
1. 概览
在此 Codelab 中,您将构建一个可扩缩的知识库搜索应用。您无需使用 Python 脚本和循环来管理复杂的 ETL 流水线以生成向量嵌入,而是使用 AlloyDB AI 通过单个 SQL 命令在数据库中原生处理嵌入生成。
构建内容
一款高性能“可搜索”知识库数据库应用。
学习内容
您将学习如何:
- 预配 AlloyDB 集群并启用 AI 扩展程序。
- 使用 SQL 生成合成数据(5 万行以上)。
- 使用批量处理功能回填整个数据集的矢量嵌入。
- 设置实时增量触发器以自动嵌入新数据。
- 针对“Flexing Context”执行混合搜索(向量 + SQL 过滤条件)。
要求
2. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 启用必需的 API:点击链接并启用 API。
或者,您也可以使用 gcloud 命令来完成此操作。如需了解 gcloud 命令和用法,请参阅文档。
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
注意事项和问题排查
“幽灵项目” 综合征 | 您运行了 |
结算 路障 | 您已启用项目,但忘记了结算账号。AlloyDB 是一款高性能引擎;如果“油箱”(结算)为空,它将无法启动。 |
API 传播 延迟 | 您点击了“启用 API”,但命令行仍显示 |
配额 Quags | 如果您使用的是全新试用账号,则可能会达到 AlloyDB 实例的区域配额。如果 |
“隐藏”服务代理 | 有时,AlloyDB 服务代理不会自动获得 |
3. 数据库设置
在本实验中,我们将使用 AlloyDB 作为测试数据的数据库。它使用集群来保存所有资源,例如数据库和日志。每个集群都有一个主实例,可提供对数据的接入点。表将包含实际数据。
我们来创建 AlloyDB 集群、实例和表,以便加载测试数据集。
- 点击相应按钮,或将下方的链接复制到已登录 Google Cloud 控制台用户的浏览器中。
- 完成此步骤后,代码库将克隆到本地 Cloud Shell 编辑器,您将能够从项目文件夹中运行以下命令(请务必确保您位于项目目录中):
sh run.sh
- 现在,使用界面(点击终端中的链接或点击终端中的“在网页上预览”链接)。
- 输入项目 ID、集群名称和实例名称等详细信息,即可开始使用。
- 在日志滚动时,您可以去喝杯咖啡,并点击此处了解该功能在后台的运作方式。此过程可能需要大约 10-15 分钟。
注意事项和问题排查
“耐心”问题 | 数据库集群是重型基础架构。如果您因 Cloud Shell 会话“看起来卡住了”而刷新页面或终止会话,最终可能会得到一个“幽灵”实例,该实例已部分完成预配,但无法在不进行人工干预的情况下删除。 |
区域不匹配 | 如果您在 |
僵尸集群 | 如果您之前曾使用过某个集群名称,但未删除该集群,脚本可能会提示该集群名称已存在。集群名称在项目中必须是唯一的。 |
Cloud Shell 超时 | 如果您的咖啡休息时间为 30 分钟,Cloud Shell 可能会进入休眠状态并断开 |
4. 架构配置
在此步骤中,我们将介绍以下内容:
在 AlloyDB 集群和实例运行后,前往 AlloyDB Studio SQL 编辑器,启用 AI 扩展程序并预配架构。
您可能需要等待实例完成创建。完成后,使用您在创建集群时创建的凭据登录 AlloyDB。使用以下数据向 PostgreSQL 进行身份验证:
- 用户名:“
postgres” - 数据库:“
postgres” - 密码:“
alloydb”(或您在创建时设置的任何密码)
成功通过 AlloyDB Studio 的身份验证后,您可以在编辑器中输入 SQL 命令。您可以使用最后一个窗口右侧的加号添加多个编辑器窗口。
您将在编辑器窗口中输入 AlloyDB 命令,并根据需要使用“运行”“格式化”和“清除”选项。
启用扩展程序
在构建此应用时,我们将使用扩展程序 pgvector 和 google_ml_integration。借助 pgvector 扩展程序,您可以存储和搜索向量嵌入。google_ml_integration 扩展程序提供了一些函数,您可以使用这些函数访问 Vertex AI 预测端点,以在 SQL 中获取预测结果。运行以下 DDL 以启用这些扩展程序:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
创建表
我们需要一个数据集来展示规模。我们将使用 SQL 立即生成 5 万行合成的“帮助文章”,而不是导入 CSV 文件。
您可以在 AlloyDB Studio 中使用以下 DDL 语句创建表:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
item_vector 列将允许存储文本的矢量值。
验证数据:
SELECT count(*) FROM help_articles;
-- Output: 50000
启用数据库标志
前往实例配置控制台,点击“修改主实例”,然后前往“高级配置”,点击“添加数据库标志”。
如果不是,请在标志下拉菜单中输入该标志,将其设置为“开启”,然后更新实例。
如果不是,请在标志下拉菜单中输入该标志,将其设置为“开启”,然后更新实例。
配置数据库标志的步骤:
- 在 Google Cloud 控制台中,前往“集群”页面。
- 在资源名称列中点击相应集群。
- 在概览页面中,前往集群中的实例,选择一个实例,然后点击修改。
- 对实例添加、修改或删除数据库标志:
添加标志
- 如需向实例添加数据库标志,请点击“添加标志”。
- 从“新增数据库标志”列表中选择一个标志。
- 为标志提供值。
- 点击“完成”。
- 点击更新实例。
- 验证 google_ml_integration 扩展程序是否为 1.5.2 版或更高版本:
您可以使用以下命令查看扩展程序版本:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
如果您需要将扩展程序更新到更高版本,请使用以下命令:
ALTER EXTENSION google_ml_integration UPDATE;
授予权限
- 如需允许用户管理自动嵌入生成,请授予对 google_ml.embed_gen_progress 和 google_ml.embed_gen_settings 表的 INSERT、UPDATE 和 DELETE 权限:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
“postgres”是授予权限的 USER_NAME。
- 运行以下语句,以授予对“embedding”函数的执行权限:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
为 AlloyDB 服务账号授予 Vertex AI User 角色
在 Google Cloud IAM 控制台中,向 AlloyDB 服务账号(格式如下:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)授予“Vertex AI 用户”角色。PROJECT_NUMBER 将包含您的项目编号。
或者,您也可以从 Cloud Shell 终端运行以下命令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
注意事项和问题排查
“密码遗忘”循环 | 如果您使用了“一键式”设置,但不记得密码,请前往控制台中的实例基本信息页面,然后点击“修改”以重置 |
“找不到扩展服务”错误 | 如果 |
5. “一次性”向量生成
这是本实验的核心。我们将使用 ai.initialize_embeddings 函数,而不是编写 Python 循环来处理这 50,000 行数据。
此单个命令会执行两项操作:
- 回填所有现有行。
- 创建触发器以自动嵌入未来的行。
在 AlloyDB 查询编辑器中运行以下 SQL 语句
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
验证嵌入内容
检查 embedding 列是否已填充:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
您应该会看到类似如下所示的结果:
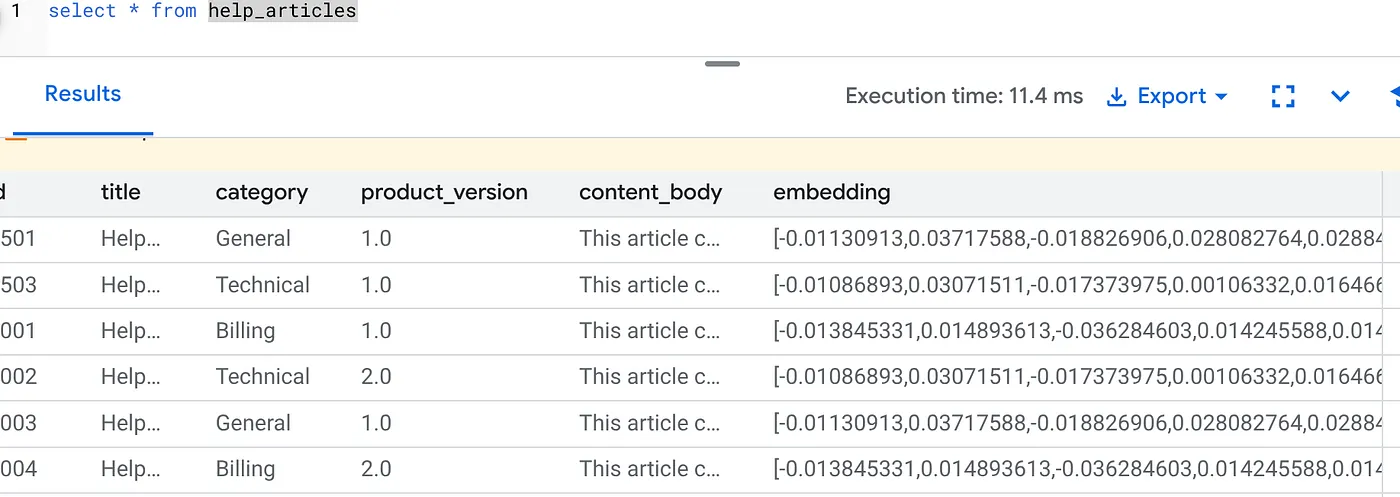
刚才发生了什么?
- 大规模回填:系统会自动扫描您现有的 5 万行数据,并通过 Vertex AI 生成嵌入。
- 自动化:通过设置 incremental_refresh_mode => 'transactional',AlloyDB 会自动设置内部触发器。插入到 help_articles 中的任何新行都会立即生成嵌入内容。
- 您可以选择将 incremental_refresh_mode 设置为“None”,这样您只能获取用于执行批量更新的语句,并手动调用 ai.refresh_embeddings() 来更新所有行的嵌入。
您刚刚用 6 行 SQL 替换了 Kafka 队列、Python worker 和迁移脚本。如需查看所有属性的详细官方文档,请点击此处。
实时触发条件测试
我们来验证一下“零循环”自动化功能是否适用于新数据。
- 插入新行:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- 立即检查:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
结果:
您应该会看到系统立即生成矢量,而无需运行任何外部脚本。
调整批次大小
目前,AlloyDB 默认将批次大小设置为 50。虽然默认设置开箱即用,但 AlloyDB 仍允许用户根据自己的独特模型和数据集调整出最佳配置。
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
不过,用户需要注意可能会限制性能的配额限制。如需查看建议的 AlloyDB 配额,请参阅文档中的“准备工作”部分。
注意事项和问题排查
IAM 传播差距 | 您运行了 |
向量维度不匹配 | 将 |
6. 灵活的内容相关搜索
现在,我们执行混合搜索。我们将语义理解(向量)与业务逻辑(SQL 过滤条件)相结合。
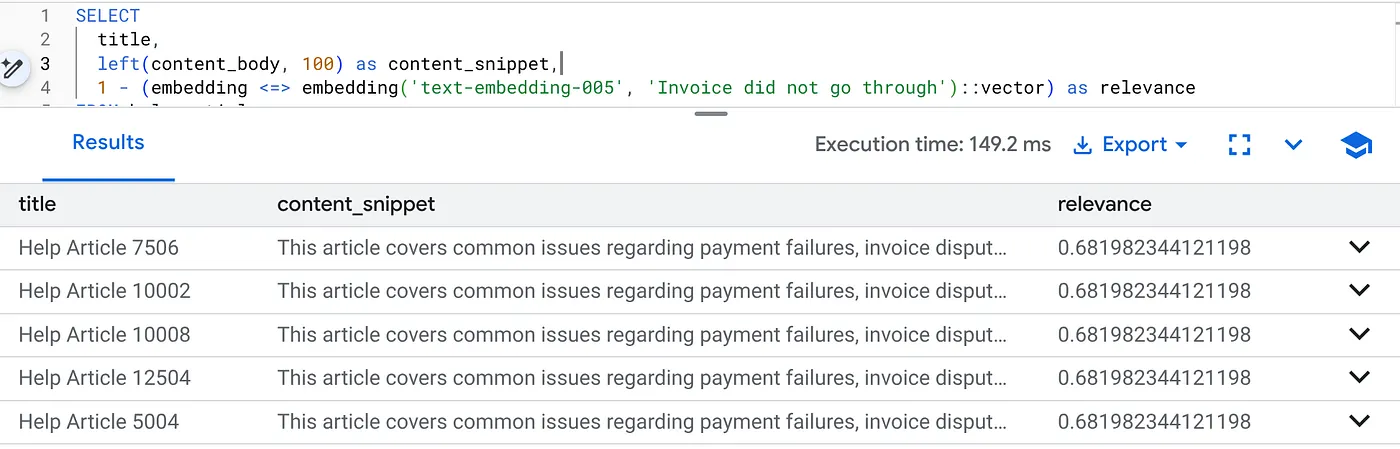
运行以下查询,查找特定于产品版本 2.0 的结算问题:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
这是 Flexing Context。搜索会“灵活”地理解用户意图(“账单问题”),同时遵守严格的业务限制(版本 2.0)。
为何此功能对初创公司和迁移有益
- 零基础设施债务:您没有启动单独的向量数据库 (Pinecone/Milvus)。您没有编写单独的 ETL 作业。所有数据都在 Postgres 中。
- 实时更新:通过使用“事务性”模式,您的搜索索引绝不会过时。数据提交后,即可转换为向量。
- 可伸缩性:AlloyDB 基于 Google 的基础架构构建。它可以处理数百万个向量的批量生成,速度比您的 Python 脚本快得多。
注意事项和问题排查
生产环境中的性能问题 | 问题:5 万行数据处理速度快。如果类别过滤条件不够精细,则处理 100 万行数据时速度非常慢。解决方案:添加向量索引:对于生产规模,您必须创建索引:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);验证索引使用情况:运行 |
“模型不匹配”灾难 | 问题:您在 CALL 过程中使用 text-embedding-005 初始化了列。如果您在 SELECT 查询函数 embedding('model-name', …) 中意外使用了其他模型(例如 text-embedding-004 或 OSS 模型),则维度可能相同 (768),但向量空间会完全不同。查询会正常运行,但结果完全不相关(相关性得分为垃圾)。问题排查:确保 ai.initialize_embeddings 中的 model_id 与 SELECT 查询中的 model_id 完全一致。 |
“无声空”结果(过度过滤) | 问题:混合搜索是“AND”运算。它需要语义匹配和 SQL 匹配。如果用户搜索“Billing help”,但
|
4. 权限/配额错误(500 错误) | 问题:
|
5. Null Embeddings | 问题:如果您在模型完全初始化之前插入数据,或者后台工作器失败,则某些行的
|
7. 清理
完成本实验后,请务必删除 AlloyDB 集群和实例。
它应清理集群及其实例。
8. 恭喜
您已成功构建可扩缩的知识库搜索应用。您无需使用 Python 脚本和循环来管理复杂的 ETL 流水线以生成向量嵌入,而是使用 AlloyDB AI 通过单个 SQL 命令在数据库中原生处理嵌入生成。
我们的学习内容
- 我们淘汰了用于数据处理的“Python For 循环”。
- 我们使用一条 SQL 命令生成了 5 万个向量。
- 我们使用触发器自动生成未来的矢量。
- 我们执行了混合搜索。
后续步骤
- 不妨使用您自己的数据集试一下。
- 探索 AlloyDB AI 文档。
- 如需了解更多工作坊,请访问 Code Vipassana 网站。