
1. Tổng quan
Trong lớp học lập trình này, bạn sẽ tạo một ứng dụng tìm kiếm Cơ sở kiến thức có khả năng mở rộng. Thay vì quản lý một quy trình ETL phức tạp bằng các tập lệnh và vòng lặp Python để tạo các giá trị nhúng vectơ, bạn sẽ sử dụng AlloyDB AI để xử lý việc tạo giá trị nhúng một cách tự nhiên trong cơ sở dữ liệu bằng một lệnh SQL duy nhất.
Sản phẩm bạn sẽ tạo ra
Một ứng dụng cơ sở dữ liệu cơ sở kiến thức "có thể tìm kiếm" với hiệu suất cao.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Cung cấp một Cụm AlloyDB và bật các tiện ích AI.
- Tạo dữ liệu tổng hợp (hơn 50.000 hàng) bằng SQL.
- Điền lại các vectơ nhúng cho toàn bộ tập dữ liệu bằng cách sử dụng Xử lý hàng loạt.
- Thiết lập Trình kích hoạt gia tăng theo thời gian thực để tự động nhúng dữ liệu mới.
- Thực hiện Tìm kiếm kết hợp (Bộ lọc vectơ + SQL) cho "Flexing Context" (Bối cảnh linh hoạt).
Yêu cầu
2. Trước khi bắt đầu
Tạo dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud. Nhấp vào Kích hoạt Cloud Shell ở đầu Cloud Console.

- Sau khi kết nối với Cloud Shell, bạn có thể kiểm tra để đảm bảo rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt dự án:
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc: Truy cập vào đường liên kết rồi bật các API.
Ngoài ra, bạn có thể dùng lệnh gcloud cho việc này. Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Các vấn đề thường gặp và cách khắc phục
Hội chứng "Dự án ma" | Bạn đã chạy |
Rào chắn thanh toán | Bạn đã bật dự án nhưng quên tài khoản thanh toán. AlloyDB là một công cụ hiệu suất cao; công cụ này sẽ không khởi động nếu "bình xăng" (thanh toán) trống. |
Độ trễ truyền API | Bạn đã nhấp vào "Bật API", nhưng dòng lệnh vẫn hiển thị |
Hạn mức Quags | Nếu đang sử dụng tài khoản dùng thử mới, bạn có thể đạt đến hạn mức theo khu vực cho các phiên bản AlloyDB. Nếu |
Nhân viên hỗ trợ dịch vụ"bị ẩn" | Đôi khi, AlloyDB Service Agent không được tự động cấp vai trò |
3. Thiết lập cơ sở dữ liệu
Trong phòng thí nghiệm này, chúng ta sẽ sử dụng AlloyDB làm cơ sở dữ liệu cho dữ liệu kiểm thử. Nó sử dụng cụm để lưu giữ tất cả các tài nguyên, chẳng hạn như cơ sở dữ liệu và nhật ký. Mỗi cụm có một phiên bản chính cung cấp điểm truy cập vào dữ liệu. Các bảng sẽ chứa dữ liệu thực tế.
Hãy tạo một cụm, thực thể và bảng AlloyDB để tải tập dữ liệu kiểm thử.
- Nhấp vào nút hoặc Sao chép đường liên kết bên dưới vào trình duyệt mà bạn đã đăng nhập người dùng Google Cloud Console.
- Sau khi hoàn tất bước này, kho lưu trữ sẽ được sao chép vào trình chỉnh sửa Cloud Shell cục bộ và bạn có thể chạy lệnh bên dưới từ thư mục dự án (điều quan trọng là bạn phải đảm bảo mình đang ở trong thư mục dự án):
sh run.sh
- Bây giờ, hãy sử dụng giao diện người dùng (nhấp vào đường liên kết trong thiết bị đầu cuối hoặc nhấp vào đường liên kết "xem trước trên web" trong thiết bị đầu cuối.
- Nhập thông tin chi tiết về mã dự án, tên cụm và tên phiên bản để bắt đầu.
- Hãy đi lấy một tách cà phê trong khi nhật ký cuộn và bạn có thể đọc về cách nhật ký thực hiện việc này ở chế độ nền tại đây. Quá trình này có thể mất khoảng 10 đến 15 phút.
Các vấn đề thường gặp và cách khắc phục
Vấn đề về "Sự kiên nhẫn" | Cụm cơ sở dữ liệu là cơ sở hạ tầng lớn. Nếu làm mới trang hoặc kết thúc phiên Cloud Shell vì phiên này "có vẻ bị treo", bạn có thể gặp phải một phiên bản "ảo" được cung cấp một phần và không thể xoá nếu không có sự can thiệp thủ công. |
Khu vực không khớp | Nếu đã bật API trong |
Nhóm zombie | Nếu trước đây bạn đã dùng cùng một tên cho một cụm và chưa xoá cụm đó, thì tập lệnh có thể cho biết tên cụm đã tồn tại. Tên cụm phải là duy nhất trong một dự án. |
Thời gian chờ của Cloud Shell | Nếu thời gian giải lao uống cà phê của bạn là 30 phút, Cloud Shell có thể chuyển sang chế độ ngủ và ngắt kết nối quy trình |
4. Cung cấp giản đồ
Trong bước này, chúng ta sẽ tìm hiểu những nội dung sau:
Sau khi bạn chạy cụm và phiên bản AlloyDB, hãy chuyển đến trình chỉnh sửa SQL của AlloyDB Studio để bật các tiện ích AI và cung cấp giản đồ.
Bạn có thể phải đợi phiên bản của mình được tạo xong. Sau khi tạo xong, hãy đăng nhập vào AlloyDB bằng thông tin đăng nhập mà bạn đã tạo khi tạo cụm. Sử dụng dữ liệu sau để xác thực với PostgreSQL:
- Tên người dùng : "
postgres" - Cơ sở dữ liệu : "
postgres" - Mật khẩu : "
alloydb" (hoặc mật khẩu bạn đặt tại thời điểm tạo)
Sau khi bạn xác thực thành công vào AlloyDB Studio, các lệnh SQL sẽ được nhập vào Trình chỉnh sửa. Bạn có thể thêm nhiều cửa sổ Trình chỉnh sửa bằng cách nhấp vào dấu cộng ở bên phải cửa sổ cuối cùng.
Bạn sẽ nhập các lệnh cho AlloyDB trong cửa sổ trình chỉnh sửa, sử dụng các lựa chọn Chạy, Định dạng và Xoá khi cần.
Bật tiện ích
Để tạo ứng dụng này, chúng ta sẽ sử dụng các tiện ích pgvector và google_ml_integration. Tiện ích pgvector cho phép bạn lưu trữ và tìm kiếm các vectơ nhúng. Tiện ích google_ml_integration cung cấp các hàm mà bạn dùng để truy cập vào các điểm cuối dự đoán của Vertex AI nhằm nhận thông tin dự đoán bằng SQL. Bật các tiện ích này bằng cách chạy các DDL sau:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Tạo bảng
Chúng ta cần một tập dữ liệu để minh hoạ quy mô. Thay vì nhập tệp CSV, chúng ta sẽ tạo ngay 50.000 hàng "Bài viết trợ giúp" giả tạo bằng SQL.
Bạn có thể tạo một bảng bằng câu lệnh DDL bên dưới trong AlloyDB Studio:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
Cột item_vector sẽ cho phép lưu trữ các giá trị vectơ của văn bản.
Xác minh dữ liệu:
SELECT count(*) FROM help_articles;
-- Output: 50000
Bật cờ cơ sở dữ liệu
Chuyển đến bảng điều khiển Cấu hình phiên bản, nhấp vào "Chỉnh sửa chính", chuyển đến phần Cấu hình nâng cao rồi nhấp vào "Thêm cờ cơ sở dữ liệu".
Nếu không, hãy nhập tên đó vào trình đơn thả xuống cờ, đặt thành "ON" rồi cập nhật phiên bản.
Nếu không, hãy nhập tên đó vào trình đơn thả xuống cờ, đặt thành "ON" rồi cập nhật phiên bản.
Các bước định cấu hình cờ cơ sở dữ liệu:
- Trong Cloud Console, hãy chuyển đến trang Cụm.
- Nhấp vào một cụm trong cột Tên tài nguyên.
- Trong trang Tổng quan, hãy chuyển đến Các phiên bản trong cụm, chọn một phiên bản rồi nhấp vào Chỉnh sửa.
- Thêm, sửa đổi hoặc xoá cờ cơ sở dữ liệu khỏi phiên bản:
Thêm cờ
- Để thêm cờ cơ sở dữ liệu vào phiên bản, hãy nhấp vào Thêm cờ.
- Chọn một cờ trong danh sách Cờ cơ sở dữ liệu mới.
- Cung cấp giá trị cho cờ.
- Nhấp vào Xong.
- Nhấp vào Cập nhật phiên bản.
- Xác minh rằng tiện ích google_ml_integration là phiên bản 1.5.2 trở lên:
Để kiểm tra phiên bản tiện ích bằng lệnh sau:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Nếu bạn cần cập nhật tiện ích lên phiên bản cao hơn, hãy dùng lệnh:
ALTER EXTENSION google_ml_integration UPDATE;
Cấp quyền
- Để cho phép người dùng quản lý việc tạo tính năng nhúng tự động, hãy cấp quyền INSERT, UPDATE và DELETE trên các bảng google_ml.embed_gen_progress và google_ml.embed_gen_settings:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
"postgres" là USER_NAME mà bạn cấp quyền.
- Chạy câu lệnh bên dưới để cấp quyền thực thi cho hàm "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Cấp VAI TRÒ Người dùng Vertex AI cho tài khoản dịch vụ AlloyDB
Trên bảng điều khiển IAM của Google Cloud, hãy cấp cho tài khoản dịch vụ AlloyDB (có dạng như sau: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) quyền truy cập vào vai trò "Người dùng Vertex AI". PROJECT_NUMBER sẽ có số dự án của bạn.
Ngoài ra, bạn có thể chạy lệnh bên dưới trong Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Các vấn đề thường gặp và cách khắc phục
Vòng lặp "Quên mật khẩu" | Nếu bạn sử dụng chế độ thiết lập "Một lần nhấp" và không nhớ mật khẩu, hãy chuyển đến trang Thông tin cơ bản về phiên bản trong bảng điều khiển rồi nhấp vào "Chỉnh sửa" để đặt lại mật khẩu |
Lỗi "Không tìm thấy tiện ích" | Nếu |
5. Tính năng tạo vectơ "One-Shot"
Đây là cốt lõi của phòng thí nghiệm. Thay vì viết một vòng lặp Python để xử lý 50.000 hàng này, chúng ta sẽ sử dụng hàm ai.initialize_embeddings.
Lệnh duy nhất này thực hiện hai việc:
- Điền lại tất cả các hàng hiện có.
- Tạo một Trình kích hoạt để tự động nhúng các hàng trong tương lai.
Chạy câu lệnh SQL bên dưới trong Trình chỉnh sửa truy vấn AlloyDB
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
Xác minh các vectơ nhúng
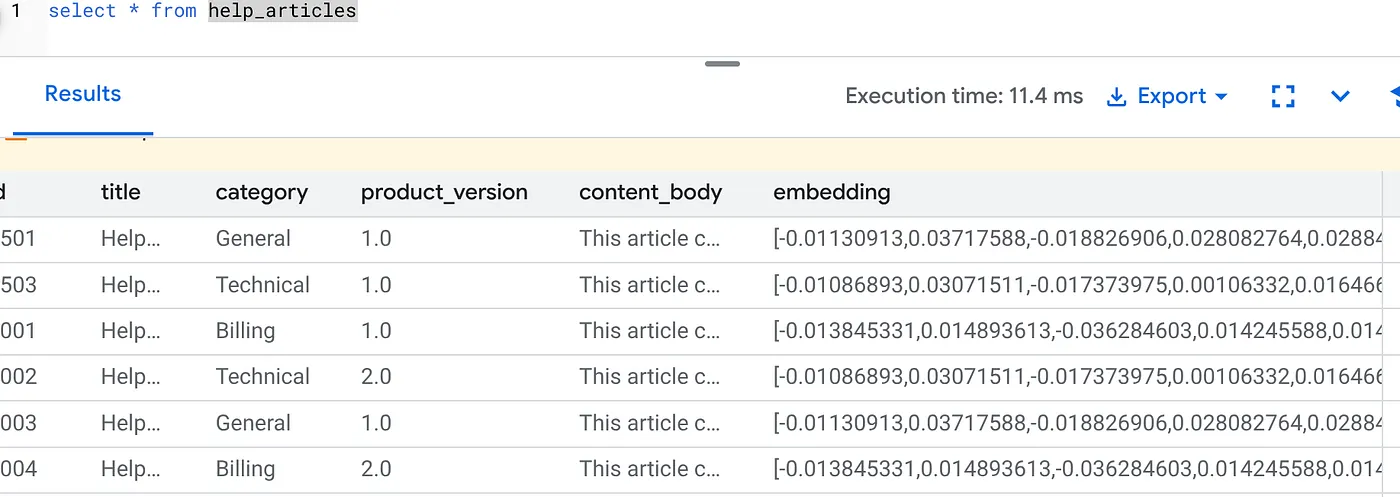
Kiểm tra để đảm bảo cột embedding hiện đã được điền sẵn:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Bạn sẽ thấy kết quả tương tự như dưới đây:
Điều gì vừa xảy ra?
- Điền dữ liệu ở quy mô lớn: Công cụ này tự động quét 50.000 hàng hiện có của bạn và tạo vectơ nhúng thông qua Vertex AI.
- Tự động hoá: Bằng cách đặt incremental_refresh_mode => "transactional", AlloyDB sẽ tự động thiết lập các trình kích hoạt nội bộ. Mọi hàng mới được chèn vào help_articles sẽ được tạo phần nhúng ngay lập tức.
- Bạn có thể tuỳ ý đặt incremental_refresh_mode => "None" để chỉ có thể nhận câu lệnh thực hiện các bản cập nhật hàng loạt và gọi ai.refresh_embeddings() theo cách thủ công để cập nhật tất cả các hàng nhúng.
Bạn vừa thay thế một hàng đợi Kafka, một worker Python và một tập lệnh di chuyển bằng 6 dòng SQL. Sau đây là tài liệu chính thức chi tiết cho tất cả các thuộc tính.
Thử nghiệm trình kích hoạt theo thời gian thực
Hãy xác minh rằng quy trình tự động hoá "Zero Loop" hoạt động đối với dữ liệu mới.
- Chèn một hàng mới:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Kiểm tra ngay:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Kết quả:
Bạn sẽ thấy vectơ được tạo ngay lập tức mà không cần chạy bất kỳ tập lệnh bên ngoài nào.
Điều chỉnh kích thước lô
Hiện tại, AlloyDB mặc định kích thước lô là 50. Mặc dù các giá trị mặc định hoạt động hiệu quả ngay khi bạn bắt đầu sử dụng, nhưng AlloyDB vẫn cho phép người dùng kiểm soát để điều chỉnh cấu hình hoàn hảo cho mô hình và tập dữ liệu riêng biệt của bạn.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Tuy nhiên, người dùng cần biết về hạn mức có thể hạn chế hiệu suất. Để xem hạn mức được đề xuất cho AlloyDB, hãy tham khảo phần "Trước khi bắt đầu" trong tài liệu.
Các vấn đề thường gặp và cách khắc phục
Khoảng trống lan truyền IAM | Bạn đã chạy lệnh IAM |
Vector Dimension Mismatch | Bảng |
6. Tìm kiếm theo ngữ cảnh linh hoạt
Giờ đây, chúng ta sẽ thực hiện Tìm kiếm kết hợp. Chúng tôi kết hợp khả năng hiểu ngữ nghĩa (Vector) với logic nghiệp vụ (Bộ lọc SQL).
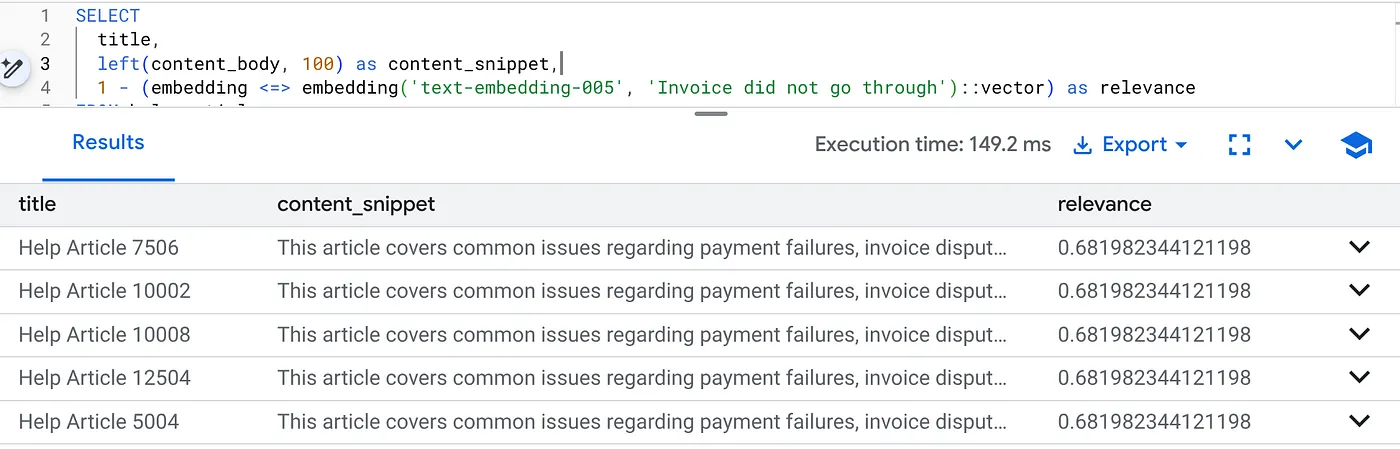
Chạy truy vấn này để tìm các vấn đề về việc thanh toán dành riêng cho Phiên bản 2.0 của Sản phẩm:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Đây là Flexing Context. Tính năng tìm kiếm "linh hoạt" để hiểu ý định của người dùng ("vấn đề về việc thanh toán") trong khi vẫn tuân thủ các ràng buộc nghiêm ngặt về hoạt động kinh doanh (Phiên bản 2.0).
Lý do khiến tính năng này phù hợp với các công ty khởi nghiệp và hoạt động di chuyển
- Không có nợ cơ sở hạ tầng: Bạn không cần tạo một cơ sở dữ liệu vectơ riêng biệt (Pinecone/Milvus). Bạn không viết một công việc ETL riêng biệt. Tất cả đều nằm trong Postgres.
- Thông tin cập nhật theo thời gian thực: Bằng cách sử dụng chế độ "giao dịch", chỉ mục tìm kiếm của bạn sẽ không bao giờ lỗi thời. Khi dữ liệu được xác nhận, dữ liệu đó sẽ sẵn sàng ở dạng vectơ.
- Quy mô: AlloyDB được xây dựng trên cơ sở hạ tầng của Google. Nó có thể xử lý việc tạo hàng loạt hàng triệu vectơ nhanh hơn bất kỳ tập lệnh Python nào của bạn.
Các vấn đề thường gặp và cách khắc phục
Các lỗi thường gặp về hiệu suất trong quá trình sản xuất | Vấn đề: Nhanh đối với 50.000 hàng. Rất chậm đối với 1 triệu hàng nếu bộ lọc danh mục không đủ chọn lọc.Giải pháp:Thêm chỉ mục vectơ: Đối với quy mô sản xuất, bạn phải tạo một chỉ mục:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);Xác minh việc sử dụng chỉ mục: Chạy |
Thảm hoạ "Không khớp mô hình" | Vấn đề: Bạn đã khởi tạo cột bằng cách sử dụng text-embedding-005 trong quy trình CALL. Nếu bạn vô tình sử dụng một mô hình khác (ví dụ: text-embedding-004 hoặc mô hình OSS) trong hàm truy vấn SELECT embedding('model-name', ...), thì các phương diện có thể khớp (768), nhưng không gian vectơ sẽ hoàn toàn khác. Truy vấn chạy mà không gặp lỗi, nhưng kết quả hoàn toàn không liên quan (điểm liên quan rác). Khắc phục sự cố: Đảm bảo model_id trong ai.initialize_embeddings khớp chính xác với model_id trong truy vấn SELECT. |
Kết quả "Silent Empty" (Lọc quá mức) | Vấn đề: Tìm kiếm kết hợp là một thao tác "VÀ". Yêu cầu Khớp ngữ nghĩa VÀ Khớp SQL.Nếu người dùng tìm kiếm "Trợ giúp về việc thanh toán" nhưng cột
|
4. Lỗi về quyền/hạn mức (Lỗi 500) | Vấn đề:Hàm
|
5. Mục nhúng rỗng | Vấn đề:Nếu bạn chèn dữ liệu trước khi mô hình được khởi tạo hoàn toàn hoặc nếu trình chạy ở chế độ nền gặp lỗi, thì một số hàng có thể có
|
7. Dọn dẹp
Sau khi hoàn tất bài thực hành này, đừng quên xoá cụm và phiên bản AlloyDB.
Thao tác này sẽ dọn dẹp cụm cùng với(các) phiên bản của cụm.
8. Xin chúc mừng
Bạn đã tạo thành công một ứng dụng tìm kiếm Cơ sở kiến thức có khả năng mở rộng. Thay vì quản lý một quy trình ETL phức tạp bằng các tập lệnh và vòng lặp Python để tạo các giá trị nhúng vectơ, bạn đã sử dụng AlloyDB AI để xử lý việc tạo giá trị nhúng một cách tự nhiên trong cơ sở dữ liệu bằng một lệnh SQL duy nhất.
Nội dung đã đề cập
- Chúng tôi đã loại bỏ "Vòng lặp For của Python" để xử lý dữ liệu.
- Chúng tôi đã tạo 50.000 vectơ bằng một lệnh SQL.
- Chúng tôi đã tự động hoá việc tạo vectơ trong tương lai bằng các điều kiện kích hoạt.
- Chúng tôi đã thực hiện Tìm kiếm kết hợp.
Các bước tiếp theo
- Hãy thử với tập dữ liệu của riêng bạn.
- Khám phá Tài liệu về AI AlloyDB.
- Hãy truy cập trang web Code Vipassana để biết thêm các hội thảo.