
1. 總覽
在本程式碼研究室中,您將建構可擴充的知識庫搜尋應用程式。您不必使用 Python 指令和迴圈管理複雜的 ETL 管道來生成向量嵌入,而是使用 AlloyDB AI,透過單一 SQL 指令在資料庫中原生處理嵌入生成作業。
建構項目
高效能「可搜尋」知識庫資料庫應用程式。
課程內容
您將學習下列內容:
- 佈建 AlloyDB 叢集並啟用 AI 擴充功能。
- 使用 SQL 產生合成資料 (50,000 列以上)。
- 使用批次處理功能,為整個資料集回填向量嵌入。
- 設定即時增量觸發條件,自動嵌入新資料。
- 對「Flexing Context」執行混合搜尋 (向量 + SQL 篩選器)。
需求條件
2. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境。按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連至 Cloud Shell 後,請使用下列指令確認驗證已完成,專案也已設為獲派的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令已瞭解您的專案。
gcloud config list project
- 如果未設定專案,請使用下列指令設定:
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API:按照連結啟用 API。
或者,您也可以使用 gcloud 指令。如要瞭解 gcloud 指令和用法,請參閱說明文件。
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
常見問題與疑難排解
「幽靈專案」 症候群 | 您執行了 |
帳單 路障 | 您已啟用專案,但忘記帳單帳戶。AlloyDB 是高效能引擎,如果「油箱」(帳單) 空了,就無法啟動。 |
API 傳播 延遲 | 您點選了「啟用 API」,但指令列仍顯示 |
配額 Quags | 如果您使用的是全新試用帳戶,可能會達到 AlloyDB 執行個體的區域配額。如果 |
「隱藏」服務專員 | 有時系統不會自動將 |
3. 資料庫設定
在本實驗室中,我們將使用 AlloyDB 做為測試資料的資料庫。並使用「叢集」保存所有資源,例如資料庫和記錄檔。每個叢集都有「主要執行個體」,可做為資料的存取點。資料表會保存實際資料。
我們來建立 AlloyDB 叢集、執行個體和資料表,以便載入測試資料集。
- 按一下按鈕,或將下方連結複製到已登入 Google Cloud 控制台使用者的瀏覽器。
- 完成這個步驟後,存放區會複製到本機 Cloud Shell 編輯器,您就能從專案資料夾執行下列指令 (請務必確認您位於專案目錄中):
sh run.sh
- 現在請使用 UI (按一下終端機中的連結,或按一下終端機中的「preview on web」連結)。
- 輸入專案 ID、叢集和執行個體名稱等詳細資料,即可開始使用。
- 在記錄檔捲動時,您可以去喝杯咖啡,並在這裡瞭解系統在幕後執行的作業。這個過程大約需要 10 到 15 分鐘。
常見問題與疑難排解
「耐心」問題 | 資料庫叢集是繁重的基礎架構,如果因為「看起來卡住」而重新整理頁面或終止 Cloud Shell 工作階段,可能會導致「虛擬」執行個體部分佈建完成,且必須手動介入才能刪除。 |
區域不符 | 如果您在 |
殭屍叢集 | 如果您先前使用過相同名稱的叢集,但未刪除,指令碼可能會顯示叢集名稱已存在。叢集名稱在專案內不得重複。 |
Cloud Shell 逾時 | 如果咖啡休息時間為 30 分鐘,Cloud Shell 可能會進入休眠狀態,並中斷 |
4. 結構定義佈建
本步驟將涵蓋下列內容:
AlloyDB 叢集和執行個體啟動後,請前往 AlloyDB Studio SQL 編輯器啟用 AI 擴充功能,並佈建結構定義。
您可能需要等待執行個體建立完成。完成後,請使用建立叢集時建立的憑證登入 AlloyDB。使用下列資料向 PostgreSQL 進行驗證:
- 使用者名稱:「
postgres」 - 資料庫:「
postgres」 - 密碼:「
alloydb」(或您在建立時設定的密碼)
成功驗證 AlloyDB Studio 後,即可在編輯器中輸入 SQL 指令。如要新增多個編輯器視窗,請按一下最後一個視窗右側的加號。
您會在編輯器視窗中輸入 AlloyDB 指令,並視需要使用「執行」、「格式化」和「清除」選項。
啟用擴充功能
我們會使用 pgvector 和 google_ml_integration 擴充功能建構這個應用程式。pgvector 擴充功能可讓您儲存及搜尋向量嵌入。google_ml_integration 擴充功能提供多種函式,可供您存取 Vertex AI 預測端點,並在 SQL 中取得預測結果。執行下列 DDL,啟用這些擴充功能:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
建立資料表
我們需要資料集來展示規模。我們不會匯入 CSV 檔案,而是使用 SQL 立即產生 50,000 列合成的「說明文章」。
您可以在 AlloyDB Studio 中使用下列 DDL 陳述式建立資料表:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
item_vector 欄可儲存文字的向量值。
驗證資料:
SELECT count(*) FROM help_articles;
-- Output: 50000
啟用資料庫旗標
前往執行個體設定控制台,按一下「編輯主要」,然後前往「進階設定」,並點選「新增資料庫旗標」。
如果沒有,請在旗標下拉式選單中輸入,並設為「開啟」,然後更新執行個體。
如果沒有,請在旗標下拉式選單中輸入,並設為「開啟」,然後更新執行個體。
設定資料庫旗標的步驟:
- 前往 Google Cloud 控制台的「叢集」頁面。
- 按一下「資源名稱」欄中的叢集。
- 在「總覽」頁面中,前往叢集中的「執行個體」,選取執行個體,然後按一下「編輯」。
- 從執行個體新增、修改或刪除資料庫旗標:
新增旗標
- 如要為執行個體新增資料庫旗標,請按一下「新增旗標」。
- 從「New database flag」(新的資料庫旗標) 清單中選取旗標。
- 提供旗標值。
- 按一下 [完成]。
- 按一下「更新執行個體」。
- 確認 google_ml_integration 擴充功能為 1.5.2 以上版本:
如要使用下列指令檢查擴充功能版本:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
如要將擴充功能更新至較高版本,請使用下列指令:
ALTER EXTENSION google_ml_integration UPDATE;
授予權限
- 如要讓使用者管理自動產生嵌入內容,請授予 google_ml.embed_gen_progress 和 google_ml.embed_gen_settings 資料表的 INSERT、UPDATE 和 DELETE 權限:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
「postgres」是獲授權的使用者名稱。
- 執行下列陳述式,授予「embedding」函式的執行權:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
為 AlloyDB 服務帳戶授予 Vertex AI 使用者角色
在 Google Cloud IAM 控制台,授予 AlloyDB 服務帳戶 (格式如下:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)「Vertex AI 使用者」角色存取權。PROJECT_NUMBER 會顯示您的專案編號。
或者,您也可以從 Cloud Shell 終端機執行下列指令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
常見問題與疑難排解
「密碼失憶」迴圈 | 如果您使用「一鍵」設定,但忘記密碼,請前往控制台的「執行個體基本資訊」頁面,然後按一下「編輯」重設 |
「找不到擴充功能」錯誤 | 如果 |
5. 「單次」向量生成
這是實驗室的核心內容。我們不會編寫 Python 迴圈來處理這 50,000 列資料,而是使用 ai.initialize_embeddings 函式。
這個單一指令會執行下列兩項作業:
- 補充所有現有資料列。
- 建立觸發條件,自動嵌入未來的資料列。
從 AlloyDB 查詢編輯器執行下列 SQL 陳述式
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
驗證嵌入
確認 embedding 欄位現在已填入:
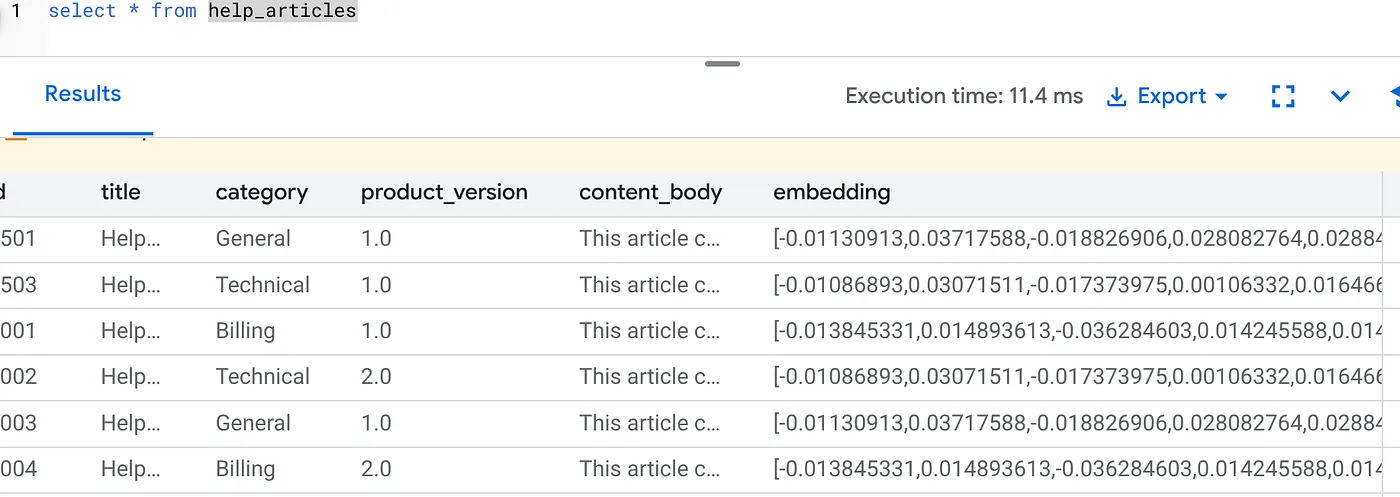
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
畫面會顯示類似以下的結果:
發生什麼事了?
- 大規模回填:系統會自動掃描現有的 50,000 列,並透過 Vertex AI 生成嵌入項目。
- 自動化:設定 incremental_refresh_mode => 'transactional' 後,AlloyDB 會自動設定內部觸發條件。插入 help_articles 的任何新資料列都會立即生成嵌入內容。
- 您可以選擇設定 incremental_refresh_mode => ‘None',這樣您就只能取得陳述式來進行大量更新,並手動呼叫 ai.refresh_embeddings() 來更新所有資料列的嵌入。
您剛才只用 6 行 SQL 程式碼,就取代了 Kafka 佇列、Python 工作人員和遷移指令碼。如需所有屬性的詳細資料,請參閱官方說明文件。
即時觸發測試
請確認「零迴圈」自動化功能是否適用於新資料。
- 插入新資料列:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- 立即檢查:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
結果:
您應該會看到系統立即生成向量,不必執行任何外部指令碼。
微調批次大小
目前 AlloyDB 預設的批量大小為 50。AlloyDB 預設設定已能提供絕佳效能,但使用者仍可自行調整,為獨特的模型和資料集設定最佳配置。
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
不過,使用者必須注意配額限制,這可能會影響效能。如要查看建議的 AlloyDB 配額,請參閱說明文件的「事前準備」一節。
常見問題與疑難排解
IAM 傳播落差 | 您已執行 |
向量維度不符 | 資料表 |
6. 彈性脈絡搜尋
現在執行混合型搜尋。我們結合語意理解 (向量) 和商業邏輯 (SQL 篩選條件)。
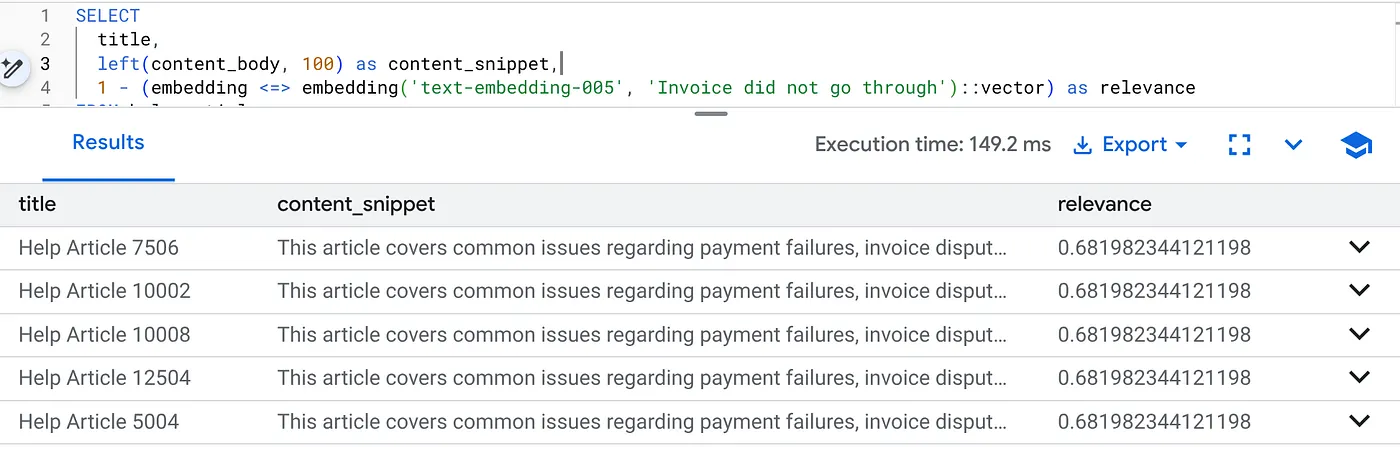
執行這項查詢,找出 Product Version 2.0 的帳單問題:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
這就是彈性背景資訊。搜尋功能會「彈性」解讀使用者意圖 (「帳單問題」),同時遵守嚴格的業務限制 (2.0 版)。
為什麼這項功能適合新創公司和遷移作業
- 基礎架構債務為零:您並未啟動個別的向量資料庫 (Pinecone/Milvus)。您並未撰寫獨立的 ETL 工作。一切都在 Postgres 中。
- 即時更新:使用「交易」模式時,搜尋索引絕不會過時。資料一經提交,即可轉換為向量。
- 擴充性:AlloyDB 建構在 Google 基礎架構上,與 Python 指令碼相比,這項功能可處理數百萬個向量的大量生成作業,速度更快。
常見問題與疑難排解
生產環境效能錯誤 | 問題:快速處理 50,000 列資料。如果類別篩選器不夠精確,100 萬列的查詢速度會非常緩慢。解決方法:新增向量索引:如要正式發布,您必須建立索引:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops);驗證索引使用情形:執行 |
「模型不符」災難 | 問題:您在 CALL 程序中,使用 text-embedding-005 初始化資料欄。如果您在 SELECT 查詢函式 embedding('model-name', ...) 中誤用其他模型 (例如 text-embedding-004 或 OSS 模型),維度可能會相符 (768),但向量空間會完全不同。查詢會順利執行,但結果完全不相關 (關聯性分數為垃圾)。疑難排解:請確保 ai.initialize_embeddings 中的 model_id 與 SELECT 查詢中的 model_id 完全相符。 |
「無聲空白」結果 (過度篩選) | 問題:混合搜尋是「AND」運算。這需要語意比對和 SQL 比對。如果使用者搜尋「帳單說明」,但
|
4. 權限/配額錯誤 (500 錯誤) | 問題:
|
5. 空值嵌入 | 問題:如果在模型完全初始化「之前」插入資料,或背景工作人員失敗,部分資料列的
|
7. 清理
完成本實驗室後,請務必刪除 AlloyDB 叢集和執行個體。
這項作業應會清理叢集及其執行個體。
8. 恭喜
您已成功建構可擴充的知識庫搜尋應用程式。您不必使用 Python 指令和迴圈管理複雜的 ETL 管道來生成向量嵌入,而是使用 AlloyDB AI,透過單一 SQL 指令在資料庫中原生處理嵌入生成作業。
涵蓋內容
- 我們終止了「Python For-Loop」資料處理作業。
- 我們使用一個 SQL 指令產生了 50,000 個向量。
- 我們透過觸發條件自動生成未來的向量。
- 我們執行了混合型搜尋。
後續步驟
- 請使用自己的資料集試試看。
- 請參閱 AlloyDB AI 說明文件。
- 如要參加更多工作坊,請前往 Code Vipassana 網站。