlloyDB jest oparta na infrastrukturze Google. Może on generować miliony wektorów szybciej niż skrypt w Pythonie.
Pułapki i rozwiązywanie problemów
Pułapka związana z wydajnością w środowisku produkcyjnym | Problem: szybkie przetwarzanie 50 tys. wierszy. Bardzo wolne w przypadku 1 mln wierszy , jeśli filtr kategorii nie jest wystarczająco selektywny.Rozwiązanie:dodaj indeks wektorowy: w przypadku skali produkcyjnej musisz utworzyć indeks:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops); sprawdź użycie indeksu: uruchom |
Katastrofa „Niedopasowanie modelu” | Problem: kolumna została zainicjowana za pomocą modelu text-embedding-005 w procedurze CALL. Jeśli w zapytaniu SELECT w funkcji embedding('model-name', ...) przypadkowo użyjesz innego modelu (np. text-embedding-004 lub modelu OSS), wymiary mogą się zgadzać (768), ale przestrzeń wektorowa będzie zupełnie inna. Zapytanie zostanie wykonane bez błędów, ale wyniki będą całkowicie nieistotne (nieprawidłowe wyniki trafności). Rozwiązywanie problemów:upewnij się, że model_id w funkcji ai.initialize_embeddings dokładnie odpowiada model_id w zapytaniu SELECT. |
Wynik „Silent Empty” (nadmierne filtrowanie) | Problem: wyszukiwanie hybrydowe to operacja „I”. Wymaga to dopasowania semantycznego I dopasowania SQL.Jeśli użytkownik wyszuka „Pomoc dotycząca płatności”, ale w kolumnie
|
4. Błędy uprawnień lub limitów (błąd 500) | Problem:funkcja
|
5. Wektory dystrybucyjne o wartości null | Problem:jeśli wstawisz dane zanim model zostanie w pełni zainicjowany lub jeśli proces w tle ulegnie awarii, niektóre wiersze mogą zawierać wartość
|
7. Czyszczenie danych
Po ukończeniu tego laboratorium nie zapomnij usunąć klastra i instancji AlloyDB.
Powinien on zwalniać miejsce w klastrze wraz z jego instancjami.
8. Gratulacje
Udało Ci się utworzyć skalowalną aplikację do wyszukiwania w bazie wiedzy. Zamiast zarządzać złożoną potokiem ETL z użyciem skryptów i pętli w Pythonie do generowania wektorów dystrybucyjnych, używasz AlloyDB AI do obsługi generowania wektorów dystrybucyjnych natywnie w bazie danych za pomocą jednego polecenia SQL.
Omówione zagadnienia
- Zrezygnowaliśmy z pętli „Python For-Loop” na potrzeby przetwarzania danych.
- Wygenerowaliśmy 50 tys. wektorów za pomocą jednego polecenia SQL.
- Zautomatyzowaliśmy generowanie przyszłych wektorów za pomocą aktywatorów.
- Przeprowadziliśmy wyszukiwanie hybrydowe.
Następne kroki
- Wypróbuj to na własnym zbiorze danych.
- Zapoznaj się z dokumentacją AlloyDB AI.
- Więcej warsztatów znajdziesz na stronie Code Vipassana.