
1. Visão geral
Neste codelab, você vai criar um aplicativo de pesquisa de base de conhecimento escalonável. Em vez de gerenciar um pipeline de ETL complexo com scripts e loops Python para gerar embeddings de vetores, você vai usar a IA do AlloyDB para processar a geração de embeddings de forma nativa no banco de dados com um único comando SQL.
O que você vai criar
Um aplicativo de banco de dados de base de conhecimento "pesquisável" de alto desempenho.
O que você vai aprender
Você aprenderá o seguinte:
- Provisione um cluster do AlloyDB e ative as extensões de IA.
- Gere dados sintéticos (mais de 50.000 linhas) usando SQL.
- Faça o backfill dos embeddings de vetor para todo o conjunto de dados usando o processamento em lote.
- Configure gatilhos incrementais em tempo real para incorporar automaticamente novos dados.
- Faça uma Pesquisa híbrida (vetor + filtros SQL) por "Flexing Context".
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: siga o link e ative as APIs.
Como alternativa, use o comando gcloud. Consulte a documentação para ver o uso e os comandos gcloud.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Problemas e solução de problemas
A síndrome do projeto fantasma | Você executou |
A barricada de faturamento | Você ativou o projeto, mas esqueceu a conta de faturamento. O AlloyDB é um mecanismo de alto desempenho. Ele não vai iniciar se o "tanque de combustível" (faturamento) estiver vazio. |
Atraso na propagação da API | Você clicou em "Ativar APIs", mas a linha de comando ainda mostra |
Quags de cota | Se você estiver usando uma conta de teste nova, talvez atinja uma cota regional para instâncias do AlloyDB. Se |
Agente de serviço"oculto" | Às vezes, o agente de serviço do AlloyDB não recebe automaticamente o papel |
3. Configuração do banco de dados
Neste laboratório, vamos usar o AlloyDB como banco de dados para os dados de teste. Ele usa clusters para armazenar todos os recursos, como bancos de dados e registros. Cada cluster tem uma instância principal que fornece um ponto de acesso aos dados. As tabelas vão conter os dados reais.
Vamos criar um cluster, uma instância e uma tabela do AlloyDB em que o conjunto de dados de teste será carregado.
- Clique no botão ou copie o link abaixo para o navegador em que o usuário do console do Google Cloud está conectado.
- Depois que essa etapa for concluída, o repositório será clonado no editor local do Cloud Shell, e você poderá executar o comando abaixo na pasta do projeto. É importante verificar se você está no diretório do projeto:
sh run.sh
- Agora use a interface (clique no link no terminal ou no link "visualizar na Web" no terminal).
- Insira os detalhes do ID do projeto, do cluster e dos nomes das instâncias para começar.
- Tome um café enquanto os registros rolam e leia aqui como isso é feito nos bastidores. Isso pode levar de 10 a 15 minutos.
Problemas e solução de problemas
O problema da "paciência" | Os clusters de banco de dados são uma infraestrutura pesada. Se você atualizar a página ou encerrar a sessão do Cloud Shell porque ela "parece travada", poderá acabar com uma instância "fantasma" parcialmente provisionada e impossível de excluir sem intervenção manual. |
Incompatibilidade de região | Se você ativou as APIs em |
Clusters zumbis | Se você já usou o mesmo nome para um cluster e não o excluiu, o script pode informar que o nome do cluster já existe. Os nomes de cluster precisam ser exclusivos em um projeto. |
Tempo limite do Cloud Shell | Se o intervalo para o café durar 30 minutos, o Cloud Shell poderá entrar em modo de espera e desconectar o processo |
4. Provisionamento de esquema
Nesta etapa, vamos abordar o seguinte:
Depois que o cluster e a instância do AlloyDB estiverem em execução, acesse o editor de SQL do AlloyDB Studio para ativar as extensões de IA e provisionar o esquema.
Talvez seja necessário aguardar a conclusão da criação da instância. Depois disso, faça login no AlloyDB usando as credenciais criadas ao criar o cluster. Use os seguintes dados para autenticar no PostgreSQL:
- Nome de usuário : "
postgres" - Banco de dados : "
postgres" - Senha : "
alloydb" (ou o que você definiu no momento da criação)
Depois de se autenticar no AlloyDB Studio, os comandos SQL são inseridos no editor. É possível adicionar várias janelas do Editor usando o sinal de mais à direita da última janela.
Você vai inserir comandos para o AlloyDB nas janelas do editor, usando as opções "Executar", "Formatar" e "Limpar" conforme necessário.
Ativar extensões
Para criar esse app, vamos usar as extensões pgvector e google_ml_integration. A extensão pgvector permite armazenar e pesquisar embeddings de vetores. A extensão google_ml_integration oferece funções que você usa para acessar endpoints de previsão da Vertex AI e receber previsões em SQL. Ative essas extensões executando os seguintes DDLs:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Criar uma tabela
Precisamos de um conjunto de dados para demonstrar a escala. Em vez de importar um CSV, vamos gerar 50.000 linhas de "Artigos de ajuda" sintéticos instantaneamente usando SQL.
É possível criar uma tabela usando a instrução DDL abaixo no AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
A coluna item_vector vai permitir o armazenamento dos valores vetoriais do texto.
Verifique os dados:
SELECT count(*) FROM help_articles;
-- Output: 50000
Ativar flags de banco de dados
Acesse o console de configuração da instância, clique em "Editar primária", acesse "Configuração avançada" e clique em "Adicionar flags de banco de dados".
Se não, insira no menu suspenso de flags, defina como "ON" e atualize a instância.
Se não, insira no menu suspenso de flags, defina como "ON" e atualize a instância.
Etapas para configurar flags do banco de dados:
- No console do Google Cloud, acesse a página "Clusters".
- Clique em um cluster na coluna Nome do Recurso.
- Na página Visão geral, acesse Instâncias no cluster, selecione uma instância e clique em Editar.
- Adicione, modifique ou exclua uma flag de banco de dados da sua instância:
Adicionar uma flag
- Para adicionar uma flag de banco de dados à instância, clique em "Adicionar flag".
- Selecione uma flag na lista "Nova flag de banco de dados".
- Informe um valor para a flag.
- Clique em "Concluído".
- Clique em Atualizar instância.
- Verifique se a extensão google_ml_integration é a versão 1.5.2 ou mais recente:
Para verificar a versão da extensão com o seguinte comando:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Se você precisar atualizar a extensão para uma versão mais recente, use o comando:
ALTER EXTENSION google_ml_integration UPDATE;
Conceder permissão
- Para permitir que um usuário gerencie a geração de incorporação automática, conceda permissões INSERT, UPDATE e DELETE nas tabelas google_ml.embed_gen_progress e google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
"postgres" é o USER_NAME para o qual as permissões são concedidas.
- Execute a instrução abaixo para conceder a execução na função "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Conceder o papel de usuário da Vertex AI à conta de serviço do AlloyDB
No console do Google Cloud IAM, conceda à conta de serviço do AlloyDB (que tem esta aparência: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acesso à função "Usuário da Vertex AI". PROJECT_NUMBER vai ter o número do seu projeto.
Como alternativa, execute o comando abaixo no terminal do Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Problemas e solução de problemas
O loop de "amnésia de senha" | Se você usou a configuração "Um clique" e não se lembra da senha, acesse a página de informações básicas da instância no console e clique em "Editar" para redefinir a senha |
O erro "Extensão não encontrada" | Se |
5. Geração de vetores "one-shot"
Esta é a essência do laboratório. Em vez de escrever um loop Python para processar essas 50.000 linhas, vamos usar a função ai.initialize_embeddings.
Esse único comando faz duas coisas:
- Preenche todas as linhas atuais.
- Cria um gatilho para incorporar automaticamente linhas futuras.
Execute a instrução SQL abaixo no editor de consultas do AlloyDB
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
Verificar os embeddings
Verifique se a coluna embedding está preenchida:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Você vai ver um resultado semelhante a este:
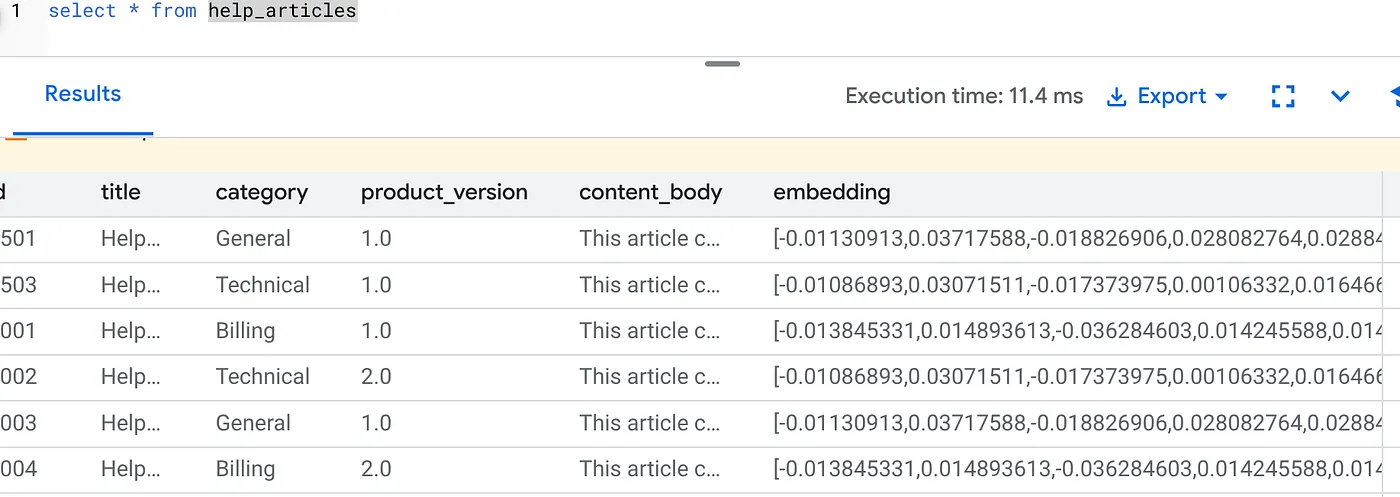
O que aconteceu?
- Preenchimento automático em grande escala:ele faz uma varredura automática nas 50.000 linhas atuais e gera incorporações usando a Vertex AI.
- Automação:ao definir incremental_refresh_mode => 'transactional', o AlloyDB configura automaticamente os gatilhos internos. Qualquer nova linha inserida em "help_articles" terá o embedding gerado instantaneamente.
- Você pode definir incremental_refresh_mode => "None" para que a instrução só faça atualizações em massa e chame manualmente ai.refresh_embeddings() para atualizar todas as incorporações de linhas.
Você acabou de substituir uma fila do Kafka, um worker do Python e um script de migração por seis linhas de SQL. Confira a documentação oficial detalhada de todos os atributos.
Teste de acionador em tempo real
Vamos verificar se a automação "Zero Loop" funciona com novos dados.
- Inserir uma nova linha:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Verifique imediatamente:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Resultado:
O vetor será gerado instantaneamente sem a execução de um script externo.
Ajustar o tamanho do lote
No momento, o AlloyDB define o tamanho do lote como 50 por padrão. Embora os padrões funcionem muito bem, o AlloyDB ainda oferece aos usuários o controle para ajustar a configuração perfeita para seu modelo e conjunto de dados exclusivos.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
No entanto, os usuários precisam estar cientes dos limites de cota que podem restringir a performance. Para conferir as cotas recomendadas do AlloyDB, consulte a seção "Antes de começar" na documentação.
Problemas e solução de problemas
A lacuna de propagação do IAM | Você executou o comando do IAM |
Incompatibilidade de dimensão do vetor | A tabela |
6. Pesquisa contextual flexível
Agora vamos realizar uma pesquisa híbrida. Combinamos a compreensão semântica (vetor) com a lógica de negócios (filtros SQL).
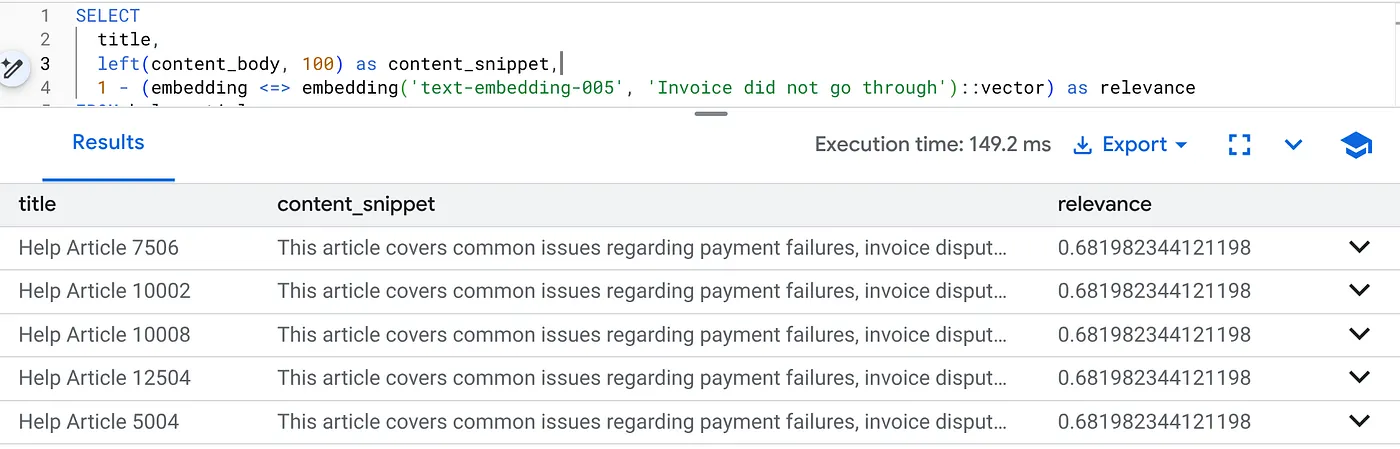
Execute esta consulta para encontrar problemas de faturamento específicos da versão 2.0 do produto:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Esse é o contexto de flexão. A pesquisa "se adapta" para entender a intenção do usuário ("problemas de faturamento") e respeitar as restrições rígidas da empresa (versão 2.0).
Por que isso é bom para startups e migrações
- Débito de infraestrutura zero: você não criou um banco de dados vetorial separado (Pinecone/Milvus). Você não escreveu um job de ETL separado. Tudo está no Postgres.
- Atualizações em tempo real: ao usar o modo "transacional", seu índice de pesquisa nunca fica desatualizado. No momento em que os dados são confirmados, eles estão prontos para serem usados com vetores.
- Escalonamento: o AlloyDB é criado com base na infraestrutura do Google. Ele pode processar a geração em massa de milhões de vetores mais rápido do que seu script Python.
Problemas e solução de problemas
Problema de performance na produção | Problema: rápido para 50.000 linhas. Muito lento para 1 milhão de linhas se o filtro de categoria não for seletivo o suficiente. Solução: adicione um índice de vetor. Para a escala de produção, crie um índice: CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops); Verifique o uso do índice: execute |
O desastre da "incompatibilidade de modelos" | Problema: você inicializou a coluna usando text-embedding-005 no procedimento CALL. Se você usar acidentalmente um modelo diferente (por exemplo, text-embedding-004 ou um modelo de código aberto) na função de incorporação da consulta SELECT embedding('model-name', ...), as dimensões poderão corresponder (768), mas o espaço vetorial será totalmente diferente. A consulta é executada sem erros, mas os resultados são completamente irrelevantes (pontuações de relevância inúteis). Solução de problemas:verifique se o model_id em ai.initialize_embeddings corresponde exatamente ao model_id na sua consulta SELECT. |
O resultado "vazio silencioso" (filtragem excessiva) | Problema: a pesquisa híbrida é uma operação "AND". Ela exige correspondência semântica E correspondência de SQL.Se um usuário pesquisar "Ajuda com faturamento", mas a coluna
|
4. Erros de permissão/cota (erro 500) | Problema:a função
|
5. Embeddings nulos | Problema:se você inserir dados antes que o modelo seja totalmente inicializado ou se o worker em segundo plano falhar, algumas linhas poderão ter
|
7. Limpar
Depois de concluir este laboratório, não se esqueça de excluir o cluster e a instância do AlloyDB.
Ele vai limpar o cluster e as instâncias dele.
8. Parabéns
Você criou um aplicativo de pesquisa de base de conhecimento escalonável. Em vez de gerenciar um pipeline de ETL complexo com scripts e loops Python para gerar embeddings de vetores, você usou a IA do AlloyDB para processar a geração de embeddings de forma nativa no banco de dados com um único comando SQL.
O que abordamos
- Acabamos com o "loop for do Python" para processamento de dados.
- Geramos 50 mil vetores com um comando SQL.
- Automatizamos a geração de vetores futuros com gatilhos.
- Realizamos uma pesquisa híbrida.
Próximas etapas
- Faça um teste com seu próprio conjunto de dados.
- Confira a documentação da IA do AlloyDB.
- Confira mais workshops no site Code Vipassana.