
1. Обзор
В этом практическом занятии вы создадите масштабируемое приложение для поиска в базе знаний. Вместо управления сложным конвейером ETL с помощью скриптов Python и циклов для генерации векторных представлений, вы будете использовать AlloyDB AI для генерации представлений непосредственно в базе данных с помощью одной команды SQL.
Что вы построите
Высокопроизводительное приложение для создания баз знаний с возможностью поиска.
Что вы узнаете
Вы научитесь:
- Создайте кластер AlloyDB и включите расширения искусственного интеллекта.
- Сгенерировать синтетические данные (более 50 000 строк) с помощью SQL.
- Заполнение векторных представлений для всего набора данных с использованием пакетной обработки .
- Настройте триггеры для автоматического внедрения новых данных в режиме реального времени .
- Выполните гибридный поиск (векторный поиск + SQL-фильтры) для "гибкого контекста".
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: перейдите по ссылке и включите API.
В качестве альтернативы можно использовать команду gcloud. Для получения информации о командах gcloud и их использовании обратитесь к документации .
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Подводные камни и устранение неполадок
Синдром «Проекта-призрака» | Вы выполнили команду |
Баррикада Биллинга | Вы активировали проект, но забыли указать платежный аккаунт. AlloyDB — высокопроизводительный движок; он не запустится, если «топливо» (платежный бак) пуст. |
Задержка распространения API | Вы нажали «Включить API», но в командной строке по-прежнему отображается сообщение |
Квота Квагс | Если вы используете совершенно новую пробную учетную запись, вы можете столкнуться с региональной квотой на экземпляры AlloyDB. Если |
«Скрытый» сервисный агент | Иногда агенту службы AlloyDB автоматически не предоставляется роль |
3. Настройка базы данных
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для тестовых данных. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , который обеспечивает точку доступа к данным. Таблицы будут содержать сами данные.
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будет загружен тестовый набор данных.
- Нажмите на кнопку или скопируйте ссылку ниже в браузер, где вы авторизованы в Google Cloud Console.
- После завершения этого шага репозиторий будет клонирован в ваш локальный редактор CloudShell, и вы сможете запустить приведенную ниже команду, указав папку проекта (важно убедиться, что вы находитесь в каталоге проекта):
sh run.sh
- Теперь воспользуйтесь пользовательским интерфейсом (щелкните ссылку в терминале или щелкните ссылку «предварительный просмотр в веб-браузере» в терминале).
- Введите данные для идентификатора проекта, названия кластера и экземпляра, чтобы начать работу.
- Пока прокручиваются логи, выпейте кофе, а здесь вы сможете почитать о том, как это происходит за кулисами. Это может занять около 10-15 минут.
Подводные камни и устранение неполадок
Проблема «терпения» | Кластеры баз данных — это ресурсоемкая инфраструктура. Если вы обновите страницу или завершите сессию Cloud Shell, потому что она «зависла», вы можете получить «фантомный» экземпляр, который будет частично выделен и его невозможно будет удалить без ручного вмешательства. |
Региональное несоответствие | Если вы включили API в регионе |
Скопления зомби | Если вы ранее использовали это же имя для кластера и не удалили его, скрипт может сообщить, что имя кластера уже существует. Имена кластеров должны быть уникальными в рамках одного проекта. |
Таймаут облачной оболочки | Если ваш перерыв на кофе длится 30 минут, Cloud Shell может перейти в спящий режим и отключить процесс |
4. Предоставление схемы
На этом этапе мы рассмотрим следующее:
После запуска кластера и экземпляра AlloyDB перейдите в редактор SQL AlloyDB Studio, чтобы включить расширения AI и настроить схему.
Возможно, вам потребуется дождаться завершения создания экземпляра. После этого войдите в AlloyDB, используя учетные данные, которые вы создали при создании кластера. Для аутентификации в PostgreSQL используйте следующие данные:
- Имя пользователя: "
postgres" - База данных: "
postgres" - Пароль: "
alloydb" (или тот, который вы указали при создании учетной записи)
После успешной аутентификации в AlloyDB Studio команды SQL вводятся в редакторе. Вы можете добавить несколько окон редактора, используя значок плюса справа от последнего окна.
Команды для AlloyDB будут вводиться в окнах редактора, используя при необходимости параметры «Выполнить», «Форматировать» и «Очистить».
Включить расширения
Для создания этого приложения мы будем использовать расширения pgvector и google_ml_integration . Расширение pgvector позволяет хранить и искать векторные представления. Расширение google_ml_integration предоставляет функции, которые вы используете для доступа к конечным точкам прогнозирования Vertex AI и получения прогнозов в формате SQL. Включите эти расширения, выполнив следующие DDL-скрипты:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Создайте таблицу
Нам нужен набор данных для демонстрации масштабируемости. Вместо импорта CSV-файла мы мгновенно сгенерируем 50 000 строк синтетических «справочных статей» с помощью SQL.
В AlloyDB Studio можно создать таблицу, используя приведенный ниже оператор DDL:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
Столбец item_vector позволит хранить векторные значения текста.
Проверьте данные:
SELECT count(*) FROM help_articles;
-- Output: 50000
Включить флаги базы данных
Перейдите в консоль настройки экземпляра, нажмите «Редактировать основной экземпляр», перейдите в раздел «Расширенная конфигурация» и нажмите «Добавить флаги базы данных».
В противном случае введите его в выпадающее меню «Флаги», установите значение «ВКЛ» и обновите экземпляр.
В противном случае введите его в выпадающее меню «Флаги», установите значение «ВКЛ» и обновите экземпляр.
Шаги по настройке флагов базы данных:
- В консоли Google Cloud перейдите на страницу «Кластеры».
- Щелкните по кластеру в столбце «Имя ресурса» .
- На странице «Обзор» перейдите в раздел «Экземпляры в вашем кластере», выберите экземпляр и нажмите «Редактировать» .
- Добавьте, измените или удалите флаг базы данных из вашего экземпляра:
Добавить флаг
- Чтобы добавить флаг базы данных к вашему экземпляру, нажмите кнопку «Добавить флаг».
- Выберите флаг из списка флагов новой базы данных.
- Укажите значение для флага.
- Нажмите «Готово».
- Нажмите «Обновить экземпляр» .
- Убедитесь, что версия расширения google_ml_integration — 1.5.2 или выше:
Чтобы проверить версию вашего расширения, используйте следующую команду:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Если вам нужно обновить расширение до более новой версии, используйте команду:
ALTER EXTENSION google_ml_integration UPDATE;
Предоставить разрешение
- Чтобы разрешить пользователю управлять автоматической генерацией встраивания, предоставьте разрешения INSERT, UPDATE и DELETE для таблиц google_ml.embed_gen_progress и google_ml.embed_gen_settings :
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
'postgres' — это имя пользователя, которому предоставлены права доступа.
- Выполните указанное ниже выражение, чтобы предоставить права на выполнение функции "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте учетной записи службы AlloyDB роль пользователя Vertex AI.
В консоли Google Cloud IAM предоставьте учетной записи службы AlloyDB (которая выглядит следующим образом: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) доступ к роли "Пользователь Vertex AI". В поле PROJECT_NUMBER будет указан номер вашего проекта.
В качестве альтернативы вы можете выполнить следующую команду в терминале Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Подводные камни и устранение неполадок
Цикл «Забвения паролей» | Если вы использовали настройку "в один клик" и не помните свой пароль, перейдите на страницу основной информации об экземпляре в консоли и нажмите "Изменить", чтобы сбросить пароль |
Ошибка "Расширение не найдено" | Если |
5. Генерация вектора "за один раз".
Это основная часть лабораторной работы. Вместо того чтобы писать цикл на Python для обработки этих 50 000 строк, мы будем использовать функцию ai.initialize_embeddings .
Эта единственная команда выполняет две вещи:
- Заполняет все существующие строки.
- Создает триггер для автоматического встраивания будущих строк.
Выполните приведенный ниже SQL-запрос в редакторе запросов AlloyDB.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
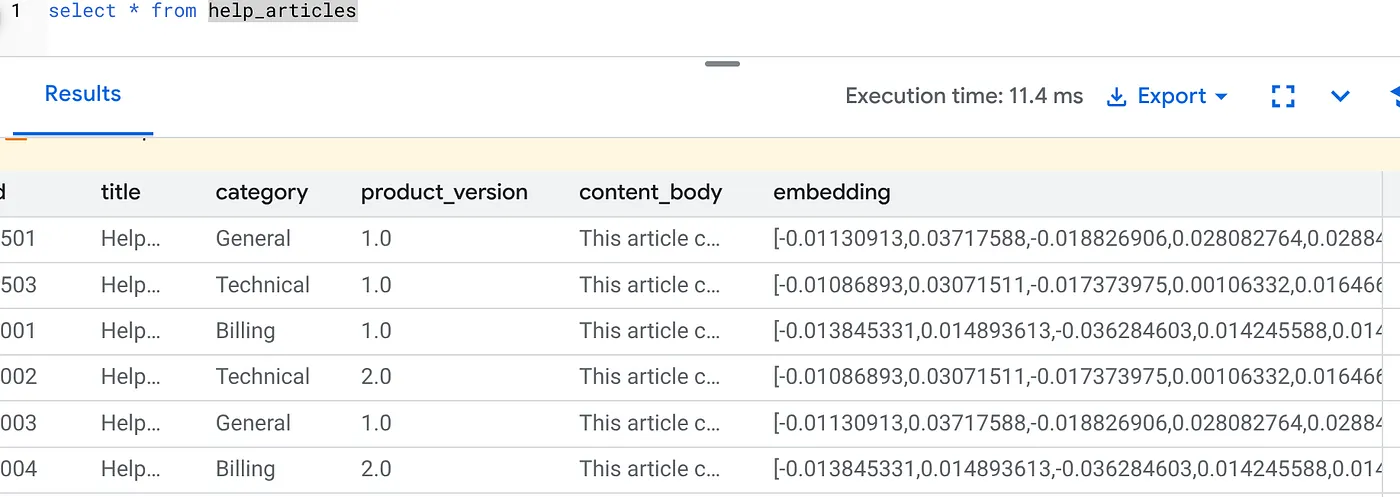
Проверьте векторные представления.
Убедитесь, что столбец embedding теперь заполнен:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
В результате вы должны увидеть изображение, похожее на приведенное ниже:
Что только что произошло?
- Функция автоматического заполнения данных в масштабе: она автоматически обрабатывает существующие 50 000 строк и генерирует векторные представления с помощью Vertex AI.
- Автоматизация: Установив incremental_refresh_mode => 'transactional', AlloyDB автоматически настраивает внутренние триггеры. Для каждой новой строки, вставленной в help_articles, будет мгновенно сгенерировано соответствующее встраивание.
- При желании можно установить incremental_refresh_mode => 'None', чтобы оператор выполнял только пакетные обновления, а для обновления всех строк эмбеддингов вызывался вручную метод ai.refresh_embeddings().
Вы только что заменили очередь Kafka, обработчик Python и скрипт миграции всего шестью строками SQL-запроса. Вот подробная официальная документация по всем атрибутам.
Тестирование триггера в реальном времени
Давайте проверим, работает ли автоматизация "нулевого цикла" для новых данных.
- Вставить новую строку:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Проверьте немедленно:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Результат:
Вы должны увидеть сгенерированный вектор мгновенно, без запуска каких-либо внешних скриптов.
Размер партии настройки
В настоящее время в AlloyDB размер пакета по умолчанию равен 50. Хотя настройки по умолчанию отлично работают, AlloyDB всё же предоставляет пользователям возможность настроить идеальную конфигурацию для своей уникальной модели и набора данных.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Однако пользователям необходимо знать об ограничениях квот, которые могут снизить производительность. Рекомендуемые квоты AlloyDB см. в разделе «Перед началом работы» в документации .
Подводные камни и устранение неполадок
Разрыв в распространении IAM | Вы выполнили команду |
Несоответствие размерности вектора | В таблице |
6. Гибкий контекстный поиск
Теперь мы выполняем гибридный поиск . Мы объединяем семантическое понимание (векторный поиск) с бизнес-логикой (SQL-фильтры).
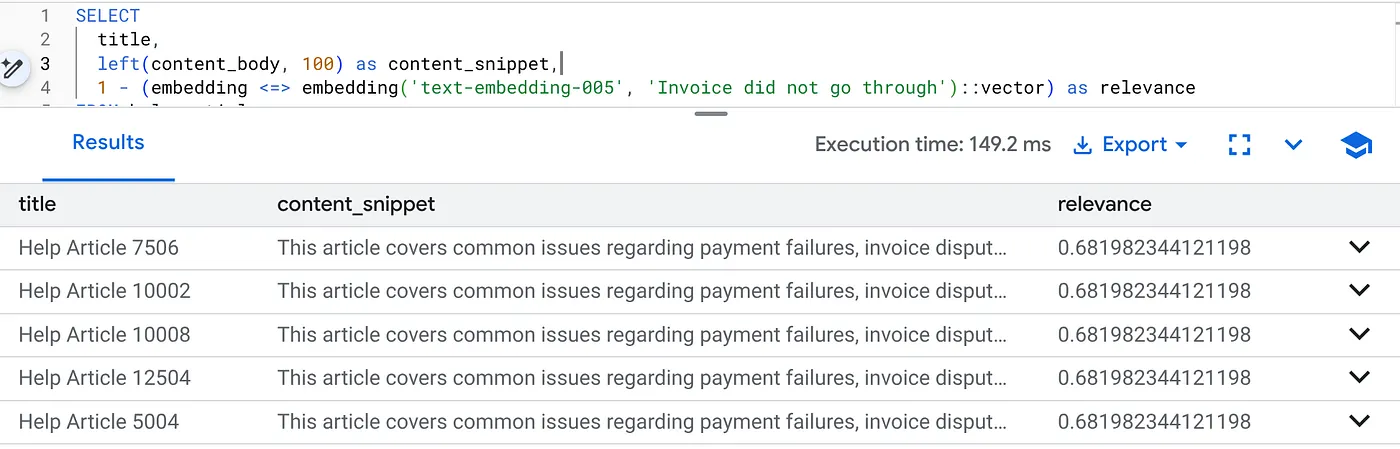
Выполните этот запрос, чтобы найти проблемы с выставлением счетов, относящиеся именно к версии продукта 2.0:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Это гибкий контекст. Поиск "подстраивается" под намерения пользователя (например, по вопросам выставления счетов), соблюдая при этом жесткие бизнес-ограничения (версия 2.0).
Почему это выгодно для стартапов и миграции
- Отсутствие инфраструктурных долгов: вам не пришлось создавать отдельную базу данных Vector (Pinecone/Milvus). Вам не пришлось писать отдельную задачу ETL. Все в Postgres.
- Обновления в реальном времени: благодаря использованию «транзакционного» режима ваш поисковый индекс никогда не устаревает. Как только данные сохраняются, они сразу же готовы к использованию в векторной обработке.
- Масштабируемость: AlloyDB построена на инфраструктуре Google. Она может обрабатывать генерацию миллионов векторов в больших объемах быстрее, чем это когда-либо смог бы сделать ваш скрипт на Python.
Подводные камни и устранение неполадок
Подвох в производительности производства | Проблема: Быстро обрабатывается 50 000 строк. Очень медленно обрабатывается 1 миллион строк , если фильтр по категориям недостаточно избирательный. Решение: Добавить векторный индекс: Для масштабируемости производственной среды необходимо создать индекс: CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops); Проверить использование индекса: Запустите |
Катастрофа, связанная с «несоответствием моделей». | Проблема: Вы инициализировали столбец с помощью text-embedding-005 в процедуре CALL. Если вы случайно используете другую модель (например, text-embedding-004 или модель OSS) в функции запроса SELECT embedding('model-name', ...), размеры могут совпадать (768), но векторное пространство будет совершенно другим. Запрос выполняется без ошибок, но результаты совершенно нерелевантны (мусорные оценки релевантности). Устранение неполадок: Убедитесь, что model_id в ai.initialize_embeddings точно совпадает с model_id в вашем запросе SELECT. |
Результат "тихой пустоты" (чрезмерная фильтрация) | Проблема: Гибридный поиск — это операция «И». Он требует семантического соответствия И соответствия SQL . Если пользователь ищет «Помощь по выставлению счетов», но в столбце
|
4. Ошибки доступа/квот (ошибка 500) | Проблема: Функция
|
5. Нулевые вложения | Проблема: Если вставить данные до полной инициализации модели или если фоновый процесс завершится с ошибкой, в столбце
|
7. Уборка
После завершения этой лабораторной работы не забудьте удалить кластер и экземпляр AlloyDB.
Это должно привести к очистке кластера вместе с его экземплярами.
8. Поздравляем!
Вы успешно создали масштабируемое приложение для поиска в базе знаний. Вместо управления сложным конвейером ETL с помощью скриптов Python и циклов для генерации векторных представлений, вы использовали AlloyDB AI для генерации представлений непосредственно в базе данных с помощью одной команды SQL.
Что мы обсудили
- Мы отказались от использования цикла For в Python для обработки данных.
- Мы сгенерировали 50 000 векторов с помощью одной команды SQL.
- Мы автоматизировали генерацию будущих векторов с помощью триггеров.
- Мы провели гибридный поиск.
Следующие шаги
- Попробуйте это со своим собственным набором данных.
- Изучите документацию AlloyDB AI .
- Посетите веб-сайт Code Vipassana , чтобы узнать о других мастер-классах.