
1. ภาพรวม
ใน Codelab นี้ คุณจะได้สร้างแอปพลิเคชันค้นหาฐานความรู้ที่ปรับขนาดได้ แทนที่จะจัดการไปป์ไลน์ ETL ที่ซับซ้อนด้วยสคริปต์ Python และลูปเพื่อสร้างการฝังเวกเตอร์ คุณจะใช้ AlloyDB AI เพื่อจัดการการสร้างการฝังภายในฐานข้อมูลโดยใช้คำสั่ง SQL เดียว
สิ่งที่คุณจะสร้าง
แอปพลิเคชันฐานข้อมูลฐานความรู้ที่มีประสิทธิภาพสูงและ "ค้นหาได้"
สิ่งที่คุณจะได้เรียนรู้
คุณจะได้เรียนรู้วิธีต่อไปนี้
- จัดสรรคลัสเตอร์ AlloyDB และเปิดใช้ส่วนขยาย AI
- สร้างข้อมูลสังเคราะห์ (มากกว่า 50,000 แถว) โดยใช้ SQL
- เติมข้อมูลเวกเตอร์ฝังสำหรับทั้งชุดข้อมูลโดยใช้การประมวลผลแบบกลุ่ม
- ตั้งค่าทริกเกอร์แบบเพิ่มทีละรายการแบบเรียลไทม์เพื่อฝังข้อมูลใหม่โดยอัตโนมัติ
- ทำการค้นหาแบบผสม (เวกเตอร์ + ตัวกรอง SQL) สำหรับ "Flexing Context"
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์ของคุณโดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น: ทำตามลิงก์และเปิดใช้ API
หรือจะใช้คำสั่ง gcloud สำหรับการดำเนินการนี้ก็ได้ โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
ข้อควรระวังและการแก้ปัญหา
กลุ่มอาการ"โปรเจ็กต์ผี" | คุณเรียกใช้ |
แผงกั้น การเรียกเก็บเงิน | คุณเปิดใช้โปรเจ็กต์แล้ว แต่ลืมบัญชีสำหรับการเรียกเก็บเงิน AlloyDB เป็นเครื่องมือที่มีประสิทธิภาพสูง จึงจะไม่เริ่มทำงานหาก "ถังน้ำมัน" (การเรียกเก็บเงิน) ว่างเปล่า |
ความล่าช้าการเผยแพร่ API | คุณคลิก "เปิดใช้ API" แล้ว แต่บรรทัดคำสั่งยังคงแสดง |
คำถามเกี่ยวกับโควต้า | หากใช้บัญชีทดลองใช้ใหม่ คุณอาจพบโควต้าระดับภูมิภาคสำหรับอินสแตนซ์ AlloyDB หาก |
ตัวแทนบริการ"ซ่อน" | บางครั้งระบบไม่ได้มอบบทบาท |
3. การตั้งค่าฐานข้อมูล
ในแล็บนี้ เราจะใช้ AlloyDB เป็นฐานข้อมูลสำหรับข้อมูลทดสอบ โดยจะใช้คลัสเตอร์เพื่อเก็บทรัพยากรทั้งหมด เช่น ฐานข้อมูลและบันทึก แต่ละคลัสเตอร์มีอินสแตนซ์หลักที่ให้จุดเข้าใช้งานข้อมูล ตารางจะเก็บข้อมูลจริง
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่จะโหลดชุดข้อมูลทดสอบกัน
- คลิกปุ่มหรือคัดลอกลิงก์ด้านล่างไปยังเบราว์เซอร์ที่คุณเข้าสู่ระบบผู้ใช้คอนโซล Google Cloud
- เมื่อทำขั้นตอนนี้เสร็จแล้ว ระบบจะโคลนที่เก็บไปยังโปรแกรมแก้ไข Cloud Shell ในเครื่อง และคุณจะเรียกใช้คำสั่งด้านล่างจากโฟลเดอร์โปรเจ็กต์ได้ (โปรดตรวจสอบว่าคุณอยู่ในไดเรกทอรีโปรเจ็กต์)
sh run.sh
- ตอนนี้ให้ใช้ UI (คลิกลิงก์ในเทอร์มินัลหรือคลิกลิงก์ "แสดงตัวอย่างบนเว็บ" ในเทอร์มินัล
- ป้อนรายละเอียดสำหรับรหัสโปรเจ็กต์ ชื่อคลัสเตอร์ และชื่ออินสแตนซ์เพื่อเริ่มต้นใช้งาน
- ไปหากาแฟดื่มระหว่างที่บันทึกเลื่อนลงมาเรื่อยๆ และคุณสามารถอ่านเกี่ยวกับวิธีที่ระบบดำเนินการนี้เบื้องหลังได้ที่นี่ อาจใช้เวลาประมาณ 10-15 นาที
ข้อควรระวังและการแก้ปัญหา
ปัญหาเรื่อง "ความอดทน" | คลัสเตอร์ฐานข้อมูลเป็นโครงสร้างพื้นฐานที่มีขนาดใหญ่ หากรีเฟรชหน้าเว็บหรือปิดเซสชัน Cloud Shell เนื่องจาก "ดูเหมือนว่าค้างอยู่" คุณอาจมีอินสแตนซ์ "ผี" ที่มีการจัดสรรบางส่วนและลบไม่ได้หากไม่มีการแทรกแซงด้วยตนเอง |
ภูมิภาคไม่ตรงกัน | หากเปิดใช้ API ใน |
คลัสเตอร์ซอมบี้ | หากก่อนหน้านี้คุณใช้ชื่อเดียวกันสำหรับคลัสเตอร์และไม่ได้ลบคลัสเตอร์ออก สคริปต์อาจแจ้งว่ามีชื่อคลัสเตอร์อยู่แล้ว ชื่อคลัสเตอร์ต้องไม่ซ้ำกันภายในโปรเจ็กต์ |
ระยะหมดเวลาของ Cloud Shell | หากคุณพักดื่มกาแฟเป็นเวลา 30 นาที Cloud Shell อาจเข้าสู่โหมดสลีปและยกเลิกการเชื่อมต่อกระบวนการ |
4. การจัดสรรสคีมา
ในขั้นตอนนี้ เราจะพูดถึงหัวข้อต่อไปนี้
เมื่อคลัสเตอร์และอินสแตนซ์ AlloyDB ทำงานแล้ว ให้ไปที่เครื่องมือแก้ไข SQL ของ AlloyDB Studio เพื่อเปิดใช้ส่วนขยาย AI และจัดสรรสคีมา
คุณอาจต้องรอให้อินสแตนซ์สร้างเสร็จ เมื่อพร้อมแล้ว ให้ลงชื่อเข้าใช้ AlloyDB โดยใช้ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้นเมื่อสร้างคลัสเตอร์ ใช้ข้อมูลต่อไปนี้เพื่อตรวจสอบสิทธิ์ใน PostgreSQL
- ชื่อผู้ใช้ : "
postgres" - ฐานข้อมูล : "
postgres" - รหัสผ่าน : "
alloydb" (หรือรหัสผ่านที่คุณตั้งค่าไว้ตอนสร้าง)
เมื่อตรวจสอบสิทธิ์ใน AlloyDB Studio สำเร็จแล้ว ให้ป้อนคำสั่ง SQL ในเอดิเตอร์ คุณเพิ่มหน้าต่างเอดิเตอร์หลายหน้าต่างได้โดยใช้เครื่องหมายบวกทางด้านขวาของหน้าต่างสุดท้าย
คุณจะป้อนคำสั่งสำหรับ AlloyDB ในหน้าต่างเอดิเตอร์ โดยใช้ตัวเลือกเรียกใช้ จัดรูปแบบ และล้างตามที่จำเป็น
เปิดใช้ส่วนขยาย
ในการสร้างแอปนี้ เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เพื่อเข้าถึงอุปกรณ์ปลายทางการคาดการณ์ของ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
สร้างตาราง
เราต้องการชุดข้อมูลเพื่อแสดงให้เห็นถึงขนาด เราจะสร้างแถว "บทความช่วยเหลือ" สังเคราะห์ 50,000 แถวโดยใช้ SQL ทันทีแทนที่จะนำเข้า CSV
คุณสร้างตารางได้โดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
คอลัมน์ item_vector จะอนุญาตให้จัดเก็บค่าเวกเตอร์ของข้อความ
ยืนยันข้อมูล
SELECT count(*) FROM help_articles;
-- Output: 50000
เปิดใช้แฟล็กฐานข้อมูล
ไปที่คอนโซลการกำหนดค่าอินสแตนซ์ คลิก "แก้ไขหลัก" ไปที่การกำหนดค่าขั้นสูง แล้วคลิก "เพิ่มแฟล็กฐานข้อมูล"
หากไม่มี ให้ป้อนในเมนูแบบเลื่อนลงของฟีเจอร์ แล้วตั้งค่าเป็น "เปิด" และอัปเดตอินสแตนซ์
หากไม่มี ให้ป้อนในเมนูแบบเลื่อนลงของฟีเจอร์ แล้วตั้งค่าเป็น "เปิด" และอัปเดตอินสแตนซ์
ขั้นตอนการกำหนดค่าแฟล็กฐานข้อมูลมีดังนี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าคลัสเตอร์
- คลิกคลัสเตอร์ในคอลัมน์ชื่อทรัพยากร
- ในหน้าภาพรวม ให้ไปที่อินสแตนซ์ในคลัสเตอร์ เลือกอินสแตนซ์ แล้วคลิกแก้ไข
- วิธีเพิ่ม แก้ไข หรือลบแฟล็กฐานข้อมูลจากอินสแตนซ์
ติดธง
- หากต้องการเพิ่มแฟล็กฐานข้อมูลลงในอินสแตนซ์ ให้คลิกเพิ่มแฟล็ก
- เลือกฟีเจอร์จากรายการฟีเจอร์ใหม่ของฐานข้อมูล
- ระบุค่าสำหรับ Flag
- คลิกเสร็จสิ้น
- คลิกอัปเดตอินสแตนซ์
- ตรวจสอบว่าส่วนขยาย google_ml_integration เป็นเวอร์ชัน 1.5.2 ขึ้นไป
หากต้องการตรวจสอบเวอร์ชันของส่วนขยาย ให้ใช้คำสั่งต่อไปนี้
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
หากต้องการอัปเดตส่วนขยายให้สูงขึ้น ให้ใช้คำสั่งต่อไปนี้
ALTER EXTENSION google_ml_integration UPDATE;
ให้สิทธิ์
- หากต้องการให้ผู้ใช้จัดการการสร้างการฝังอัตโนมัติ ให้ให้สิทธิ์ INSERT, UPDATE และ DELETE ในตาราง google_ml.embed_gen_progress และ google_ml.embed_gen_settings โดยทำดังนี้
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
"postgres" คือ USER_NAME ที่ได้รับสิทธิ์
- เรียกใช้คำสั่งด้านล่างเพื่อให้สิทธิ์ดำเนินการในฟังก์ชัน "embedding"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล Google Cloud IAM ให้สิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" แก่บัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือจะเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
ข้อควรระวังและการแก้ปัญหา
วงจร "ลืมรหัสผ่าน" | หากคุณใช้การตั้งค่า "คลิกเดียว" และจำรหัสผ่านไม่ได้ ให้ไปที่หน้าข้อมูลพื้นฐานของอินสแตนซ์ในคอนโซล แล้วคลิก "แก้ไข" เพื่อรีเซ็ตรหัสผ่าน |
ข้อผิดพลาด "ไม่พบส่วนขยาย" | หาก |
5. การสร้างเวกเตอร์แบบ "นัดเดียว"
ซึ่งเป็นหัวใจสำคัญของห้องทดลอง แทนที่จะเขียนลูป Python เพื่อประมวลผลแถว 50,000 แถวนี้ เราจะใช้ฟังก์ชัน ai.initialize_embeddings
คำสั่งเดียวนี้ทำได้ 2 อย่าง ได้แก่
- การแสดงโฆษณาสำรองจะแทนที่แถวที่มีอยู่ทั้งหมด
- สร้างทริกเกอร์เพื่อฝังแถวในอนาคตโดยอัตโนมัติ
เรียกใช้คำสั่ง SQL ด้านล่างจากเครื่องมือแก้ไขการค้นหาของ AlloyDB
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
ยืนยันการฝัง
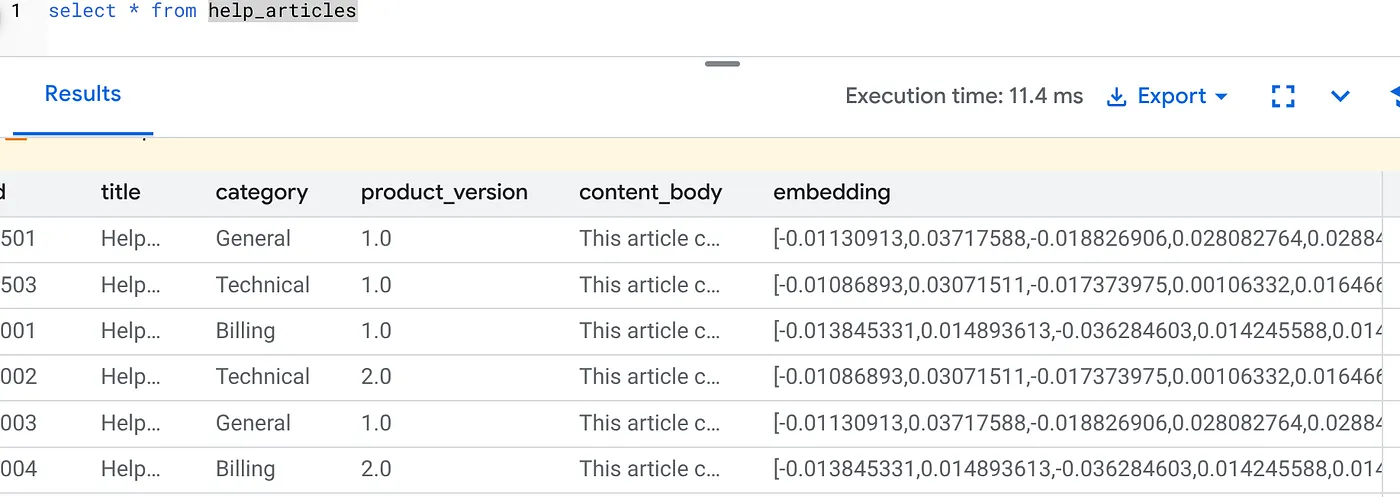
ตรวจสอบว่าคอลัมน์ embedding มีข้อมูลแล้ว
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
คุณควรเห็นผลลัพธ์ที่คล้ายกับด้านล่าง
เกิดอะไรขึ้น
- การแทนที่โฆษณาที่ขาดหายไปจำนวนมาก: ระบบจะสแกนแถวที่มีอยู่ 50,000 แถวโดยอัตโนมัติและสร้างการฝังผ่าน Vertex AI
- การทำงานอัตโนมัติ: เมื่อตั้งค่า incremental_refresh_mode => 'transactional' แล้ว AlloyDB จะตั้งค่าทริกเกอร์ภายในโดยอัตโนมัติ แถวใหม่ที่แทรกลงใน help_articles จะได้รับการฝังทันที
- คุณเลือกตั้งค่า incremental_refresh_mode => ‘None' ได้เพื่อให้รับเฉพาะใบแจ้งยอดเพื่อทำการอัปเดตแบบเป็นกลุ่ม และเรียกใช้ ai.refresh_embeddings() ด้วยตนเองเพื่ออัปเดตการฝังทั้งหมดในแถว
คุณเพิ่งแทนที่คิว Kafka, Worker Python และสคริปต์การย้ายข้อมูลด้วย SQL 6 บรรทัด ดูเอกสารประกอบอย่างเป็นทางการโดยละเอียดสำหรับแอตทริบิวต์ทั้งหมดได้ที่นี่
การทดสอบทริกเกอร์แบบเรียลไทม์
มาตรวจสอบว่าระบบอัตโนมัติ "Zero Loop" ใช้งานได้กับข้อมูลใหม่
- แทรกแถวใหม่
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- ตรวจสอบทันที:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
ผลลัพธ์:
คุณควรเห็นเวกเตอร์ที่สร้างขึ้นทันทีโดยไม่ต้องเรียกใช้สคริปต์ภายนอก
การปรับขนาดกลุ่ม
ปัจจุบัน AlloyDB ตั้งค่าเริ่มต้นของขนาดกลุ่มเป็น 50 แม้ว่าค่าเริ่มต้นจะทำงานได้ดีตั้งแต่แรก แต่ AlloyDB ยังคงให้ผู้ใช้ควบคุมเพื่อปรับแต่งการกำหนดค่าที่สมบูรณ์แบบสำหรับโมเดลและชุดข้อมูลที่ไม่ซ้ำกันของคุณ
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
อย่างไรก็ตาม ผู้ใช้ควรทราบถึงโควต้าที่อาจจำกัดประสิทธิภาพ หากต้องการตรวจสอบโควต้า AlloyDB ที่แนะนำ โปรดดูส่วน "ก่อนที่จะเริ่มต้น" ในเอกสารประกอบ
ข้อควรระวังและการแก้ปัญหา
ช่องว่างในการเผยแพร่ IAM | คุณเรียกใช้ |
มิติข้อมูลเวกเตอร์ไม่ตรงกัน | ตั้งค่าตาราง |
6. การค้นหาตามบริบทที่ยืดหยุ่น
ตอนนี้เราจะทำการค้นหาแบบไฮบริด เราผสานความเข้าใจเชิงความหมาย (Vector) เข้ากับตรรกะทางธุรกิจ (ตัวกรอง SQL)
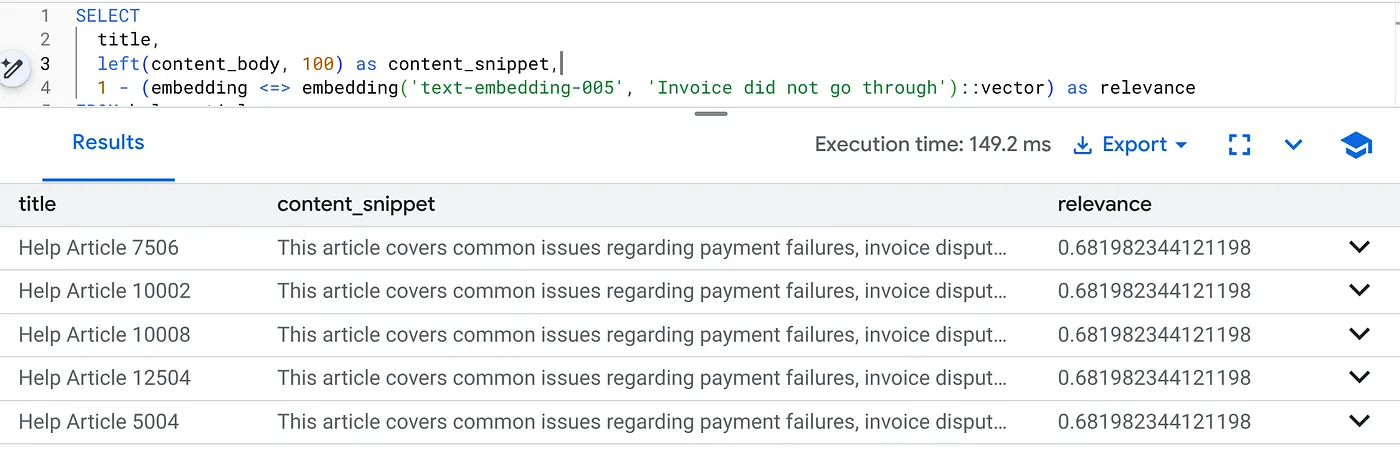
เรียกใช้การค้นหานี้เพื่อค้นหาปัญหาการเรียกเก็บเงินสำหรับผลิตภัณฑ์เวอร์ชัน 2.0 โดยเฉพาะ
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
นี่คือการปรับบริบท การค้นหาจะ "ยืดหยุ่น" เพื่อทำความเข้าใจความตั้งใจของผู้ใช้ ("ปัญหาการเรียกเก็บเงิน") ในขณะที่ยังคงปฏิบัติตามข้อจำกัดทางธุรกิจที่เข้มงวด (เวอร์ชัน 2.0)
เหตุผลที่การย้ายข้อมูลและสตาร์ทอัพควรเลือกใช้
- ไม่มีหนี้สินด้านโครงสร้างพื้นฐาน: คุณไม่ต้องสร้างฐานข้อมูลเวกเตอร์แยกต่างหาก (Pinecone/Milvus) คุณไม่ได้เขียนงาน ETL แยกต่างหาก ทั้งหมดนี้อยู่ใน Postgres
- การอัปเดตแบบเรียลไทม์: การใช้โหมด "ธุรกรรม" จะทำให้ดัชนีการค้นหาของคุณเป็นข้อมูลล่าสุดอยู่เสมอ เมื่อมีการคอมมิตข้อมูลช่วงเวลา ข้อมูลนั้นจะพร้อมใช้งานเวกเตอร์
- การปรับขนาด: AlloyDB สร้างขึ้นบนโครงสร้างพื้นฐานของ Google โดยสามารถจัดการการสร้างเวกเตอร์จำนวนมากนับล้านได้เร็วกว่าสคริปต์ Python ของคุณ
ข้อควรระวังและการแก้ปัญหา
ข้อควรระวังเกี่ยวกับประสิทธิภาพการผลิต | ปัญหา: รวดเร็วสำหรับ 50,000 แถว ช้ามากสำหรับ 1 ล้านแถวหากตัวกรองหมวดหมู่ไม่เลือกมากพอวิธีแก้ปัญหา:เพิ่มดัชนีเวกเตอร์: สำหรับขนาดการผลิต คุณต้องสร้างดัชนี:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);ยืนยันการใช้ดัชนี: เรียกใช้ |
ภัยพิบัติ "โมเดลไม่ตรงกัน" | ปัญหา: คุณเริ่มต้นคอลัมน์โดยใช้ text-embedding-005 ในขั้นตอน CALL หากคุณใช้โมเดลอื่นโดยไม่ได้ตั้งใจ (เช่น text-embedding-004 หรือโมเดล OSS) ในฟังก์ชันการฝังของคำค้นหา SELECT embedding('model-name', ...), มิติข้อมูลอาจตรงกัน (768) แต่เวกเตอร์สเปซจะแตกต่างกันโดยสิ้นเชิง คำค้นหาจะทำงานโดยไม่มีข้อผิดพลาด แต่ผลลัพธ์จะไม่เกี่ยวข้องเลย (คะแนนความเกี่ยวข้องที่ไม่ถูกต้อง) การแก้ปัญหา:ตรวจสอบว่า model_id ใน ai.initialize_embeddings ตรงกับ model_id ในคำค้นหา SELECT ของคุณทุกประการ |
ผลลัพธ์ "ว่างเปล่าเงียบ" (การกรองมากเกินไป) | ปัญหา: การค้นหาแบบไฮบริดเป็นการดำเนินการ "AND" ต้องใช้ทั้งการจับคู่เชิงความหมายและการจับคู่ SQL หากผู้ใช้ค้นหา "ความช่วยเหลือด้านการเรียกเก็บเงิน" แต่คอลัมน์
|
4. ข้อผิดพลาดเกี่ยวกับสิทธิ์/โควต้า (ข้อผิดพลาด 500) | ปัญหา:ฟังก์ชัน
|
5. การฝังค่า Null | ปัญหา:หากคุณแทรกข้อมูลก่อนที่โมเดลจะเริ่มต้นอย่างสมบูรณ์หรือหากโปรแกรมทำงานเบื้องหลังล้มเหลว บางแถวอาจมี
|
7. ล้างข้อมูล
เมื่อแล็บนี้เสร็จแล้ว อย่าลืมลบคลัสเตอร์และอินสแตนซ์ AlloyDB
ซึ่งควรล้างข้อมูลคลัสเตอร์พร้อมกับอินสแตนซ์
8. ขอแสดงความยินดี
คุณสร้างแอปพลิเคชันการค้นหาฐานความรู้ที่ปรับขนาดได้เรียบร้อยแล้ว แทนที่จะจัดการไปป์ไลน์ ETL ที่ซับซ้อนด้วยสคริปต์ Python และลูปเพื่อสร้างการฝังเวกเตอร์ คุณใช้ AlloyDB AI เพื่อจัดการการสร้างการฝังภายในฐานข้อมูลโดยใช้คำสั่ง SQL เดียว
สิ่งที่เราพูดถึง
- เราเลิกใช้ "Python For-Loop" สำหรับการประมวลผลข้อมูล
- เราสร้างเวกเตอร์ 50,000 รายการด้วยคำสั่ง SQL เดียว
- เราได้ทำให้การสร้างเวกเตอร์ในอนาคตเป็นแบบอัตโนมัติด้วยทริกเกอร์
- เราทำการค้นหาแบบไฮบริด
ขั้นตอนถัดไป
- ลองใช้กับชุดข้อมูลของคุณเอง
- สำรวจเอกสารประกอบของ AlloyDB AI
- ดูเวิร์กช็อปเพิ่มเติมได้ที่เว็บไซต์ Code Vipassana